") 通過(guò)NVIDIA Magnum IO擴(kuò)展VASP
通過(guò)NVIDIA Magnum IO擴(kuò)展VASP

盡管硅和其他半導(dǎo)體材料可能是當(dāng)今推動(dòng)變革的最重要的材料,但研究中還有其他幾種材料同樣可以推動(dòng)下一代變革,包括以下任何一種:
高溫超導(dǎo)體
光伏
石墨烯電池
半導(dǎo)體是構(gòu)建芯片的核心,這些芯片能夠?qū)@種新型材料進(jìn)行廣泛而復(fù)雜的搜索。
本文研究了一種叫做鉿或氧化鉿( HfO )的材料的性質(zhì)計(jì)算2.).
就其本身而言,鉿是一種電絕緣體。它在半導(dǎo)體制造中大量使用,因?yàn)樵跇?gòu)建動(dòng)態(tài)隨機(jī)存取存儲(chǔ)器( DRAM )存儲(chǔ)時(shí),它可以充當(dāng)高κ介電膜。它還可以作為金屬氧化物半導(dǎo)體場(chǎng)效應(yīng)晶體管( MOSFET )的柵極絕緣體。 Hafnia 對(duì)非易失性電阻 RAM 非常感興趣,這可能會(huì)使啟動(dòng)計(jì)算機(jī)成為過(guò)去。
而理想的純 HfO2.晶體只能用 12 個(gè)原子來(lái)計(jì)算,這只是一個(gè)理論模型。這種晶體實(shí)際上含有雜質(zhì)。
有時(shí),必須添加摻雜劑以產(chǎn)生超出絕緣的所需材料特性。這種摻雜可以在純度水平上進(jìn)行,這意味著在 100 個(gè)合格原子中,一個(gè)原子被不同的元素取代。至少有 12 個(gè)原子,其中只有 4 個(gè)是 Hf 。很快,很明顯,這樣的計(jì)算很容易需要數(shù)百個(gè)原子。
這篇文章演示了如何在數(shù)百甚至數(shù)千 GPU 上高效地并行化此類計(jì)算。 Hafnia 是一個(gè)例子,但這里所展示的原理當(dāng)然也可以應(yīng)用于類似大小的計(jì)算。
術(shù)語(yǔ)定義
Speedup:相對(duì)于參考的無(wú)維度性能度量。對(duì)于這篇文章,參考是使用 8x A100 80 GB SXM4 GPU 而不啟用 NCCL 的單節(jié)點(diǎn)性能。加速是通過(guò)將參考運(yùn)行時(shí)間除以經(jīng)過(guò)的運(yùn)行時(shí)間來(lái)計(jì)算的。
Linear scaling:完全平行的應(yīng)用程序的加速曲線。根據(jù) Amdahl 定律,它適用于 100% 并行化且互連速度無(wú)限快的應(yīng)用程序。在這種情況下, 2 倍的計(jì)算資源將導(dǎo)致一半的運(yùn)行時(shí)間, 10 倍的計(jì)算時(shí)間將導(dǎo)致十分之一的運(yùn)行時(shí)間。當(dāng)繪制與計(jì)算資源數(shù)量相比的加速時(shí),性能曲線是一條向上向右傾斜 45 度的直線。并行運(yùn)行的效果優(yōu)于此比例關(guān)系。也就是說(shuō),坡度將大于 45 度,這被稱為超線性縮放。
Parallel efficiency:以百分比表示的特定應(yīng)用程序執(zhí)行與理想線性縮放的接近程度的無(wú)量綱度量。并行效率通過(guò)將所獲得的加速率除以該計(jì)算資源數(shù)量的線性縮放加速率來(lái)計(jì)算。為了避免浪費(fèi)計(jì)算時(shí)間,大多數(shù)數(shù)據(jù)中心都有最低并行效率目標(biāo)( 50-70% )的策略。
VASP 用例和區(qū)別
VASP 是電子結(jié)構(gòu)計(jì)算和第一原理分子動(dòng)力學(xué)中應(yīng)用最廣泛的應(yīng)用之一。它提供了最先進(jìn)的算法和方法來(lái)預(yù)測(cè)材料性能,如前面所討論的。
GPU 加速度使用 OpenACC 實(shí)現(xiàn)。 GPU 通信可以使用 NVIDIA HPC-X 或 NVIDIA Collective Communications Library ( NCCL )中的 Magnum IO MPI 庫(kù)來(lái)執(zhí)行。
混合 DFT 的用例和區(qū)別
本節(jié)側(cè)重于使用稱為密度泛函理論( DFT )的量子化學(xué)方法,通過(guò)將精確交換計(jì)算與 DFT 內(nèi)的近似值混合,從而實(shí)現(xiàn)更高精度的預(yù)測(cè),然后稱為混合 DFT 。這種增加的精度有助于根據(jù)實(shí)驗(yàn)結(jié)果確定帶隙。
