") 全球GPU缺口超40萬張!算力之困,中國大模型有解了
全球GPU缺口超40萬張!算力之困,中國大模型有解了

【導(dǎo)讀】大模型時代,玩家如何掘金?最近,這套大模型智算軟件棧OGAI,竟吸引了國內(nèi)幾十家參與「百模大戰(zhàn)」的企業(yè)圍觀。 中國企業(yè),能否趕超OpenAI? 大模型爆火之后,許多人都在追問這樣的問題。 然而,這個領(lǐng)域的中美差異性,決定了這一事實:美國現(xiàn)在的格局,未必就是中國未來的格局。 美國可能只有少數(shù)的大模型企業(yè),而中國,或許會呈現(xiàn)百花齊放的新格局,并不會是只剩下少數(shù)幾個大模型,其他人在它們的基礎(chǔ)上去做應(yīng)用和開發(fā)。 從十年維度來看,如今的GPT-4還只是一個baby,而今天的我們,只是剛剛打開生成式AI的一扇門而已。

在這個大模型狂飆的時代,英偉達CEO黃仁勛有一句名言,「the more you buy,the more you save!」 「如果你能將一個價值50億美元的數(shù)據(jù)中心的訓練時間縮短一半,那么節(jié)省下來的費用就超過了所有芯片的成本。」
大模型,怎樣才能玩得起
但問題在于,面對如此高的門檻,究竟哪些玩家才能玩得起? 目前,大模型研發(fā)已進入萬卡時代,一家企業(yè)如果想自己擁有大模型,至少需要幾十億投資。 然而,即便是買下來之后,緊接著還會面臨建不了的問題。 此前的云計算是把一臺機器拆分成很多容器,而現(xiàn)在的大模型需要多臺機器集群的集中力量,在較長時間內(nèi)完成海量計算任務(wù)。 如何保證低時延海量數(shù)據(jù)交換?如何讓多臺機器均衡計算,避免冷熱不均?如果硬件出現(xiàn)故障,算法需要重新跑一遍,又怎么辦?
瓶頸之下,算力利用率變得尤為重要
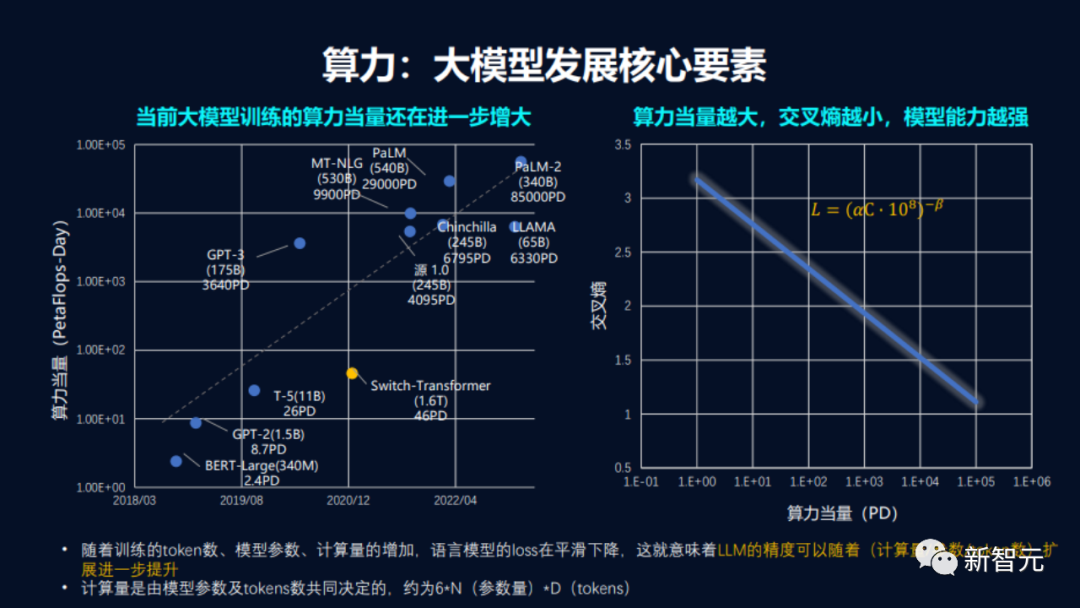
不可否認,對于大模型的研發(fā)來說,最大的挑戰(zhàn)之一,就是對龐大的算力基礎(chǔ)設(shè)施的需求。 然而,訓練大模型的算力平臺并不是算力的簡單堆積,隨著模型的規(guī)模越來越大,單卡算力與模型總算力需求之間存在著巨大的差異。 與此同時,雖然隨著硬件的改進FLOPs的成本得到了部分改善,但大模型的持續(xù)升級使得總成本一直在增加。 目前,GPT-4、PaLM-2的算力當量,已經(jīng)達到了GPT-3的數(shù)十倍,相當于上萬顆業(yè)界性能領(lǐng)先的NVIDIA Hopper架構(gòu)的GPU芯片組成的AI集群,訓練超過1個月的時間。 算力平臺的構(gòu)建之所以這么難,是因為它不止是服務(wù)器、存儲、 網(wǎng)絡(luò)等硬件設(shè)備的集成,也有諸多設(shè)備軟硬件兼容性和性能調(diào)教上的know-how。 而對于企業(yè)來說,由于缺乏工程實踐的經(jīng)驗,進一步限制了硬件計算能力的發(fā)揮。這不僅讓本就匱乏的算力資源雪上加霜,更是無法快速地提升模型質(zhì)量來應(yīng)對狂卷的競爭。
