 解析ChatGPT背后的技術演進
解析ChatGPT背后的技術演進

解析ChatGPT背后的技術演進
一、OpenAI正式發布多模態大模型GPT-4,實現多重能力躍升
(一)多模態大模型GPT-4是OpenAI公司GPT系列最新一代模型
美國OpenAI公司成立于2015年12月,是全球頂級的人工智能研究機構之一,創始人 包括Elon Musk、著名投資者Sam Altman、支付服務PayPal創始人Peter Thiel等人。 OpenAI作為人工智能領域的革命者,成立至今開發出多款人工智能產品。2016年, OpenAI推出了用于強化學習研究的工具集OpenAI Gym;同時推出開源平臺OpenAI Universe,用于測試和評估智能代理機器人在各類環境中的表現。2019年,OpenAI 發布了GPT-2模型,可根據輸入文本自動生成語言,展現出人工智能創造性思維的 能力;2020年更新了GPT-3語言模型,并在其基礎上發布了OpenAI Codex模型,該 模型可以自動生成完整有效的程序代碼。
2021年1月,OpenAI發布了OpenAI CLIP, 用于進行圖像和文本的識別分類;同時推出全新產品DALL-E,該模型可以根據文字 描述自動生成對應的圖片,2022年更新的DALL-E2更是全方位改進了生成圖片的質 量,獲得了廣泛好評。 2022年12月,OpenAI推出基于GPT-3.5的新型AI聊天機器人ChatGPT,在發布進 兩個月后擁有1億用戶,成為史上用戶增長最快的應用;美東時間2023年3月14日, ChatGPT的開發機構OpenAI正式推出多模態大模型GPT-4。
GPT(General Pre-Training)系列模型即通用預訓練語言模型,是一種利用 Transformer作為特征抽取器,基于深度學習技術的自然語言處理模型。 GPT系列模型由OpenAI公司開發,經歷了長達五年時間的發展: (1)其最早的產品GPT模型于2018年6月發布,該模型可以根據給定的文本序列進 行預測下一個單詞或句子,充分證明通過對語言模型進行生成性預訓練可以有效減 輕NLP任務中對于監督學習的依賴; (2)2019年2月GPT-2模型發布,該模型取消了原GPT模型中的微調階段,變為無 監督模型,同時,GPT-2采用更大的訓練集嘗試zero-shot學習,通過采用多任務模 型的方式使其在面對不同任務時都能擁有更強的理解能力和較高的適配性;
(3)GPT-3模型于2020年6月被發布,它在多項自然語言處理任務上取得了驚人的 表現,并被認為是迄今為止最先進的自然語言處理模型之一。GPT-3訓練使用的數 據集為多種高質量數據集的混合,一次保證了訓練質量;同時,該模型在下游訓練 時用Few-shot取代了GPT-2模型使用的zero-shot,即在執行任務時給予少量樣例, 以此提高準確度;除此之外,它在前兩個模型的基礎上引入了新的技術——“零樣 本學習”,即GPT-3即便沒有對特定的任務進行訓練也可以完成相應的任務,這使 得GPT-3面對陌生語境時具有更好的靈活性和適應性。
(4)2022年11月,OpenAI發布GPT-3.5模型,是由GPT-3微調出來的版本,采用 不同的訓練方式,其功能更加強大。基于GPT-3.5模型,并加上人類反饋強化學習 (RLHF)發布ChatGPT應用,ChatGPT的全稱為Chat Generative Pre-trained Transformer,是建立在大型語言模型基礎上的對話式自然語言處理工具,表現形式 是一種聊天機器人程序,能夠學習及理解人類的語言,根據聊天的上下文進行互動, 甚至能夠完成翻譯、編程、撰寫論文、編輯郵件等功能。 (5)2023年3月,OpenAI正式發布大型多模態模型GPT-4(輸入圖像和文本,輸出 文本輸出),此前主要支持文本,現模型能支持識別和理解圖像。

(二)GPT大模型通過底層技術的疊加,實現組合式的創新
由于OpenAI并沒有提供關于GPT-4用于訓練的數據、算力成本、訓練方法、架構等 細節,故我們本章主要討論ChatGPT模型的技術路徑。 ChatGPT模型從算法分來上來講屬于生成式大規模語言模型,底層技術包括 Transformer架構、有監督微調訓練、RLHF強化學習等,ChatGPT通過底層技術 的疊加,實現了組合式的創新。 GPT模型采用了由Google提出的Transformer架構。Transformer架構采用自注意 力機制的序列到序列模型,是目前在自然語言處理任務中最常用的神經網絡架構之 一。相比于傳統的循環神經網絡(RNN)或卷積神經網絡(CNN),Transformer 沒有顯式的時間或空間結構,因此可以高效地進行并行計算,并且Transformer具有 更好的并行化能力和更強的長序列數據處理能力。
ChatGPT模型采用了“預訓練+微調”的半監督學習的方式進行訓練。第一階段是 Pre-Training階段,通過預訓練的語言模型(Pretrained Language Model),從大 規模的文本中提取訓練數據,并通過深度神經網絡進行處理和學習,進而根據上下 文預測生成下一個單詞或者短語,從而生成流暢的語言文本;第二階段是Fine-tuning 階段,將已經完成預訓練的GPT模型應用到特定任務上,并通過少量的有標注的數 據來調整模型的參數,以提高模型在該任務上的表現。
ChatGPT在訓練中使用了RLHF人類反饋強化學習模型,是GPT-3模型經過升級并 增加對話功能后的最新版本。2022年3月,OpenAI發布InstructGPT,這一版本是 GPT-3模型的升級版本。相較于之前版本的GPT模型,InstructGPT引入了基于人類 反饋的強化學習技術(Reinforcement Learning with Human Feedback,RLHF), 對模型進行微調,通過獎勵機制進一步訓練模型,以適應不同的任務場景和語言風 格,給出更符合人類思維的輸出結果。
RLHF的訓練包括訓練大語言模型、訓練獎勵模型及RLHF微調三個步驟。首先,需 要使用預訓練目標訓練一個語言模型,同時也可以使用額外文本進行微調。其次, 基于語言模型訓練出獎勵模型,對模型生成的文本進行質量標注,由人工標注者按 偏好將文本從最佳到最差進行排名,借此使得獎勵模型習得人類對于模型生成文本 序列的偏好。最后利用獎勵模型輸出的結果,通過強化學習模型微調優化,最終得 到一個更符合人類偏好語言模型。
(三)GPT-4相較于ChatGPT實現多重能力躍遷
ChatGPT于2022年11月推出之后,僅用兩個月時間月活躍用戶數便超過1億,在短 時間內積累了龐大的用戶基數,也是歷史上增長最快的消費應用。多模態大模型GPT-4是OpenAI的里程碑之作,是目前最強的文本生成模型。 ChatGPT推出后的三個多月時間里OpenAI就正式推出GPT-4,再次拓寬了大模型的 能力邊界。GPT-4是一個多模態大模型(接受圖像和文本輸入,生成文本),相比 上一代,GPT-4可以更準確地解決難題,具有更廣泛的常識和解決問題的能力:更 具創造性和協作性;能夠處理超過25000個單詞的文本,允許長文內容創建、擴展 對話以及文檔搜索和分析等用例。
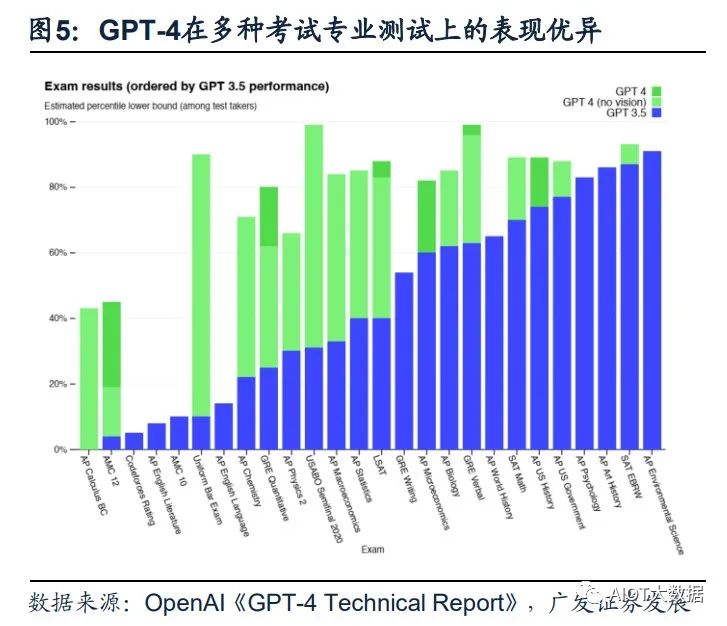
(1)GPT-4具備更高的準確性及更強的專業性。GPT-4在更復雜、細微的任務處理 上回答更可靠、更有創意,在多類考試測驗中以及與其他LLM的benchmark比較中 GPT-4明顯表現優異。GPT-4在模擬律師考試GPT-4取得了前10%的好成績,相比 之下GPT-3.5是后10%;生物學奧賽前1%;美國高考SAT中GPT-4在閱讀寫作中拿 下710分高分、數學700分(滿分800)。
(2)GPT能夠處理圖像內容,能夠識別較為復雜的圖片信息并進行解讀。GPT-4 突破了純文字的模態,增加了圖像模態的輸入,支持用戶上傳圖像,并且具備強大 的圖像能力—能夠描述內容、解釋分析圖表、指出圖片中的不合理指出或解釋梗圖。 在OpenAI發布的產品視頻中,開發者給GPT-4輸入了一張“用VGA電腦接口給 iPhone充電”的圖片,GPT-4不僅可以可描述圖片,還指出了圖片的荒謬之處。
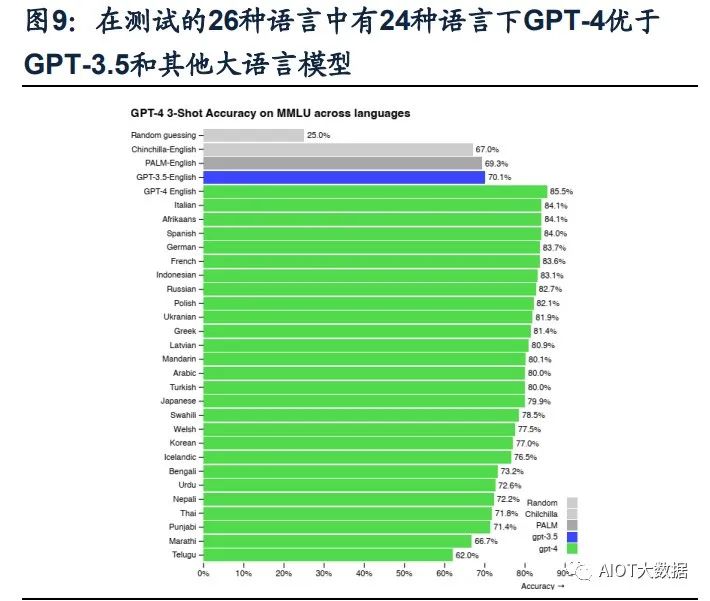
(3)GPT-4可以處理超過25000字的文本。在文本處理上,GPT-4支持輸入的文字 上限提升至25000字,允許長文內容創建、擴展對話以及文檔搜索和分析等用例。 且GPT-4的多語言處理能力更優,在GPT-4的測評展示中,GPT-4可以解決法語的 物理問題,且在測試的英語、拉脫維亞語、威爾士語和斯瓦希里語等26種語言中, 有24種語言下,GPT-4優于GPT-3.5和其他大語言模型(Chinchilla、PaLM)的英 語語言性能。(4)具備自我訓練與預測能力,同時改善幻覺、安全等局限性。GPT-4的一大更新 重點是建立了一個可預測拓展的深度學習棧,使其具備了自我訓練及預測能力。同 時,GPT-4在相對于以前的模型已經顯著減輕了幻覺問題。在OpenAI的內部對抗性 真實性評估中,GPT-4的得分比最新的GPT-3.5模型高 40%;在安全能力的升級上, GPT-4明顯超出ChatGPT和GPT3.5。
(四)商業模式愈發清晰,微軟Copilot引發跨時代的生產力變革
OpenAI已正式宣布為第三方開開發者開放ChatGPT API,價格降低加速場景應用 爆發。起初ChatGPT免費向用戶開放,以獲得用戶反饋;今年2月1日,Open AI推 出新的ChatGPT Plus訂閱服務,收費方式為每月20美元,訂閱者能夠因此而獲得更 快、更穩定的響應并優先體驗新功能。3月2日,OpenAI官方宣布正式開放ChatGPT API(應用程序接口),允許第三方開發者通過API將ChatGPT集成至他們的應用程 序和服務中,價格為1ktokens/$0.002,即每輸出100萬個單詞需要2.7美元,比已有 的GPT-3.5模型價格降低90%。模型價格的降低將推動ChatGPT被集成到更多場景 或應用中,豐富ChatGPT的應用生態,加速多場景應用的爆發。
GPT-4發布后OpenAI把ChatGPT直接升級為GPT-4最新版本,同時開放了GPT-4 的API。ChatGPT Plus付費訂閱用戶可以獲得具有使用上限的GPT-4訪問權限(每4 小時100條消息),可以向GPT-4模型發出純文本請求。用戶可以申請使用GPT-4 的API,OpenAI會邀請部分開發者體驗,并逐漸擴大邀請范圍。該API的定價為每輸 入1000個字符(約合750個單詞),價格為0.03美元;GPT-4每生成1000個字符價格為 0.06美元。 Office引入GPT-4帶來的結果是生產力、創造力的全面躍升。微軟今天宣布,其與 OpenAI共同開發的聊天機器人技術Bing Chat正在GPT-4上運行。
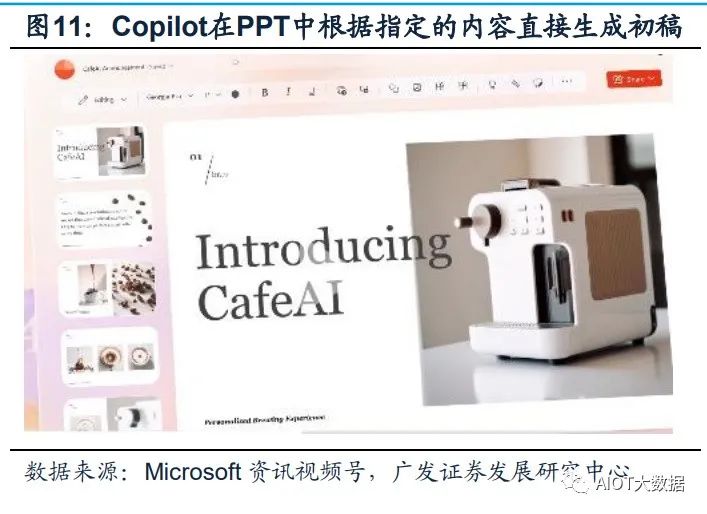