帶隙是將材料分類為絕緣體、半導(dǎo)體或?qū)w的特性。對(duì)于基于鉿的材料,這種額外的精度是至關(guān)重要的,但計(jì)算復(fù)雜度會(huì)增加。
將這一點(diǎn)與使用多個(gè)原子的需求結(jié)合起來(lái),證明了在 GPU 加速的超級(jí)計(jì)算機(jī)上擴(kuò)展到多個(gè)節(jié)點(diǎn)的需求。幸運(yùn)的是, VASP 中有更高精度的方法。有關(guān)其他功能的更多信息,請(qǐng)參見(jiàn) VASP6 。
在更高的層次上, VASP 是一種量子化學(xué)應(yīng)用程序,它與 NAMD 、 GROMACS 、 LAMMPS 和 AMBER 等其他高性能計(jì)算( HPC )計(jì)算化學(xué)應(yīng)用程序不同,甚至可能更為熟悉。這些代碼側(cè)重于分子動(dòng)力學(xué)( MD ),通過(guò)簡(jiǎn)化原子之間的相互作用,例如將它們視為點(diǎn)電荷。這使得模擬這些原子的運(yùn)動(dòng)(比如因?yàn)闇囟龋┰谟?jì)算上變得廉價(jià)。
另一方面, VASP 在量子水平上處理原子之間的相互作用,因?yàn)樗?jì)算電子如何相互作用并形成化學(xué)鍵。它還可以為量子或從頭計(jì)算 MD ( AIMD )模擬導(dǎo)出力和移動(dòng)原子。這確實(shí)對(duì)本文討論的科學(xué)問(wèn)題很有意思。
然而,這種模擬將包括多次重復(fù)混合 DFT 計(jì)算步驟。雖然后續(xù)步驟可能會(huì)更快地收斂,但每個(gè)單獨(dú)步驟的計(jì)算輪廓不會(huì)改變。這就是為什么我們?cè)谶@里只顯示了一個(gè)離子步驟。
運(yùn)行單節(jié)點(diǎn)或多節(jié)點(diǎn)
許多 VASP 計(jì)算使用的化學(xué)系統(tǒng)足夠小,不需要在 HPC 設(shè)施上執(zhí)行。一些用戶可能會(huì)對(duì)在多個(gè)節(jié)點(diǎn)上擴(kuò)展 VASP 感到不舒服,并在解決方案的過(guò)程中遭受痛苦,甚至可能導(dǎo)致停電或其他故障。其他人可能會(huì)限制他們的模擬大小,這樣運(yùn)行時(shí)就不會(huì)像研究更適合的系統(tǒng)大小那樣繁重。
有多種原因可以促使您多節(jié)點(diǎn)運(yùn)行仿真:
在一個(gè)節(jié)點(diǎn)上運(yùn)行模擬需要不可接受的時(shí)間,即使后者可能更有效。
需要大量?jī)?nèi)存且無(wú)法容納在單個(gè)節(jié)點(diǎn)上的大型計(jì)算需要分布式并行。雖然某些計(jì)算量必須在節(jié)點(diǎn)之間復(fù)制,但大多數(shù)計(jì)算量都可以分解。因此,每個(gè)節(jié)點(diǎn)所需的內(nèi)存量大致由參與并行任務(wù)的節(jié)點(diǎn)數(shù)量決定。
有關(guān)多節(jié)點(diǎn)并行性和計(jì)算效率的更多信息,請(qǐng)參閱最近的 HPC for the Age of AI and Cloud Computing 電子書(shū)。
NVIDIA 使用數(shù)據(jù)集 Si256 _ VJT _ HSE06 發(fā)布了 study of multi-node parallelism 。在這項(xiàng)研究中, NVIDIA 提出了一個(gè)問(wèn)題,“對(duì)于這個(gè)數(shù)據(jù)集,以及 V100 系統(tǒng)和 InfiniBand 網(wǎng)絡(luò)的 HPC 環(huán)境,我們可以合理地?cái)U(kuò)展到什么程度?”
Magnum IO 并行通信工具
VASP 使用 NVIDIA Magnum IO 庫(kù)和技術(shù)來(lái)優(yōu)化多 GPU 和多節(jié)點(diǎn)編程,以提供可擴(kuò)展的性能。這些是 NVIDIA HPC SDK 的一部分。
在本文中,我們將介紹兩個(gè)通信庫(kù):
Message Passing Interface ( MPI ):編程分布式內(nèi)存可擴(kuò)展系統(tǒng)的標(biāo)準(zhǔn)。
NVIDIA Collective Communications Library ( NCCL ):使用 MPI 兼容的全聚集、全減少、廣播、減少、減少分散和點(diǎn)對(duì)點(diǎn)例程,實(shí)現(xiàn)高度優(yōu)化的多 GPU 和多節(jié)點(diǎn)集體通信原語(yǔ),以利用 HPC 服務(wù)器節(jié)點(diǎn)內(nèi)和跨 HPC 服務(wù)器節(jié)點(diǎn)的所有可用 GPU 。
