 十分鐘讀懂旋轉編碼(RoPE)
十分鐘讀懂旋轉編碼(RoPE)
旋轉位置編碼(Rotary Position Embedding,RoPE)是論文 Roformer: Enhanced Transformer With Rotray Position Embedding 提出的一種能夠將相對位置信息依賴集成到 self-attention 中并提升 transformer 架構性能的位置編碼方式。而目前很火的 LLaMA、GLM 模型也是采用該位置編碼方式。
和相對位置編碼相比,RoPE 具有更好的外推性,目前是大模型相對位置編碼中應用最廣的方式之一。
備注:什么是大模型外推性?
外推性是指大模型在訓練時和預測時的輸入長度不一致,導致模型的泛化能力下降的問題。例如,如果一個模型在訓練時只使用了 512 個 token 的文本,那么在預測時如果輸入超過 512 個 token,模型可能無法正確處理。這就限制了大模型在處理長文本或多輪對話等任務時的效果。
旋轉編碼RoPE
1.1 基本概念
在介紹 RoPE 之前,先給出一些符號定義,以及基本背景。
首先定義一個長度為 的輸入序列為:
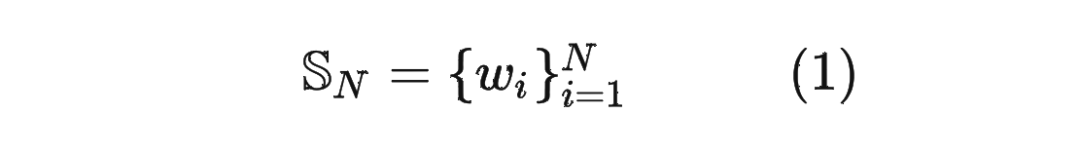
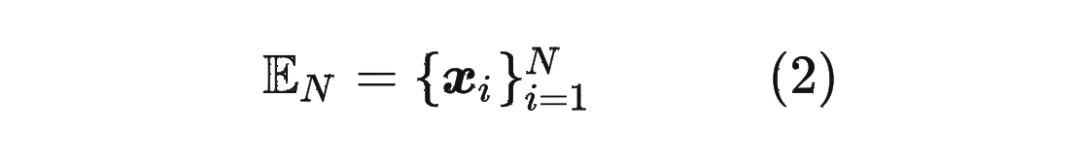
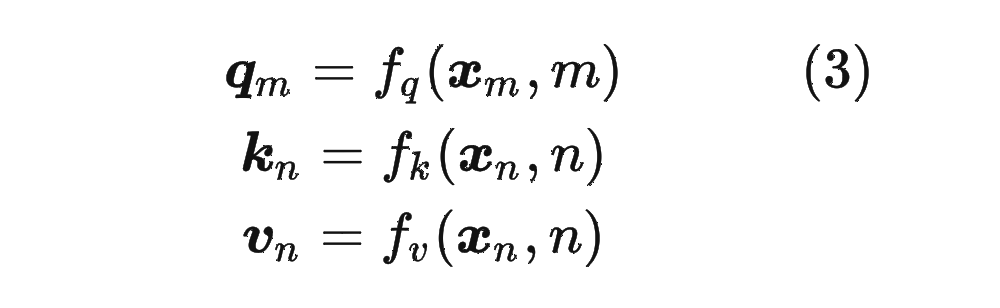
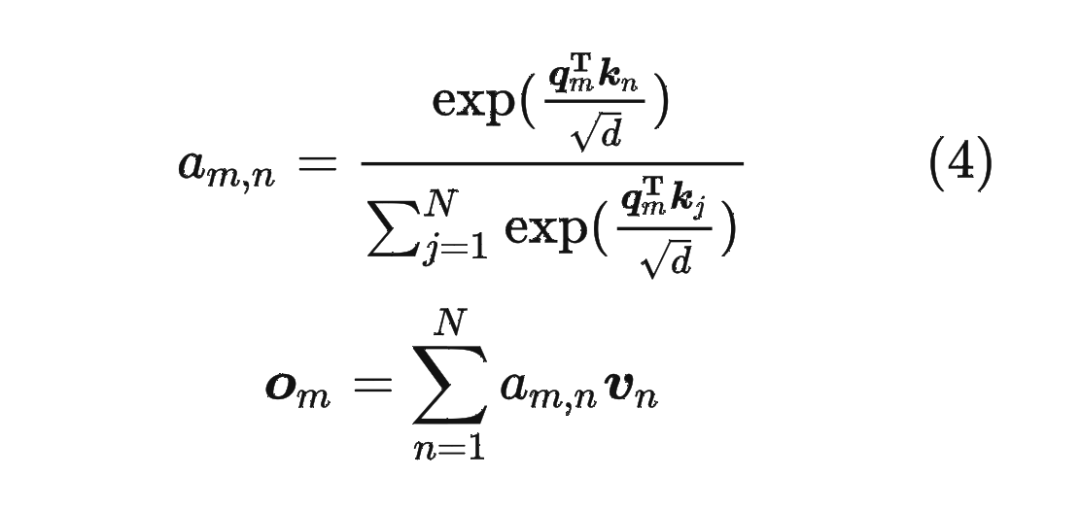
1.2 絕對位置編碼
對于位置編碼,常規的做法是在計算 query,key 和 value 向量之前,會計算一個位置編碼向量 加到詞嵌入 上,位置編碼向量 同樣也是 維向量,然后再乘以對應的變換矩陣 :
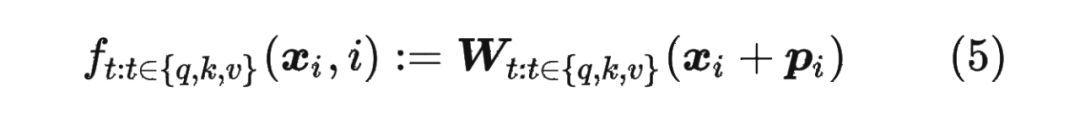
而經典的位置編碼向量 的計算方式是使用 Sinusoidal 函數:
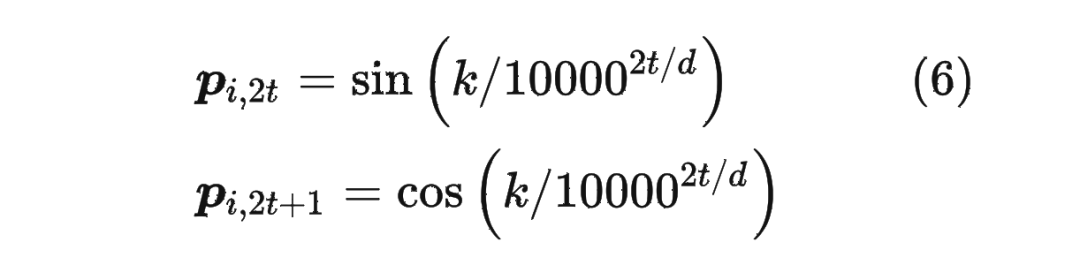
其中 表示位置 維度向量 中的第 位置分量也就是偶數索引位置的計算公式,而 就對應第 位置分量也就是奇數索引位置的計算公式。
1.3 2維旋轉位置編碼
論文中提出為了能利用上 token 之間的相對位置信息,假定 query 向量 和 key 向量 之間的內積操作可以被一個函數 表示,該函數 的輸入是詞嵌入向量 , 和它們之間的相對位置 :
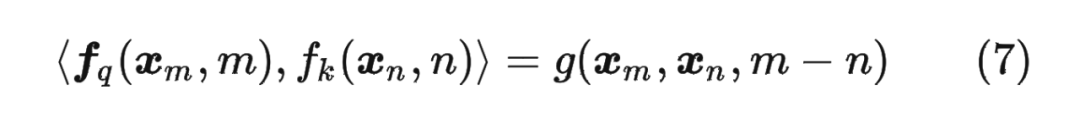 接下來的目標就是找到一個等價的位置編碼方式,從而使得上述關系成立。
假定現在詞嵌入向量的維度是兩維 ,這樣就可以利用上 2 維度平面上的向量的幾何性質,然后論文中提出了一個滿足上述關系的 和 的形式如下:
接下來的目標就是找到一個等價的位置編碼方式,從而使得上述關系成立。
假定現在詞嵌入向量的維度是兩維 ,這樣就可以利用上 2 維度平面上的向量的幾何性質,然后論文中提出了一個滿足上述關系的 和 的形式如下: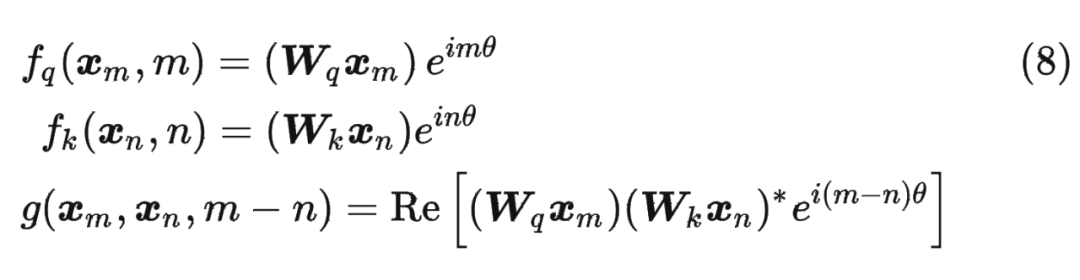 這里面 Re 表示復數的實部。
進一步地, 可以表示成下面的式子:
這里面 Re 表示復數的實部。
進一步地, 可以表示成下面的式子: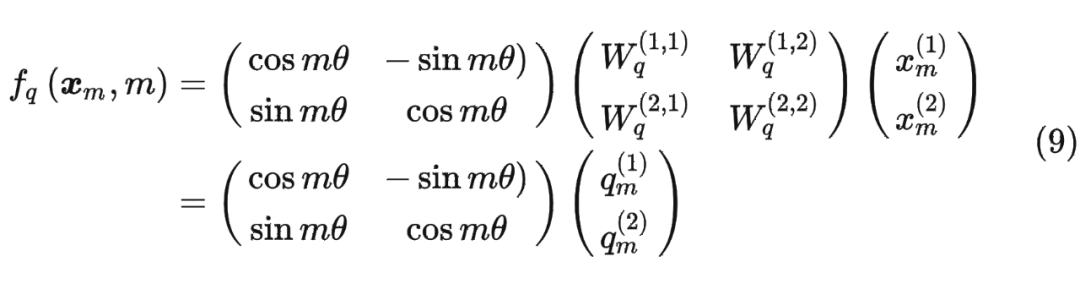 看到這里會發現,這不就是 query 向量乘以了一個旋轉矩陣嗎?這就是為什么叫做旋轉位置編碼的原因。
