") CPU、GPU與算存互連的復(fù)雜比較與重要性分析
CPU、GPU與算存互連的復(fù)雜比較與重要性分析

隨著深度學(xué)習(xí)、高性能計(jì)算、NLP、AIGC、GLM、AGI的快速發(fā)展,大模型得到快速發(fā)展。2023年科創(chuàng)圈的頂尖技術(shù)無疑是大模型,據(jù)科技部新一代人工智能發(fā)展研究中心發(fā)布的《中國人工智能大模型地圖研究報(bào)告》顯示,我國已發(fā)布79個(gè)參數(shù)規(guī)模超過10億的大模型,幾乎形成了百模大戰(zhàn)的局面。在大模型研發(fā)方面,中國14個(gè)省區(qū)市都在積極開展工作,其中北京擁有38個(gè)項(xiàng)目,廣東擁有20個(gè)項(xiàng)目。
目前,自然語言處理是大模型研發(fā)最活躍的領(lǐng)域,其次是多模態(tài)領(lǐng)域,而在計(jì)算機(jī)視覺和智能語音等領(lǐng)域大模型相對(duì)較少。大學(xué)、科研機(jī)構(gòu)和企業(yè)等不同創(chuàng)新主體都參與了大模型的研發(fā),但學(xué)術(shù)界和產(chǎn)業(yè)界之間的合作研發(fā)仍有待加強(qiáng)。
隨著人工智能大模型參數(shù)量從億級(jí)增長到萬億級(jí),人們對(duì)支撐大模型訓(xùn)練所需的超大規(guī)模算力和網(wǎng)絡(luò)連接的重要性越來越關(guān)注。大模型的訓(xùn)練任務(wù)需要龐大的GPU服務(wù)器集群提供計(jì)算能力,并通過網(wǎng)絡(luò)進(jìn)行海量數(shù)據(jù)交換。然而,即使單個(gè)GPU性能強(qiáng)大,如果網(wǎng)絡(luò)性能跟不上,整個(gè)算力集群的計(jì)算能力也會(huì)大幅下降。因此,大集群并不意味著大算力,相反,GPU集群越大,額外的通信損耗也越多。本文將詳細(xì)介紹CPU和GPU的復(fù)雜性比較,多元算力的結(jié)合(CPU+GPU),算存互連和算力互連的重要性。
多元算力:CPU+GPU
ChatGPT廣受歡迎使得智算中心的關(guān)注度再次上升,GPU同時(shí)也成為各大公司爭(zhēng)相爭(zhēng)奪的對(duì)象。GPU不僅是智算中心的核心,也在超算領(lǐng)域得到廣泛的應(yīng)用。根據(jù)最新一屆TOP500榜單(于2023年5月下旬公布)顯示:
使用加速器或協(xié)處理器的系統(tǒng)從上一屆的179個(gè)增加到185個(gè),其中150個(gè)系統(tǒng)采用英偉達(dá)(NVIDIA)的Volta(如V100)或Ampere(如A100)GPU。
在榜單的前10名中,有7個(gè)系統(tǒng)使用GPU,在前5名中,只有第二名沒有使用GPU。
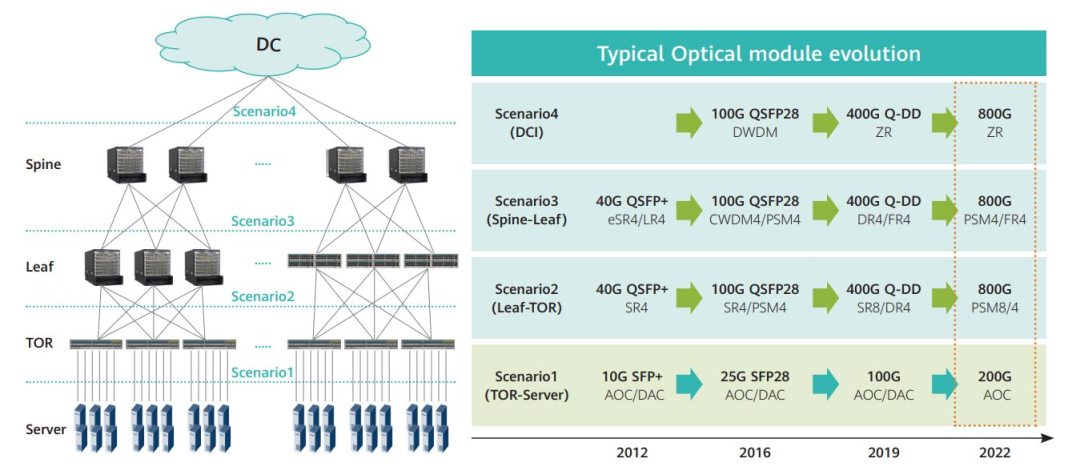
超大規(guī)模數(shù)據(jù)中心架構(gòu)及光模塊升級(jí)路徑
當(dāng)然,CPU仍然是不可或缺的。以榜單前10名為例,AMC EPYC家族處理器占據(jù)4個(gè)位置,英特爾至強(qiáng)家族處理器和IBM的POWER9各占據(jù)2個(gè)位置,而Arm也有1個(gè)位置(富士通A64FX)位居第二位。
通用算力和智能算力相輔相成,可以滿足多樣化的計(jì)算需求。以歐洲高性能計(jì)算聯(lián)合事業(yè)(EuroHPC JU)正在部署的MareNostrum 5為例:基于第四代英特爾至強(qiáng)可擴(kuò)展處理器的通用算力計(jì)劃將于2023年6月開放服務(wù),而基于NVIDIA Grace CPU的"下一代"通用算力以及由第四代英特爾至強(qiáng)可擴(kuò)展處理器和NVIDIA Hopper GPU(如H100)組成的加速算力,則計(jì)劃于2023年下半年投入使用。
一、GPU:大芯片與小芯片
盡管英偉達(dá)在GPU市場(chǎng)上占據(jù)著統(tǒng)治地位,但AMD和英特爾并未放棄競(jìng)爭(zhēng)。以最新的TOP500榜單前10名為例,其中4個(gè)基于AMC EPYC家族處理器的系統(tǒng)中,有2個(gè)搭配AMD Instinct MI250X和NVIDIA A100,前者排名較高,分別位居第一和第三位。
然而,在人工智能應(yīng)用方面,英偉達(dá)GPU的優(yōu)勢(shì)顯著。在GTC 2022上發(fā)布的NVIDIA H100 Tensor Core GPU進(jìn)一步鞏固其領(lǐng)先地位。H100 GPU基于英偉達(dá)Hopper架構(gòu),采用臺(tái)積電(TSMC)N4制程,擁有高達(dá)800億個(gè)晶體管,并在計(jì)算、存儲(chǔ)和連接方面全面提升:
132個(gè)SM(流式多處理器)和第四代Tensor Core使性能翻倍;
比前一代更大的50MB L2緩存和升級(jí)到HBM3的顯存構(gòu)成新的內(nèi)存子系統(tǒng);
第四代NVLink總帶寬達(dá)到900GB/s,支持NVLink網(wǎng)絡(luò),PCIe也升級(jí)到5.0。
在2023年1月,英特爾也推出代號(hào)為Ponte Vecchio的英特爾數(shù)據(jù)中心GPU Max系列,與第四代英特爾至強(qiáng)可擴(kuò)展處理器和英特爾至強(qiáng)CPU Max系列一起發(fā)布。英特爾數(shù)據(jù)中心GPU Max系列利用英特爾的Foveros和EMIB技術(shù),在單個(gè)產(chǎn)品上整合47個(gè)小芯片,集成超過1000億個(gè)晶體管,擁有高達(dá)408MB的L2緩存和128GB的HBM2e顯存,充分體現(xiàn)芯片模塊化的理念。
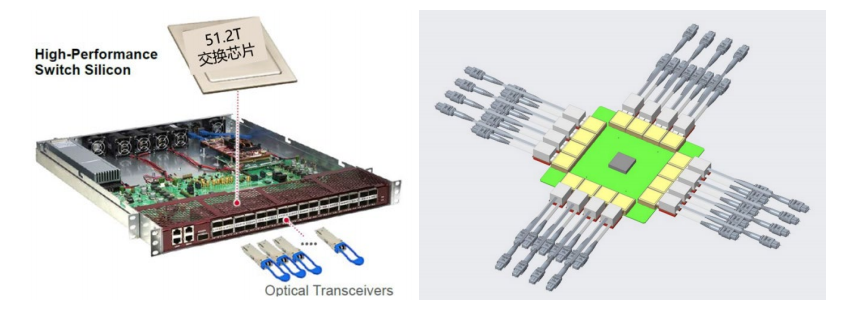
可插拔光模塊與 CPO 對(duì)比
二、CPU:性能核與能效核
通用算力的發(fā)展趨勢(shì)是多元化的,以滿足不同應(yīng)用場(chǎng)景的需求。在手機(jī)、PC和其他終端產(chǎn)品中,經(jīng)過驗(yàn)證的"大小核"架構(gòu)逐漸成為主流,而在服務(wù)器CPU市場(chǎng)也開始流行起來。然而,服務(wù)器的特點(diǎn)是集群作戰(zhàn),并不迫切需要在同一款CPU內(nèi)部實(shí)現(xiàn)大小核的組合。主流廠商正通過提供全是大核或全是小核的CPU來滿足不同客戶的需求,其中大核注重單核性能,適合縱向擴(kuò)展,而小核注重核數(shù)密度,適合橫向擴(kuò)展。
作為big.LITTLE技術(shù)的發(fā)明者,Arm將異構(gòu)核的理念引入服務(wù)器CPU市場(chǎng),并已經(jīng)有一段時(shí)間。Arm的Neoverse平臺(tái)分為三個(gè)系列:
Neoverse V系列用于構(gòu)建高性能CPU,提供高每核心性能,適用于高性能計(jì)算、人工智能機(jī)器學(xué)習(xí)加速等工作負(fù)載;
Neoverse N系列注重橫向擴(kuò)展性能,提供經(jīng)過優(yōu)化的平衡CPU設(shè)計(jì),以提供理想的每瓦性能,適用于橫向擴(kuò)展云、企業(yè)網(wǎng)絡(luò)、智能網(wǎng)卡DPU、定制ASIC加速器、5G基礎(chǔ)設(shè)施以及電源和空間受限的邊緣場(chǎng)景;
Neoverse E系列旨在以最小的功耗支持高數(shù)據(jù)吞吐量,面向網(wǎng)絡(luò)數(shù)據(jù)平面處理器、低功耗網(wǎng)關(guān)的5G部署。
這些系列的設(shè)計(jì)旨在滿足不同領(lǐng)域和應(yīng)用的需求。
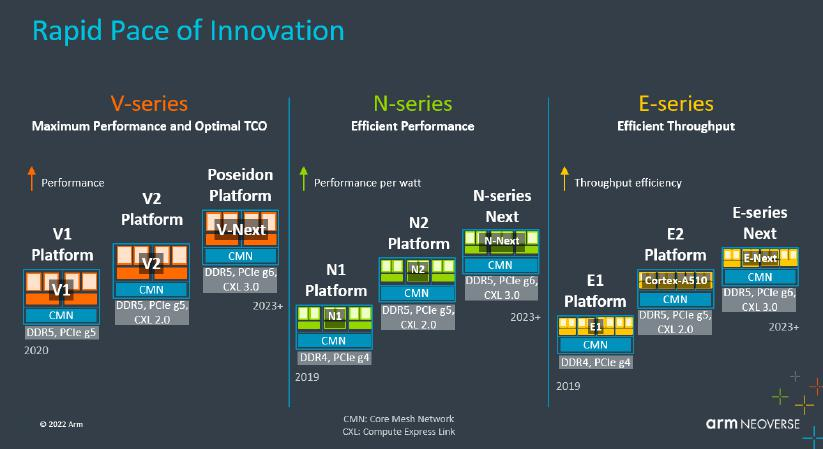
在規(guī)模較大的云計(jì)算中心、智算中心和超級(jí)計(jì)算中心等應(yīng)用場(chǎng)景中,可以將大小核架構(gòu)在數(shù)據(jù)中心市場(chǎng)上的實(shí)踐歸納為兩個(gè)系列:V系列側(cè)重單核性能的縱向擴(kuò)展(Scale-up)而N系列側(cè)重多核性能的橫向擴(kuò)展(Scale-out)。
在這些應(yīng)用場(chǎng)景中,V系列產(chǎn)品的代表包括64核的AWS Graviton3(猜測(cè)為V1)和72核的NVIDIA Grace CPU(V2)而N系列產(chǎn)品除阿里云的128核倚天710(猜測(cè)為N2)外,還在DPU領(lǐng)域得到廣泛應(yīng)用。最近發(fā)布的AmpereOne采用Ampere Computing公司自研的A1核,最多擁有192個(gè)核心,更接近Neoverse N系列的設(shè)計(jì)風(fēng)格。英特爾在面向投資者的會(huì)議上也公布類似的規(guī)劃。

