 上交清華提出中文大模型的知識評估基準C-Eval,輔助模型開發而非打榜
上交清華提出中文大模型的知識評估基準C-Eval,輔助模型開發而非打榜

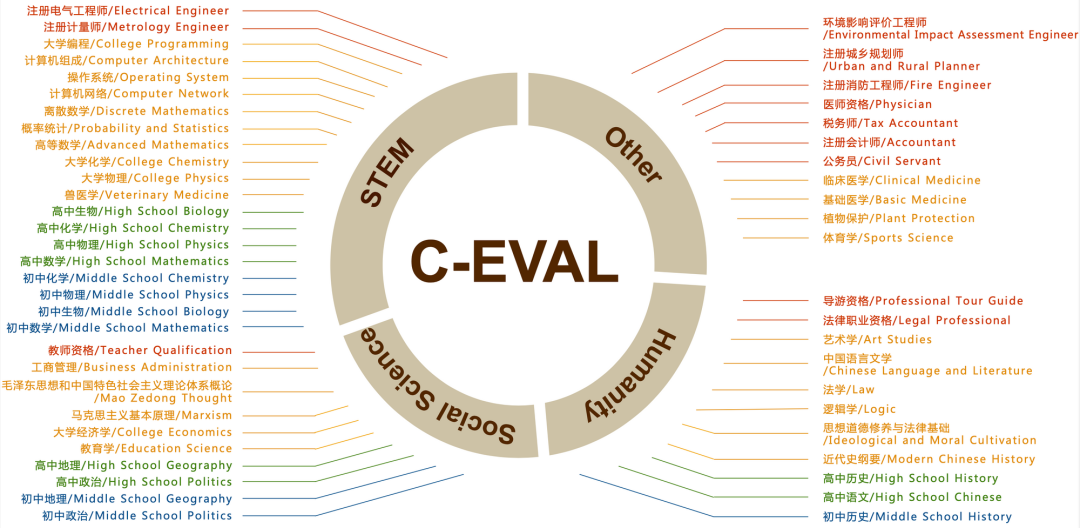
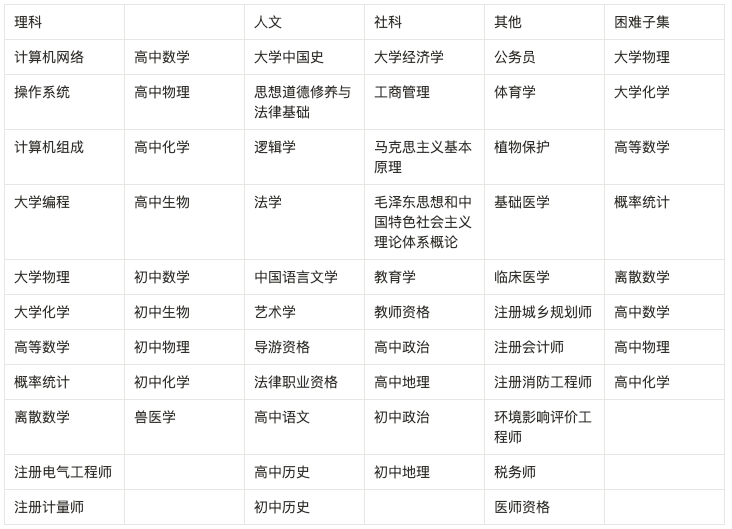
ChatGPT 的出現,使中文社區意識到與國際領先水平的差距。近期,中文大模型研發如火如荼,但中文評價基準卻很少。在 OpenAI GPT 系列 / Google PaLM 系列 / DeepMind Chinchilla 系列 / Anthropic Claude 系列的研發過程中,MMLU / MATH / BBH 這三個數據集發揮了至關重要的作用,因為它們比較全面地覆蓋了模型各個維度的能力。最值得注意的是 MMLU 這個數據集,它考慮了 57 個學科,從人文到社科到理工多個大類的綜合知識能力。DeepMind 的 Gopher 和 Chinchilla 這兩個模型甚至只看 MMLU 的分數,因此我們想要構造一個中文的,有足夠區分度的,多學科的基準榜單,來輔助開發者們研發中文大模型。我們花了大概三個月的時間,構造了一個覆蓋人文,社科,理工,其他專業四個大方向,52 個學科(微積分,線代 …),從中學到大學研究生以及職業考試,一共 13948 道題目的中文知識和推理型測試集,我們管它叫 C-Eval,來幫助中文社區研發大模型。
這篇文章是把我們構造 C-Eval 的過程記下來,與開發者們分享我們的思考和我們視角下的研發重點。我們的最重要目標是輔助模型開發,而不是打榜。一味地追求榜單排名高會帶來諸多不利后果,但如果能夠科學地使用 C-Eval 幫助模型迭代的話,則可以最大化地利用 C-Eval。因此我們推薦從模型研發的視角來對待 C-Eval 數據集和榜單。
1 - 模型強弱的核心指標
首先,把一個模型調成一個對話機器人這件事情并不難,開源界已經有了類似于 Alpaca, Vicuna, RWKV 這樣的對話機器人,跟它們隨便聊聊感覺都還不錯;但要真正希望這些模型成為生產力,隨便聊聊是不夠的。所以構造評價基準的第一個問題是要找到區分度,弄明白什么樣的能力才是區分模型強弱的核心指標。我們考慮知識和推理這兩項核心。
1.1 - 知識
為什么說知識性的能力是核心能力?有以下幾點論點:
我們希望模型可以通用,可以在不同領域都貢獻生產力,這自然需要模型知道各個領域的知識。
我們同時希望模型不要胡說八道,不知為不知,這也需要擴大模型的知識,讓它可以在更少的時候說它不知道。
斯坦福的 HELM 英文評價榜單中,一個重要的結論是,模型大小與知識密集型任務的效果顯著正相關,這是因為模型的參數量可以被用來儲存知識。
上文已經提到,已有的重要模型,比如 DeepMind 的 Gopher / Chinchilla,在評價的時候幾乎只看 MMLU,MMLU 的核心就是測模型的知識覆蓋面。
GPT-4 的發布博客中,首先就是列出模型在各個學科考試上的效果,作為模型能力的衡量標準。
因此,知識型能力可以很好地衡量底座模型的潛力。
1.2 - 推理
推理能力是在知識的基礎上進一步上升的能力,它代表著模型是否能做很困難,很復雜的事情。一個模型要強,首先需要廣泛的知識,然后在知識的基礎上做推理。
推理很重要的論點是:
GPT-4 的發布博客中,OpenAI 明確寫道 “The difference comes out whenthe complexity of the task reaches a sufficient threshold” (GPT-3.5 和 GPT-4 的區別只在任務復雜到一定程度之后才會顯現)。這說明推理是很顯著的強的模型有,弱一點的模型不大有的能力。
在 PaLM-2 的 Tech Report 中,BBH 和 MATH 這兩個推理數據集被專門列出來討論劃重點。
如果希望模型成為新一代的計算平臺,并在上面孕育出全新的應用生態的話,就需要讓模型能夠做足夠強的完成復雜任務的能力。
這里我們還需要厘清推理和知識的關系:
