") Nature:人工智能芯片!
Nature:人工智能芯片!
具有數(shù)十億參數(shù)的人工智能(AI)模型可以在一系列任務(wù)中實(shí)現(xiàn)高精度,但它們加劇了傳統(tǒng)通用處理器(例如圖形處理單元或中央處理單元)的低能效。模擬內(nèi)存計(jì)算(模擬 AI)可以通過在“內(nèi)存塊”上并行執(zhí)行矩陣向量乘法來提供更好的能源效率。然而,模擬人工智能尚未在需要許多此類圖塊以及圖塊之間神經(jīng)網(wǎng)絡(luò)激活的有效通信的模型上證明軟件等效(SWeq)準(zhǔn)確性。
有鑒于此,美國IBM 研究中心S. Ambrogio(一作兼通訊)等人展示了一款14 nm的模擬 AI 芯片,該芯片結(jié)合了跨 34 個區(qū)塊的 3500 萬個相變存儲器件、大規(guī)模并行區(qū)塊間通信和模擬低功耗外圍電路,可實(shí)現(xiàn)12.4 萬億次 / 秒 / 瓦運(yùn)算性能,能效是傳統(tǒng)數(shù)字計(jì)算機(jī)芯片的14倍。作者展示了小型關(guān)鍵字識別網(wǎng)絡(luò)的完全端到端 SWeq 精度,以及更大的 MLPerf 循環(huán)神經(jīng)網(wǎng)絡(luò)傳感器 (RNNT) 上接近 SWeq 的精度,其中超過4500萬個權(quán)重映射到跨越5個芯片的1.4億個相變存儲器件上。
芯片架構(gòu)
作者展示了芯片的顯微照片,突出顯示了34個模擬塊的 2D 網(wǎng)格,每個塊都有512×2048PCM 交叉陣列。當(dāng)持續(xù)時間向量從模擬快發(fā)送到OLP時,芯片有效地實(shí)現(xiàn)了基于斜坡的模數(shù)轉(zhuǎn)換器 (ADC)。所有權(quán)重配置、MAC操作和路由方案均由每個圖塊上可用的用戶可配置本地控制器(LC) 定義。本地SRAM存儲定義數(shù)百個控制信號的時間序列的所有指令,從而實(shí)現(xiàn)高度靈活的測試并簡化設(shè)計(jì)驗(yàn)證,與預(yù)定義狀態(tài)機(jī)相比,面積損失較小。作者驗(yàn)證了持續(xù)時間可以在整個芯片上可靠地傳輸,最大誤差等于5ns(較短持續(xù)時間為 3ns)。
