") HaluEval數(shù)據(jù)集的構(gòu)建過程分析
HaluEval數(shù)據(jù)集的構(gòu)建過程分析
一、背景
最近,大語言模型(Large Language Models, LLMs)的快速發(fā)展帶來了自然語言處理領(lǐng)域的范式轉(zhuǎn)變,在各類任務(wù)上的優(yōu)秀表現(xiàn)引發(fā)了眾多關(guān)注。然而,在自然語言社區(qū)迎接和擁抱大語言模型時(shí)代的同時(shí),也迎來了一些屬于大模型時(shí)代的新問題,其中大模型的幻象問題(Hallucination in LLMs)是最具代表性的問題之一。大語言模型的幻象問題是指其生成的內(nèi)容要么與現(xiàn)有的內(nèi)容有沖突,要么無法通過已有的事實(shí)或知識(shí)進(jìn)行驗(yàn)證。圖1是一個(gè)大模型生成的文本中包含幻象的例子,當(dāng)用戶詢問大模型兩磅羽毛和一磅磚頭哪個(gè)更重時(shí),模型給出的答案自相矛盾,首先回答二者一樣重,然后又說兩磅比一磅重。這也就是眾多用戶在與大模型交互過程中遇到的,大模型會(huì)“一本正經(jīng)的胡說八道”的現(xiàn)象。對(duì)用戶來說,大模型生成文本的可信度是一項(xiàng)非常重要的指標(biāo)。如果生成的文本無法信任,則會(huì)嚴(yán)重影響大模型在現(xiàn)實(shí)世界中的應(yīng)用。
為了進(jìn)一步研究大模型幻象的內(nèi)容類型和大模型生成幻象的原因,本文提出了用于大語言模型幻象評(píng)估的基準(zhǔn)——HaluEval。我們基于現(xiàn)有的數(shù)據(jù)集,通過自動(dòng)生成和手動(dòng)標(biāo)注的方式構(gòu)建了大量的幻象數(shù)據(jù)組成HaluEval的數(shù)據(jù)集,其中包含特定于問答、對(duì)話、文本摘要任務(wù)的30000條樣本以及普通用戶查詢的5000條樣本。在本文中,我們?cè)敿?xì)介紹了HaluEval數(shù)據(jù)集的構(gòu)建過程,對(duì)構(gòu)建的數(shù)據(jù)集進(jìn)行了內(nèi)容分析,并初步探索了大模型識(shí)別和減少幻象的策略。
二、HaluEval Benchmark
數(shù)據(jù)構(gòu)建
HaluEval包含35000條帶幻象的樣本和對(duì)應(yīng)的正確樣本用于大模型幻象的評(píng)估。為了生成幻象數(shù)據(jù)集,我們?cè)O(shè)計(jì)了自動(dòng)生成和人工標(biāo)注兩種構(gòu)建方式。對(duì)于特定于問答、基于知識(shí)的對(duì)話和文本摘要三類任務(wù)的樣本,我們采用自動(dòng)生成的構(gòu)建方式;對(duì)于一般的用戶查詢數(shù)據(jù),我們采用人工標(biāo)注的構(gòu)建方式。
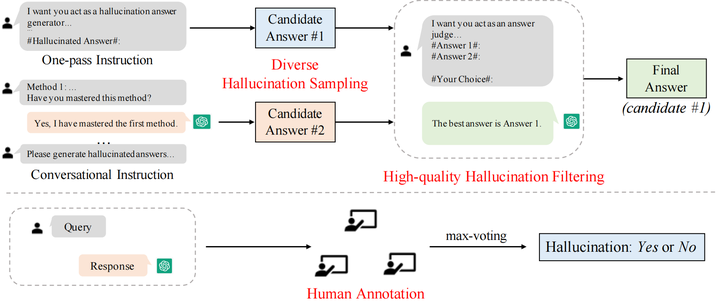
圖2 HaluEval的構(gòu)建方法
自動(dòng)生成
HaluEval中基于任務(wù)的樣本共有30000條,其中問答、基于知識(shí)的對(duì)話和文本摘要各有10000條,分別基于現(xiàn)有的數(shù)據(jù)集HotpotQA,OpenDialKG, CNN/Daily Mail作為種子數(shù)據(jù)進(jìn)行采樣生成。