英特爾在面向投資者的會(huì)議上也公布類似的規(guī)劃:
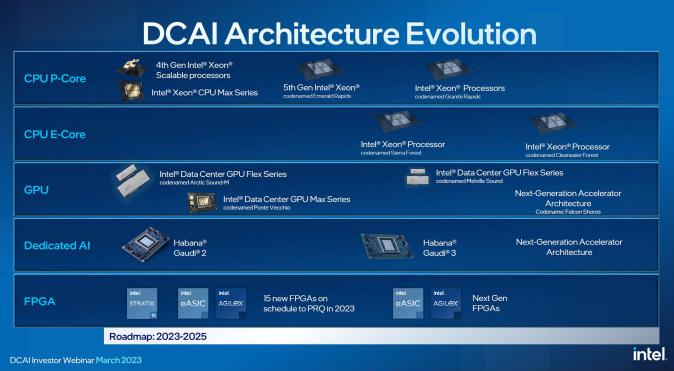
2023年第四季度推出第五代英特爾至強(qiáng)可擴(kuò)展處理器(代號(hào)Emerald Rapids)
2024年推出的代號(hào)為Granite Rapids的下一代產(chǎn)品。這些處理器將延續(xù)目前的性能核(P-Core)路線。另外,2024年上半年推出的代號(hào)為Sierra Forest的CPU將是第一代能效核(E-Core)至強(qiáng)處理器,擁有144個(gè)核心。
第五代英特爾至強(qiáng)可擴(kuò)展處理器與第四代共享平臺(tái)易于遷移而Granite Rapids和Sierra Forest將采用英特爾的3納米制程。P-Core和E-Core的組合已經(jīng)在英特爾的客戶端CPU上得到驗(yàn)證,兩者之間的一個(gè)重要區(qū)別是否支持超線程。E-Core每個(gè)核心只有一個(gè)線程注重能效,適用于追求更高物理核密度的云原生應(yīng)用。
AMD 的策略大同小異。
2022年11月發(fā)布代號(hào)為Genoa的第四代EPYC處理器,采用5納米的Zen 4核心,最高可達(dá)96個(gè)核心。
2023年中,AMD還將推出代號(hào)為Bergamo的“云原生”處理器,據(jù)傳擁有多達(dá)128個(gè)核心,通過縮小核心和緩存來提供更高的核心密度。
雖然性能核和能效核這兩條路線之間存在著核心數(shù)量的差異,但增加核心數(shù)是共識(shí)。隨著CPU核心數(shù)量的持續(xù)增長,對(duì)內(nèi)存帶寬的要求也越來越高,僅僅升級(jí)到DDR5內(nèi)存是不夠的。AMD的第四代EPYC處理器(Genoa)已將每個(gè)CPU的DDR通道數(shù)量從8條擴(kuò)展到12條,Ampere Computing也有類似的規(guī)劃。
然而,擁有超過100個(gè)核心的CPU已經(jīng)超出了一些企業(yè)用戶的實(shí)際需求,而每個(gè)CPU的12條內(nèi)存通道在雙路配置下也給服務(wù)器主板設(shè)計(jì)帶來新的挑戰(zhàn)。在多種因素的影響下,單路服務(wù)器在數(shù)據(jù)中心市場(chǎng)的份額是否會(huì)有顯著增長,這仍然需要拭目以待。
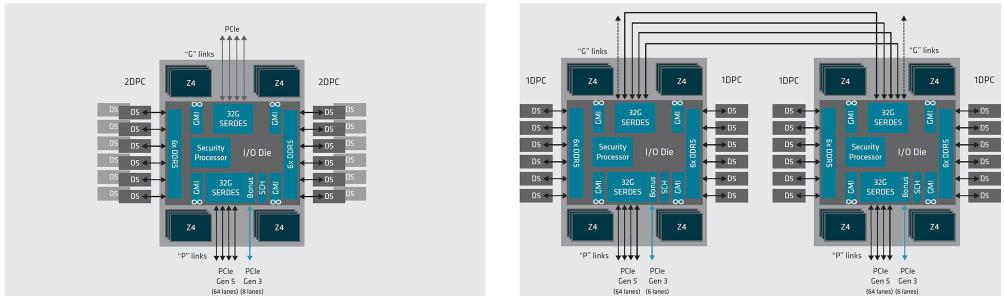
AMD 第四代 EPYC 處理器擁有 12 個(gè) DDR5 內(nèi)存通道,但單路(2DPC)和雙路(1DPC)配置都不超 過 24 個(gè)內(nèi)存槽,比 8 內(nèi)存通道 CPU 的雙路配置(32 個(gè)內(nèi)存槽)還要少。換言之,單 CPU 的內(nèi)存通 道數(shù)增加了,雙路配置的內(nèi)存槽數(shù)反而減少
三、GPU和CPU芯片相比誰更復(fù)雜
在大規(guī)模并行計(jì)算方面,高端GPU(如NVIDIA的A100或AMD的Radeon Instinct MI100)和高端CPU(如Intel的Xeon系列或AMD的EPYC系列)都具有各自的復(fù)雜性。GPU擁有大量的CUDA核心或流處理器,專注于并行計(jì)算,以支持高性能的并行任務(wù)。而高端CPU則具有更多的核心、更高的頻率和復(fù)雜的超線程技術(shù),以提供強(qiáng)大的通用計(jì)算能力。我們從應(yīng)用場(chǎng)景、晶體管數(shù)量、架構(gòu)設(shè)計(jì)幾個(gè)維度來看看。
光芯片是光通信系統(tǒng)中的核心元件
1、應(yīng)用場(chǎng)景
GPU擁有大量的計(jì)算核心、專用存儲(chǔ)器和高速數(shù)據(jù)傳輸通道,其設(shè)計(jì)注重于滿足圖形渲染和計(jì)算密集型應(yīng)用的需求,強(qiáng)調(diào)大規(guī)模并行計(jì)算、內(nèi)存訪問和圖形數(shù)據(jù)流處理。GPU的核心理念是并行處理,通過擁有更多的處理單元,能夠同時(shí)執(zhí)行大量并行任務(wù)。這使得GPU在處理可并行化的工作負(fù)載(如圖形渲染、科學(xué)計(jì)算和深度學(xué)習(xí))時(shí)表現(xiàn)出色。相比之下,CPU專注于通用計(jì)算和廣泛的應(yīng)用領(lǐng)域,通常具有多個(gè)處理核心、高速緩存層次和復(fù)雜的指令集體系結(jié)構(gòu)。
2、晶體管數(shù)量
頂級(jí)的GPU通常擁有更多的晶體管,這是因?yàn)樗鼈冃枰罅康牟⑿刑幚韱卧獊碇С指咝阅苡?jì)算。舉例來說,NVIDIA的A100 GPU擁有約540億個(gè)晶體管,而AMD的EPYC 7742 CPU則包含約390億個(gè)晶體管。晶體管數(shù)量的差異反映了GPU在并行計(jì)算方面的重要性和專注度。
3、架構(gòu)設(shè)計(jì)
從架構(gòu)和設(shè)計(jì)的角度來看,CPU通常被認(rèn)為更復(fù)雜。CPU需要處理各種不同類型的任務(wù),并且需要優(yōu)化以盡可能快地執(zhí)行這些任務(wù)。為了實(shí)現(xiàn)這一目標(biāo),CPU采用了許多復(fù)雜的技術(shù),如流水線、亂序執(zhí)行、分支預(yù)測(cè)和超線程等。這些技術(shù)旨在提高CPU的性能和效率。
相比之下,頂級(jí)的GPU可能在硬件規(guī)模(如晶體管數(shù)量)上更大,但在架構(gòu)和設(shè)計(jì)上可能相對(duì)簡化。GPU的設(shè)計(jì)注重于大規(guī)模并行計(jì)算和圖形數(shù)據(jù)流處理,因此其架構(gòu)更加專注和優(yōu)化于這些特定的任務(wù)。
1)GPU架構(gòu)
GPU具有一些關(guān)鍵的架構(gòu)特性。
首先,它擁有大量的并行處理單元(核心),每個(gè)處理單元可以同時(shí)執(zhí)行指令。如NVIDIA的Turing架構(gòu)具有數(shù)千個(gè)并行處理單元,也稱為CUDA核心。其次,GPU采用分層的內(nèi)存架構(gòu),包括全局內(nèi)存、共享內(nèi)存、本地內(nèi)存和常量內(nèi)存等。這些內(nèi)存類型用于緩存數(shù)據(jù),以減少對(duì)全局內(nèi)存的訪問延遲。另外,GPU利用硬件進(jìn)行線程調(diào)度和執(zhí)行,保持高效率。在NVIDIA的GPU中,線程以warp(32個(gè)線程)的形式進(jìn)行調(diào)度和執(zhí)行。此外,還擁有一些特殊的功能單元,如紋理單元和光柵化單元,這些單元專為圖形渲染而設(shè)計(jì)。最新的GPU還具有為深度學(xué)習(xí)和人工智能設(shè)計(jì)的特殊單元,如張量核心和RT核心。此外,GPU采用了流多處理器和SIMD(單指令多數(shù)據(jù)流)架構(gòu),使得一條指令可以在多個(gè)數(shù)據(jù)上并行執(zhí)行。
具體的GPU架構(gòu)設(shè)計(jì)因制造商和產(chǎn)品線而異,例如NVIDIA的Turing和Ampere架構(gòu)與AMD的RDNA架構(gòu)存在一些關(guān)鍵差異。然而,所有的GPU架構(gòu)都遵循并行處理的基本理念。
2)CPU架構(gòu)
CPU(中央處理單元)的架構(gòu)設(shè)計(jì)涉及多個(gè)領(lǐng)域,包括硬件設(shè)計(jì)、微體系結(jié)構(gòu)和指令集設(shè)計(jì)等。
指令集架構(gòu)(ISA)是CPU的基礎(chǔ),它定義了CPU可以執(zhí)行的操作以及如何編碼這些操作。常見的ISA包括x86(Intel和AMD)、ARM和RISC-V。現(xiàn)代CPU采用流水線技術(shù),將指令分解為多個(gè)階段,以提高指令的吞吐量。CPU還包含緩存和內(nèi)存層次結(jié)構(gòu),以減少訪問內(nèi)存的延遲。亂序執(zhí)行和寄存器重命名是現(xiàn)代CPU的關(guān)鍵優(yōu)化手段,可以提高指令的并行執(zhí)行能力和解決數(shù)據(jù)冒險(xiǎn)問題。分支預(yù)測(cè)是一種優(yōu)化技術(shù),用于預(yù)測(cè)條件跳轉(zhuǎn)指令的結(jié)果,以避免因等待跳轉(zhuǎn)結(jié)果而產(chǎn)生的停頓。現(xiàn)代CPU通常具有多個(gè)處理核心,每個(gè)核心可以獨(dú)立執(zhí)行指令,并且一些CPU還支持多線程技術(shù),可以提高核心的利用率。
CPU架構(gòu)設(shè)計(jì)是一個(gè)極其復(fù)雜的過程,需要考慮性能、能耗、面積、成本和可靠性等多個(gè)因素。
四、Chiplet 與芯片布局
在CPU的Chiplet實(shí)現(xiàn)上,AMD和英特爾有一些不同。從代號(hào)為羅馬(Rome)的第二代EPYC開始,AMD將DDR內(nèi)存控制器、Infinity Fabric和PCIe控制器等I/O器件從CCD中分離出來,集中到一個(gè)獨(dú)立的芯片(IOD)中,充當(dāng)交換機(jī)的角色。這部分芯片仍然采用成熟的14納米制程,而CCD內(nèi)部的8個(gè)核心和L3緩存的占比從56%提高到86%,從7納米制程中獲得更大的收益。通過分離制造IOD和CCD,并按需組合,帶來了許多優(yōu)點(diǎn):
1、獨(dú)立優(yōu)化
根據(jù)I/O、運(yùn)算和存儲(chǔ)(SRAM)的不同需求,選擇適合成本的制程。例如,代號(hào)為Genoa的第四代EPYC處理器將使用5納米制程的CCD搭配6納米制程的IOD。
2、高度靈活
一個(gè)IOD可以搭配不同數(shù)量的CCD,以提供不同核心數(shù)的CPU。例如,代號(hào)為羅馬的第二代EPYC處理器最多支持8個(gè)CCD,但也可以減少到6個(gè)、4個(gè)或2個(gè),因此可以輕松提供8至64個(gè)核心。將CCD視為8核CPU,IOD視為原來服務(wù)器中的北橋或MCH(內(nèi)存控制器中心),第二代EPYC相當(dāng)于一套微型化的八路服務(wù)器。采用這種方法構(gòu)建64核的CPU比在單個(gè)芯片上提供64核要簡化許多,并具有良率和靈活性的優(yōu)勢(shì)。
3、擴(kuò)大規(guī)模更容易
通過增加CCD的數(shù)量,在IOD的支持下,可以輕松獲得更多的CPU核心。例如,第四代EPYC處理器通過使用12個(gè)CCD將核心數(shù)量擴(kuò)展到96個(gè)。這種Chiplet實(shí)現(xiàn)方式為AMD帶來許多優(yōu)勢(shì),并且在制程選擇、靈活性和擴(kuò)展性方面更具有競(jìng)爭(zhēng)力。
AMD 第四代 EPYC 處理器,12 顆 CCD 環(huán)繞 1 顆 IOD
第二至四代EPYC處理器采用星形拓?fù)浣Y(jié)構(gòu),以IOD為中心連接多個(gè)較小規(guī)模的CCD。這種架構(gòu)的優(yōu)勢(shì)在于可以靈活增加PCIe和內(nèi)存控制器的數(shù)量,降低成本。然而,劣勢(shì)在于任意核心與其他資源的距離較遠(yuǎn),可能會(huì)限制帶寬和增加時(shí)延。
在過去,AMD憑借制程優(yōu)勢(shì)和較高的核數(shù),使得EPYC處理器在多核性能上表現(xiàn)出色。然而,隨著競(jìng)爭(zhēng)對(duì)手如英特爾和Arm的制造工藝改進(jìn)以及大核心性能提升,AMD的核數(shù)優(yōu)勢(shì)可能會(huì)減弱,多核性能優(yōu)勢(shì)難以持續(xù)。同時(shí),其他廠商的多核CPU采用網(wǎng)格化布局,通過快速互聯(lián)來減小核心與其他資源的訪問距離,更有效地控制時(shí)延。
五、Arm 新升:NVIDIA Grace 與 AmpereOne
Arm一直希望在服務(wù)器市場(chǎng)上占有一席之地。亞馬遜、高通、華為等企業(yè)都推出基于Arm指令集的服務(wù)器CPU。隨著亞馬遜的Graviton、Ampere Altra等產(chǎn)品在市場(chǎng)上站穩(wěn)腳跟,Arm在服務(wù)器CPU市場(chǎng)上的地位逐漸增強(qiáng)。同時(shí),隨著異構(gòu)計(jì)算的興起,Arm在高性能計(jì)算和AI/ML算力基礎(chǔ)設(shè)施中的影響力也在擴(kuò)大。
英偉達(dá)推出的基于Arm Neoverse架構(gòu)的數(shù)據(jù)中心專用CPU即NVIDIA Grace,具有72個(gè)核心。Grace CPU超級(jí)芯片由兩個(gè)Grace芯片組成,通過NVLink-C2C連接在一起,在單插座內(nèi)提供144個(gè)核心和1TB LPDDR5X內(nèi)存。此外NVIDIA還宣稱Grace可以通過NVLink-C2C與Hopper GPU連接,組成Grace Hopper超級(jí)芯片。
NVIDIA Grace是基于Arm Neoverse V2 IP的重要產(chǎn)品。目前尚未公布NVIDIA Grace的晶體管規(guī)模,但可以參考基于Arm Neoverse V1的AWS Graviton 3和阿里云倚天710的數(shù)據(jù)。根據(jù)推測(cè),基于Arm Neoverse V1的AWS Graviton 3約有550億晶體管,對(duì)應(yīng)64核和8通道DDR5內(nèi)存;基于Arm Neoverse N2的阿里云倚天710約有600億晶體管,對(duì)應(yīng)128核、8通道DDR5內(nèi)存和96通道PCIe 5.0。從NVIDIA Grace Hopper超級(jí)芯片的渲染圖來看,Grace的芯片面積與Hopper接近,已知后者為800億晶體管,因此推測(cè)72核的Grace芯片的晶體管規(guī)模大于Graviton 3和倚天710是合理的,并與Grace基于Neoverse V2(支持Arm V9指令集、SVE2)的情況相符。
Arm Neoverse V2配套的互連方案是CMN-700,在NVIDIA Grace中稱為SCF(Scalable Coherency Fabric可擴(kuò)展一致性結(jié)構(gòu))。英偉達(dá)聲稱Grace的網(wǎng)格支持超過72個(gè)CPU核心的擴(kuò)展,實(shí)際上在英偉達(dá)白皮書的配圖中可以數(shù)出80個(gè)CPU核心。每個(gè)核心有1MB L2緩存,整個(gè)CPU有高達(dá)117MB的L3緩存(平均每個(gè)核心1.625MB),明顯高于其他同級(jí)別的Arm處理器。
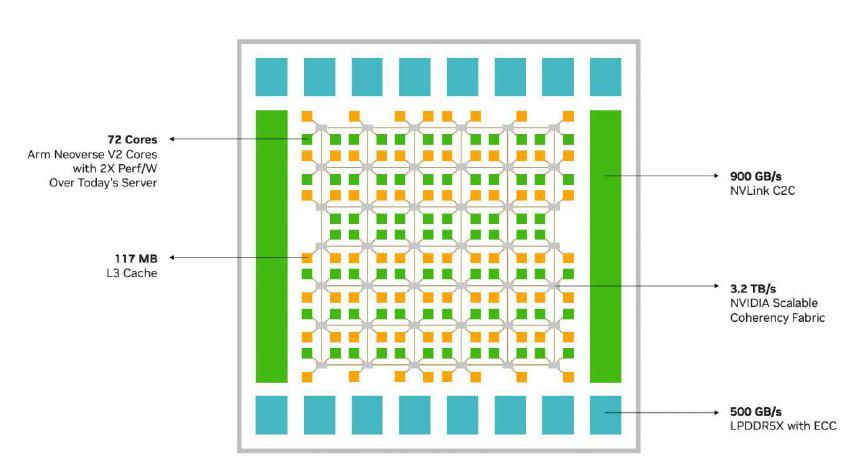
NVIDIA Grace CPU 的網(wǎng)格布局
NVIDIA Grace芯片內(nèi)的SCF提供3.2 TB/s的分段帶寬,連接CPU核心、內(nèi)存控制器和NVLink等系統(tǒng)I/O控制器。網(wǎng)格中的節(jié)點(diǎn)稱為CSN通常每個(gè)CSN連接2個(gè)核心和2個(gè)SCC(SCF緩存分區(qū))。然而,從示意圖可以看出,位于網(wǎng)格角落的4個(gè)CSN連接了2個(gè)核心和1個(gè)SCC,而位于中部兩側(cè)的4個(gè)CSN連接了1個(gè)核心和2個(gè)SCC。總體而言,Grace的網(wǎng)格內(nèi)應(yīng)該有80個(gè)核心和76個(gè)SCC,其中8個(gè)核心可能由于良率等因素而被屏蔽。而網(wǎng)格外圍缺失的4個(gè)核心和8個(gè)SCC的位置被用于連接NVLink、NVLink-C2C、PCIe和LPDDR5X內(nèi)存控制器等。
NVIDIA Grace支持Arm的許多管理特性,如服務(wù)器基礎(chǔ)系統(tǒng)架構(gòu)(SBSA)、服務(wù)器基礎(chǔ)啟動(dòng)要求(SBBR)、內(nèi)存分區(qū)與監(jiān)控(MPAM)和性能監(jiān)控單元(PMU)。通過Arm的內(nèi)存分區(qū)和監(jiān)控功能,可以解決由于共享資源競(jìng)爭(zhēng)而導(dǎo)致的CPU訪問緩存過程中性能下降的問題。高優(yōu)先級(jí)的任務(wù)可以優(yōu)先占用L3緩存,或者根據(jù)虛擬機(jī)預(yù)先劃分資源,實(shí)現(xiàn)業(yè)務(wù)之間的性能隔離。

