 電子發(fā)燒友App
電子發(fā)燒友App


融合零樣本學(xué)習(xí)和小樣本學(xué)習(xí)的弱監(jiān)督學(xué)習(xí)方法綜述
來(lái)源:《系統(tǒng)工程與電子技術(shù)》,作者潘崇煜等
摘 要:?深度學(xué)習(xí)模型嚴(yán)重依賴于大量人工標(biāo)注的數(shù)據(jù),使得其在數(shù)據(jù)缺乏的特殊領(lǐng)域內(nèi)應(yīng)用嚴(yán)重受限。面對(duì)數(shù)據(jù)缺乏等現(xiàn)實(shí)挑戰(zhàn),很多學(xué)者針對(duì)數(shù)據(jù)依賴小的弱監(jiān)督學(xué)習(xí)方法開展研究,出現(xiàn)了小樣本學(xué)習(xí)、零樣本學(xué)習(xí)等典型研究方向。對(duì)此,本文主要介紹了弱監(jiān)督學(xué)習(xí)方法條件下的小樣本學(xué)習(xí)和零樣本學(xué)習(xí),包括問(wèn)題定義、當(dāng)前主流方法以及實(shí)驗(yàn)設(shè)計(jì)方案,并對(duì)典型模型的分類性能進(jìn)行對(duì)比。然后,給出零-小樣本學(xué)習(xí)的問(wèn)題描述,總結(jié)研究現(xiàn)狀和實(shí)驗(yàn)設(shè)計(jì),并對(duì)比典型方法的性能。最后,基于當(dāng)前研究中出現(xiàn)的問(wèn)題對(duì)未來(lái)研究方向進(jìn)行展望,包括多種弱監(jiān)督學(xué)習(xí)方法的融合與理論基礎(chǔ)的探究,以及在其他領(lǐng)域的應(yīng)用。
關(guān)鍵詞:?弱監(jiān)督學(xué)習(xí); 小樣本學(xué)習(xí); 零樣本學(xué)習(xí); 零-小樣本學(xué)習(xí)
0 引 言
近年來(lái),深度學(xué)習(xí)模型在諸多領(lǐng)域取得了引人矚目的成就,如圖像分類、語(yǔ)音識(shí)別、棋類對(duì)弈等。然而,包括深度學(xué)習(xí)在內(nèi),以大數(shù)據(jù)為基礎(chǔ)的傳統(tǒng)監(jiān)督學(xué)習(xí)模型嚴(yán)重依賴于大量人工標(biāo)注的高質(zhì)量標(biāo)簽數(shù)據(jù),在很多領(lǐng)域內(nèi),由于數(shù)據(jù)缺乏,使得這些模型很難取得應(yīng)有成效。針對(duì)數(shù)據(jù)缺乏的現(xiàn)實(shí)情況,當(dāng)前很多研究[1-2]關(guān)注數(shù)據(jù)依賴性小的弱監(jiān)督學(xué)習(xí)方法,如小樣本學(xué)習(xí)、零樣本學(xué)習(xí)等。
小樣本學(xué)習(xí)試圖在有限樣本條件下實(shí)現(xiàn)對(duì)新類別或新概念的有效認(rèn)知。通過(guò)度量學(xué)習(xí)、樣本生成等途徑,已有一些方法在少量支持樣本情況下實(shí)現(xiàn)了新概念識(shí)別。盡管取得了一定成效,但每個(gè)新類別中的幾個(gè)支持樣本仍然難以準(zhǔn)確表征整個(gè)類別的特征分布,這使得小樣本學(xué)習(xí)任務(wù)仍然充滿了挑戰(zhàn)性。
相對(duì)于小樣本學(xué)習(xí),零樣本學(xué)習(xí)試圖識(shí)別訓(xùn)練過(guò)程中從未見過(guò)的新類別概念。這需要額外的語(yǔ)義特征輔助信息,如訓(xùn)練集和待分類的測(cè)試集類別語(yǔ)義特征描述向量,借此實(shí)現(xiàn)從訓(xùn)練集向測(cè)試集類別的知識(shí)遷移。由于其內(nèi)在固有的域適應(yīng)及樞紐度問(wèn)題[3],零樣本學(xué)習(xí)也面臨著識(shí)別精度不高等問(wèn)題。
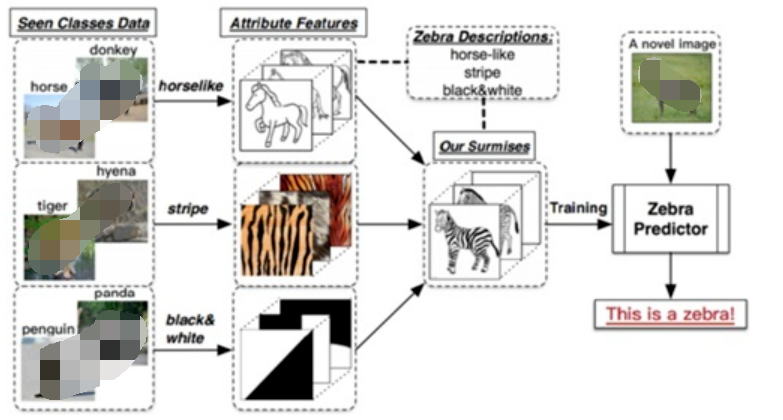
基于零樣本學(xué)習(xí)和小樣本學(xué)習(xí)面臨諸多的問(wèn)題,正如文獻(xiàn)[3]指出,在當(dāng)前小樣本學(xué)習(xí)中融合額外的語(yǔ)義文本信息是一個(gè)重要的研究方向,即零-小樣本學(xué)習(xí)。零-小樣本學(xué)習(xí)既包含了小樣本學(xué)習(xí)中若干支持樣本特征,同時(shí)考慮了語(yǔ)義特征輔助信息,可以有效提高弱監(jiān)督機(jī)器學(xué)習(xí)的識(shí)別性能,同時(shí)也更加符合人類對(duì)新概念、新事物舉一反三、多方融合的認(rèn)知原理。
本文從小樣本學(xué)習(xí)和零樣本學(xué)習(xí)入手,重點(diǎn)開展了問(wèn)題描述、典型方法介紹、實(shí)驗(yàn)設(shè)計(jì)以及性能對(duì)比。基于小樣本學(xué)習(xí)和零樣本學(xué)習(xí)之間的信息互補(bǔ),本文介紹了零-小樣本學(xué)習(xí)這一新問(wèn)題。在此基礎(chǔ)上,本文指出了多種弱監(jiān)督學(xué)習(xí)方法融合發(fā)展、基礎(chǔ)理論探索以及多領(lǐng)域上擴(kuò)展等重要發(fā)展方向。
1 小樣本學(xué)習(xí)
小樣本學(xué)習(xí)旨在通過(guò)有限樣本對(duì)新的類別或者概念進(jìn)行識(shí)別,本節(jié)首先給出明確問(wèn)題描述,之后回顧目前主流方法和模型,最后介紹具體的實(shí)驗(yàn)設(shè)計(jì)和部分基準(zhǔn)結(jié)果。
1.1 問(wèn)題描述
給定由Ns個(gè)訓(xùn)練樣本構(gòu)成的訓(xùn)練集
其中
是第i個(gè)樣本圖像;