從數(shù)據(jù)到算法再到RLHF,過程冗長
在算法開發(fā)層面,PB級數(shù)據(jù)的爬取、清洗、過濾和質(zhì)檢,大規(guī)模預(yù)訓練的算法設(shè)計、性能優(yōu)化和失效管理,都面臨著重重難題。 DeepMind的研究表明,想要把一個大模型訓練充分,每個參數(shù)的訓練量要達到20個token。因此,當前的很多千億規(guī)模的大模型還需要多用10倍的數(shù)據(jù)進行訓練,模型性能才能達到比較好的水平。 目前,國內(nèi)大模型產(chǎn)業(yè)數(shù)據(jù)集主要還是簡體中文加上少量英文為主,數(shù)據(jù)集的單詞量在100億級。相比之下,訓練GPT模型的單詞量級為5700億。也就是說,單從規(guī)模上來看就是1:57的差距。 不僅如此,從設(shè)計指令微調(diào)數(shù)據(jù)集,到優(yōu)化RLHF,整個開發(fā)鏈十分冗長,這更需要背后有諸多工程化工具。

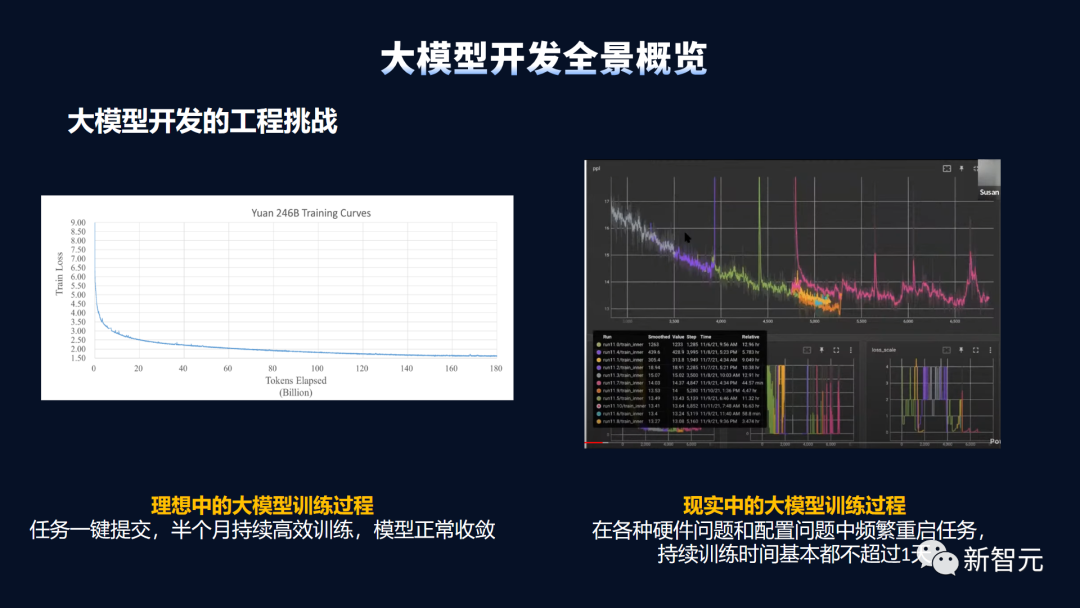
模型訓練:周期長、效率低,斷點問題嚴峻
另外,大模型的訓練過程,也比傳統(tǒng)的分布式訓練復(fù)雜,訓練周期長達數(shù)月。 而集群計算效率低、故障頻發(fā)且處理復(fù)雜,會導(dǎo)致訓練中斷后不能及時恢復(fù),從而會降低成功率,也會使訓練成本 居高不下。 從工程角度來看,這是一個非常復(fù)雜的流程,其中的硬件、系統(tǒng)、軟件、驅(qū)動等等都必須相互適配,才能起跑。 期間,各個部分都需要能穩(wěn)定持續(xù)運轉(zhuǎn),才能保障模型訓練的效率。一旦出現(xiàn)問題,都會讓整個訓練過程停擺。 比如,Meta就曾在訓練OPT-175B模型的日志中提到,幾乎整個訓練過程都要面對不停地重啟和中斷。
在訓練完成到30%左右處,Meta的訓練日志顯示,在兩個星期的時間段內(nèi)因為硬件、基礎(chǔ)設(shè)施或?qū)嶒灧€(wěn)定性問題而重新啟動了40多次! 絕大多數(shù)重新啟動都是由于硬件故障以及缺乏提供足夠數(shù)量的「緩沖」節(jié)點來替換壞節(jié)點的能力。通過云接口更換一臺機器可能需要幾個小時。
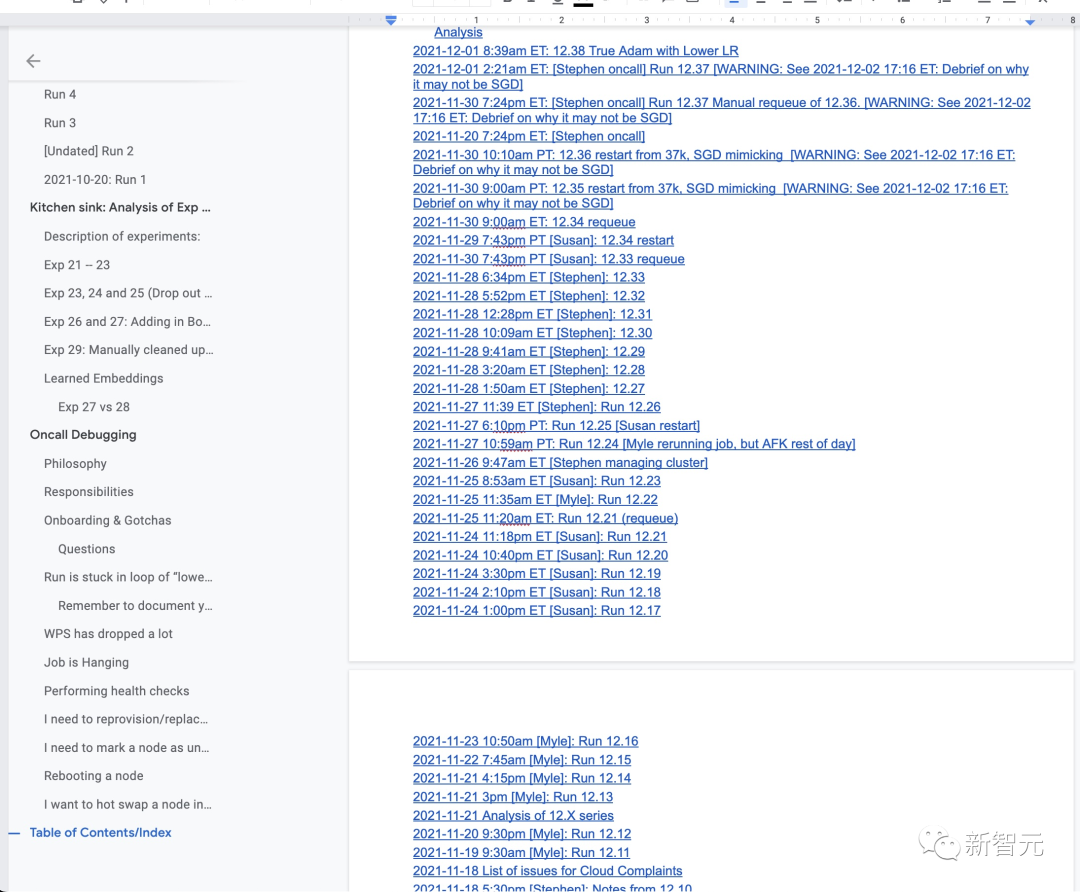
在維護日志中,Meta的訓練人員記錄到:
總而言之,解決基礎(chǔ)設(shè)施問題占據(jù)了團隊最后兩周的大部分時間,因為這些硬件問題可能會在一天中的任何時間導(dǎo)致訓練中斷幾個小時。
雖然我們充分意識到這些問題會在這種規(guī)模的訓練過程中反復(fù)出現(xiàn),但考慮到在2021年底之前完成一個175B模型訓練全部工作時間非常緊迫,我們別無選擇,只能通過不停重啟的方式,看看如果沒有額外的訓練工具的幫助我們能走多遠。?
