") 一個(gè)通用的自適應(yīng)prompt方法,突破了零樣本學(xué)習(xí)的瓶頸
一個(gè)通用的自適應(yīng)prompt方法,突破了零樣本學(xué)習(xí)的瓶頸

今天要給大家介紹一篇Google的研究,解決了大語(yǔ)言模型(LLMs)在零樣本學(xué)習(xí)方面的困境。相比于少樣本學(xué)習(xí),LLMs在零樣本學(xué)習(xí)上常常表現(xiàn)得比較弱,這主要是因?yàn)槿狈χ笇?dǎo)。而且,目前的研究對(duì)零樣本學(xué)習(xí)的改進(jìn)也不多,因?yàn)樵跊](méi)有真實(shí)標(biāo)簽的任務(wù)中設(shè)計(jì)prompt方法還比較困難。
為了解決這個(gè)問(wèn)題,這篇研究提出了一種Universal Self-adaptive Prompting (USP)方法,對(duì)LLMs的零樣本學(xué)習(xí)進(jìn)行了優(yōu)化,同時(shí)也適用于少樣本學(xué)習(xí)任務(wù)。USP只需要少量未標(biāo)記的數(shù)據(jù),就能大幅提升LLMs在20多個(gè)自然語(yǔ)言理解和生成任務(wù)上的表現(xiàn)。實(shí)際上,它的結(jié)果比起少樣本基線方法甚至更好!
接下來(lái)就讓我們一起揭開USP方法的神秘面紗,看看它是如何做到這一切的吧!

論文:Universal Self-adaptive Prompting
地址:https://arxiv.org/pdf/2305.14926.pdf
前言
在介紹USP方法之前,讓我們先了解一下三種主流方法,分別是:Chain of Thought (CoT)、Self-Consistency (SC)和Consistency-based Self-adaptive Prompting (COSP)。這些方法是目前LLMs推理研究的主要方向,而COSP方法也是這篇研究的主要靈感來(lái)源。
首先,CoT方法將一個(gè)具體的推理問(wèn)題拆分成多個(gè)步驟,并將每個(gè)步驟的解釋信息輸入LLMs,從而得出最終的答案。這種方法已經(jīng)被證明可以解決具有較大推理難度的問(wèn)題,并且當(dāng)訓(xùn)練數(shù)據(jù)足夠時(shí),大模型會(huì)表現(xiàn)出出色的推理能力。很快,SC方法應(yīng)運(yùn)而生,對(duì)CoT方法進(jìn)行了改進(jìn)。SC方法認(rèn)為,通過(guò)對(duì)多個(gè)CoT推理路徑進(jìn)行采樣,并將它們的結(jié)果進(jìn)行投票,選擇一致性最高的輸出作為最終答案,可以進(jìn)一步提高LLMs的推理準(zhǔn)確性。
而COSP方法采用了雙階段策略,以進(jìn)一步增強(qiáng)LLMs的零樣本學(xué)習(xí)能力。在第一階段,COSP類似于SC,采用多路徑解碼進(jìn)行零樣本推理。它對(duì)同一查詢?cè)诓煌獯a路徑上進(jìn)行預(yù)測(cè),并計(jì)算出歸一化熵,用于量化模型在不同解碼路徑下的自信程度和預(yù)測(cè)之間的差異。基于熵值(以及其他指標(biāo)如多樣性和重復(fù)性),COSP對(duì)第一階段的輸出進(jìn)行排名,并選擇自信的輸出作為偽演示數(shù)據(jù)。在第二階段,COSP再次將這些偽演示數(shù)據(jù)與查詢結(jié)合,以類似于少樣本推理的方式進(jìn)行處理。最終的預(yù)測(cè)結(jié)果是通過(guò)兩個(gè)階段的輸出進(jìn)行多數(shù)投票得出的。
這些方法為L(zhǎng)LMs的推理能力帶來(lái)了顯著提升。然而,它們對(duì)于不同類型的任務(wù)可能存在一些局限性和挑戰(zhàn)。比如,針對(duì)一些分類NLP問(wèn)題,模型的邏輯回歸結(jié)果對(duì)于不確定性的量化很有用,但在COSP的設(shè)計(jì)中卻忽視了這一信息。此外,對(duì)于那些涉及創(chuàng)造性和生成性任務(wù)的任務(wù),多數(shù)投票的概念可能并不存在,因?yàn)橛泻芏嗪侠淼慕鉀Q方案存在。
因此,這篇研究的目標(biāo)是提出一種通用的、適用于各種任務(wù)的方法,而不僅僅局限于COSP所考慮的狹窄領(lǐng)域。然而,要實(shí)現(xiàn)這個(gè)目標(biāo)并不容易,因?yàn)橥ㄓ玫奶崾静呗孕枰m應(yīng)眾多且差異巨大的任務(wù),這些任務(wù)在目標(biāo)、提示、評(píng)估以及置信度/不確定性量化方面都存在顯著的差異。
接下來(lái),我們將詳細(xì)介紹Universal Self-adaptive Prompting(USP)方法,看看它是如何解決這些挑戰(zhàn)的!