是其類別標(biāo)簽,Cs是訓(xùn)練集標(biāo)簽集合;Ds通常由大量訓(xùn)練樣本構(gòu)成。
在測(cè)試階段,對(duì)于新的類別Ct?(測(cè)試類別與訓(xùn)練集類別不同,即Cs∩?Ct=?),每個(gè)類別給定幾個(gè)支持樣本
小樣本識(shí)別的任務(wù)是對(duì)新的測(cè)試樣本圖像
進(jìn)行識(shí)別,確定其對(duì)應(yīng)的類別標(biāo)簽
1.2 當(dāng)前主流模型
小樣本學(xué)習(xí)領(lǐng)域目前已經(jīng)出現(xiàn)很多方法和模型,這些方法可以概括為基于度量的方法、基于優(yōu)化的方法、基于生成式模型的方法、基于圖神經(jīng)網(wǎng)絡(luò)的方法以及基于記憶單元的方法。表1對(duì)這幾種主流方法進(jìn)行了簡(jiǎn)要列舉和分析。
表1 不同的小樣本學(xué)習(xí)方法對(duì)比分析
Table 1 Comparision analysis of the different methods for few-shot learning
(1) 基于度量的方法
基于度量的方法核心思想是學(xué)習(xí)樣本之間的相似度。孿生網(wǎng)絡(luò)[4]是最早的基于度量學(xué)習(xí)的小樣本學(xué)習(xí)模型,該模型通過(guò)卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network, CNN)直接學(xué)習(xí)兩個(gè)樣本之間的相似度。之后,文獻(xiàn)[5]提出了基于元學(xué)習(xí)的匹配網(wǎng)絡(luò),元學(xué)習(xí)是一種訓(xùn)練策略,具體算法流程如表2所示。
表2 元學(xué)習(xí)訓(xùn)練范式
Table 2 Training paradigm of the meta-learning
匹配網(wǎng)絡(luò)利用了雙向長(zhǎng)短時(shí)記憶(long short-term memory, LSTM)網(wǎng)絡(luò)模型以及注意力機(jī)制來(lái)學(xué)習(xí)樣本之間的度量函數(shù)。原型網(wǎng)絡(luò)[6]也是一種典型的度量學(xué)習(xí)模型,將圖像特征映射到一度量空間中,在該空間中,將同類多個(gè)樣本均值作為代表該類別的原型樣本點(diǎn),對(duì)于待識(shí)別的樣本,通過(guò)在多類的原型樣本點(diǎn)之間進(jìn)行最近鄰距離實(shí)現(xiàn)分類,該方法直接用歐氏距離作為距離度量,僅學(xué)習(xí)圖像編碼網(wǎng)絡(luò)。值得一提的是,文獻(xiàn)[7-8]提出了包含圖像編碼模塊及關(guān)系度量模塊的關(guān)系網(wǎng)絡(luò),原始圖像經(jīng)過(guò)CNN編碼模塊形成圖像特征向量,之后待測(cè)試樣本與支持樣本連接形成圖像對(duì),經(jīng)過(guò)關(guān)系網(wǎng)絡(luò)度量每一圖像對(duì)的相似度。如圖1所示[7],該模型同時(shí)學(xué)習(xí)編碼網(wǎng)絡(luò)和度量函數(shù),與以往使用某一固定度量函數(shù)不同,該模型通過(guò)訓(xùn)練學(xué)習(xí)了一個(gè)非線性的度量函數(shù),提高了模型的適應(yīng)性。
基于度量的小樣本學(xué)習(xí)方法模型通常較為直觀,易于理解,具備較強(qiáng)的可解釋性,但往往需要大量訓(xùn)練數(shù)據(jù),對(duì)于訓(xùn)練集樣本數(shù)量要求較高,且最終性能對(duì)模型結(jié)構(gòu)敏感度較高,模型細(xì)節(jié)設(shè)計(jì)對(duì)性能影響較大。
(2) 基于優(yōu)化的方法
基于優(yōu)化的方法依據(jù)元學(xué)習(xí)的思想,旨在學(xué)習(xí)一組元分類器,這些分類器可以在新的任務(wù)上通過(guò)參數(shù)微調(diào)實(shí)現(xiàn)較好的分類性能。最典型的優(yōu)化方法是模型無(wú)關(guān)元學(xué)習(xí)(model-agnostic meta-learning, MAML)算法[9],如圖2所示,該方法通過(guò)大量訓(xùn)練數(shù)據(jù)學(xué)習(xí)到一組好的初始化參數(shù),在新任務(wù)測(cè)試時(shí),僅通過(guò)很少的參數(shù)迭代步數(shù),模型即可自適應(yīng)到該新任務(wù)上。基于元學(xué)習(xí)思想,之后又出現(xiàn)了很多基于優(yōu)化的小樣本學(xué)習(xí)方法,包括meta network[10]、meta-SGD[11]、meta-learner LSTM[12]以及其他變種[13]。
圖1 基于度量的小樣本學(xué)習(xí)模型-關(guān)系網(wǎng)絡(luò)
Fig.1 Metric based model for few-shot learning-relation network
圖2 基于優(yōu)化的小樣本學(xué)習(xí)方法-MAML算法
Fig.2 Optimization based method for few-shot learning-MAML algorithm
基于優(yōu)化的小樣本學(xué)習(xí)模型具備快速適應(yīng)新任務(wù)的能力,但卻存在明顯的缺陷,即模型只能在固定任務(wù)上預(yù)訓(xùn)練和遷移,如在5-way 1-shot分類任務(wù)上訓(xùn)練的模型只能適應(yīng)5-way 1-shot的任務(wù),缺乏靈活性。