在找到一個加速重啟的方案并安排了更多的人手24小時輪值維護之后,Meta依然還是要面對硬件層面的各種問題。 內(nèi)部訓練進度的圖表顯示,接下來的兩周之內(nèi),最長的3次連續(xù)訓練時間長度只有2.8天,2天,1.5天。
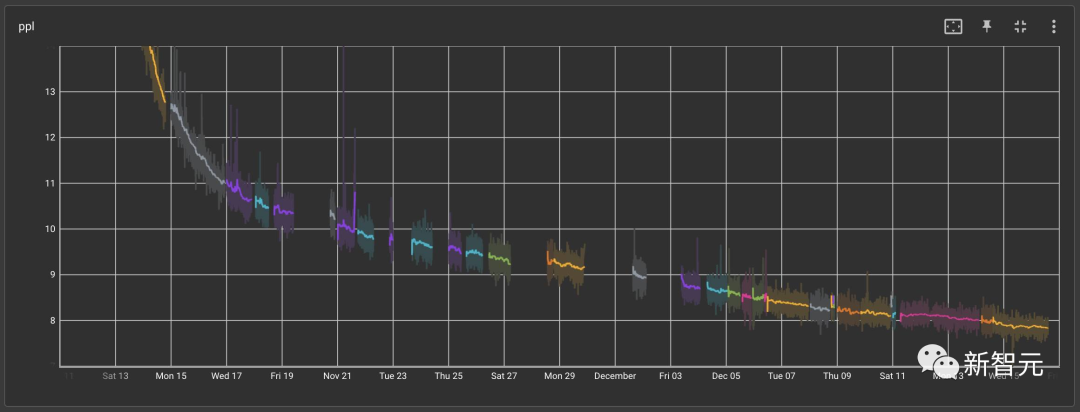
不難看出,就連強如Meta這樣的團隊,都會或多或少地受到上述挑戰(zhàn)的困擾。 因此,對于還處在探索階段的國內(nèi)大模型產(chǎn)業(yè)來說,就更加需要一套能夠保障其生產(chǎn)力的AI基礎(chǔ)設(shè)施。 正如浪潮信息人工智能與高性能應(yīng)用軟件部AI架構(gòu)師Owen ZHU所說:「以前都認為,買服務(wù)器就像買手機、買電腦一樣,只要開機就能用了;但實際上隨著算力需求持續(xù)變大,事情變得越來越復(fù)雜,實際上買回去也不一定能用得起來。」
OGAI:你可能要踩的坑,他們都替你踩過了
為了切實地解決這些問題,近日,浪潮信息正式發(fā)布發(fā)布了大模型智算軟件棧OGAI(Open GenAI Infra)——「元腦生智」。 面對各種以大模型為核心的生成式AI開發(fā)與應(yīng)用場景,OGAI都提供了全棧全流程的軟件,包括集群系統(tǒng)環(huán)境部署、算力調(diào)度保障、大模型開發(fā)管理等。 為了充分釋放智算集群的能力,OGAI在每個層次上都對性能和穩(wěn)定性進行了相應(yīng)的優(yōu)化,包括服務(wù)器BIOS的調(diào)教、大規(guī)模集群組網(wǎng)性能、算力調(diào)度策略等。 同時,也融合了浪潮信息在MLPerf性能評測、服務(wù)客戶實際需求、開發(fā)源大模型的實踐經(jīng)驗。 如此一來,就可以大幅降低大模型算力系統(tǒng)的使用門檻、優(yōu)化大模型的研發(fā)效率。無論是生產(chǎn),還是應(yīng)用,都得到了保障。 總之,你可能會踩的坑,浪潮信息都提前幫你踩過了。
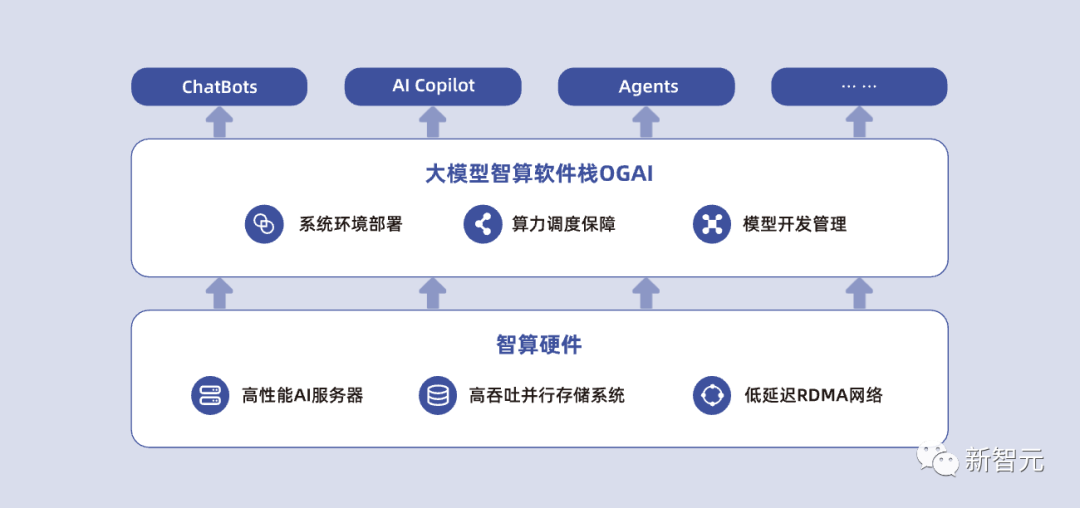
具體而言,OGAI由5層架構(gòu)組成,從L0到L4分別對應(yīng)基礎(chǔ)設(shè)施層的智算中心OS、系統(tǒng)環(huán)境層的PODsys、調(diào)度平臺層的AIStation、模型工具層的YLink和多模納管層的MModel。 值得注意的是,OGAI軟件棧的使用非常靈活。從L0到L4層的設(shè)計和實現(xiàn),都是分層的。也就是說,你并不一定要用到L0到L4整體的方案去開發(fā)大模型。 因為每一層都是分層解耦的,需要哪一層的實現(xiàn)或?qū)?yīng)的功能,就只用那一層就可以了。

L0層智算中心OS:面向大模型算力服務(wù)的智能算力運管平臺,滿足多租戶以裸金屬為主的彈性AI算力運管需求。
其中,高效的裸金屬服務(wù)可以在幾分鐘內(nèi)部署規(guī)模達上千的裸金屬節(jié)點,并按照需求進行擴容,能夠一鍵獲取異構(gòu)計算芯片、IB、RoCE高速網(wǎng)絡(luò)、高性能存儲等環(huán)境,同時實現(xiàn)計算、網(wǎng)絡(luò)和數(shù)據(jù)的隔離,確保業(yè)務(wù)的安全性。
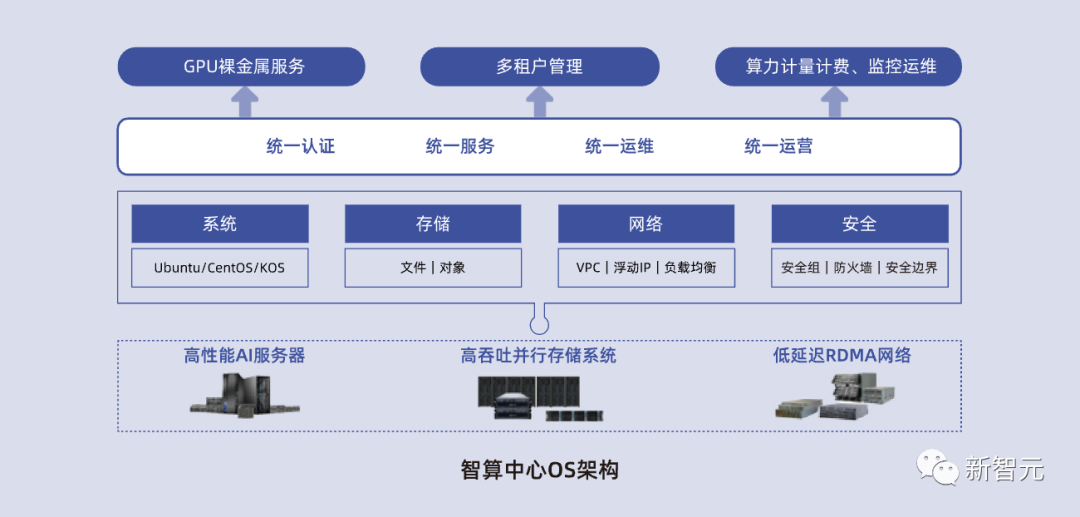