NVIDIA Grace CPU 超級(jí)芯片
作為最新、最強(qiáng)版本的Arm架構(gòu)核心(Neoverse V2)的代表,NVIDIA Grace引起業(yè)界的高度關(guān)注,尤其是考慮到它將受益于NVIDIA強(qiáng)大的GPGPU技術(shù)。人們?cè)贕TC 2023上終于有機(jī)會(huì)親眼目睹Grace的實(shí)物,但實(shí)際市場(chǎng)表現(xiàn)還需要一段時(shí)間來驗(yàn)證。大家對(duì)Grace在超級(jí)計(jì)算和機(jī)器學(xué)習(xí)等領(lǐng)域的表現(xiàn)抱有很高的期待。

GTC2023 演講中展示的 Grace 超級(jí)芯片實(shí)物
六、網(wǎng)格架構(gòu)的兩類 Chiplet
Ampere One采用流行的Chiplet技術(shù),擁有多達(dá)192個(gè)核心和384MB L2緩存,這并不令人意外。目前普遍的推測(cè)是,它的設(shè)計(jì)類似于AWS Graviton3即將CPU和緩存單獨(dú)放置在一個(gè)die上,DDR控制器的die位于其兩側(cè),而PCIe控制器的die位于其下方。將CPU核心和緩存與負(fù)責(zé)外部I/O的控制器分離在不同的die上,是實(shí)現(xiàn)服務(wù)器CPU的Chiplet的主流做法。
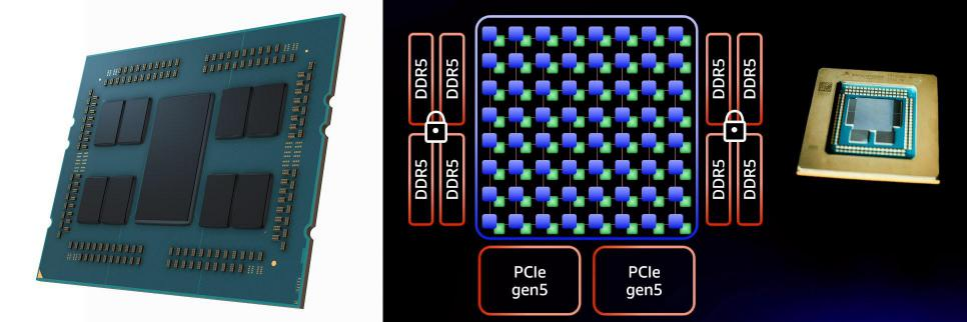
IOD 居 中 的 AMD 第 二 代 EPYC 處 理 器, 與 核 心 die 居 中 的 AWS Graviton3 處理器
正如之前提到的AMD EPYC家族處理器采用星形拓?fù)浣Y(jié)構(gòu),將I/O部分集中放置在一個(gè)IOD上,而CPU核心和緩存(CCD)則環(huán)繞在周圍。這是由網(wǎng)格架構(gòu)的特性所決定的,要求CPU核心和緩存必須位于中央,而I/O部分則分散在外圍。因此,當(dāng)進(jìn)行拆分時(shí),布局會(huì)相反,中央的die會(huì)更大,而周圍的die會(huì)更小。
與EPYC家族的架構(gòu)相比,網(wǎng)格架構(gòu)具有更強(qiáng)的整體性,天生具有單體式(Monolithic)結(jié)構(gòu)不太適合拆分。在網(wǎng)格架構(gòu)中,必須考慮交叉點(diǎn)(節(jié)點(diǎn))的利用率問題,如果有太多的空置交叉點(diǎn),會(huì)導(dǎo)致資源浪費(fèi),因此縮小網(wǎng)格規(guī)模可能更為有效。
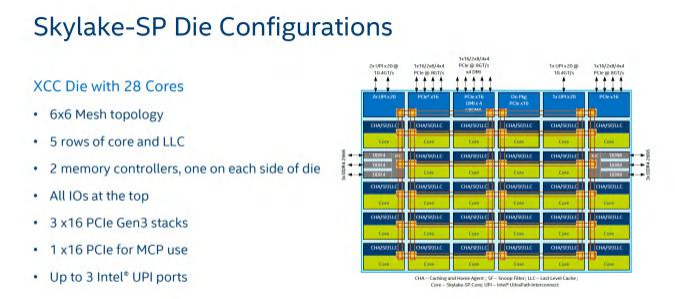
以初代英特爾至強(qiáng)可擴(kuò)展處理器為例,為了滿足核數(shù)(Core Count,CC)從4到28的范圍變化提供三種不同構(gòu)型的die(die chop)。其中,6×6的XCC(eXtreme CC,最多核或極多核)支持最多28個(gè)核心;6×4的HCC(High CC,高核數(shù))支持最多18個(gè)核心;4×4的LCC(Low CC,低核數(shù))支持最多10個(gè)核心。
從這個(gè)角度來看,Ampere One不支持128核及以下是合理的,除非增加die的構(gòu)型,但這涉及到公司規(guī)模和出貨量的支持需要量產(chǎn)來解決。而第四代英特爾至強(qiáng)可擴(kuò)展處理器提供了兩種構(gòu)型的die。
其中,MCC(Medium CC中等核數(shù))主要滿足32核及以下的需求,比代號(hào)Ice Lake的第三代英特爾至強(qiáng)可擴(kuò)展處理器的40核要低,因此網(wǎng)格規(guī)模比后者的7×8少了1列為7×7,最多可以安置34個(gè)核心及其緩存。而36到60個(gè)核心的需求則必須由XCC來滿足,它是前面提到的Chiplet版本,將網(wǎng)格架構(gòu)從中間切割成4等分,非常獨(dú)特。
XCC版本的第四代英特爾至強(qiáng)可擴(kuò)展處理器由兩種互為鏡像的die拼成2×2的大矩陣,因此整體具有高度對(duì)稱性上下和左右都對(duì)稱,而前三代產(chǎn)品和同代的MCC版本則沒有如此對(duì)稱。
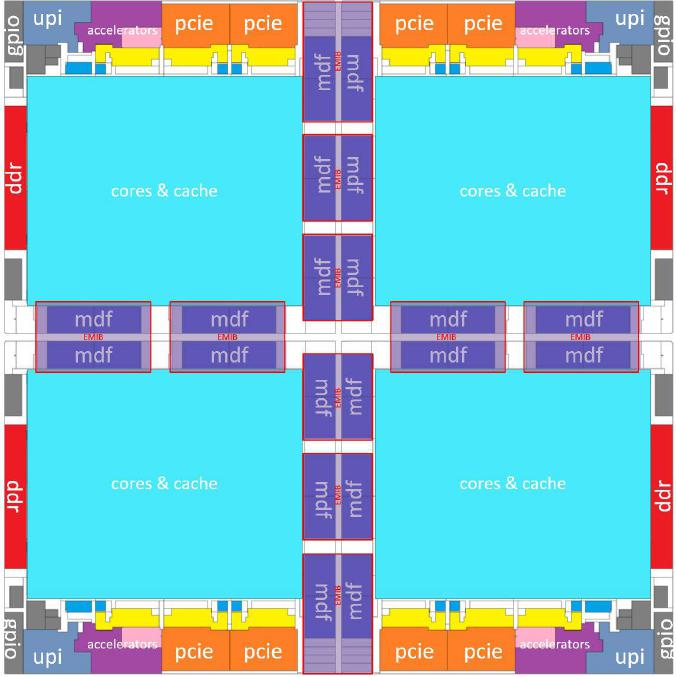
英特爾認(rèn)為,第四代英特爾至強(qiáng)可擴(kuò)展處理器(XCC版本)由4個(gè)die拼接而成,形成了一個(gè)準(zhǔn)單體式(quasi-monolithic)的die。單體式的概念比較容易理解常見的網(wǎng)格架構(gòu)就是這樣的。在第四代英特爾至強(qiáng)可擴(kuò)展處理器中外圈左右是DDR內(nèi)存控制器,上下是PCIe控制器和集成的加速器(DSA/QAT/DLB/IAA),而UPI位于四個(gè)角落,這是典型的網(wǎng)格架構(gòu)布局。