USP方法
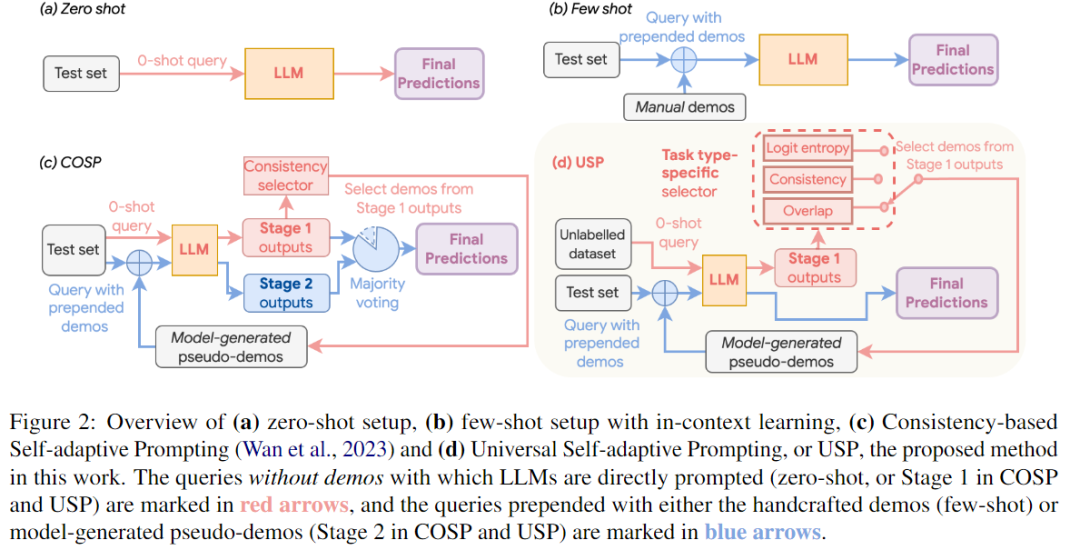
如上圖所示,USP總體上與COSP方法有一些相似之處:同樣采用兩階段的過(guò)程。在第一階段,LLMs以零樣本的方式進(jìn)行提示,生成一組候選回答,然后從中選擇一些模型生成的偽演示數(shù)據(jù)。在第二階段,這些偽演示數(shù)據(jù)以少樣本的方式添加到測(cè)試查詢之前,再次提示LLMs以獲得最終的預(yù)測(cè)結(jié)果。
然而,USP引入了幾個(gè)關(guān)鍵的設(shè)計(jì)決策,使其與COSP有所區(qū)別,有效地提高了其泛化能力:
任務(wù)特定的偽演示數(shù)據(jù)選擇器:在USP中,從零樣本輸出中選擇適合的查詢-回答對(duì)是至關(guān)重要的,這就是偽演示數(shù)據(jù)選擇器。COSP使用基于一致性的選擇器,只適用于一部分特定任務(wù),而USP則設(shè)計(jì)了一個(gè)選擇器,針對(duì)不同任務(wù),選擇不同的偽演示數(shù)據(jù)集,增強(qiáng)了其靈活性。
測(cè)試集和生成偽演示數(shù)據(jù)集的分離:與COSP默認(rèn)使用完整的測(cè)試集T在第一階段生成偽演示數(shù)據(jù)不同,USP需要一個(gè)通用的無(wú)標(biāo)簽數(shù)據(jù)集D。該數(shù)據(jù)集可以是完整的測(cè)試集T其中的一個(gè)子集,或者是一個(gè)不同的無(wú)標(biāo)簽集合。D的唯一目的是生成偽演示數(shù)據(jù),即使事先不知道完整的測(cè)試集,或者只有少量無(wú)標(biāo)簽的查詢可用。
減少對(duì)多數(shù)投票的依賴:雖然多數(shù)投票對(duì)于COSP至關(guān)重要(如圖中c所示),但它計(jì)算上較為昂貴,并且在多數(shù)本身無(wú)法明確定義的情況下不適用。相比之下,USP默認(rèn)在第二階段只進(jìn)行一次解碼,使用貪婪解碼(即temperature=0),將最大似然估計(jì)(MLE)的輸出作為最終預(yù)測(cè)結(jié)果。USP仍然支持對(duì)多次解碼進(jìn)行多數(shù)投票,以進(jìn)一步提高性能,但不再依賴這種方式來(lái)運(yùn)行。