L1層PODsys:開源、高效、兼容、易用的智算集群系統(tǒng)環(huán)境部署方案。
這一層可以全面覆蓋AI集群的部署場景,包括系統(tǒng)環(huán)境,從OS、驅(qū)動到系統(tǒng)監(jiān)控可視化、資源調(diào)度等。值得一提的是,這是浪潮信息首創(chuàng)的一個開源項目。

下載地址:https://podsys.ai/ PODsys集成了數(shù)十個智算集群部署所需的驅(qū)動程序、軟件和其他安裝包,并提供了一系列腳本工具來簡化部署過程,而用戶只需執(zhí)行兩個簡單的命令就能完成整個集群的部署。 就拿模型整套流程中的一環(huán)「驅(qū)動」來說,不管是上層調(diào)優(yōu),還是底層調(diào)優(yōu)。 在過去就像是開盲盒一樣,對于客戶來說A可能適用,而對B并非適用,由此所帶來的成本是巨大的。
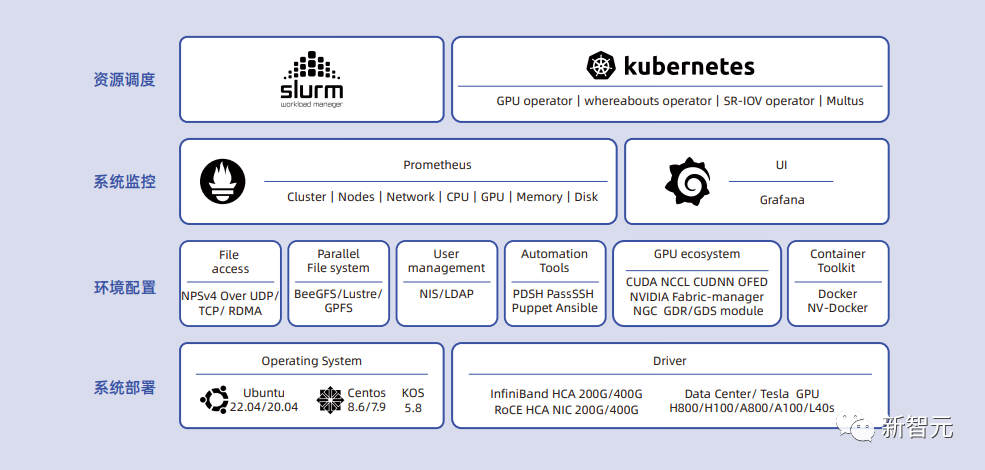
舉個栗子,某互聯(lián)網(wǎng)客戶A在使用AI集群,在對面向推薦場景的AI大模型進行訓練時,卻發(fā)現(xiàn)服務(wù)器中的CPU到GPU之間的通信帶寬和存儲到服務(wù)器之間的通信帶寬沒法同時跑滿。 帶來的結(jié)果就是,模型數(shù)據(jù)不能及時從存儲讀取,進而導(dǎo)致GPU空閑和訓練性能低下。 面對這一難題,客戶A的算法團隊用了幾個月的時間也沒有攻克。 浪潮信息的AI團隊介入后,發(fā)現(xiàn)客戶的場景中,大模型對數(shù)據(jù)讀取IO的需求遠超一般的AI模型訓練情況,從而導(dǎo)致針對普通模型訓練的服務(wù)器配置在推薦場景中出現(xiàn)了不適配的情況。 針對這一特殊的需求,基于自身經(jīng)驗,浪潮信息團隊對CPU BIOS中的mps等多個選項配置進行了針對性的的修改優(yōu)化,很好的解決了這一問題。 再比如在環(huán)境配置中,也會遇到一些意想不到問題。 為了滿足大模型算力需求,某互聯(lián)網(wǎng)客戶B購買多臺高端的AI服務(wù)器,并沿用之前的使用習慣進行了操作系統(tǒng)和環(huán)境的部署。 然而,在運行大模型訓練任務(wù)時發(fā)現(xiàn),GPU掉卡,OOM等錯誤頻頻出現(xiàn),導(dǎo)致開發(fā)人無法正常使用設(shè)備。 觸發(fā)這一故障警報的主要原因就是,客戶B操作系統(tǒng)配置中的部分pcie相關(guān)參數(shù)和當前GPU設(shè)備的需求不兼容。 對此,浪潮信息向客戶提供了正確的配置參數(shù)之后,很快解決了這個問題。 可以看出,大模型算力平臺并非是簡單算力堆積,還需要解決訓練推理效率,系統(tǒng)穩(wěn)定性等一系列工程問題。 就像Owen ZHU談到的一樣,當智算中心的規(guī)模從十幾臺服務(wù)器擴展到幾百臺,使用難度便會呈指數(shù)級上升。 L1層PODsys就像初始化操作系統(tǒng)預(yù)裝的驅(qū)動程序,能夠高效部署AI系統(tǒng),而不用重新開發(fā)組件。 它恰恰為AI集群部署提供一個完美的解決方案,即「將工程經(jīng)驗總結(jié)成一套工具鏈式的回答。」
L2層AIStation:面向大模型開發(fā)的商業(yè)化人工智能算力調(diào)度平臺。