對(duì)于自動(dòng)生成,我們?cè)O(shè)計(jì)了先采樣后過濾的兩步生成框架,包括多樣化的幻象采樣和高質(zhì)量的幻象過濾兩個(gè)步驟。
多樣化的幻象采樣 為了在采樣指令中給出條理的幻象生成方法,針對(duì)三類任務(wù),我們參考現(xiàn)有的工作將幻象分為不同類型,并向模型輸入各個(gè)類別幻象介紹作為生成幻象樣本的方法。對(duì)于問答任務(wù),將幻象分為comprehension、factualness、specificity和inference四種類型;對(duì)于基于知識(shí)的問答任務(wù),將幻象分為extrinsic-soft,、extrinsic-hard和 extrinsic-grouped三類;對(duì)于文本摘要任務(wù),將幻象分為factual、non-factual和intrinsic三類。考慮到生成的幻象樣本可以有不同的類型,我們提出了兩種采樣方法來生成幻象。如圖2所示,第一種方法采用單指令模式(one-pass instruction),我們直接將包含所有生成幻象方法的完整的指令輸入ChatGPT,然后得到生成的幻象答案;第二種方法采用對(duì)話式的指令(conversational instruction),每輪對(duì)話輸入一種生成幻象的方法,確保ChatGPT掌握了每一類方法,最后根據(jù)學(xué)到的指令生成給定問題的幻象答案。使用兩種策略進(jìn)行采樣,每個(gè)問題可以得到兩個(gè)候選的幻象答案。
高質(zhì)量的幻象過濾 為了得到更加合理和具有挑戰(zhàn)性的幻象樣本,我們對(duì)采樣得到的兩個(gè)候選答案進(jìn)行過濾。為了提高過濾質(zhì)量,我們?cè)诨孟筮^濾指令中加入樣本過濾的示例。與對(duì)兩個(gè)幻象答案進(jìn)行過濾不同,過濾指令中的示例包含正確答案和幻象答案,我們選擇正確答案作為過濾結(jié)果;然后輸入測試樣本的兩個(gè)候選幻象答案讓模型進(jìn)行選擇,期望ChatGPT選擇更加接近真實(shí)答案的幻象答案來增強(qiáng)過濾效果。通過進(jìn)一步的過濾,得到的幻象答案更加難以識(shí)別。我們收集過濾得到的更具挑戰(zhàn)性的候選樣本作為最終的幻象樣本。
在先采樣后過濾的自動(dòng)生成框架中,關(guān)鍵在于設(shè)計(jì)有效的指令來生成和過濾幻象答案。在我們的設(shè)計(jì)中,幻象的采樣指令包括意圖描述、幻象模式和幻象示例三部分,圖3為問答任務(wù)的采樣指令,其中藍(lán)色部分表示意圖描述,紅色部分為幻象模式,綠色部分為幻象示例;幻象的過濾指令包括意圖描述和過濾示例兩部分,圖4為問答任務(wù)的幻象過濾指令,其中藍(lán)色部分表示意圖描述,綠色部分為過濾示例。

圖3 問答任務(wù)的幻象采樣指令
 圖4 問答任務(wù)的幻象過濾指令
圖4 問答任務(wù)的幻象過濾指令
人工標(biāo)注