同理, 可以表示成下面的式子:
看到這里會發現,這不就是 query 向量乘以了一個旋轉矩陣嗎?這就是為什么叫做旋轉位置編碼的原因。
同理, 可以表示成下面的式子: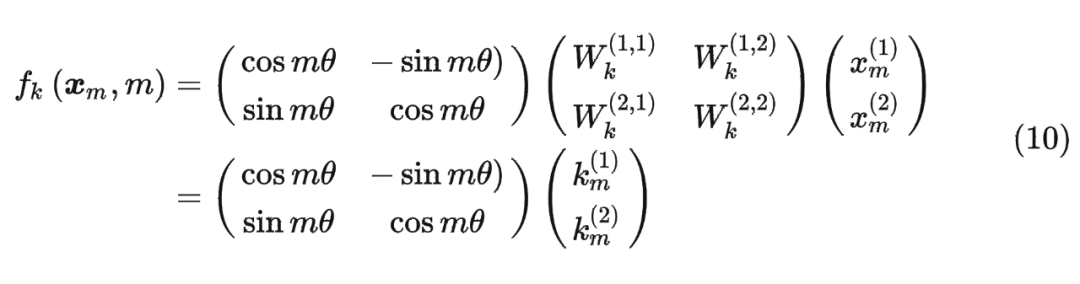 最終 可以表示如下:
最終 可以表示如下:
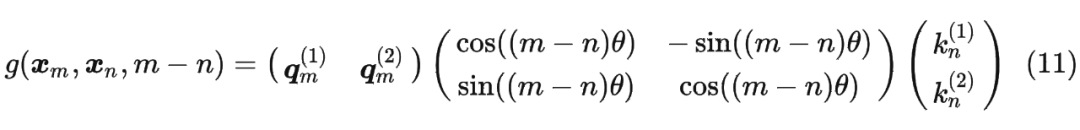
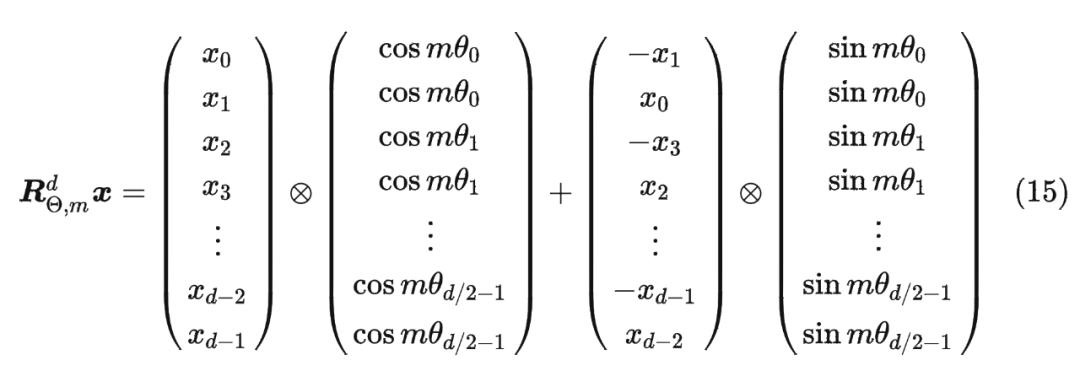
將2維推廣到任意維度,可以表示如下:
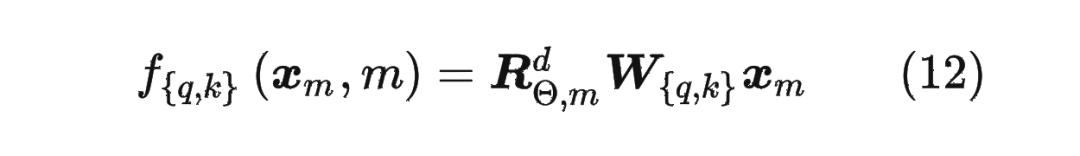 內積滿足線性疊加性,因此任意偶數維的 RoPE,我們都可以表示為二維情形的拼接,即
內積滿足線性疊加性,因此任意偶數維的 RoPE,我們都可以表示為二維情形的拼接,即 將 RoPE 應用到前面公式(4)的 Self-Attention 計算,可以得到包含相對位置信息的 Self-Attetion:
將 RoPE 應用到前面公式(4)的 Self-Attention 計算,可以得到包含相對位置信息的 Self-Attetion: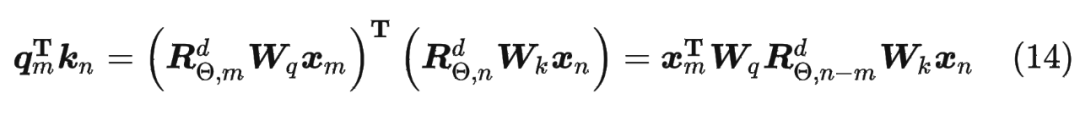
其中,。
值得指出的是,由于 是一個正交矩陣,它不會改變向量的模長,因此通常來說它不會改變原模型的穩定性。 1.5 RoPE 的高效計算由于 的稀疏性,所以直接用矩陣乘法來實現會很浪費算力,推薦通過下述方式來實現 RoPE:
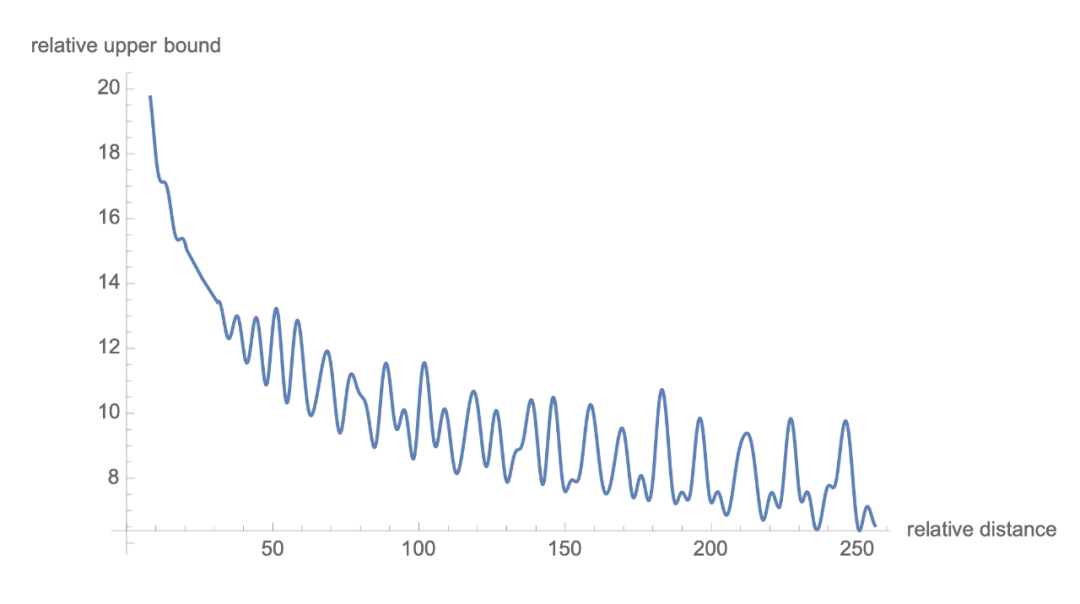
1.6 遠程衰減
可以看到,RoPE 形式上和前面公式(6)Sinusoidal 位置編碼有點相似,只不過 Sinusoidal 位置編碼是加性的,而 RoPE 可以視為乘性的。在 的選擇上,RoPE 同樣沿用了 Sinusoidal 位置編碼的方案,即 ,它可以帶來一定的遠程衰減性。
具體證明如下:將 兩兩分組后,它們加上 RoPE 后的內積可以用復數乘法表示為:
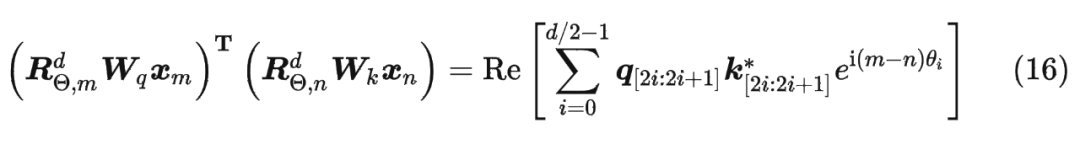
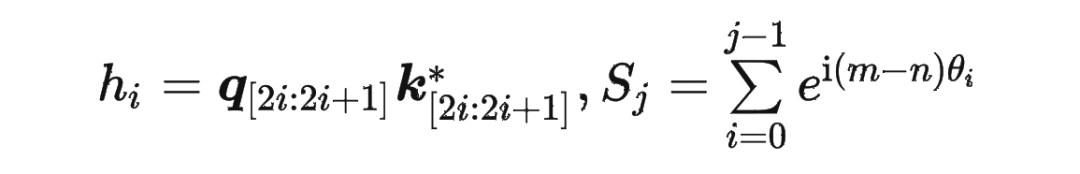
并約定 ,那么由 Abel 變換(分部求和法)可以得到:
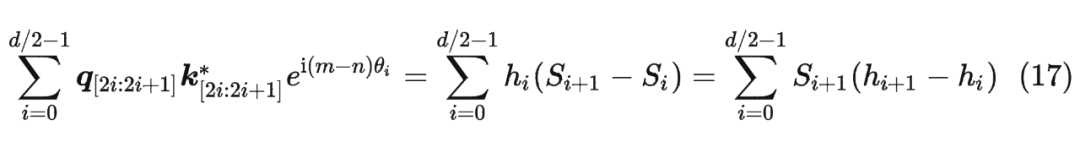
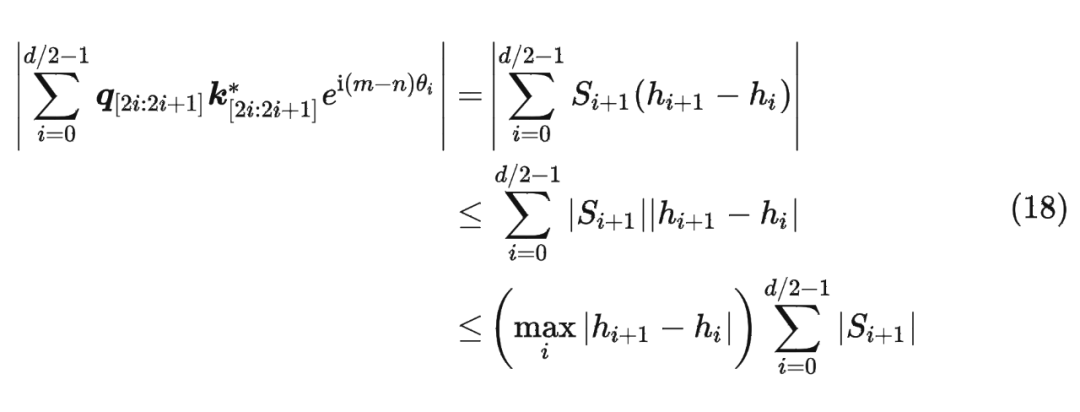
RoPE實驗
我們看一下 RoPE 在預訓練階段的實驗效果:
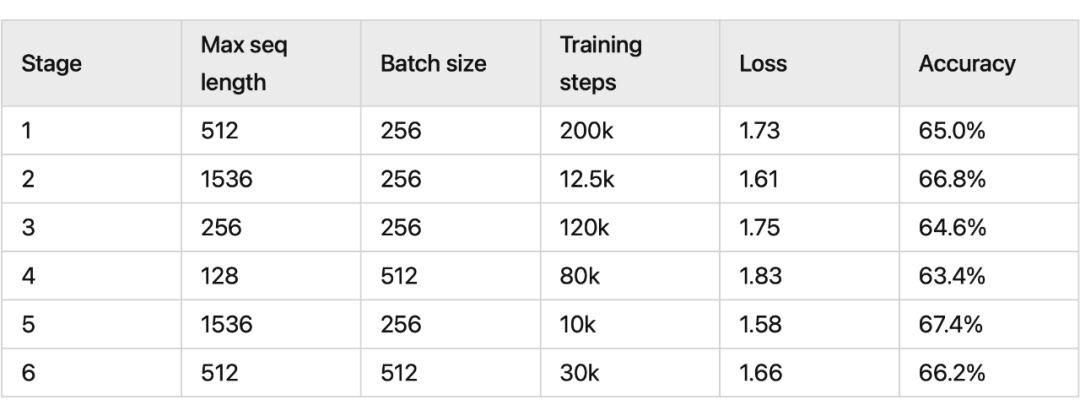
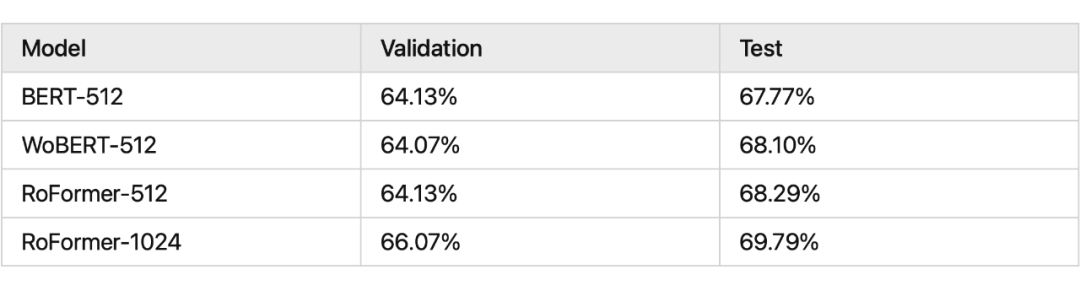 其中 RoFormer 是一個絕對位置編碼替換為 RoPE 的 WoBERT 模型,后面的參數(512)是微調時截斷的maxlen,可以看到 RoPE 確實能較好地處理長文本語義。
其中 RoFormer 是一個絕對位置編碼替換為 RoPE 的 WoBERT 模型,后面的參數(512)是微調時截斷的maxlen,可以看到 RoPE 確實能較好地處理長文本語義。
RoPE代碼實現
Meta 的 LLAMA 和 清華的 ChatGLM 都使用了 RoPE 編碼,下面看一下具體實現。
3.1 在LLAMA中的實現
#生成旋轉矩陣
