") 基于異常上線場景的實時攔截與問題分發(fā)策略
基于異常上線場景的實時攔截與問題分發(fā)策略

性能中臺負(fù)責(zé)MEG端研發(fā)數(shù)據(jù)的接入、傳輸、管理、應(yīng)用等各個環(huán)節(jié)。為了應(yīng)對移動應(yīng)用領(lǐng)域中端技術(shù)的快速迭代和線上突增問題的挑戰(zhàn),中臺提出了實時攔截與問題的分發(fā)機(jī)制,旨在在端上線的不同階段及時發(fā)現(xiàn)并攔截異常上線,最大程度減少線上變更對用戶體驗的不良影響。本文在數(shù)據(jù)建設(shè)的時效性和準(zhǔn)確性上進(jìn)行深入的探討,包括:變更上線的染色過程、基于染色I(xiàn)D的性能核心數(shù)據(jù)指標(biāo)的監(jiān)控、線上問題實時分發(fā)至相關(guān)模塊組件和人員等。
01
背景
1.1 業(yè)務(wù)背景
在快速發(fā)展的移動應(yīng)用領(lǐng)域中,持續(xù)的技術(shù)迭代是保持APP競爭力的關(guān)鍵因素。然而,對于規(guī)模龐大、用戶眾多的APP應(yīng)用,每一次的變更上線都存在引入線上問題的風(fēng)險。APP的各個組件模塊相互交織,一旦某處出現(xiàn)異常,往往會像連鎖反應(yīng)一樣影響整個系統(tǒng)的穩(wěn)定性,導(dǎo)致用戶體驗的下降。在以往的經(jīng)驗中,即便在開發(fā)和測試階段充分驗證,也難免會有一些問題在真實用戶環(huán)境中暴露出來。這些問題可能表現(xiàn)為崩潰、卡頓、功能失效等,嚴(yán)重影響用戶的使用體驗。在過去,應(yīng)對這些問題通常是事后進(jìn)行問題修復(fù),然而這種方式并不能完全避免線上問題對用戶體驗的不良影響。因此我們希望在業(yè)務(wù)迭代變更上線的過程中,盡可能早的發(fā)現(xiàn)和攔截問題,最大程度的降低問題對用戶的影響。因此,性能中臺引入了多級攔截和問題分發(fā)的機(jī)制,這一機(jī)制旨在在變更上線的不同灰度放量階段,對每次上線或者放量操作進(jìn)行染色形成唯一染色I(xiàn)D,通過對每個染色I(xiàn)D的核心性能數(shù)據(jù)指標(biāo)進(jìn)行監(jiān)控,一旦發(fā)現(xiàn)異常,多級攔截機(jī)制將會被觸發(fā),攔截本次上線以及后續(xù)放量。同時,問題實時分發(fā)機(jī)制能夠直接將問題指向?qū)е略搯栴}發(fā)生的模塊和組件以及開發(fā)和測試人員。從而準(zhǔn)確定位問題,并迅速修復(fù),避免問題在更大范圍內(nèi)擴(kuò)散。
1.2 技術(shù)背景
實時UV計算:在處理異常上線的攔截過程中,數(shù)據(jù)的實時消費(fèi)以及數(shù)據(jù)的時效性的要求特別高,必須在分鐘級別內(nèi)完成。同時,業(yè)務(wù)方不僅需要獲得異常的PV數(shù),同時也需要獲得在各個維度下異常影響的用戶數(shù)(UV)。但實時UV計算不能簡單地累加,這涉及到同維度間用戶交集的處理。例如:A版本和B版本異常影響的用戶數(shù)分別是100,但整體用戶數(shù)實際上可能不足200。但是也不能直接存儲用戶ID,例如通過使用HashSet或者HashMap存儲所有的用戶ID進(jìn)行去重,這面對大量用戶時,會占用大量的計算節(jié)點(diǎn)內(nèi)存資源。因此,我們采取一種計算的時效性和準(zhǔn)確性較高的數(shù)據(jù)結(jié)構(gòu)Bitmap來計算實時UV。
Bitmap 的底層數(shù)據(jù)結(jié)構(gòu)用的是 String 類型的 SDS 數(shù)據(jù)結(jié)構(gòu)來保存位數(shù)組,把每個字節(jié)數(shù)組的 8 個 bit 位利用起來,每個 bit 位 表示一個元素的二值狀態(tài)。該數(shù)據(jù)結(jié)構(gòu)能節(jié)約大量的存儲,同時在用戶群做交集和并集運(yùn)算的時候也有極大的便利。例如,每個用戶ID如果存儲在HashSet或者HashMap中,需要占4個字節(jié)即32bit,而一個用戶在Bitmap中只占一個bit。在做交并集運(yùn)算時,例如,員工1、員工2都是程序員,員工1使用蘋果手機(jī),那么如何查找使用蘋果手機(jī)的程序員用戶?
