 自動駕駛上下求索之路—感知
自動駕駛上下求索之路—感知

“一元復始,萬象更新”。經歷了去年自動駕駛的寒冬,自動駕駛行業正在重新孕育新生,以其堅韌的發展力量引領新一輪的科技變革。度盡劫波,自動駕駛的發展道路正愈發清晰——“漸進式”以一步一個腳印,穩打穩扎,指明了自動駕駛的發展道路。而隨著自動駕駛的等級逐步提升,解決一個個corner cases就成了技術進步的關鍵,在這其中最先需要提升的便是自動駕駛的感知能力。
把自動駕駛當作一個工程項目來看的話,感知、規劃、控制便是其中的一個模塊。今天我們就來聊聊這個模塊的頭部——感知。
和人類一樣,智能駕駛汽車想要自己開上路,首先需要對周圍環境有一個認識,而智能汽車的”眼睛“、”耳朵“就是由多種傳感器組成。
現在行業里喜歡提一個新名詞:”行泊一體“。
其實無論是行車還是泊車,最常用的三種傳感器便是攝像頭、毫米波雷達和激光雷達。
有了這些傳感器是不是就能實現自動駕駛呢?答案顯然是否定的,我們還需要對采集到的數據進行處理,提取出對我們有用的信息,才能進行下一步的規劃和控制。
俗話說”工欲善其事,必先利其器“。
只有打磨好自動駕駛感知算法,與優質的硬件相匹配,才能獲得好的感知結果。接下來我們就按照三款傳感器量產上車的時間順序倒序來講講其基本的感知算法。
一、激光雷達感知算法
激光雷達的輸出產物是點云,近處非常稠密、遠處又非常稀疏的點云,數量以萬計數。因此,Lidar的感知算法任務就是如何從這堆點云中完成目標的檢測。這里的檢測包括了物體的大小、位置、類別、朝向和速度等等,涵蓋了目標的各種特征。

激光雷達生成的3D點云
Lidar的點云感知算法分為基于啟發式的方法和基于深度學習的方法。在深度學習沒有大規模運用之前,人們用的都是啟發式的方法。
面對一個復雜問題,正常的思路也是從啟發式入手。空間中這么多的點,我哪知道誰和誰是同一個物體的呢?但是有一點我是能確定的,這就像是點云空間的“公理”:空間上位置接近的點來自同一個障礙物。這很好理解,我點云是掃描到物體產生的,那產生的一坨靠在一起的點必然是來自同一個物體的,你不可能把FOV里兩個相隔很遠的點關聯成一個物體吧。這個公理有個高大上的名字,叫空間平滑性假設。
有了這個假設,我們就可以把點云建成圖,利用圖論的知識來分割,實現切圖聚類。
對于一個圖G,有頂點V,邊E和權重W。我們把所有的點云看做空間中的點,這些點之間可以用邊連接起來。距離較遠的兩個點之間的邊賦低權重,而距離較近的兩個點之間的邊賦高權重,通過對所有數據點組成的圖進行切圖,讓切圖后不同的子圖間邊權重之和盡可能的低,而子圖內的邊權重之和盡可能的高,從而達到聚類的目的。
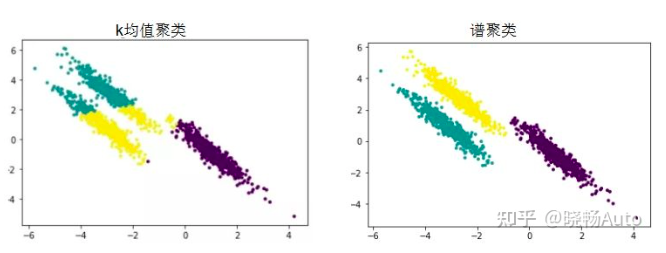
這種方法叫做譜聚類(spectral clustering)。這種方法的優點在于解釋性非常好,如果出現什么bad case,只需要專門針對這種情況調整一下參數即可解決。但是缺點在于分割的規則過于簡單,又丟失了語義信息,像道路旁的草叢這種邊緣不清晰的就沒法很好分割。