任務(wù)特定的偽演示數(shù)據(jù)選擇器
選擇器的目標(biāo)是為了構(gòu)建候選偽演示數(shù)據(jù)集P(通過(guò)將數(shù)據(jù)集查詢和LLMs的零樣本預(yù)測(cè)連接而成),并從中選擇一些偽演示數(shù)據(jù)S來(lái)添加到測(cè)試查詢中。作者使用一個(gè)函數(shù)F來(lái)對(duì)每個(gè)候選偽演示數(shù)據(jù)進(jìn)行評(píng)分。首先,找到在P中使得F最大的偽演示數(shù)據(jù)作為第一個(gè)被選中的偽演示數(shù)據(jù)。對(duì)于接下來(lái)的偽演示數(shù)據(jù),作者使用一個(gè)帶有多樣性促進(jìn)項(xiàng)的F來(lái)選擇,同時(shí)懲罰那些與已選中的偽演示數(shù)據(jù)過(guò)于相似的候選項(xiàng)。
作者設(shè)計(jì)F函數(shù)的目的是根據(jù)任務(wù)的特性,將可能的任務(wù)分為三種通用類型(如下表所示),并對(duì)每種類型設(shè)計(jì)不同的評(píng)分函數(shù)。這樣做可以實(shí)現(xiàn)通用提示,在不同的任務(wù)上取得良好的效果。在設(shè)計(jì)F函數(shù)時(shí),作者考慮了可能的響應(yīng)數(shù)量和正確響應(yīng)的數(shù)量,并使用了一些技巧來(lái)確保評(píng)分的準(zhǔn)確性和可比性。
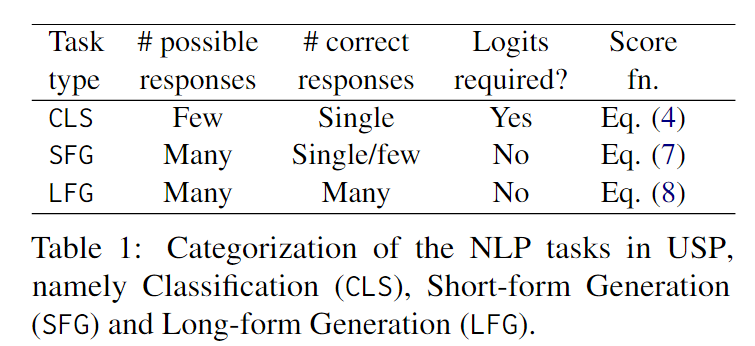
下面我們?cè)敿?xì)介紹一下這三種任務(wù)的劃分標(biāo)準(zhǔn)及選擇方法的差異。
針對(duì)分類(CLS)問(wèn)題,LLMs需要從幾個(gè)可能選項(xiàng)中選擇一個(gè)正確答案。這種情況下,標(biāo)簽空間很小,模型的邏輯回歸結(jié)果對(duì)于不確定性的量化很有用。我們不需要使用SC方法來(lái)估計(jì)預(yù)測(cè)的置信度。對(duì)于偽演示數(shù)據(jù)集,我們只需查詢LLM一次,并使用類別的負(fù)熵作為CLS情況下評(píng)分函數(shù)F的度量指標(biāo)。