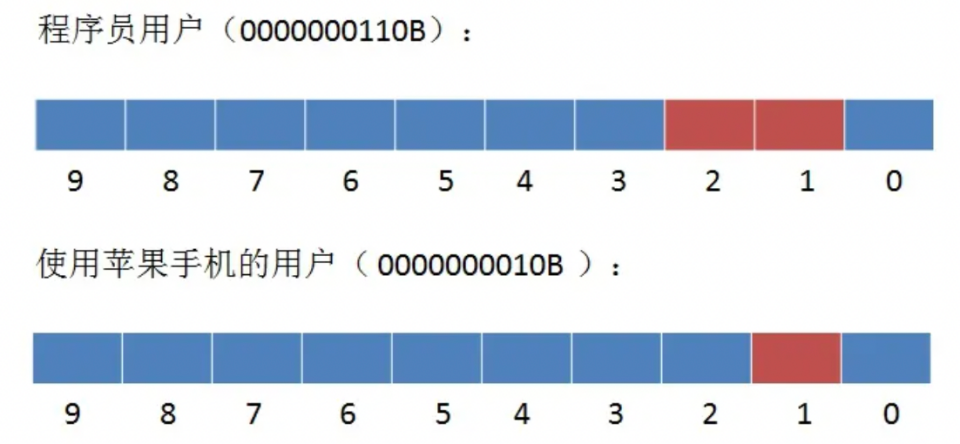
直接使用位運(yùn)算,使用蘋果手機(jī)的程序員用戶:(0000000110B & 0000000010B = 0000000010B)

異常反混淆:主要用于問題分發(fā)階段。APP廠商在發(fā)布應(yīng)用程序包時,通常會對包進(jìn)行混淆操作,這是為了提高APP應(yīng)用的安全性和減少反編譯的風(fēng)險。混淆是將源代碼中的符號、名稱和結(jié)構(gòu)等轉(zhuǎn)換為難以理解的形式,使得反編譯后的代碼難以還原為原始的源代碼,但是APP上報的異常信息也被混淆了。反混淆操作是將混淆后的異常信息還原為可讀的形式,使開發(fā)人員能夠更準(zhǔn)確地分析問題的原因,并迅速采取正確的修復(fù)措施。在APP產(chǎn)出應(yīng)用程序包時,同時也會產(chǎn)生一份用于反混淆異常信息的映射文件(密碼本),通過映射文件 + 解析算法對混淆的異常進(jìn)行解析,即可得到已讀的異常堆棧。
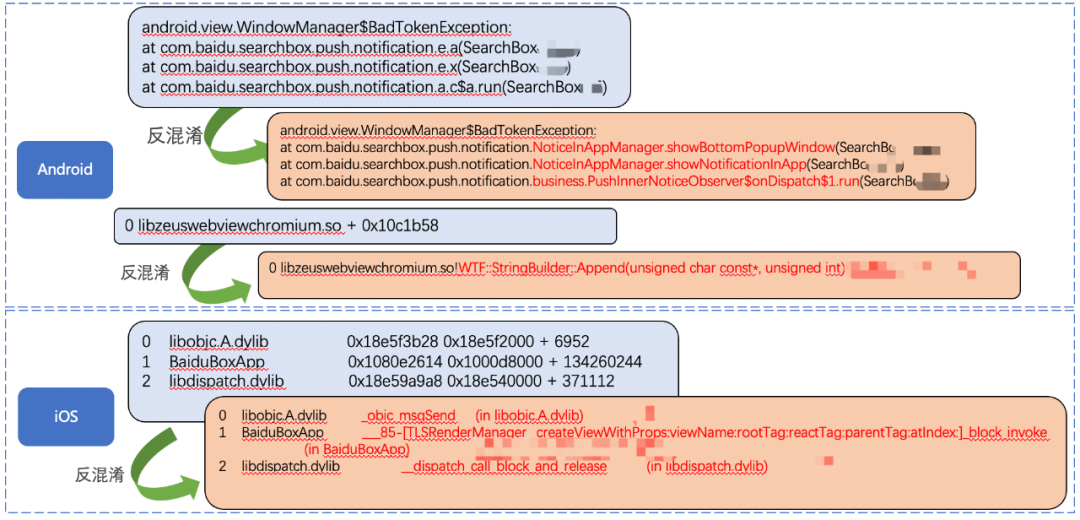
△異常信息反混淆過程
1.3 名詞解釋
性能中臺:性能中臺是APP性能追蹤的一站式解決方案平臺,為APP提供全面、實時的性能分析服務(wù)與工具鏈。
移動線上質(zhì)量平臺:移動線上質(zhì)量平臺是移動端APP發(fā)包后,用來查看、分析包質(zhì)量數(shù)據(jù)、進(jìn)行核心指標(biāo)監(jiān)控/報警、變更異常攔截。
日志中臺:指端日志中臺,包括端日志全生命周期的能力建設(shè)。包括打點(diǎn)SDK / 打點(diǎn)server/日志管理平臺等核心組件。
Tekes平臺:App端研發(fā)平臺,提供包組件管理等基礎(chǔ)設(shè)施。
GEEK TALK
02
系統(tǒng)設(shè)計
2.1整體流程
在以往的流程中,針對客戶端上線變更,我們通常使用大盤性能指標(biāo)來進(jìn)行監(jiān)控,以便進(jìn)行問題定位和止損。然而,在灰度用戶數(shù)量較少的情況下,線上問題往往無法在大盤性能指標(biāo)中產(chǎn)生明顯波動。當(dāng)業(yè)務(wù)決定全量上線或擴(kuò)大灰度用戶規(guī)模時,問題就可能顯現(xiàn)出來了。在問題定位和解決的階段,我們過多地依賴人工干預(yù)和手動排查,這導(dǎo)致問題定位和解決的時間較長,并可能升級為事故。因此,在舊流程中,線上問題影響面大小主要取決于灰度用戶的規(guī)模以及問題排查人員對客戶端各個模塊和相關(guān)人員的了解程度,這是不合理的。因此,系統(tǒng)設(shè)計的關(guān)鍵在于解決兩個核心問題:首先,如何在灰度階段攔截問題,避免其進(jìn)一步擴(kuò)大;其次,一旦線上問題出現(xiàn),如何能夠迅速進(jìn)行問題召回與解決。
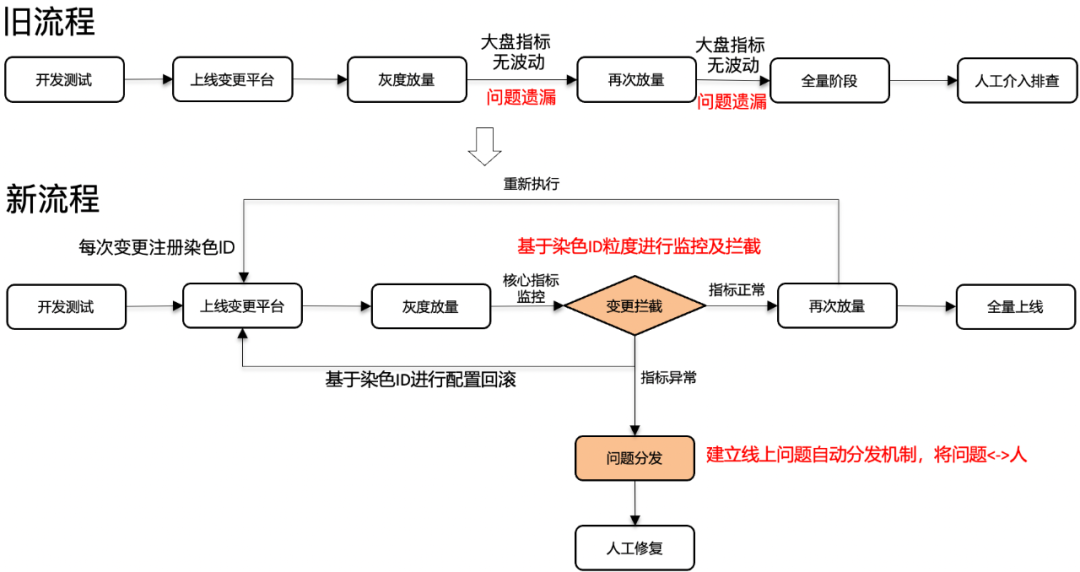
△線上異常實時攔截與問題分發(fā)整體流程設(shè)計圖