第四代英特爾至強(qiáng)可擴(kuò)展處理器的 EMIB 連接
算存互連:Chiplet 與 CXL
“東數(shù)西存”是“東數(shù)西算”的基礎(chǔ)和前奏,而不是子集。其涉及到數(shù)據(jù)、存儲(chǔ)和計(jì)算之間的關(guān)系。數(shù)據(jù)通常在人口密集的東部產(chǎn)生,而存儲(chǔ)則在地廣人稀的西部進(jìn)行。其中主要難點(diǎn)在于如何以較低的成本完成數(shù)據(jù)傳輸。計(jì)算需要頻繁地訪問數(shù)據(jù),而在跨地域的情況下,網(wǎng)絡(luò)的帶寬和時(shí)延成為難以克服的障礙。
與數(shù)據(jù)傳輸和計(jì)算相比,存儲(chǔ)并不消耗太多能源,但占用大量空間。核心區(qū)域始終是稀缺資源,就像核心城市的核心地段不會(huì)被用來建設(shè)超大規(guī)模的數(shù)據(jù)中心一樣,CPU的核心區(qū)域也只能留給存儲(chǔ)器的硅片面積有限。
實(shí)現(xiàn)“東數(shù)西算”并非一蹴而就的事情,超大規(guī)模的數(shù)據(jù)中心與核心城市也逐漸疏遠(yuǎn)而且并不是越遠(yuǎn)越好。同樣圍繞CPU已經(jīng)建立一套分層的存儲(chǔ)體系,盡管從高速緩存到內(nèi)存都屬于易失性存儲(chǔ)器(內(nèi)存)但通常那些處于中間狀態(tài)的數(shù)據(jù)對(duì)訪問時(shí)延的要求更高,因此需要更靠近核心。如果是需要長期保存的數(shù)據(jù),離核心遠(yuǎn)一些也沒有關(guān)系,而訪問頻率較低的數(shù)據(jù)可以存儲(chǔ)在較遠(yuǎn)的位置(西存)。
距離CPU核心最近的存儲(chǔ)器是各級(jí)緩存(Cache),除了基于SRAM的各級(jí)Cache之外。即使在緩存中也存在遠(yuǎn)近之分。在現(xiàn)代CPU中,L1和L2緩存已經(jīng)成為核心的一部分則需要考慮占用面積的主要是L3緩存。
一、SRAM 的面積律
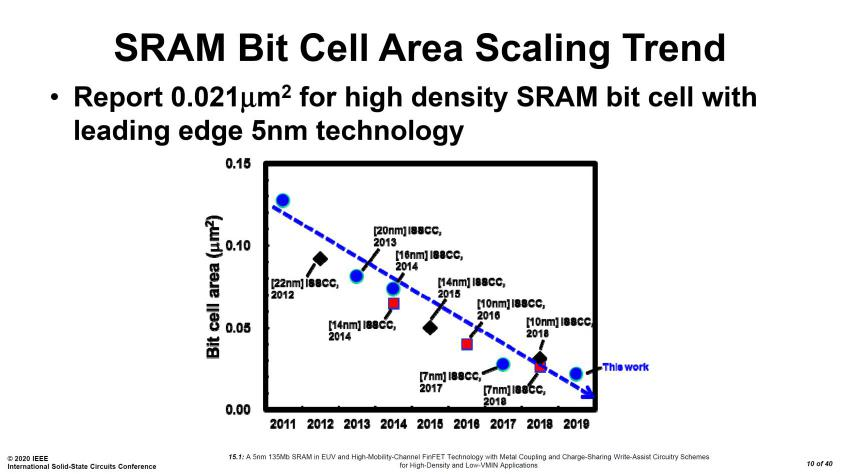
現(xiàn)在是2023年制造工藝正在向3納米邁進(jìn)。臺(tái)積電公布其N3制程的SRAM單元面積為0.0199平方微米,相比N5制程的面積為0.021平方微米,僅縮小了5%。更為困擾的是由于良率和成本問題,預(yù)計(jì)N3并不會(huì)成為臺(tái)積電的主力工藝客戶們更關(guān)注第二代3納米工藝N3E。而N3E的SRAM單元面積為0.021平方微米與N5工藝完全相同。
就成本而言據(jù)傳N3一片晶圓的成本為2萬美元而N5的報(bào)價(jià)為1.6萬美元,這意味著N3的SRAM比N5貴25%。作為參考Intel的7納米制程(10納米)的SRAM面積為0.0312平方微米Intel的4納米制程(7納米)的SRAM面積為0.024平方微米與臺(tái)積電的N5和N3E工藝相當(dāng)。
盡管半導(dǎo)體制造商的報(bào)價(jià)是商業(yè)機(jī)密但SRAM的價(jià)格越來越高,密度也難以再提高。因此將SRAM單獨(dú)制造并與先進(jìn)封裝技術(shù)結(jié)合,以實(shí)現(xiàn)高帶寬和低時(shí)延成為一種合理的選擇。
二、向上堆疊,翻越內(nèi)存墻
當(dāng)前,AMD的架構(gòu)面臨內(nèi)存性能落后的問題。其中原因包括核心數(shù)量較多導(dǎo)致平均每個(gè)核心的內(nèi)存帶寬偏小、核心與內(nèi)存的距離較遠(yuǎn)導(dǎo)致延遲較大以及跨CCD的帶寬過小等。為了彌補(bǔ)訪問內(nèi)存的劣勢(shì),AMD需要使用較大規(guī)模的L3緩存。
然而,從Zen 2到Zen 4架構(gòu),AMD每個(gè)CCD的L3緩存仍然保持32MB的容量并沒有與時(shí)俱進(jìn)。為了解決SRAM規(guī)模滯后的問題,AMD決定將擴(kuò)容SRAM的機(jī)會(huì)獨(dú)立于CPU之外。在代號(hào)為Milan-X的EPYC 7003X系列處理器上,AMD應(yīng)用了第一代3D V-Cache技術(shù)。這些處理器采用Zen 3架構(gòu)核心,每個(gè)緩存(L3緩存芯片,簡稱L3D)的容量為64MB,面積約為41mm2采用7納米工藝制造。
緩存芯片通過混合鍵合、TSV(Through Silicon Vias,硅通孔)工藝與CCD(背面)垂直連接。該單元包含4個(gè)組成部分:最底層的CCD、上層中間部分L3D、以及上層兩側(cè)的支撐結(jié)構(gòu),采用硅材質(zhì)以在垂直方向上平衡整個(gè)結(jié)構(gòu)并將下方CCX(Core Complex,核心復(fù)合體)部分的熱量傳導(dǎo)到頂蓋。

Zen4 CCD 的布局,請(qǐng)感受一下 L3 Cache 的面積
在Zen 3架構(gòu)核心設(shè)計(jì)之初AMD就預(yù)留了必要的邏輯電路和TSV電路,相關(guān)部分大約使CCD的面積增加4%。L3D的堆疊位置恰好位于CCD的L2/L3緩存區(qū)域上方。這一設(shè)計(jì)既符合雙向環(huán)形總線內(nèi)CCD中緩存居中、CPU核心分布在兩側(cè)的布局。又考慮到(L3)緩存的功率密度相對(duì)較低于CPU核心,有利于控制整個(gè)緩存區(qū)域的發(fā)熱量。

3D V-Cache 結(jié)構(gòu)示意圖
Zen 3架構(gòu)的L3緩存由8個(gè)切片組成每片4MB;而L3D設(shè)計(jì)為8個(gè)切片每片8MB。兩組緩存的每個(gè)切片之間有1024個(gè)TSV連接,總共有8192個(gè)連接。AMD聲稱這額外的L3緩存只會(huì)增加4個(gè)周期的延遲。
隨著Zen 4架構(gòu)處理器的推出,第二代3D V-Cache也登場(chǎng)了。它的帶寬從上一代的2TB/s提升到2.5TB/s容量仍然為64MB,制程仍然是7納米,但面積縮減到了36mm2。這個(gè)面積的縮減主要來自TSV部分,AMD聲稱在TSV的最小間距沒有縮小的情況下,相關(guān)區(qū)域的面積縮小了50%。代號(hào)為Genoa-X的EPYC系列產(chǎn)品預(yù)計(jì)將于2023年中發(fā)布。
增加SRAM容量可以大幅提高緩存命中率,減少內(nèi)存延遲對(duì)性能的影響。AMD的3D V-Cache以相對(duì)合理的成本實(shí)現(xiàn)了緩存容量的巨大提升(在CCD內(nèi)L3緩存的基礎(chǔ)上增加了2倍),對(duì)性能的改進(jìn)也非常明顯。

應(yīng)用 3D V-Cache 的 AMD EPYC 7003X 處理器
三、HBM 崛起:從 GPU 到 CPU
HBM(High Bandwidth Memory)是一種由AMD和SK海力士于2014年共同發(fā)布的技術(shù),它使用TSV技術(shù)將多個(gè)DRAM芯片堆疊在一起,大幅提高容量和數(shù)據(jù)傳輸速率。隨后三星、美光、NVIDIA、Synopsys等公司也積極參與這一技術(shù)路線。標(biāo)準(zhǔn)化組織JEDEC也將HBM2列入了標(biāo)準(zhǔn)(JESD235A)并陸續(xù)推出了HBM2e(JESD235B)和HBM3(JESD235C)。主要得益于堆疊封裝和巨大的位寬(單封裝1024位),HBM提供遠(yuǎn)遠(yuǎn)超過其他常見內(nèi)存形式(如DDR DRAM、LPDDR、GDDR等)的帶寬和容量。
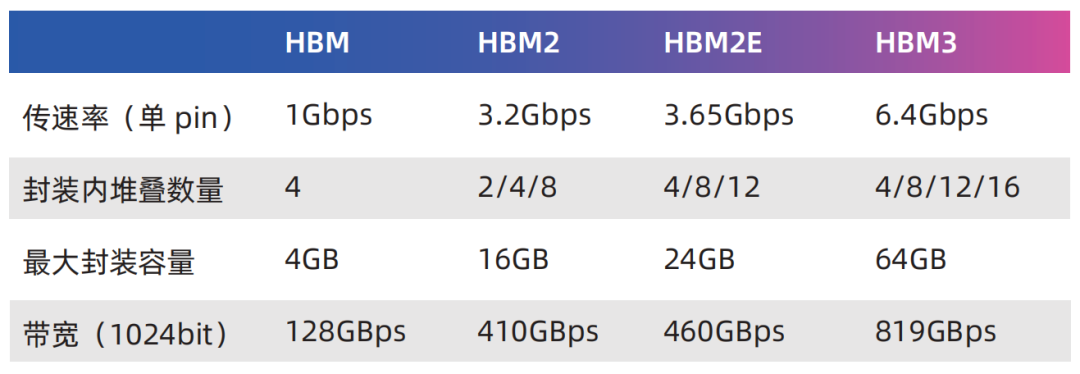
典型的實(shí)現(xiàn)方式是通過2.5D封裝與處理器核心連接,在CPU、GPU等產(chǎn)品中廣泛應(yīng)用。早期有人將HBM視為L4緩存,從TB/s級(jí)別的帶寬來看這個(gè)觀點(diǎn)也是合理的。而從容量的角度來看HBM比SRAM或eDRAM要大得多。
因此,HBM既可以勝任(一部分)緩存的工作也可以作為高性能內(nèi)存使用。AMD是HBM的早期采用者,目前AMD Instinct MI250X計(jì)算卡在單一封裝內(nèi)集成了2顆計(jì)算核心和8顆HBM2e,總?cè)萘繛?28GB,帶寬達(dá)到3276.8GB/s。NVIDIA主要在專業(yè)卡中應(yīng)用HBM其2016年的TESLA P100 HBM版配備了16GB HBM2,隨后的V100則配備了32GB HBM2。目前熱門的A100和H100也都有HBM版,前者最大提供80GB HBM2e,帶寬約為2TB/s;后者升級(jí)到HBM3,帶寬約為3.9TB/s。華為的昇騰910處理器也集成了4顆HBM。
對(duì)于計(jì)算卡、智能網(wǎng)卡、高速FPGA等產(chǎn)品來說,HBM作為GDDR的替代品,應(yīng)用已非常成熟。CPU也已經(jīng)開始集成HBM,其中最突出的案例是曾經(jīng)問鼎超算TOP500的富岳(Fugaku),它采用富士通研發(fā)的A64FX處理器。A64FX基于Armv8.2-A架構(gòu),采用7納米制程,在每個(gè)封裝中集成了4顆HBM2,總?cè)萘繛?2GB,帶寬為1TB/s。
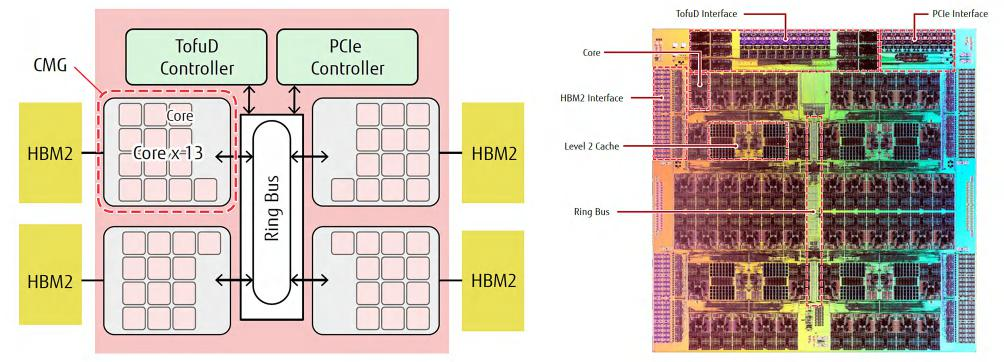
富士通 A64FX CPU
四、向下發(fā)展:基礎(chǔ)層加持
英特爾數(shù)據(jù)中心Max GPU系列引入了Base Tile的概念,可以將其看作是基礎(chǔ)芯片。相對(duì)于中介層的概念,我們也可以將基礎(chǔ)芯片視為基礎(chǔ)層。表面上看基礎(chǔ)層和硅中介層的功能類似,都用于承載計(jì)算核心和高速I/O(如HBM),但實(shí)際上基礎(chǔ)層的功能更加豐富。
硅中介層主要利用成熟的半導(dǎo)體光刻、沉積等工藝(如65納米級(jí)別),在硅上形成高密度的電氣連接。而基礎(chǔ)層更進(jìn)一步:既然已經(jīng)在加工多層圖案,為什么不將邏輯電路等功能也整合進(jìn)去呢?