知識型的能力是模型能力的基礎,推理能力是進一步的升華 — 模型要推理也是基于現有的知識圖里。
知識性任務的榜單上,模型大小和模型分數一般是連續變化的,不大會因為模型小就出現斷崖式下跌 — 從這個角度來說知識型的任務更有區分度一點。
推理型任務的榜單上,模型大小和模型分數可能存在相變,只有當模型大到一定程度之后(大概是 50B 往上,也就是 LLaMA 65B 這個量級),模型推理能力才會上來。
對于知識性的任務,Chain-of-thought (CoT) prompting 和 Answer-only (AO) prompting 的效果是差不多的;對于推理型任務,CoT 顯著好于 AO.
所以這邊需要記住一下,CoT 只加推理效果不加知識效果。在 C-Eval 數據集中,我們也觀察到了這個現象。
2 - C-Eval 的目標
有了上述對于知識和推理的闡述,我們決定從知識型的任務出發,構造數據集測試模型的知識能力,相當于對標一下 MMLU 這個數據集;同時,我們也希望帶一點推理相關的內容,進一步衡量模型的高階能力,所以我們把 C-Eval 中需要強推理的學科(微積分,線性代數,概率 …)專門抽出來,命名為 C-Eval Hard 子集,用來衡量模型的推理能力,相當于對標一下 MATH 這個數據集。在 C-Eval Hard 上面,模型首先需要有數學相關知識,然后需要有逐步解題的思路,然后需要在解題過程中調用 Wolfram Alpha/ Mathematica/ Matlab 進行數值和符號 / 微分和積分計算的能力,并把計算過程和結果以 Latex 的格式表示出來,這部分的題目非常難。
C-Eval 希望可以在整體上對標 MMLU (這個數據集被用于 GPT-3.5, GPT-4, PaLM, PaLM-2, Gopher, Chinchilla 的研發),希望在 Hard 的部分對標 MATH (這個數據集被用于 GPT-4, PaLM-2, Minerva, Galactica 的研發)。
這里需要注意的是,我們的最重要目標是輔助模型開發,而不是打榜。一味地追求榜單排名高會帶來諸多不利后果,這個我們馬上會闡述;但如果能夠科學地使用 C-Eval 幫助模型迭代的話,則會得到巨大收益。我們推薦從模型研發地視角來對待 C-Eval 數據集和榜單。
2.1 - 目標是輔助模型開發
在實際研發的過程中,很多時候我們需要知道某種方案的好壞或者某種模型的好壞,這個時候我們需要一個數據集幫助我們測試。以下是兩個經典場景:
場景 1 ,輔助超參數搜索:我們有多種預訓練數據混合方案,不確定哪種更好,于是我們在 C-Eval 上相互比較一下,來確定最優預訓練數據混合方案。
場景 2 ,比較模型的訓練階段:我有一個預訓練的 checkpoint ,也有一個 instruction-tuned checkpoint,然后我想要衡量我的 instruction-tuning 的效果如何,這樣可以把兩個 checkpoint 在 C-Eval 上相互比較,來衡量預訓練和 instruction-tuning 的相對質量。
2.2 - 打榜不是目標
我們需要強調一下為什么不應該以榜單排名作為目標:
如果把打榜作為目標,則容易為了高分而過擬合榜單,反而丟失通用性 — 這是 GPT-3.5 之前 NLP 學術界在 finetune Bert 上學到的一個重要教訓。
榜單本身只測模型潛力,不測真實用戶感受 — 要模型真的被用戶喜好,還是需要大量的人工評價的
如果目標是排名,則容易為了高分想走捷徑,失去了踏實科研的品質與精神。
因此,如果把 C-Eval 作為輔助開發的工具,那么可以最大程度上的發揮它的積極作用;但是如果把它作為一個榜單排名,則存在極大的誤用 C-Eval 的風險,最終也大概率不會有很好的結果。
所以再一次,我們推薦從模型研發地視角來對待 C-Eval 數據集和榜單。
2.3 - 從開發者反饋中持續迭代