因此,在新流程中,引入了兩個關(guān)鍵模塊:"變更攔截模塊"和"問題分發(fā)模塊"。對于每次平臺的上線變更,必須先在變更攔截模塊中進(jìn)行注冊,從而生成一個唯一的上線染色I(xiàn)D。同時,將染色I(xiàn)D下發(fā)至本次變更上線的用戶客戶端。此后,該數(shù)據(jù)集的用戶日志將攜帶染色I(xiàn)D進(jìn)行上報。變更攔截模塊將基于染色I(xiàn)D的粒度進(jìn)行監(jiān)控和攔截,以保證在上線過程中問題的及時發(fā)現(xiàn)。同時,問題分發(fā)模塊建立了問題自動分發(fā)機(jī)制。當(dāng)一個上線變更被攔截或者在線上出現(xiàn)問題時,該模塊將直接將問題指派給涉及問題的模塊、組件,以及相關(guān)的研發(fā)和測試人員。協(xié)助業(yè)務(wù)方快速準(zhǔn)確的定位問題,人工再介入修復(fù)。
2.2異常上線變更攔截
異常上線變更攔截的核心思路是:為每次上線變更生成獨(dú)特的染色I(xiàn)D,通過對每個染色I(xiàn)D的性能核心數(shù)據(jù)進(jìn)行攔截與監(jiān)控。
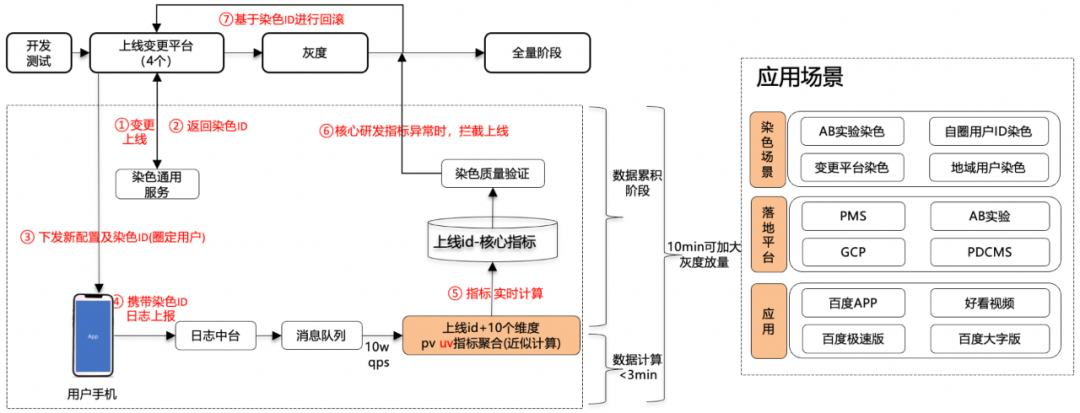
△異常上線變更攔截流程設(shè)計圖
變更攔截流程的具體步驟如下:
① 變更上線注冊:針對廠內(nèi)各個配置變更平臺,需要在每次上線配置生效之前,將上線信息在染色通用服務(wù)進(jìn)行注冊。
② 獲取染色I(xiàn)D:染色通用服務(wù)通過HTTP接口為每次上線注冊生成通用的染色I(xiàn)D,并將其返回給上線變更平臺。
③ 下發(fā)染色配置:在圈定的用戶群范圍內(nèi),上線變更平臺將新配置和染色信息同時下發(fā)到端上的業(yè)務(wù)SDK(如AB-SDK)中。
④ 染色日志上報:業(yè)務(wù)SDK會判定染色是否生效,如果生效,則在涉及性能核心場景的日志中附加染色I(xiàn)D信息,然后通過UBC-SDK上報。這些日志會通過日志中臺實時轉(zhuǎn)發(fā),并寫入消息隊列。
⑤ 實時指標(biāo)計算:性能中臺會實時訂閱消息隊列中的核心性能數(shù)據(jù),例如崩潰、APP啟動次數(shù)等,然后針對每個染色I(xiàn)D,根據(jù)多個維度(如產(chǎn)品線、APP版本、操作系統(tǒng)、地域等)形成性能聚合指標(biāo),并將其寫入持久存儲。
⑥ 異常攔截服務(wù):基于存儲中的染色數(shù)據(jù),異常攔截服務(wù)通過配置監(jiān)控項來檢測數(shù)據(jù)是否出現(xiàn)異常。一旦染色數(shù)據(jù)異常,系統(tǒng)會觸發(fā)攔截措施并發(fā)出告警。
⑦ 異常止損:在觸發(fā)攔截和告警后,系統(tǒng)會通過關(guān)聯(lián)染色I(xiàn)D和變更上線的關(guān)系,攔截繼續(xù)放量以及通知業(yè)務(wù)方針對本次上線的配置回滾。
針對每次線上配置的變更,都會有一段觀察期。這個觀察期的長短需要適度,以確保數(shù)據(jù)的可靠性。過短的觀察期會影響數(shù)據(jù)的置信度,而過長則可能降低研發(fā)效率。一般而言,每次變更后需要等待10分鐘的觀察期,然后再逐步增加線上流量。因此,變更攔截模塊對數(shù)據(jù)時效性的要求非常高,要求數(shù)據(jù)的端到端傳輸時效在3分鐘以內(nèi),以確保有足夠的數(shù)據(jù)累積時間,從而提升監(jiān)控指標(biāo)的可信度。同時,染色I(xiàn)D的數(shù)據(jù)指標(biāo)項不僅涵蓋了基礎(chǔ)的PV指標(biāo)(如崩潰次數(shù)和APP啟動用戶數(shù)),還擴(kuò)展至UV級別的指標(biāo)(如受崩潰影響的用戶數(shù)收斂情況和APP用戶啟動數(shù))。多個指標(biāo)維度下UV的計算也給數(shù)據(jù)鏈路的時效性和準(zhǔn)確性帶來了挑戰(zhàn)。具體的數(shù)據(jù)流設(shè)計如下所示:
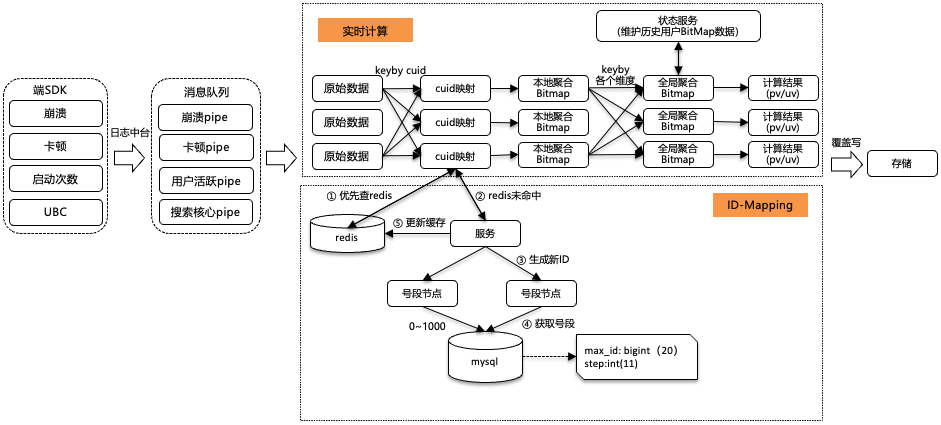
△變圖更攔截數(shù)據(jù)流設(shè)計
變更攔截的數(shù)據(jù)流主要分為兩個部分:
(1)實時指標(biāo)計算服務(wù);
(2) ID生成服務(wù)。
ID生成服務(wù)
ID生成服務(wù)主要用于將廠內(nèi)的CUID生成INT類型的數(shù)字,從而存儲到Bitmap的數(shù)據(jù)結(jié)構(gòu)中。整個服務(wù)需要滿足以下條件:
(1)CUID-ID的的映射全局唯一,不會出現(xiàn)重復(fù)的ID,且ID的整體趨勢遞增。
(2)高并發(fā)低延時。核心數(shù)據(jù)在計算節(jié)點(diǎn)內(nèi)存中進(jìn)行產(chǎn)出,減少數(shù)據(jù)庫壓力。
(3)高可用,服務(wù)基于云上分布式架構(gòu),即使存儲mysql宕機(jī),也能容忍一段時間數(shù)據(jù)庫不可用。
在實時流中,在接收到原始數(shù)據(jù)時,先根據(jù)CUID進(jìn)行keyby分發(fā),將相同的CUID分發(fā)到同一個計算節(jié)點(diǎn)。對于每個計算節(jié)點(diǎn):
(1)優(yōu)先查詢自身內(nèi)存中的緩存的映射關(guān)系,若不存在,則查詢redis。
(2)若redis不存在映射關(guān)系,則訪問生成新ID服務(wù)。
(3)服務(wù)請求hash到號段節(jié)點(diǎn)上,每次去DB拿固定長度的ID List進(jìn)行分發(fā),然后把最大的ID持久化下來,也就是并非每個ID都做持久化,僅僅持久化一批ID中最大的那一個。這個方式有點(diǎn)像游戲里的定期存檔功能,只不過存檔的是未來某個時間下發(fā)給用戶的ID,這樣極大地減輕了DB持久化的壓力。
(4)最終將映射關(guān)系寫入到Redis存儲中。
實時指標(biāo)計算服務(wù)
在數(shù)據(jù)處理流程中,端上傳的日志數(shù)據(jù)經(jīng)由日志中臺進(jìn)行轉(zhuǎn)發(fā),進(jìn)而分發(fā)到性能的各個消息隊列中。實時計算服務(wù)訂閱這些消息隊列中的數(shù)據(jù),以多級聚合方式進(jìn)行維度指標(biāo)的計算:
(1)數(shù)據(jù)分發(fā)與映射:首先,從消息隊列中獲取原始數(shù)據(jù)。根據(jù)CUID進(jìn)行keyby分發(fā),將相同的CUID分發(fā)到同一個計算節(jié)點(diǎn)。防止相同的CUID同時訪問ID-Mapping服務(wù),導(dǎo)致CUID-ID的的映射全局不唯一。
(2)本地聚合:對數(shù)據(jù)進(jìn)行解析獲得指標(biāo)和維度,然后在每個計算節(jié)點(diǎn)上進(jìn)行本地窗口聚合操作,將具有相同維度(版本、操作系統(tǒng)、染色I(xiàn)D等)的CUID匯總成Bitmap格式。本地聚合的目的在于減少后續(xù)的keyby shuffle階段的數(shù)據(jù)量。
(3)全局聚合:狀態(tài)服務(wù)維護(hù)實時流的運(yùn)行時狀態(tài)信息和歷史數(shù)據(jù)的Bitmap結(jié)果。將實時數(shù)據(jù)與歷史數(shù)據(jù)進(jìn)行全局聚合,從而得到最終的結(jié)果數(shù)據(jù)。同時,新的Bitmap結(jié)重新寫入狀態(tài)服務(wù)。其中,運(yùn)行時狀態(tài)信息保證了在實時流斷流或重啟時,能夠恢復(fù)上次運(yùn)行狀態(tài)。加上可重入的數(shù)據(jù)源和冪等的數(shù)據(jù)輸出,確保了數(shù)據(jù)流的不丟不重。