defprecompute_freqs_cis(dim:int,seq_len:int,theta:float=10000.0):
#計算詞向量元素兩兩分組之后,每組元素對應的旋轉角度 heta_i
freqs=1.0/(theta**(torch.arange(0,dim,2)[:(dim//2)].float()/dim))
#生成token序列索引t=[0,1,...,seq_len-1]
t=torch.arange(seq_len,device=freqs.device)
#freqs.shape=[seq_len,dim//2]
freqs=torch.outer(t,freqs).float()#計算m* heta
#計算結果是個復數向量
#假設freqs=[x,y]
#則freqs_cis=[cos(x)+sin(x)i,cos(y)+sin(y)i]
freqs_cis=torch.polar(torch.ones_like(freqs),freqs)
returnfreqs_cis
#旋轉位置編碼計算
defapply_rotary_emb(
xq:torch.Tensor,
xk:torch.Tensor,
freqs_cis:torch.Tensor,
)->Tuple[torch.Tensor,torch.Tensor]:
#xq.shape=[batch_size,seq_len,dim]
#xq_.shape=[batch_size,seq_len,dim//2,2]
xq_=xq.float().reshape(*xq.shape[:-1],-1,2)
xk_=xk.float().reshape(*xk.shape[:-1],-1,2)
#轉為復數域
xq_=torch.view_as_complex(xq_)
xk_=torch.view_as_complex(xk_)
#應用旋轉操作,然后將結果轉回實數域
#xq_out.shape=[batch_size,seq_len,dim]
xq_out=torch.view_as_real(xq_*freqs_cis).flatten(2)
xk_out=torch.view_as_real(xk_*freqs_cis).flatten(2)
returnxq_out.type_as(xq),xk_out.type_as(xk)
classAttention(nn.Module):
def__init__(self,args:ModelArgs):
super().__init__()
self.wq=Linear(...)
self.wk=Linear(...)
self.wv=Linear(...)
self.freqs_cis=precompute_freqs_cis(dim,max_seq_len*2)
defforward(self,x:torch.Tensor):
bsz,seqlen,_=x.shape
xq,xk,xv=self.wq(x),self.wk(x),self.wv(x)
xq=xq.view(batch_size,seq_len,dim)
xk=xk.view(batch_size,seq_len,dim)
xv=xv.view(batch_size,seq_len,dim)
#attention操作之前,應用旋轉位置編碼
xq,xk=apply_rotary_emb(xq,xk,freqs_cis=freqs_cis)