因為我們希望模型可以最大程度的支持開發者,所以我們選擇直接跟開發者交流,從開發者的反饋中持續學習迭代 — 這也讓我們學到了很多東西;就像大模型是 Reinforcement Learning from Human Feedback 一樣,C-Eval 的開發團隊是 Continue Learning from Developers’ Feedback.
具體來說,我們在研發的過程中,邀請了字節跳動,商湯,深言等企業將 C-Eval 接入到他們自己的工作流中做測試,然后相互溝通測試過程中存在哪些比較有挑戰的點。這個過程讓我們學習到很多開始時沒想到的內容:
很多測試團隊,即使是在同一個公司,也無法知道被測試模型的任何相關信息(黑盒測試),甚至不知道這個模型有沒有經過 instruction-tuning ,所以我們需要同時支持 in-context learning 和 zero-shot prompting.
因為有些模型是黑盒測試,沒辦法拿到 logits,但是小模型沒有 logits 就比較難確定答案,所以我們需要確定一套小模型定答案的方案。
模型的測試模型有多種,比如in-context learning 和 zero-shot prompting;prompt 的格式有多種,比如 answer-only 和 chain-of-thought;模型本身有多種類型,比如 pretrained checkpoint 和 instruction-finetuned checkpoint,因此我們需要明確這些因素各自的影響以及相互作用。
模型的對于 prompt 的敏感度很高,是否需要做 prompt engineering,以及 prompt engineering 是否有礙公平。
GPT-3.5 / GPT-4 / Claude / PaLM 的 prompt engineering 應該怎么做,然后如果從中學習到他們的經驗。
以上的這些問題都是我們在跟開發者的交互過程中,從開發者反饋里發現的。在現在 C-Eval 的公開版本的文檔和 github 代碼中,這些問題都有解決。
上面的這些過程也證明了,從模型研發的視角來對待 C-Eval 數據集和榜單,可以非常好地幫助大家開發中文大模型。
我們歡迎所有的開發者們給我們的 GitHub 提 issue 和 pull request,讓我們知道如何更好地幫助你,我們希望可以更好地幫助你 :)
3 - 如何保證質量
這個章節我們討論在制作的過程中,我們用了哪些方法來保證數據集的質量。這里我們最重要的參考是 MMLU 和 MATH 這兩個數據集,因為 OpenAI, Google, DeepMind, Anthropic 這四個最重要的大模型團隊都重點參考了 MMLU 和 MATH,所以我們希望可以向這兩個數據集看齊。在我們初步的調研和一系列的討論之后,我們做了兩個重要的決策,一個是從頭開始手工制做數據集,另一個是在此過程中重點防止題目被爬蟲爬到訓練集里。
3.1 - 手工制作
GPT 的開發過程的一個重要啟發是,人工智能這行,有多少人工就有多少智能,這個在我們建立 C-Eval 的過程中也有很好地體現,具體來說,從題目來源看:
C-Eval里面的題目大多是來源于pdf和word格式的文件,這類題目需要額外的處理和(人工)清洗才能使用。這是因為網上各種題目太多了,直接是網頁文本形式存在的題目很可能已經被用于模型的預訓練中
然后是處理題目:
收集到題目之后,先把pdf文件做 OCR 來電子化,然后把格式統一成 Markdown,其中數理的部分統一用 Latex 格式來表示
公式的處理是一件麻煩的事情:首先 OCR 不一定能識別對,然后 OCR 也不能直接識別成 Latex;這里我們的做法是能自動轉 Latex 就自動轉,不能自動轉就同學自己手動敲
最終的結果是,13000多 道題目里面所有跟符號相關的內容(包括數學公式和化學式,H2O 這種)都是被我們項目組的同學一一驗證過的,我們大概有十來位同學花了將近兩周的時間做這個事情
所以現在我們的題目可以非常漂亮地用 markdown 的形式呈現,這里我們給一個微積分的例子,這個例子可以直接在我們的網站中,explore 的部分看到:

接下來的難點就是如何構造官方的 chain-of-thought prompt ,這個地方的重點在于,我們需要保證我們的 CoT 是對的。我們一開始的做法是對于每個 in-context example ,我們讓 GPT-4 生成一個 Chain-of-thought,但后來發現這個不大行,一來是生成的太長了 (超過 2048 個 token),有些模型的輸入長度不一定支持;另一個是錯誤率太高了,一個個檢查不如自己做一遍
所以我們的同學們就基于GPT-4生成的CoT,把微積分,線代,概率,離散這些 prompt 的題目(每個科目5道題作為in-context examples),真的自己做了一遍,以下是一個例子:

大家也能感受到為什么題目很難,chain-of-thought prompt 很長,為什么模型需要有能力做微積分的符號和數值計算
3.2 - 防止混入訓練集
為了評測的科學性,我們考慮了一系列機制來防止我們的題目被混入訓練集
首先,我們的測試集只公開題目不公開答案,大家可以拿自己的模型在本地把答案跑出來然后在網站提交,然后后臺會給出分數
然后,C-Eval的所有題目都是模擬題,從中學到考研到職業考試我們都沒有用過任何真題,這是因為全國性考試的真題廣泛存在于網上,非常容易被爬取到模型訓練集里
當然,盡管我們做出了這些努力,但可能也會不可避免的發生某個網頁里能搜到題庫里的題目,但我們相信這種情況應該不多。且從我們已有的結果看,C-Eval 的題目還是有足夠區分度的,特別是 Hard 的部分。
4 - 提升排名的方法
接下來我們分析有哪些方法可以提升模型的排名。我們先把捷徑給大家列出來,包括使用不能商用的 LLaMA 和使用 GPT 產生的數據,以及這些方法的壞處;然后我們討論什么是困難但正確的路。
4.1 - 有哪些捷徑可以走?
以下是可以走的捷徑:
使用 LLaMA 作為基座模型:在我們另一個相關的英文模型評測項目 Chain-of-thought Hub 中,我們指出了 65B 的 LLaMA 模型是一個稍弱于 GPT-3.5 的基礎模型,它有著很大的潛力,如果把它用中文的數據訓練,其強大的英文能力可以自動遷移到中文。
但這樣做的壞處,一來是研發能力的上限被 LLaMA 65B 鎖死,不可能超過 GPT-3.5,更何況 GPT-4 了,另一方面是 LLaMA 不可商用,使用它商業化會直接違反條例
使用 GPT-4 生成的數據:特別是 C-Eval Hard 的部分,直接讓 GPT-4 做一遍,然后 GPT-4 的答案喂給自己的模型就可以了
但這樣做的壞處,一來是如果商業化,就直接違反了 OpenAI 的使用條例;二來是從 GPT-4 做蒸餾會加劇模型胡說八道的現象,這是因為 RLHF 在微調模型拒絕能力的時候,是鼓勵模型知之為知之,不知為不知;但是直接抄 GPT-4 的話,GPT-4 知道的東西,其他的模型不一定知道,這樣反而鼓勵模型胡說八道。這個現象在 John Schulman 近期在伯克利的一個演講中被重點討論了。
很多時候,看似是捷徑的道路,其實在暗中標好了價格。
4.2 - 困難但正確的路
最好的方法是自立自強,從頭研發。這件事情很難,需要時間,需要耐心,但這是正確的路。
具體來說,需要重點關注以下機構的論文
OpenAI - 這個毋庸置疑,所有文章都要全文背誦
Anthropic - OpenAI 不告訴你的東西,Anthropic 會告訴你
Google DeepMind - Google 比較冤大頭,什么技術都老實告訴你,不像 OpenAI 藏著掖著
