") 基于Transformer多模態(tài)先導性工作
基于Transformer多模態(tài)先導性工作
多模態(tài)(Multimodality)是指在信息處理、傳遞和表達中涉及多種不同的感知模態(tài)或信息來源。這些感知模態(tài)可以包括語言、視覺、聽覺、觸覺等,它們共同作用來傳遞更豐富、更全面的信息。在多模態(tài)系統(tǒng)中,不同模態(tài)之間的信息可以相互補充、交互作用,從而提供更深入、更全面的理解和溝通。
以人類的感知為例,我們在日常生活中通常會同時接收多種感知信息。當我們觀看一部電影時,我們不僅僅依靠視覺信息來理解情節(jié)和角色,還借助于聽覺信息(對話、音效)、語言信息(字幕或?qū)Π祝⒁约扒楦猩系挠|覺體驗等,這些信息相互交織,共同構(gòu)成我們對電影的感知和理解。
在計算機科學和人工智能領域,多模態(tài)的概念也得到廣泛應用。例如,在自然語言處理中,多模態(tài)模型可以結(jié)合文本和圖像信息,使得計算機能夠更好地理解和生成豐富的內(nèi)容。在人機交互中,多模態(tài)界面可以通過語音、觸控和手勢等方式,讓用戶更自然、更便捷地與計算機進行交互。此外,多模態(tài)也在自動駕駛、醫(yī)療診斷、情感分析等領域有著廣泛的應用前景。
正文:
不同模態(tài)語義的對齊問題一直是多模態(tài)人工智能研究的一個重點課題。傳統(tǒng)意義上的多模態(tài)數(shù)據(jù)包括有:視覺數(shù)據(jù)、文字數(shù)據(jù)、聲音數(shù)據(jù)、觸覺數(shù)據(jù)等等;在不斷地研究與發(fā)展中,多模態(tài)數(shù)據(jù)又細化為圖像數(shù)據(jù)、視頻數(shù)據(jù)、語言文字數(shù)據(jù)、其他文字數(shù)據(jù)(如代碼等)、聲音數(shù)據(jù)、語音數(shù)據(jù)、紅外數(shù)據(jù)、3d點云數(shù)據(jù)等等眾多的數(shù)據(jù)形式。
1 引言
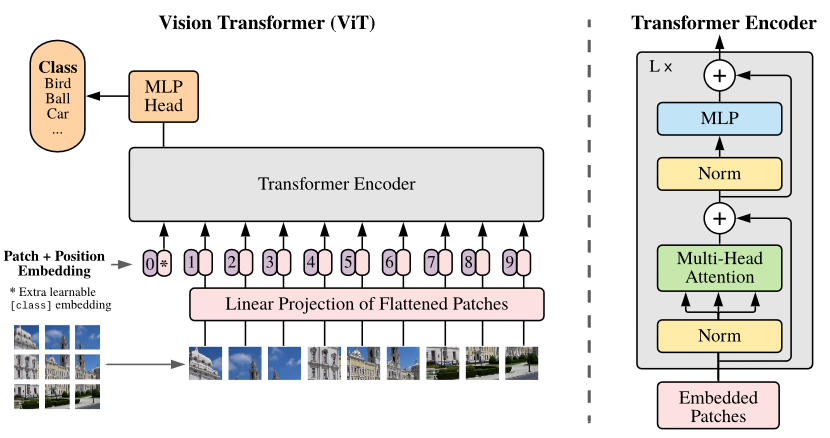
圖1. Vision Transformer Overview
不同模態(tài)數(shù)據(jù)的語義密度不同、信噪比不同、能覆蓋的知識范圍也不同。因此不同模態(tài)數(shù)據(jù)的對齊就面臨著巨大的困難。以視覺-語言數(shù)據(jù)的語義對齊為例,對齊不同模態(tài)數(shù)據(jù)需要解決形式對齊和內(nèi)容對齊兩個問題。