#scores.shape=(bs,seqlen,seqlen)
scores=torch.matmul(xq,xk.transpose(1,2))/math.sqrt(dim)
scores=F.softmax(scores.float(),dim=-1)
output=torch.matmul(scores,xv)#(batch_size,seq_len,dim)
#......
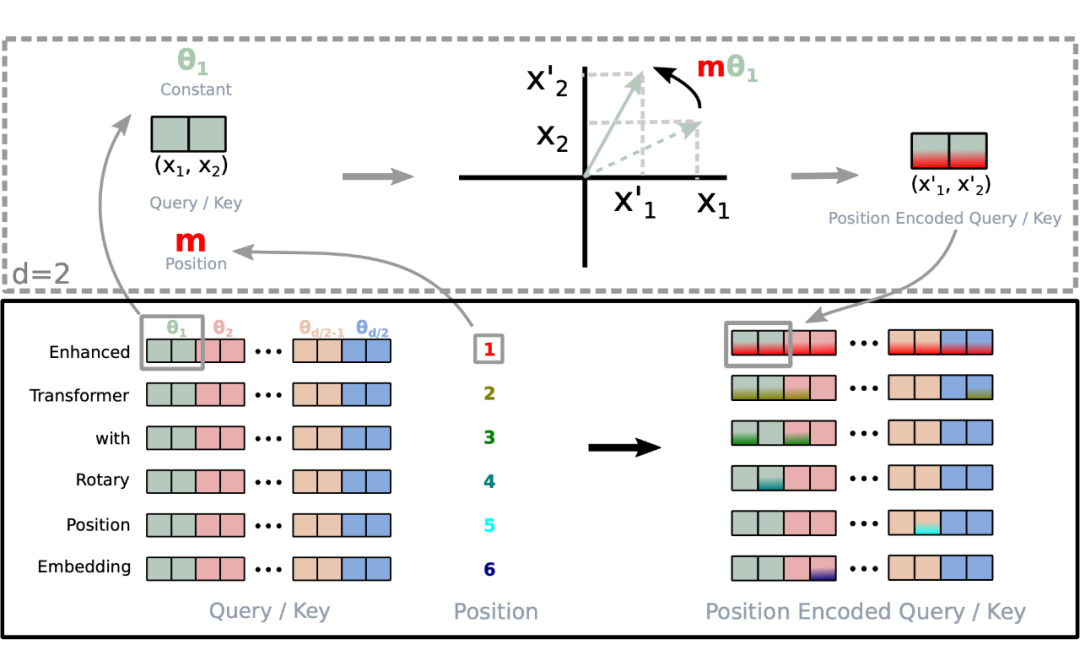
這里舉一個例子,假設 batch_size=10, seq_len=3, d=8,則調用函數 precompute_freqs_cis(d, seq_len) 后,生成結果為:
In[239]:freqs_cis
Out[239]:
tensor([[1.0000+0.0000j,1.0000+0.0000j,1.0000+0.0000j,1.0000+0.0000j],
[0.5403+0.8415j,0.9950+0.0998j,0.9999+0.0100j,1.0000+0.0010j],
[-0.4161+0.9093j,0.9801+0.1987j,0.9998+0.0200j,1.0000+0.0020j]])
以結果中的第二行為例(對應的 m = 1),也就是:
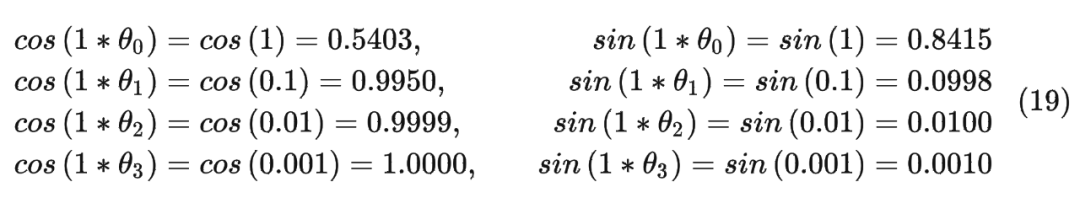 最終按照公式(12)可以得到編碼之后的 。
注意:在代碼中是直接用 freqs_cis[0] * xq_[0] 的結果表示第一個 token 對應的旋轉編碼(和公式 12 計算方式有所區別)。其中將原始的 query 向量 轉換為了復數形式。
最終按照公式(12)可以得到編碼之后的 。
注意:在代碼中是直接用 freqs_cis[0] * xq_[0] 的結果表示第一個 token 對應的旋轉編碼(和公式 12 計算方式有所區別)。其中將原始的 query 向量 轉換為了復數形式。
In[351]:q_=q.float().reshape(*q.shape[:-1],-1,2)
In[352]:q_[0]
Out[352]:
tensor([[[1.0247,0.4782],
[1.5593,0.2119],
[0.4175,0.5309],
[0.4858,0.1850]],
[[-1.7456,0.6849],
[0.3844,1.1492],
[0.1700,0.2106],
[0.5433,0.2261]],
[[-1.1206,0.6969],
[0.8371,-0.7765],
[-0.3076,0.1704],
[-0.5999,-1.7029]]])
In[353]:xq=torch.view_as_complex(q_)
In[354]:xq[0]
Out[354]:
tensor([[1.0247+0.4782j,1.5593+0.2119j,0.4175+0.5309j,0.4858+0.1850j],
[-1.7456+0.6849j,0.3844+1.1492j,0.1700+0.2106j,0.5433+0.2261j],
[-1.1206+0.6969j,0.8371-0.7765j,-0.3076+0.1704j,-0.5999-1.7029j]])
這里為什么可以這樣計算?
主要是利用了復數的乘法性質。
