") 利用生成式AI進(jìn)行法律研究
利用生成式AI進(jìn)行法律研究
概述
本論文(Hallucination is the last thing you need)主要研究的背景是利用生成式AI進(jìn)行法律研究,但是目前遇到了幻覺(jué)(hallucination)問(wèn)題,這種情況可能導(dǎo)致一些法律錯(cuò)誤的生成,對(duì)法律行業(yè)造成影響。
過(guò)去的解決方法包括提高模型對(duì)事實(shí)的理解、使用搜索和比較算法進(jìn)行事實(shí)檢查以及提高模型對(duì)法律事實(shí)的理解能力等。然而,面對(duì)龐雜的法律事實(shí),現(xiàn)有的模型并不理想,容易出現(xiàn)幻覺(jué)。
為了解決這一問(wèn)題,本文提出了三個(gè)LLM模型——理解、經(jīng)驗(yàn)和事實(shí),將它們合成為一個(gè)組合模型。還引入了多長(zhǎng)度分詞的概念來(lái)保護(hù)關(guān)鍵信息資產(chǎn),最終探究了現(xiàn)有的公開(kāi)可用的法律幻覺(jué)模型,并提出兩種其他解決方案——多長(zhǎng)度標(biāo)記化和垂直對(duì)齊組合模型,試圖解決幻覺(jué)問(wèn)題。
通過(guò)推動(dòng)三個(gè)獨(dú)立的LLM模型——理解、經(jīng)驗(yàn)和事實(shí),構(gòu)成一個(gè)組合模型的方式,提高輸出的準(zhǔn)確性。
本文的方法在法律任務(wù)中取得了良好的表現(xiàn),大大降低了幻覺(jué)的發(fā)生率,便于人工專業(yè)檢查,恢復(fù)AI在法律行業(yè)中的聲譽(yù)。
重要問(wèn)題探討
這篇文章中提到了關(guān)于生成式AI在法律研究中可能產(chǎn)生的幻覺(jué)問(wèn)題,你是否聽(tīng)說(shuō)過(guò)或經(jīng)歷過(guò)這類問(wèn)題?你認(rèn)為這樣的錯(cuò)誤會(huì)給司法系統(tǒng)帶來(lái)什么影響?
答:文章中提到了一些案例,警示我們當(dāng)前普遍的AI模型和技術(shù)還不能完全保證從法律事實(shí)和法律文本上準(zhǔn)確解決問(wèn)題,存在一定的幻覺(jué)錯(cuò)誤危險(xiǎn)。如果這些錯(cuò)誤嚴(yán)重影響到司法的公正和權(quán)威性,那么很可能會(huì)導(dǎo)致法律體系和法律秩序的混亂。
2. 文章討論了在生成式AI模型中使用多項(xiàng)式tokenization方法來(lái)防止普適性幻覺(jué)錯(cuò)誤。您是否了解或嘗試過(guò)這種方法?在這種具體情況下,tokenization是如何影響模型輸出結(jié)果的呢?
答:文章中提到tokenization對(duì)于法律文本數(shù)據(jù)的處理比較特殊,在生成式AI中會(huì)受到一定的局限性。多項(xiàng)式tokenization是一種將單詞序列轉(zhuǎn)換為被分類器識(shí)別的多個(gè)序列的方法,這可以更好地控制法律文本素材的準(zhǔn)確性和格式化,進(jìn)而保證輸出結(jié)果的正確性。但是,這種方法也需要更加結(jié)合實(shí)際情況再進(jìn)行分解、重組,研究進(jìn)行不同領(lǐng)域的優(yōu)化。
3. 在文章中,作者提到了組合模型(Ensemble Models),這種方法可以有效降低生成式AI的幻覺(jué)錯(cuò)誤。您怎么理解這種方法?是否有相關(guān)的實(shí)踐應(yīng)用例子?