Short-form generation(SFG)問(wèn)題是指這樣一類生成問(wèn)題:通常有很多可能的回答,但只有一個(gè)到幾個(gè)是正確的短回答。例如問(wèn)答任務(wù),其中可能的回答涵蓋整個(gè)詞匯表V。與CLS情況不同,我們假設(shè)只能訪問(wèn)模型的輸出,而沒(méi)有對(duì)數(shù)概率分布。這種情況包括了COSP中的問(wèn)題(例如COSP中考慮的算術(shù)推理問(wèn)題),我們可以使用歸一化熵來(lái)衡量模型的置信度,不過(guò)對(duì)于非CoT提示的任務(wù),我們跳過(guò)了生成理由的步驟,直接詢問(wèn)答案。
最后一類是Long-form generation(LFG)問(wèn)題,通常需要生成較長(zhǎng)的回答,并有許多合理的可能回答,典型的例子包括總結(jié)和翻譯。在這種情況下,如果對(duì)同一個(gè)查詢進(jìn)行m次溫度采樣解碼,即使對(duì)于置信的預(yù)測(cè),生成的文本也不可能完全相同,這是因?yàn)樯傻奈谋鹃L(zhǎng)度較長(zhǎng)。為了衡量這種情況下的置信度,我們首先按照SFG問(wèn)題的設(shè)置,對(duì)每個(gè)回答進(jìn)行m次溫度采樣查詢,得到m個(gè)預(yù)測(cè)結(jié)果。隨后,我們計(jì)算所有m個(gè)響應(yīng)對(duì)之間的平均ROUGE分?jǐn)?shù)。注意我們也可以采用其他指標(biāo)例如如pairwise BLEU或句子的余弦相似度。我們使用FLFG來(lái)對(duì)D中的查詢進(jìn)行置信度排序,并確定要在S中使用哪些查詢。對(duì)于偽演示的響應(yīng)部分,我們?cè)俅螌?duì)LLM進(jìn)行一次解碼,使用argmax或貪婪解碼,以獲得所選查詢上的MLE預(yù)測(cè)結(jié)果。然后將這些預(yù)測(cè)結(jié)果與查詢連接起來(lái)構(gòu)建S。最后,鑒于零樣本文本生成完全由提示驅(qū)動(dòng),我們觀察到LLM有時(shí)會(huì)生成極具自信的文本補(bǔ)全,而不是實(shí)際完成指定的任務(wù),選擇這些輸出作為偽演示會(huì)嚴(yán)重降低性能。考慮到這些輸出通常具有異常高的平均ROUGE得分,我們采用了一種簡(jiǎn)單有效的異常值過(guò)濾方法,即移除得分大于上四分位數(shù)加1.5倍四分位距(IQR)的查詢。這是一種經(jīng)典的用于定義異常值的方法。