我們首先來復習一下復數乘法的性質:
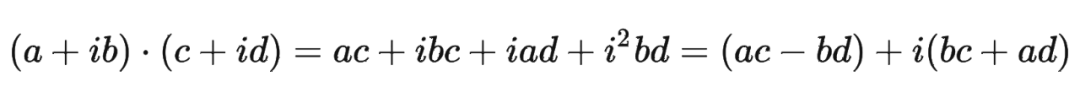
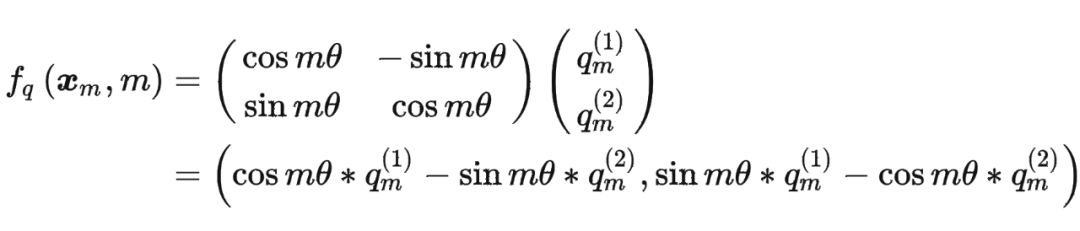
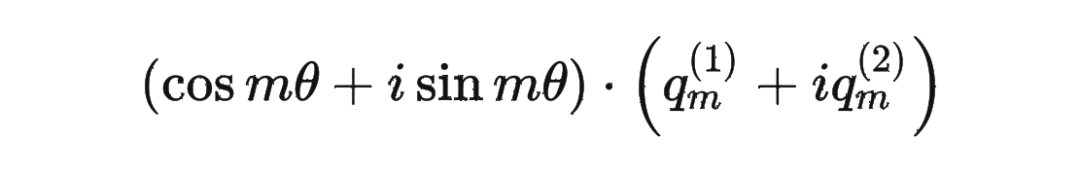
classRotaryEmbedding(torch.nn.Module):
def__init__(self,dim,base=10000,precision=torch.half,learnable=False):
super().__init__()
#計算 heta_i
inv_freq=1./(base**(torch.arange(0,dim,2).float()/dim))
inv_freq=inv_freq.half()
self.learnable=learnable
iflearnable:
self.inv_freq=torch.nn.Parameter(inv_freq)
self.max_seq_len_cached=None
else:
self.register_buffer('inv_freq',inv_freq)
self.max_seq_len_cached=None
self.cos_cached=None
self.sin_cached=None
self.precision=precision
defforward(self,x,seq_dim=1,seq_len=None):
ifseq_lenisNone:
seq_len=x.shape[seq_dim]
ifself.max_seq_len_cachedisNoneor(seq_len>self.max_seq_len_cached):
self.max_seq_len_cached=Noneifself.learnableelseseq_len
#生成token序列索引t=[0,1,...,seq_len-1]
t=torch.arange(seq_len,device=x.device,dtype=self.inv_freq.dtype)
#對應m* heta
freqs=torch.einsum('i,j->ij',t,self.inv_freq)
#將m* heta拼接兩次,對應復數的實部和虛部
emb=torch.cat((freqs,freqs),dim=-1).to(x.device)
ifself.precision==torch.bfloat16:
emb=emb.float()
#[sx,1(b*np),hn]
cos_cached=emb.cos()[:,None,:]#計算得到cos(m* heta)
sin_cached=emb.sin()[:,None,:]#計算得到cos(m* heta)
ifself.precision==torch.bfloat16:
cos_cached=cos_cached.bfloat16()
sin_cached=sin_cached.bfloat16()
ifself.learnable:
returncos_cached,sin_cached
self.cos_cached,self.sin_cached=cos_cached,sin_cached
returnself.cos_cached[:seq_len,...],self.sin_cached[:seq_len,...]