(3) 基于生成式模型的方法
基于大量訓(xùn)練數(shù)據(jù)以及少量的支持樣本,生成式模型期望生成大量新類別數(shù)據(jù)樣本,進(jìn)而將小樣本學(xué)習(xí)轉(zhuǎn)化為傳統(tǒng)的監(jiān)督學(xué)習(xí)。生成式模型通常由自動(dòng)編碼器以及其他學(xué)習(xí)模型構(gòu)成[14]。典型的生成式模型如圖3所示[15]。
圖3 基于生成式模型的小樣本學(xué)習(xí)方法
Fig.3 Generative model based method for few-shot learning
通過(guò)類比訓(xùn)練集中多個(gè)樣本之間的特征差異,在少量支持樣本的基礎(chǔ)上,生成器試圖在新類別上生成更多樣本。隨后,在生成樣本基礎(chǔ)上訓(xùn)練常規(guī)分類器進(jìn)行新類別識(shí)別。近年來(lái),隨著生成對(duì)抗網(wǎng)絡(luò)(generative adversarial network, GAN)[16]的出現(xiàn),基于GAN的小樣本學(xué)習(xí)模型[17]也層出不窮。
基于生成式模型的方法通常分為樣本生成和分類器訓(xùn)練兩部分分步進(jìn)行,易于追溯,但卻存在生成樣本可信度不高、模型訓(xùn)練困難等問(wèn)題。
(4) 基于圖神經(jīng)網(wǎng)絡(luò)的方法
在圖神經(jīng)網(wǎng)絡(luò)模型[18]中,以單個(gè)樣本作為節(jié)點(diǎn)(Node),以樣本間相似度作為邊(Edge),通過(guò)神經(jīng)網(wǎng)絡(luò)模型迭代計(jì)算圖模型的連接矩陣。如圖4所示,以所有樣本的特征向量作為節(jié)點(diǎn)狀態(tài),以樣本間關(guān)系為邊,迭代更新節(jié)點(diǎn)狀態(tài)向量和鄰接矩陣,最終推斷出待識(shí)別樣本與所有支持樣本的相似度[19]。
由于將每個(gè)樣本作為一個(gè)高維向量節(jié)點(diǎn)進(jìn)行動(dòng)態(tài)更新,基于圖神經(jīng)網(wǎng)絡(luò)的方法[19-20]在模型訓(xùn)練過(guò)程中會(huì)消耗大量?jī)?nèi)存空間,同時(shí)計(jì)算量會(huì)隨著樣本數(shù)量增加而激增。

圖4 基于圖神經(jīng)網(wǎng)絡(luò)的小樣本學(xué)習(xí)方法
Fig.4 Graph neural network based method for few-shot learning
(5) 基于記憶單元的方法
基于外掛的記憶單元模塊,一些方法試圖通過(guò)在學(xué)習(xí)過(guò)程中持續(xù)更新內(nèi)存狀態(tài)來(lái)實(shí)現(xiàn)小樣本學(xué)習(xí)甚至持續(xù)學(xué)習(xí)[21],典型方法包括記憶增強(qiáng)網(wǎng)絡(luò)(memory augmented neural network, MANN)[22]、記憶匹配網(wǎng)絡(luò)(memory matching network, MMN)[23]等。
基于記憶單元的小樣本學(xué)習(xí)方法模型,如圖5所示,可動(dòng)態(tài)更新,但需額外增加外置記憶單元,增大了內(nèi)存需求,同時(shí)也增加了如讀寫控制器等復(fù)雜模型組件[22]。
圖5 基于記憶單元的小樣本學(xué)習(xí)-MANN
Fig.5 Memory unit based method for few-shot learning-MANN
1.3 實(shí)驗(yàn)設(shè)計(jì)
(1) 數(shù)據(jù)集
當(dāng)前,小樣本學(xué)習(xí)的公共數(shù)據(jù)集主要是Omniglot以及miniImagenet。其中,Omniglot[24]是手寫字符符號(hào)數(shù)據(jù)集,包含50個(gè)大類,共1 623個(gè)類別符號(hào),每個(gè)類別只有20個(gè)樣本圖像。miniImagenet[5]是圖像領(lǐng)域公共數(shù)據(jù)集ImageNet的一部分,包含100個(gè)類別,每個(gè)類別包含600個(gè)圖像樣本,在小樣本學(xué)習(xí)中具體劃分為64類用于訓(xùn)練集,16類用于驗(yàn)證集,其余20類用于測(cè)試集。
(2) 實(shí)驗(yàn)設(shè)置
如表2所示,小樣本學(xué)習(xí)普遍采用元學(xué)習(xí)訓(xùn)練范式,在訓(xùn)練階段和測(cè)試階段構(gòu)建分類子任務(wù),稱為M-way?N-shot?Q-query分類子任務(wù),即每一個(gè)實(shí)驗(yàn)輪次中,對(duì)于M類分類類別,每一類別提供N個(gè)支持樣本,同時(shí)提供Q個(gè)測(cè)試樣本用于參數(shù)調(diào)整(訓(xùn)練階段)或準(zhǔn)確率評(píng)估(測(cè)試階段)。在模型訓(xùn)練階段,通過(guò)多個(gè)輪次迭代,實(shí)現(xiàn)模型參數(shù)的調(diào)整。在模型測(cè)試階段,采用多個(gè)輪次分類準(zhǔn)確率取平均值的方法,評(píng)估模型最終的分類準(zhǔn)確率。當(dāng)前研究通常在Omniglot數(shù)據(jù)集上采用5/20-way 1/5-shot的分類子任務(wù),在miniImagenet數(shù)據(jù)集上采用5-way 1/5-shot的分類子任務(wù)。
表3 幾種典型小樣本學(xué)習(xí)模型在miniImagenet數(shù)據(jù)集上的性能對(duì)比