答:組合模型是將多個(gè)不同輸入的AI模型組合于一起,用線性加權(quán)的方式改進(jìn)模型的輸出效果。這種方法可以在解決法律案例中提出問(wèn)題時(shí)更加細(xì)致地研究每個(gè)模型的表現(xiàn),并利用其各自的優(yōu)勢(shì)來(lái)消除各自的限制。在實(shí)踐中,類似的組合模型方法已經(jīng)被廣泛應(yīng)用于視覺(jué)圖像識(shí)別、自然語(yǔ)言處理等各種AI領(lǐng)域。
4. 您認(rèn)為,文中與AI模型應(yīng)用于法律研究相關(guān)的這個(gè)問(wèn)題,是否應(yīng)該得到更廣泛的社會(huì)關(guān)注,比如在立法和監(jiān)管層級(jí)方面?
答:AI模型在法律研究中應(yīng)用的問(wèn)題牽涉到繁瑣的法律文獻(xiàn)數(shù)據(jù)處理,需要更加權(quán)威的機(jī)構(gòu)和領(lǐng)域?qū)<业膮f(xié)助。因此,這個(gè)問(wèn)題確實(shí)需要政府和專業(yè)組織關(guān)注和監(jiān)管,以確定標(biāo)準(zhǔn)化的數(shù)據(jù)標(biāo)注和模型評(píng)估方法。此外,隨著AI技術(shù)應(yīng)用范圍的進(jìn)一步擴(kuò)大,對(duì)于監(jiān)管應(yīng)當(dāng)適時(shí)跟進(jìn)和調(diào)整。
5. 文章中提出的mutli-length tokenisation方法似乎可以為解決語(yǔ)言和翻譯模型中的類似問(wèn)題提供參考。這種思路會(huì)對(duì)其他自然語(yǔ)言處理(NLP)領(lǐng)域的AI工作產(chǎn)生怎樣的影響呢?
答:multi-length tokenisation方法可以應(yīng)用于語(yǔ)言和翻譯模型,以正確地處理從不同角度和語(yǔ)境中產(chǎn)生的各種數(shù)據(jù),避免混淆和錯(cuò)誤。NLP領(lǐng)域在這一技術(shù)的基礎(chǔ)上可以進(jìn)一步改善關(guān)鍵詞提取、句子結(jié)構(gòu)分析、語(yǔ)言理解和情感分析等任務(wù),以優(yōu)化語(yǔ)言模型效果和可用性。
6. 文章指出了盡管高精度的AI技術(shù)在法律研究中可以起到很有幫助的作用,但是我們必須保留人類智慧、專業(yè)責(zé)任和人際溝通等方面的價(jià)值。您是否認(rèn)為這種客觀事實(shí)需要隨著AI技術(shù)在司法體系中的應(yīng)用而得到更廣泛的認(rèn)知和保障?