def_apply(self,fn):
ifself.cos_cachedisnotNone:
self.cos_cached=fn(self.cos_cached)
ifself.sin_cachedisnotNone:
self.sin_cached=fn(self.sin_cached)
returnsuper()._apply(fn)
defrotate_half(x):
x1,x2=x[...,:x.shape[-1]//2],x[...,x.shape[-1]//2:]
returntorch.cat((-x2,x1),dim=x1.ndim-1)
RoPE的外推性
我們都知道 RoPE 具有很好的外推性,前面的實驗結果也證明了這一點。這里解釋下具體原因。 RoPE 可以通過旋轉矩陣來實現位置編碼的外推,即可以通過旋轉矩陣來生成超過預期訓練長度的位置編碼。這樣可以提高模型的泛化能力和魯棒性。 我們回顧一下 RoPE 的工作原理:假設我們有一個 維的絕對位置編碼 ,其中 是位置索引。我們可以將 看成一個 維空間中的一個點。我們可以定義一個 維空間中的一個旋轉矩陣 ,它可以將任意一個點沿著某個軸旋轉一定的角度。我們可以用 來變換 ,得到一個新的點 。我們可以發現, 和 的距離是相等的,即 。這意味著 和 的相對關系沒有改變。但是, 和 的距離可能發生改變,即 。這意味著 和 的相對關系有所改變。因此,我們可以用 來調整不同位置之間的相對關系。 如果我們想要生成超過預訓練長度的位置編碼,我們只需要用 來重復變換最后一個預訓練位置編碼 ,得到新的位置編碼
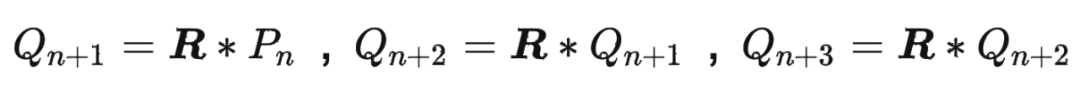 依此類推。這樣就可以得到任意長度的位置編碼序列 ,其中 可以大于 。由于 是一個正交矩陣,它保證了 和 的距離不會無限增大或縮小,而是在一個有限范圍內波動。這樣就可以避免數值溢出或下溢的問題。同時,由于 是一個可逆矩陣,它保證了 和 的距離可以通過 的逆矩陣 還原到 和 的距離,即
依此類推。這樣就可以得到任意長度的位置編碼序列 ,其中 可以大于 。由于 是一個正交矩陣,它保證了 和 的距離不會無限增大或縮小,而是在一個有限范圍內波動。這樣就可以避免數值溢出或下溢的問題。同時,由于 是一個可逆矩陣,它保證了 和 的距離可以通過 的逆矩陣 還原到 和 的距離,即
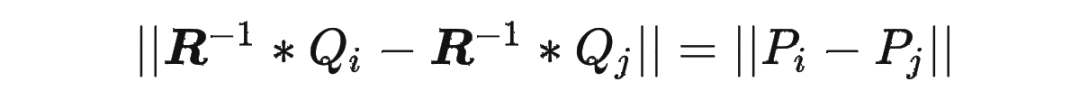
總結
最近一直聽到旋轉編碼這個詞,但是一直沒有仔細看具體原理。今天花時間仔細看了一遍,確實理論寫的比較完備,而且實驗效果也不錯。目前很多的大模型,都選擇了使用了這種編碼方式(LLAMA、GLM 等)。