英特爾數(shù)據(jù)中心 Max GPU
在ISSCC 2022上,英特爾展示了英特爾數(shù)據(jù)中心Max GPU的Chiplet(小芯片)架構(gòu)。其中基礎(chǔ)芯片的面積為640mm2,采用了英特爾7納米制程,這是目前英特爾用于主流處理器的先進(jìn)制程。為什么在"基礎(chǔ)"芯片上需要使用先進(jìn)制程呢?這是因?yàn)橛⑻貭枌⒏咚買/O的SerDes都集成在基礎(chǔ)芯片中,類似于AMD的IOD。這些高速I/O包括HBM PHY、Xe Link PHY、PCIe 5.0以及緩存等。這些電路都更適合使用5納米及以上的工藝制造,將它們與計(jì)算核心解耦后重新打包在同一制程內(nèi)是一個(gè)相當(dāng)合理的選擇。
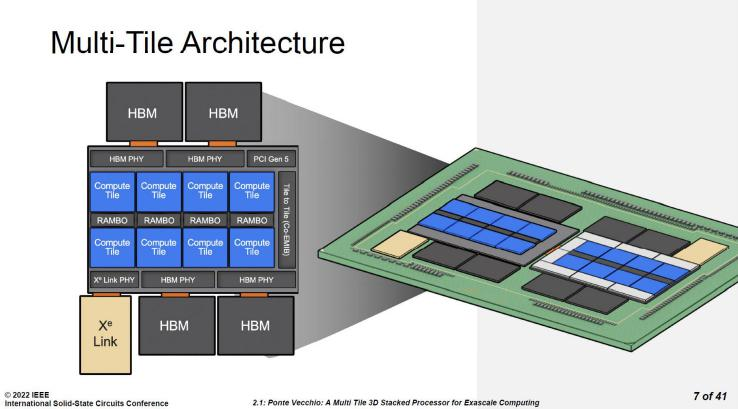
英特爾數(shù)據(jù)中心 Max GPU 的 Chiplet 架構(gòu)
英特爾數(shù)據(jù)中心Max GPU系列通過Foveros封裝技術(shù),在基礎(chǔ)芯片上方疊加了8顆計(jì)算芯片(Compute Tile)和4顆RAMBO芯片(RAMBO Tile)。計(jì)算芯片采用臺(tái)積電N5工藝制造,每顆芯片擁有4MB的L1 Cache。RAMBO是"Random Access Memory Bandwidth Optimized"的縮寫,即帶寬優(yōu)化的隨機(jī)訪問存儲(chǔ)器。獨(dú)立的RAMBO芯片基于英特爾7納米制程,每顆芯片有4個(gè)3.75MB的Bank,總共提供15MB的容量。每組4顆RAMBO芯片共提供了60MB的L3 Cache。此外,在基礎(chǔ)芯片中還有一個(gè)容量為144MB的RAMBO,以及L3 Cache的交換網(wǎng)絡(luò)(Switch Fabric)。
因此,在英特爾數(shù)據(jù)中心Max GPU中,基礎(chǔ)芯片通過Cache交換網(wǎng)絡(luò)將基礎(chǔ)層內(nèi)的144MB Cache與8顆計(jì)算芯片和4顆RAMBO芯片的60MB Cache組織在一起,總共提供了204MB的L2/L3 Cache。整個(gè)封裝由兩組組成,即總共408MB的L2/L3 Cache。每組處理單元通過Xe Link Tile與其他7組進(jìn)行連接。Xe Link芯片采用臺(tái)積電N7工藝制造。

XHPC 的邏輯架構(gòu)
前面已經(jīng)提到,I/O 芯片獨(dú)立是大勢(shì)所趨,共享 Cache 與 I/O 拉近也是趨勢(shì)。英特爾數(shù)據(jù)中心 Max GPU 將 Cache 與各種高 速 I/O 的 PHY 集成在同一芯片內(nèi),正是前述趨勢(shì)的集大成者。 至于 HBM、Xe Link 芯片,以及同一封裝內(nèi)相鄰的基礎(chǔ)芯片,則 通過 EMIB(爆炸圖中的橙色部分)連接在一起。

英特爾數(shù)據(jù)中心 Max GPU 爆炸圖
根據(jù)英特爾在 HotChips 上公布的數(shù)據(jù),英特爾數(shù)據(jù)中心 Max GPU 的 L2 Cache 總帶寬可以達(dá)到 13TB/s。考慮到封裝了兩組基礎(chǔ)芯片和計(jì)算芯片給帶寬打個(gè)對(duì)折,基礎(chǔ)芯片和 4 顆 RAMBO 芯片的帶寬是 6.5TB/s,依舊遠(yuǎn)遠(yuǎn)超過目前至強(qiáng)和 EPYC 的 L2、L3 Cache 的帶寬。其實(shí)之前 AMD 已經(jīng)通過指甲蓋大小的 3D V-Cache 證明 3D 封裝的性能,那就更不用說英特爾數(shù)據(jù)中心 Max GPU 的 RAMBO 及基礎(chǔ)芯片的面積。

回顧一下3D V-Cache的一個(gè)弱點(diǎn)即散熱不良。我們還發(fā)現(xiàn)將Cache集成到基礎(chǔ)芯片中有一個(gè)優(yōu)點(diǎn):將高功耗的計(jì)算核心安排在整個(gè)封裝的上層,更有利于散熱。進(jìn)一步觀察在網(wǎng)格化的處理器架構(gòu)中L3 Cache并不是簡單的幾個(gè)塊(切片),而是分成數(shù)十甚至上百個(gè)單元分別連接到網(wǎng)格節(jié)點(diǎn)上。基礎(chǔ)芯片在垂直方向上可以完全覆蓋或容納處理器芯片,其中的SRAM可以分成相等數(shù)量的單元與處理器的網(wǎng)格節(jié)點(diǎn)相連接。
目前已經(jīng)成熟的3D封裝技術(shù)中,凸點(diǎn)間距在30到50微米的范圍內(nèi)足以滿足每平方毫米內(nèi)數(shù)百至數(shù)千個(gè)連接的需求,可以滿足當(dāng)前網(wǎng)格節(jié)點(diǎn)帶寬的需求。當(dāng)然更高密度的連接也是可行的,10微米甚至亞微米的技術(shù)正在不斷推進(jìn)中,但優(yōu)先考慮的場(chǎng)景是HBM、3D NAND等高度定制化的內(nèi)部堆棧混合鍵合,可能并不適合Chiplet對(duì)靈活性的需求。
五、標(biāo)準(zhǔn)化:Chiplet 與 UCIe
為了實(shí)現(xiàn)這一愿景,2022年3月,通用處理器市場(chǎng)的核心參與者,包括Intel、AMD、Arm等,共同發(fā)布新的互聯(lián)標(biāo)準(zhǔn)UCIe(Universal Chiplet Interconnect Express通用小芯片互連通道),旨在解決Chiplet的行業(yè)標(biāo)準(zhǔn)化問題。這一標(biāo)準(zhǔn)的推出將有助于推動(dòng)Chiplet技術(shù)的發(fā)展和應(yīng)用。
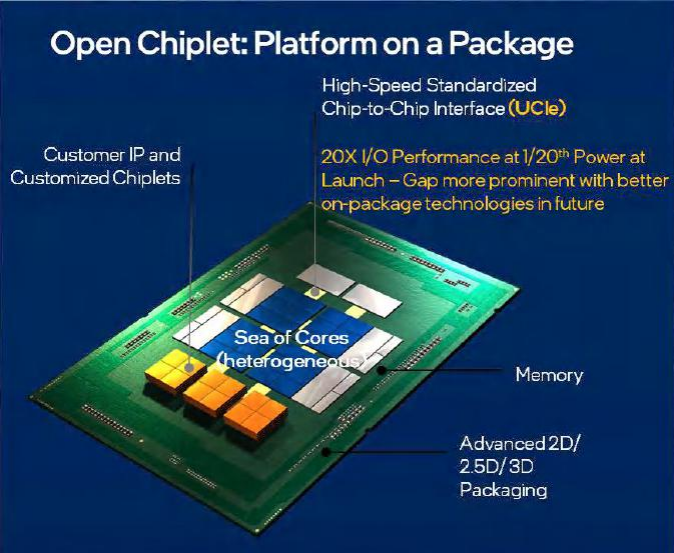
由于標(biāo)準(zhǔn)的主導(dǎo)者與PCIe和CXL(Compute Express Link)已經(jīng)有密切的關(guān)系,因此UCIe非常強(qiáng)調(diào)與PCIe/CXL的協(xié)同,提供在協(xié)議層本地端進(jìn)行PCIe和CXL協(xié)議映射的功能。與CXL的協(xié)同說明UCIe的目標(biāo)不僅僅是解決芯片制造中的互聯(lián)互通問題,而是希望芯片與設(shè)備、設(shè)備與設(shè)備之間的交互是無縫的。
在UCIe 1.0標(biāo)準(zhǔn)中展現(xiàn)兩種層面的應(yīng)用:Chiplet(封裝內(nèi))和Rack space(封裝外)。這意味著UCIe可以在芯片內(nèi)部實(shí)現(xiàn)Chiplet之間的互聯(lián),同時(shí)也可以在封裝外部實(shí)現(xiàn)芯片與設(shè)備之間的互聯(lián)。這種靈活性使得UCIe能夠適應(yīng)不同的應(yīng)用場(chǎng)景。
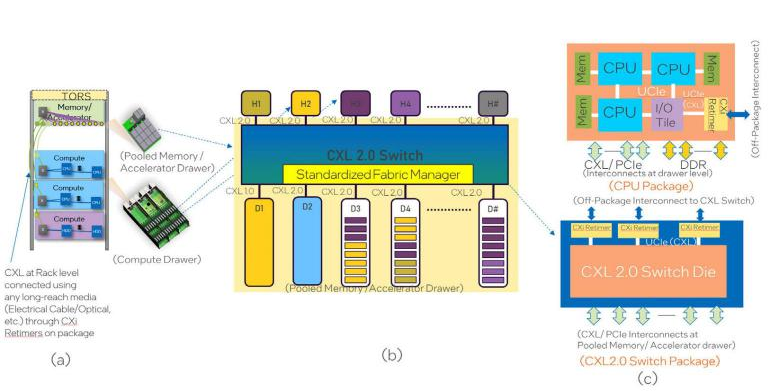
UCIe 規(guī)劃的機(jī)架連接交給了 CXL
1、CXL:內(nèi)存的解耦與擴(kuò)展
相對(duì)于PCIe,CXL最重要的價(jià)值在于減少各子系統(tǒng)內(nèi)存的訪問延遲(理論上PCIe的延遲為100納秒級(jí)別而CXL為10納秒級(jí)別)。例如GPU訪問系統(tǒng)內(nèi)存時(shí),這對(duì)于設(shè)備之間的大容量數(shù)據(jù)交換至關(guān)重要。這種改進(jìn)主要源于兩個(gè)方面:
首先,PCIe在設(shè)計(jì)之初并沒有考慮緩存一致性問題。當(dāng)通過PCIe進(jìn)行跨設(shè)備的DMA讀寫數(shù)據(jù)時(shí),在操作延遲期間,內(nèi)存數(shù)據(jù)可能已經(jīng)發(fā)生變化,因此需要額外的驗(yàn)證過程,這增加了指令復(fù)雜度和延遲。而CXL通過CXL.cache和CXL.memory協(xié)議解決緩存一致性問題,簡化操作也減少延遲。
其次,PCIe的初衷是針對(duì)大流量進(jìn)行優(yōu)化,針對(duì)大數(shù)據(jù)塊(512字節(jié)、1KB、2KB、4KB)進(jìn)行優(yōu)化,希望減少指令開銷。而CXL則針對(duì)64字節(jié)傳輸進(jìn)行優(yōu)化,對(duì)于固定大小的數(shù)據(jù)塊而言操作延遲較低。換句話說,PCIe的協(xié)議特點(diǎn)更適合用于以NVMe SSD為代表的塊存儲(chǔ)設(shè)備,而對(duì)于注重字節(jié)級(jí)尋址能力的計(jì)算型設(shè)備CXL更為適合。
除充分釋放異構(gòu)計(jì)算的算力,CXL還讓內(nèi)存池化的愿景看到了標(biāo)準(zhǔn)化的希望。CXL Type 3設(shè)備的用途是內(nèi)存緩沖,利用CXL.io和CXL.memory的協(xié)議實(shí)現(xiàn)擴(kuò)展遠(yuǎn)端內(nèi)存。在擴(kuò)展后,系統(tǒng)內(nèi)存的帶寬和容量即為本地內(nèi)存和CXL內(nèi)存模塊的疊加。
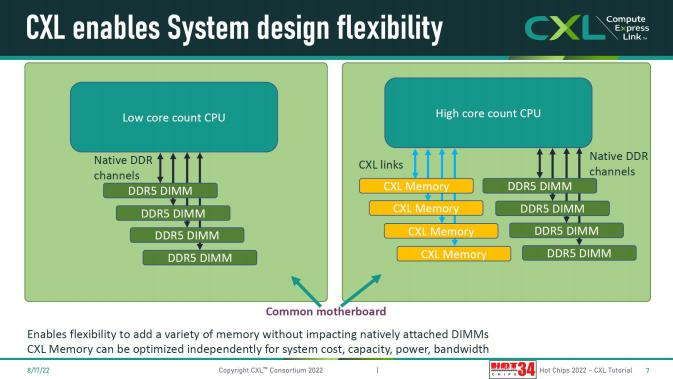
在新一代CPU普遍支持的CXL 1.0/1.1中,CXL內(nèi)存模塊首先實(shí)現(xiàn)主機(jī)級(jí)的內(nèi)存擴(kuò)展,試圖突破傳統(tǒng)CPU內(nèi)存控制器的發(fā)展瓶頸。CPU核心數(shù)量增長的速度遠(yuǎn)遠(yuǎn)快于內(nèi)存通道的增加速度是其中的原因。
在過去的十年間CPU的核心數(shù)量從8到12個(gè)增長到了60甚至96個(gè)核心,而每個(gè)插槽CPU的內(nèi)存通道數(shù)僅從4通道增加到8或12通道。每個(gè)通道的內(nèi)存在此期間也經(jīng)歷三次大的迭代,帶寬大約增加1.5到2倍,存儲(chǔ)密度大約增加4倍。從發(fā)展趨勢(shì)來看,每個(gè)CPU核心所能分配到的內(nèi)存通道數(shù)量在明顯下降,每個(gè)核心可以分配的內(nèi)存容量和內(nèi)存帶寬也有所下降。這是內(nèi)存墻的一種表現(xiàn)形式,導(dǎo)致CPU核心無法充分獲取數(shù)據(jù)以處于滿負(fù)荷的運(yùn)行狀態(tài),從而導(dǎo)致整體計(jì)算效率下降。
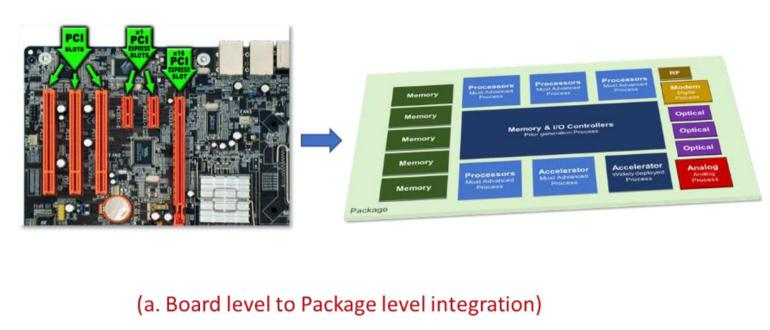
2、UCIe 與異構(gòu)算力
隨著人工智能時(shí)代的到來,異構(gòu)計(jì)算已經(jīng)成為常態(tài)。原則上只要功率密度允許,這些異構(gòu)計(jì)算單元的高密度集成可以由UCIe完成。除集成度的考慮,標(biāo)準(zhǔn)化的Chiplet還帶來功能和成本的靈活性。對(duì)于不需要的單元,在制造時(shí)可以不參與封裝,而對(duì)于傳統(tǒng)處理器而言,無用的單元常常成為無用的"暗硅",意味著成本的浪費(fèi)。一個(gè)典型的例子是DSA,如英特爾第四代可擴(kuò)展至強(qiáng)處理器中的若干加速器,用戶可以付費(fèi)開啟,但是如果用戶不付費(fèi),這些DSA其實(shí)已經(jīng)制造出來。
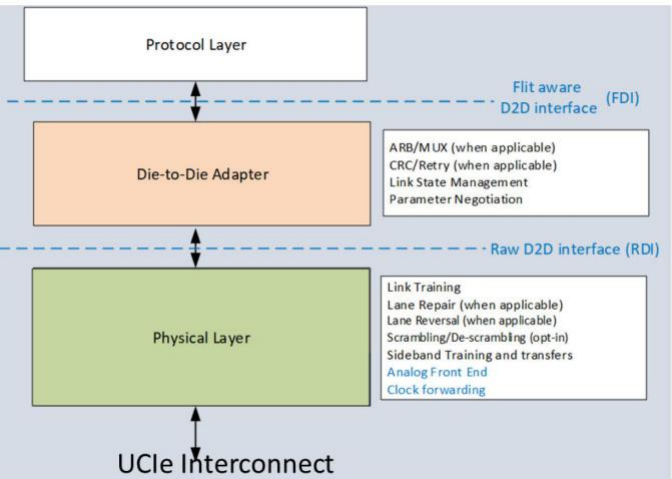
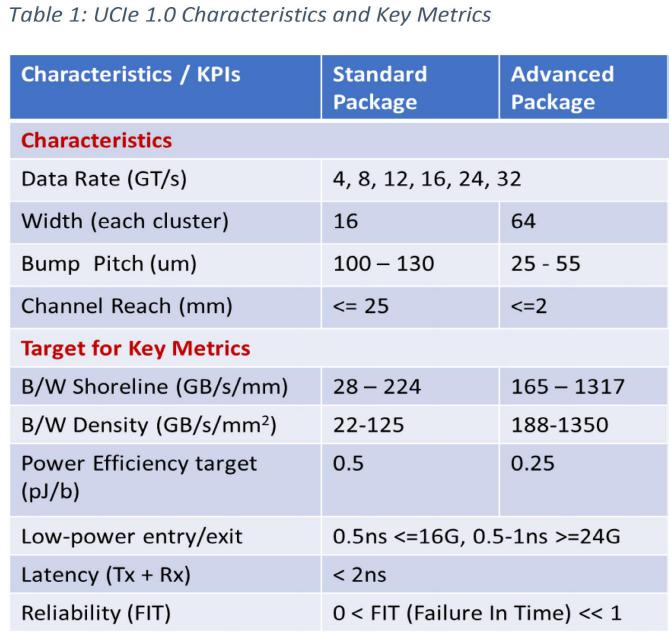
UCIe包括協(xié)議層(Protocol Layer)、適配層(Adapter Layer)和物理層(Physical Layer)。協(xié)議層支持PCIe 6.0、CXL 2.0和CXL 3.0同時(shí)也支持用戶自定義的協(xié)議。根據(jù)不同的封裝等級(jí),UCIe還提供不同的Package模塊。通過使用UCIe的適配層和PHY替換PCIe/CXL的PHY和數(shù)據(jù)包可以實(shí)現(xiàn)更低功耗和性能更優(yōu)的Die-to-Die互連接口。
UCIe考慮了兩種不同等級(jí)的封裝:標(biāo)準(zhǔn)封裝(Standard Package)和先進(jìn)封裝(Advanced Package)。這兩種封裝在凸塊間距、傳輸距離和能耗方面存在數(shù)量級(jí)的差異。例如,對(duì)于先進(jìn)封裝,凸塊間距(Bump Pitch)為25~55μm,代表采用硅中介層的2.5D封裝技術(shù)特點(diǎn)。以英特爾的EMIB為例,當(dāng)前的凸塊間距約為50μm,未來將演進(jìn)至25μm甚至10μm。臺(tái)積電的InFO、CoWoS等也具有類似的規(guī)格和演進(jìn)趨勢(shì)。而標(biāo)準(zhǔn)封裝(2D)的規(guī)格則對(duì)應(yīng)目前應(yīng)用最廣泛的有機(jī)載板。