這一層主要針對大模型訓練中常見的「訓練中斷」難題,能夠訓練異常快速定位,斷點自動續(xù)訓。 AIStation的核心能力,可以歸結(jié)為以下3個方面:1. 在開發(fā)環(huán)境和作業(yè)管理方面AIStation實現(xiàn)了計算、存儲、網(wǎng)絡(luò)等訓練環(huán)境的自動化配置,同時允許用戶自定義基本的超參數(shù),只需簡單幾步,就能完成大模型分布式訓練。 并且,AIStation還集成了主流的大模型訓練框架,包括Megatron-LM、DeepSpeed、HunggingFace上的諸多開源解決方案,實現(xiàn)了秒級構(gòu)建運行環(huán)境。 這樣的優(yōu)勢在于,能夠幫助開發(fā)者在大規(guī)模集群環(huán)境下便捷地提交分布式任務(wù)。 然后,調(diào)度系統(tǒng)根據(jù)分布式任務(wù)對GPU算力的需求,通過多種親和性調(diào)度策略,大大降低構(gòu)建分布式訓練任務(wù)技術(shù)門檻。 比如,英偉達開發(fā)的基于PyTorch框架Megatron-LM能夠在AIStation上實現(xiàn)快速部署,訓練全程都有保障。
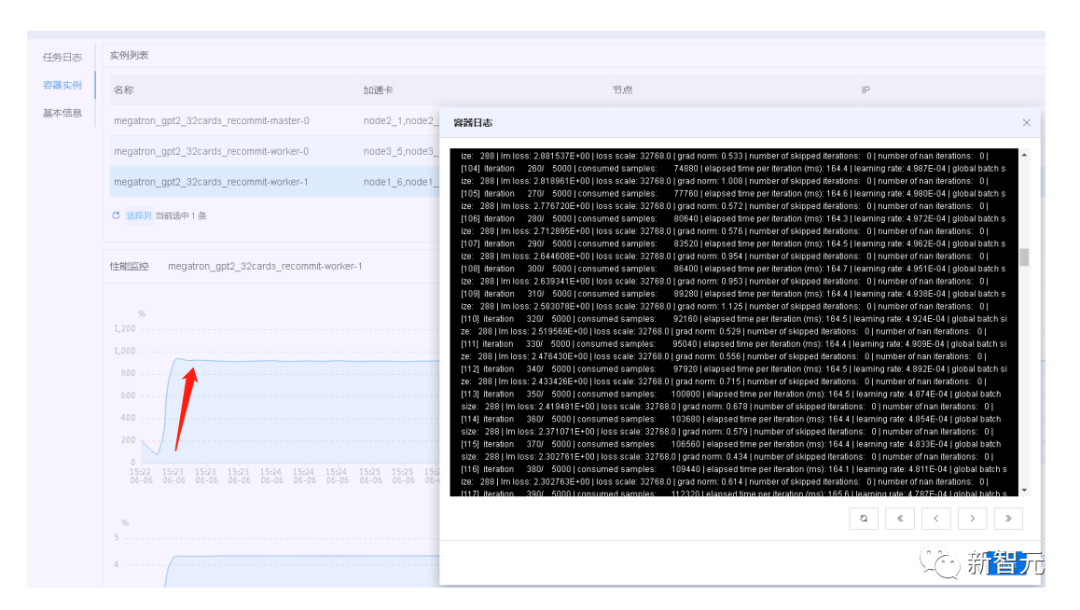
2. 在大規(guī)模算力調(diào)度方面能夠制定合理的作業(yè)執(zhí)行計劃,以最大限度地利用資源,滿足訓練任務(wù)的時延和吞吐需求。 AIStation優(yōu)化調(diào)度系統(tǒng)性能,實現(xiàn)了上千POD極速啟動和環(huán)境就緒。 另外,針對大模型訓練通信要求高的場景,AIStation提供集群拓撲感知能力。通過聯(lián)合優(yōu)化,AIStation在千卡集群中能實現(xiàn)90%以上的分布式計算擴展。 比如,就拿GPT-4來說,在大約25000個A100GPU上訓練90-100天,算力利用率為32%至36%。 而浪潮信息所打造的「源1.0」訓練算力效率則達到了44.8%。

3. 在訓練穩(wěn)定保障方面健壯性與穩(wěn)定性是高效完成大模型訓練的必要條件。 利用AIStation內(nèi)置的監(jiān)控全面的監(jiān)控系統(tǒng)和智能運維模塊,可以快速定位芯片、網(wǎng)卡、通訊設(shè)備異常或故障。 進一步,通過對訓練任務(wù)進行暫停保持,然后從熱備算力中進行自動彈性替換異常節(jié)點,最后利用健康節(jié)點進行快速checkpoint讀取,讓大模型斷點自動續(xù)訓成為可能。 比如,之前提到Meta在訓練OPT-175B模型時反復(fù)遇到的訓練中斷問題。 AIStation就能提供一整套的解決方案,避免類似情況的發(fā)生,或者將訓練中斷造成的影響控制到最小。
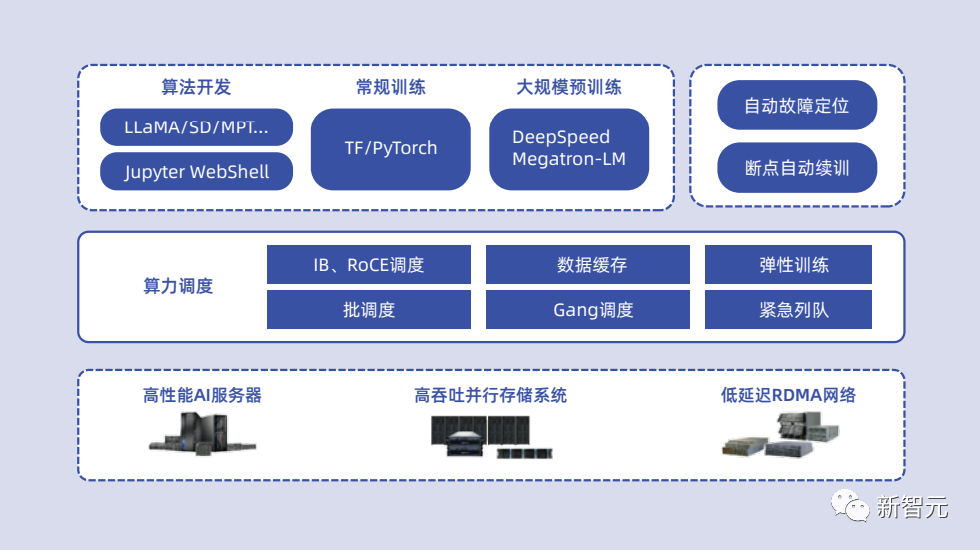
L3層YLink:面向大模型數(shù)據(jù)治理、預(yù)訓練、微調(diào)的高效工具鏈。
針對大模型開發(fā)的2個核心環(huán)節(jié)——數(shù)據(jù)處理和模型訓練。浪潮信息在YLink中集成了大模型研發(fā)中所需的自研工具和開源工具,如數(shù)據(jù)處理工具包(Y-DataKit)、大模型訓練工具包(Y-TrainKit)和大模型微調(diào)工具包(Y-FTKit)。 這些多樣且完善的工程化、自動化工具,大大加速了大模型的訓練和開發(fā)效率。
