 經典多目標跟蹤算法DeepSORT的基本原理和實現
經典多目標跟蹤算法DeepSORT的基本原理和實現
目標檢測 vs 目標跟蹤
在開始介紹DeepSORT的原理之前呢,我們先來了解下目標檢測,和目標跟蹤之間的區別:
目標檢測:在目標檢測任務中,我們需要利用AI模型識別出單張畫面中,物體的位置和類別信息,每一幀畫面之間檢測結果相對獨立,沒有依賴關系。這也意味著目標檢測算法可以被應用于單張圖片的檢測,也可以用于視頻中每一幀畫面的檢測。
目標跟蹤:而目標跟蹤則是在目標檢測的基礎上加入的跟蹤機制,他需要追蹤視頻中同一物體在不同時刻的位置信息,因此他需要判斷相鄰幀之間的被檢測到對象是否是同一個物體,并且為同一物體分配唯一的編號ID,用來區別不同的目標對象。
例如下面短跑運動員比賽的例子中,目標檢測任務只需要識別到畫面中所有人體的位置即可,而目標跟蹤任務則需要區分畫面中相同的對象和不同對象。
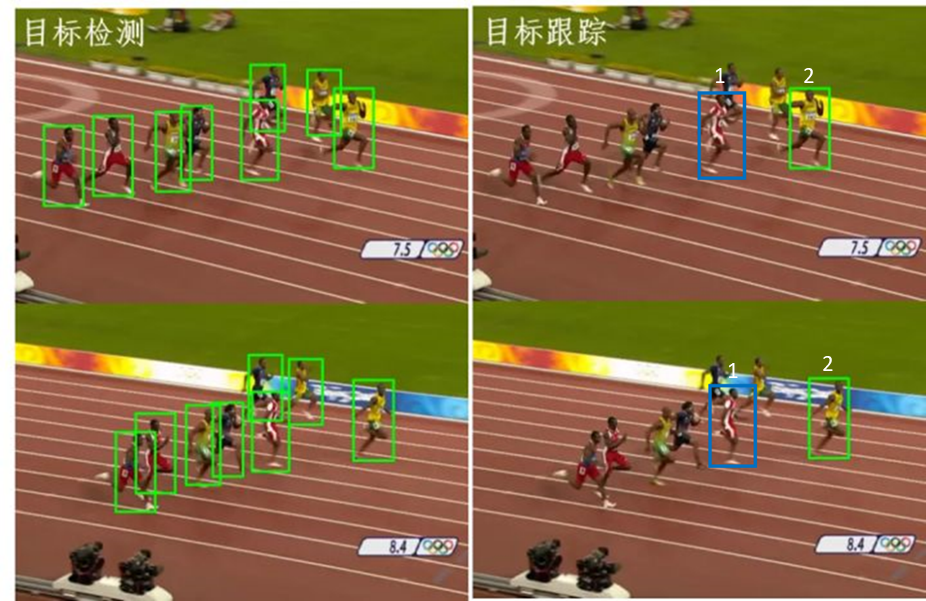
圖:目標檢測與目標跟蹤比較
DeepSORT
DeepSORT的前身是SORT算法,SORT算法是由目標檢測器以及跟蹤器所構成,其跟蹤器的核心是卡爾曼濾波算法和匈牙利算法。利用卡爾曼濾波算法預測檢測框在下一幀的狀態,將該狀態與下一幀的檢測結果利用匈牙利算法進行匹配,實現追蹤。一旦物體受到遮擋或者其他原因沒有被檢測到,卡爾曼濾波預測的狀態信息將無法和檢測結果進行匹配,該追蹤片段將會提前結束。
而DeepSORT則引入了深度學習中的重識別算法來提取被檢測物體(檢測框物體中)的外觀特征(低維向量表示),在每次(每幀)檢測+追蹤后,進行一次物體外觀特征的提取并保存。后面每執行一步時,都要執行一次當前幀被檢測物體外觀特征與之前存儲的外觀特征的相似度計算,依次來避免遇到漏檢的情況,將失去身份ID的情況,可以說DeepSORT不光使用了物體的速度和方向趨勢來對目標進行跟蹤,同時也利用物體的外觀特征鞏固對是否為同一物體的判斷。
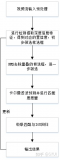
這里我們可以將DeepSORT跟蹤算法歸納為以下幾個步驟:
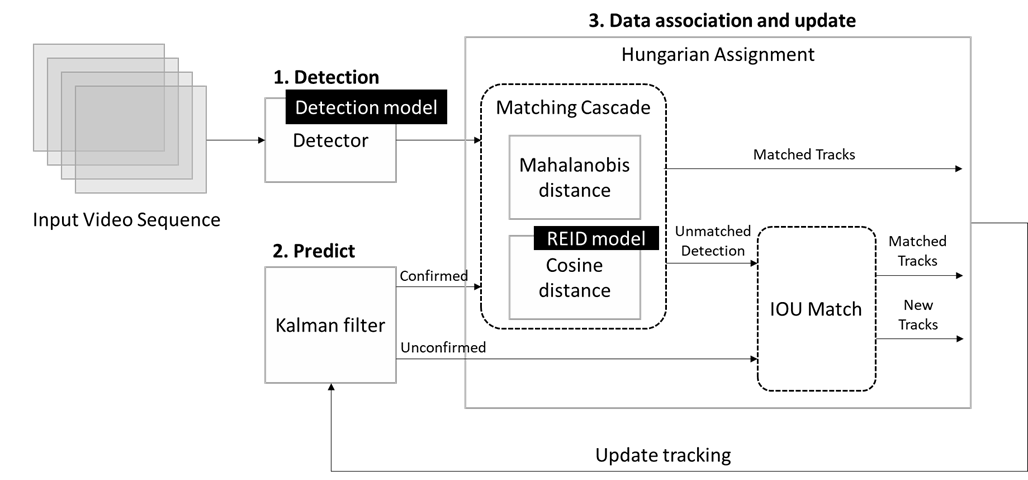