對(duì)于一般的用戶查詢,我們采用人工標(biāo)注的方法構(gòu)建數(shù)據(jù)。我們邀請(qǐng)三位專家對(duì)來自Alpaca數(shù)據(jù)集的普通用戶查詢和ChatGPT回復(fù)進(jìn)行人工標(biāo)注,判斷ChatGPT的回復(fù)中是否包含幻象并標(biāo)注包含幻象的片段。在進(jìn)行人工標(biāo)注之前,為了篩選出更有可能產(chǎn)生幻覺的用戶查詢,我們首先設(shè)計(jì)了一個(gè)預(yù)選程序。具體來說,我們使用 ChatGPT 對(duì)每個(gè)用戶查詢生成三個(gè)響應(yīng),然后使用 BERTScore 計(jì)算它們的平均語義相似度,最終保留了 5000 個(gè)相似度最低的用戶查詢。如圖2所示,篩選出來的每個(gè)樣本由三個(gè)專家進(jìn)行標(biāo)記,標(biāo)注者從三個(gè)方面判斷回復(fù)中是否包含幻象并標(biāo)注幻象所在位置:unverifiable,、non-factual和irrelevant,我們最終采用最大投票策略來確定回復(fù)中是否包含幻象。
基準(zhǔn)使用
為了幫助大家更好地使用HaluEval,我們提出了使用HaluEval來進(jìn)行大模型幻象研究的三個(gè)可能的方向。
基于HaluEval中生成和注釋的幻象樣本,研究人員可以分析大模型產(chǎn)生幻象的查詢屬于什么主題;
HaluEval可以用于評(píng)估大模型識(shí)別幻象的能力,例如給定一個(gè)問題及答案,要求大模型判斷答案中是否包含幻象;
HaluEval包含正確樣本和幻象樣本,因此也可用于評(píng)估大模型的輸出是否包含幻象。
三、實(shí)驗(yàn)
在實(shí)驗(yàn)部分,為了測試大模型在HaluEval上的幻象識(shí)別表現(xiàn),我們使用所構(gòu)造的HaluEval,在davinci、text-davinci-002、text-davinci-003和gpt-3.5-turbo四個(gè)模型上進(jìn)行了幻象識(shí)別實(shí)驗(yàn),并針對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行了詳細(xì)分析,最后提出了一些可能對(duì)提高識(shí)別效果有用的策略。
幻象識(shí)別實(shí)驗(yàn)
在幻象識(shí)別實(shí)驗(yàn)中,對(duì)于每一個(gè)測試樣本我們以50%的概率從幻象答案和正確答案中選擇一個(gè)作為測試答案,將問題與測試答案一起輸入模型,讓模型判斷測試答案中是否包含幻象。如圖5所示,類似于幻象生成和過濾的步驟,我們?cè)O(shè)計(jì)了用于幻象識(shí)別的指令,包括意圖描述、幻象模式和幻象識(shí)別示例,并在上述四個(gè)模型上進(jìn)行測試。表1中展示了四個(gè)模型在幻象識(shí)別任務(wù)上的準(zhǔn)確率。

圖5 問答任務(wù)的幻象識(shí)別指令
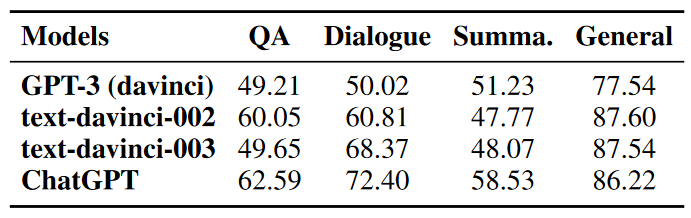
表1 幻象識(shí)別實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)結(jié)果表明,LLM在識(shí)別文本中的幻象這一任務(wù)上表現(xiàn)不佳,ChatGPT在文本摘要任務(wù)上僅達(dá)到58.53%的準(zhǔn)確率,與50%的隨機(jī)概率相差不大;而其他模型例如GPT-3在問答、對(duì)話和摘要任務(wù)上的準(zhǔn)確率幾乎都在50%左右。