Copilot OpenAI發布升級后的GPT-4后,微軟重磅發布了GPT-4平臺支持的新AI功能, Microsoft 365 Copilot,并將其嵌入Word、PowerPoint、Excel、Teams等Office辦 公軟件中。Copilot可以在一篇速記的基礎上快速生成新聞草稿、并完成草稿潤色; 在Excel中完成各種求和、求平均數,做表格、歸納數據、甚至是完成總結提取;在 PPT上可以直接將文稿內容一鍵生成;在Outlook郵件中自動生成內容、并自由調整 寫作風格、插入圖表;在Teams中總結視頻會議的要點/每個發言人誰說了核心內容, 跟進會議流程和內容,自動生成會議紀要、要點和任務模板。基于GPT-4的Copilot 可以看作是一個辦公AI助理,充分發揮出了AI對于辦公場景的賦能作用,有望從根 本上改變工作模式并開啟新一輪生產力增長浪潮。
二、GPT-4帶動多模態x多場景落地,AIGC藍海市場打開
(一)歷經三階段發展,AIGC技術升級步入深化階段
AIGC全程為AI-Generated Content,人工智能生成內容,是繼專業生成內容(PGC, Professional Generate Content)和用戶生成內容(UGC,User Generate Content) 之后,利用AI自動生成內容的新型生產方式。傳統AI大多屬于分析式AI,對已有數 據進行分析并應用于相應領域。以AIGC為典型的生成式AI不在局限于分析固有數據, 而是基于訓練數據和算法模型自主生成創造新的文本、3D、視頻等各種形式的內容。
歷經三階段迭代,AIGC現已進入快速發展階段: (1)早期萌芽階段(1950s-1990s),受限于科技水平及高昂的系統成本,AIGC 僅限于小范圍實驗。 (2)沉淀積累階段(1990s-2010s),AIGC開始從實驗性向實用性逐漸轉變。但 由于其受限于算法瓶頸,完成創作能力有限,應用領域仍具有局限性; (3)快速發展階段(2010s-至今),GAN(Generative Adversarial Network,生成 式對抗網絡)等深度學習算法的提出和不斷迭代推動了AIGC技術的快速發展,生成 內容更加多元化。
AIGC可分為智能數字內容孿生、智能數字內容編輯及智能數字內容創作三大層次。 生成式AI是指利用現有文本、音頻文件或圖像創建新內容的人工智能技術,其起源 于分析式AI,在分析式AI總結歸納數據知識的基礎上學習數據產生模式,創造出新 的樣本內容。在分析式AI的技術基礎上,GAN、Transformer網絡等多款生成式AI 技術催生出許多AIGC產品,如DALL-E、OpenAI系列等,它們在音頻、文本、視覺 上有眾多技術應用,并在創作內容的方式上變革演化出三大前沿能力。AIGC根據面 向對象、實現功能的不同可以分為智能數字內容孿生、智能數字內容編輯及智能數 字內容創作三大層次。
(二)生成算法+預訓練模型+多模態推動AIGC的爆發
AIGC的爆發離不開其背后的深度學習模型的技術加持,生成算法、預訓練和多模態 技術的不斷發展幫助了AIGC模型具備通用性強、參數海量、多模態和生成內容高質 量的特質,讓AIGC實現從技術提升到技術突破的轉變。 (1)生成算法模型不斷迭代創新,為AIGC的發展奠定基礎。早期人工智能算法學 習能力不強,AIGC技術主要依賴于事先指定的統計模型或任務來完成簡單的內容生 成和輸出,對客觀世界和人類語言文字的感知能力較弱,生成內容刻板且具有局限 性。GAN(Generative Adversarial Network,生成式對抗網絡)的提出讓AIGC發展 進入新階段,GAN是早期的生成模型,利用博弈框架產生輸出,被廣泛應用于生成 圖像、視頻語音等領域。隨后Transformer、擴散模型、深度學習算法模型相繼涌現。
Transformer被廣泛應用于NLP、CV等領域,GPT-3、LaMDA等預訓練模型大多是 基于transformer架構構建的。ChatGPT是基于Transformer架構上的語言模型, Transformer負責調度架構和運算邏輯,進而實現最終計算。Tansformer是谷歌于 2017年《Attention is All You Need》提出的一種深度學習模型架構,其完全基于注 意力機制,可以按照輸入數據各部分重要性來分配不同的權重,無需重復和卷積。 相較于循環神經網絡(RNN)流水線式的序列計算,Transformer可以一次處理所有 的輸入,擺脫了人工標注數據集的缺陷,實現了大規模的并行計算,模型所需的訓 練時間明顯減少,大規模的AI模型質量更優。
Transformer的核心構成是編碼模塊和解碼模塊。GPT使用的是解碼模塊,通過模 塊間彼此大量堆疊的方式形成了GPT模型的底層架構,模塊分為前饋神經網絡層、 編解碼自注意力機制層(Self-Attention)、自注意力機制掩碼層。自注意力機制層 負責計算數據在全部內容的權重(即Attention),掩碼層幫助模型屏蔽計算位置右 側未出現的數據,最后把輸出的向量結果輸入前饋神經網絡,完成模型參數計算。
(2)預訓練模型引發AIGC技術能力的質變。AI預訓練模型是基于大規模寬泛的數 據進行訓練后擁有適應廣泛下游任務能力的模型,預訓練屬于遷移學習的領域,其 主旨是使用標注數據前,充分利用大量無標注數據進行訓練,模型從中全面學習到 與標注無關的潛在知識,進而使模型靈活變通的完成下游任務。視覺大模型提升 AIGC感知能力,語言大模型增強AIGC認知能力。
NLP模型是一種使用自然語言處理(Natural Language Processing,NLP)技術來解決自然語言相關問題的機器學習模型。在NLP領域,AI大模型可適用于人機語言交互,并進行自然語言處理從實現相應的文本分類、文本生成、語音識別、序列標注、機器翻譯等功能。NLP的研究經過了以規則為基礎的研究方法和以統計為基礎的研究方法的發展,目前以基于Transformer的預訓練模型已成為當前NLP領域的研究熱點,BERT、GPT等模型均采用這一方法。CV模型指計算機視覺模型,是一種基于圖像或視頻數據的人工智能模型。常見的CV 模型有采用深度學習的卷積神經網絡(CNN)和生成對抗網絡(GAN)。
近年來以 視覺Transformer(ViT)為典型的新型神經網絡,通過人類先驗知識引入網絡設計, 使得模型的收斂速度、泛化能力、擴展性及并行性得到飛速提升,通過無監督預訓 練和微調學習,在多個計算機視覺任務,如圖像分類、目標檢測、物體識別、圖像 生成等取得顯著的進步。
(3)多模態技術拓寬了AIGC技術的應用廣度。多模態技術將不同模態(圖像、聲 音、語言等)融合在預訓練模型中,使得預訓練模型從單一的NLP、CV發展成音視 頻、語言文字、文本圖像等多模態、跨模態模型。多模態大模型通過尋找模態數據 之間的關聯點,將不同模態的原始數據投射在相似的空間中,讓模態之間的信號相 互理解,進而實現模態數據之間的轉化和生成。這一技術對AIGC的原創生成能力的 發展起到了重要的支持作用,2021年OpenAI推出AI繪畫產品DALL.E可通過輸入文 字理解生成符合語義且獨一無二的繪畫作品,其背后離不開多模態技術的支持。
(三)多模態x多場景落地,AIGC爆發商業潛力
ChatGPT的廣泛應用意味著AIGC規模化、商業化的開始。ChatGPT是文字語言模 態AIGC的具體應用,在技術、應用領域和商業化方面和傳統AI產品均有所不同。 ChatGPT已經具備了一定的對現實世界內容進行語義理解和屬性操控的能力,并可 以對其回以相應的反饋。ChatGPT是AIGC重要的產品化應用,意味著AIGC規模化、 商業化的開始。創新工場董事長兼CEO李開復博士在3月14日表示,ChatGPT快速 普及將進一步引爆AI 2.0商業化。AI 2.0 是絕對不能錯過的一次革命。
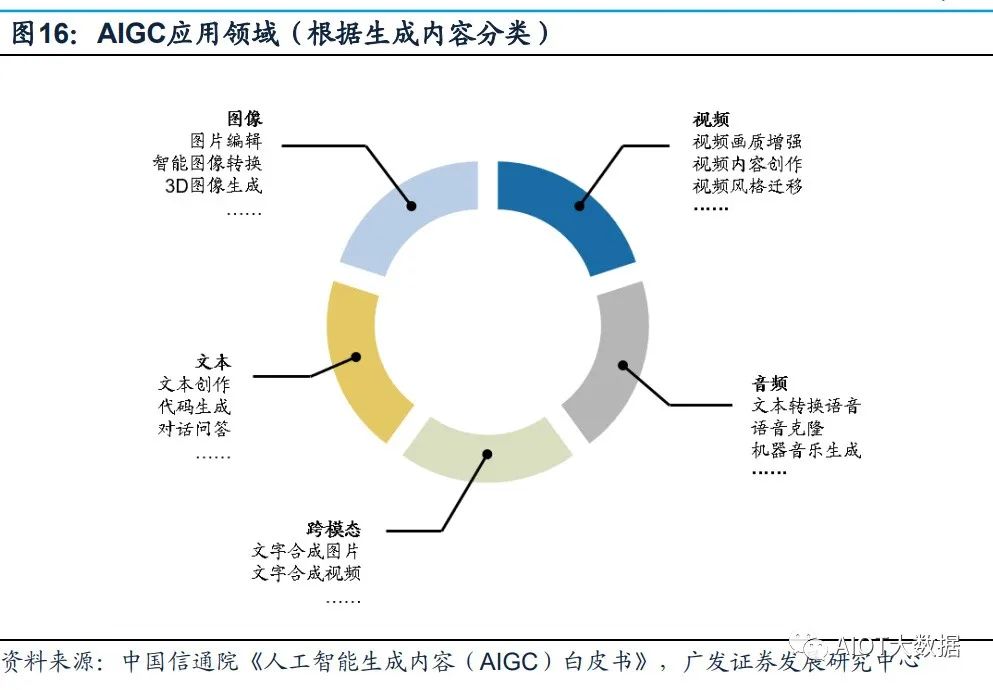
多家公司正加緊研發ChatGPT類似產品,引爆新一輪科技企業AI軍備競賽。在GPT4 推出之后,Google開放自家的大語言模型API「PaLM API」,此外還發布了一款幫 助開發者快速構建AI程序的工具 MakerSuite。2月底,META公布一款全新的AI大型 語言模型LLaMA,宣稱可幫助研究人員降低生成式AI工具可能帶來的“偏見、有毒 評論、產生錯誤信息的可能性”等問題。 AIGC的應用領域分為視頻、音頻、文本、圖像、跨模態生成五個部分。
AIGC以其 真實性、多樣性、可控性、組合性的特質,為各行業、各領域提供了更加豐富多元、 動態且可交互的內容。根據AIGC生成內容的模態不同,可將AIGC的應用領域分為 視頻、音頻、文本、圖像、跨模態生成五個部分。其中,在圖像、文本、音頻等領 域,AIGC已經得到了較大優化,生成內容質量得到明顯提升;而在視頻與跨模態內 容生成方面,AIGC擁有巨大發展潛力。
三、高算力需求帶動基礎設施迭代加速
(一)AI大模型驅動高算力需求
數據、算力及模型是人工智能發展的三要素。以GPT系列為例: (1)數據端:自OpenAI于2018年發布GPT-1,到2020年的GPT-3,GPT模型參數 數量和訓練數據量實現指數型增長。參數數量從GPT-1的1.17億增長到GPT-3的 1750億,訓練數據量從5GB增長到的45TB; (2)模型端:ChatGPT在以往模型的基礎上,在語料庫、計算能力、預訓練、自我 學習能力等方面有了明顯提升,同時Transformer架構突破了人工標注數據集的不足, 實現與人類更順暢的交流; (3)算力端:根據OpenAl發布的《Language Models are Few-Shot Learners》, 訓練13億參數的GPT-3 XL模型訓練一次消耗的算力約為27.5 PFlop/s-dav,訓練 1750億參數的完整GPT-3模型則會消耗算力3640 PFlop/s-dav(以一萬億次每秒速 度計算,需要3640天完成)。
在人工智能發展的三要素中,數據與算法都離不開算力的支撐。隨著AI算法突飛猛 進的發展,越來越多的模型訓練需要巨量算力支撐才能快速有效實施,同時數據量 的不斷增加也要求算力配套進化。如此看來,算力成為AI突破的關鍵因素。 AI大模型的算力需求主要來自于預訓練、日常運營和模型微調。 (1)預訓練:在完成完整訓練之前,搭建一個網絡模型完成特定任務,在訓練網絡 過程中不斷調整參數,直至網絡損失和運行性能達到預期目標,此時可以將訓練模 型的參數保存,用于之后執行類似任務。根據中國信通院數據,ChatGPT基于GPT3.5 系列模型,模型參數規模據推測達十億級別,參照參數規模相近的GPT-3 XL模型, 則ChatGPT完整一次預訓練消耗算力約為27.5 PFlop/s-dav。
(2)日常運營:滿足用戶日常使用數據處理需求。根據Similarweb的數據,23年1月份ChatGPT月活約6.16億,跳出率13.28%每次訪問頁數5.85頁,假設每頁平均200 token。同時假設:模型的FLlops利用率為21.3%與訓練期間的GPT-3保持一致;完整參數模型較GPT-3上升至2500億;以FLOPs為指標,SOTA大型語言在在推理過程中每個token的計算成本約為2N。根據以上數據及假設,每月日常運營消耗算力約為6.16億*2*(1-13.28%)*5.85*200*2500億/21.3%=14672PFlop/s-day。(3)模型微調:執行類似任務時,使用先前保存的模型參數作為初始化參數,在訓練過程中依據結果不斷進行微調,使之適應新的任務。