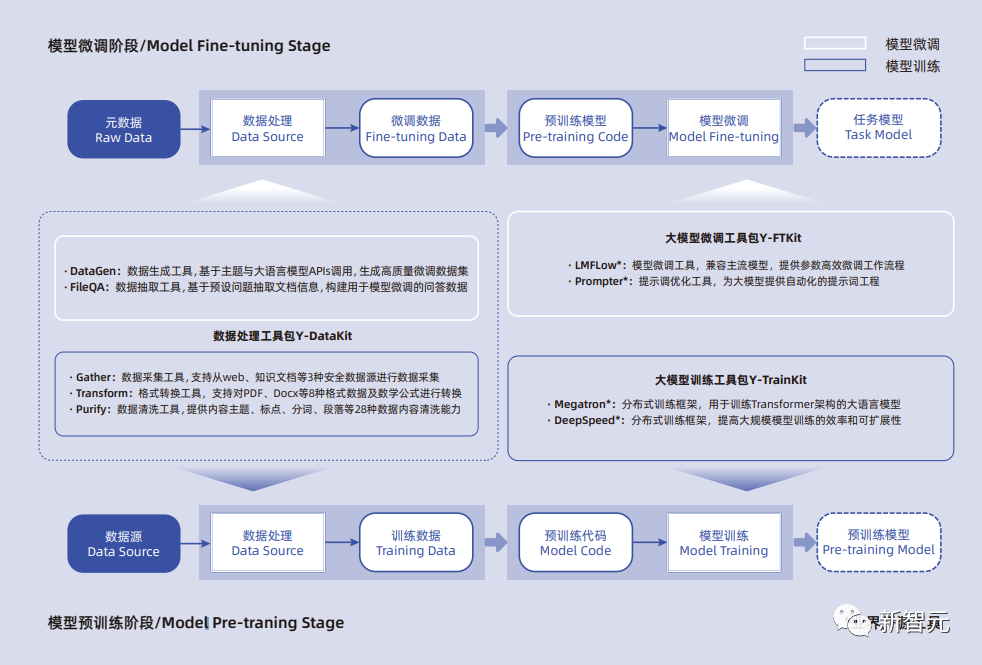
首先是數(shù)據(jù)的處理。 在LLM出現(xiàn)以前,鮮少有人能預(yù)見它背后巨大的想象力。它被視為大模型落地的入場券,軍備競賽中的護城河,AI界的戰(zhàn)略資源。 GPT-3.5的文本語料多達45TB,而GPT-4在GPT-3和GPT-3.5訓練數(shù)據(jù)集的基礎(chǔ)上,又增加了多模態(tài)數(shù)據(jù)。 想訓練出強大的大語言模型,就需要依托充足的高質(zhì)量數(shù)據(jù)。數(shù)據(jù)的數(shù)量、質(zhì)量、多樣性乃至清洗能力,都是影響大模型性能的關(guān)鍵要素。 在YLink工具鏈中,數(shù)據(jù)生成工具DataGen、數(shù)據(jù)抽取工具FileQA、數(shù)據(jù)采集工具Gather、格式轉(zhuǎn)換工具Transform、數(shù)據(jù)清洗工具Purify,大大方便了開發(fā)者的數(shù)據(jù)處理過程。 這樣,數(shù)據(jù)源和元數(shù)據(jù)被采集、處理后,就被轉(zhuǎn)換成模型訓練所需的數(shù)據(jù),也就是得到了「煉丹」的原材料。 在有了「足夠高質(zhì)量」的標注數(shù)據(jù)之后,就可以進一步為「足夠穩(wěn)定」的模型邏輯推理能力提供支撐了。 接下來,針對大模型的預(yù)訓練過程,YLink提供了數(shù)據(jù)處理工具Gather、Transform和Purity以及基于業(yè)界主流大模型分布式訓練框架NVIDIA Megatron和MS DeepSpeed的大規(guī)模分布式預(yù)訓練參考流程。
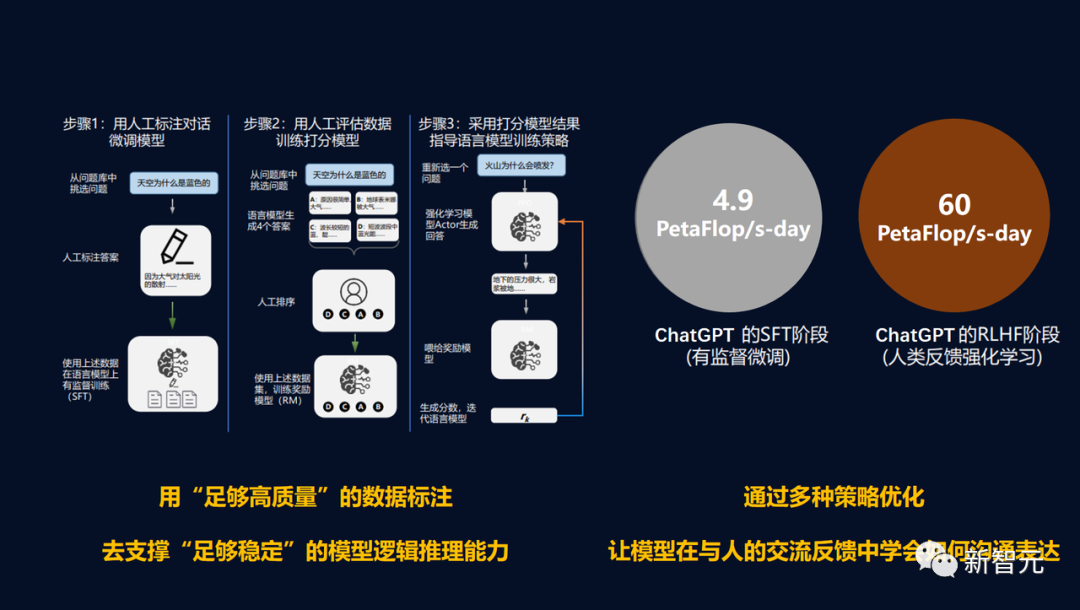
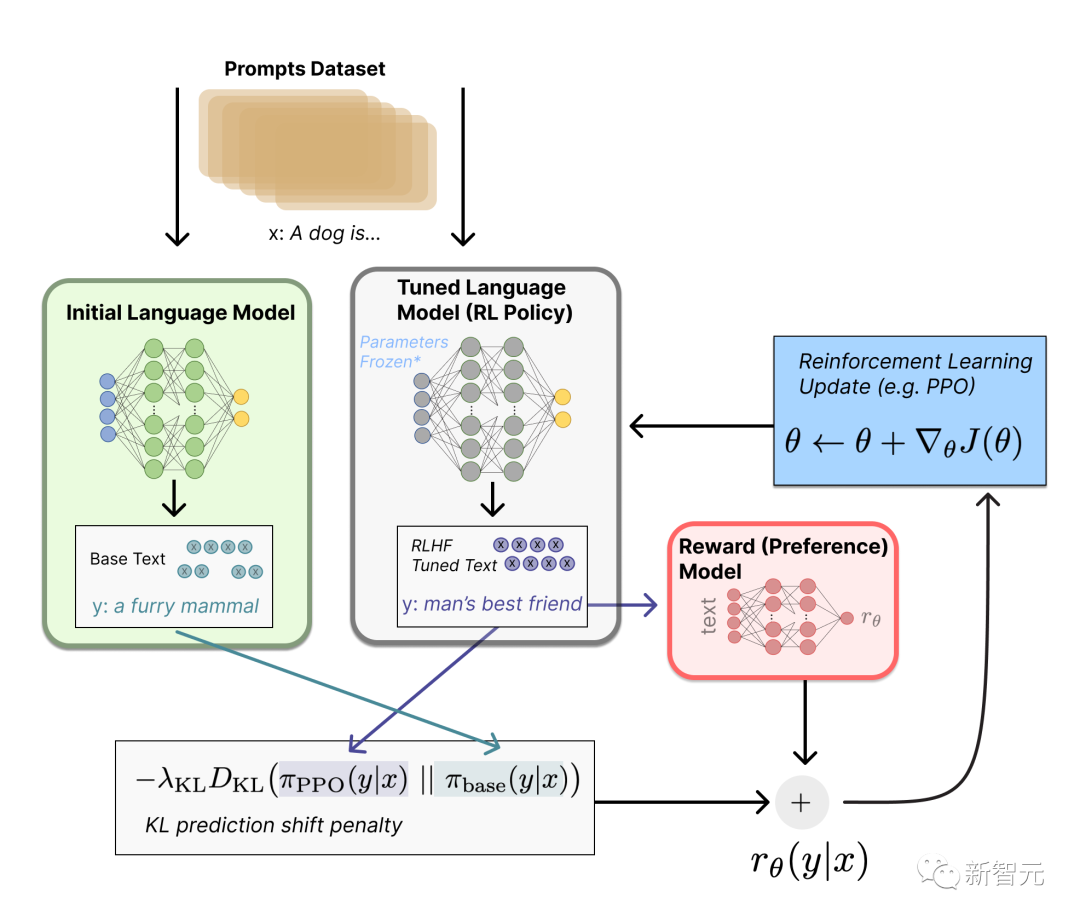
ChatGPT能火爆全球,關(guān)鍵的原因之一,是「它能像人一樣思考。這背后的原因,就是基于人類反饋的強化學習(RLHF)」。 在微調(diào)類ChatGPT模型過程中,主要會涉及三個階段:有監(jiān)督微調(diào)(SFT)、獎勵模型(RM)訓練和獎勵模型上的近端策略優(yōu)化(PPO)。 在SFT階段,模型通過模仿人類標注的對話示例來學習通用的類人對話;在獎勵模型訓練過程中,模型會根據(jù)人類反饋來比較不同回復(fù)的偏好;在PPO階段,根據(jù)獎勵模型的反饋更新模型,通過探索(exploration)和利用(exploitation)發(fā)現(xiàn)最優(yōu)策略。 同樣的,對于模型微調(diào)這個階段來說,數(shù)據(jù)質(zhì)量也至關(guān)重要。 現(xiàn)在,有了YLink在數(shù)據(jù)和訓練上提供的全方位支持,我們就可以輕松煉丹了。
L4層MModel:提供多模型接入、服務(wù)、評測等功能的納管平臺。