Table 3?Performance evaluations of the several typical models for few-shot learning on miniImagenent data sets
(3) 典型方法性能對(duì)比
表3列出了小樣本學(xué)習(xí)領(lǐng)域當(dāng)前幾種典型模型在miniImagenet數(shù)據(jù)集上的識(shí)別準(zhǔn)確率對(duì)比。可以看出,大部分方法在5-way 1-shot分類識(shí)別中都取得了超過(guò)50%的準(zhǔn)確率,表明僅依靠少量標(biāo)簽樣本識(shí)別新類具有一定的實(shí)踐性。同時(shí),隨著支持樣本的增加(由1-shot增加為5-shot),識(shí)別率取得了明顯的提高,表明支持樣本數(shù)量對(duì)最終識(shí)別效果有決定性作用。最后,不同模型不僅設(shè)計(jì)思想及模型構(gòu)成不同,而且在圖像處理中最基本的特征提取器結(jié)構(gòu)也存在很大區(qū)別(如表3特征提取器所列),因此模型性能之間存在較大差異。
2 零樣本學(xué)習(xí)
零樣本學(xué)習(xí)[29-30]旨在通過(guò)文本描述信息對(duì)新的類別或者概念進(jìn)行識(shí)別,本節(jié)首先給出明確問(wèn)題描述,之后回顧目前主流方法和模型,最后介紹具體的實(shí)驗(yàn)設(shè)計(jì)和部分基準(zhǔn)結(jié)果。
2.1 問(wèn)題描述
給定由Ns個(gè)訓(xùn)練樣本構(gòu)成的訓(xùn)練集,
其中
是第i個(gè)樣本圖像,
是其類別標(biāo)簽,Cs是訓(xùn)練集標(biāo)簽集合。零樣學(xué)習(xí)的任務(wù)是對(duì)測(cè)試樣本
進(jìn)行識(shí)別,將其劃分到新的類別Ct中,即確定其對(duì)應(yīng)的類別標(biāo)簽
其中測(cè)試類別與訓(xùn)練集類別不同,即Cs∩Ct=?。除此之外,零樣本學(xué)習(xí)為所有類別提供了額外的文本信息作為特征描述,即為Cs和Ct中的每個(gè)類別
提供了一個(gè)類別特征描述向量
借助于通用的類別特征描述向量,零樣本學(xué)習(xí)期望實(shí)現(xiàn)從已知的訓(xùn)練樣本類別到新的測(cè)試樣本類別之間的知識(shí)遷移。在零樣本學(xué)習(xí)中,類別描述向量作為知識(shí)遷移的橋梁,通常是由人工標(biāo)注的屬性向量構(gòu)成,如形狀、顏色、尺寸、材質(zhì)等訓(xùn)練集和測(cè)試集類別通用屬性,也有一些研究使用文本理解領(lǐng)域成熟的詞向量作為特征描述向量[3]。
2.2 當(dāng)前主流模型
針對(duì)零樣本學(xué)習(xí)問(wèn)題,國(guó)內(nèi)外學(xué)者提出了很多方法,整體上可分為度量學(xué)習(xí)方法、相似度學(xué)習(xí)方法、基于流形結(jié)構(gòu)的方法以及基于生成式模型的方法。表4對(duì)這幾種主流方法進(jìn)行了簡(jiǎn)要列舉和分析。
表4 不同零樣本學(xué)習(xí)方法對(duì)比分析
Table 4 Comparisions of the different methods for zero-shot learning
(1) 度量學(xué)習(xí)方法
度量學(xué)習(xí)方法旨在找到一個(gè)度量空間,在該空間中樣本的圖像特征和其對(duì)應(yīng)的語(yǔ)義向量在某種度量下距離最小。最基本的方法是直接將語(yǔ)義向量空間作為度量空間[31-33],將圖像特征映射到語(yǔ)義向量空間,在該空間中進(jìn)行最近鄰分類,直接使用歐氏距離或者余弦距離作為度量函數(shù)。有研究表明[34],將圖像特征空間作為度量空間,能夠有效減輕零樣本學(xué)習(xí)中固有的域適應(yīng)以及樞紐度問(wèn)題[3]。在此基礎(chǔ)上,以圖像特征空間作為度量空間的深度嵌入模型(deep embedding model, DEM)[35-36]等模型被提出,如圖6所示[35],原始圖像經(jīng)過(guò)CNN網(wǎng)絡(luò)編碼到圖像特征空間,語(yǔ)義向量經(jīng)多層感知機(jī)(multi-layer perceptron, MLP)映射到同一特征空間,在該度量空間中基于最近鄰分類。除了圖像特征以及語(yǔ)義特征空間本身,一些方法探索了尋找隱空間作為度量空間,如EXEM[37]、隱性屬性字典(latent attribute dictionary, LAD)[38]學(xué)習(xí)、耦合字典學(xué)習(xí)(coupled dictionary learning, CDL)[39]、公共嵌入空間[40-41]以及共享特征相對(duì)屬性空間[42]。在這些方法中,除了度量空間不同,空間映射函數(shù)也各有不同,包括線性變換[31,38-39,43]以及非線性變換,如支持向量回歸(support vector regression, SVR)[37]以及神經(jīng)網(wǎng)絡(luò)模型[35]。度量學(xué)習(xí)方法中最重要的問(wèn)題是設(shè)計(jì)目標(biāo)(損失)函數(shù),關(guān)系到模型的整體性能。
圖6 基于度量的零樣本學(xué)習(xí)
Fig.6 Metric based zero-shot learning
基于度量學(xué)習(xí)的方法在某一特征空間中基于最近鄰規(guī)則進(jìn)行分類,模型直觀、易于理解,然而模型性能因度量空間選擇而變化較大,適用于訓(xùn)練集數(shù)量較大的情況。