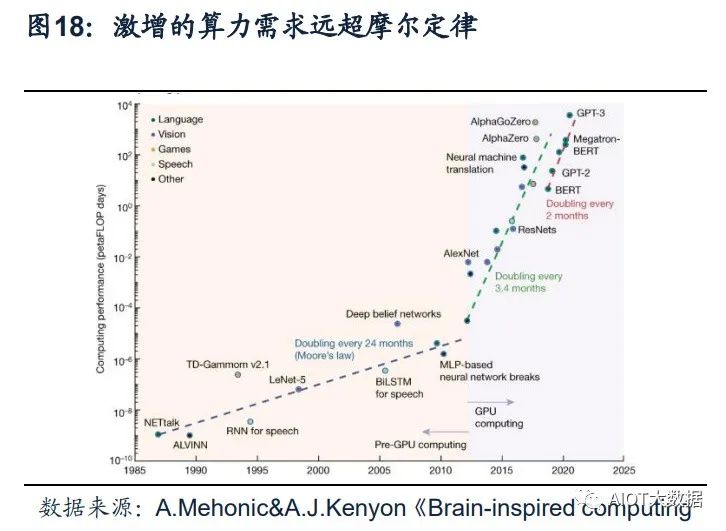
ChatGPT引發新一輪AI算力需求爆發。根據OpenAI發布的《AI and Compute》分 析報告中指出,自2012年以來,AI訓練應用的算力需求每3.4個月就回會翻倍,從 2012年至今,AI算力增長超過了30萬倍。據OpenAI報告,ChatGPT的總算力消耗 約為3640PF-days(即假如每秒計算一千萬億次,需要計算3640天),需要7-8個算 力500P的數據中心才能支撐運行。上海新興信息通信技術應用研究院首席專家賀仁 龍表示,“自2016年阿爾法狗問世,智能算力需求開啟爆發態勢。如今ChatGPT則 代表新一輪AI算力需求的爆發”。
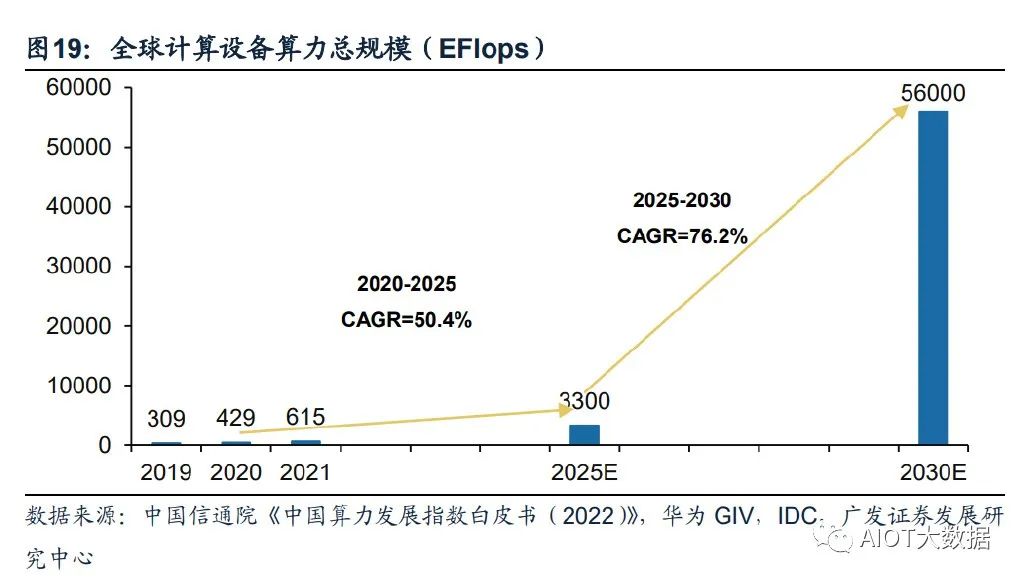
全球算力規模將呈現高速增長態勢。根據國家數據資源調查報告數據,2021年全球 數據總產量67ZB,近三年平均增速超過26%,經中國信息通信研究院測算,2021 年全球計算設備算力總規模達到615EFlops,增速達44%。根據中國信通院援引的 IDC數據,2025年全球算力整體規模將達3300EFlops,2020-2025年的年均復合增 長率達到50.4%。結合華為GIV預測,2030年人類將迎來YB數據時代,全球算力規 模達到56ZFlops,2025-2030年復合增速達到76.2%。
(二)云商/運營商推進AI領域算力基礎設施投入
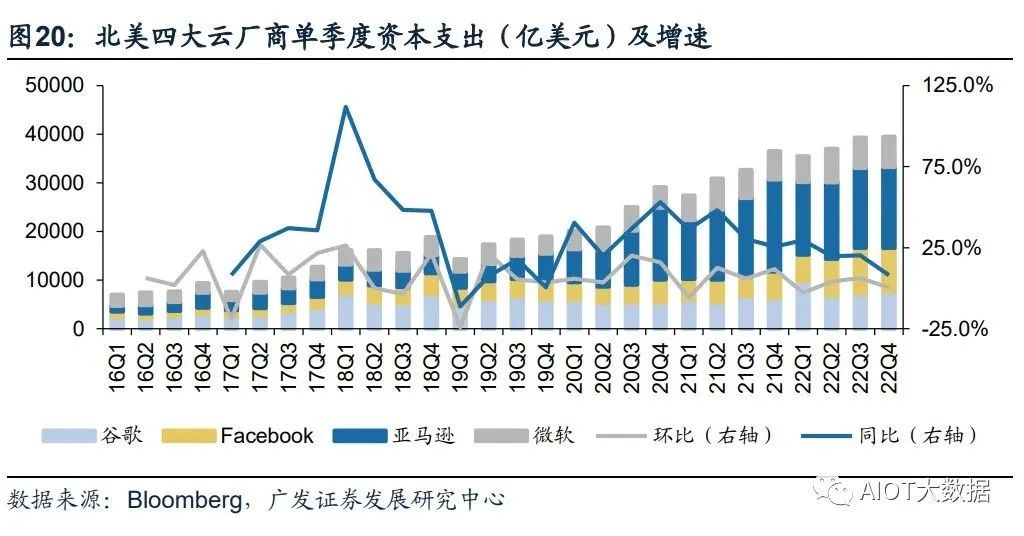
北美云廠商資本支出向技術基礎設施和新數據中心架構傾斜。22Q4亞馬遜資本支出 主要用于技術基礎設施的投資,其中大部分用于支持AWS業務增長與支持履行網絡 的額外能力。預計未來相關投資將延續,并增加在技術基礎設施方面的支出。谷歌 指引2023年資本開支與2022年基本持平,其中技術基礎設施有所增加,而辦公基礎 設施將減少。Meta2022年資本開支為314.3億美元,同比增長69.3%,但同時Meta 略微調低其2023年資本開支預期至300-330億美元(此前預期為340-370億美元), 主要原因系減少數據中心建設的相關支出,轉向新的更具成本效益的、同時支持AI 和非AI工作量的數據中心新架構。
國內三大運營商積極布局算力網絡,資本支出向新興業務傾斜。電信運營商作為數 字基座打造者,運營商數字業務板塊成為收入增長的主要引擎,近幾年資本支出由 主干網絡向新興業務傾斜。中國移動計劃2022年全年算力網絡投資480億元,占其 總資本開支的39.0%。2022Q3,中國移動算力規模達到7.3EFLOPS,并計劃在2025 年底達到20EFLOPS以上。中國電信產業數字化資本開支占比同比上升9.3pc,算力 總規模計劃由2022年中的3.1EFLOPS提升至2025年底的16.3EFLOPS。中國聯通 2022年預計算力網絡資本開支達到145億,同比提升43%,云投資預計提升88%。
作為算力基礎設施建設的主力軍,三大運營商目前已經進行前瞻性的基礎設施布局。 通信運營商自身擁有優質網絡、算力、云服務能力的通信運營商,同時具備天然的 產業鏈優勢,依靠5G+AI技術優勢,為下游客戶提供AI服務能力,是新型信息服務 體系中重要的一環,助力千行百業數字化轉型。在移動網絡方面,中國運營商已建 設覆蓋全國的高性能高可靠4/5G網絡;在固定寬帶方面,光纖接入(FTTH/O)端 口達到10.25億個,占比提升至95.7%;在算力網絡方面,運營商在資本開支結構上 向算力網絡傾斜,提升服務全國算力網絡能力。在AI服務能力方面,加快AI領域商 業化應用推出,發揮自身產業鏈優勢,助力千行百業數字化轉型。
(三)算力需求帶動數據中心架構及技術加速升級
1、數據中心呈現超大規模發展趨勢。超大規模數據中心,即Hyperscale Data Center,與傳統數據中心的核心區別在于 超大規模數據中心具備更強大的可擴展性及計算能力。1)規模上,超級數據中心可 容納的規模要比傳統數據中心大得多,可以容納數百萬臺服務器和更多的虛擬機;2) 性能上,超級數據中心具有更高的可擴展性和計算能力,能夠滿足數據處理數量和 速率大幅提升的需求。
具體來講,相較于傳統數據中心,超大規模數據中心的優勢在于: (1)可擴展性:超大規模數據中心的網絡基礎架構響應更迅速、擴展更高效且更具 成本效益,并且提供快速擴展存儲和計算資源以滿足需求的能力,超大規模數據中 心通過在負載均衡器后水平擴展,快速旋轉或重新分配額外資源并將其添加到現有 集群,可以實現快速向集群添加額外資源,從而在不中斷操作的情況下進行擴展; (2)定制化:超大規模數據中心采用更新的服務器設計,具有更寬的機架,可以容 納更多組件并且允許定制化設計服務器,使得服務器能夠同時接入多個電源和硬盤 驅動器;
(3)自動化服務:超大規模數據中心提供自動化服務,幫助客戶管理高流量網站和 需要專門處理的高級工作負載,例如密碼學、基因處理和三維渲染; (4)冷卻效率更高:超大規模數據中心對其電源架構進行了優化,并將冷卻能力集 中在托管高強度工作負載的服務器,大大降低了成本和對環境的影響,電源使用效 率和冷卻效率遠高于傳統數據中心;
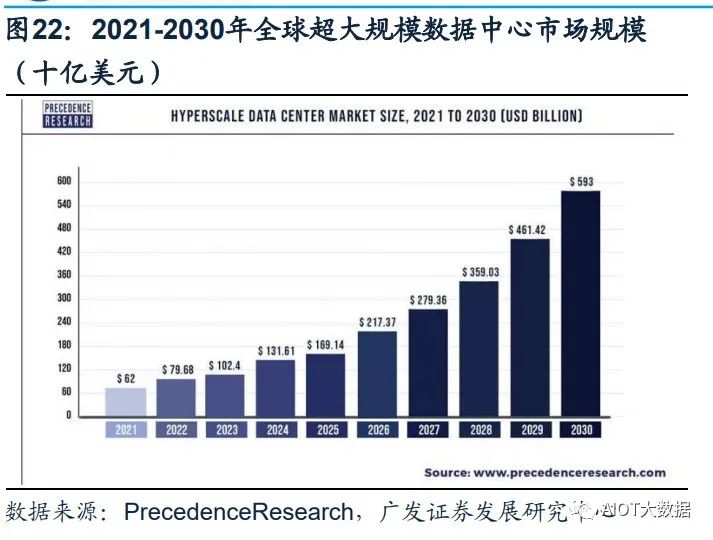
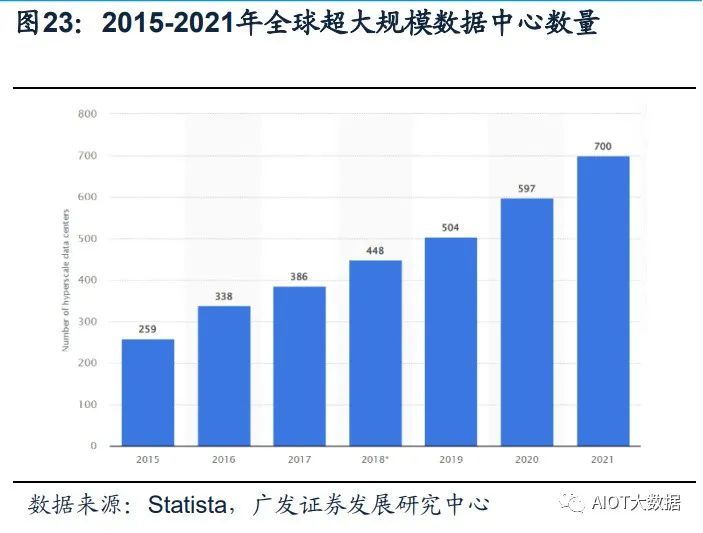
(5)工作負載更平衡:超大規模數據中心有效地將工作負載分布在多臺服務器上, 從而避免單臺服務器過熱。避免了過熱的服務器損壞附近的服務器,從而產生不必 要的連鎖反應。 Statista數據顯示,全球超大規模數據中心的數量從2015年的259個,提升到2021年 的700個。根據PrecedenceResearch的報告顯示,全球超大規模數據中心市場規模 在2021年為620億美元,到2030年將達到5930億美元,預計在2022-2030年間以 28.52%的復合增長率(CAGR)增長。
海內外云商均具備自己的超大規模數據中心。Structure Research在其報告中估計, 到2022年全球超大規模自建數據中心總容量將達到13177兆瓦(MW)。全球四大 超大規模數據中心平臺——AWS、谷歌云、Meta和微軟Azure——約占該容量的78%。 全球占主導地位的超大規模數據中心企業仍然是亞馬遜、谷歌、Meta和微軟,在中 國,本土企業阿里巴巴、華為、百度、騰訊和金山云都是領先的超大規模數據中心 企業。
2、IB網絡技術將更廣泛應用于AI訓練超算領域。超級數據中心是具有更大規模和更高計算能力的數據中心。隨著對數據處理數量和 速率需求的提升,數據中心的可擴展性需求也在迅速提升。超級數據中心在規模和 性能上較傳統數據中心都有了大幅升級,能夠滿足超高速度擴展以滿足超級需求的 能力。
泛AI應用是超算中心的重要下游。自20世紀80年代以來,超級計算主要服務于科研 領域。傳統超算基本上都是以國家科研機構為主體的超算中心,如氣象預測、地震 預測、航空航天、石油勘探等。截止2022年底,國內已建成10家國家超級計算中心, 不少省份都建立起省級超算中心,服務于當地的中科院、氣象局以及地震爆炸模型。 一方面,行業頭部企業將超算應用于芯片設計、生物醫療、材料測試等工業應用場 景;另一方面,自動駕駛訓練、大語言模型訓練、類ChatGPT等AI訓練的需求,也 推動超算應用場景延伸至圖像識別、視頻識別定位、智能駕駛場景模擬以及對話和 客服系統等,成為超算中心的重要下游。
超級數據中心成為算力儲備的重要方向,中美加速算力基建布局。憑借其在算力能 力及能耗效率的巨大提升,超級數據中心在算力儲備中的地位日漸凸顯。根據 Synergy Research Group數據,全球超級數據中心數量從2017年的390個增長至 2021年二季度的659個,增長近一倍,預計2024年總數將超1000個。份額方面,中 美持續加強超級數據中心的布局,占全球市場份額持續提升。
InfiniBand網絡滿足大帶寬和低時延的需求,成為超算中心的主流。InfiniBand(簡 稱IB)是一個用于高性能計算的計算機網絡通信標準,主要應用于大型或超大型數 據中心。IB網絡的主要目標是實現高的可靠性、可用性、可擴展性及高性能,且能 在單個或多個互聯網絡中支持冗余的I/O通道,因此能夠保持數據中心在局部故障時 仍能運轉。相比傳統的以太網絡,帶寬及時延都有非常明顯的優勢。(一般InfiniBand 的網卡收發時延在600ns,而以太網上的收發時延在10us左右,英偉達推出的 MetroX-3提升長距離InfiniBand系統帶寬至400G)。作為未來算力的基本單元,高 性能的數據中心越來越多的采用InfiniBand網絡方案,尤其在超算中心應用最為廣 泛,成為AI訓練網絡的主流。
(四)細分受益環節
GPT-4多模態大模型將引領新一輪AI算力需求的爆發,超大規模數據中心及超算數 據中心作為泛AI領域的重要基礎設施支持,其數量、規模都將相應增長,帶動整個 算力基礎設施產業鏈(如高端服務器/交換機、CPO技術、硅光、液冷技術)的滲透 加速。同時在應用側,Copilot的推出加速AI在辦公領域的賦能,看好辦公場景硬件 配套廠商機會。
1、服務器/交換機: AIGC帶動算力爆發式增長,全球進入以數據為關鍵生產要素的數字經濟時代。從國 內三大運營商資本支出結構上看,加碼算力基礎設施投資成重要趨勢。重點推薦: 中興通訊。公司作為運營商板塊算力投資的核心受益標的,持續在服務器及存儲、 交換機/路由器、數據中心等算力基礎設施領域加強布局,將作為數字經濟筑路者充 分受益我國數字經濟建設。
算力需求帶動上游硬件設備市場規模持續增長,高規格產品占比提升。伴隨著數據 流量持續提升,交換機作為數據中心必要設備,預計全球數據中心交換機保持穩定 增長。2021年全球數據中心交換機市場規模為138億美元,預計到2031年將達246 億美元,2022年至2031年復合年增長率為5.9%。多元開放的AI服務器架構為可以人 工智能發展提供更高的性能和可擴展性的AI算力支撐,隨著AI應用的發展,高性能 服務器數量有望隨之增長,帶動出貨量及服務器單價相應提升。根據IDC報告, 2022Q3,200/400GbE交換機市場收入環比增長25.2%,100GbE交換機收入同比增 長19.8%,高速部分呈現快速增長。
2、光模塊/光芯片: 算力需求提升推動算力基礎設施升級迭代,傳統可插拔光模塊技術弊端和瓶頸開始 顯現。(1)功耗過高,AI技術的加速落地,使得數據中心面臨更大的算力和網絡流 量壓力,交換機、光模塊等網絡設備升級的同時,功耗增長過快。以博通交換機芯 片為例,2010年到2022年交換機芯片速率從640G提升到51.2T,光模塊速率從10G 迭代到800G。速率提升的同時,交換機芯片功耗提升了約8倍,光模塊功耗提升了 26倍,SerDes功耗提升了25倍。(2)交換機端口密度難以繼續提升,光模塊速率 提升的同時,自身體積也在增大,而交換機光模塊端口數量有限。(3)PCB材料遭 遇瓶頸,PCB用于傳輸高速電信號,傳統可插拔光模塊信號傳輸距離長、傳輸損失 大,更低耗損的可量產PCB材料面臨技術難題難以攻克。