如果讀者在里經驗不足,那么可以先不要看其他的地方的文章。先培養判斷力,再去讀其他地方的文章,這樣才能分清好壞。在學術上,要分清好壞,而不是不加判斷一味接受。
在研發的過程中,建議關注以下內容:
如何組 pretraining 的數據,比如 DoReMi 這個方法
如何增加 pretraining 的穩定性,比如 BLOOM 的方法
如何組 instruction tuning 的數據,比如 The Flan Collection
如何做 instruction tuning ,比如 Self-instruct
如何做 RL,比如 Constitutional AI
如何增加 reasoning 的能力,比如我們先前的博客
如何增加 coding 能力,比如 StarCoder
如何增加工具使用的能力 (C-Eval Hard 需要模型能調用工具做科學計算),比如 toolformer
4.3 - 不著急
大模型就是一件花時間的事情,它是對人工智能工業能力的全方位大考:
OpenAI 的 GPT 系列從 GPT-3 走到 GPT-4,從 2019 到 2023,一共花了四年的時間。
Anthropic 原班人馬從 OpenAI 剝離之后,即使有 GPT-3 的經驗,重新做一遍 Claude 也花了一年的時間。
LLaMA 的團隊,即使有 OPT 和 BLOOM 的教訓,也花了六個月的時間。
GLM-130B 從立項到發布,花了兩年的時間。
MOSS 的 alignment 的部分,在 RL 之前的內容,也花了將近半年的時間,這還是沒算 RL 的。
因此,不用著急打榜,不用明天就看結果,不用后天上線 — 慢慢來,一步一步來。很多時候,困難但正確的路,反而是最快的路。
5 - 結論
在這篇文章中,我們介紹了 C-Eval 的開發目標,過程,和重點考量的因素。我們的目標是幫助開發者更好地開發中文大模型,促進學術界和產業界科學地使用 C-Eval 幫助模型迭代。我們不著急看結果,因為大模型本身就是一件非常困難的事情。我們知道有哪些捷徑可以走,但也知道困難但正確的路反而是最快的路。我們希望這份工作可以促進中文大模型的研發生態,讓人們早一點體驗到這項技術帶來的便利。
附錄1:C-Eval 包含的科目
附錄2:項目成員的貢獻

審核編輯 :李倩
-
機器人
+關注
關注
213文章
29756瀏覽量
213051 -
數據集
+關注
關注
4文章
1224瀏覽量
25463 -
OpenAI
+關注
關注
9文章
1210瀏覽量
8952
原文標題:上交清華提出中文大模型的知識評估基準C-Eval,輔助模型開發而非打榜
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【大語言模型:原理與工程實踐】大語言模型的評測
esp-dl int8量化模型數據集評估精度下降的疑問求解?
Al大模型機器人
【「基于大模型的RAG應用開發與優化」閱讀體驗】+第一章初體驗
ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜單位列榜首
大模型評測難度大嗎 大模型的評測應該怎么弄?

清華大學大語言模型綜合性能評估報告發布!哪個模型更優秀?

云知聲千億參數山海大模型首次亮相

第一!vivo自研AI大模型位列C-Eval、CMMLU榜首
小米大語言模型獲備案,有望應用于汽車、手機等產品
中文大模型測評基準SuperCLUE:商湯日日新5.0,刷新國內最好成績

【每天學點AI】人工智能大模型評估標準有哪些?






 工商網監
工商網監
評論