實(shí)驗(yàn)設(shè)置
作者在PaLM-540B和PaLM-62B上進(jìn)行了實(shí)驗(yàn),并考慮了各種常見的自然語(yǔ)言處理任務(wù):對(duì)于CLS任務(wù),包括常識(shí)推理、閱讀理解、填空完成、自然語(yǔ)言推理等;對(duì)于SFG任務(wù),包括開放域問(wèn)答、閱讀理解問(wèn)答和詞語(yǔ)預(yù)測(cè);對(duì)于LFG任務(wù),包括摘要任務(wù)。作者沒(méi)有考慮CoT推理任務(wù),因?yàn)橄惹暗难芯恳呀?jīng)證明了COSP方法在這些任務(wù)上的有效性。
作者將USP與四個(gè)baseline進(jìn)行比較,分別是:zero-shot、AutoCoT、Random demo(按照USP的步驟進(jìn)行操作,但是在選擇偽演示時(shí)不使用評(píng)分函數(shù),而是從P中隨機(jī)選擇K個(gè)偽演示)、5-shot(few-shot, k=5)。為了公平比較,AutoCoT、Random demo和USP都會(huì)為每個(gè)樣本生成5個(gè)偽演示,從每個(gè)任務(wù)中隨機(jī)選擇64個(gè)未標(biāo)記的測(cè)試查詢。
結(jié)果分析
下面3個(gè)表分別展示了CLS、SFG和LFG任務(wù)上的實(shí)驗(yàn)結(jié)果。
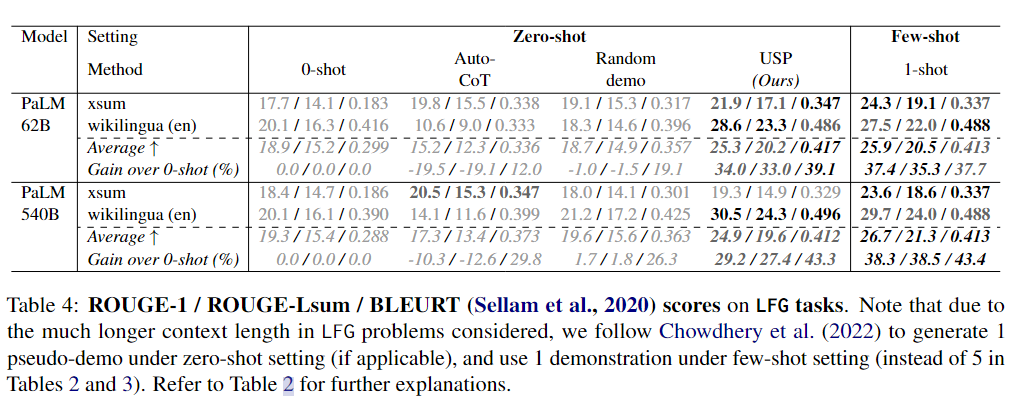
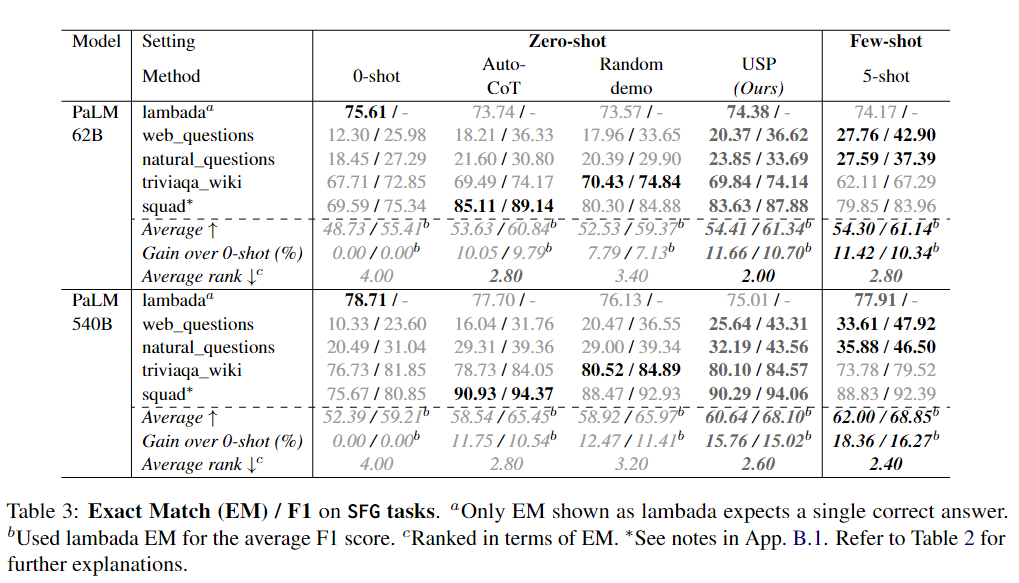
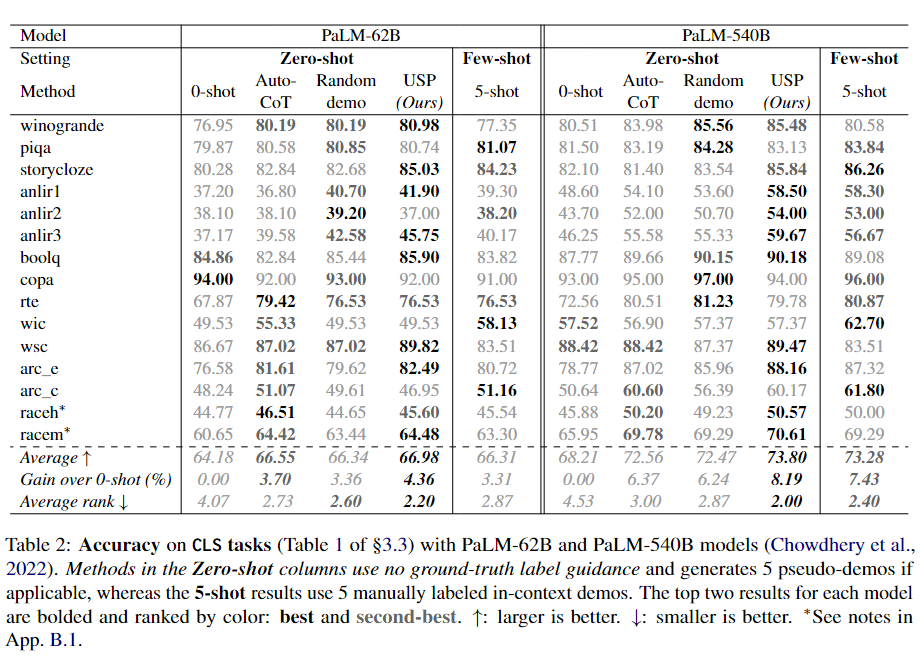
可以看到,在CLS、SFG和LFG任務(wù)中,USP顯著改善了標(biāo)準(zhǔn)的zero-shot性能,優(yōu)于其他zero-shot提示方法,并且在許多情況下接近甚至優(yōu)于標(biāo)準(zhǔn)的few-shot提示方法,而這才僅使用了每個(gè)任務(wù)64個(gè)未標(biāo)記樣本。