為了進(jìn)一步分析ChatGPT沒有檢測出的幻象樣本,我們使用LDA對(duì)所有的測試樣本和檢測失敗樣本進(jìn)行聚類,并對(duì)聚類得到的主題進(jìn)行可視化。我們將各個(gè)數(shù)據(jù)集的測試數(shù)據(jù)聚類為10個(gè)主題,并將其中檢測失敗的主題標(biāo)記為紅色,如圖6所示。從聚類結(jié)果來看,我們發(fā)現(xiàn)LLM無法識(shí)別的幻象集中在幾個(gè)特定的主題。例如QA中的電影、公司、樂隊(duì);對(duì)話中的書籍、電影、科學(xué);摘要中的學(xué)校、政府、家庭;普通用戶查詢中的技術(shù)、氣候和語言等話題。
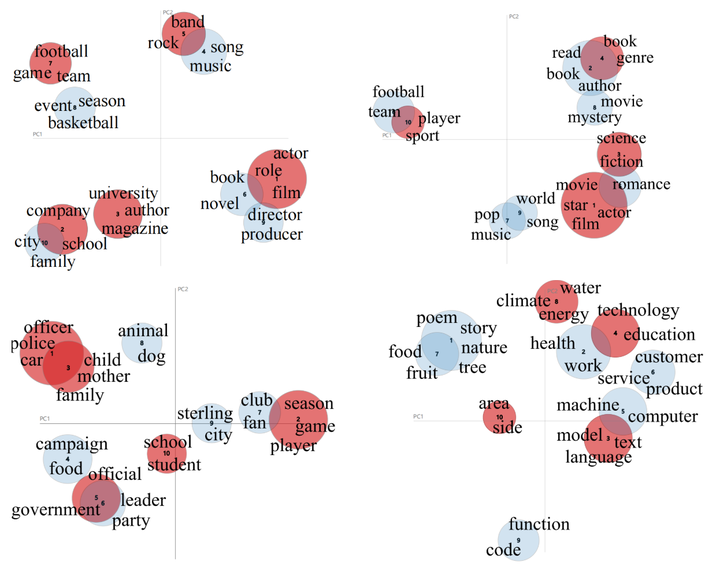
圖6 主題聚類
提升策略
鑒于現(xiàn)有的LLM在幻象識(shí)別方面表現(xiàn)欠佳,我們嘗試提出幾種策略來提升大模型識(shí)別幻象的能力,包括知識(shí)檢索、思維鏈推理和樣本對(duì)比。我們使用提出的三種策略在ChatGPT上重新進(jìn)行幻象識(shí)別實(shí)驗(yàn),下表為使用各個(gè)策略后ChatGPT的幻象識(shí)別準(zhǔn)確率。
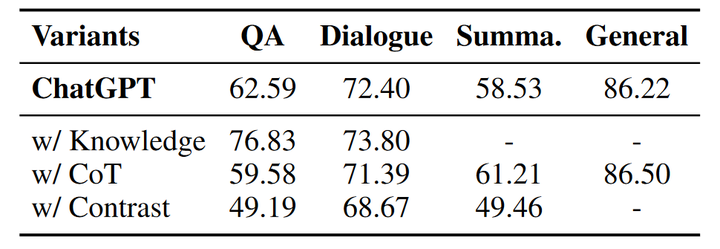
表2 幻象識(shí)別能力提升策略實(shí)驗(yàn)結(jié)果
知識(shí)檢索
知識(shí)檢索是一個(gè)廣泛使用的用于減少幻象的手段。在幻象檢測實(shí)驗(yàn)中,我們向ChatGPT提供在Wikipedia檢索到的相關(guān)事實(shí)知識(shí)(除了摘要任務(wù)),并在指令中要求ChatGPT根據(jù)給定知識(shí)和問題判斷答案中是否包含幻象。通過向模型提供相關(guān)的事實(shí)知識(shí),幻象的識(shí)別準(zhǔn)確率有較為明顯的提升,尤其是在問答任務(wù)中,準(zhǔn)確率從62.59%提升到了76.83%;對(duì)話任務(wù)也有小幅度的提升。因此,為LLM提供外部知識(shí)可以很大程度上增強(qiáng)其識(shí)別幻象的能力。
CoT推理
思維鏈(chain-of-thought)推理是一種通過使LLM加入中間步驟進(jìn)行推理來獲得最終結(jié)果的手段,之前的工作在一些數(shù)學(xué)問題和邏輯問題中引入思維鏈,能夠明顯提升模型解決問題的能力。在幻象識(shí)別實(shí)驗(yàn)中,我們同樣引入思維鏈推理進(jìn)行嘗試,在識(shí)別指令中要求模型逐步生成推理步驟最終得到識(shí)別結(jié)果。然而和知識(shí)檢索相比,在輸出中添加思維鏈并沒有提高模型識(shí)別幻象的能力,反而在部分任務(wù)上準(zhǔn)確率有所下降。與知識(shí)檢索相比,思維鏈推理并不能為模型提供顯式的外部知識(shí),反而有可能會(huì)干擾最終的判斷。
樣本對(duì)比
我們進(jìn)一步為模型同時(shí)提供正確答案和幻象答案來測試模型是否具備區(qū)分正確樣本和幻象樣本的能力。表中的實(shí)驗(yàn)結(jié)果顯示提供正確樣本使得幻象識(shí)別的準(zhǔn)確率有較大的下降,這可能是由于生成的幻象答案與真實(shí)答案有很高的相似性,也進(jìn)一步說明了HaluEval的幻象識(shí)別對(duì)LLM來說具有很大的挑戰(zhàn)性。
四、總結(jié)