附錄
這里補充一下前面公式 1.3.2 節中,公式(8)~(11)是怎么推導出來的。 回到之前的公式(8),編碼之后的 以及內積 的形式如下:
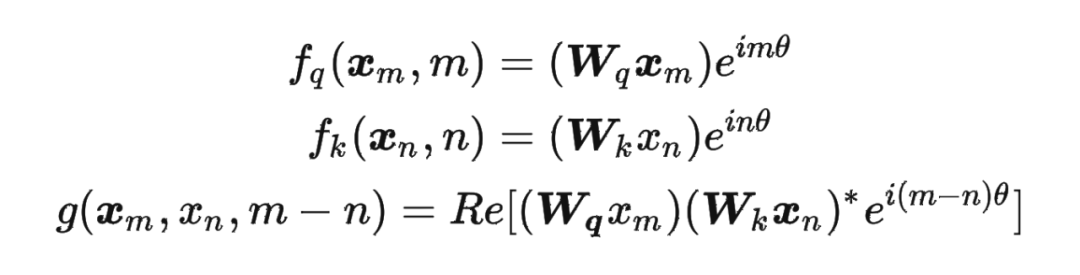
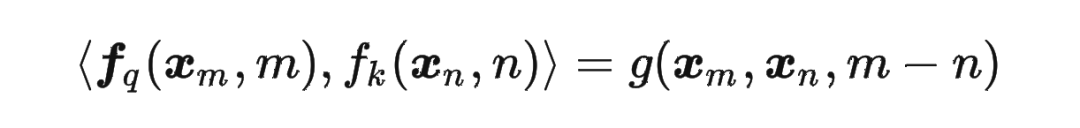
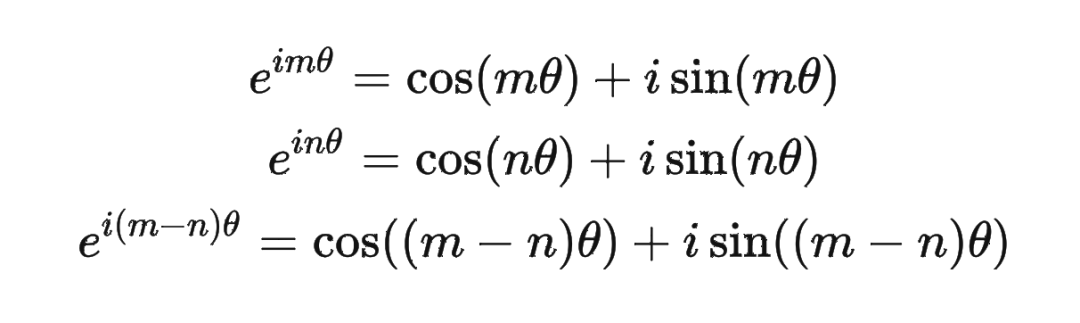 然后我們看回公式:
然后我們看回公式: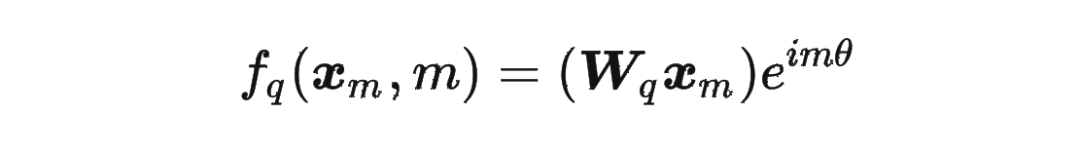 其中 是個二維矩陣, 是個二維向量,相乘的結果也是一個二維向量,這里用 表示:
其中 是個二維矩陣, 是個二維向量,相乘的結果也是一個二維向量,這里用 表示:
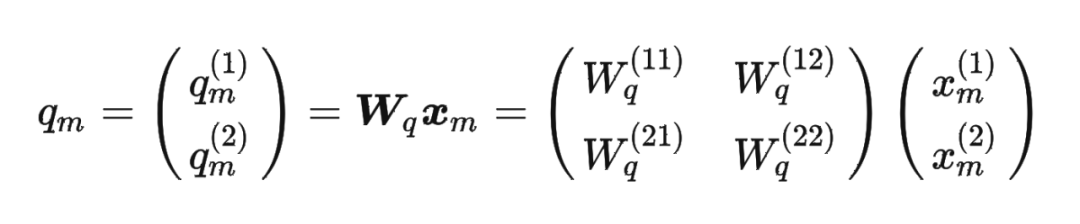
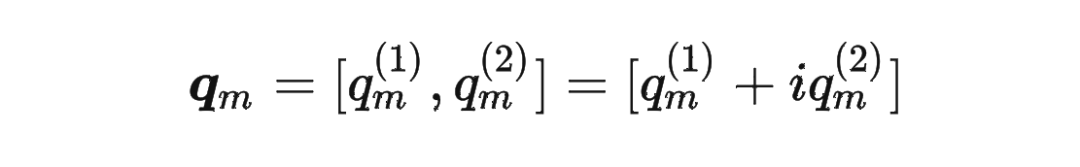 接著
接著
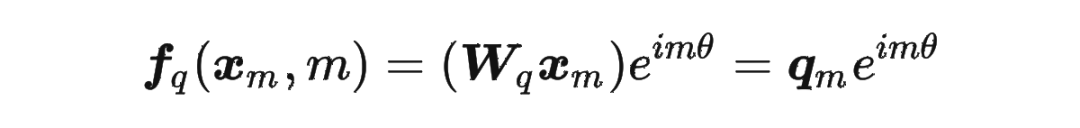
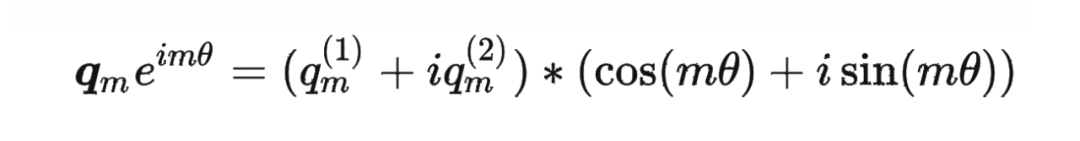
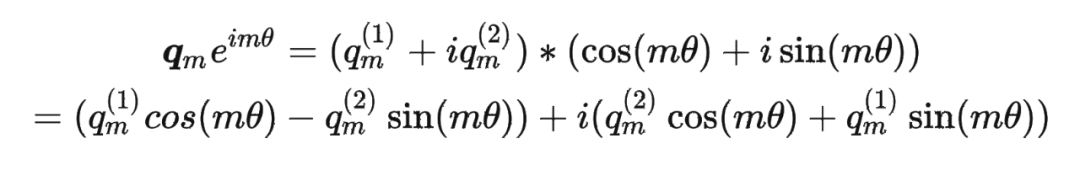
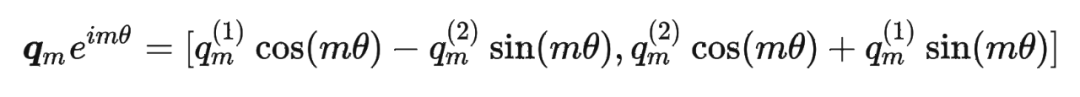
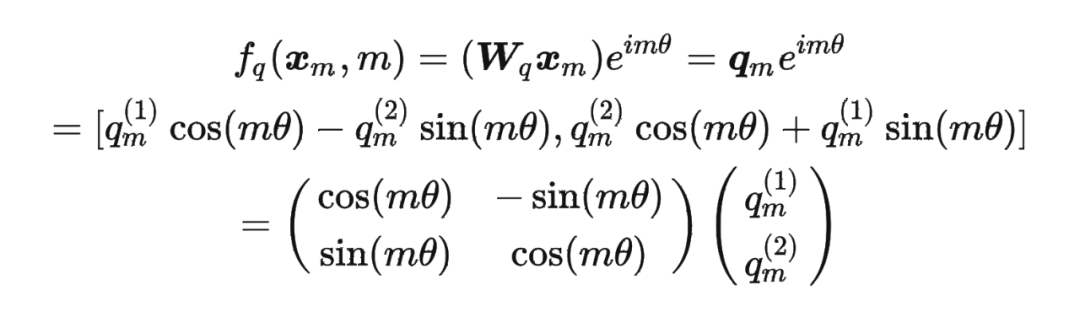
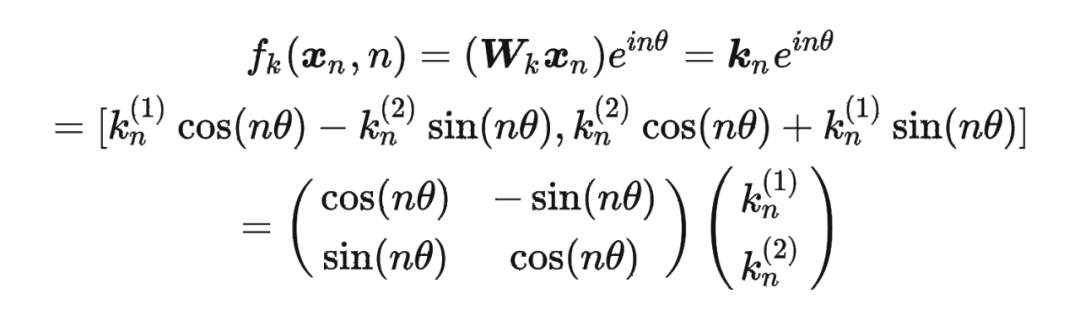
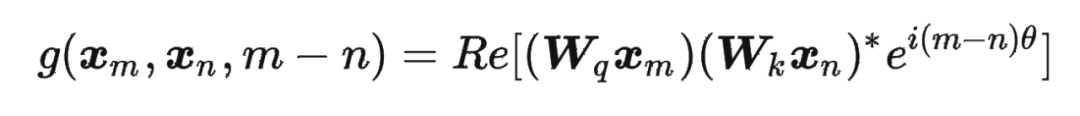 其中 表示一個復數 的實部部分,而 則表示復數 的共軛。
復習一下共軛復數的定義:
其中 表示一個復數 的實部部分,而 則表示復數 的共軛。
復習一下共軛復數的定義:
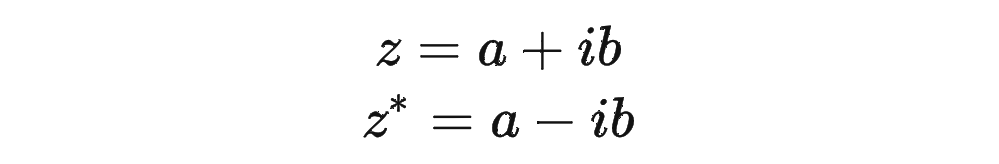
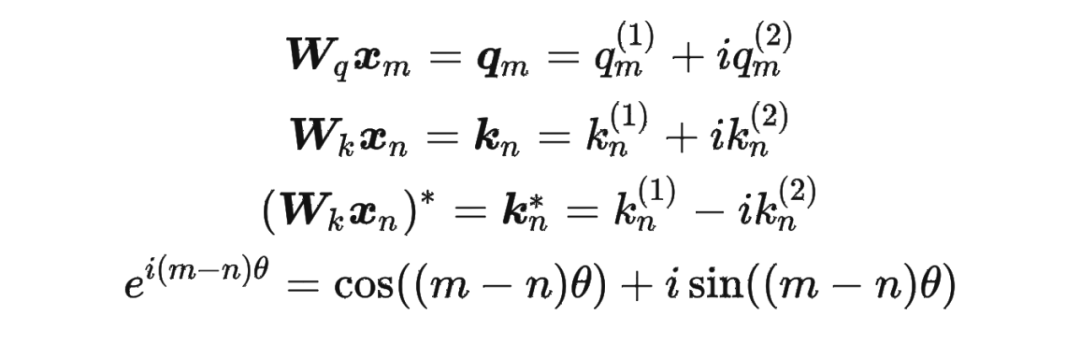
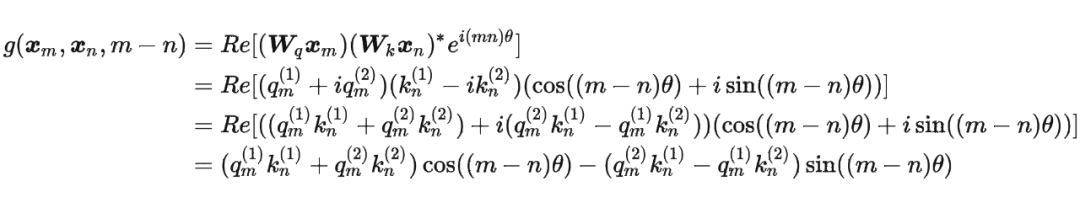
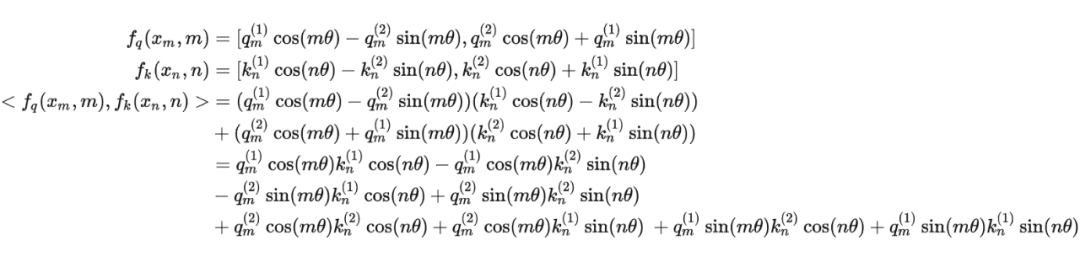
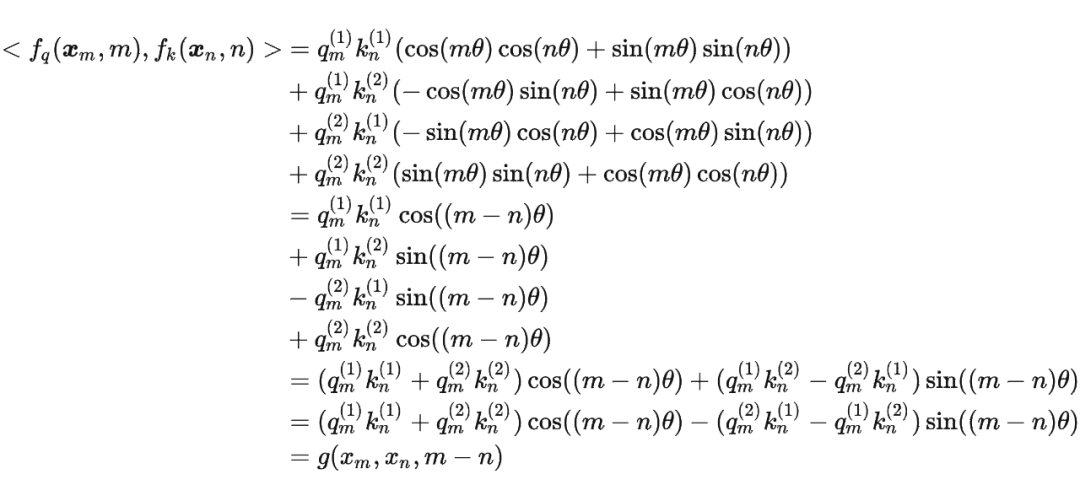
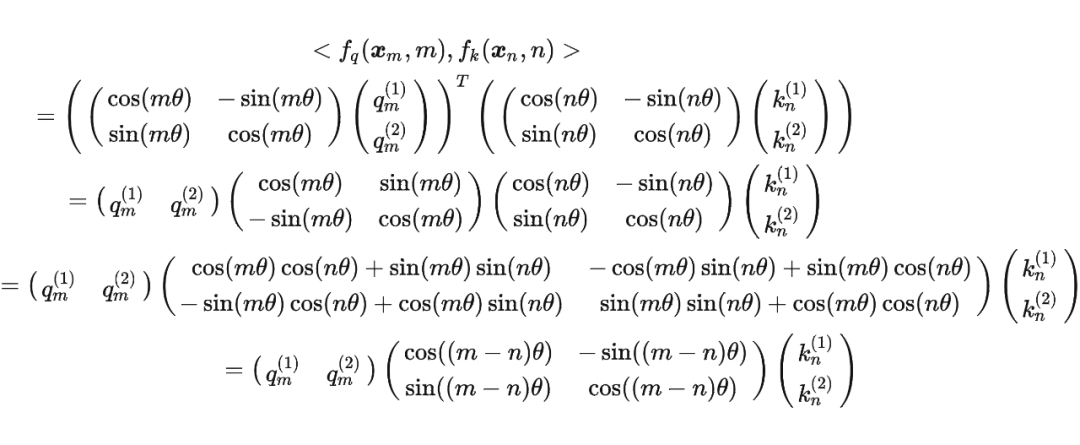 ?
?
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
向量
+關注
關注
0文章
55瀏覽量
11856 -
旋轉編碼
+關注
關注
0文章
6瀏覽量
10554 -