NPO/CPO技術有望成為高算力背景下的解決方案。CPO(光電共封裝技術)是一 種新型的高密度光組件技術,將交換芯片和光引擎共同裝配在同一個Socketed(插 槽)上,形成芯片和模組的共封裝。CPO可以取代傳統的插拔式光模塊技術,將硅 光電組件與電子晶片封裝相結合,從而使引擎盡量靠近ASIC,降低SerDes的驅動功 耗成本,減少高速電通道損耗和阻抗不連續性,實現更高密度的高速端口,提升帶 寬密度,大幅減少功耗。
CPO技術的特點主要有:(1)CPO技術縮短了交換芯片和光引擎之間的距離(控制在5~7cm),使得高速電信號在兩者之間實現高質量傳 輸,滿足系統的誤碼率(BER)要求;(2)CPO用光纖配線架取代更大體積的可 插拔模塊,系統集成度得到提升,實現更高密度的高速端口,提升整機的帶寬密度; (3)降低功耗,根據銳捷網絡招股說明書,采用CPO技術的設備整機相比于采用可 插拔光模塊技術的設備,整機功耗降低23%。
高算力背景下,數據中心網絡架構升級帶動光模塊用量擴張及向更高速率的迭代。 硅光、相干及光電共封裝技術(CPO)等具備高成本效益、高能效、低能耗的特點, 被認為是高算力背景下的解決方案。CPO將硅光電組件與電子晶片封裝相結合,使 引擎盡量靠近ASIC,減少高速電通道損耗,實現遠距離傳送。目前,頭部網絡設備 和芯片廠商已開始布局硅光、CPO相關技術與產品。
3、數據中心: IDC數據中心:“東數西算”工程正式全面啟動一周年,從系統布局進入全面建設階 段。隨著全國一體化算力網絡國家樞紐節點的部署和“東數西算”工程的推進,算 力集聚效應初步顯現,算力向規模化集約化方向加速升級,同時數據中心集中東部 的局得到改善,西部地區對東部地區數據計算需求的支撐作用越發明顯。我們認為 政策面推動供給側不斷出清,AI等應用將帶動新一輪流量需求,有望打破數據中心 近兩年供給過剩的局面,帶動數據中心長期發展。
液冷溫控:隨云計算、AI、超算等應用發展,數據中心機柜平均功率密度數預計將 逐年提升,高密度服務器也將被更廣泛的應用于數據中心中。數據中心液冷技術能 夠穩定CPU溫度、保障CPU在一定范圍內進行超頻工作不會出現過熱故障,有效提 升了服務器的使用效率和穩定性,有助于提高數據中心單位空間的服務器密度,大幅 提升數據中心運算效率,液冷技術有望在超高算力密度場景下持續滲透。
4、運營商: 通信運營商自身擁有優質網絡、算力、云服務能力的通信運營商,同時具備天然的 產業鏈優勢,依靠5G+AI技術優勢,為下游客戶提供AI服務能力,是新型信息服務 體系中重要的一環,助力千行百業數字化轉型。作為算力基礎設施建設的主力軍已 經進行前瞻性的基礎設施布局。中國移動打造九天人工智能平臺,推進AI商業化, 賦能中國移動內外部數智化轉型;中國電信全面布局大模型技術,積極探索產業版 “ChatGPT”的商業化應用;中國聯通全力升級算力網絡,推動5G和AI技術的融合。
5、企業通信: 3月16日晚微軟正式宣布推出Microsoft 365 Copilot,將大型語言模型(LLMs)的能 力嵌入到Office辦公套件產品中。基于GPT-4的Copilot以其視頻+圖文的多模態分析 以及更強大生成與理解能力,可更深度、全面發揮視頻會議AI助理功能,比如可以確定目標捕捉發言總結某人談話要點、全面理解會議主要內容并自動整理及發送會 議紀要等。隨著Copilot更強大功能對微軟辦公套件的加持,有望帶動Teams需求的 增長,中國企業通信終端廠商將作為微軟重要的硬件合作伙伴有望深度受益。
GPT將如何影響我們的工作?
(報告出品方/作者:東北證券,黃凈、吳雨萌)
1. 總結:GPT 對工作的沖擊將跨越各個職業
3 月 17 日,OpenAI 官網發布最新研究論文 GPTs are GPTs: An early look at the labor market impact potential of large language models,對 LLM 語言模型,特別是 GPT, 對美國不同職業和行業的潛在影響進行了探討。我們將論文中的結論進行了匯總:
1、 多數職業將受到 GPT 的沖擊:80%的工人有至少 10%的任務可以被 GPT 減少 ≥50%的工作時間;19%的工人有至少 50%的任務可以被 GPT 減少≥50%的工 作時間;
2、 GPT 的影響橫跨各類薪資層級:盡管存在部分特殊情況,但整體來看,工資越 高,受 GPT 沖擊的程度越大;
3、 職業技能與 GPT 的沖擊程度有關:科學和批判性思維技能最不容易受 GPT 沖 擊,而編程和寫作技能受影響的程度最高;
4、 高學歷更容易受到 GPT 的沖擊:持有學士、碩士和更高學位的人比沒有正規教 育學歷的人更容易受到 GPT 的沖擊;
5、 在職培訓時間時長與 GPT 沖擊程度有關:在職培訓時長最長的職業收入水平偏 低,且受 GPT 沖擊程度最低,而沒有在職培訓或只需實習的工作則表現出更高 的收入水平和更容易受 GPT 沖擊的屬性。
6、 證券相關和數據處理行業受 GPT 影響程度最高:在人類打分和 GPT 打分模式 下,證券商品合約及其他金融投資和數據處理托管分別是受 GPT 沖擊程度最高 的行業;在直接調用 GPT 模型的情況下,口譯筆譯和數學家分別是受影響最大 的職業;在進一步開發 GPT 衍生功能的情況下,數學家和會計審計則分別為受 影響最大的職業。
2. 統計指標來源及解釋
2.1. 數據來源
2.1.1. 美國職業、工作活動和任務數據的來源
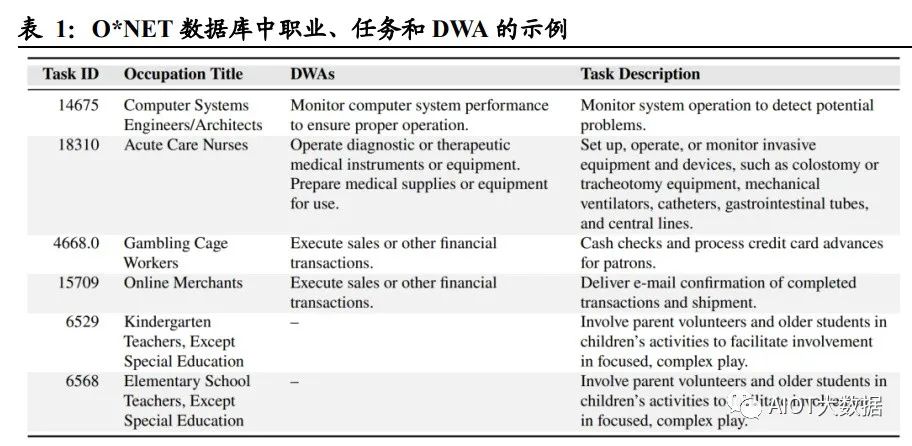
論文中使用了 O*NET 27.2 數據庫,包含 1016 種職業,以及各個職業的工作活動 (Detailed Work Activities,簡稱 DWA)和任務(Task)。論文中對工作活動和任務 給出了定義: 詳細工作活動 DWA 是由完成任務構成的綜合操作,大多數工作活動與一個或 多個任務相對應,該數據集中包括 2087 種 DWA; 任務 Task 是某個特定職業的基礎單位,一項任務可以與 0 個、1 個或多個 DWA 關聯,且每個任務都有與之對應的職業,該數據集中包括 19265 種任務。 例如,對于職業“急癥護理護士”,其工作活動 DWA 包括“操作診斷或治療性醫療儀 器或設備”和“準備醫療用品或設備”,其任務包括“設置、操作或監測侵入性設備和 裝置,例如結腸造口術或氣管切開術設備、機械呼吸機、導管、胃腸道管和中心插 管”。
2.1.2. 工資、就業及人口數據來源
論文選取了美國勞工統計局(Bureau of Labor Statistics,以下簡稱 BLS)提供的 2020 年和 2021 年職業就業系列中的就業和工資數據。該數據集包括職業名稱、每個職 業的工人數量、2031 年職業水平的就業預測、職業準入的教育水平以及獲得職業能 力所需的在職培訓情況。BLS 數據庫可以同 O*NET 數據庫進行聯動:通過當前人 口調查(Current Population Survey,簡稱 CPS),將 O*NET 中的任務和工作活動數 據集與 BLS 勞動力人口統計數據聯系起來,形成截面數據。
2.2. 暴露度 Exposure:用于衡量 GPT 對各職業的沖擊程度
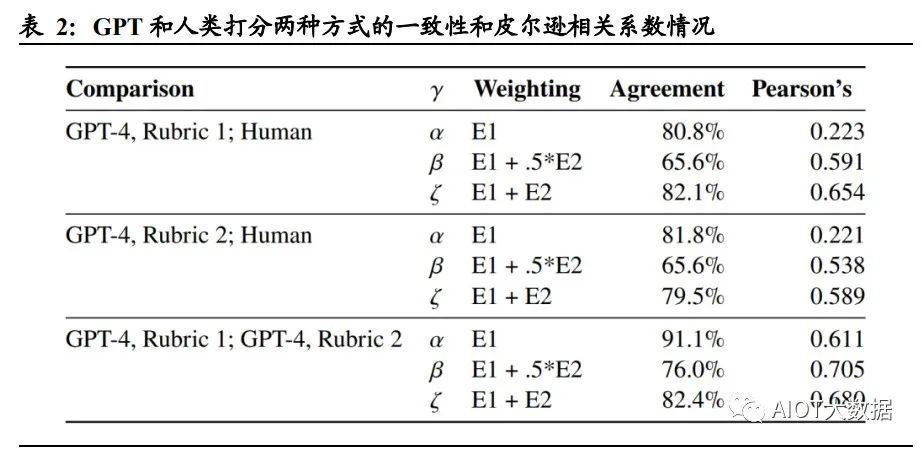
論文中設定了暴露度 Exposure 這一指標,作為重點討論的對象。暴露度 Exposure 用于衡量 GPT 對特定工作活動和任務的沖擊程度,即保證一項工作活動和任務完成 質量相同的情況下,使用 GPT 或 GPT 驅動的系統是否能夠將執行工作活動或任務 的所需時間減少 50%以上。 論文采用了兩種暴露度的注釋方式,分別為人工評分法與 GPT-4 評級法: 人工評分:通過對 O*NET 數據庫中的每一個工作活動 DWA 和任務進行人為 歸類并注釋打分。 GPT-4 評級:采用早期版本的 GPT-4 對工作活動和任務進行注釋打分。
論文將暴露度分為以下三類: E0 無暴露度:如果經驗豐富的工人在高質量完成任務時所需的時間沒有明顯減少 50%,或使用 GPT 相關技術會降低工作活動/任務的完成質量,則定義為 E0(例: 需要高強度人際互動的任務)。 E1 直接暴露:在保證完成質量相同的前提下,如果通過 ChatGPT 或 OpenAI 直接訪 問 LLM 或 GPT-4 可以將完成工作活動或任務所需時間減少 50%及以上,則將其定 義為 E1(例:指令編寫、轉換文本和代碼的任務)。 E2 LLM+暴露:直接訪問 LLM 不能將完成任務所需的時間減>50%,但在 LLM 基 礎上開發額外功能后可以達成目的,則定義該類工作活動和任務為 E2(例:總結超過 2000 字的文檔并回答關于文檔的問題)。 為了更為準確地衡量暴露度這一指標的統計學意義,論文中構建了三個度量指標, α、β 和 ζ,分別衡量低、中、高水平下的 GPT 對各職業的沖擊程度。其中,α=E1, 代表一個職業受 GPT 沖擊程度的下限;β=E1+0.5*E2,其中 E2 的 0.5 倍權重旨在解 釋通過補充工具或應用程序來完成任務/工作活動需要額外計算的暴露度;ζ=E1+E2, 代表一個職業受 GPT 沖擊程度的上限,可用于評估一項工作/任務對于 GPT 及 GPT 驅動的系統的最大暴露度(即GPT進一步開發后,一項工作/任務受到的最大影響)。
3. 研究結論:30%的職業或任務將受到 GPT 沖擊
前文將暴露度 Exposure 這一指標的定義進行了描述,論文中還將暴露度的衡量指標 α、β 和 ζ 進行了統計數據的匯總。不論采取人類打分的方式還是 GPT-4 打分,暴露 度α的均值在0.14左右,表示了從平均意義上說,15%左右的職業/任務暴露于GPT, 即 15%左右的工作可能會被現有的 LLM/GPT-4 降低 50%以上的工作時間。類似 地,暴露度 β 和 ζ 均值分別在 0.3 和 0.5 左右,代表 30%/50%的職業或任務將受到 中/高水平的 GPT 沖擊,即減少工作時間 50%及以上。
4. 研究結論:工資水平與 GPT 沖擊程度呈正相關
論文探索了職業、工人分布程度與暴露度之間的關系。對于中等水平的 GPT(β) 來說,約 19%的工人有 50%以上的任務將受到 GPT 的沖擊,80%的工人有 10%以 上的任務受到了 GPT 的沖擊;18%的職業中有 50%以上的任務受到了 GPT 的沖 擊。
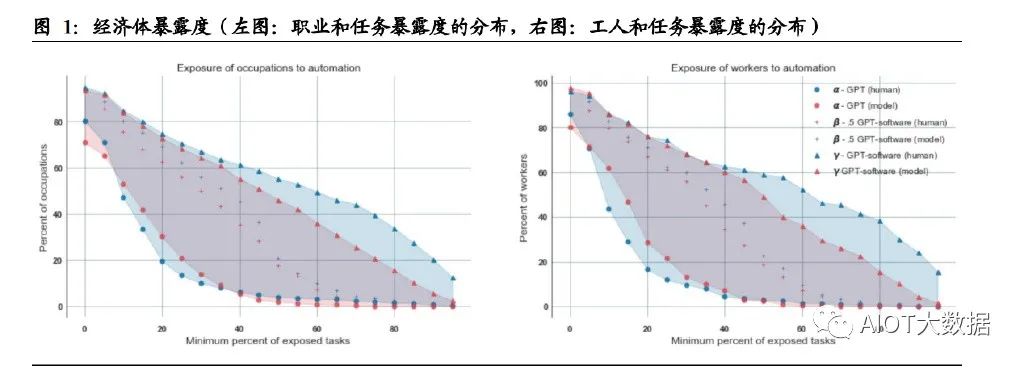
論文還對工資、就業水平與暴露度的相關性進行了探討。兩種打分模式下,盡管存 在一些高暴露度的低工資職業和低暴露度的高工資職業,整體圖表顯示,工資越高, 受 GPT 影響的程度也隨之增加。而 GPT 沖擊程度與就業水平則并無顯著關聯。
5. 研究結論:科學和批判性思維是受 GPT 沖擊最小的技能
論文研究了不同職業中技能重要性與 GPT 暴露度之間的關系。作者將 O*NET 數據 庫中的基本技能進行標準化,并將其與暴露度指標(α,β,ζ)進行回歸分析,檢驗 技能重要性和暴露度之間的關聯度。結果表明,科學和批判性思維技能(Science and CriticalThinking)與暴露度呈強烈的負相關(以β作為研究,相關系數分別-0.23 和 -0.19),即需要該技能的職業或任務不太可能受到 GPT 的沖擊;相反,編程和寫作 技能(Programming and Writing)與暴露度呈現出強正相關(相關系數分別為 0.62 和 0.47),即涉及該技能的職業更容易受到 GPT 的沖擊。
