") 基于通過非常稀疏的視角輸入合成場景的方法
基于通過非常稀疏的視角輸入合成場景的方法

作者引入了一種方法,可以僅使用單個寬基線立體圖像對生成新視角。在這種具有挑戰(zhàn)性的情況下,3D場景點只被正常觀察一次,需要基于先驗進行場景幾何和外觀的重建。作者發(fā)現(xiàn)從稀疏觀測中生成新視角的現(xiàn)有方法因恢復(fù)不正確的3D幾何和可導(dǎo)渲染的高成本而失敗,這阻礙了其在大規(guī)模訓(xùn)練中的擴展。作者通過構(gòu)建一個多視圖轉(zhuǎn)換編碼器、提出一種高效的圖像空間極線采樣方案來組裝目標(biāo)射線的圖像特征,以及一個輕量級的基于交叉注意力的渲染器來解決這些問題。作者的貢獻使作者的方法能夠在一個大規(guī)模的室內(nèi)和室外場景的真實世界數(shù)據(jù)集上進行訓(xùn)練。作者展示了本方法學(xué)習(xí)到了強大的多視圖幾何先驗,并降低了渲染時間。作者在兩個真實世界數(shù)據(jù)集上進行了廣泛的對比實驗,在保留測試場景的情況下,明顯優(yōu)于先前從稀疏圖像觀測中生成新視圖的方法并實現(xiàn)了多視圖一致的新視圖合成。
1 前言
本文介紹了在極端稀疏輸入條件下進行新視圖合成的問題,提出了一個從單個廣角立體圖像對中生成高質(zhì)量新視圖的方法。為了更好地推理三維場景,提出了一個多視圖視覺變換器來計算每個輸入圖像的像素對準(zhǔn)特征,并引入多視圖特征匹配以進一步煉化三維幾何。通過采用以圖像為中心的采樣策略,提出了一種高效的可微分渲染器,解決了樣本稀疏問題,從而大大減少了樣本量需求。實驗證明了該方法在幾個數(shù)據(jù)集上均獲得了最先進的結(jié)果,比現(xiàn)有方法表現(xiàn)出更好的性能。
2 相關(guān)背景
IBR方法通過融合一組輸入圖像的信息生成新的相機視角下的圖像。單場景體繪制方法則利用可微渲染進行的3D場景表示來進行新視角合成。不同于IBR方法需要多個輸入圖像,單場景體繪制方法需要數(shù)百個密集采樣的3D場景的輸入圖像。與這兩種方法不同,一些方式使用可微渲染來監(jiān)督基于先驗的推理方法,即先驗知識可以幫助優(yōu)化3D重建和視圖合成。現(xiàn)有的方法普遍依賴于多個圖像觀測,而作者的方法通過僅使用一組寬基線立體圖像對場景進行重建來解決這一問題。
3 方法
本文提出一種用于生成3D場景新視角圖像的方法。該方法使用已知相機內(nèi)參和外參以及寬基線立體圖像計算像素對齊的特征,并使用基于交叉注意力的渲染器將特征轉(zhuǎn)換為新視角的圖像渲染結(jié)果。該方法為解決新視角圖像生成問題提供了一種有效的解決方案。
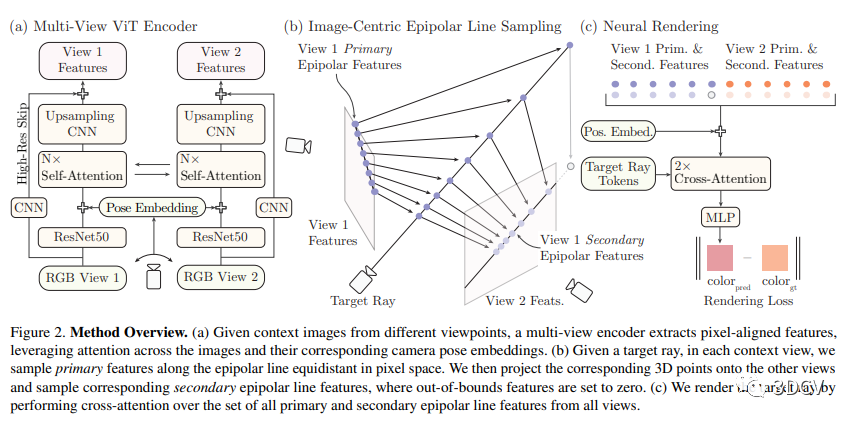
3.1 Multiview Feature Encoding - 多視圖特征編碼
本文中提出了一種多視角編碼器來獲取特征。該方法包括兩個階段:首先通過ResNet50提取基礎(chǔ)卷積特征。然后,通過學(xué)習(xí)的每像素位置嵌入和相機位置嵌入將這兩個圖像轉(zhuǎn)換為平面特征向量。接下來,這些向量經(jīng)過視覺Transformer編碼器處理,使每個向量的表示包含了整個場景的上下文。最后,用一個低分辨率的基礎(chǔ)CNN獲取高頻的圖像信息,這些信息與之前的圖像特征映射級聯(lián)在一起。
3.2 Epipolar Line Sampling and Feature Matching - 線極線采樣和特征匹配