(2) 兼容性學(xué)習(xí)方法
與學(xué)習(xí)空間映射函數(shù)不同,兼容性學(xué)習(xí)方法直接學(xué)習(xí)圖像空間和語(yǔ)義空間向量的相似度。最基本的方法是直接利用雙線性函數(shù)將圖像空間和語(yǔ)義空間向量轉(zhuǎn)換為相似度標(biāo)量,如極端零樣本學(xué)習(xí)采樣方法(embarrassingly sample approach to zero-shot learning, ESZSL)[44]、 深度圖像-嵌入語(yǔ)義(deep visual-semantic embedding, DeViSE)模型[45]、 結(jié)構(gòu)化聯(lián)合嵌入(structured joint embedding,SJE)[46]以及屬性標(biāo)簽嵌入(attribute label embedding, ALE)[47]。其他一些方法利用了非線性的函數(shù)轉(zhuǎn)換,如隱形嵌入(latent embedding, LatEm)[48]以及關(guān)系網(wǎng)絡(luò)[7]。
基于兼容性學(xué)習(xí)的方法模型如圖7所示[46],較為簡(jiǎn)單,計(jì)算量較小,但對(duì)訓(xùn)練集數(shù)據(jù)量要求較高。
圖7 基于兼容性的零樣本學(xué)習(xí)
Fig.7 Compatibility based zero-shot learning
(3) 基于流形結(jié)構(gòu)的方法
一些研究從流形學(xué)習(xí)[49]的角度出發(fā),探索語(yǔ)義空間與圖像特征空間的流形結(jié)構(gòu),企圖通過(guò)學(xué)習(xí)訓(xùn)練集中的流形結(jié)構(gòu),遷移到新的測(cè)試類別中去。如圖8所示,模型在語(yǔ)義空間中學(xué)習(xí)各個(gè)類別特征向量間的流形結(jié)構(gòu),基于流形學(xué)習(xí)思想,將該結(jié)構(gòu)遷移到視覺(jué)特征分類器模型空間中。典型方法包括跨模態(tài)遷移(cross-modal transfer, CMT)[50]、數(shù)據(jù)遺失問(wèn)題(missing data problem, MDP)[51]、語(yǔ)義嵌入凸組合(convex combination of semantic embeddings, CONSE)[52]、雙向隱形嵌入(bidirectional latent embedding, BiDiLEL)[53]、相關(guān)知識(shí)遷移(relational knowledge transfer, RKT)[54]、生成分類器(synthesized classifiers, SYNC)[49]以及局部敏感的流形保持方法[55]。
基于流形結(jié)構(gòu)的零樣本學(xué)習(xí)方法[49],如圖8所示,能夠考慮到類別間的關(guān)聯(lián)關(guān)系,但不同特征空間的流形結(jié)構(gòu)存在異構(gòu)性,通常難以遷移。
圖8 基于流形結(jié)構(gòu)的零樣本學(xué)習(xí)
Fig.8 Manifold structure based zero-shot learning
(4) 基于生成式模型的方法
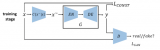
最近一些研究基于生成樣本的思想,借助于生成式網(wǎng)絡(luò),經(jīng)訓(xùn)練集訓(xùn)練,在新類別上生成圖像特征樣本甚至原始二維圖像,將零樣本學(xué)習(xí)轉(zhuǎn)化為監(jiān)督學(xué)習(xí)分類問(wèn)題加以解決。典型方法包括未知類別樣本生成(unseen visual data synthesis, UVDS)[56]、ZSL對(duì)抗生成式方法(generative adversarial approach for ZSL, GAZSL)[57]、特征生成網(wǎng)絡(luò)(feature generating networks, FGN)[58]、ZSL樣本生成方法(synthesized examples ZSL, SE-ZSL)[59]、保留語(yǔ)義的對(duì)抗式嵌入網(wǎng)絡(luò)(semantics-preserving adversarial embedding networks, SP-AEN)[60]等。
基于生成式模型的方法[61],如圖9所示。
圖9 基于生成式模型的零樣本學(xué)習(xí)
Fig.9 Generative model based zero-shot learning
該方法通常分為樣本生成和分類器訓(xùn)練兩部分。在樣本生成階段,基于訓(xùn)練樣本及其對(duì)應(yīng)的文本描述信息,在新類別文本描述向量條件下,生成新類別的圖像樣本。在分類器訓(xùn)練階段,基于生成的樣本訓(xùn)練分類器并對(duì)測(cè)試樣本進(jìn)行在線識(shí)別。基于生成式模型的方法分步進(jìn)行,易于追溯,但同樣存在生成樣本代表性不高、模型訓(xùn)練困難等問(wèn)題。
2.3 實(shí)驗(yàn)設(shè)計(jì)
(1) 數(shù)據(jù)集及實(shí)驗(yàn)設(shè)置
當(dāng)前零樣本學(xué)習(xí)研究中常用的數(shù)據(jù)集包括動(dòng)物屬性標(biāo)記(animals with attributes, AWA)[62]數(shù)據(jù)集、CUB(CUB-200-2011)[63]以及ImageNet 2010[64]等。表5詳細(xì)列出了這些數(shù)據(jù)集統(tǒng)計(jì)信息以及在零樣本學(xué)習(xí)中的固定測(cè)試集/訓(xùn)練集類別數(shù)劃分。