6. 研究結論:學歷水平和在職培訓時長與 GPT 沖擊程度相關
論文研究了不同工作類型的準入壁壘與暴露程度的關系。作者選取 O*NET 數據庫 中的“工作區(Job Zone)”概念作為變量,同一工作區中的職業在準入教育水平、 準入相關經驗、在職培訓程度方面具有更高的相似度。O*NET 數據庫將工作區分為 5 種,隨著準入工作經驗的增加,各工作區收入的中位數單調遞增,如工作區 1 的 準入工作經驗是 3 個月,收入的中位數為 30,230 美元,而工作區 5 的準入工作經驗 是≥4 年,收入中位數為 80,980 美元。 研究結果顯示,從工作區 1 到工作區 4,暴露度水平逐漸增加,但在工作區 5 則保 持相似甚至有所降低。平均來說,在不同工作區,50%以上任務受到 GPT 沖擊的職 業比例分別為 0.00%(工作區 1)、6.11%(工作區 2)、10.57%(工作區 3)、34.5% (工作區 4)和 26.45%(工作區 5)。
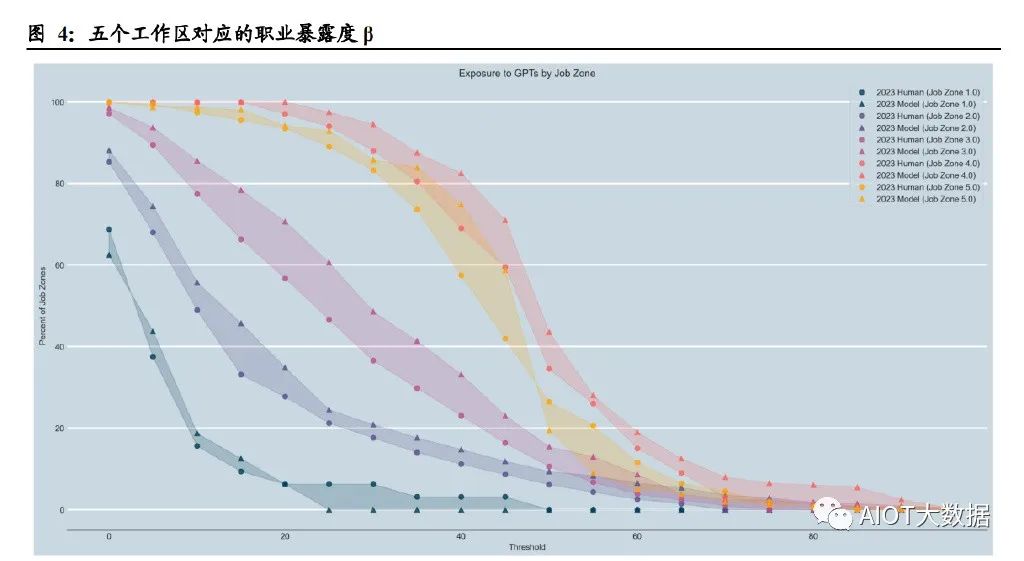
論文還單獨研究了職業準入教育水平和在職培訓情況與暴露度的關系。結果表明, 持有學士、碩士和更高學位的人比沒有正規教育學歷的人更容易受到GPT的沖擊; 在職培訓時間最長的職業受 GPT 沖擊程度最低(且這類工作的收入水平更低),而 沒有在職培訓或只需要實習的工作表現出更高的收入水平和更容易受 GPT 沖擊的 屬性。
7. 研究結論:證券投資和數據處理可能是受沖擊程度最高的職業
論文中對各行業受 GPT 沖擊的程度進行了排序。結果表明,人類打分模式下,證券 商品合約及其他金融投資及相關活動是受 GPT 沖擊最為嚴重的行業,而 GPT 打分 模式下,數據處理托管和相關服務的受沖擊程度最高。 在直接調用 GPT 模型的情況下(暴露度 α),口譯筆譯和數學家分別是兩種打分模 式下受影響最大的職業。在進一步開發 GPT 衍生功能的情況下(暴露度 ζ),人類打 分模式中,有 15 項職業的所有任務都將被 GPT 降低 50%以上的工作時間,包括數 學家、稅務準備、量化分析師、作家、網頁和數字化頁面設計師;GPT 打分模式中, 有 86 項職業的所有任務都將被 GPT 降低 50%以上的工作時間,包括審計會計、新 聞分析記者、法務專員、臨床數據經理、氣象變化政策分析師等。從方差角度看, 搜索營銷策略師、平面設計師、投資基金經理、財務經理、汽車損壞保險估價師可 能是受 GPT 影響程度爭議最大的幾項職業。
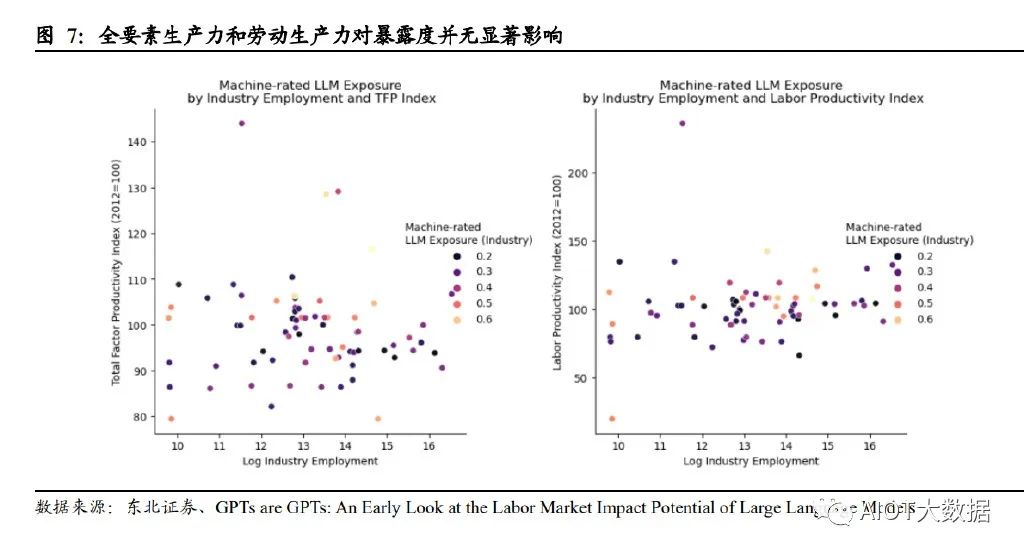
此外,論文研究表明,近期的生產增長率(包含全要素和勞動力兩方面)與暴露度 并無顯著相關性。換言之,如果 LLM 有可能在不同行業之間以不同程度提高生產力, 那么生產力最高的企業可能會良性循環。由于這些行業的生產需求普遍缺乏彈性, 生產率最高的部門在經濟投入中所占的比例將縮小。
8. 對國內的探討:賣方分析師≥80%的工作可能受 GPT 沖擊
我們采用了論文中類似的方法,試圖對國內證券行業相關工作進行打分,并計算了 其可能受 GPT 沖擊的程度。論文中采用的 O*NET 數據庫將每一項職業對應的任務、 工作活動都進行了定義,但由于國內暫無類似的數據庫和較為詳細的職業分類,我 們仍采用了 O*NET 數據庫中的分類,但依據國內的情況做了本土化調整,例如, O*NET 數據庫中的金融投資分析師(Financial and InvestmentAnalysts)職業包含任 務“對綠色建筑和綠色改造項目進行投資財務分析(Conduct financial analyses related to investments in green construction or green retrofitting projects)”,而中國的分析師普 遍不涉及這項工作,因此予以刪除調整。
我們選取了 O*NET 數據庫中的Financial and Investment Analysts金融和投資分析師、 Investment Fund Managers 投資基金經理這兩項職業和對應的任務與工作活動 (DWA),并根據中國的實際情況,將其重新組合為二級賣方分析師、一級市場投 行和基金經理。采用與論文相同的標準,對這些職業的任務/工作活動進行了打分, 并計算了暴露度β和ζ。結果顯示,按任務情況進行計算,三種行業對比下,二級 賣方分析師受 GPT 沖擊的程度高于投行一級市場和基金經理。在經過專業知識訓 練的 LLM 和 GPT 的幫助下(代表暴露度ζ),賣方分析師可能有 82%的任務將被 減少 50%以上的工作時間,基金經理可能有 55%的任務被減少 50%以上的工作時 間。按照工作活動計算,二級賣方分析師和一級市場投行受 GPT 影響的程度相差不 大,約為 65%左右,但仍顯著高于基金經理。
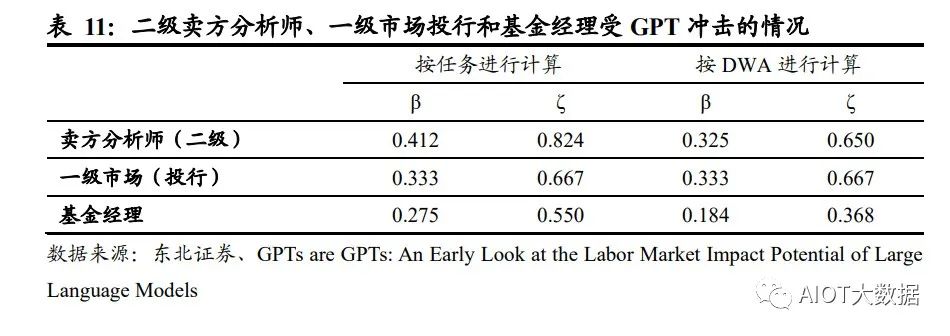
在論文中,作者將 E1 直接暴露定義為運用現有 ChatGPT 和 OpenAI 接口直接方位 LLM 可以減少50%以上的工作時間,對應的工作內容包括編寫文本(2000 字以內)、 翻譯、準備短資料等,而證券業的任務由于涉及專業知識、撰寫長度超過 2000 字的 報告等,因此在進行打分時,不存在直接暴露 E1 的情況,所有任務及工作活動均 被歸類為無暴露(E0)或 LLM+暴露(E2)。另外,在打分過程中,根據論文作者 的標準,我們將法律法規要求人類完成的任務、需要確認/授權/決策的任務、涉及雇 傭員工和培訓團隊的任務以及涉及大量人際交流的任務歸類為無暴露(E0),分析 類、文本整理類、資料搜集類工作定義為 LLM+暴露(E2)。值得注意的是,由于基 金經理這一職業涉及更多審查合規性、響應監管要求等任務,因此展現出較分析師 更低的暴露度(ζ),即受 GPT 的影響低于分析師。
根據論文中對于不同行業的暴露度統計,按照人類打分,美國證券商品合約及其他金融投資的暴露度β在 0.6-0.7 之間,我們將這一數值作為美國證券行業受到 GPT 沖擊的平均水平。為了方便對比,我們采用暴露度β進行對比,國內賣方分析師、 一級市場(投行)和基金經理分別對應的暴露度 0.41、0.33 和 0.28,證明國內賣方 分析師、一級市場(投行)和基金經理受到 GPT 沖擊的情況略好于美國證券行業 受沖擊的平均水平。我們推測可能由以下原因導致:
1、 美國擁有更高比例的量化分析師:論文中特別提到,在經過專業知識訓練的 LLM 和 GPT 的幫助下(暴露度ζ),人類打分模式下,量化分析師的暴露度是 100%,即量化分析師所有的任務都可以在 GPT 的幫助下大幅降低工作時間;美 國量化分析行業發展相對靠前,量化分析師可能擁有更高的權重,從而拉高行 業整體的暴露度;
2、 不同證券市場的有效性可能對工作任務的打分產生影響:美國資本市場被認為 是半強有效市場,較 A 股相比,美股市場的信息更加公開透明;GPT 在公開信 息的搜集整理、歸納總結方面具有明顯的優勢,因此相比國內,GPT 和 LLM 能 夠更好地幫助美國的證券從業者降低工作時長,從而表現出更高的暴露度。
GPT~4引發新一輪AI算力需求爆發
(報告出品方/作者:廣發證券,李娜,王亮)
一、OpenAI正式發布多模態大模型GPT-4,實現多重能力躍升
(一)多模態大模型GPT-4是OpenAI公司GPT系列最新一代模型
美國OpenAI公司成立于2015年12月,是全球頂級的人工智能研究機構之一,創始人 包括Elon Musk、著名投資者Sam Altman、支付服務PayPal創始人Peter Thiel等人。 OpenAI作為人工智能領域的革命者,成立至今開發出多款人工智能產品。2016年, OpenAI推出了用于強化學習研究的工具集OpenAI Gym;同時推出開源平臺OpenAI Universe,用于測試和評估智能代理機器人在各類環境中的表現。2019年,OpenAI 發布了GPT-2模型,可根據輸入文本自動生成語言,展現出人工智能創造性思維的 能力;2020年更新了GPT-3語言模型,并在其基礎上發布了OpenAI Codex模型,該 模型可以自動生成完整有效的程序代碼。
2021年1月,OpenAI發布了OpenAI CLIP, 用于進行圖像和文本的識別分類;同時推出全新產品DALL-E,該模型可以根據文字 描述自動生成對應的圖片,2022年更新的DALL-E2更是全方位改進了生成圖片的質 量,獲得了廣泛好評。 2022年12月,OpenAI推出基于GPT-3.5的新型AI聊天機器人ChatGPT,在發布進 兩個月后擁有1億用戶,成為史上用戶增長最快的應用;美東時間2023年3月14日, ChatGPT的開發機構OpenAI正式推出多模態大模型GPT-4。
GPT(General Pre-Training)系列模型即通用預訓練語言模型,是一種利用 Transformer作為特征抽取器,基于深度學習技術的自然語言處理模型。 GPT系列模型由OpenAI公司開發,經歷了長達五年時間的發展: (1)其最早的產品GPT模型于2018年6月發布,該模型可以根據給定的文本序列進 行預測下一個單詞或句子,充分證明通過對語言模型進行生成性預訓練可以有效減 輕NLP任務中對于監督學習的依賴; (2)2019年2月GPT-2模型發布,該模型取消了原GPT模型中的微調階段,變為無 監督模型,同時,GPT-2采用更大的訓練集嘗試zero-shot學習,通過采用多任務模 型的方式使其在面對不同任務時都能擁有更強的理解能力和較高的適配性;
(3)GPT-3模型于2020年6月被發布,它在多項自然語言處理任務上取得了驚人的 表現,并被認為是迄今為止最先進的自然語言處理模型之一。GPT-3訓練使用的數 據集為多種高質量數據集的混合,一次保證了訓練質量;同時,該模型在下游訓練 時用Few-shot取代了GPT-2模型使用的zero-shot,即在執行任務時給予少量樣例, 以此提高準確度;除此之外,它在前兩個模型的基礎上引入了新的技術——“零樣 本學習”,即GPT-3即便沒有對特定的任務進行訓練也可以完成相應的任務,這使 得GPT-3面對陌生語境時具有更好的靈活性和適應性。
(4)2022年11月,OpenAI發布GPT-3.5模型,是由GPT-3微調出來的版本,采用 不同的訓練方式,其功能更加強大。基于GPT-3.5模型,并加上人類反饋強化學習 (RLHF)發布ChatGPT應用,ChatGPT的全稱為Chat Generative Pre-trained Transformer,是建立在大型語言模型基礎上的對話式自然語言處理工具,表現形式 是一種聊天機器人程序,能夠學習及理解人類的語言,根據聊天的上下文進行互動, 甚至能夠完成翻譯、編程、撰寫論文、編輯郵件等功能。 (5)2023年3月,OpenAI正式發布大型多模態模型GPT-4(輸入圖像和文本,輸出 文本輸出),此前主要支持文本,現模型能支持識別和理解圖像。
(二)GPT大模型通過底層技術的疊加,實現組合式的創新