通過上述服務(wù),當(dāng)新的變更上線導(dǎo)致端上異常數(shù)據(jù)突增時,變更攔截服務(wù)能夠在分鐘級內(nèi)對異常上線進(jìn)行監(jiān)控告警以及攔截。此外,除了向業(yè)務(wù)方披露攔截的數(shù)據(jù)指標(biāo),我們也希望中臺能夠直接協(xié)助業(yè)務(wù)方定位排查出問題的根因。
2.3 問題自動分發(fā)
問題自動分發(fā)的核心思路是:建立端上各個模塊、組件、類方法和研發(fā)測試人員的映射關(guān)系,當(dāng)發(fā)生線上問題時,通過聚類規(guī)則將經(jīng)過反混淆之后問題直接指向?qū)е聠栴}發(fā)生的組件、模塊以及負(fù)責(zé)該模塊的研發(fā)測試人員。
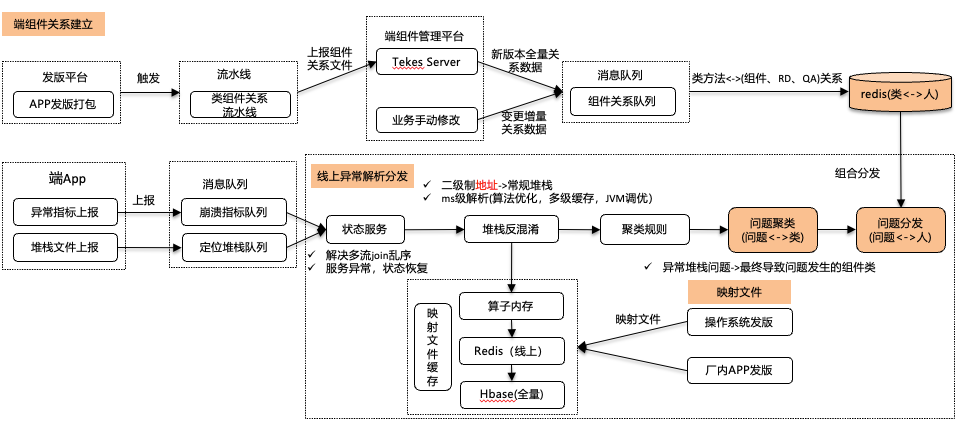
△線上問題實時自動分發(fā)數(shù)據(jù)流
問題分發(fā)的數(shù)據(jù)流主要分為四個部分:
(1)映射文件寫入存儲
(2)線上異常反混淆
(3)端組件關(guān)系建立
(4)問題分發(fā)
其中(1)(2)步驟是為了將線上異常解析為可讀的形式。(3)(4)步驟為將可讀的堆棧進(jìn)行聚類以及分發(fā)。
映射文件寫入存儲
在技術(shù)背景的實時反混淆介紹中,為了將經(jīng)過混淆的異常信息恢復(fù)成可讀的形式,關(guān)鍵在于使用映射文件。映射文件分為兩種:一種是針對每個APP發(fā)版時生成的映射文件,用于對該版本的APP自身的異常信息進(jìn)行反混淆;另一種是操作系統(tǒng)發(fā)版產(chǎn)生的映射文件,用于系統(tǒng)級別的異常信息的反混淆。當(dāng)APP發(fā)版或操作系統(tǒng)升級時,通過配置流水線將相應(yīng)的映射文件寫入映射文件緩存中。 APP的版本又有線上和線下的區(qū)別。針對線上發(fā)版的APP版本,其版本的特點(diǎn)表現(xiàn)為每個版本的發(fā)版周期較長,線上異常數(shù)量較多,同時對數(shù)據(jù)解析的實時性要求較高。為滿足這些特點(diǎn),將線上發(fā)版的映射文件存儲于高性能的Redis集群中。對于廠內(nèi)線下測試發(fā)版的APP版本,其版本特點(diǎn)體現(xiàn)在研發(fā)測試人員都能發(fā)版,導(dǎo)致版本數(shù)量相對較多。然而,與線上環(huán)境不同的是,線下測試環(huán)境中構(gòu)造的異常較少,而對數(shù)據(jù)解析的實時性要求較低。鑒于這些特點(diǎn),更適合將線下測試發(fā)版的映射文件存儲于性能稍弱但更適合存儲大量數(shù)據(jù)的Hbase集群中。
線上異常反混淆
在端發(fā)生線上異常時,端會上報兩條信息流。一條是崩潰的指標(biāo)數(shù)據(jù)流,一條是定位堆棧的文件流。指標(biāo)數(shù)據(jù)流的特點(diǎn)是上傳信息快,包含核心信息以及簡化版的異常信息,但異常信息量不全。而文件流的特點(diǎn)是,上傳速度偏慢,但是異常信息完整(2M)。結(jié)合這兩種信息流,可以獲得完整的線上異常信息,供業(yè)務(wù)分析使用。但是由于兩條信息流是異步上報,經(jīng)常面臨數(shù)據(jù)流亂序到達(dá)的問題。因此,為了解決亂序問題,我們設(shè)計了狀態(tài)服務(wù)。