表5 零樣本學(xué)習(xí)常用數(shù)據(jù)集
Table 5 Data sets for zero-shot learning
關(guān)于類別描述特征向量,AWA和CUB數(shù)據(jù)集分別包含85維和312維的類別屬性描述向量(Attributes),對(duì)于ImageNet 2010大型數(shù)據(jù)集,當(dāng)前研究多采用大規(guī)模無(wú)標(biāo)簽文本訓(xùn)練詞向量(Word Embedding)的方式,為每個(gè)類別生成高維的詞向量表征[49]。
值得注意的是,在零樣本學(xué)習(xí)中,由于缺少大量標(biāo)簽數(shù)據(jù)訓(xùn)練圖像特征提取網(wǎng)絡(luò),當(dāng)前研究中,圖像特征通常采用預(yù)訓(xùn)練的CNN圖像特征,即調(diào)用在miniImageNet數(shù)據(jù)集上預(yù)訓(xùn)練的CNN模型,在訓(xùn)練集/測(cè)試集圖像上直接提取特征,常用的預(yù)訓(xùn)練模型包括GoogLeNet[65]以及VGGNet[66]等。
零樣本學(xué)習(xí)中,訓(xùn)練集和測(cè)試集類別不同,在訓(xùn)練集上訓(xùn)練模型,在測(cè)試集類別中進(jìn)行性能評(píng)估,通常采用分類任務(wù),以分類準(zhǔn)確率作為模型評(píng)估指標(biāo)。
(2) 典型方法性能對(duì)比
表6列出了零樣本學(xué)習(xí)領(lǐng)域當(dāng)前幾種典型模型的分類性能對(duì)比。可以看出,在僅有新類別語(yǔ)義特征描述的情況下,模型能夠?qū)崿F(xiàn)新概念識(shí)別分類,在AWA數(shù)據(jù)集10分類問(wèn)題上取得了高達(dá)約90%的準(zhǔn)確率,在CUB數(shù)據(jù)集50分類問(wèn)題上取得了高達(dá)60%的準(zhǔn)確率,甚至在ImageNet大型數(shù)據(jù)集200分類問(wèn)題上取得了超過(guò)60%的Top 5準(zhǔn)確率。與小樣本學(xué)習(xí)類似,不同方法不僅模型設(shè)計(jì)思想不同,而且底層圖像特征提取器結(jié)構(gòu)也有所不同,因此各方法之間存在較大性能差異。
表6 幾種典型零樣本學(xué)習(xí)模型的分類性能對(duì)比
Table 6 Classification performance comparisons of the several typical models for zero-shot learning
3 零-小樣本學(xué)習(xí)
與小樣本學(xué)習(xí)和零樣本學(xué)習(xí)類似,零-小樣本學(xué)習(xí)借助于通用的類別特征描述,在少量支持樣本條件下實(shí)現(xiàn)對(duì)新類別或概念的識(shí)別,本節(jié)首先給出明確問(wèn)題描述,其次介紹當(dāng)前的研究現(xiàn)狀,最后介紹具體的實(shí)驗(yàn)設(shè)計(jì)和部分基準(zhǔn)結(jié)果。
3.1 問(wèn)題描述
給定由Ns個(gè)訓(xùn)練樣本構(gòu)成的訓(xùn)練集
其中,
是第i個(gè)樣本圖像,
是其類別標(biāo)簽,Cs是訓(xùn)練集標(biāo)簽集合,
是類別
對(duì)應(yīng)的類別特征描述向量。Ds通常由大量訓(xùn)練樣本構(gòu)成。
基于上述訓(xùn)練集,零-小樣本學(xué)習(xí)旨在分類識(shí)別新類別樣本。在測(cè)試階段,對(duì)于每一個(gè)新類別提供了少量支持樣本
且所有的新類別的特征描述向量是已知的。對(duì)于給定的測(cè)試樣本
零-小樣本學(xué)習(xí)的任務(wù)是識(shí)別其類別標(biāo)簽
3.2 研究現(xiàn)狀
為了更好地識(shí)別訓(xùn)練過(guò)程中未見過(guò)的新類別,一些學(xué)者在小樣本學(xué)習(xí)的基礎(chǔ)上增加類別屬性特征描述向量,探索了文本信息輔助的小樣本學(xué)習(xí)問(wèn)題,即本文所述的零-小樣本學(xué)習(xí)。
文獻(xiàn)[47]最早提出融合零樣本學(xué)習(xí)和小樣本學(xué)習(xí)是提高機(jī)器智能的有效途徑。之后,零-小樣本學(xué)習(xí)問(wèn)題逐漸被關(guān)注[56],并且出現(xiàn)了初步的研究工作。其中,文獻(xiàn)[48]設(shè)計(jì)了多注意力網(wǎng)絡(luò),借助語(yǔ)義特征描述,利用圖像局部特征,研究了語(yǔ)義信息輔助的小樣本學(xué)習(xí)。基于生成式模型的思想,文獻(xiàn)[47]提出對(duì)偶三角網(wǎng)絡(luò),基于類別語(yǔ)義信息生成新的樣本特征;文獻(xiàn)[70]在變分自編碼器模型中增加多模態(tài)交叉配準(zhǔn)損失函數(shù),在新的隱特征空間中生成更多新樣本,提出跨模態(tài)分布式變分自編碼器(cross-modal and distribution aligned variational autoencoder, CADA-VAE), 實(shí)現(xiàn)了零-小樣本條件下的數(shù)據(jù)增強(qiáng)。盡管出現(xiàn)了很長(zhǎng)時(shí)間,但零-小樣本學(xué)習(xí)領(lǐng)域尚未被充分研究。以上部分工作仍然依賴于預(yù)訓(xùn)練的CNN圖像特征,在一些特定領(lǐng)域內(nèi),標(biāo)簽數(shù)據(jù)有限,難以開展預(yù)訓(xùn)練工作,這些方法的可行性較差。