由于OpenAI并沒有提供關于GPT-4用于訓練的數據、算力成本、訓練方法、架構等 細節,故我們本章主要討論ChatGPT模型的技術路徑。 ChatGPT模型從算法分來上來講屬于生成式大規模語言模型,底層技術包括 Transformer架構、有監督微調訓練、RLHF強化學習等,ChatGPT通過底層技術 的疊加,實現了組合式的創新。 GPT模型采用了由Google提出的Transformer架構。Transformer架構采用自注意 力機制的序列到序列模型,是目前在自然語言處理任務中最常用的神經網絡架構之 一。相比于傳統的循環神經網絡(RNN)或卷積神經網絡(CNN),Transformer 沒有顯式的時間或空間結構,因此可以高效地進行并行計算,并且Transformer具有 更好的并行化能力和更強的長序列數據處理能力。
ChatGPT模型采用了“預訓練+微調”的半監督學習的方式進行訓練。第一階段是 Pre-Training階段,通過預訓練的語言模型(Pretrained Language Model),從大 規模的文本中提取訓練數據,并通過深度神經網絡進行處理和學習,進而根據上下 文預測生成下一個單詞或者短語,從而生成流暢的語言文本;第二階段是Fine-tuning 階段,將已經完成預訓練的GPT模型應用到特定任務上,并通過少量的有標注的數 據來調整模型的參數,以提高模型在該任務上的表現。
ChatGPT在訓練中使用了RLHF人類反饋強化學習模型,是GPT-3模型經過升級并 增加對話功能后的最新版本。2022年3月,OpenAI發布InstructGPT,這一版本是 GPT-3模型的升級版本。相較于之前版本的GPT模型,InstructGPT引入了基于人類 反饋的強化學習技術(Reinforcement Learning with Human Feedback,RLHF), 對模型進行微調,通過獎勵機制進一步訓練模型,以適應不同的任務場景和語言風 格,給出更符合人類思維的輸出結果。
RLHF的訓練包括訓練大語言模型、訓練獎勵模型及RLHF微調三個步驟。首先,需 要使用預訓練目標訓練一個語言模型,同時也可以使用額外文本進行微調。其次, 基于語言模型訓練出獎勵模型,對模型生成的文本進行質量標注,由人工標注者按 偏好將文本從最佳到最差進行排名,借此使得獎勵模型習得人類對于模型生成文本 序列的偏好。最后利用獎勵模型輸出的結果,通過強化學習模型微調優化,最終得 到一個更符合人類偏好語言模型。
(三)GPT-4相較于ChatGPT實現多重能力躍遷
ChatGPT于2022年11月推出之后,僅用兩個月時間月活躍用戶數便超過1億,在短 時間內積累了龐大的用戶基數,也是歷史上增長最快的消費應用。多模態大模型GPT-4是OpenAI的里程碑之作,是目前最強的文本生成模型。 ChatGPT推出后的三個多月時間里OpenAI就正式推出GPT-4,再次拓寬了大模型的 能力邊界。GPT-4是一個多模態大模型(接受圖像和文本輸入,生成文本),相比 上一代,GPT-4可以更準確地解決難題,具有更廣泛的常識和解決問題的能力:更 具創造性和協作性;能夠處理超過25000個單詞的文本,允許長文內容創建、擴展 對話以及文檔搜索和分析等用例。
(1)GPT-4具備更高的準確性及更強的專業性。GPT-4在更復雜、細微的任務處理 上回答更可靠、更有創意,在多類考試測驗中以及與其他LLM的benchmark比較中 GPT-4明顯表現優異。GPT-4在模擬律師考試GPT-4取得了前10%的好成績,相比 之下GPT-3.5是后10%;生物學奧賽前1%;美國高考SAT中GPT-4在閱讀寫作中拿 下710分高分、數學700分(滿分800)。
(2)GPT能夠處理圖像內容,能夠識別較為復雜的圖片信息并進行解讀。GPT-4 突破了純文字的模態,增加了圖像模態的輸入,支持用戶上傳圖像,并且具備強大 的圖像能力—能夠描述內容、解釋分析圖表、指出圖片中的不合理指出或解釋梗圖。 在OpenAI發布的產品視頻中,開發者給GPT-4輸入了一張“用VGA電腦接口給 iPhone充電”的圖片,GPT-4不僅可以可描述圖片,還指出了圖片的荒謬之處。
(3)GPT-4可以處理超過25000字的文本。在文本處理上,GPT-4支持輸入的文字 上限提升至25000字,允許長文內容創建、擴展對話以及文檔搜索和分析等用例。 且GPT-4的多語言處理能力更優,在GPT-4的測評展示中,GPT-4可以解決法語的 物理問題,且在測試的英語、拉脫維亞語、威爾士語和斯瓦希里語等26種語言中, 有24種語言下,GPT-4優于GPT-3.5和其他大語言模型(Chinchilla、PaLM)的英 語語言性能。(4)具備自我訓練與預測能力,同時改善幻覺、安全等局限性。GPT-4的一大更新 重點是建立了一個可預測拓展的深度學習棧,使其具備了自我訓練及預測能力。同 時,GPT-4在相對于以前的模型已經顯著減輕了幻覺問題。在OpenAI的內部對抗性 真實性評估中,GPT-4的得分比最新的GPT-3.5模型高 40%;在安全能力的升級上, GPT-4明顯超出ChatGPT和GPT3.5。
(四)商業模式愈發清晰,微軟Copilot引發跨時代的生產力變革
OpenAI已正式宣布為第三方開開發者開放ChatGPT API,價格降低加速場景應用 爆發。起初ChatGPT免費向用戶開放,以獲得用戶反饋;今年2月1日,Open AI推 出新的ChatGPT Plus訂閱服務,收費方式為每月20美元,訂閱者能夠因此而獲得更 快、更穩定的響應并優先體驗新功能。3月2日,OpenAI官方宣布正式開放ChatGPT API(應用程序接口),允許第三方開發者通過API將ChatGPT集成至他們的應用程 序和服務中,價格為1ktokens/$0.002,即每輸出100萬個單詞需要2.7美元,比已有 的GPT-3.5模型價格降低90%。模型價格的降低將推動ChatGPT被集成到更多場景 或應用中,豐富ChatGPT的應用生態,加速多場景應用的爆發。
GPT-4發布后OpenAI把ChatGPT直接升級為GPT-4最新版本,同時開放了GPT-4 的API。ChatGPT Plus付費訂閱用戶可以獲得具有使用上限的GPT-4訪問權限(每4 小時100條消息),可以向GPT-4模型發出純文本請求。用戶可以申請使用GPT-4 的API,OpenAI會邀請部分開發者體驗,并逐漸擴大邀請范圍。該API的定價為每輸 入1000個字符(約合750個單詞),價格為0.03美元;GPT-4每生成1000個字符價格為 0.06美元。 Office引入GPT-4帶來的結果是生產力、創造力的全面躍升。微軟今天宣布,其與 OpenAI共同開發的聊天機器人技術Bing Chat正在GPT-4上運行。
Copilot OpenAI發布升級后的GPT-4后,微軟重磅發布了GPT-4平臺支持的新AI功能, Microsoft 365 Copilot,并將其嵌入Word、PowerPoint、Excel、Teams等Office辦 公軟件中。Copilot可以在一篇速記的基礎上快速生成新聞草稿、并完成草稿潤色; 在Excel中完成各種求和、求平均數,做表格、歸納數據、甚至是完成總結提取;在 PPT上可以直接將文稿內容一鍵生成;在Outlook郵件中自動生成內容、并自由調整 寫作風格、插入圖表;在Teams中總結視頻會議的要點/每個發言人誰說了核心內容, 跟進會議流程和內容,自動生成會議紀要、要點和任務模板。基于GPT-4的Copilot 可以看作是一個辦公AI助理,充分發揮出了AI對于辦公場景的賦能作用,有望從根 本上改變工作模式并開啟新一輪生產力增長浪潮。
二、GPT-4帶動多模態x多場景落地,AIGC藍海市場打開
(一)歷經三階段發展,AIGC技術升級步入深化階段
AIGC全程為AI-Generated Content,人工智能生成內容,是繼專業生成內容(PGC, Professional Generate Content)和用戶生成內容(UGC,User Generate Content) 之后,利用AI自動生成內容的新型生產方式。傳統AI大多屬于分析式AI,對已有數 據進行分析并應用于相應領域。以AIGC為典型的生成式AI不在局限于分析固有數據, 而是基于訓練數據和算法模型自主生成創造新的文本、3D、視頻等各種形式的內容。
歷經三階段迭代,AIGC現已進入快速發展階段: (1)早期萌芽階段(1950s-1990s),受限于科技水平及高昂的系統成本,AIGC 僅限于小范圍實驗。 (2)沉淀積累階段(1990s-2010s),AIGC開始從實驗性向實用性逐漸轉變。但 由于其受限于算法瓶頸,完成創作能力有限,應用領域仍具有局限性; (3)快速發展階段(2010s-至今),GAN(Generative Adversarial Network,生成 式對抗網絡)等深度學習算法的提出和不斷迭代推動了AIGC技術的快速發展,生成 內容更加多元化。
AIGC可分為智能數字內容孿生、智能數字內容編輯及智能數字內容創作三大層次。 生成式AI是指利用現有文本、音頻文件或圖像創建新內容的人工智能技術,其起源 于分析式AI,在分析式AI總結歸納數據知識的基礎上學習數據產生模式,創造出新 的樣本內容。在分析式AI的技術基礎上,GAN、Transformer網絡等多款生成式AI 技術催生出許多AIGC產品,如DALL-E、OpenAI系列等,它們在音頻、文本、視覺 上有眾多技術應用,并在創作內容的方式上變革演化出三大前沿能力。AIGC根據面 向對象、實現功能的不同可以分為智能數字內容孿生、智能數字內容編輯及智能數 字內容創作三大層次。
(二)生成算法+預訓練模型+多模態推動AIGC的爆發
AIGC的爆發離不開其背后的深度學習模型的技術加持,生成算法、預訓練和多模態 技術的不斷發展幫助了AIGC模型具備通用性強、參數海量、多模態和生成內容高質 量的特質,讓AIGC實現從技術提升到技術突破的轉變。 (1)生成算法模型不斷迭代創新,為AIGC的發展奠定基礎。早期人工智能算法學 習能力不強,AIGC技術主要依賴于事先指定的統計模型或任務來完成簡單的內容生 成和輸出,對客觀世界和人類語言文字的感知能力較弱,生成內容刻板且具有局限 性。GAN(Generative Adversarial Network,生成式對抗網絡)的提出讓AIGC發展 進入新階段,GAN是早期的生成模型,利用博弈框架產生輸出,被廣泛應用于生成 圖像、視頻語音等領域。隨后Transformer、擴散模型、深度學習算法模型相繼涌現。
Transformer被廣泛應用于NLP、CV等領域,GPT-3、LaMDA等預訓練模型大多是 基于transformer架構構建的。ChatGPT是基于Transformer架構上的語言模型, Transformer負責調度架構和運算邏輯,進而實現最終計算。Tansformer是谷歌于 2017年《Attention is All You Need》提出的一種深度學習模型架構,其完全基于注 意力機制,可以按照輸入數據各部分重要性來分配不同的權重,無需重復和卷積。 相較于循環神經網絡(RNN)流水線式的序列計算,Transformer可以一次處理所有 的輸入,擺脫了人工標注數據集的缺陷,實現了大規模的并行計算,模型所需的訓 練時間明顯減少,大規模的AI模型質量更優。
