 通用緩存引擎cachelib介紹
通用緩存引擎cachelib介紹
背景
網絡服務幾乎在系統架構的每一層都依賴于緩存。大型網絡服務依靠緩存系統來實現高性能和高效率。例如,在Facebook,CDN緩存為70%的網絡請求提供服務,將延遲降低了一個或多個數量級。一臺緩存服務器可以取代幾十臺后端數據庫服務器,實現20倍的吞吐量和超過80%的命中率。通常,每個緩存都是由一個不同的團隊獨立實現和維護的,并且對其功能高度專業化。在Facebook,各種各樣的緩存系統構成了系統架構的一個組成部分。Facebook的架構包括CDN緩存、鍵值應用緩存、社交圖譜緩存和媒體緩存(圖1)。緩存在亞馬遜、Twitter、Reddit以及其他許多大型網絡服務中扮演著類似的角色。然而,每個團隊獨立實現和維護的緩存系統存在重復的邏輯和功能,忽略了不同緩存系統共同面臨的困難挑戰,大大增加了部署、維護和擴展每個緩存所需的整體努力。
問題
1. 多種緩存系統的冗余
Facebook的每個緩存系統都是單獨實現的。例如,如圖1所示,Facebook分別設計了CDN緩存、鍵值緩存、社交圖譜緩存、存儲緩存、數據庫緩存,以及其他許多緩存。這些高度專業化的系統都需要一個高度專業化的緩存,以實現復雜的一致性協議,利用自定義的數據結構,并針對所需的硬件平臺進行優化。盡管這些緩存系統服務于不同的工作負載,需要不同的功能,但它們在設計和部署方面有許多共同的挑戰。所有這些系統每秒都要處理數以百萬計的查詢,緩存工作集大到需要同時使用閃存和DRAM進行緩存,并且必須容忍因應用程序更新而頻繁重啟,這在Facebook的生產環境中很常見。隨著Facebook的緩存系統數量的增加,為每個系統維持獨立的緩存實現變得難以維持。通過重復解決相同的工程難題,團隊重復了彼此的努力,產生了多余的代碼。此外,維護獨立的緩存系統也阻礙了系統之間分享性能優化帶來的效率提升。
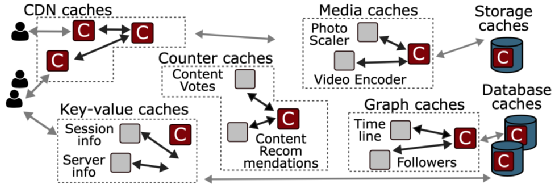
圖1 緩存類型
2. DRAM開銷
隨著傳統的動態隨機存取存儲器 (DRAM) 緩存變得更加昂貴并且需要更多的能力來擴展。在大型服務器的場景下,全部采用DRAM作為緩存介質是不現實的,這將會造成巨大的成本開銷。像 Facebook 這樣的公司正在探索硬件選擇,例如非易失性存儲器 (NVM) 驅動器來增強他們的緩存系統。這種 DRAM 和 NVM 混合模型向前邁進了一步,但需要創新的緩存設計來利用混合緩存的全部潛力。
探索
1. 緩存數據集分布(冷熱)
工作負載的流行度分布衡量的是每個鍵在某個時間范圍內的取樣跟蹤的頻率。這些頻率表明系統中不同對象的相對受歡迎程度。之前對CDN和網絡工作負載的測量表明,高度傾斜的Zipf分布是一種常見的流行分布。在Zipf分布中,"最受歡迎的20%的對象占了80%的請求"。圖2顯示了Facebook四個工作負載的對數尺度的流行分布。在這個尺度上,Zipf分布將是一條具有負斜率(-α)的直線。Lookaside是四個系統中唯一一個流行度分布為Zipfian的系統,α接近于1。Storage的分布在分布的頭部更平坦,盡管尾部遵循Zipf分布。此外,盡管是Zip-fian分布,SocialGraph和CDN的分布分別表現為α=0.55和α=0.7。較低的α意味著明顯較高比例的請求進入流行分布的尾部,這導致了更大的工作集。
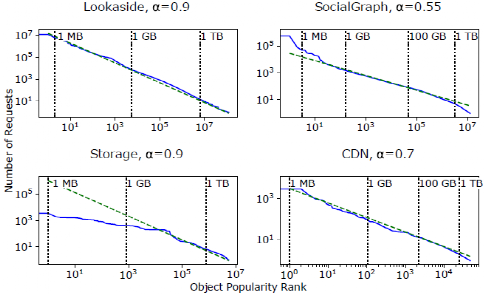
圖2 數據集流行度分布
2. 緩存數據集分布流失(冷熱變化)
流失指的是由于新keys的引入和現有keys的流行程度隨著時間的推移而產生的工作集的變化。流行的YCSB工作負載生成器假設沒有流失,即每個密鑰在整個基準期間保持同樣的流行。這個基準和無流失假設被廣泛用于系統論文的評估中。