值得一提的是,最近的研究工作[71]為零-小樣本學(xué)習(xí)提供了有益探索。自適應(yīng)模態(tài)混合機(jī)制(adaptive modality mixture mechanism, AM3)模型如圖10所示。
圖10 零-小樣本學(xué)習(xí)模型(AM3)
Fig.10 Model (AM3) for zero-to-few shot learning
包含圖像流和文本流兩條路徑,上部分表示圖像信息流,下部分表示文本信息流,通過(guò)可自適應(yīng)調(diào)整的權(quán)重因子加權(quán),形成最終的類別原型。該模型提出了多模態(tài)信息自適應(yīng)利用機(jī)制,可以在文本特征和圖像特征中自適應(yīng)調(diào)節(jié)權(quán)重因子,借助于跨模態(tài)信息來(lái)增強(qiáng)小樣本學(xué)習(xí)性能。
3.3 實(shí)驗(yàn)設(shè)計(jì)
(1) 數(shù)據(jù)集及實(shí)驗(yàn)設(shè)置
當(dāng)前零-小樣本學(xué)習(xí)仍處于初始探索階段,相關(guān)的研究十分有限。在零-小樣本學(xué)習(xí)中,除了若干新類別支持樣本外,還需要額外的類別語(yǔ)義特征描述向量作為輔助信息。當(dāng)前研究主要是在miniImageNet[6]以及tieredImageNet[72]數(shù)據(jù)集上展開,其類別語(yǔ)義信息是通過(guò)預(yù)訓(xùn)練詞向量提取得到的。
與小樣本學(xué)習(xí)類似,零-小樣本學(xué)習(xí)也采用表1所列的元學(xué)習(xí)訓(xùn)練范式。在訓(xùn)練階段,通過(guò)已知類別的訓(xùn)練樣本圖像、類別標(biāo)簽以及類別描述向量訓(xùn)練模型參數(shù)。在測(cè)試階段,在少量新類別支持樣本及其類別描述向量信息輔助下,對(duì)大量測(cè)試樣本進(jìn)行分類識(shí)別,并統(tǒng)計(jì)識(shí)別正確率,作為最終的模型評(píng)價(jià)指標(biāo)。當(dāng)前常用的實(shí)驗(yàn)設(shè)置為5-way 1/5-shot 圖像分類子任務(wù)。
(2) 典型方法性能對(duì)比
表7列出了零-小樣本學(xué)習(xí)典型方法的分類性能。可以看出,在語(yǔ)義特征信息輔助下,僅提供1個(gè)支持樣本就可以在miniImageNet數(shù)據(jù)集上取得65%的識(shí)別率。除各方法使用的圖像特征提取器結(jié)構(gòu)不同之外,值得一提的是,DeViSE, 魯棒半監(jiān)督視覺(jué)語(yǔ)義嵌入(robust semi-supervised visual-semantic embeddings, ReViSE)以及CADA-VAE模型使用了預(yù)訓(xùn)練的CNN圖像特征,而AM3系列方法是端到端的模型參數(shù)訓(xùn)練,無(wú)需使用預(yù)訓(xùn)練圖像特征。
表7 幾種典型零-小樣本學(xué)習(xí)模型在miniImagenet及tieredImageNet數(shù)據(jù)集上的分類性能
Table 7 Classification performance evaluations of the several typical models for zero-to-few-shot learning on the data sets of miniImagenet and tieredImageNet
4 未來(lái)研究方向
4.1 多種弱監(jiān)督學(xué)習(xí)方法融合發(fā)展
當(dāng)前弱監(jiān)督機(jī)器學(xué)習(xí)研究主要集中在零樣本學(xué)習(xí)以及小樣本學(xué)習(xí)上,而對(duì)于文本信息輔助的零-小樣本學(xué)習(xí)研究還很薄弱。零-小樣本學(xué)習(xí)既包含了少量支持樣本,同時(shí)又融合了文本信息,具備跨模態(tài)學(xué)習(xí)的獨(dú)特優(yōu)勢(shì),相對(duì)于零樣本學(xué)習(xí)和小樣本學(xué)習(xí),性能獲得了顯著提升[71,73]。從人類認(rèn)知角度看,人類識(shí)別新類別或者新概念會(huì)通過(guò)少數(shù)樣本歸納總結(jié),同時(shí)結(jié)合多種認(rèn)知模式進(jìn)行綜合理解,如“未見其人,先聞其聲”“字如其人”等都是多種認(rèn)知模式綜合作用的結(jié)果。綜合實(shí)際需求和學(xué)術(shù)研究,零-小樣本學(xué)習(xí)將是弱監(jiān)督學(xué)習(xí)和人類認(rèn)知結(jié)合的重要研究方向。
除此之外,零樣本學(xué)習(xí)可以和主動(dòng)學(xué)習(xí)相結(jié)合,提升主動(dòng)學(xué)習(xí)效果。零樣本學(xué)習(xí)可以融入到終身學(xué)習(xí)系統(tǒng)中,在僅有相關(guān)信息描述的情況下,持續(xù)學(xué)習(xí)新的任務(wù)。當(dāng)前,強(qiáng)化學(xué)習(xí)迅速發(fā)展,結(jié)合弱監(jiān)督機(jī)器學(xué)習(xí),強(qiáng)化學(xué)習(xí)系統(tǒng)可以更好地應(yīng)對(duì)新任務(wù)、新場(chǎng)景,甚至新領(lǐng)域。
4.2 弱監(jiān)督機(jī)器學(xué)習(xí)的理論基礎(chǔ)探究