不同封裝的信號(hào)密度也存在本質(zhì)差異。標(biāo)準(zhǔn)封裝模塊對(duì)應(yīng)的是16對(duì)數(shù)據(jù)線(TX、RX),而高級(jí)封裝模塊則包含64對(duì)數(shù)據(jù)線。每32個(gè)數(shù)據(jù)管腳還額外提供2個(gè)用于Lane修復(fù)的管腳。如果需要更大的帶寬,可以擴(kuò)展更多的模塊并且這些模塊的頻率是可以獨(dú)立設(shè)置的。
需要特別提到的是,UCIe與高速PCIe的深度集成使其更適合高性能應(yīng)用。實(shí)際上,SoC(片上系統(tǒng))是一個(gè)廣義的概念而UCIe面向的是宏觀系統(tǒng)級(jí)的集成。傳統(tǒng)觀念中適合低成本、高密度的SoC可能需要集成大量的收發(fā)器、傳感器、塊存儲(chǔ)設(shè)備等。例如,一些面向邊緣場(chǎng)景的推理應(yīng)用和視頻流處理的IP設(shè)計(jì)企業(yè)非常活躍,這些IP可能需要更靈活的商品化落地方式。由于UCIe不考慮相對(duì)低速設(shè)備的集成,低速、低成本接口的標(biāo)準(zhǔn)化仍然有空間。
算力互連:由內(nèi)及外,由小漸大
隨著"東數(shù)西算"工程的推進(jìn),出現(xiàn)了細(xì)分場(chǎng)景如"東數(shù)西渲"和"東數(shù)西訓(xùn)"。視頻渲染和人工智能(AI)/機(jī)器學(xué)習(xí)(ML)的訓(xùn)練任務(wù)本質(zhì)上都是離線計(jì)算或批處理,可以在"東數(shù)西存"的基礎(chǔ)上進(jìn)行。即原始素材或歷史數(shù)據(jù)傳輸?shù)轿鞑康貐^(qū)的數(shù)據(jù)中心后,在該地區(qū)獨(dú)立完成計(jì)算過程,與東部地區(qū)的數(shù)據(jù)中心交互較少,因此不會(huì)受到跨地域時(shí)延的影響。換句話說,"東數(shù)西渲"和"東數(shù)西訓(xùn)"的業(yè)務(wù)邏輯成立是因?yàn)橛?jì)算與存儲(chǔ)仍然就近耦合,不需要面對(duì)跨地域的"存算分離"挑戰(zhàn)。
在服務(wù)器內(nèi)部,CPU和GPU之間存在類似但不同的關(guān)系。對(duì)于當(dāng)前熱門的大模型來說,對(duì)計(jì)算性能和內(nèi)存容量都有很高的要求。然而,CPU和GPU之間存在一種"錯(cuò)配"現(xiàn)象:GPU的AI算力明顯高于CPU,但直接的內(nèi)存(顯存)容量通常不超過100GB,與CPU的TB級(jí)內(nèi)存容量相比相差一個(gè)數(shù)量級(jí)。幸運(yùn)的是CPU和GPU之間的距離可以縮短,帶寬可以提升。通過消除互連瓶頸,可以大大減少不必要的數(shù)據(jù)移動(dòng),提高GPU的利用率。
一、為GPU而生的CPU
NVIDIA Grace CPU的核心基于Arm Neoverse V2架構(gòu),其互連架構(gòu)SCF(可擴(kuò)展一致性結(jié)構(gòu))可以看作是定制版的Arm CMN-700網(wǎng)格。然而在外部I/O方面,NVIDIA Grace CPU與其他Arm和x86服務(wù)器有很大不同,這體現(xiàn)NVIDIA開發(fā)這款CPU的主要意圖,即為需要高速訪問大內(nèi)存的GPU提供服務(wù)。
在內(nèi)存方面,Grace CPU具有16個(gè)LPDDR5X內(nèi)存控制器,這些內(nèi)存控制器對(duì)應(yīng)著封裝在一起的8個(gè)LPDDR5X芯片,總?cè)萘繛?12GB。經(jīng)過ECC開銷后,可用容量為480GB。因此可以推斷有一個(gè)內(nèi)存控制器及其對(duì)應(yīng)的LPDDR5X內(nèi)存die用于ECC。根據(jù)NVIDIA官方資料,與512GB內(nèi)存容量同時(shí)出現(xiàn)的內(nèi)存帶寬參數(shù)是546GB/s而與480GB(帶ECC)同時(shí)出現(xiàn)的是約500GB/s,實(shí)際的內(nèi)存帶寬應(yīng)該在512GB/s左右。
PCIe控制器是必不可少的Arm CPU的慣例是將部分PCIe通道與CCIX復(fù)用,但這樣的CCIX互連帶寬相對(duì)較弱,不如英特爾專用于CPU間互連的QPI/UPI。
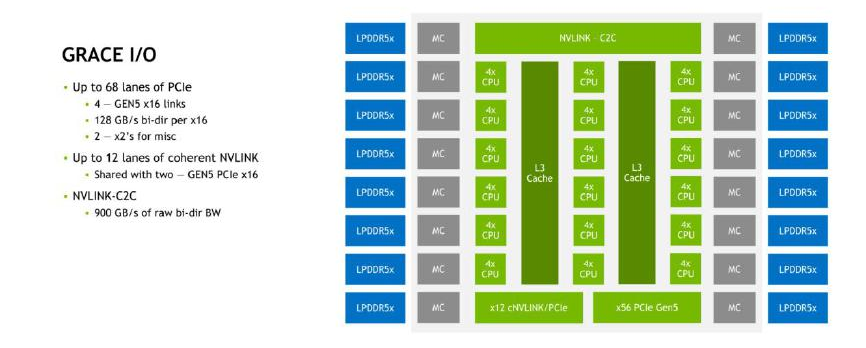
NVIDIA Grace CPU提供68個(gè)PCIe 5.0通道,其中有2個(gè)x16通道可以用作12通道一致性NVLink(cNVLINK)。真正用于芯片(CPU/GPU)之間互連的是cNVLINK/PCIe隔"核"相望的NVLink-C2C接口,其帶寬高達(dá)900GB/s。
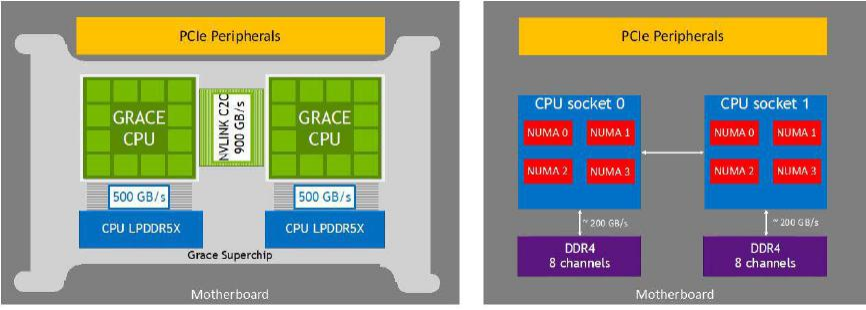
NVLink-C2C中的C2C代表芯片到芯片之間的連接。根據(jù)NVIDIA在ISSCC 2023論文中的描述,NVLink-C2C由10組連接組成(每組9對(duì)信號(hào)和1對(duì)時(shí)鐘),采用NRZ調(diào)制,工作頻率為20GHz,總帶寬為900GB/s。每個(gè)封裝內(nèi)的傳輸距離為30mm,PCB上的傳輸距離為60mm。對(duì)于NVIDIA Grace CPU超級(jí)芯片,使用NVLink-C2C連接兩個(gè)CPU可以構(gòu)成一個(gè)144核的模塊;而對(duì)于NVIDIA Grace Hopper超級(jí)芯片,即將Grace CPU和Hopper GPU進(jìn)行互聯(lián)。
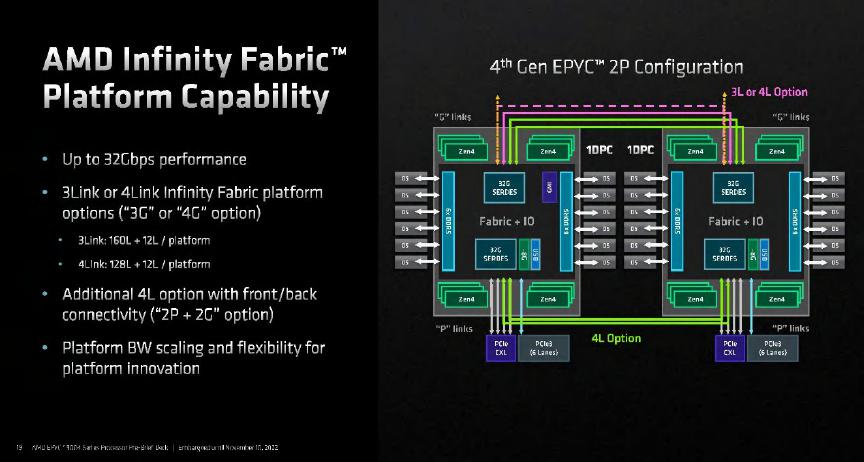
NVLink-C2C的900GB/s帶寬是非常驚人的數(shù)據(jù)。作為參考,Intel代號(hào)為Sapphire Rapids的第四代至強(qiáng)可擴(kuò)展處理器包含3或4組x24 UPI 2.0(@16GT/s)多個(gè)處理器之間的總帶寬接近200GB/s;而AMD第四代EPYC處理器使用的GMI3接口用于CCD與IOD之間的互聯(lián)帶寬為36GB/s,而CPU之間的Infinity Fabric相當(dāng)于16通道PCIe 5.0,帶寬為32GB/s。在雙路EPYC 9004之間可以選擇使用3或4組Infinity Fabric互聯(lián),4組的總帶寬為128GB/s。
通過巨大的帶寬,兩顆Grace CPU可以被緊密聯(lián)系在一起,其"緊密"程度遠(yuǎn)超傳統(tǒng)的多路處理器系統(tǒng),已經(jīng)足以與基于有機(jī)載板的大多數(shù)芯片封裝方案(2D封裝)相匹敵。要超越這個(gè)帶寬,需要引入硅中介層(2.5D封裝)的技術(shù)。例如,蘋果M1 Ultra的Ultra Fusion架構(gòu)利用硅中介層連接兩顆M1 Max芯粒。蘋果聲稱Ultra Fusion可以同時(shí)傳輸超過10,000個(gè)信號(hào),實(shí)現(xiàn)高達(dá)2.5TB/s的低延遲處理器互聯(lián)帶寬。Intel的EMIB也是一種2.5D封裝技術(shù),其芯粒間的互聯(lián)帶寬也應(yīng)當(dāng)達(dá)到TB級(jí)別。
NVLink-C2C的另一個(gè)重要應(yīng)用案例是GH200 Grace Hopper超級(jí)芯片,它將一顆Grace CPU與一顆Hopper GPU進(jìn)行互聯(lián)。Grace Hopper是世界上第一位著名的女性程序員,也是"bug"術(shù)語的發(fā)明者。因此,NVIDIA將這一代CPU和GPU分別命名為Grace和Hopper,這個(gè)命名實(shí)際上有著深刻的意義,充分說明在早期規(guī)劃中,它們就是緊密結(jié)合的關(guān)系。
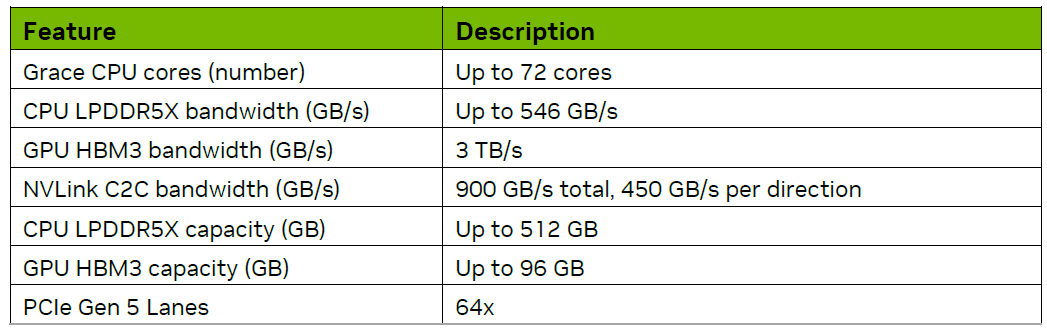
NVIDIA Grace Hopper 超級(jí)芯片主要規(guī)格
CPU和GPU之間的數(shù)據(jù)交換效率(帶寬、延遲)在超大機(jī)器學(xué)習(xí)模型時(shí)代尤為重要。NVIDIA為Hopper GPU配備了大容量高速顯存,全開啟6組顯存控制器,容量達(dá)到96GB,帶寬達(dá)到3TB/s。
相比之下,獨(dú)立的GPU卡H100的顯存配置為80GB,而H100 NVL的雙卡組合則為188GB。Grace CPU搭載了480GB的LPDDR5X內(nèi)存,帶寬略超過500GB/s。盡管Grace的內(nèi)存帶寬與使用DDR5內(nèi)存的競(jìng)品相當(dāng),但CPU與GPU之間的互連才是決定性因素。典型的x86 CPU只能通過PCIe與GPU通信而NVLink-C2C的帶寬遠(yuǎn)超PCIe并具有緩存一致性的優(yōu)勢(shì)。
通過NVLink-C2C Hopper GPU可以順暢地訪問CPU內(nèi)存超過H100 PCIe和H100 SXM。此外,高帶寬的直接尋址還可以轉(zhuǎn)化為容量優(yōu)勢(shì),使Hopper GPU能夠?qū)ぶ?76GB的本地內(nèi)存。
CPU擁有的內(nèi)存容量是GPU無法比擬的,而GPU到CPU之間的互連(PCIe)是瓶頸。NVLink-C2C的帶寬和能效比優(yōu)勢(shì)是GH200 Grace Hopper超級(jí)芯片相對(duì)于x86+GPU方案的核心優(yōu)勢(shì)之一。NVLink-C2C每傳輸1比特?cái)?shù)據(jù)僅消耗1.3皮焦耳能量大約是PCIe 5.0的五分之一具有25倍的能效差異。需要注意的是這種比較并不完全公平,因?yàn)镻CIe是板間通信,與NVLink-C2C的傳輸距離有本質(zhì)區(qū)別。
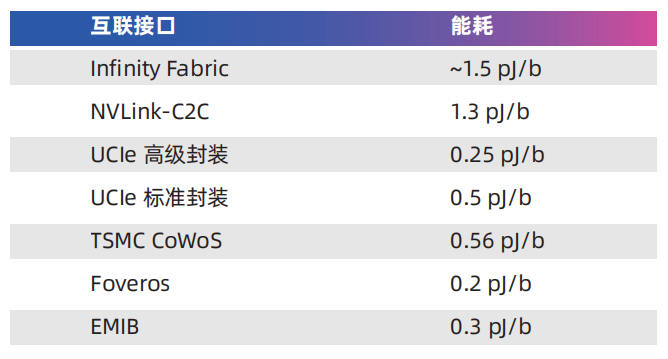
NVLink最初是為了實(shí)現(xiàn)高速GPU之間的數(shù)據(jù)交換而設(shè)計(jì)的,通過NVSwitch的幫助,可以將服務(wù)器內(nèi)部的多個(gè)GPU連接在一起,形成一個(gè)容量成倍增加的顯存池。
二、NVLink 之 GPU 互連
NVLink的目標(biāo)是突破PCIe接口的帶寬瓶頸,提高GPU之間交換數(shù)據(jù)的效率。2016年發(fā)布的P100搭載了第一代NVLink,提供160GB/s的帶寬,相當(dāng)于當(dāng)時(shí)PCIe 3.0 x16帶寬的5倍。V100搭載的NVLink2將帶寬提升到300GB/s 接近PCIe 4.0 x16的5倍。A100搭載了NVLink3帶寬為600GB/s。
H100搭載的是NVLink4,相對(duì)于NVLink3,NVLink4不僅增加了鏈接數(shù)量,內(nèi)涵也有比較重大的變化。NVLink3中,每個(gè)鏈接通道使用4個(gè)50Gb/s差分對(duì),每通道單向25GB/s,雙向50GB/s。A100使用12個(gè)NVLink3鏈接,總共構(gòu)成了600GB/s的帶寬。NVLink4則改為每鏈接通道使用2個(gè)100Gb/s差分對(duì),每通道雙向帶寬依舊為50GB/s,但線路數(shù)量減少了。
在H100上可以提供18個(gè)NVLink4鏈接總共900GB/s帶寬。NVIDIA的GPU大多提供NVLink接口,其中PCIe版本可以通過NVLink Bridge互聯(lián),但規(guī)模有限。更大規(guī)模的互聯(lián)還是得通過主板/基板上的NVLink進(jìn)行組織,與之對(duì)應(yīng)的GPU有NVIDIA私有的規(guī)格SXM。
SXM規(guī)格的NVIDIA GPU主要應(yīng)用于數(shù)據(jù)中心場(chǎng)景其基本形態(tài)為長方形,正面看不到金手指屬于一種mezzanine卡,采用類似CPU插座的水平安裝方式"扣"在主板上,通常是4-GPU或8-GPU一組。其中4-GPU的系統(tǒng)可以不通過NVSwitch即可彼此直連,而8-GPU系統(tǒng)需要使用NVSwitch。
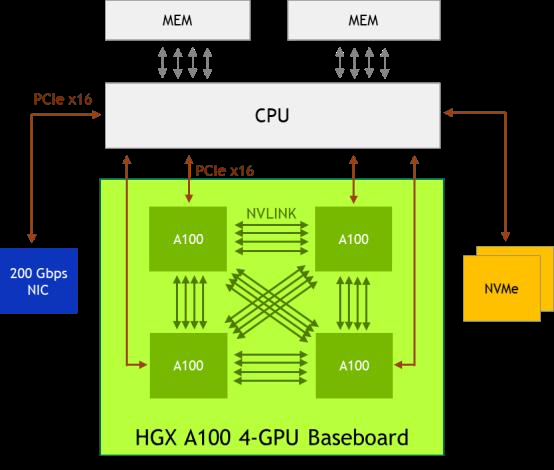
NVIDIA HGX A100 4-GPU 系 統(tǒng) 的 組 織 結(jié) 構(gòu)。 每 個(gè) A100 的 12 條 NVLink 被均分為 3 組,分別與其他 3 個(gè) A100 直聯(lián)
經(jīng)過多代發(fā)展,NVLink已經(jīng)日趨成熟,并開始應(yīng)用于GPU服務(wù)器之間的互連,進(jìn)一步擴(kuò)大GPU(以及其顯存)集群的規(guī)模。
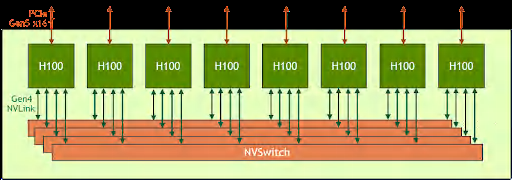
NVIDIA HGX H100 8-GPU 系 統(tǒng) 的 組 織 結(jié) 構(gòu)。 每 個(gè) H100 的 18 條 NVLink 被分為 4 組,分別與 4 個(gè) NVSwitch 互聯(lián)。
三、NVLink 組網(wǎng)超級(jí)集群
在2023年5月底召開的COMPUTEX上,英偉達(dá)宣布了由256個(gè)Grace Hopper超級(jí)芯片組成的集群,總共擁有144TB的GPU內(nèi)存。大語言模型(LLM)如GPT對(duì)顯存容量的需求非常迫切,巨大的顯存容量符合大模型的發(fā)展趨勢(shì)。那么,這個(gè)前所未見的容量是如何實(shí)現(xiàn)的呢?
其中一個(gè)重大創(chuàng)新是NVLink4 Networks,它使得NVLink可以擴(kuò)展到節(jié)點(diǎn)之外。通過DGX A100和DGX H100構(gòu)建的256-GPU SuperPOD的架構(gòu)圖,可以直觀地感受到NVLink4 Networks的特點(diǎn)。在DGX A100 SuperPOD中,每個(gè)DGX節(jié)點(diǎn)的8個(gè)GPU通過NVLink3互聯(lián),而32個(gè)節(jié)點(diǎn)則需要通過HDR InfiniBand 200G網(wǎng)卡和Quantum QM8790交換機(jī)互聯(lián)。在DGX H100 SuperPOD中,節(jié)點(diǎn)內(nèi)部采用NVLink4互聯(lián)8個(gè)GPU,節(jié)點(diǎn)之間通過NVLink4 Network互聯(lián),各節(jié)點(diǎn)接入了稱為NVLink Switch的設(shè)備。
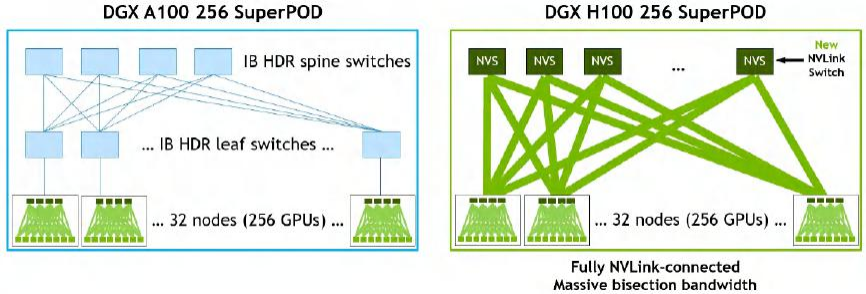
DGX A100 和 DGX H100 256 SuperPOD 架構(gòu)
根據(jù)NVIDIA提供的架構(gòu)信息NVLink Network支持OSFP(Octal Small Form Factor Pluggable)光口,這也符合NVIDIA聲稱的線纜長度從5米增加到20米的說法。DGX H100 SuperPOD使用的NVLink Switch規(guī)格為:端口數(shù)量為128個(gè),有32個(gè)OSFP籠(cage),總帶寬為6.4TB/s。
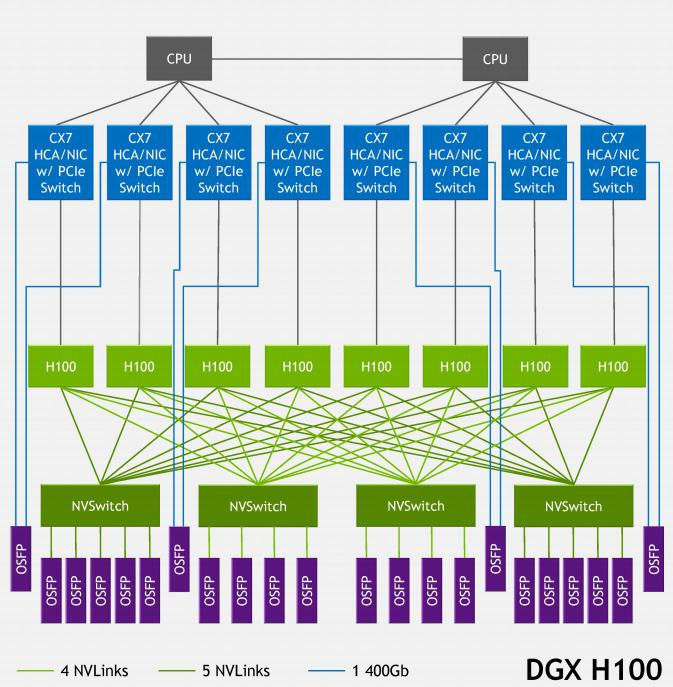
DGX H100 SuperPOD 節(jié)點(diǎn)內(nèi)部的網(wǎng)絡(luò)架構(gòu)
每個(gè)8-GPU節(jié)點(diǎn)內(nèi)部有4個(gè)NVSwitch,對(duì)于DGX H100 SuperPOD每個(gè)NVSwitch都通過4或5條NVLink對(duì)外連接。每條NVLink的帶寬為50GB/s,對(duì)應(yīng)一個(gè)OSFP口相當(dāng)于400Gb/s,非常成熟。每個(gè)節(jié)點(diǎn)總共需要連接18個(gè)OSFP接口,32個(gè)節(jié)點(diǎn)共需要576個(gè)連接,對(duì)應(yīng)18臺(tái)NVLink Switch。
DGX H100也可以(僅)通過InfiniBand互聯(lián),參考DGX H100 BasePOD的配置,其中的DGX H100系統(tǒng)配置了8個(gè)H100、雙路56核第四代英特爾至強(qiáng)可擴(kuò)展處理器、2TB DDR5內(nèi)存,搭配了4塊ConnectX-7網(wǎng)卡——其中3塊雙端口卡用于管理和存儲(chǔ)服務(wù),還有一塊4個(gè)OSFP口的用于計(jì)算網(wǎng)絡(luò)。
回到Grace Hopper超級(jí)芯片,NVIDIA提供了一個(gè)簡化的示意圖其中的Hopper GPU上的18條NVLink4與NVLink Switch相連。NVLink Switch連接了"兩組"Grace Hopper超級(jí)芯片。任何GPU都可以通過NVLink-C2C和NVLink Switch訪問網(wǎng)絡(luò)內(nèi)其他CPU、GPU的內(nèi)存。
NVLink4 Networks的規(guī)模是256個(gè)GPU,注意是GPU而不是超級(jí)芯片,因?yàn)镹VLink4連接是通過H100 GPU提供的。對(duì)于Grace Hopper超級(jí)芯片,這個(gè)集群的內(nèi)存上限就是:(480GB內(nèi)存+96GB顯存)×256節(jié)點(diǎn)=147456GB,即144TB的規(guī)模。假如NVIDIA推出了GTC2022中提到的Grace + 2Hopper,那么按照NVLink Switch的接入能力,那就是128個(gè)Grace和256個(gè)Hopper,整個(gè)集群的內(nèi)存容量將下降至約80TB的量級(jí)。
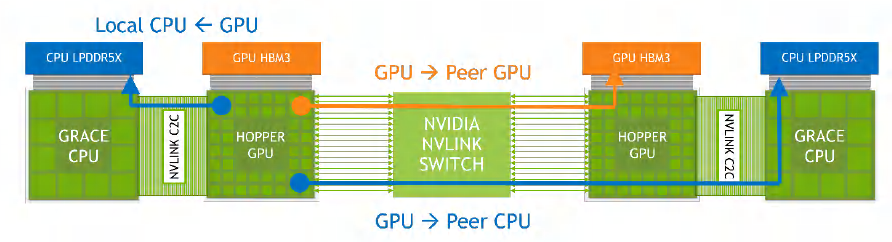
Grace Hooper 超級(jí)芯片之間的互聯(lián)
在COMPUTEX 2023期間,NVIDIA宣布Grace Hopper超級(jí)芯片已經(jīng)量產(chǎn),并發(fā)布了基于此的DGX GH200超級(jí)計(jì)算機(jī)。NVIDIA DGX GH200使用了256組Grace Hopper超級(jí)芯片,以及NVLink互聯(lián),整個(gè)集群提供高達(dá)144TB的可共享的"顯存",以滿足超大模型的需求。以下是一些數(shù)字,讓我們感受一下NVIDIA打造的E級(jí)超算系統(tǒng)的規(guī)模:
算力:1 exa Flops (FP8)
光纖總長度:150英里
風(fēng)扇數(shù)量:2112個(gè)(60mm)
風(fēng)量:7萬立方英尺/分鐘(CFM)
重量:4萬磅
顯存:144TB NVLink
帶寬:230TB/s
從150英里的光纖長度,我們可以感受到其網(wǎng)絡(luò)的復(fù)雜性。這個(gè)集群的整體網(wǎng)絡(luò)資源如下:

由于Grace Hopper芯片上只有一個(gè)CPU和一個(gè)GPU,與DGX H100相比GPU的數(shù)量要少得多。要達(dá)到256個(gè)GPU所需的節(jié)點(diǎn)數(shù)大大增加,這導(dǎo)致NVLink Network的架構(gòu)變得更加復(fù)雜。
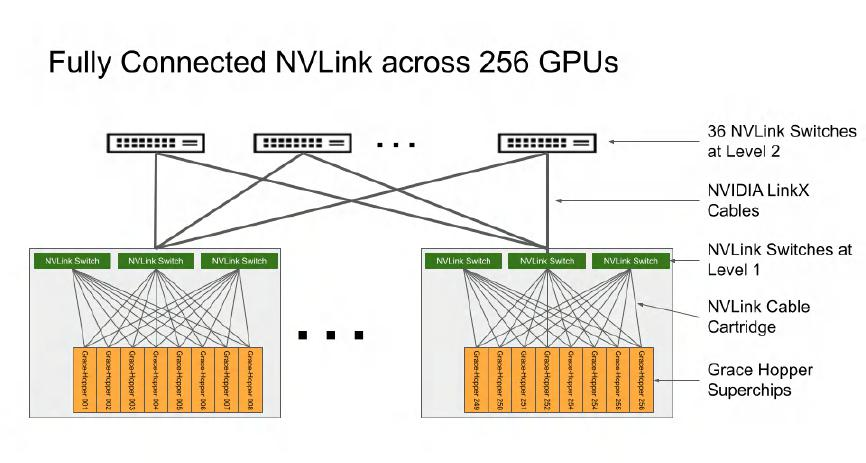
NVIDIA DGX GH200 集群內(nèi)的 NVLink 網(wǎng)絡(luò)架構(gòu)
DGX GH200的每個(gè)節(jié)點(diǎn)有3組NVLink對(duì)外連接,每個(gè)NVLink Switch連接8個(gè)節(jié)點(diǎn)。256個(gè)節(jié)點(diǎn)總共分為32組,每組8個(gè)節(jié)點(diǎn)搭配3臺(tái)L1 NVLink Switch,共需要使用96臺(tái)交換機(jī)。這32組網(wǎng)絡(luò)還要通過36臺(tái)L2 NVLink Switch組織在一起。
與DGX H100 SuperPOD相比GH200的節(jié)點(diǎn)數(shù)量大幅增加,NVLink Network的復(fù)雜度明顯提高了。以下是二者的對(duì)比:
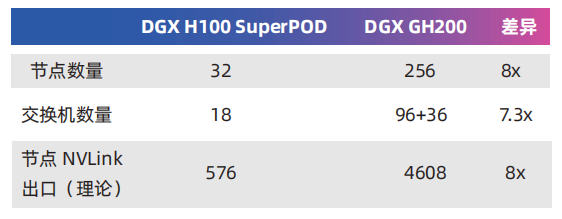
三、InfiniBand 擴(kuò)大規(guī)模
如果需要更大規(guī)模(超過256個(gè)GPU)的集群就需要引入InfiniBand交換機(jī)。對(duì)于Grace Hopper超級(jí)芯片的大規(guī)模集群NVIDIA建議采用Quantum-2交換機(jī)組網(wǎng)提供NDR 400 Gb/s端口。每個(gè)節(jié)點(diǎn)配置BlueField-3 DPU(已集成ConnectX-7),每個(gè)DPU提供2個(gè)400Gb/s端口,總帶寬達(dá)到100GB/s。理論上使用以太網(wǎng)連接也可以達(dá)到類似的帶寬水平,但考慮到NVIDIA收購Mellanox,傾向于使用InfiniBand是可以理解的。