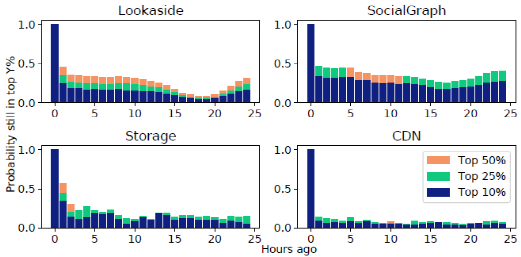
圖3 流失程度
在Facebook的生產工作負載中體現出有很高程度的流失率。如果一個對象屬于收到最多請求的10%的對象,我們就定義它是受歡迎的。圖3顯示了流行對象的集合如何隨時間變化。例如,x=3處的藍條顯示了一個3小時前很受歡迎的對象仍然在前10%最多請求的對象中的概率。在所有的工作負載中,超過三分之二的熱門對象在一小時后就跌出了前10%的位置。這種高流失率與使用哪個小時作為基線、不同的百分比(例如前25%)以及不同的時間粒度(例如,10分鐘后,50%的熱門對象不再受歡迎)無關。這種高流失率增加了時間定位的重要性,使緩存策略更難根據過去的訪問模式來估計對象的受歡迎程度。
3. 緩存對象的粒度變化
除了受歡迎程度和流失率之外,對象的大小在緩存性能上也起著關鍵作用。圖4顯示了四個大型用例的對象大小分布。對于Storage和CDN,64KB和128KB的小塊非常常見,這是將大對象分成小塊的結果。對于Lookaside和SocialGraph,對象的大小跨越了七個數量級。
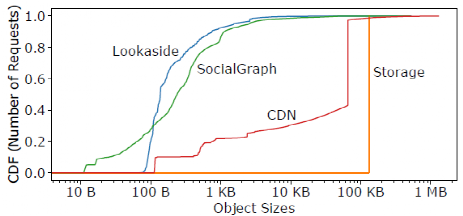
圖4 緩存對象粒度分布
4.急促訪問
Facebook的工作負載流量是相當突發性的。圖5顯示了與泊松到達序列相比的實際請求到達率,這通常是在系統評估中假設的。圖5顯示,實際到達率的變化比Poisson暗示的要大得多。這對CDN來說尤其明顯,它在相當穩定的請求率之上有急劇的流量爆發。多變的到達率使得緩存系統很難有足夠的資源來維持負載高峰期的低延遲。
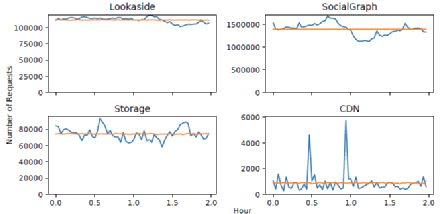
圖5 請求數量分布
方法和設計
1. 混合式緩存架構
相對來說這些東西需要寫很多相同的緩存邏輯:換出策略,內存使用,處理 empty cache 等,所以 Facebook 造了一套通用的 CacheLib,用來節省團隊造輪子的功夫。同時,很重要的一點是對于 Flash 的使用。用 SSD/Flash 當緩存,相對來說能夠提供較低的成本,和可以接受的性能。相對 DRAM,機器一般會提供更大的盤,同時,SSD 也會提供更低的成本和更可接受的性能。這套功能在 CacheLib 中叫做 HybridCache,CacheLib 允許指定存儲設備。CacheLib 對外提供的是 byte-addressable 的對象和 cache。它提供了一套線程安全的 api,來處理對應的邏輯:

圖6 API
此外,CacheLib 還給自定義的 Serialize/Deserialize 定義了接口,以便用戶塞一些自定義結構體。
2.小對象緩存優化 (Small Object Cache)
SOC存儲很多小對象,如果像LOC一樣存儲它們的索引,系統整個DRAM開銷會非常大。所以SOC使用了一個近似的索引來實現對應的邏輯。如圖7所示,SOC 把小對象劃分成很多 sets,每個包含一個4kB page,按照FIFO存儲對象。每組有一個8 bytes的Bloom Filter。這里把key查一下Bloom Filter,如果不存在則返回不存在,否則讀取整個Page并順序掃描。
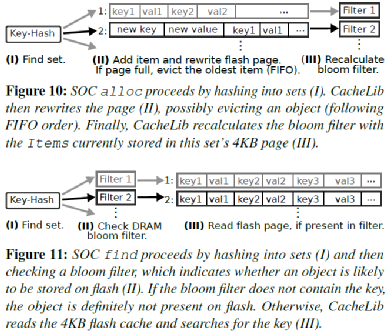
圖7 小對象存儲示意圖
3. 大對象緩存優化 (Large Object Cache)
LOC 存儲的都是 2kB 以上的對象。作者認為,這些大對象讓用戶能夠在內存中放置這些對象的 Index。具體的對象按照 4kb 的大小對齊。論文用了 4 bytes 的大小定位這部分的數據:4 bytes最大能表示232個數據,可以放 16T的數據了。