VASP 用戶可以在運(yùn)行時(shí)選擇應(yīng)該使用什么通信庫(kù)。當(dāng) MPI 替換為 NCCL 時(shí),性能通常會(huì)顯著提高,這是 VASP 中的默認(rèn)設(shè)置。
在 MPI 上使用 NCCL 時(shí),觀察到的差異有兩個(gè)強(qiáng)烈的原因。
使用 NCCL ,通信由 GPU 啟動(dòng)并具有流感知。這消除了 GPU 到 – CPU 同步的需要,否則,在每個(gè) CPU 啟動(dòng) MPI 通信之前都需要進(jìn)行同步,以確保在 MPI 庫(kù)接觸緩沖區(qū)之前所有 GPU 操作都已完成。 NCCL 通信可以像內(nèi)核一樣在 CUDA 流上排隊(duì),并且可以促進(jìn)異步操作。 CPU 可以對(duì)進(jìn)一步的操作進(jìn)行排隊(duì),以保持 GPU 忙碌。
在 MPI 情況下, GPU 至少在完成 MPI 通信后 CPU 入隊(duì)并啟動(dòng)下一個(gè) GPU 操作所需的時(shí)間內(nèi)是空閑的。最小化 GPU 空閑時(shí)間有助于提高 parallel efficiencies 。
使用兩個(gè)單獨(dú)的 CUDA 流,您可以輕松地使用一個(gè)流進(jìn)行 GPU 計(jì)算,另一個(gè)流用于通信。鑒于這些流是獨(dú)立的,通信可以在后臺(tái)進(jìn)行,并且可能完全隱藏在計(jì)算后面。實(shí)現(xiàn)后者是邁向高并行效率的一大步。此技術(shù)可用于任何啟用雙緩沖方法的程序中。
非阻塞 MPI 通信也可以帶來(lái)類似的好處。但是,您仍然必須手動(dòng)處理 GPU 和 CPU 之間的同步,并具有所描述的性能缺點(diǎn)。
由于非阻塞 MPI 通信也必須在 CPU 側(cè)同步,因此增加了另一層復(fù)雜性。與使用 NCCL 相比,這從一開(kāi)始就需要更詳細(xì)的代碼。然而,由于 MPI 通信是由 CPU 啟動(dòng)的,因此通常沒(méi)有硬件資源自動(dòng)使通信真正異步。
如果您的應(yīng)用程序有 CPU 內(nèi)核可供使用,您可以生成 CPU threads 以確保通信進(jìn)度,但這再次增加了代碼復(fù)雜性。否則,通信可能僅在進(jìn)程進(jìn)入 MPI _ Wait 時(shí)發(fā)生,這與使用阻塞調(diào)用相比沒(méi)有任何優(yōu)勢(shì)。
另一個(gè)需要注意的區(qū)別是,對(duì)于縮減,數(shù)據(jù)在 CPU 上進(jìn)行匯總。在單線程 CPU 內(nèi)存帶寬低于網(wǎng)絡(luò)帶寬的情況下,這可能也是一個(gè)意外的瓶頸。
另一方面, NCCL 使用 GPU 求和,并了解拓?fù)浣Y(jié)構(gòu)。在節(jié)點(diǎn)內(nèi),它可以使用可用的 NVLink 連接,并使用 Mellanox 以太網(wǎng)、 InfiniBand 或類似結(jié)構(gòu)優(yōu)化節(jié)點(diǎn)間通信。
使用 HfO 的計(jì)算建模測(cè)試用例2.
鉿晶體由兩種元素構(gòu)成:鉿( Hf )和氧( O )。在沒(méi)有摻雜劑或空位的理想系統(tǒng)中,對(duì)于每個(gè) Hf 原子,將有兩個(gè) O 原子。描述無(wú)限延伸晶體結(jié)構(gòu)所需的最小原子數(shù)是四個(gè) Hf (黃色)和八個(gè) O (紅色)原子。圖 2 顯示了結(jié)構(gòu)。
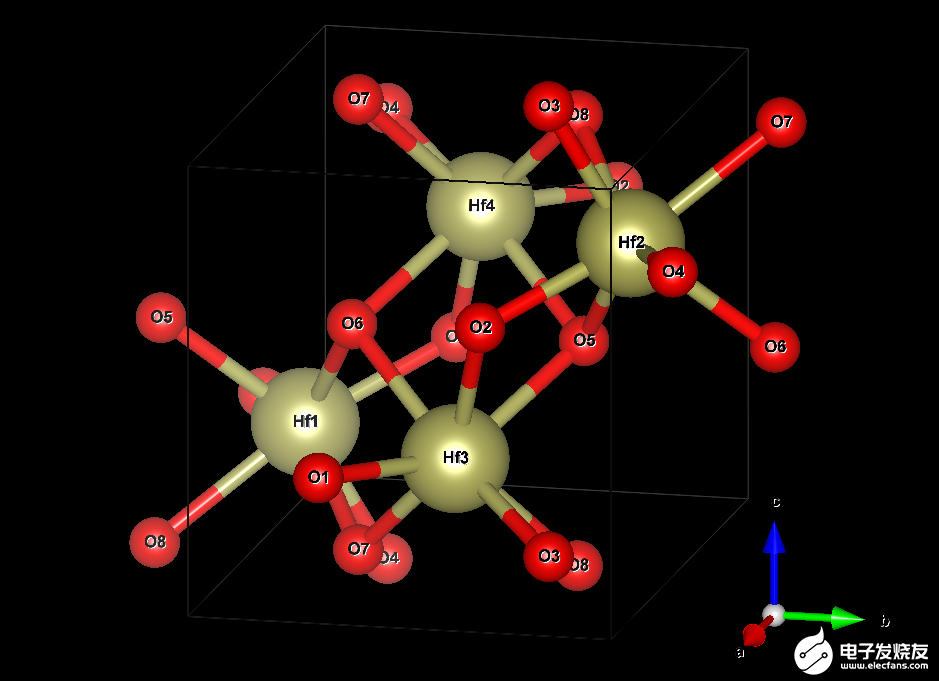
圖 2.鉿( HfO )晶胞的可視化2.) 晶體
框線框指定所謂的單位單元。它在所有三維空間中重復(fù),產(chǎn)生無(wú)限延伸的晶體。這張圖片暗示了通過(guò)在晶胞外復(fù)制原子 O5 、 O6 、 O7 和 O8 來(lái)顯示它們與 Hf 原子的各自鍵。該電池的尺寸為 51.4 × 51.9 × 53.2 納米。這不是一個(gè)完美的長(zhǎng)方體,因?yàn)樗囊粋€(gè)角度是 99.7 °而不是 90 °。
最小模型僅明確地處理圖 2 中框中的 12 個(gè)原子。但是,您也可以將長(zhǎng)方體在一個(gè)或多個(gè)空間方向上延長(zhǎng)相應(yīng)邊的整數(shù)倍,并將原子的結(jié)構(gòu)復(fù)制到新創(chuàng)建的空間中。這樣的結(jié)果被稱為超級(jí)細(xì)胞,可以幫助治療在最小模型內(nèi)無(wú)法達(dá)到的效果,例如 1% 的氧空位。