答:相信的AI的產(chǎn)生是基于人類的智慧和經(jīng)驗(yàn),其應(yīng)用不應(yīng)取代人類。司法領(lǐng)域?qū)τ诘赖潞蜕鐣?huì)責(zé)任等方面,也需要依靠人性的底線,不能完全依賴技術(shù)術(shù)語(yǔ)和AI算法。因此,保留人類智慧和專業(yè)責(zé)任是司法計(jì)算的基本前提,必須與AI技術(shù)相結(jié)合,共同促進(jìn)社會(huì)的發(fā)展和進(jìn)步。
-
算法
+關(guān)注
關(guān)注
23文章
4687瀏覽量
94434 -
AI
+關(guān)注
關(guān)注
87文章
33701瀏覽量
274437 -
ai技術(shù)
+關(guān)注
關(guān)注
1文章
1307瀏覽量
24949 -
生成式AI
+關(guān)注
關(guān)注
0文章
524瀏覽量
688
原文標(biāo)題:概述
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
MCU或MPU上生成AI算法,進(jìn)行對(duì)嵌入式設(shè)備操控
AI沖入法律界,律師也開(kāi)始變得更智能
GTC23 | 生成式 AI 最前沿研究和實(shí)踐!請(qǐng)關(guān)注這場(chǎng)分會(huì)
什么是生成式AI?生成式AI的四大優(yōu)勢(shì)
在線研討會(huì) | 9 月 19 日,利用 GPU 加速生成式 AI 圖像內(nèi)容生成

利用 NVIDIA Jetson 實(shí)現(xiàn)生成式 AI
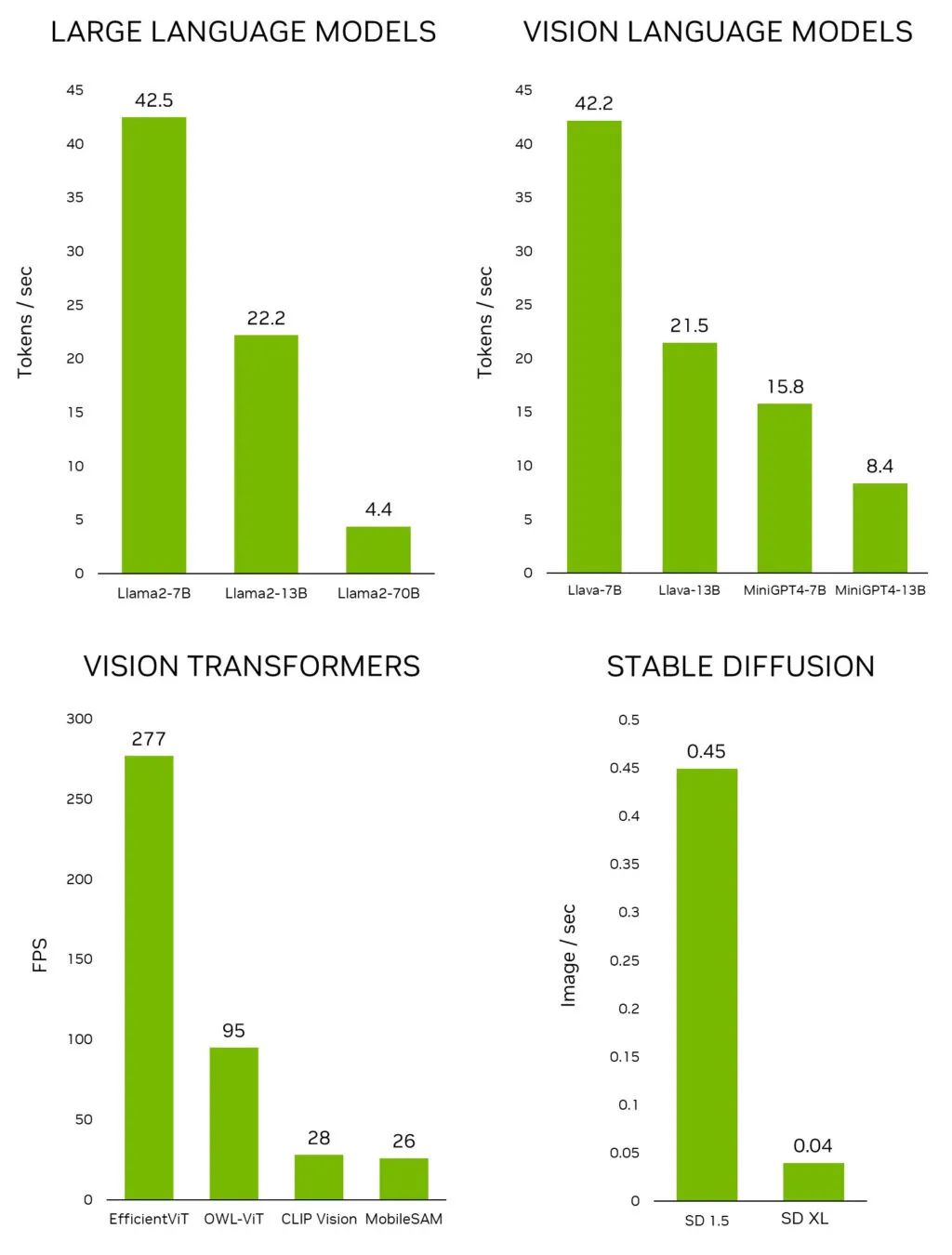
NVIDIA生成式AI研究實(shí)現(xiàn)在1秒內(nèi)生成3D形狀

Bria利用NVIDIA NeMo和Picasso為企業(yè)打造負(fù)責(zé)任的生成式AI
原來(lái)這才是【生成式AI】!!

生成式AI的基本原理和應(yīng)用領(lǐng)域
如何利用生成式人工智能進(jìn)行精確編碼
LexLegis.ai在印度利用人工智能推動(dòng)法律研究轉(zhuǎn)型,并將向全球推廣






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論