LOC 的內存索引存儲,LOC 會主動把 SSD 劃分成不同的區域,根據這個來判斷大小。然后LOC對象的地址會對齊4kB,這大概是一個SSD Page的大小,這樣能夠保證一個 SSD Page 不會存儲過多的對象;同時地址對齊 4kB,減小地址對象的開銷。如果對象很大,那么它會連續跨多個頁,需要把他們都讀起來。如果一個cache read讀取有一個相同的hash key,這里會把Flash中的元數據讀起來。這里在元數據上需要存儲對應的key。然后把這個key跟用戶請求的真實 key 比較,判斷具體是否命中緩存。
這里還有一個 Erase 相關的優化。LOC 的 Erase 是以 Block 為單位的,它默認 16MB,但是是可配置的。這實際上相當于 抹去 SSD 的 Block,通過這種方式來增加寫的順序寫。如果淘汰出的對象是一個比較熱的對象,可能會重新加入 cache 中。
實驗結果
實驗性能對比包含三個方面,分別為緩存命中率、吞吐量和暖啟動。
緩存命中率和吞吐量性能:圖12顯示了8到144GB的緩存規模和1億個對象的典型工作集的命中率和吞吐量。Memcached和CacheLib實現了相似的命中率,Memcached在小的緩存大小時略高,在大的緩存大小時略低。在所有的緩存大小中,CacheLib實現了比Memcached更高的吞吐量,每秒鐘處理的請求比Memcached多60%。
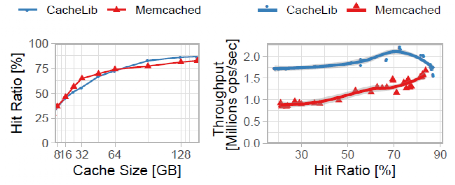
圖8 命中率和吞吐量實驗結果圖
小對象緩存性能:圖9顯示,CacheLib對小對象的明確處理為Flash緩存提供了比NGINX和ATS更大的優勢。當對象的大小變大時,這種優勢就會減弱。最終,對象的大小變得足夠大,以至于這三個系統都變成了網絡約束,其吞吐量急劇下降。
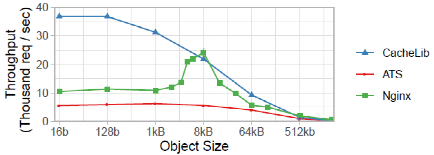
圖9 小對象吞吐量實驗結果
暖啟動:圖10顯示了L1和L2 SocialGraph緩存重啟時的命中率,而沒有執行暖重啟。在沒有啟用這個功能的情況下,緩存重啟會導致命中率下降,然后慢慢恢復正常。這在二級混合緩存中尤其具有破壞性,因為大容量的緩存可能需要幾天時間來 "熱身"。這樣的命中率下降可以轉化為后端系統的暫時過載,因為后端系統假定有相對穩定的到達率。
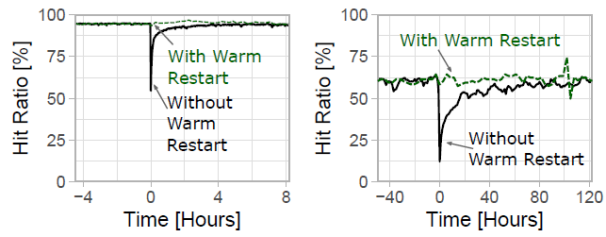
圖10 暖啟動實驗結果
總結
Cachelib的出現避免了緩存系統重復造輪子的現象,降低了系統的冗余程度和開發維護成本。同時cachelib設計了混合式緩存架構,使用性價比高的SSD進行混合式緩存,使得緩存系統的成本降低同時提升性能。與傳統的內存作為緩存層相比,cachelib考慮到閃存的特性,進行了小對象緩存優化,并且在性能上有很大改進。
審核編輯:劉清
-
驅動器
+關注
關注
54文章
8643瀏覽量
149193 -
DRAM芯片
+關注
關注
1文章
88瀏覽量
18301 -
緩存器
+關注
關注
0文章
63瀏覽量
11844 -
CDN網絡
+關注
關注
0文章
11瀏覽量
6890 -
隨機存取存儲器
+關注
關注
0文章
45瀏覽量
9079
原文標題:通用緩存引擎cachelib
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
阿里巴巴開源的通用緩存訪問框架JetCache介紹
介紹AWTK
請問AzureRTOS ThreadX/NetXDuo在通用字節池上緩存怎么樣
高速緩存Cache介紹
Mybatis緩存之一級緩存
硬盤緩存有什么用
基于鴻蒙適配移植的開源視頻緩存引擎項目案例

使用Matlab實現了一個通用無源網絡仿真引擎
如何在SpringBoot中解決Redis的緩存穿透等問題
Caffeine教程緩存介紹

聊聊本地緩存和分布式緩存
緩存之美——如何選擇合適的本地緩存?





 工商網監
工商網監
評論