首先是形式對齊的問題。NLP領域的經(jīng)典工作ELMo[3]提出用上下文雙向預測來提取詞元底層語義向量的方法,Bert[4]中改善為類似完型填空的語句重建任務,利用Transformer[5]的高并行性和更深的深度為大模型時代的到來解決了語言數(shù)據(jù)的人工標注成本問題。NLP領域的高速發(fā)展同樣也刺激著計算機視覺領域?qū)W者們的眼球,探索Transformer在視覺領域的潛力,其中影響力最大的便是來自Google的Vision Transformer[6],此工作將一張分辨率為224*224的圖片分割為16*16個分辨率為14*14的patch,每個patch當做一個token交給Transformer Encoder模塊進行運算。至此,Transformer統(tǒng)一了語言數(shù)據(jù)和視覺數(shù)據(jù)的數(shù)據(jù)格式和計算方式,解決了形式對齊的問題。
今天要給大家分享的論文,ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision,就是基于以上工作的Transformer多模態(tài)先導性工作。
2 相關工作
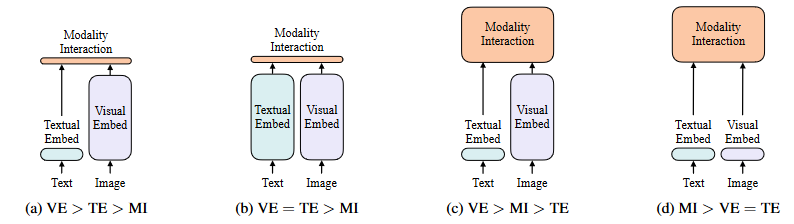 圖2. 四類視覺語言模型
圖2. 四類視覺語言模型
在論文的第一部分作者總結(jié)了截止到2021年為止的多模態(tài)方法,并以計算量進行了分類。如圖2所示,其中VE代表視覺編碼,TE代表文字編碼,MI代表模態(tài)融合,方框的面積代表計算量。
在ViT出現(xiàn)之前,視覺-語言模型的視覺部分由CNN[8] Backbone統(tǒng)治,VE部分也幾乎都是以基于像素和CNN的模型進行嵌入,如Pixel-Bert[7]等工作。本文提到,大多數(shù)視覺-語言模型的研究都集中在提高VE部分的性能和計算量,又由于區(qū)域特征通常在訓練時提前緩存,以減輕特征提取的負擔,因此在學術(shù)嚴重中往往會忽略了過重的VE部分的缺點,比如在實際的應用場景中,需要極大的開銷和推理時間用于提取視覺特征,其推理過于緩慢,十分影響其真實可用性。同時筆者也認為,此類方法過于依賴CNN Backbone的泛化性和訓練數(shù)據(jù)量,有很大的優(yōu)化空間。