當(dāng)然,用更多的原子處理更大的細(xì)胞在計(jì)算上要求更高。當(dāng)您再添加一個(gè)單元時(shí),在 a 方向上總共有兩個(gè)單元,同時(shí)保留 b 和 c ,這稱為具有 24 個(gè)原子的 2x1x1 超級(jí)單元。
為了本研究的目的,我們只考慮了成本足以證明至少使用少數(shù)超級(jí)計(jì)算機(jī)節(jié)點(diǎn)的超級(jí)單元:
2x2x2 : 96 個(gè)原子, 512 個(gè)軌道
3x3x2 : 216 個(gè)原子, 1280 個(gè)軌道
3x3x3 : 324 個(gè)原子, 1792 個(gè)軌道
4x4x3 : 576 個(gè)原子, 3072 個(gè)軌道
4x4x4 : 768 個(gè)原子, 3840 個(gè)軌道
請(qǐng)記住,計(jì)算工作量與原子數(shù)或晶胞體積不成正比。本案例研究中使用的粗略估計(jì)是,它與任何一個(gè)都成立方比例。
當(dāng)然,這里使用的哈夫尼亞系統(tǒng)只是一個(gè)例子。由于基本算法和通信模式不會(huì)改變,因此這些經(jīng)驗(yàn)教訓(xùn)也可以轉(zhuǎn)移到使用類似大小單元和混合 DFT 的其他系統(tǒng)。
如果你想用 HfO 做一些測(cè)試2.,您可以 下載輸入文件用于本研究。出于版權(quán)原因,我們可能不會(huì)重新分發(fā) POTCAR 文件。此文件在所有超級(jí)單元格中都是相同的。作為 VASP 許可證持有人,您可以通過(guò)以下 Linux 命令從提供的文件中輕松創(chuàng)建它:
# cat PAW_PBE_54/Hf_sv/POTCAR PAW_PBE_54/O/POTCAR > POTCAR
對(duì)于這些定標(biāo)實(shí)驗(yàn),我們強(qiáng)制使用恒定數(shù)量的晶體軌道,或 bands 。這會(huì)略微增加工作量,超出所需的最小值,但不會(huì)影響計(jì)算精度。
如果沒(méi)有這樣做, VASP 將自動(dòng)選擇一個(gè)可以被 GPU 的整數(shù)整除的數(shù)字,這可能會(huì)增加某些節(jié)點(diǎn)計(jì)數(shù)的工作量。我們選擇了可被所有 GPU 計(jì)數(shù)整除的軌道數(shù)。此外,為了更好的計(jì)算可比性, k 點(diǎn)的數(shù)量保持固定為 8 ,即使更大的超級(jí)單元在實(shí)踐中可能不需要這一點(diǎn)。
基于 VASP 的超級(jí)電池建模測(cè)試方法
以下列出的所有基準(zhǔn)測(cè)試均使用最新的 VASP 6.3.2 版本,該版本使用 NVIDIA HPC SDK 22.5 和 CUDA 11.7 編譯。
作為完整參考,makefile.include已可下載。它們?cè)谟?560 個(gè) DGX A100 節(jié)點(diǎn)組成的 NVIDIA Selene supercomputer 上運(yùn)行,每個(gè)節(jié)點(diǎn)提供八個(gè) NVIDIA A100-SXM4-80GB GPU 、八個(gè) NVVIDIA ConnectX-6 HDR InfiniBand 網(wǎng)絡(luò)接口卡( NIC )和兩個(gè) AMD EPYC 7742 CPU 。
為了確保最佳性能,進(jìn)程和線程被固定到 CPU 上的 NUMA 節(jié)點(diǎn),這些節(jié)點(diǎn)為它們將使用的相應(yīng) GPU 和 NIC 提供理想的連接。 AMD EPYC 上的反向 NUMA 節(jié)點(diǎn)編號(hào)產(chǎn)生以下最佳硬件位置的進(jìn)程綁定。
| Node local rank | CPU NUMA node | GPU ID | NIC ID |
| 0 | 3 | 0 | mlx5_0 |
| 1 | 2 | 1 | mlx5_1 |
| 2 | 1 | 2 | mlx5_2 |
| 3 | 0 | 3 | mlx5_3 |
| 4 | 7 | 4 | mlx5_6 |
| 5 | 6 | 5 | mlx5_7 |
| 6 | 5 | 6 | mlx5_8 |
| 7 | 4 | 7 | mlx5_9 |
表 1.計(jì)算節(jié)點(diǎn) GPU 和 NIC ID 映射
downloadable files 集合中包括一個(gè)名為selenerun-ucx.sh的腳本。該腳本通過(guò)在工作負(fù)載管理器(例如 Slurm )作業(yè)腳本中執(zhí)行以下操作來(lái)包裝對(duì) VASP 的調(diào)用:
# export EXE=/your/path/to/vasp_std # srun ./selenerun-ucx.sh
selenerun-ucx.sh文件必須根據(jù)可用的資源配置進(jìn)行定制,以匹配您的環(huán)境。例如,每個(gè)節(jié)點(diǎn)的 GPU 數(shù)量或 NIC 數(shù)量可能與 Selene 不同,腳本必須反映這些差異。
為了盡可能縮短基準(zhǔn)測(cè)試的計(jì)算時(shí)間,我們通過(guò)在 INCAR 文件中設(shè)置NELM=1,將所有計(jì)算限制為僅一個(gè)電子步驟。我們之所以能做到這一點(diǎn),是因?yàn)槲覀儾魂P(guān)心總能量等科學(xué)結(jié)果,而運(yùn)行一個(gè)電子步驟就足以預(yù)測(cè)整個(gè)運(yùn)行的性能。這樣的運(yùn)行需要 19 次迭代才能與 3x3x2 超級(jí)單元收斂。
當(dāng)然,每個(gè)不同的單元設(shè)置可能需要不同的迭代次數(shù),直到收斂。為了對(duì)縮放行為進(jìn)行基準(zhǔn)測(cè)試,無(wú)論如何都需要比較固定的迭代次數(shù),以保持工作負(fù)載的可比性。
然而,僅使用一次電子迭代評(píng)估跑步的性能會(huì)誤導(dǎo)您,因?yàn)榕渲梦募遣黄胶獾摹Ec凈迭代相比,初始化時(shí)間所占的份額要大得多,而像力計(jì)算這樣的后收斂部分也是如此。
幸運(yùn)的是,電子迭代都需要同樣的努力和時(shí)間。您可以使用以下公式預(yù)測(cè)代表性運(yùn)行的總運(yùn)行時(shí)間:
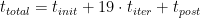
您可以從 VASP 內(nèi)部 LOOP 計(jì)時(shí)器中提取一次迭代的時(shí)間 ,而迭代后步驟
,而迭代后步驟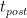 中花費(fèi)的時(shí)間由 LOOP +和 LOOP 計(jì)時(shí)器之間的差值給出。
中花費(fèi)的時(shí)間由 LOOP +和 LOOP 計(jì)時(shí)器之間的差值給出。
另一方面,初始化時(shí)間是 VASP 中報(bào)告為經(jīng)過(guò)時(shí)間的總時(shí)間與 LOOP +之間的差值。由于一次性分配之類的實(shí)例,第一次迭代所需的時(shí)間稍長(zhǎng),因此這種預(yù)測(cè)有一點(diǎn)錯(cuò)誤。然而,經(jīng)檢查,誤差小于 2% 。
VASP 中混合 DFT 迭代的并行效率結(jié)果
我們首先回顧了 96 個(gè)原子的最小數(shù)據(jù)集: 2x2x2 超級(jí)電池。如今,這個(gè)數(shù)據(jù)集幾乎不需要超級(jí)計(jì)算機(jī)。它的完整運(yùn)行, 19 次迭代,在一個(gè) DGX A100 上大約 40 分鐘內(nèi)完成。
盡管如此,通過(guò) MPI ,它可以以 93% 的并行效率擴(kuò)展到兩個(gè)節(jié)點(diǎn),然后在四個(gè)節(jié)點(diǎn)上下降到 83% ,甚至在八個(gè)節(jié)點(diǎn)上降低到 63% 。
另一方面, NCCL 在兩個(gè)節(jié)點(diǎn)上實(shí)現(xiàn)了近乎理想的 97% 的縮放,在四個(gè)節(jié)點(diǎn)上達(dá)到了 90% ,甚至在八個(gè)節(jié)點(diǎn)上也達(dá)到了 71% 。然而, NCCL 的最大優(yōu)勢(shì)在 16 個(gè)節(jié)點(diǎn)上得到了明顯的證明。與僅使用 MPI 的 6 倍相比,您仍然可以看到> 10 倍的相對(duì)加速。
超過(guò) 64 個(gè)節(jié)點(diǎn)的負(fù)縮放需要解釋。要使用 1024 GPU 運(yùn)行 128 個(gè)節(jié)點(diǎn),還必須使用 1024 個(gè)軌道。其他計(jì)算只使用了 512 ,因此這里的工作量增加了。不過(guò),我們不想在低節(jié)點(diǎn)運(yùn)行中包含如此多的軌道計(jì)數(shù)。
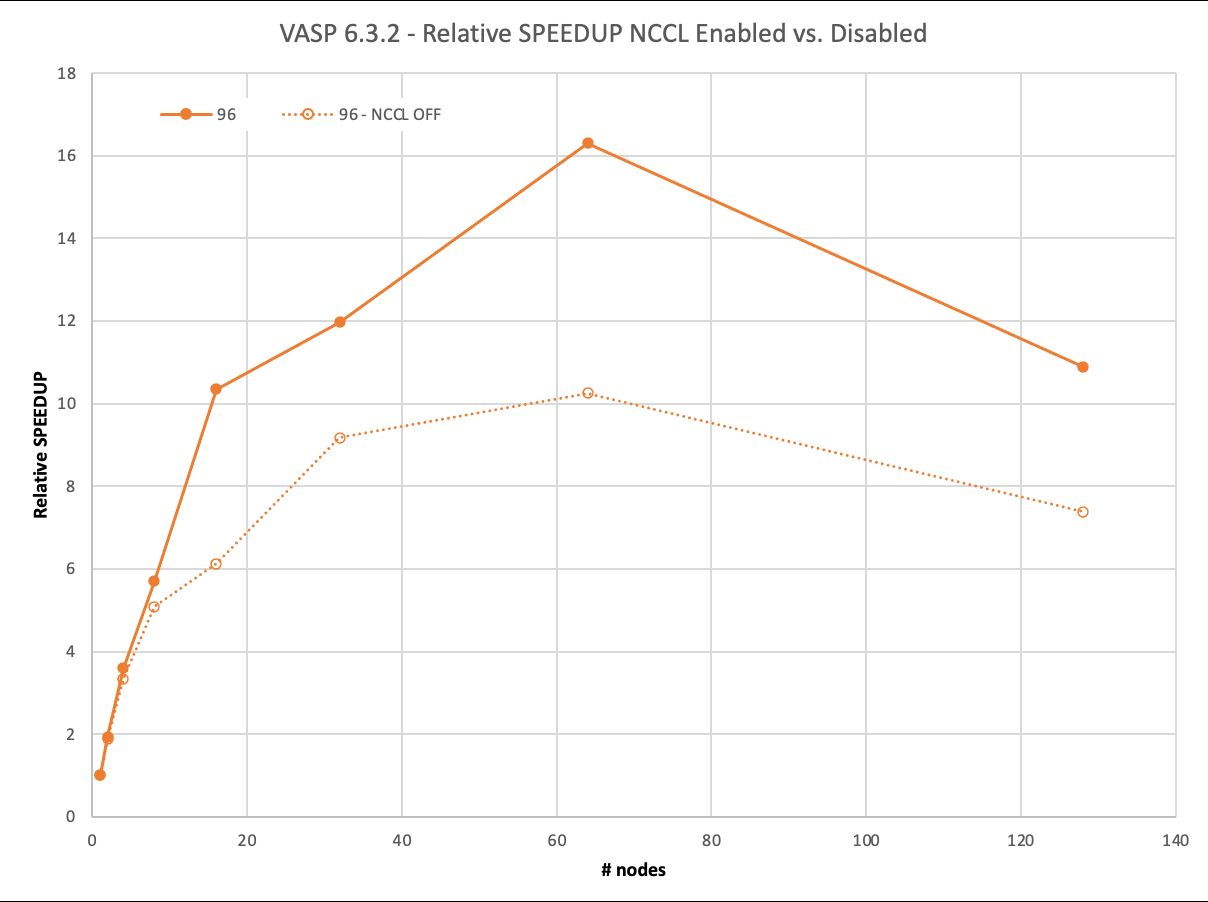
圖 4.96 原子情況下的縮放和性能。啟用 NCCL 的結(jié)果相對(duì)于禁用 NCCL 的單節(jié)點(diǎn)性能進(jìn)行了縮放 .