大模型
+關注
關注
2文章
3035瀏覽量
3840
原文標題:十分鐘讀懂旋轉編碼(RoPE)
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
快充技術&芯片詳解 十分鐘讓你的手機滿血復活
快沖技術全面來襲!你了解市面上的這些手機用的快充技術原理嗎?你知道有哪些電池管理芯片的使用讓你的手機十分鐘滿血復活嗎?今天跟小編一起,了解一下這些快充技術和芯片吧。
發表于 06-23 13:35
?6.7w次閱讀
ModelSim SE 十分鐘入門
ModelSim SE 十分鐘入門[table=98%][tr][td][table=98%][tr][td]1.ModuleSim SE 快速入門本文以ModelSim SE 5.6版本為
發表于 08-12 15:07
全球首發十分鐘快速充滿電移動電源
`快速充電無壓力:十分鐘能充滿的移動電源MY POWER 任性系列土豪金版深圳市麥可電源有限公司是一家專業從事高頻開關電源研發、生產、銷售、服務于一體的綜合性企業。產品廣泛應用于網絡系統、安防系統
發表于 03-25 14:56
采集系統需要隔十分鐘采集10S數據,怎么實現?
畢業實驗需要用labview做個采集界面,但是我沒有這方面基礎,所以這個隔十分鐘采集10S數據功能怎么也實現不了,現在我就做到下面這樣,求大神指導一二~不勝感激!
發表于 01-13 12:56
十分鐘學會Xilinx FPGA 設計
十分鐘學會Xilinx FPGA 設計
Xilinx FPGA設計基礎系統地介紹了Xilinx公司FPGA的結構特點和相關開發軟件的使用方法,詳細描述了VHDL語言的語法和設計方法,并深入討
發表于 03-15 15:09
?178次下載
三星改革智能手機充電技術,充滿只需十分鐘
現在的手機電池續航短的問題一直手機領域研究的重點。近日,三星爆出猛料,宣布已經成功研制出石墨烯電池,以后充電只需要十分鐘。
發表于 12-02 11:24
?2215次閱讀
英國搭建太陽能汽車充電網試點項目,電動汽車在三十分鐘內完成充電
英國計劃在國內設立100多座以太陽能為能源的汽車充電站。每個充電站場地配備24個汽車充電區,車主可用手機app預訂充電。據悉,所有電動汽車均能在三十分鐘內完成充電,部分車型甚至在十分鐘內即可充滿。
十分鐘分析穩壓三極管工作原理資料下載
電子發燒友網為你提供十分鐘分析穩壓三極管工作原理資料下載的電子資料下載,更有其他相關的電路圖、源代碼、課件教程、中文資料、英文資料、參考設計、用戶指南、解決方案等資料,希望可以幫助到廣大的電子工程師們。
發表于 04-11 08:54
?3次下載






 工商網監
工商網監
評論