本文引入了大型語言模型幻象評(píng)估基準(zhǔn)——HaluEval,這是一個(gè)大規(guī)模的自動(dòng)生成的和人工注釋的幻象樣本集合,用于評(píng)估大語言模型在識(shí)別幻象方面的表現(xiàn)。首先我們介紹了HaluEval的構(gòu)建過程,包含自動(dòng)生成和人工標(biāo)注。為了自動(dòng)生成幻象樣本,我們提出先采樣后過濾的兩步生成框架;人工標(biāo)注部分我們請(qǐng)專家針對(duì)用戶查詢的回復(fù)進(jìn)行標(biāo)注。基于HaluEval,我們?cè)u(píng)估了四個(gè)大模型在識(shí)別幻象方面的表現(xiàn),分析了幻象識(shí)別實(shí)驗(yàn)的結(jié)果,并且提出了三個(gè)提升幻想識(shí)別能力的策略。基于在HaluEval上的測評(píng)實(shí)驗(yàn),我們得出以下結(jié)論:
ChatGPT很可能會(huì)編造無法核實(shí)的信息,從而在一些特定主題中產(chǎn)生幻覺內(nèi)容。
現(xiàn)有的大語言模型在識(shí)別文本中的幻覺方面面臨著巨大的挑戰(zhàn)。
可以通過提供外部知識(shí)或增加推理步驟來提高幻覺識(shí)別的準(zhǔn)確率。
總之,我們提出的HaluEval基準(zhǔn)能夠幫助分析大模型生成幻象的內(nèi)容,也可用于大模型幻象識(shí)別和減輕的研究,為未來建立更加安全可靠的LLM鋪平了道路。
審核編輯:劉清
-
過濾器
+關(guān)注
關(guān)注
1文章
436瀏覽量
20069 -
LDA
+關(guān)注
關(guān)注
0文章
29瀏覽量
10741 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1584瀏覽量
8650
原文標(biāo)題:幻象 or 事實(shí) | HaluEval:大語言模型的幻象評(píng)估基準(zhǔn)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
請(qǐng)問NanoEdge AI數(shù)據(jù)集該如何構(gòu)建?
DevEco Studio構(gòu)建分析工具Build Analyzer 為原生鴻蒙應(yīng)用開發(fā)提速
請(qǐng)問NanoEdge AI數(shù)據(jù)集該如何構(gòu)建?
怎么刪除分析中的“Ghost”數(shù)據(jù)集
高階API構(gòu)建模型和數(shù)據(jù)集使用
分析數(shù)據(jù)集(食品篇)

統(tǒng)計(jì)行業(yè)數(shù)據(jù)倉庫構(gòu)建及應(yīng)用
WSN中能量有效的連通支配集構(gòu)建算法
PyTorch教程16.1之情緒分析和數(shù)據(jù)集

使用DSFD檢測DarkFace數(shù)據(jù)集過程
如何構(gòu)建高質(zhì)量的大語言模型數(shù)據(jù)集
大模型數(shù)據(jù)集:構(gòu)建、挑戰(zhàn)與未來趨勢
宏集INSYS工業(yè)路由器構(gòu)建可靠的水廠過程控制系統(tǒng)

宏集ASPION數(shù)據(jù)記錄器:分析運(yùn)輸過程中的碰撞、沖擊和振動(dòng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論