譜聚類(spectral clustering)原理總結那既然啟發式的方法沒法很好地像人一樣進行目標分割,我們就來想想人是怎么做分割的,僅僅是通過距離遠近我們就認為那些點云是屬于同一個目標的嗎?不,我們人類會首先根據它是個什么東西,來判斷它應該有多大,邊界在什么地方來為環境中的目標進行分割的。這層至關重要的信息就是啟發式方法中丟棄的語義信息,而想要使用這層特征,就需要深度學習的方法,通過數據驅動,讓模型去挖掘其中蘊含的語義信息,這就是深度學習做目標檢測識別的原理。
深度學習方法在自動駕駛激光雷達目標檢測中的應用始于2010年代。當時,研究人員使用卷積神經網絡(CNN)來處理激光雷達數據,并在檢測和分類目標方面取得了一些成功。隨著深度學習技術的進步和數據量的增加,這些方法變得更加準確和高效。現在,深度學習方法已成為自動駕駛激光雷達目標檢測的主流技術。
以點云卷積神經網絡(PointNet)為例,這種模型能夠處理點云數據,并在點云數據上實現目標檢測。PointNet能夠在沒有明顯結構的點云數據上取得較好的性能。
由于深度學習在激光雷達點云數據處理上方法層出不窮,且與圖像數據進行融合處理成為一種主流趨勢,因此就不在此過多介紹了,之后會結合具體論文與大家一同分析學習。
二、視覺感知算法
視覺感知任務作為機器模仿人類最重要的一環而早早地被安排上了汽車輔助駕駛系統。但在應用初期,其感興趣范圍還比較狹窄,只關注于前方的近距離目標、車道線的識別、行人的輔助檢測等等,這些應用能夠支持車輛進行縱向運動的控制。
這一時期的視覺算法主要是基于計算機圖像處理技術的,基于規則的。通過提取各種各種的邊緣算子完成模型邊緣提取和分割。通過人工構造特征+淺層分類器實現感知任務。但隨著視覺感知任務變得越來越重要,簡單的目標檢測已不能cover更高階自動駕駛的需求,因其總體上是一種low-level的視覺算法。

車道線檢測技術而當前,深度學習在視覺感知中扮演了重要的角色。當前智能駕駛中的視覺感知算法主要包括深度學習方法,如卷積神經網絡(CNN)和卷積神經網絡檢測器(YOLO,SSD等)。當然最新的方向包括Transformer以及BEV感知,還有去年Tesla AI Day上公開的Occupancy Network。
計算機視覺技術的突飛猛進自然帶起了自動駕駛中的視覺感知,但是需要注意攝像頭的視角約束與結構化道路的約束,它并不像CV圖像里的一切皆有可能,而是發生在實實在在道路上的視覺感知。
同時這種感知已不簡簡單單是2D輸出,而是對三維信息提出了要求,因此三維目標檢測技術就會更加受到重視。
一般的視覺感知流程框圖是像素信號輸入進來,首先做detection,隨后做2D到3D的投影轉換,這部分可以和激光雷達數據結合起來,之后做Tracking。不同的架構中使用深度學習的地方不同,有只在檢測任務里使用CNN的,后面兩個模塊仍使用傳統方法,這樣子可以保證實時性,因為自動駕駛對實時性要求很高,很多論文中花里胡哨的神經網絡模型實際上沒法部署到車上。而現在也有端到端訓練的趨勢,即把檢測到追蹤打包放進一個網絡中訓練,通過大量喂數據,直接得到最終的目標位置、距離等信息。同時,由于視覺感知不止目標檢測追蹤這一個任務,而其他任務使用的輸入又都是相同的,因此可以在模型輸出時采用多頭結構,一套網絡多個輸出,同時完成檢測、分類、分割等多重任務。