圖:DeepSORT方法流程圖
1. 目標檢測
使用常規的目標檢測模型,對單幀畫面進行識別,并過濾出待跟蹤對象,例如這個任務中我們的跟蹤對象為人體,那其他被檢測到的對象,例如桌子,椅子將被全部丟棄。
2. 目標預測
在這一步中,我們將使用卡爾曼濾波算法。基于當前的一系列運動變量去預測下一時刻的運動變量,但是第一次的檢測結果用來初始化卡爾曼濾波的運動變量。預測結果分為確認態 (confirmed),和不確認態 (unconfirmed),新產生的 Tracks 是不確認態的;不確認態的 Tracks 必須要和 Detections 連續匹配一定的次數才可以轉化成確認態。確認態的Tracks必須和Detections連續適配一定次數才會被刪除。
3. 數據關聯和更新
接下來需要把檢測到的物體和預測的物體進行關聯, 此處DeepSORT將使用匈牙利算法,并根據不同的代價函數來尋找最大匹配。如果卡爾曼濾波輸出確認態的預測結果,DeepSORT將采用馬氏距離加余弦距離的級聯方法對相關信息進行關聯,通過馬氏距離我們可以獲取運動物體在兩個不同狀態的距離信息,如果某次關聯的馬氏距離小于指定的閾值,則設置運動狀態的關聯成功,但是DeepSORT不僅看框與框之間的距離,還要看框內的表觀特征才能更好的進行關聯匹配,所以DeepSORT還引入了表觀特征余弦距離度量,這里會使用一個重識別模型來獲取不同物體的特征向量,然后再通過余弦距離構建代價函數,計算預測對象與檢測對象的相似度。這兩個代價函數結果都盡量的小,框也接近、特征也接近的話,就認為兩個預測框中是同一個東西。
DeepSORT之所以引入這樣的級聯方法,是因為如果在運動狀態變化比較劇烈的場景下,基于目標狀態之間的關聯很可能是不可靠的(舉個例子,當一個人在跑步時,如果相機是靜止的或者與人的運動方向相反,那么相機中的人在每幀之間的運動狀態就會差異較大),在這樣的情況下,運動的不確定性變高,先驗狀態與目標檢測之間的匹配差異較大,而彌補這個缺陷的方法就是使用特征相似距離關聯;但是在目標運動狀態變化并不劇烈的情況下,這時候幀與幀之間,馬氏距離就成為了很好的數據關聯度量的選擇。