下一個(gè)例子已經(jīng)是一個(gè)具有計(jì)算挑戰(zhàn)性的問(wèn)題。在單個(gè)節(jié)點(diǎn)上的 8xA100 上,完成具有 216 個(gè)原子的 3x3x2 超級(jí)電池的完整計(jì)算需要超過(guò) 7.5 小時(shí)。
隨著計(jì)算需求的增加,有更多的時(shí)間在后臺(tái)使用 NCCL 異步完成通信。 VASP 在 16 個(gè)節(jié)點(diǎn)之前保持在 91% 以上,僅在 128 個(gè)節(jié)點(diǎn)上接近 50% 。
使用 MPI , VASP 無(wú)法有效隱藏通信,即使在 8 個(gè)節(jié)點(diǎn)上也無(wú)法達(dá)到 90% ,在 64 個(gè)節(jié)點(diǎn)上已降至 41% 。
對(duì)于下一個(gè)具有 324 個(gè)原子的更大 3x3x3 超級(jí)電池,縮放行為的趨勢(shì)保持不變,這需要一整天的時(shí)間才能在單個(gè)節(jié)點(diǎn)上解決。然而,使用 NCCL 和 MPI 之間的差異顯著增加。在使用 NCCL 的 128 個(gè)節(jié)點(diǎn)上,您可以獲得 2 倍的相對(duì)加速。
如果是一個(gè)更大的 4x4x3 超級(jí)電池,包含 576 個(gè)原子,那么使用一個(gè) DGX A100 進(jìn)行完整計(jì)算需要等待 5 天以上。
然而,對(duì)于如此苛刻的數(shù)據(jù)集,必須討論一個(gè)新的影響:內(nèi)存容量和并行化選項(xiàng)。 VASP 提供在 k 點(diǎn)上分配工作負(fù)載,同時(shí)在這種設(shè)置中復(fù)制內(nèi)存。雖然這對(duì)于標(biāo)準(zhǔn) DFT 運(yùn)行更有效,但也有助于提高混合 DFT 計(jì)算的性能,而且無(wú)需保留未使用的可用內(nèi)存。
對(duì)于較小的數(shù)據(jù)集,即使在所有 k 點(diǎn)上進(jìn)行并行化,也很容易適合 8xA100 GPU ,每個(gè)點(diǎn)都有 80GB 的內(nèi)存。對(duì)于 576 原子數(shù)據(jù)集,在單個(gè)節(jié)點(diǎn)上,情況不再如此,我們必須減少 k 點(diǎn)的并行性。從兩個(gè)節(jié)點(diǎn)開(kāi)始,我們可以再次充分利用它。
雖然在圖 6 中無(wú)法區(qū)分,但在 MPI 情況下,兩個(gè)節(jié)點(diǎn)上存在輕微的超線性縮放( 102% 的并行效率)。這是因?yàn)樵趦蓚€(gè)或更多節(jié)點(diǎn)上提升的一個(gè)節(jié)點(diǎn)上的并行度必然降低。然而,這也是你在實(shí)踐中會(huì)做的。
對(duì)于一個(gè)節(jié)點(diǎn)和兩個(gè)節(jié)點(diǎn)上有 768 個(gè)原子的 4x4x4 超級(jí)電池,我們面臨著類似的情況,但超線性縮放效應(yīng)在那里更不明顯。