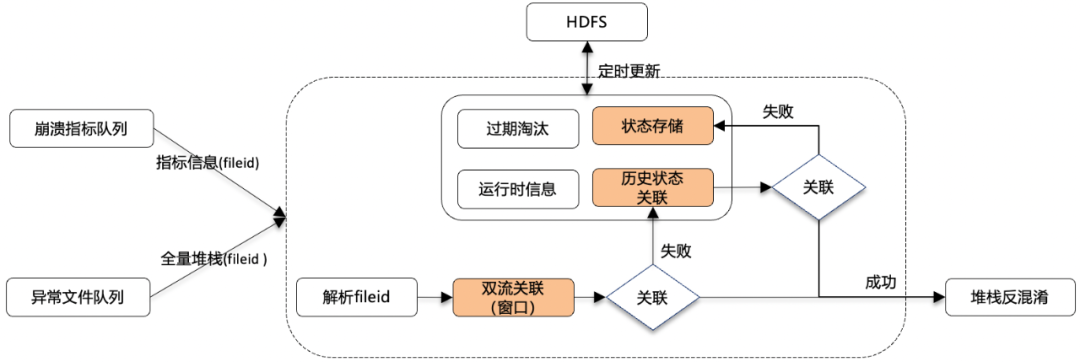
△狀態(tài)服務(wù)數(shù)據(jù)流設(shè)計
狀態(tài)服務(wù)的主要目的是處理雙流亂序的數(shù)據(jù),以確保它們能夠被正確關(guān)聯(lián)。其核心流程如下:
(1)同時間窗口數(shù)據(jù)關(guān)聯(lián):從消息隊列中訂閱數(shù)據(jù)后,首先會對處于計算節(jié)點(diǎn)同一個時間窗口的數(shù)據(jù)進(jìn)行關(guān)聯(lián),若關(guān)聯(lián)成功,則數(shù)據(jù)直接發(fā)往下游進(jìn)行計算。
(2)同歷史未關(guān)聯(lián)的數(shù)據(jù)關(guān)聯(lián):若未成功,則查詢狀態(tài)服務(wù)中之前窗口中尚未被關(guān)聯(lián)的數(shù)據(jù)進(jìn)行關(guān)聯(lián),若關(guān)聯(lián)成功,發(fā)往下游,狀態(tài)存儲中清除關(guān)聯(lián)數(shù)據(jù)。
(3)未關(guān)聯(lián)數(shù)據(jù)寫入狀態(tài)存儲:若未成功,則將未關(guān)聯(lián)的數(shù)據(jù)寫入到狀態(tài)存儲中,等待被將來的數(shù)據(jù)進(jìn)行關(guān)聯(lián)。
此外,狀態(tài)存儲也不能無限的增長,需要有過期淘汰的策略,在該場景下,我們設(shè)置的是30min的TTL,能夠關(guān)聯(lián)到99.9%以上的數(shù)據(jù)。 在成功關(guān)聯(lián)雙流數(shù)據(jù)后,緊接著是對堆棧進(jìn)行反混淆解析。反混淆的目標(biāo)是將經(jīng)過混淆后的異常信息還原為可讀的形式。在反混淆過程中,各種類型異常的解析算法工具(如騰訊Bugly、谷歌CrashPad)通常能夠在秒級別(約10秒)內(nèi)完成解析操作。然而,在實時數(shù)據(jù)流處理中,僅僅滿足秒級的解析時效性是不夠的,需要將解析速度提升至毫秒級。因此,中臺實時流中對反混淆解析進(jìn)行了升級,包含算法升級適配實時流以及多級緩存在構(gòu)建。 多級緩存由計算節(jié)點(diǎn)內(nèi)存,Redis以及Hbase構(gòu)成。其中,根據(jù)不同的緩存命中情況,反混淆解析的性能會有所不同。如果堆棧對應(yīng)的映射文件在計算節(jié)點(diǎn)內(nèi)存中命中,解析可以在<10ms內(nèi)完成。若在Redis或Hbase中命中,則解析時間會略有延長,達(dá)到秒級別(約10秒),那么最理想的方式是將所有的映射文件都在計算節(jié)點(diǎn)內(nèi)存中被命中。然而,由于每個版本都有對應(yīng)的映射文件,且每個線上APP都有數(shù)十個版本,每個映射文件大小約為300MB,這使得無法將線上流量所需的所有映射文件都加載到算子內(nèi)存中。為了解決這一問題,我們對解析算法進(jìn)行了多級索引的優(yōu)化。這種優(yōu)化策略將整個映射文件進(jìn)行了細(xì)粒度拆分,僅將異常堆棧命中的映射文件行信息加載到內(nèi)存中。因此,解析算法現(xiàn)在不再需要將整個映射文件完全存入內(nèi)存。相反,它只需存儲一級索引和二級索引的關(guān)系,以及命中堆棧后獲得的結(jié)果數(shù)據(jù)。這一方式在顯著提高內(nèi)存利用效率的同時,也解決了計算節(jié)點(diǎn)內(nèi)存不足的問題。