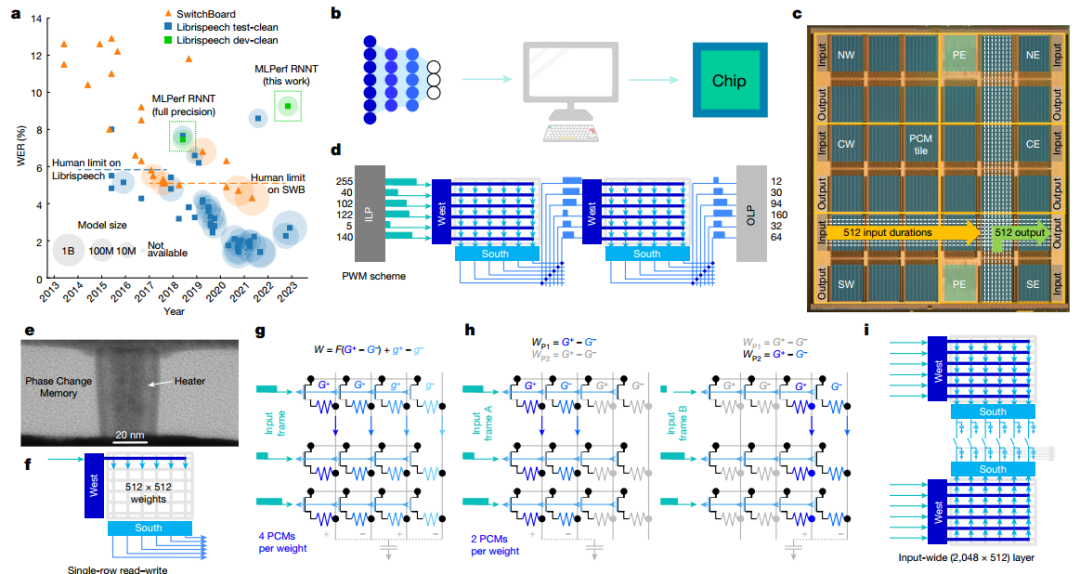
圖 芯片架構(gòu)
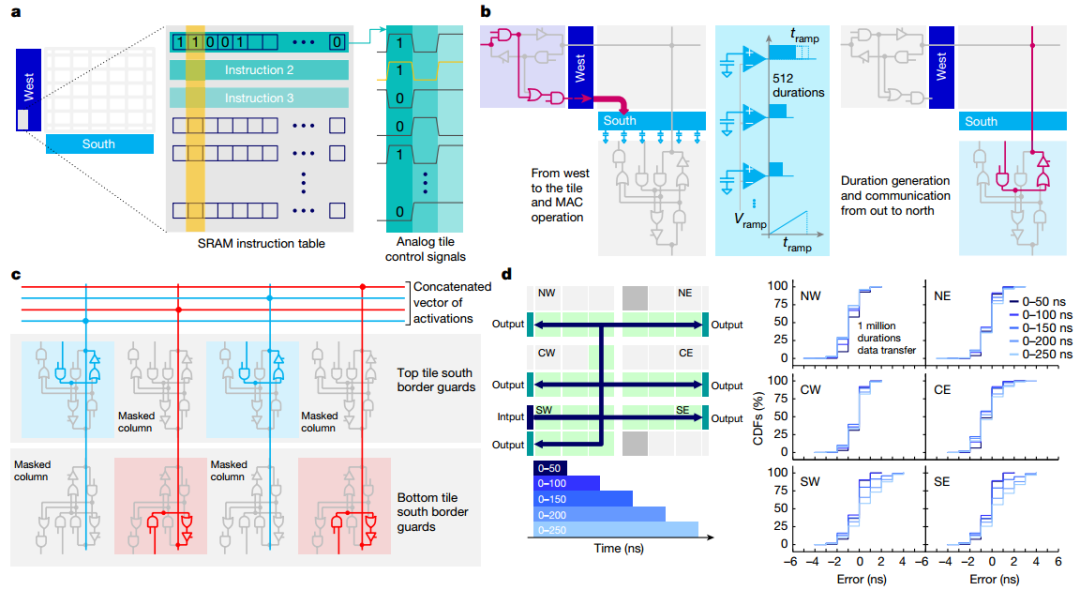
圖 可重構(gòu)架構(gòu)和路由
KWS任務(wù)
為了演示芯片在端到端網(wǎng)絡(luò)中的性能,實(shí)現(xiàn)了多類KWS任務(wù)。作者采用了 FC網(wǎng)絡(luò),實(shí)現(xiàn)了 86.75% 的分類準(zhǔn)確度。為了在芯片上實(shí)現(xiàn)完全端到端的傳輸,作者進(jìn)行了一系列修改,最終端到端實(shí)現(xiàn)總共使用四個圖塊。為了提高M(jìn)AC精度并補(bǔ)償外圍電路的不對稱性,引入了MAC不對稱平衡(AB)方法,測得的KWS精度為86.14%,完全在 MLPerf SWeq“等精度”極限 85.88%之內(nèi)。
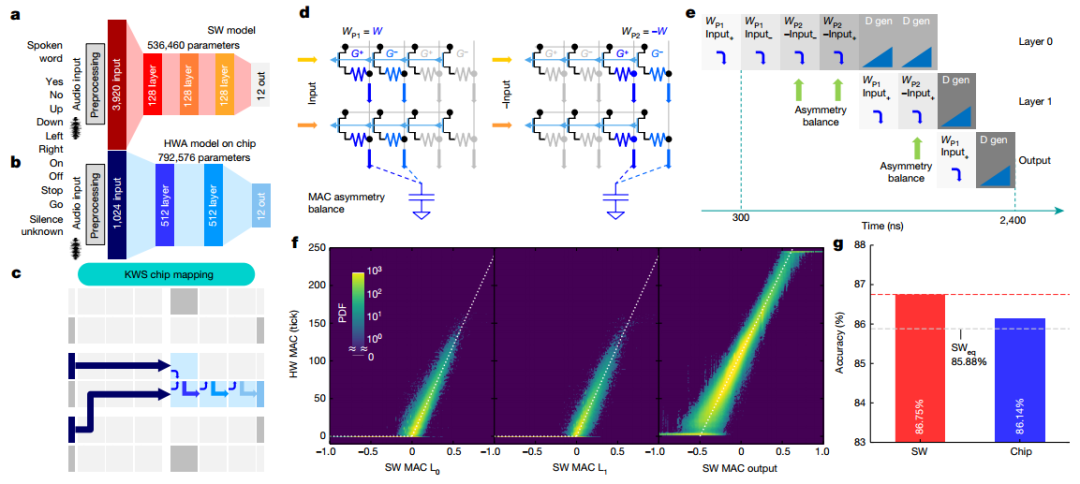
圖 端到端 KWS 任務(wù)
芯片上的 RNNT 映射
作者實(shí)施了MLPerf數(shù)據(jù)中心網(wǎng)絡(luò)RNNT作為行業(yè)相關(guān)的工作負(fù)載演示。當(dāng) RNNT等大型DNN以降低的數(shù)字精度實(shí)現(xiàn)時,整個網(wǎng)絡(luò)的最佳精度選擇可能會有所不同。研究表明即使使用激進(jìn)的量化,不易受影響的層或整個網(wǎng)絡(luò)塊仍將提供較低的 WER,而高度敏感的塊即使對于少量的權(quán)重量化也將表現(xiàn)出較高的 WER。對每個單獨(dú)的層重復(fù)此過程以識別最敏感的層,接著將 MLPerf 權(quán)重映射到分布在5個芯片上的142個圖塊上。在總共 45,321,309 個網(wǎng)絡(luò)權(quán)重和偏差參數(shù)中,45,261,568 個被映射到模擬存儲器(權(quán)重的 99.9%)。