無(wú)論是在不同的數(shù)據(jù)集還是不同的模型上,USP在SFG和LFG任務(wù)上的改進(jìn)幅度比在CLS任務(wù)上要大,而在PaLM-540B上的改進(jìn)幅度也比PaLM-62B更大。作者推測(cè)前一觀察結(jié)果的原因是在生成任務(wù)中,LLMs更需要來(lái)自示例的指導(dǎo),因?yàn)檫@些任務(wù)涉及到無(wú)限的動(dòng)作選擇,而在CLS任務(wù)中,LLM只需要從幾個(gè)選項(xiàng)中選擇一個(gè)回答。至于后一觀察結(jié)果,作者認(rèn)為較大的模型具有更強(qiáng)的能力從示例中學(xué)習(xí),能夠更好地利用更準(zhǔn)確/更好的示例(5-shot結(jié)果在PaLM-540B中更強(qiáng)的事實(shí)也支持這一觀點(diǎn))。在這種情況下,USP生成的更準(zhǔn)確/更高質(zhì)量的偽示例導(dǎo)致了對(duì)基線方法的更大優(yōu)勢(shì),而基線方法的偽示例質(zhì)量?jī)H取決于模型的平均表現(xiàn)。
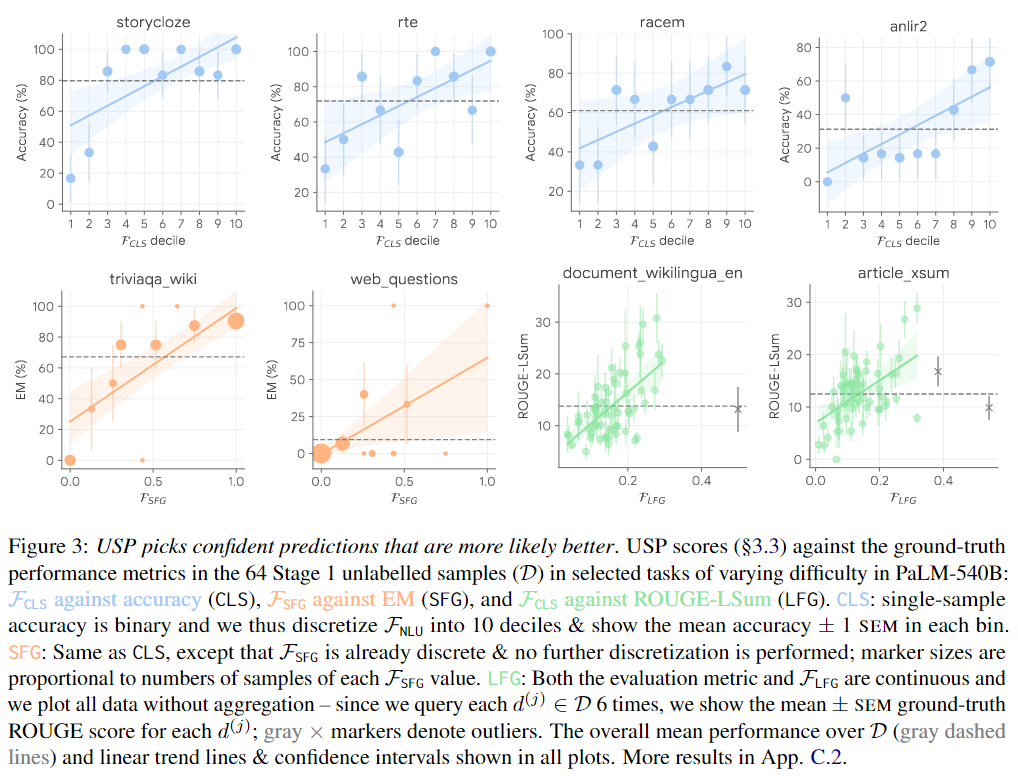
為了分析偽演示選擇器如何選擇高質(zhì)量的偽演示,作者分析了所有任務(wù)的未標(biāo)記數(shù)據(jù)集D中查詢的USP得分與ground-truth性能(準(zhǔn)確性、EM或ROUGE,取決于任務(wù)類型)之間的關(guān)系。下圖展示了一些代表性結(jié)果,在各種任務(wù)類型和不同難度的任務(wù)中(如圖中由灰色虛線標(biāo)記的平均性能),USP得分通常與ground-truth性能呈良好的相關(guān)性。最近的研究結(jié)果表明,更大的LLMs確實(shí)通過(guò)在上下文中學(xué)習(xí)信息(而不僅僅是遵循提示格式)并從正確示例中受益,這與USP的結(jié)果一致。
總結(jié)
本研究提出了USP方法,它是一種專為零樣本學(xué)習(xí)而設(shè)計(jì)的自適應(yīng)prompt方法,適用于各種自然語(yǔ)言理解和生成任務(wù)。通過(guò)精心選擇零樣本模型生成的輸出作為示例進(jìn)行上下文學(xué)習(xí),取得了顯著的改進(jìn)效果。在本研究中,作者們展示了USP在兩個(gè)LLM模型上超過(guò)標(biāo)準(zhǔn)零樣本提示和其他基線方法的優(yōu)勢(shì)。