因此,在此篇工作中作者們專注于研究視覺嵌入的輕量化和快速化,并只使用Transformer作為網(wǎng)絡主體,以一種統(tǒng)一的方式處理兩種模態(tài)。區(qū)別于以往的視覺-語言模型,ViLT模型是沒有卷積網(wǎng)絡的,通過特殊的設計,去除了專門用于視覺輸入的深度嵌入器顯著減少了模型大小和運行時間,從圖3中可以看出此工作的參數(shù)有效模型(parameter-efficient model)的運行速度比使用區(qū)域特征的VLP(Vision-Language Pretrain)模型要快幾十倍,比使用網(wǎng)格特征的VLP模型要快四倍以上,同時在性能上,并沒有比上述模型有明顯下降,甚至在某些任務上要優(yōu)于上述模型。
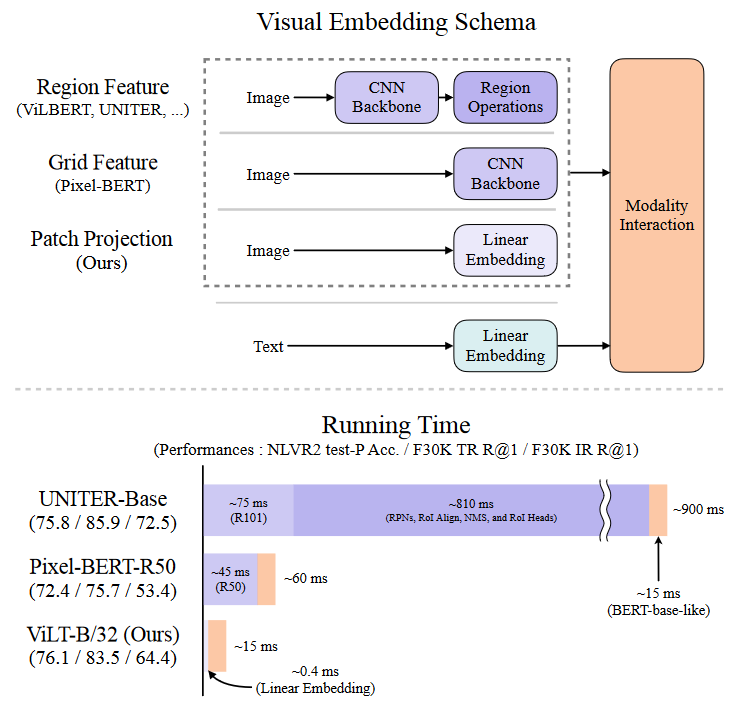 圖3.推理代價對比圖
圖3.推理代價對比圖
ViLT工作的主要貢獻被作者總結(jié)為如下:
ViLT是迄今為止最簡單的視覺-語言模型架構(gòu),它統(tǒng)一使用Transformer來處理視覺和語言特征,這種設計顯著降低了運行時間并提高了參數(shù)效率。
ViLT首次證明了CNN不是視覺-語言任務上的唯一解,在不適用任何CNN網(wǎng)絡的情況下,在視覺和語言任務上取得了令人滿意的性能。視覺語義嵌入(VSE)模型,如VSE++(Faghri等人,2017年)和SCAN(Lee等人,2018年)屬于圖2a。他們對圖像和文本使用不同的嵌入器,前者要重得多。然后,它們用簡單的點積或淺的注意層來表示兩種模態(tài)中嵌入特征的相似性。
ViLT證明了,在多模態(tài)任務的訓練中,使用整詞掩蔽和圖像增強能進一步增強模型的性能。
3 背景
3.1 視覺語言模型的分類方式
作者提出視覺和語言模型的分類法基于兩點:( 1 )兩種模態(tài)在專用參數(shù)和,或計算方面是否具有均勻的表達能力;( 2 )兩種模態(tài)在深度網(wǎng)絡中是否存在相互作用。這些點的組合導致了圖2中的四個原型。
視覺語義嵌入(VSE)模型,如VSE++[9]和SCAN[10]屬于圖2a。他們對圖像和文本使用不同的嵌入器,前者要重得多。然后,它們用簡單的點積或淺的注意層來表示兩種模態(tài)中嵌入特征的相似性。
CLIP[11](雷德福等人,2021年)屬于圖2b,因為它為每種模態(tài)使用單獨但同樣昂貴的Transformer model嵌入器。合并的圖像矢量和文本矢量之間的交互仍然很淺(點積)。盡管CLIP在圖像到文本檢索方面表現(xiàn)出色,但我們無法在其他視覺和語言下游任務中觀察到相同水平的表現(xiàn)。例如,使用來自CLIP的匯集的視覺和文本向量的點積作為多模態(tài)表示來微調(diào)NLVR2[12]上的MLP頭,給出了50.99±0.38的低dev精度(用三種不同的種子運行);由于機會水平準確度為0.5,我們得出結(jié)論,表示不能學習這項任務。這也符合Suhr[13]等人的發(fā)現(xiàn)。(2018)所有簡單融合多模態(tài)表示的模型都無法學習NLVR2。