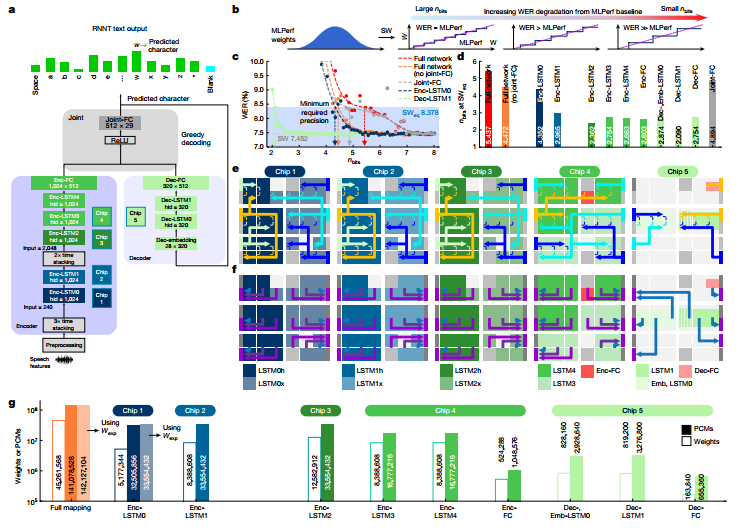
圖 用于語音轉(zhuǎn)錄的 MLPerf RNNT 網(wǎng)絡(luò)
準(zhǔn)確度結(jié)果
作者展示了2513個音頻查詢的完整 Librispeech 驗(yàn)證數(shù)據(jù)集的權(quán)重映射和編程后的實(shí)驗(yàn)WER。總WER為9.475%,與SW 基線相比總體下降了 2.02%。在本實(shí)驗(yàn)中,通過芯片推斷完整的Librispeech驗(yàn)證數(shù)據(jù)集并保存輸出結(jié)果。然后將這些輸入到芯片 2 中,依此類推,輸入到所有 5 個芯片中。即使在PCM漂移超過1周后重復(fù)進(jìn)行,且沒有任何重新校準(zhǔn)或重量重新編程,RNNT WER 也僅下降了 0.4%。
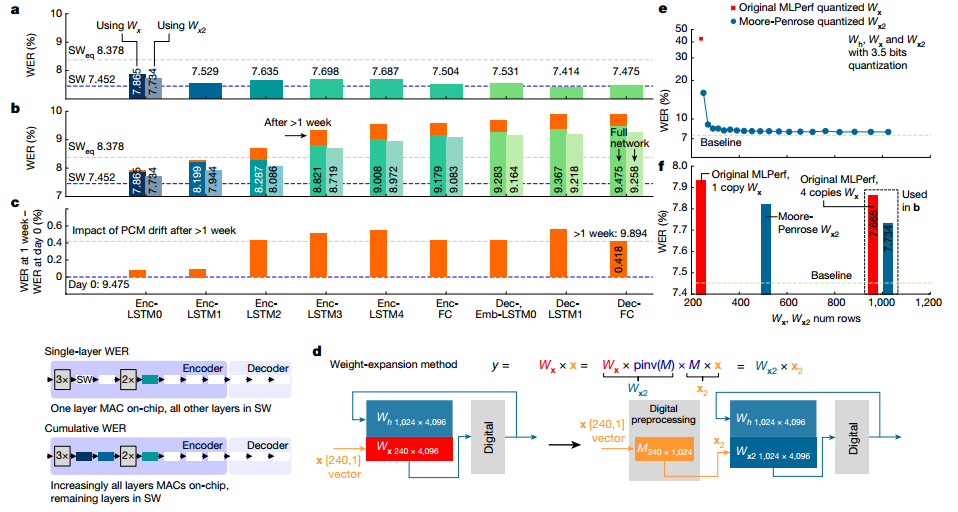
圖 在 MLPerf RNNT上使用Librispeech進(jìn)行WER實(shí)驗(yàn)
電源和系統(tǒng)性能
作者還測量了推理操作期間每個芯片的全部功耗。所有控制和通信電路均以 0.8V 驅(qū)動。芯片最佳功率性能 為12.40 TOPS/W。通過將積分時間減半,芯片的 TOPS/W 可以再提高 25%,但 WER 會額外降低1%。隨著重量的增加,使用本文報道的芯片的模擬人工智能系統(tǒng)可以在3.57W的功率下實(shí)現(xiàn)6.704TOPS/W,比MLPerf的最佳能效提高了14 倍,WER 為 9.258%。

圖 MLPerf RNNT功率和系統(tǒng)性能
-
芯片
+關(guān)注
關(guān)注
459文章
52253瀏覽量
436996 -
人工智能
+關(guān)注
關(guān)注
1804文章
48788瀏覽量
246950 -
存儲器件
+關(guān)注
關(guān)注
1文章
32瀏覽量
9838
原文標(biāo)題:Nature:人工智能芯片!
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論