Transformer的核心構成是編碼模塊和解碼模塊。GPT使用的是解碼模塊,通過模 塊間彼此大量堆疊的方式形成了GPT模型的底層架構,模塊分為前饋神經網絡層、 編解碼自注意力機制層(Self-Attention)、自注意力機制掩碼層。自注意力機制層 負責計算數據在全部內容的權重(即Attention),掩碼層幫助模型屏蔽計算位置右 側未出現的數據,最后把輸出的向量結果輸入前饋神經網絡,完成模型參數計算。
(2)預訓練模型引發AIGC技術能力的質變。AI預訓練模型是基于大規模寬泛的數 據進行訓練后擁有適應廣泛下游任務能力的模型,預訓練屬于遷移學習的領域,其 主旨是使用標注數據前,充分利用大量無標注數據進行訓練,模型從中全面學習到 與標注無關的潛在知識,進而使模型靈活變通的完成下游任務。視覺大模型提升 AIGC感知能力,語言大模型增強AIGC認知能力。
NLP模型是一種使用自然語言處理(Natural Language Processing,NLP)技術來解決自然語言相關問題的機器學習模型。在NLP領域,AI大模型可適用于人機語言交互,并進行自然語言處理從實現相應的文本分類、文本生成、語音識別、序列標注、機器翻譯等功能。NLP的研究經過了以規則為基礎的研究方法和以統計為基礎的研究方法的發展,目前以基于Transformer的預訓練模型已成為當前NLP領域的研究熱點,BERT、GPT等模型均采用這一方法。CV模型指計算機視覺模型,是一種基于圖像或視頻數據的人工智能模型。常見的CV 模型有采用深度學習的卷積神經網絡(CNN)和生成對抗網絡(GAN)。
近年來以 視覺Transformer(ViT)為典型的新型神經網絡,通過人類先驗知識引入網絡設計, 使得模型的收斂速度、泛化能力、擴展性及并行性得到飛速提升,通過無監督預訓 練和微調學習,在多個計算機視覺任務,如圖像分類、目標檢測、物體識別、圖像 生成等取得顯著的進步。
(3)多模態技術拓寬了AIGC技術的應用廣度。多模態技術將不同模態(圖像、聲 音、語言等)融合在預訓練模型中,使得預訓練模型從單一的NLP、CV發展成音視 頻、語言文字、文本圖像等多模態、跨模態模型。多模態大模型通過尋找模態數據 之間的關聯點,將不同模態的原始數據投射在相似的空間中,讓模態之間的信號相 互理解,進而實現模態數據之間的轉化和生成。這一技術對AIGC的原創生成能力的 發展起到了重要的支持作用,2021年OpenAI推出AI繪畫產品DALL.E可通過輸入文 字理解生成符合語義且獨一無二的繪畫作品,其背后離不開多模態技術的支持。
(三)多模態x多場景落地,AIGC爆發商業潛力
ChatGPT的廣泛應用意味著AIGC規模化、商業化的開始。ChatGPT是文字語言模 態AIGC的具體應用,在技術、應用領域和商業化方面和傳統AI產品均有所不同。 ChatGPT已經具備了一定的對現實世界內容進行語義理解和屬性操控的能力,并可 以對其回以相應的反饋。ChatGPT是AIGC重要的產品化應用,意味著AIGC規模化、 商業化的開始。創新工場董事長兼CEO李開復博士在3月14日表示,ChatGPT快速 普及將進一步引爆AI 2.0商業化。AI 2.0 是絕對不能錯過的一次革命。
多家公司正加緊研發ChatGPT類似產品,引爆新一輪科技企業AI軍備競賽。在GPT4 推出之后,Google開放自家的大語言模型API「PaLM API」,此外還發布了一款幫 助開發者快速構建AI程序的工具 MakerSuite。2月底,META公布一款全新的AI大型 語言模型LLaMA,宣稱可幫助研究人員降低生成式AI工具可能帶來的“偏見、有毒 評論、產生錯誤信息的可能性”等問題。 AIGC的應用領域分為視頻、音頻、文本、圖像、跨模態生成五個部分。
AIGC以其 真實性、多樣性、可控性、組合性的特質,為各行業、各領域提供了更加豐富多元、 動態且可交互的內容。根據AIGC生成內容的模態不同,可將AIGC的應用領域分為 視頻、音頻、文本、圖像、跨模態生成五個部分。其中,在圖像、文本、音頻等領 域,AIGC已經得到了較大優化,生成內容質量得到明顯提升;而在視頻與跨模態內 容生成方面,AIGC擁有巨大發展潛力。
三、高算力需求帶動基礎設施迭代加速
(一)AI大模型驅動高算力需求
數據、算力及模型是人工智能發展的三要素。以GPT系列為例: (1)數據端:自OpenAI于2018年發布GPT-1,到2020年的GPT-3,GPT模型參數 數量和訓練數據量實現指數型增長。參數數量從GPT-1的1.17億增長到GPT-3的 1750億,訓練數據量從5GB增長到的45TB; (2)模型端:ChatGPT在以往模型的基礎上,在語料庫、計算能力、預訓練、自我 學習能力等方面有了明顯提升,同時Transformer架構突破了人工標注數據集的不足, 實現與人類更順暢的交流; (3)算力端:根據OpenAl發布的《Language Models are Few-Shot Learners》, 訓練13億參數的GPT-3 XL模型訓練一次消耗的算力約為27.5 PFlop/s-dav,訓練 1750億參數的完整GPT-3模型則會消耗算力3640 PFlop/s-dav(以一萬億次每秒速 度計算,需要3640天完成)。
在人工智能發展的三要素中,數據與算法都離不開算力的支撐。隨著AI算法突飛猛 進的發展,越來越多的模型訓練需要巨量算力支撐才能快速有效實施,同時數據量 的不斷增加也要求算力配套進化。如此看來,算力成為AI突破的關鍵因素。 AI大模型的算力需求主要來自于預訓練、日常運營和模型微調。 (1)預訓練:在完成完整訓練之前,搭建一個網絡模型完成特定任務,在訓練網絡 過程中不斷調整參數,直至網絡損失和運行性能達到預期目標,此時可以將訓練模 型的參數保存,用于之后執行類似任務。根據中國信通院數據,ChatGPT基于GPT3.5 系列模型,模型參數規模據推測達十億級別,參照參數規模相近的GPT-3 XL模型, 則ChatGPT完整一次預訓練消耗算力約為27.5 PFlop/s-dav。
(2)日常運營:滿足用戶日常使用數據處理需求。根據Similarweb的數據,23年1月份ChatGPT月活約6.16億,跳出率13.28%每次訪問頁數5.85頁,假設每頁平均200 token。同時假設:模型的FLlops利用率為21.3%與訓練期間的GPT-3保持一致;完整參數模型較GPT-3上升至2500億;以FLOPs為指標,SOTA大型語言在在推理過程中每個token的計算成本約為2N。根據以上數據及假設,每月日常運營消耗算力約為6.16億*2*(1-13.28%)*5.85*200*2500億/21.3%=14672PFlop/s-day。(3)模型微調:執行類似任務時,使用先前保存的模型參數作為初始化參數,在訓練過程中依據結果不斷進行微調,使之適應新的任務。
ChatGPT引發新一輪AI算力需求爆發。根據OpenAI發布的《AI and Compute》分 析報告中指出,自2012年以來,AI訓練應用的算力需求每3.4個月就回會翻倍,從 2012年至今,AI算力增長超過了30萬倍。據OpenAI報告,ChatGPT的總算力消耗 約為3640PF-days(即假如每秒計算一千萬億次,需要計算3640天),需要7-8個算 力500P的數據中心才能支撐運行。上海新興信息通信技術應用研究院首席專家賀仁 龍表示,“自2016年阿爾法狗問世,智能算力需求開啟爆發態勢。如今ChatGPT則 代表新一輪AI算力需求的爆發”。
全球算力規模將呈現高速增長態勢。根據國家數據資源調查報告數據,2021年全球 數據總產量67ZB,近三年平均增速超過26%,經中國信息通信研究院測算,2021 年全球計算設備算力總規模達到615EFlops,增速達44%。根據中國信通院援引的 IDC數據,2025年全球算力整體規模將達3300EFlops,2020-2025年的年均復合增 長率達到50.4%。結合華為GIV預測,2030年人類將迎來YB數據時代,全球算力規 模達到56ZFlops,2025-2030年復合增速達到76.2%。
(二)云商/運營商推進AI領域算力基礎設施投入
北美云廠商資本支出向技術基礎設施和新數據中心架構傾斜。22Q4亞馬遜資本支出 主要用于技術基礎設施的投資,其中大部分用于支持AWS業務增長與支持履行網絡 的額外能力。預計未來相關投資將延續,并增加在技術基礎設施方面的支出。谷歌 指引2023年資本開支與2022年基本持平,其中技術基礎設施有所增加,而辦公基礎 設施將減少。Meta2022年資本開支為314.3億美元,同比增長69.3%,但同時Meta 略微調低其2023年資本開支預期至300-330億美元(此前預期為340-370億美元), 主要原因系減少數據中心建設的相關支出,轉向新的更具成本效益的、同時支持AI 和非AI工作量的數據中心新架構。
國內三大運營商積極布局算力網絡,資本支出向新興業務傾斜。電信運營商作為數 字基座打造者,運營商數字業務板塊成為收入增長的主要引擎,近幾年資本支出由 主干網絡向新興業務傾斜。中國移動計劃2022年全年算力網絡投資480億元,占其 總資本開支的39.0%。2022Q3,中國移動算力規模達到7.3EFLOPS,并計劃在2025 年底達到20EFLOPS以上。中國電信產業數字化資本開支占比同比上升9.3pc,算力 總規模計劃由2022年中的3.1EFLOPS提升至2025年底的16.3EFLOPS。中國聯通 2022年預計算力網絡資本開支達到145億,同比提升43%,云投資預計提升88%。
作為算力基礎設施建設的主力軍,三大運營商目前已經進行前瞻性的基礎設施布局。 通信運營商自身擁有優質網絡、算力、云服務能力的通信運營商,同時具備天然的 產業鏈優勢,依靠5G+AI技術優勢,為下游客戶提供AI服務能力,是新型信息服務 體系中重要的一環,助力千行百業數字化轉型。在移動網絡方面,中國運營商已建 設覆蓋全國的高性能高可靠4/5G網絡;在固定寬帶方面,光纖接入(FTTH/O)端 口達到10.25億個,占比提升至95.7%;在算力網絡方面,運營商在資本開支結構上 向算力網絡傾斜,提升服務全國算力網絡能力。在AI服務能力方面,加快AI領域商 業化應用推出,發揮自身產業鏈優勢,助力千行百業數字化轉型。
(三)算力需求帶動數據中心架構及技術加速升級
1、數據中心呈現超大規模發展趨勢。超大規模數據中心,即Hyperscale Data Center,與傳統數據中心的核心區別在于 超大規模數據中心具備更強大的可擴展性及計算能力。1)規模上,超級數據中心可 容納的規模要比傳統數據中心大得多,可以容納數百萬臺服務器和更多的虛擬機;2) 性能上,超級數據中心具有更高的可擴展性和計算能力,能夠滿足數據處理數量和 速率大幅提升的需求。
具體來講,相較于傳統數據中心,超大規模數據中心的優勢在于: (1)可擴展性:超大規模數據中心的網絡基礎架構響應更迅速、擴展更高效且更具 成本效益,并且提供快速擴展存儲和計算資源以滿足需求的能力,超大規模數據中 心通過在負載均衡器后水平擴展,快速旋轉或重新分配額外資源并將其添加到現有 集群,可以實現快速向集群添加額外資源,從而在不中斷操作的情況下進行擴展; (2)定制化:超大規模數據中心采用更新的服務器設計,具有更寬的機架,可以容 納更多組件并且允許定制化設計服務器,使得服務器能夠同時接入多個電源和硬盤 驅動器;