這一結(jié)果支持了作者的推測,即使來自高性能單模態(tài)Embedder的輸出的簡單融合也可能不足以學習復雜的視覺和語言任務,這體現(xiàn)了對更嚴格的模態(tài)間交互方案的需求。
與具有淺層交互的模型不同,圖2c中較新的VLP模型使用深層transformer來模擬圖像和文本特征的交互。然而,除了交互模塊之外,卷積網(wǎng)絡仍然參與提取和嵌入圖像特征,這占了圖3所示的大部分計算。Modulation-based視覺和語言模型[14]也屬于圖2c,它們的視覺CNN詞干對應于視覺嵌入器,RNN產(chǎn)生文本嵌入器的調(diào)制參數(shù),調(diào)制CNN產(chǎn)生模態(tài)交互。
本文提出的ViLT是屬于圖2d的第一個模型,其中原始像素的嵌入層很淺,并且與文本標記相比計算量很輕。因此,這種架構(gòu)將大部分計算集中在建模模態(tài)交互上。
3.2 模態(tài)交互
Transformer技術(shù)是當前VLP模型的核心,它們用視覺和文本嵌入序列作為輸入,在整個層中模擬模態(tài)內(nèi)和模態(tài)間的交互,然后輸出上下文相關的特征序列。
布利亞雷羅等人[15]將交互模式分為兩類:(1)單流方法(如VisualBERT[16]、UNITER[17]),其中各層集體操作圖像和文本輸入的串聯(lián);以及(2)雙流方法(例如,ViLBERT[18],LXMERT[19]),其中兩種模式在輸入級別上沒有連接。對于交互Transformer model模塊,作者遵循單流方法,因為雙流方法引入了額外的參數(shù)。
3.3 視覺Embedding
所有高性能的VLP模型都共享相同的Text Embedding——BERT但它們在視覺嵌入器上有所不同。盡管如此,在大多數(shù)(如果不是全部)情況下,視覺嵌入仍然是現(xiàn)有VLP模型的瓶頸。我們通過引入Patch Projection而不是使用區(qū)域或網(wǎng)格特征來減少這一瓶頸,因為區(qū)域或網(wǎng)格特征使用了更大的提取模塊。
區(qū)域特征。VLP模型主要利用區(qū)域特征,也稱為自下而上特征[20]。它們是從現(xiàn)成的物體檢測器如Faster R-CNN[21]獲得的。
生成區(qū)域特征的一般流程如下。首先,使用RPN基于從CNN主干網(wǎng)匯集的網(wǎng)格特征來建議感興趣的區(qū)域(RoI)。然后,非最大抑制(NMS)將ROI的數(shù)量減少到幾千個。在被RoI Align[22]等操作匯集后,RoI通過RoI頭并成為區(qū)域特征。NMS再次應用于每個類,最終將特征的數(shù)量減少到100個以下。