△多級索引查詢
但是,隨著線上任務(wù)長時間運(yùn)行時,我們注意到程序性能逐漸下降,導(dǎo)致實時流任務(wù)的數(shù)據(jù)處理經(jīng)常出現(xiàn)延遲。我們發(fā)現(xiàn)問題的根本原因是計算節(jié)點(diǎn)緩存中的映射文件被頻繁替換,導(dǎo)致緩存命中率低。因此,我們采用了更為適合業(yè)務(wù)場景的緩存替代算法---W-TinyLFU代替常規(guī)的LRU緩存替代策略。
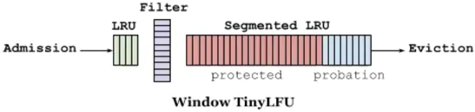
△W-TinyLFU算法
相比LRU算法,W-TinyLFU:
1、熱點(diǎn)數(shù)據(jù)適應(yīng)性更強(qiáng):在高流量的場景中,一些熱點(diǎn)數(shù)據(jù)項可能會在短時間內(nèi)被多次訪問。與LRU只關(guān)注最近的訪問,W-TinyLFU通過維護(hù)頻繁訪問計數(shù)來更好地捕獲這種熱點(diǎn)數(shù)據(jù)的特征,從而更好地適應(yīng)瞬時的流量變化。
2、低頻數(shù)據(jù)保護(hù):LRU在遇到新數(shù)據(jù)時,會立即淘汰最近最少使用的數(shù)據(jù),這可能導(dǎo)致低頻數(shù)據(jù)被頻繁淘汰。W-TinyLFU通過維護(hù)一個近似的頻率計數(shù),可以更好地保護(hù)低頻數(shù)據(jù),防止它們被過早地淘汰。
3、適應(yīng)性更強(qiáng):W-TinyLFU在面對訪問模式的變化時,能夠更快地適應(yīng)新的訪問模式。它在長時間內(nèi)持續(xù)觀察訪問模式,并逐漸調(diào)整數(shù)據(jù)項的權(quán)重,以更好地反映最近的訪問模式。
4、寫入操作考慮:LRU通常對寫入操作的適應(yīng)性較差,因為寫入操作可能導(dǎo)致數(shù)據(jù)被立即淘汰。W-TinyLFU考慮了寫入操作,通過維護(hù)寫入時的頻繁訪問計數(shù),可以更好地處理寫入操作。
5、內(nèi)存效率:W-TinyLFU使用了一些壓縮技術(shù)來存儲頻繁訪問計數(shù),從而在一定程度上減少了內(nèi)存占用。
經(jīng)過對線上異常進(jìn)行反混淆處理后,我們獲得了可讀的堆棧信息。接下來,我們可以對這些可讀的堆棧信息進(jìn)行問題聚類和分發(fā)。
端組件關(guān)系建立
組件關(guān)系變更的數(shù)據(jù)來源分為兩個部分:
(1)全量數(shù)據(jù):在APP進(jìn)行發(fā)版時,通過EasyBox等工具將組件、模塊等關(guān)系從包中解析出來,將該版本的組件信息上傳到組件管理平臺,觸發(fā)組件管理平臺的全量同步,將組件信息寫入消息隊列中。中臺通過訂閱組件數(shù)據(jù),建立類方法<->組件、模塊、研發(fā)人員、測試人員的關(guān)系,寫入到存儲中。
(2)增量數(shù)據(jù):在組件管理平臺進(jìn)行人為的修改,例如修改組件類的研發(fā)、測試負(fù)責(zé)人等,觸發(fā)增量同步,變更的數(shù)據(jù)寫入消息隊列。
通過上述數(shù)據(jù)同步,建立了類方法<->人的映射。
問題分發(fā)