對于客戶來說,不論是開發(fā)大模型,還是調(diào)用第三方模型再用數(shù)據(jù)微調(diào)訓練,都會遇到一個問題,即不會只用到一個模型。 鑒于當前AI領(lǐng)域各種模型的豐富度,他們會選擇把多家模型進行比對,以找到更適合自己的最優(yōu)解。 而這當中需要經(jīng)歷一個必不可少的過程,涉及到如何管理多模型,如何下載,如何根據(jù)自身場景對模型進行自動化評測。 對此,浪潮信息提供了多模型納管方案,其核心組件包括數(shù)據(jù)集管理、模型納管和評測,可以方便開發(fā)者和研究人員更好地管理多版本、多類型的基礎(chǔ)大模型與任務(wù)模型。 并且,通過多樣化的評測數(shù)據(jù)集與評測任務(wù),它可以對多個模型進行生成準確率、推理延遲、推理穩(wěn)定性等指標的全面評估。 這樣,開發(fā)者就可以快速部署和應(yīng)用模型,并且,多模型的納管可以讓我們在保證模型權(quán)重、數(shù)據(jù)集安全的前提下,對外提供API服務(wù)。
大模型掘金的「秘密武器」
不難看出,OGAI不僅可以保障大模型訓練時算力供應(yīng)的可持續(xù)性,而且還充分考慮到了硬件、軟件、算法、框架層面引發(fā)的訓練中斷、失效的問題,進而幫助企業(yè)順利跨越大模型研發(fā)應(yīng)用門檻。 這些能力和基礎(chǔ)的背后,是來自浪潮信息在30余年深耕硬件行業(yè)的積累之上,在AI服務(wù)器產(chǎn)品,算力系統(tǒng)優(yōu)化方面的先發(fā)優(yōu)勢。 一方面,率先布局AIGC領(lǐng)域的浪潮信息,是國內(nèi)為數(shù)不多具備了千億大模型工程實踐經(jīng)驗的企業(yè)。這使得浪潮信息對于開發(fā)大模型的整套流程了如指掌。 未來客戶在AIGC工程領(lǐng)域中要踩的坑,浪潮信息已經(jīng)提前替客戶踩了;必須要面對的技術(shù)難題,浪潮信息已經(jīng)提前解決了。客戶借助浪潮信息推出的OGAI解決方案,讓自己能站在巨人的肩膀上,落地產(chǎn)品和服務(wù)。

基于千億級大模型的工程實踐,浪潮信息對于如何高效調(diào)度千卡規(guī)模的算力,以及保障訓練任務(wù)的長期穩(wěn)定運行已經(jīng)有了豐富的經(jīng)驗。 具體來說,在訓練數(shù)據(jù)層面,浪潮信息的AI團隊逐步建立了完整的從公開數(shù)據(jù)爬取到數(shù)據(jù)清洗、格式轉(zhuǎn)化、數(shù)據(jù)質(zhì)量評估的完整流程和工具鏈。 通過自研海量數(shù)據(jù)過濾系統(tǒng)(MDFS),建立從數(shù)據(jù)采集、粗濾、質(zhì)量分類、精濾的全自動化的端到端數(shù)據(jù)工作流程,通過清洗866TB海量數(shù)據(jù),獲得5TB高質(zhì)量中文數(shù)據(jù)集。 在模型訓練層面,浪潮信息通過對云原生的調(diào)度系統(tǒng)進行了改造,大幅加速其啟動速度,并重點解決了RDMA網(wǎng)絡(luò)在容器中的接入和適配優(yōu)化,較好地構(gòu)建了一套能夠滿足大模型需求的算力調(diào)度系統(tǒng)。 另一方面,除了親自搭建和研發(fā)的經(jīng)驗之外,浪潮信息還在服務(wù)客戶的過程中,解決了各種不同體量、不同賽道的企業(yè)在實踐中遇到的問題。 在集群架構(gòu)及軟硬件層面,解決了諸多如CUDA初始化失敗、GPU掉卡、 p2p Bandwidth Latency延遲過高、NCCL通信性能低,GPU direct RDMA未使能等問題。