上述過程涉及幾個影響性能和運行時的因素:主干、NMS的風格、RoI頭.以前的工作對控制這些因素很寬容,如下所示:
?骨干網(wǎng):ResNet-101[1]和ResNext-152[1]是兩種常用的骨干網(wǎng)。
?NMS:NMS通常以逐類的方式完成。在每個類中應用NMS成為運行時一個主要的瓶頸,例如在VG數(shù)據(jù)集[23]中有1.6 K的類。為了解決這個問題,最近引入了分類NMS[24]。
?RoI頭:最初使用的是C4[20]。頭是后來引入的[25]。當heads為所有RoI工作時,帶來了巨大的運行時間負擔。
然而輕量級的目標檢測模型不太可能比backbone或單層卷積更快。提前凍結(jié)視覺backbone和緩存區(qū)域特征只在訓練時有幫助,在推理期間沒有幫助,更不用說它本就抑制性能。
網(wǎng)格特征。除了目標檢測頭,卷積神經(jīng)網(wǎng)絡(如ResNets)的輸出特征網(wǎng)格也可以用作視覺和語言預訓練的視覺特征。直接使用網(wǎng)格特征首先是由特定模型提出的[26],主要是為了避免使用嚴重緩慢的區(qū)域選擇操作。
X-LXMERT[27]通過將目標區(qū)域固定為網(wǎng)格而不是來自區(qū)域建議網(wǎng)絡的網(wǎng)格來重新研究網(wǎng)格特征。然而,他們對特征的緩存排除了對主干網(wǎng)的進一步調(diào)整。
Pixel - BERT是唯一一個將VG預訓練的目標檢測器替換為預訓練ImageNet分類的ResNet變體主干的VLP模型。與基于區(qū)域特征的VLP模型中的凍結(jié)檢測器不同,Pixel - BERT的主干在視覺和語言預訓練過程中進行了調(diào)整。Pixel - BERT與ResNet - 50的下游性能低于基于區(qū)域特征的VLP模型,但與其他競爭者相比,它使用了更重的ResNeXt - 152。
但作者聲稱網(wǎng)格特征不是首選項,由于深度卷積神經(jīng)網(wǎng)絡代價昂貴,它們占整個計算很大一部分,如圖3所示。
Patch Projection.為了最小化開銷,作者采用最簡單的視覺Embedding方案:在圖像塊上操作的線性投影。針對圖像分類任務,ViT引入了塊投影Embedding。補丁投影將視覺Embedding步驟大大簡化到文本Embedding的水平,同樣由簡單的投影(projection)操作組成。