數據關聯的第二步則是計算不確認態下的預測框和未被上一步級聯方法匹配檢測框的IOU交并比,DeepSORT使用匈牙利算法尋找最大匹配的IOU結果,如果預測框和檢測框的IOU低于閾值,我們將刪除兩者的關聯性。
最后利用當前幀的關聯結果更新預測器中所有被分配ID的跟蹤對象狀態。
DeepSORT任務實現
接下來我們來看DeepSORT的基本實現,這里我們可以直接使用DeepSORT作者提供的跟蹤器對象模塊實現卡爾曼濾波算法預測以及匈牙利算法匹配等多種功能,開發者可以直接替換其中目標檢測模型與重識別模型,并修改最大匹配次數等參數,以提升在目標場景下的識別跟蹤準確性。推理部分使用OpenVINO做為推理引擎。這里有幾個關鍵的模塊:
1. 模型初始化
本次任務中會使用兩個深度學習模型,都是來自于OpenVINO官方的Open Model Zoo模型倉庫。這里可以提前定義一個通用的OpenVINO的模型類來對這兩個模型進行初始化,并設置他的預測推理函數。由于目標檢測任務的輸出數量往往不固定,同時我們又需要利用重識別模型為每一個目標檢測任務的輸出構建特征向量,因此為了提升模型的執行效率,我們將重識別模型的batachsize初始化為“-1”,以動態匹配不斷變化的目標數量。
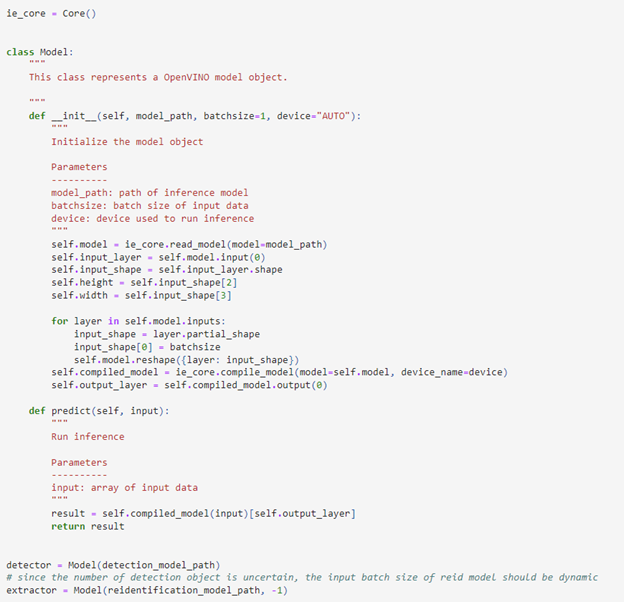
圖:OpenVINO模型對象
2. 余弦距離
本次任務采用余弦距離作為匹配算法的代價函數之一,因此我們需要首先定義余弦距離的計算方法(如下圖所示),其中x1,x2分別為重識別模型輸出的特征向量。

圖:余弦距離計算方法
接下來我們可以測試下這個方案的效果,我們將兩個不同人體對象的圖片進行特征向量化后,將模型輸出的結果直接送入余弦距離模塊中,計算相關性的置信度,可以看到當兩張圖片屬于同一對象的情況下,置信度較高,兩個圖片不屬于同一對象的情況下置信度就會低于閾值。
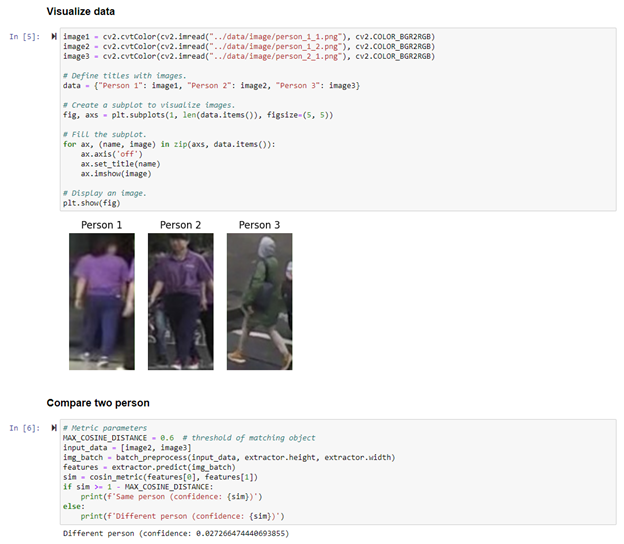
圖:不同人體對象余弦距離計算結果
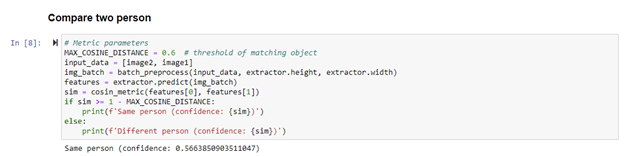
圖:相同人體對象余弦距離計算結果
3. Tracker跟蹤器