本文提出了一種基于像素對齊特征的通用的新視角合成方法。通過對極線采樣來找到樣本點,然后使用特征匹配模塊計算來自另一個視圖的次要特征,以進一步處理表面細節(jié)。采用基礎(chǔ)矩陣來定義不同視圖生產(chǎn)的極線,并在其上采樣像素來獲得樣本。深度值可通過封閉形式的三角測量獲得。在這種方法中,樣本點的數(shù)量已達到有效最大值。
3.3 Differentiable Rendering via Cross-Attention - 交叉注意力實現(xiàn)可微分渲染
本文介紹了使用交叉注意力實現(xiàn)可微分渲染的方法。為了將樣本集映射到顏色值,作者將每個視差線上的點嵌入為一個射線查詢標(biāo)記。然后,作者的渲染程序通過兩輪交叉注意力,得到特征嵌入,然后通過簡單的 MLP 解碼為顏色。作者的方法不需要顯式計算精確的場景深度,而是可以使用目標(biāo)相機射線信息和少數(shù)視差樣本計算像素顏色。
3.4 Training and Losses - 訓(xùn)練和損失函數(shù)
在視圖合成中,訓(xùn)練圖像合成模型的損失函數(shù)是關(guān)鍵。模型應(yīng)該能夠生成與真實圖像盡可能接近的合成圖像。本文提出了由圖像損失和正則化損失組成的損失函數(shù),其中圖像損失通過LPIPS感知損失測量。此外,正則化損失有助于提高多視角一致性。作者還使用幾何一致的數(shù)據(jù)增強來提高模型的泛化能力。
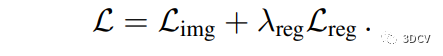
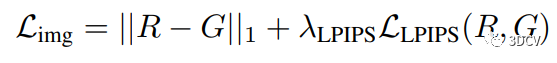
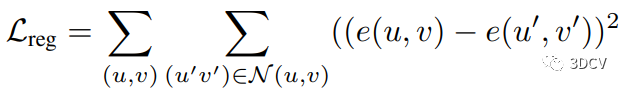
4 實驗
在本文中,作者展示的方法可以從寬基線立體圖像中有效地渲染新視角。作者在不同類型的場景中進行了評估和分析,并且成功應(yīng)用了該方法在野外捕獲的場景中。
4.1 實驗細節(jié)
作者在RealEstate10k和ACID這兩個大型室內(nèi)外場景的數(shù)據(jù)集上進行訓(xùn)練和評估。作者使用67477個場景進行RealEstate10k的訓(xùn)練和7289個場景進行測試,11075個場景進行ACID的訓(xùn)練和1972個場景進行測試,按照默認(rèn)的劃分方法。作者使用256×256分辨率的圖像對作者的方法進行訓(xùn)練,并在測試場景中評估方法的重建中間視角的能力(詳細信息在附錄中)。
作者將作者的方法與幾種現(xiàn)有的從稀疏圖像觀測中合成新視角的方法進行比較。作者將比較使用像素對齊特征的pixelNeRF和IBRNet,這些特征被解碼成使用體積渲染渲染的3D體積。作者還將與使用視覺變換器骨干計算極線特征和基于光場渲染器計算像素顏色的通用補丁渲染(GPNR)進行比較。這些基線涵蓋了現(xiàn)有方法中使用的各種設(shè)計選擇,例如使用CNN和transformer計算的像素對齊特征圖,使用MLP和transformer進行的特征解碼體積渲染以及基于光場的渲染。
作者為所有基線使用公開可用的代碼庫,并使用作者用于公正評估的相同數(shù)據(jù)集對其進行訓(xùn)練。有關(guān)更多基線的比較,請參見補充材料。評估指標(biāo)。作者使用LPIPS ,PSNR,SSIM和MSE指標(biāo)來比較渲染圖像與地面真實圖像的圖像質(zhì)量。
4.2 室內(nèi)場景的神經(jīng)渲染
在各種評估指標(biāo)下,本文的方法在室內(nèi)場景中渲染新視角時均優(yōu)于比較的基線。此外,與其他方法相比,該方法能更好地重建場景的3D結(jié)構(gòu),并捕獲更多的高頻細節(jié),這為視覺應(yīng)用提供了更好的合成質(zhì)量。