當(dāng)前,弱監(jiān)督機(jī)器學(xué)習(xí)領(lǐng)域內(nèi)研究大多在統(tǒng)一數(shù)據(jù)集下展開,甚至訓(xùn)練集/測(cè)試集的劃分都是固定的。如零樣本學(xué)習(xí)實(shí)驗(yàn)中,絕大多數(shù)研究在AWA數(shù)據(jù)集采用固定40類訓(xùn)練,指定10類測(cè)試;在CUB上固定150類訓(xùn)練,指定50類測(cè)試。實(shí)驗(yàn)數(shù)據(jù)相對(duì)固定,在這種數(shù)據(jù)設(shè)置下訓(xùn)練的模型在其他數(shù)據(jù)上的有效性,即模型的泛化能力值得考究。可考慮使用傳統(tǒng)大規(guī)模數(shù)據(jù)集訓(xùn)練的有效方式,如5折交叉驗(yàn)證等方式來(lái)進(jìn)行弱監(jiān)督機(jī)器學(xué)習(xí)實(shí)驗(yàn)驗(yàn)證,充分測(cè)試模型在多種數(shù)據(jù)條件下的綜合性能。
同時(shí),實(shí)驗(yàn)設(shè)置應(yīng)當(dāng)更加切合實(shí)際應(yīng)用,如當(dāng)前小樣本和零樣本學(xué)習(xí)大多只在未見過(guò)的新類別上進(jìn)行分類性能測(cè)試,然而在實(shí)際應(yīng)用中,往往測(cè)試樣本來(lái)源于新類別以及訓(xùn)練集中的類別,如何提升這種廣義分類問(wèn)題上的性能也是重要的研究方向。
另一方面,盡管零樣本和小樣本學(xué)習(xí)對(duì)于訓(xùn)練數(shù)據(jù)的數(shù)目要求很低,但是前期的模型預(yù)訓(xùn)練直接影響其最終性能,當(dāng)前大多數(shù)模型繁瑣復(fù)雜,如何在保證正確率的前提下,盡量降低模型復(fù)雜度也是非常值得研究的工作。
當(dāng)前的研究主要是啟發(fā)式探索和驗(yàn)證性實(shí)驗(yàn),缺乏足夠的理論基礎(chǔ),對(duì)于一些關(guān)鍵問(wèn)題需要開展更多的理論分析,如零樣本學(xué)習(xí)中如何選擇輔助性信息,從訓(xùn)練集向未見過(guò)的測(cè)試樣本遷移過(guò)程中,什么信息和知識(shí)更有效,在學(xué)習(xí)過(guò)程中,如何抑制不相關(guān)信息,避免負(fù)向遷移等。科學(xué)的理論分析和充足的實(shí)驗(yàn)證明將更有益于弱監(jiān)督機(jī)器學(xué)習(xí)發(fā)展。
4.3 弱監(jiān)督機(jī)器學(xué)習(xí)在其他領(lǐng)域任務(wù)上的應(yīng)用
當(dāng)前的弱監(jiān)督機(jī)器學(xué)習(xí)研究主要集中在計(jì)算機(jī)視覺(jué)領(lǐng)域,包括字符識(shí)別、圖像分類等。這主要得益于視覺(jué)信息易于獲取,且在傳統(tǒng)深度學(xué)習(xí)領(lǐng)域已有大量研究,很多成熟的技術(shù)可直接遷移到弱監(jiān)督學(xué)習(xí)中來(lái)。當(dāng)前針對(duì)幾個(gè)主流的實(shí)驗(yàn)數(shù)據(jù)集,如miniImageNet等,已經(jīng)取得了很高的識(shí)別率,性能提升空間很小。因此,應(yīng)當(dāng)開發(fā)更廣泛的任務(wù)應(yīng)用,如圖像檢索、目標(biāo)跟蹤、手勢(shì)識(shí)別、圖像標(biāo)注、視覺(jué)問(wèn)答、視頻事件檢測(cè)等。例如,如何將從粗粒度的動(dòng)物分類任務(wù)中學(xué)習(xí)到的知識(shí)遷移到細(xì)粒度的狗品種分類任務(wù)中去。另外,應(yīng)當(dāng)從多種數(shù)據(jù)源獲取大規(guī)模度多樣化數(shù)據(jù)集,設(shè)置更加切近現(xiàn)實(shí)應(yīng)用的實(shí)驗(yàn)基準(zhǔn)。
除了計(jì)算機(jī)視覺(jué),弱監(jiān)督機(jī)器學(xué)習(xí)應(yīng)當(dāng)逐步擴(kuò)展到其他領(lǐng)域。在自然語(yǔ)言處理中,可針對(duì)文本翻譯、語(yǔ)言建模等開展研究;在推薦系統(tǒng)方面,依據(jù)少量樣本進(jìn)行相關(guān)推薦是一個(gè)值得研究的課題;在醫(yī)學(xué)研究中,罕見藥品發(fā)現(xiàn)將為醫(yī)藥研制提供創(chuàng)新途徑。尤其是在機(jī)器人控制領(lǐng)域,依靠少量人工指導(dǎo)甚至依靠傳統(tǒng)經(jīng)驗(yàn)進(jìn)行增強(qiáng)學(xué)習(xí)的智能學(xué)習(xí)方法將為機(jī)器人復(fù)雜運(yùn)動(dòng)規(guī)劃與控制提供有效途徑,當(dāng)前典型的應(yīng)用包括小樣本模仿學(xué)習(xí)、視覺(jué)導(dǎo)航、機(jī)器人運(yùn)動(dòng)連續(xù)控制等。
5 結(jié)束語(yǔ)
本文從弱監(jiān)督機(jī)器學(xué)習(xí)方法入手,主要介紹了小樣本學(xué)習(xí)、零樣本學(xué)習(xí)的問(wèn)題定義,當(dāng)前主流方法以及實(shí)驗(yàn)設(shè)計(jì)方案,之后給出了零-小樣本學(xué)習(xí)問(wèn)題描述及當(dāng)前研究現(xiàn)狀,最后對(duì)下一步研究方向進(jìn)行了總結(jié)展望。
審核編輯:符乾江






























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論