通過數(shù)據(jù)流的反混淆解析,我們成功地將異常信息從二進(jìn)制地址轉(zhuǎn)換為可讀的信息。接下來,借助聚類規(guī)則算法,我們將不同的異常堆棧逐行遍歷,并優(yōu)先將其聚類到廠內(nèi)維護(hù)的組件和模塊中所包含的類中。在此過程中,我們建立了線上問題<->類之間的關(guān)系。而在端組件關(guān)系建立的流程中,我們成功地構(gòu)建了類方法<->研發(fā)測試人員之間的映射關(guān)系。將這兩者的關(guān)系結(jié)合起來,我們獲得了問題<->人員之間的關(guān)聯(lián)。因此,當(dāng)線上出現(xiàn)問題時,無需人工干預(yù),系統(tǒng)可以直接將該問題指向負(fù)責(zé)該問題模塊的負(fù)責(zé)人。負(fù)責(zé)人隨后可以根據(jù)反混淆后的異常信息,進(jìn)行問題的排查和修復(fù)工作。
GEEK TALK
03
總結(jié)與展望
本文主要介紹了性能中臺在處理異常上線過程中,針對變更攔截和問題分發(fā)方面做的一些努力。當(dāng)然,后面我們還會繼續(xù)更好的服務(wù)業(yè)務(wù),如:
1、提升影響力:對接更多的上線變更平臺以及落地更多的APP。
2、提升場景覆蓋度:覆蓋卡頓、啟動速度、網(wǎng)絡(luò)性能、搜索性能等更多的核心業(yè)務(wù)場景。
3、提升問題聚類以及分發(fā)策略的準(zhǔn)確度:將線上問題分發(fā)的更加合理與準(zhǔn)確。
希望,性能中臺持續(xù)不斷優(yōu)化,為保障APP的質(zhì)量做出貢獻(xiàn)。
-
移動應(yīng)用
+關(guān)注
關(guān)注
0文章
65瀏覽量
15743 -
應(yīng)用程序
+關(guān)注
關(guān)注
38文章
3329瀏覽量
58882 -
數(shù)據(jù)結(jié)構(gòu)
+關(guān)注
關(guān)注
3文章
573瀏覽量
40676
原文標(biāo)題:基于異常上線場景的實時攔截與問題分發(fā)策略
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
鴻道Intewell實時操作系統(tǒng)有哪些應(yīng)用場景
機(jī)器學(xué)習(xí)異常檢測實戰(zhàn):用Isolation Forest快速構(gòu)建無標(biāo)簽異常檢測系統(tǒng)

EGBox Mini:一體式緊湊型實時仿真平臺,適配多元實驗場景
RFID在藥品分發(fā)中的應(yīng)用

商湯科技日日新大模型SenseNova上線聲網(wǎng)云市場
工業(yè)場景下 TNC 插座的專業(yè)拆卸策略

嵌入式系統(tǒng)存儲的軟件優(yōu)化策略
數(shù)據(jù)記錄儀的計數(shù)原理和應(yīng)用場景
HarmonyOS官網(wǎng)上線“穩(wěn)定性”專欄 助力更穩(wěn)定流暢的鴻蒙原生應(yīng)用開發(fā)
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區(qū) 助力打造高性能原生應(yīng)用
串口通訊異常處理方法 串口設(shè)備連接方式
IP地址數(shù)據(jù)信息和爬蟲攔截的關(guān)聯(lián)
詳解MES系統(tǒng)的生產(chǎn)過程實時監(jiān)控與異常處理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論