NVIDIA BlueField-3 DPU
基于InfiniBand NDR400組織的Grace Hopper超級(jí)芯片集群有兩種架構(gòu)。一種是完全采用InfiniBand連接,另一種是混合配置NVLink Switch和InfiniBand連接。這兩種架構(gòu)的共同點(diǎn)是每個(gè)節(jié)點(diǎn)都通過雙端口(總共800Gbps)連接InfiniBand交換機(jī),DPU占用x32的PCIe 5.0并由Grace CPU提供PCIe連接。它們的區(qū)別在于后者每個(gè)節(jié)點(diǎn)還通過GPU接入NVLink Switch連接,形成若干NVLink子集群。
很顯然混合配置InfiniBand和NVLink Switch的方案性能更好,因?yàn)椴糠諫PU之間具有更大的帶寬以及對(duì)內(nèi)存的原子操作。例如,NVIDIA計(jì)劃打造超級(jí)計(jì)算機(jī)Helios,它將由4個(gè)DGX GH200系統(tǒng)組成,并通過Quantum-2 InfiniBand 400 Gb/s網(wǎng)絡(luò)組織起來。

四、從 H100 NVL 的角度再看 NVLink
在GTC 2023上,NVIDIA發(fā)布了專為大型語言模型部署的NVIDIA H100 NVL。與H100家族的其他兩個(gè)版本(SXM和PCIe)相比,它具有兩個(gè)特點(diǎn):首先,H100 NVL相當(dāng)于將兩張H100 PCIe通過3塊NVLink橋接連接在一起;其次,每張卡都具有接近完整的94GB顯存,甚至比H100 SXM5還要多。
根據(jù)NVIDIA官方文檔的介紹H100 PCIe的雙插槽NVLink橋接延續(xù)了上一代的A100 PCIe,因此H100 NVL的NVLink互連帶寬為600GB/s仍然比通過PCIe 5.0互連(128GB/s)高出4倍以上。H100 NVL由兩張H100 PCIe卡組合而成,適用于推理應(yīng)用高速NVLink連接使得顯存容量高達(dá)188GB以滿足大型語言模型的(推理)需求。如果將H100 NVL的NVLink互連視為縮水版的NVLink-C2C,這有助于理解NVLink通過算力單元加速內(nèi)存訪問的原理。
藍(lán)海大腦高性能大模型訓(xùn)練平臺(tái)利用工作流體作為中間熱量傳輸?shù)拿浇椋瑢崃坑蔁釁^(qū)傳遞到遠(yuǎn)處再進(jìn)行冷卻。支持多種硬件加速器,包括CPU、GPU、FPGA和AI等,能夠滿足大規(guī)模數(shù)據(jù)處理和復(fù)雜計(jì)算任務(wù)的需求。采用分布式計(jì)算架構(gòu),高效地處理大規(guī)模數(shù)據(jù)和復(fù)雜計(jì)算任務(wù),為深度學(xué)習(xí)、高性能計(jì)算、大模型訓(xùn)練、大型語言模型(LLM)算法的研究和開發(fā)提供強(qiáng)大的算力支持。具有高度的靈活性和可擴(kuò)展性,能夠根據(jù)不同的應(yīng)用場(chǎng)景和需求進(jìn)行定制化配置。可以快速部署和管理各種計(jì)算任務(wù),提高了計(jì)算資源的利用率和效率。

總結(jié)
在計(jì)算領(lǐng)域,CPU和GPU是兩個(gè)關(guān)鍵的組件其在處理數(shù)據(jù)和執(zhí)行任務(wù)時(shí)具有不同的特點(diǎn)和復(fù)雜性。隨著計(jì)算需求的增加,單一的CPU或GPU已經(jīng)無法滿足高性能計(jì)算的要求。因此,多元算力的結(jié)合和算存互連、算力互連的重要性日益凸顯。
作為計(jì)算機(jī)系統(tǒng)的核心,CPU具有高度靈活性和通用性,適用于廣泛的計(jì)算任務(wù)。它通過復(fù)雜的指令集和優(yōu)化的單線程性能,執(zhí)行各種指令和處理復(fù)雜的邏輯運(yùn)算。然而隨著計(jì)算需求的增加,單一的CPU在并行計(jì)算方面的能力有限,無法滿足高性能計(jì)算的要求。
GPU最初設(shè)計(jì)用于圖形渲染和圖像處理,但隨著時(shí)間的推移,其計(jì)算能力得到了極大的提升,成為了高性能計(jì)算的重要組成部分。GPU具有大規(guī)模的并行處理單元和高帶寬的內(nèi)存,能夠同時(shí)執(zhí)行大量的計(jì)算任務(wù)。然而,GPU的復(fù)雜性主要體現(xiàn)在其并行計(jì)算架構(gòu)和專業(yè)化的指令集,這使得編程和優(yōu)化GPU應(yīng)用程序更具挑戰(zhàn)性。
為了充分利用CPU和GPU的優(yōu)勢(shì),多元算力的結(jié)合變得至關(guān)重要。通過將CPU和GPU結(jié)合在一起,可以實(shí)現(xiàn)任務(wù)的并行處理和分工協(xié)作。CPU負(fù)責(zé)處理串行任務(wù)和控制流,而GPU則專注于大規(guī)模的并行計(jì)算。這種多元算力的結(jié)合可以提高整體的計(jì)算性能和效率,并滿足不同應(yīng)用場(chǎng)景的需求。
算存互連是指計(jì)算單元和存儲(chǔ)單元之間的高速互聯(lián),而算力互連是指計(jì)算單元之間的高速互聯(lián)。在高性能計(jì)算中,數(shù)據(jù)的傳輸和訪問速度對(duì)整體性能至關(guān)重要。通過優(yōu)化算存互連和算力互連,可以減少數(shù)據(jù)傳輸?shù)难舆t和瓶頸,提高計(jì)算效率和吞吐量。高效的算存互連和算力互連可以確保數(shù)據(jù)的快速傳輸和協(xié)同計(jì)算,從而提高系統(tǒng)的整體性能。
CPU和GPU在計(jì)算領(lǐng)域扮演著重要的角色,但單一的CPU或GPU已經(jīng)無法滿足高性能計(jì)算的需求。多元算力的結(jié)合、算存互連和算力互連成為了提高計(jì)算性能和效率的關(guān)鍵。通過充分利用CPU和GPU的優(yōu)勢(shì),并優(yōu)化算存互連和算力互連,可以實(shí)現(xiàn)更高水平的計(jì)算能力和應(yīng)用性能,推動(dòng)計(jì)算技術(shù)的發(fā)展和創(chuàng)新。
審核編輯 黃宇
-
cpu
+關(guān)注
關(guān)注
68文章
11011瀏覽量
215249 -
gpu
+關(guān)注
關(guān)注
28文章
4882瀏覽量
130409 -
算力
+關(guān)注
關(guān)注
1文章
1103瀏覽量
15360 -
大模型
+關(guān)注
關(guān)注
2文章
2941瀏覽量
3685
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論