Tracker是DeepSORT方法的核心對象,在具體調用方法里,第一步先要定義一個Tracker對象,并聲明關鍵參數里,例如考慮到內存占用情況,我們需要定義NN_BUDGET,用于限制同屏中最大跟蹤對象的數量,同時使用cosine最大余弦距離作為代價函數,并且指定IOU和余弦距離的閾值,以及max_age描述最大多少次無匹配會刪除追蹤對象, n_init描述確認狀態需要的最少匹配次數。
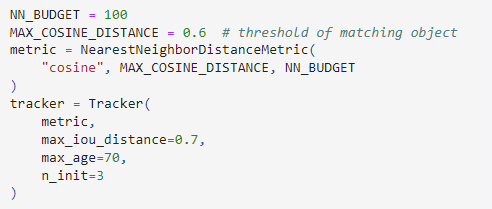
圖:Tracker跟蹤器初始化方法
然后進入到主函數部分,在開始track任務之前,會先將目標檢測模型和重識別模型的輸出結果打包成Detection對象,一起送入Tracker中進行匹配,當目標對象轉化為確認狀態后,可以從Tracker對象中獲取每一個目標的唯一ID用于在原始畫面中進行標注。

圖:調用跟蹤器的預算和update關聯方法
4. 最終實現效果
在完成主函數定義后,我們可以給他輸入一段視頻流,或者使用身邊的網絡攝像頭獲取實時影像進行驗證。
可以看到DeepSORT方法非常精確的識別并跟蹤了畫面中每一個人體對象的位置,并且在僅在普通酷睿系列的CPU上就可以實現60FPS左右的流暢表現。 
圖:最終實現效果
小結
本文分享多目標跟蹤算法的經典算法DeepSORT,它是一個兩階段的算法,作為SORT 的升級版,它整合了外觀信息 (appearance information) 從而提高 SORT 的性能,這使得我們在遇到較長時間的遮擋時,也能夠正常跟蹤目標,并有效減少 ID 轉換的發生次數。
審核編輯:劉清
-
檢測器
+關注
關注
1文章
887瀏覽量
48435 -
卡爾曼濾波
+關注
關注
3文章
166瀏覽量
24986 -
sort
+關注
關注
0文章
5瀏覽量
2680
原文標題:經典多目標跟蹤算法DeepSORT的基本原理和實現丨開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
視頻跟蹤目標跟蹤算法簡介(上海凱視力成信息科技有限...
視頻圖像動態跟蹤算法的設計與實現
多傳感器多目標跟蹤的JPDA算法


基于卷積特征的多伯努利視頻多目標跟蹤算法


多目標跟蹤算法總結歸納





 工商網監
工商網監
評論