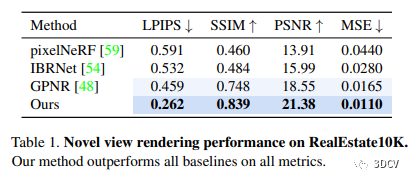
4.3 室外場景的神經(jīng)渲染
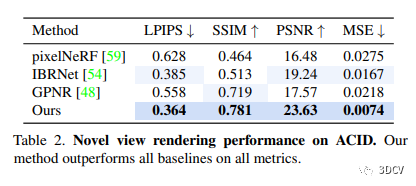
本文研究對具有潛在無界深度的戶外場景進行了神經(jīng)渲染的評估,展示了定性和定量結(jié)果,指出了該方法在重建幾何結(jié)構(gòu)、多視角一致的渲染以及各項指標(biāo)方面的表現(xiàn)均優(yōu)于基線方法。

4.4 消融實驗
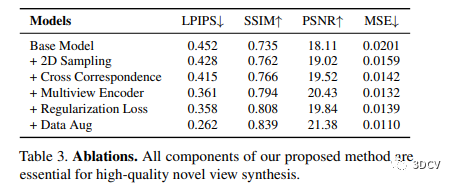
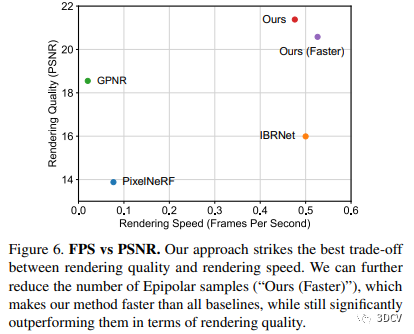
本文研究進行了組件分析和消融實驗。消融實驗表明了我們方法的各個組件對性能的貢獻,其中包括2D極線采樣、多視編碼器、跨圖像的對應(yīng)關(guān)系匹配、多視一致性的正則化損失以及數(shù)據(jù)增強。此外,本研究對不同渲染方法的質(zhì)量和速度進行了比較,結(jié)果顯示我們的輕量級方法在質(zhì)量和速度方面實現(xiàn)了最佳的平衡,并提升了高質(zhì)量視頻的渲染速度。最后,我們可視化了我們方法中的基礎(chǔ)極線注意權(quán)重,用來分析渲染器的學(xué)習(xí)計算。
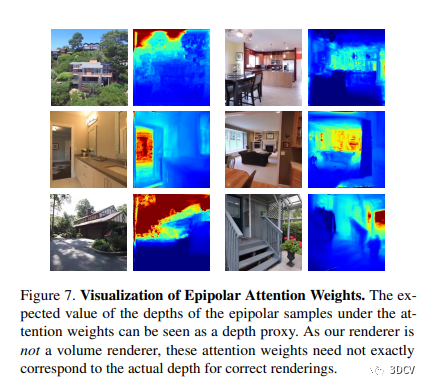
4.5 從不規(guī)定姿態(tài)圖像中合成新視角
本文提出了一種方法,可以使用寬基線立體圖像合成新視角,即使在未知相對位姿的情況下。在這種情況下,使用SuperGlue計算像素對應(yīng)關(guān)系,使用平均內(nèi)參估計本質(zhì)矩陣,從而推導(dǎo)出姿態(tài)信息。這一方法可以處理不規(guī)定姿態(tài)的圖像,能較好地推斷場景的幾何形狀。
5 討論
本文提出了一種通過非常稀疏的視角輸入合成場景的方法。然而,該方法的渲染結(jié)果質(zhì)量不如其他基于更多圖像的優(yōu)化方法。同時,由于該方法依賴于學(xué)習(xí)先驗知識,其適用范圍受到限制。雖然該方法能夠擴展到處理多于兩個輸入視角,但是目前只嘗試了處理兩個視角。
6 總結(jié)
本文提出了一種僅使用自監(jiān)督訓(xùn)練實現(xiàn)從單個寬基線立體圖像對中進行隱式3D重建和新視角合成的方法。該方法利用多視角編碼器、圖像空間對極線特征采樣方案和基于交叉注意力的渲染器,在具有挑戰(zhàn)性場景數(shù)據(jù)集上超越了以往方法的質(zhì)量,同時在渲染速度和質(zhì)量之間取得了很好的平衡。同時,利用對極線幾何在結(jié)構(gòu)化和通用化學(xué)習(xí)范例之間進行平衡,該方法可在RealEstate10k等現(xiàn)實數(shù)據(jù)集上進行訓(xùn)練。
責(zé)任編輯:彭菁
-
3D
+關(guān)注
關(guān)注
9文章
2961瀏覽量
111028 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1224瀏覽量
25531 -
渲染器
+關(guān)注
關(guān)注
0文章
18瀏覽量
3315
原文標(biāo)題:CVPR2023 I 一種全新的單個寬基線立體圖像對中學(xué)習(xí)渲染新視角的方法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
敏捷合成器的技術(shù)原理和應(yīng)用場景
基于稀疏編碼的遷移學(xué)習(xí)及其在行人檢測中的應(yīng)用
【ELT.ZIP】OpenHarmony啃論文俱樂部——淺析稀疏表示醫(yī)學(xué)圖像
基于分層稀疏編碼的行人檢測算法
結(jié)合彈性網(wǎng)絡(luò)的稀疏分解方法的人臉識別
基于坐標(biāo)下降的并行稀疏子空間聚類方法
基于塊稀疏表示的行人重識別方法
如何使用自適應(yīng)嵌入的半監(jiān)督多視角特征實現(xiàn)降維的方法概述
稀疏微波成像的研究案例
從多視角圖像做三維場景重建 (CVPR'22 Oral)
近場合成孔徑雷達稀疏測量微波成像簡析

讀者理解:LEAP泛化到新的物體類別和場景






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論