我們將 4x4x3 和 4x4x4 超級(jí)單元擴(kuò)展到 256 個(gè)節(jié)點(diǎn)。這相當(dāng)于 2048 A100 GPU 。使用 NCCL ,他們實(shí)現(xiàn)了 67% 甚至 75% 的并行效率。這使您能夠在不到 1.5 小時(shí)的時(shí)間內(nèi)生成結(jié)果,而以前在一個(gè)節(jié)點(diǎn)上幾乎需要 12 天的時(shí)間! NCCL 的使用使這種大型計(jì)算的相對(duì)速度比 MPI 快 3 倍。
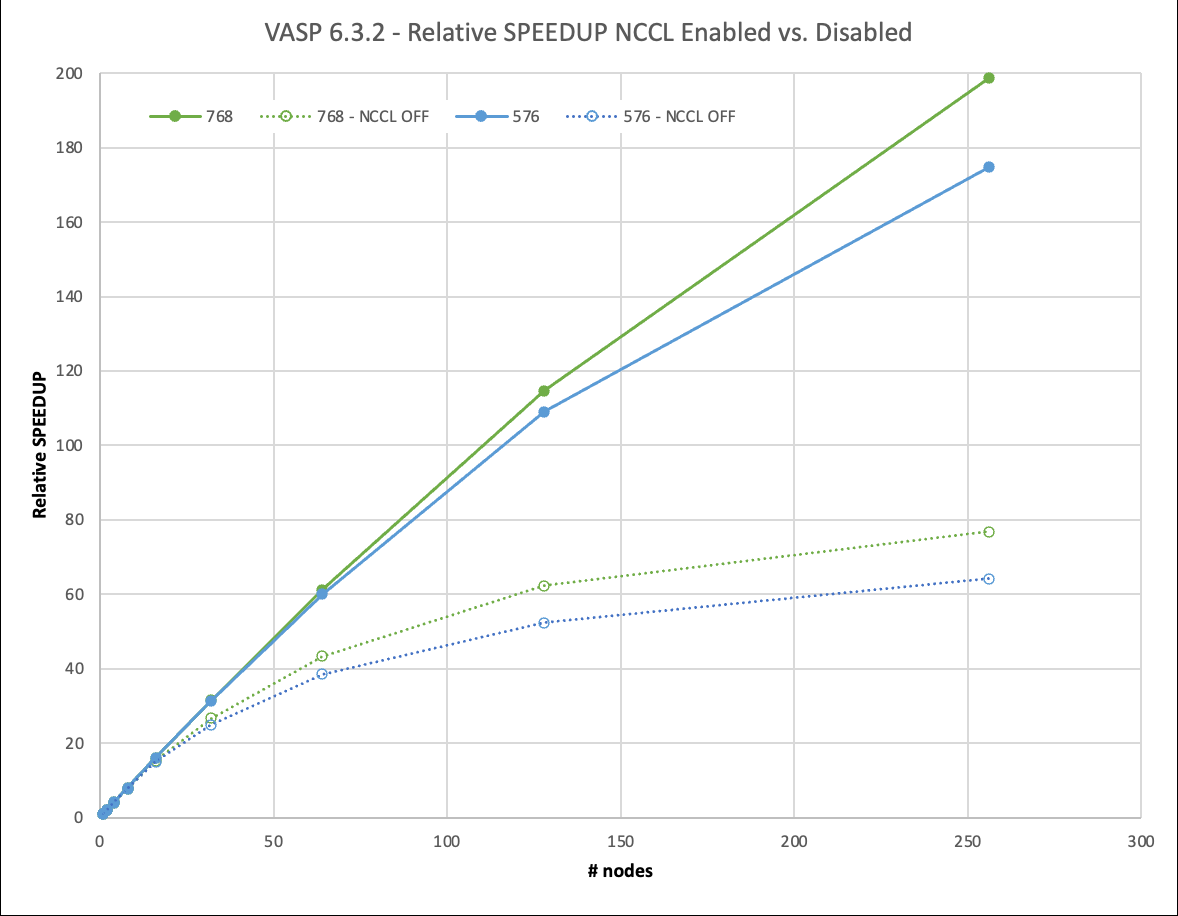
圖 6.576 和 768 原子情況下的縮放和性能。啟用 NCCL 的結(jié)果相對(duì)于禁用 NCCL 的單節(jié)點(diǎn)性能進(jìn)行了縮放。
VASP 模擬中使用 NCCL 的建議
VASP 6.3.2 計(jì)算 HfO2.當(dāng) NVIDIA InfiniBand 網(wǎng)絡(luò)增強(qiáng)的 NVIDIA GPU 加速 HPC 環(huán)境可用時(shí),通過(guò)在多個(gè)節(jié)點(diǎn)上使用 NVIDIA NCCL ,范圍從 96 到 768 個(gè)原子的超級(jí)單元實(shí)現(xiàn)了顯著的性能。
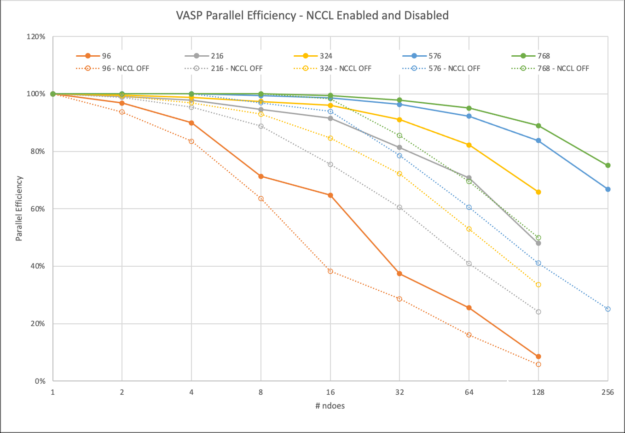
圖 7. NCCL 對(duì)類似于 HfO 的 VASP 模擬有益的一般指南2.在具有多個(gè) HDR InfiniBand 互連的 A100 GPU 上運(yùn)行
基于此測(cè)試,我們建議有能力訪問(wèn) HPC 環(huán)境的用戶考慮以下事項(xiàng):
使用 GPU 加速度運(yùn)行除最小計(jì)算之外的所有計(jì)算。
考慮使用 GPU 和多個(gè)節(jié)點(diǎn)運(yùn)行更大的原子系統(tǒng),以盡量縮短洞察時(shí)間。
使用 NCCL 啟動(dòng)所有多節(jié)點(diǎn)計(jì)算,因?yàn)樗粫?huì)在運(yùn)行大型模型時(shí)提高效率。
初始化 NCCL 時(shí)稍微增加的開(kāi)銷值得權(quán)衡。
總結(jié)
總之,您已經(jīng)看到 VASP 中混合 DFT 的可伸縮性取決于數(shù)據(jù)集的大小。鑒于數(shù)據(jù)集越小,每個(gè)個(gè)體 GPU 的計(jì)算負(fù)載越早耗盡,這在某種程度上是意料之中的。
NCCL 也有助于隱藏所需的通信。圖 7 顯示了具有不同節(jié)點(diǎn)數(shù)的特定數(shù)據(jù)集大小的并行效率水平。對(duì)于大多數(shù)計(jì)算密集型數(shù)據(jù)集, VASP 在 32 個(gè)節(jié)點(diǎn)上的并行效率達(dá)到 80% 以上。對(duì)于我們的一些客戶要求的最苛刻的數(shù)據(jù)集,可以在 256 個(gè)節(jié)點(diǎn)上高效地進(jìn)行橫向擴(kuò)展。
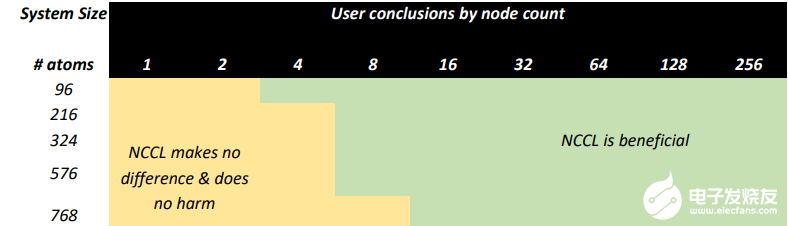
圖 8.作為節(jié)點(diǎn)計(jì)數(shù)函數(shù)的并行效率(對(duì)數(shù)尺度)
VASP 用戶體驗(yàn)