2022年以來,浪潮信息的AI團隊協(xié)助多個客戶把大模型訓練的GPU峰值效率從30%左右提升到50%。從而大幅加速了模型訓練過程。 比如,將系統(tǒng)工程經(jīng)驗,應(yīng)用于智算中心算力系統(tǒng),全面優(yōu)化了集群架構(gòu)、高速互聯(lián)網(wǎng)絡(luò)和算力調(diào)度等等。「通過合理設(shè)計張量并行、流水并行和數(shù)據(jù)并行,精準調(diào)整模型結(jié)構(gòu)和訓練過程的超參數(shù),千億參數(shù)規(guī)模的大模型訓練算力效率可達至53.5%」。 此外,網(wǎng)易伏羲中文預(yù)訓練大模型「玉言」,也在浪潮信息的助力下登頂中文語言理解權(quán)威測評基準CLUE分類任務(wù)榜單,并在多項任務(wù)上超過人類水平。 基于豐富的經(jīng)驗積累,浪潮信息能夠快速挖掘出客戶的痛點,并將需求與現(xiàn)有技術(shù)進行有效整合。 最大程度地解決未來客戶會的遇到的問題,滿足各個賽道不同客戶在AI工程領(lǐng)域的不同需求。而這,便是OGAI解決方案正在實現(xiàn)的。 大模型的發(fā)展,猶如黑暗森林里的一束光,讓整個產(chǎn)業(yè)高效邁入AGI。 站在未來10年看如今百模爭霸的時代,加快產(chǎn)業(yè)進度,就是核心關(guān)鍵。 浪潮信息高級副總裁劉軍表示,浪潮信息的初心即是「探索前沿技術(shù),讓算力充分賦能大模型訓練,以及背后的產(chǎn)業(yè)落地化」。 今時火熱的AIGC產(chǎn)業(yè)機遇中,浪潮信息必然會留下濃墨重彩的一筆。
-
gpu
+關(guān)注
關(guān)注
28文章
4936瀏覽量
131107 -
算力
+關(guān)注
關(guān)注
2文章
1186瀏覽量
15607 -
大模型
+關(guān)注
關(guān)注
2文章
3117瀏覽量
4029
原文標題:全球GPU缺口超40萬張!算力之困,中國大模型有解了
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗】+NVlink技術(shù)從應(yīng)用到原理
智能算力最具潛力的行業(yè)領(lǐng)域

阿里最新消息:國家超算互聯(lián)網(wǎng)平臺、廣州算力中心、多所高校接入通義千問大模型
GPU算力租用平臺有什么好處
科技云報到:要算力更要“算利”,“精裝算力”觸發(fā)大模型產(chǎn)業(yè)新變局?
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
【一文看懂】大白話解釋“GPU與GPU算力”

GPU算力租用平臺是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析
淺析三大算力之異同
摩爾線程GPU算力底座助力大模型產(chǎn)業(yè)發(fā)展
大模型時代的算力需求
名單公布!【書籍評測活動NO.41】大模型時代的基礎(chǔ)架構(gòu):大模型算力中心建設(shè)指南
算力服務(wù)器為什么選擇GPU





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論