(3)自動化服務:超大規模數據中心提供自動化服務,幫助客戶管理高流量網站和 需要專門處理的高級工作負載,例如密碼學、基因處理和三維渲染; (4)冷卻效率更高:超大規模數據中心對其電源架構進行了優化,并將冷卻能力集 中在托管高強度工作負載的服務器,大大降低了成本和對環境的影響,電源使用效 率和冷卻效率遠高于傳統數據中心;
(5)工作負載更平衡:超大規模數據中心有效地將工作負載分布在多臺服務器上, 從而避免單臺服務器過熱。避免了過熱的服務器損壞附近的服務器,從而產生不必 要的連鎖反應。 Statista數據顯示,全球超大規模數據中心的數量從2015年的259個,提升到2021年 的700個。根據PrecedenceResearch的報告顯示,全球超大規模數據中心市場規模 在2021年為620億美元,到2030年將達到5930億美元,預計在2022-2030年間以 28.52%的復合增長率(CAGR)增長。
海內外云商均具備自己的超大規模數據中心。Structure Research在其報告中估計, 到2022年全球超大規模自建數據中心總容量將達到13177兆瓦(MW)。全球四大 超大規模數據中心平臺——AWS、谷歌云、Meta和微軟Azure——約占該容量的78%。 全球占主導地位的超大規模數據中心企業仍然是亞馬遜、谷歌、Meta和微軟,在中 國,本土企業阿里巴巴、華為、百度、騰訊和金山云都是領先的超大規模數據中心 企業。
2、IB網絡技術將更廣泛應用于AI訓練超算領域。超級數據中心是具有更大規模和更高計算能力的數據中心。隨著對數據處理數量和 速率需求的提升,數據中心的可擴展性需求也在迅速提升。超級數據中心在規模和 性能上較傳統數據中心都有了大幅升級,能夠滿足超高速度擴展以滿足超級需求的 能力。
泛AI應用是超算中心的重要下游。自20世紀80年代以來,超級計算主要服務于科研 領域。傳統超算基本上都是以國家科研機構為主體的超算中心,如氣象預測、地震 預測、航空航天、石油勘探等。截止2022年底,國內已建成10家國家超級計算中心, 不少省份都建立起省級超算中心,服務于當地的中科院、氣象局以及地震爆炸模型。 一方面,行業頭部企業將超算應用于芯片設計、生物醫療、材料測試等工業應用場 景;另一方面,自動駕駛訓練、大語言模型訓練、類ChatGPT等AI訓練的需求,也 推動超算應用場景延伸至圖像識別、視頻識別定位、智能駕駛場景模擬以及對話和 客服系統等,成為超算中心的重要下游。
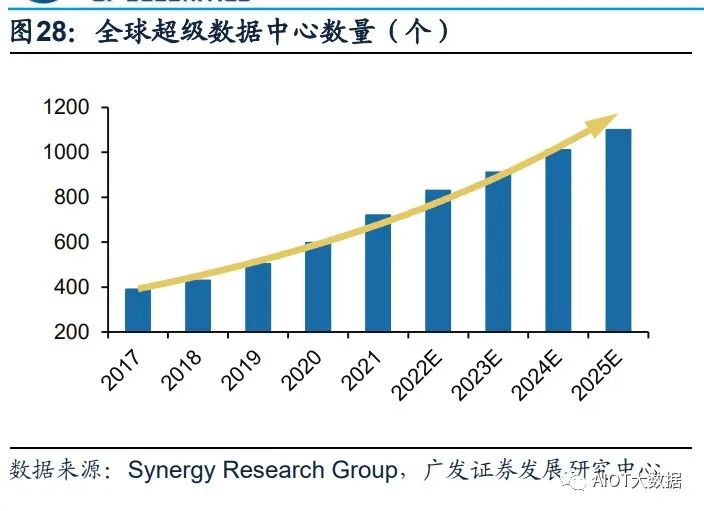
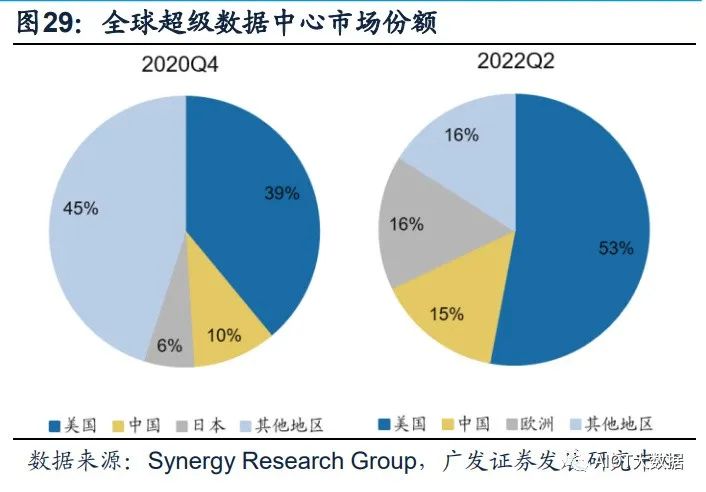
超級數據中心成為算力儲備的重要方向,中美加速算力基建布局。憑借其在算力能 力及能耗效率的巨大提升,超級數據中心在算力儲備中的地位日漸凸顯。根據 Synergy Research Group數據,全球超級數據中心數量從2017年的390個增長至 2021年二季度的659個,增長近一倍,預計2024年總數將超1000個。份額方面,中 美持續加強超級數據中心的布局,占全球市場份額持續提升。
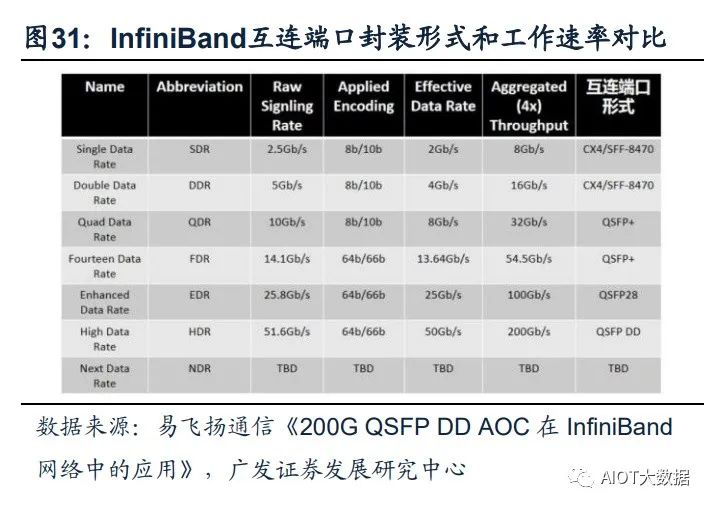
InfiniBand網絡滿足大帶寬和低時延的需求,成為超算中心的主流。InfiniBand(簡 稱IB)是一個用于高性能計算的計算機網絡通信標準,主要應用于大型或超大型數 據中心。IB網絡的主要目標是實現高的可靠性、可用性、可擴展性及高性能,且能 在單個或多個互聯網絡中支持冗余的I/O通道,因此能夠保持數據中心在局部故障時 仍能運轉。相比傳統的以太網絡,帶寬及時延都有非常明顯的優勢。(一般InfiniBand 的網卡收發時延在600ns,而以太網上的收發時延在10us左右,英偉達推出的 MetroX-3提升長距離InfiniBand系統帶寬至400G)。作為未來算力的基本單元,高 性能的數據中心越來越多的采用InfiniBand網絡方案,尤其在超算中心應用最為廣 泛,成為AI訓練網絡的主流。
(四)細分受益環節
GPT-4多模態大模型將引領新一輪AI算力需求的爆發,超大規模數據中心及超算數 據中心作為泛AI領域的重要基礎設施支持,其數量、規模都將相應增長,帶動整個 算力基礎設施產業鏈(如高端服務器/交換機、CPO技術、硅光、液冷技術)的滲透 加速。同時在應用側,Copilot的推出加速AI在辦公領域的賦能,看好辦公場景硬件 配套廠商機會。
1、服務器/交換機: AIGC帶動算力爆發式增長,全球進入以數據為關鍵生產要素的數字經濟時代。從國 內三大運營商資本支出結構上看,加碼算力基礎設施投資成重要趨勢。重點推薦: 中興通訊。公司作為運營商板塊算力投資的核心受益標的,持續在服務器及存儲、 交換機/路由器、數據中心等算力基礎設施領域加強布局,將作為數字經濟筑路者充 分受益我國數字經濟建設。
算力需求帶動上游硬件設備市場規模持續增長,高規格產品占比提升。伴隨著數據 流量持續提升,交換機作為數據中心必要設備,預計全球數據中心交換機保持穩定 增長。2021年全球數據中心交換機市場規模為138億美元,預計到2031年將達246 億美元,2022年至2031年復合年增長率為5.9%。多元開放的AI服務器架構為可以人 工智能發展提供更高的性能和可擴展性的AI算力支撐,隨著AI應用的發展,高性能 服務器數量有望隨之增長,帶動出貨量及服務器單價相應提升。根據IDC報告, 2022Q3,200/400GbE交換機市場收入環比增長25.2%,100GbE交換機收入同比增 長19.8%,高速部分呈現快速增長。
2、光模塊/光芯片: 算力需求提升推動算力基礎設施升級迭代,傳統可插拔光模塊技術弊端和瓶頸開始 顯現。(1)功耗過高,AI技術的加速落地,使得數據中心面臨更大的算力和網絡流 量壓力,交換機、光模塊等網絡設備升級的同時,功耗增長過快。以博通交換機芯 片為例,2010年到2022年交換機芯片速率從640G提升到51.2T,光模塊速率從10G 迭代到800G。速率提升的同時,交換機芯片功耗提升了約8倍,光模塊功耗提升了 26倍,SerDes功耗提升了25倍。(2)交換機端口密度難以繼續提升,光模塊速率 提升的同時,自身體積也在增大,而交換機光模塊端口數量有限。(3)PCB材料遭 遇瓶頸,PCB用于傳輸高速電信號,傳統可插拔光模塊信號傳輸距離長、傳輸損失 大,更低耗損的可量產PCB材料面臨技術難題難以攻克。
NPO/CPO技術有望成為高算力背景下的解決方案。CPO(光電共封裝技術)是一 種新型的高密度光組件技術,將交換芯片和光引擎共同裝配在同一個Socketed(插 槽)上,形成芯片和模組的共封裝。CPO可以取代傳統的插拔式光模塊技術,將硅 光電組件與電子晶片封裝相結合,從而使引擎盡量靠近ASIC,降低SerDes的驅動功 耗成本,減少高速電通道損耗和阻抗不連續性,實現更高密度的高速端口,提升帶 寬密度,大幅減少功耗。
CPO技術的特點主要有:(1)CPO技術縮短了交換芯片和光引擎之間的距離(控制在5~7cm),使得高速電信號在兩者之間實現高質量傳 輸,滿足系統的誤碼率(BER)要求;(2)CPO用光纖配線架取代更大體積的可 插拔模塊,系統集成度得到提升,實現更高密度的高速端口,提升整機的帶寬密度; (3)降低功耗,根據銳捷網絡招股說明書,采用CPO技術的設備整機相比于采用可 插拔光模塊技術的設備,整機功耗降低23%。
高算力背景下,數據中心網絡架構升級帶動光模塊用量擴張及向更高速率的迭代。 硅光、相干及光電共封裝技術(CPO)等具備高成本效益、高能效、低能耗的特點, 被認為是高算力背景下的解決方案。CPO將硅光電組件與電子晶片封裝相結合,使 引擎盡量靠近ASIC,減少高速電通道損耗,實現遠距離傳送。目前,頭部網絡設備 和芯片廠商已開始布局硅光、CPO相關技術與產品。
3、數據中心: IDC數據中心:“東數西算”工程正式全面啟動一周年,從系統布局進入全面建設階 段。隨著全國一體化算力網絡國家樞紐節點的部署和“東數西算”工程的推進,算 力集聚效應初步顯現,算力向規模化集約化方向加速升級,同時數據中心集中東部 的局得到改善,西部地區對東部地區數據計算需求的支撐作用越發明顯。我們認為 政策面推動供給側不斷出清,AI等應用將帶動新一輪流量需求,有望打破數據中心 近兩年供給過剩的局面,帶動數據中心長期發展。
液冷溫控:隨云計算、AI、超算等應用發展,數據中心機柜平均功率密度數預計將 逐年提升,高密度服務器也將被更廣泛的應用于數據中心中。數據中心液冷技術能 夠穩定CPU溫度、保障CPU在一定范圍內進行超頻工作不會出現過熱故障,有效提 升了服務器的使用效率和穩定性,有助于提高數據中心單位空間的服務器密度,大幅 提升數據中心運算效率,液冷技術有望在超高算力密度場景下持續滲透。
4、運營商: 通信運營商自身擁有優質網絡、算力、云服務能力的通信運營商,同時具備天然的 產業鏈優勢,依靠5G+AI技術優勢,為下游客戶提供AI服務能力,是新型信息服務 體系中重要的一環,助力千行百業數字化轉型。作為算力基礎設施建設的主力軍已 經進行前瞻性的基礎設施布局。中國移動打造九天人工智能平臺,推進AI商業化, 賦能中國移動內外部數智化轉型;中國電信全面布局大模型技術,積極探索產業版 “ChatGPT”的商業化應用;中國聯通全力升級算力網絡,推動5G和AI技術的融合。
5、企業通信: 3月16日晚微軟正式宣布推出Microsoft 365 Copilot,將大型語言模型(LLMs)的能 力嵌入到Office辦公套件產品中。基于GPT-4的Copilot以其視頻+圖文的多模態分析 以及更強大生成與理解能力,可更深度、全面發揮視頻會議AI助理功能,比如可以確定目標捕捉發言總結某人談話要點、全面理解會議主要內容并自動整理及發送會 議紀要等。隨著Copilot更強大功能對微軟辦公套件的加持,有望帶動Teams需求的 增長,中國企業通信終端廠商將作為微軟重要的硬件合作伙伴有望深度受益。
審核編輯 :李倩
-
GPT
+關注
關注
0文章
368瀏覽量
16037 -
AI算力
+關注
關注
0文章
94瀏覽量
9221 -
OpenAI
+關注
關注
9文章
1206瀏覽量
8803
原文標題:GPT~4引發新一輪AI算力需求爆發
文章出處:【微信號:AIOT大數據,微信公眾號:AIOT大數據】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
浮思特 | LED顯示屏驅動IC技術解析,基礎原理與創新應用

動態IP技術演進:從網絡基石到智能連接時代的創新引擎
光通信模塊技術特征與應用解析
2025 年串口服務器品牌解析:技術演進與行業應用指南

深入解析三種鋰電池封裝形狀背后的技術路線與工藝奧秘

OpenAI免費開放ChatGPT搜索功能
ChatGPT新增實時搜索與高級語音功能
OpenAI世界最貴大模型:昂貴背后的技術突破
怎樣搭建基于 ChatGPT 的聊天系統
ChatGPT 適合哪些行業
ChatGPT背后的AI背景、技術門道和商業應用






 工商網監
工商網監
評論