作者使用32 × 32的面片投影,只需要2.4 M的參數(shù)。這與復雜的ResNe(X)t Backbone和目標檢測元件形成鮮明對比。其運行時間也可忽略不計,如圖3所示,在原文的4.6節(jié)做了詳細的運行時分析。
4 ViLT
4.1 模型概述
本文所提出的ViLT模型是一個追求簡潔的,單流視覺語言模型,具有本文所提所有方法中最小的VE模塊。具體的結(jié)構(gòu)可以參考圖2。
比較反直覺的是,作者在實際的實驗過程中對模型進行參數(shù)初始化以加速訓練,直接使用bert進行參數(shù)初始化的時候效果很差,在多次的實驗中作者又分別嘗試了使用預訓練的ViT初始化IM模塊的參數(shù)和僅使用ViT的patch embedding初始化ViLT的patch embedding。最后作者發(fā)現(xiàn),使用預訓練的ViT初始化IM模塊的效果最好,其中ViT和Bert模型的結(jié)構(gòu)不同之處在于他們layer normalization(LN)的位置不同,在ViT中LN層位于多頭注意力和FC層的前面,而在Bert中則位于此兩層的后面。本工作所使用的預訓練模型是ViT-B/32,在ImageNet上進行預訓練。
4.2 預訓練目標
作者使用兩個常用于訓練VLP模型的目標訓練ViLT:圖像文本匹配( ITM )和掩蔽語言建模( MLM )。
ITM.圖像文本匹配。作者以0.5的概率將對齊后的圖像隨機替換為不同的圖像。單個線性層ITM頭將池化的輸出特征p投影到二進制類上,我們計算負對數(shù)似然損失作為我們的ITM損失。
另外作者還使用基于最優(yōu)運輸原理的此塊對齊思想,輔助ITM任務的訓練。
MLM.掩蔽語言建模。作者在次任務中使用0.15的掩蔽概率進行隨機掩蔽,進行掩蔽重建任務以計算損失,其方法同Bert。
同時作者使用了不同于Bert的整詞掩蔽方式,使用視覺信息重建掩蔽詞,以加強模態(tài)之間的交互性。
4.3 圖像增強
在多模態(tài)任務中,由于圖像增強方法經(jīng)常會影響圖像的語義,故很少使用,比如圖片的裁剪可能會影響目標的數(shù)量,圖像的歸一化會影響圖像本身的色彩。但圖像增強本身作為一個很好的增強模型魯棒性和泛化性的trick,故作者在微調(diào)過程中還是使用了部分不影響圖像語義的數(shù)據(jù)增強方法。
5 實驗
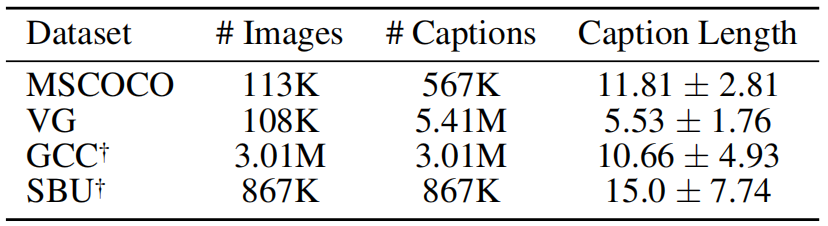
圖4.數(shù)據(jù)集
具體的實驗方法不在這里贅述,這里介紹一下本工作的數(shù)據(jù)集和評估效果。本工作使用了四個數(shù)據(jù)集共4M張圖片和約10M條描述用于預訓練,如圖4所示。并在VQAv2和NLVR2上進行評估,評估效果如下圖5-7所示。