未來(lái)的改進(jìn)空間也很大。首先,目前的工作主要集中在上下文演示方面,還沒(méi)有嘗試優(yōu)化其他提示組件。進(jìn)一步的研究可以將USP與自動(dòng)提示設(shè)計(jì)相結(jié)合,實(shí)現(xiàn)更靈活的提示方式。其次,隨著LLM能力的不斷提升,我們可以將USP的思想應(yīng)用于更多的創(chuàng)新設(shè)置中,例如規(guī)劃任務(wù)以及多模態(tài)問(wèn)題領(lǐng)域的拓展。
審核編輯 :李倩
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10780 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25427 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
292瀏覽量
13653
原文標(biāo)題:一個(gè)通用的自適應(yīng)prompt方法,突破了零樣本學(xué)習(xí)的瓶頸
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
模糊自適應(yīng)PID控制方法
什么是自適應(yīng)算術(shù)編碼?
基于神經(jīng)網(wǎng)絡(luò)自適應(yīng)諧波電流抑制方法
一種超聲測(cè)距的魯棒自適應(yīng)建模方法
基于自適應(yīng)圖像分類方法
基于模型的自適應(yīng)方法綜述
基于直推判別字典學(xué)習(xí)的零樣本分類方法
分層學(xué)習(xí)的自適應(yīng)動(dòng)態(tài)規(guī)劃
模糊時(shí)序自適應(yīng)預(yù)測(cè)方法
區(qū)塊鏈將成為自適應(yīng)學(xué)習(xí)的催化劑
融合零樣本學(xué)習(xí)和小樣本學(xué)習(xí)的弱監(jiān)督學(xué)習(xí)方法綜述

基于深度學(xué)習(xí)的零樣本SAR圖像目標(biāo)識(shí)別
形狀感知零樣本語(yǔ)義分割
什么是零樣本學(xué)習(xí)?為什么要搞零樣本學(xué)習(xí)?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論