根據(jù)我們與 VASP 用戶的經(jīng)驗(yàn),在 GPU 加速基礎(chǔ)設(shè)施上運(yùn)行 VASP 是一種積極而富有成效的體驗(yàn),使您能夠考慮更大、更復(fù)雜的模型進(jìn)行研究。
在未加速的場(chǎng)景中,您可能運(yùn)行的模型比您想要的小,因?yàn)槟M\(yùn)行時(shí)增長(zhǎng)到無(wú)法忍受的水平。使用具有 GPU 的高性能、低延遲 I / O 基礎(chǔ)設(shè)施,以及具有 Magnum IO 加速技術(shù)(如 NCCL )的 InfiniBand ,可以實(shí)現(xiàn)高效、多節(jié)點(diǎn)并行計(jì)算,并為研究人員提供更大的模型。
HPC 系統(tǒng)管理員的好處
HPC 中心,特別是商業(yè)中心,通常有禁止用戶以低并行效率運(yùn)行作業(yè)的政策。這防止了在短期限內(nèi)或需要高周轉(zhuǎn)率的用戶以犧牲其他用戶的工作等待時(shí)間為代價(jià)使用更多的計(jì)算資源。通常情況下,一個(gè)簡(jiǎn)單的經(jīng)驗(yàn)法則是 50% 的并行效率決定了用戶可能請(qǐng)求的最大節(jié)點(diǎn)數(shù),從而增加了解決問(wèn)題的時(shí)間。
我們?cè)谶@里已經(jīng)表明,通過(guò)將 NCCL 作為 NVIDIA Magnum IO 的一部分,加速 HPC 系統(tǒng)的用戶可以在效率限制內(nèi)保持良好狀態(tài),并在單獨(dú)使用 MPI 時(shí)比可能的工作擴(kuò)展得更遠(yuǎn)。這意味著,在保持 HPC 系統(tǒng)的總體吞吐量處于最高水平的同時(shí),您可以最小化運(yùn)行時(shí)間并最大化模擬次數(shù),以完成新的令人興奮的科學(xué)。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5283瀏覽量
106083 -
AI
+關(guān)注
關(guān)注
88文章
34810瀏覽量
277254
發(fā)布評(píng)論請(qǐng)先 登錄
基于PROFIBUS PROFINET遠(yuǎn)程擴(kuò)展IO的設(shè)計(jì)應(yīng)用
簡(jiǎn)單介紹單片機(jī)IO擴(kuò)展
dfrobot IO擴(kuò)展板 傳感器擴(kuò)展板簡(jiǎn)介

NVIDIA引入云原生超級(jí)計(jì)算架構(gòu)
IO擴(kuò)展芯片PCA9557

Magnum IO存儲(chǔ)的優(yōu)點(diǎn)和實(shí)施
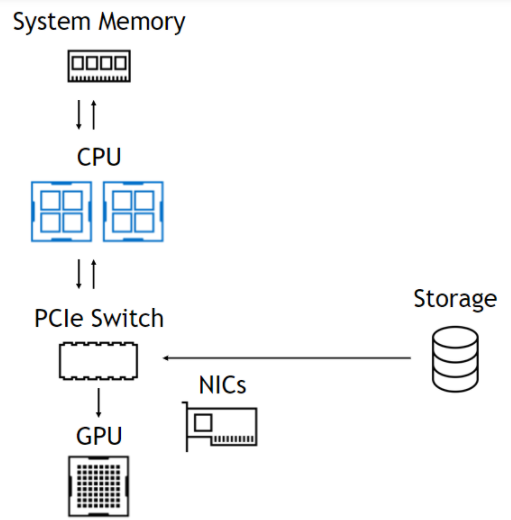
使用Magnum IO用于云本機(jī)超級(jí)計(jì)算架構(gòu)
STM32F43如何通過(guò)FPGA擴(kuò)展IO口
使用IO和繼電器擴(kuò)展器通過(guò)鍵盤控制繼電器
使用 NVIDIA AI Enterprise 3.0 優(yōu)化生產(chǎn)級(jí) AI 的性能和效率





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論