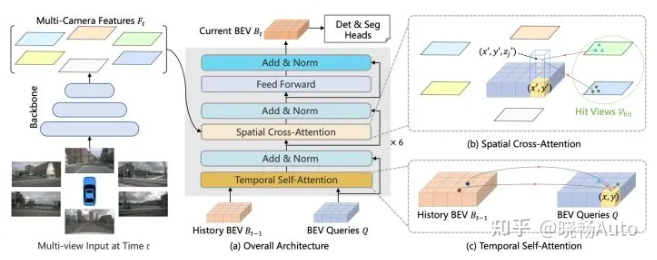
BEV Former
三、毫米波雷達感知算法
作為最早上車的感知零部件,毫米波雷達的感知算法往往是各家自動駕駛方案供應商所忽略的。究其根本并非是其不重要,而是這部分Know-how被牢牢把握在國際Tier1巨頭手里,主機廠和自動駕駛公司只能拿到輸出的目標,對他們而言,毫米波雷達感知就是一個黑盒。

Continental ARS540全球第一款量產4D毫米波雷達
但實際上,由于毫米波雷達不受光線、雨霧天氣影響,并且探測距離特別遠,在ACCAEB功能上應用非常純熟,因此毫米波雷達的感知結果相當重要。即使在視覺主導的感知體系中,由于雷達能直接探測目標的距離和速度,因此這兩者的權重相比于攝像頭的檢測是要高很多的。
毫米波雷達與激光雷達同為雷達,因此得到的輸入其實都是點云。但是毫米波雷達的點云要比激光雷達稀疏的多,哪怕是反射比較強烈的金屬物體,例如車身,毫米波雷達依舊只能打出十幾個點,而對于行人這種RCS小得多的目標,能打出一兩個點就很不錯了。這就是為什么毫米波雷達做行人檢測和目標分類不擅長的原因。
由于點云非常稀疏,這就導致依賴大量數據訓練的神經網絡發揮不了其特長,故而毫米波雷達的感知算法還是基于規則的方法,以一個個人工手動調的參數作為閾值,組成了毫米波雷達感知算法的框架。
與激光雷達感知類似,毫米波雷達也是首先對點云進行聚類,這里面常用的就是JPDA這樣的關聯算法,通過與目標關聯,獲得每一幀點云的具體位置和速度。生成目標后,對目標進行維護,這里的維護就包括預測和更新的卡爾曼濾波手法,從而實現多目標的穩定跟蹤。在FOV視野范圍內,確保目標保持同一個ID,連續不斷地進行追蹤。
在主線任務外,還會做一些目標長寬、orientation、存在概率等的屬性的判斷,幫助感知系統確認這是一個真實的可以使用的目標。
除了對目標的檢測追蹤,毫米波雷達感知算法還能夠給出車道線的預測、道路邊界描述以及Freespace等感知信息。
由于傳統的毫米波雷達天線不具有測高能力,具有測高功能的4D毫米波雷達已進入量產。4D毫米波雷達由于天線通道成倍增加,因此獲得的點云數量有了大幅度提升,因此具備了深度學習的應用條件。這部分感知算法還處于研發當中,算是毫米波雷達感知中非常前言的東西。
總結路漫漫其修遠兮,自動駕駛的道路不是一帆風順的,Corner case也是不斷出現的。只有不斷提升感知硬件的能力、完善感知算法的模型,才能確保在當前人工智能水平下智能汽車完成高級別自動駕駛功能。
審核編輯 :李倩
-
人工智能
+關注
關注
1805文章
48898瀏覽量
247823 -
激光雷達
+關注
關注
971文章
4218瀏覽量
192380 -
自動駕駛
+關注
關注
788文章
14263瀏覽量
170127
原文標題:自動駕駛上下求索之路—感知
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論