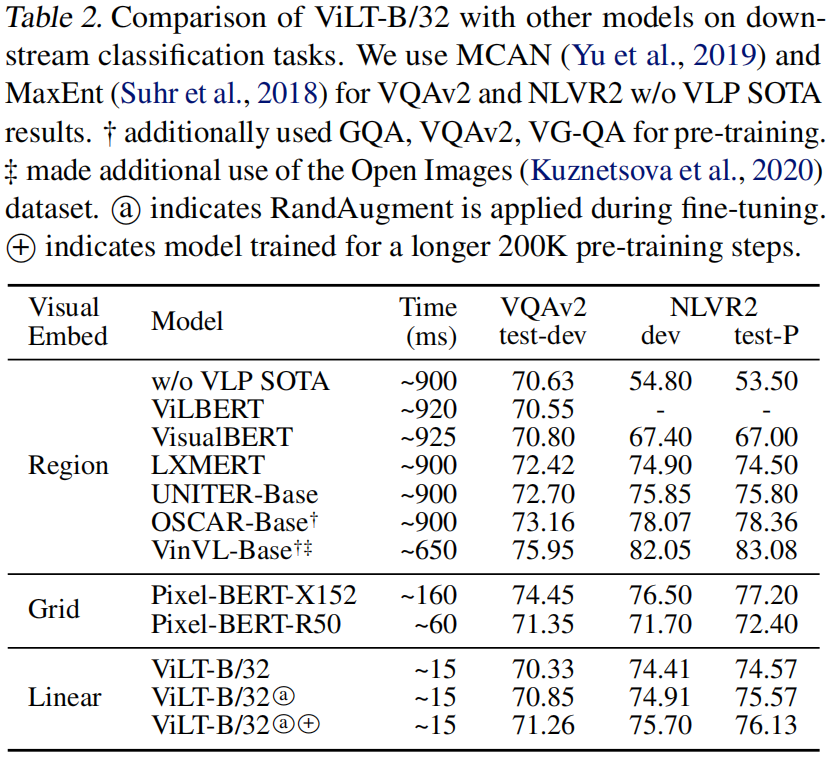 圖5.評估結(jié)果-1
圖5.評估結(jié)果-1
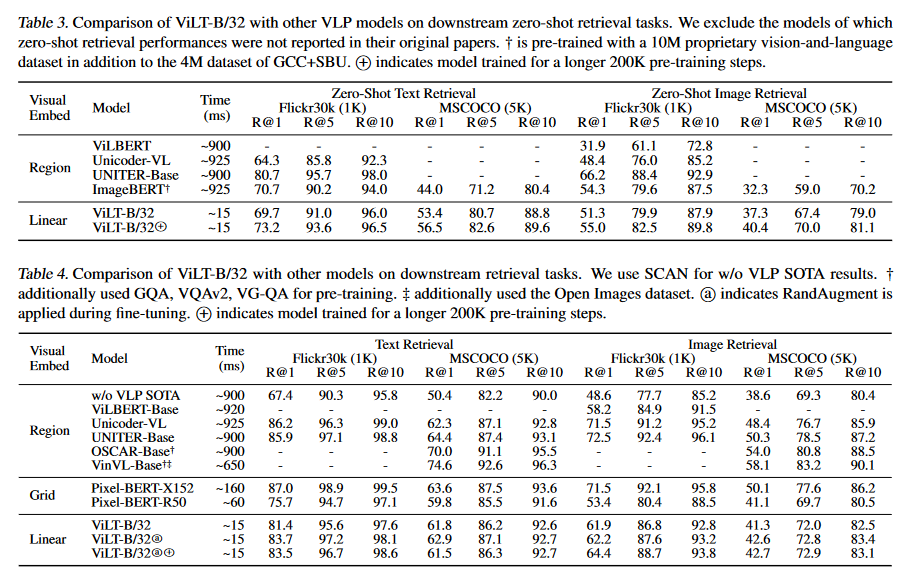 圖6.評估結(jié)果-2
圖6.評估結(jié)果-2
圖片所展示的效果很清晰,可以看到ViLT的主要提升在Time上,大幅提升了推理速度,在分數(shù)和效果上,ViLT并沒有因為推理速度大幅度提高而降低,反而在某些任務上有小幅度提升。
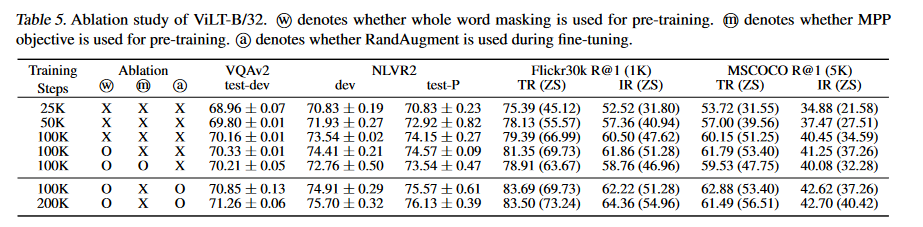 圖7.消融實驗
圖7.消融實驗
圖7所示的消融實驗探究了模型的哪些設計提升了性能,可以看到整詞掩蔽和圖像增強都帶來了幾個點的效果提升。
6 可視化效果

圖8.可視化多模態(tài)對齊展示
作者展示了ViLT的圖像可視化對齊效果,可以看到把更多了計算量分配給IM模塊時,模型會展現(xiàn)出強大的對齊能力。作者認為他們在WPA任務上的設計增強了模型的對齊能力。
審核編輯:彭菁
-
數(shù)據(jù)
+關注
關注
8文章
7246瀏覽量
91167 -
人工智能
+關注
關注
1804文章
48788瀏覽量
246938 -
Transformer
+關注
關注
0文章
151瀏覽量
6413 -
nlp
+關注
關注
1文章
490瀏覽量
22513 -
大模型
+關注
關注
2文章
3046瀏覽量
3860
原文標題:ViLT: 沒有卷積和區(qū)域監(jiān)督的視覺-語言Transformer模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄

多文化場景下的多模態(tài)情感識別
聯(lián)想楊元慶:5G是行業(yè)智能化轉(zhuǎn)型的先導性技術(shù)
如何讓Transformer在多種模態(tài)下處理不同領域的廣泛應用?
Transformer模型的多模態(tài)學習應用
如何在多模態(tài)的語境中利用Transformer強大的表達能力?
Transformer常用的輕量化方法
微軟多模態(tài)ChatGPT的常見測試介紹
基于視覺的多模態(tài)觸覺感知系統(tǒng)
探究編輯多模態(tài)大語言模型的可行性
成都匯陽投資關于多模態(tài)驅(qū)動應用前景廣闊,上游算力迎機會!
基于Transformer的多模態(tài)BEV融合方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論