") 機(jī)器學(xué)習(xí)異常檢測實(shí)戰(zhàn):用Isolation Forest快速構(gòu)建無標(biāo)簽異常檢測系統(tǒng)
機(jī)器學(xué)習(xí)異常檢測實(shí)戰(zhàn):用Isolation Forest快速構(gòu)建無標(biāo)簽異常檢測系統(tǒng)
本文轉(zhuǎn)自:DeepHub IMBA
無監(jiān)督異常檢測作為機(jī)器學(xué)習(xí)領(lǐng)域的重要分支,專門用于在缺乏標(biāo)記數(shù)據(jù)的環(huán)境中識(shí)別異常事件。本文深入探討異常檢測技術(shù)的理論基礎(chǔ)與實(shí)踐應(yīng)用,通過Isolation Forest算法進(jìn)行異常檢測,并結(jié)合LightGBM作為主分類器,構(gòu)建完整的欺詐檢測系統(tǒng)。文章詳細(xì)闡述了從無監(jiān)督異常檢測到人工反饋循環(huán)的完整工作流程,為實(shí)際業(yè)務(wù)場景中的風(fēng)險(xiǎn)控制提供參考。
異常檢測是一種識(shí)別與正常數(shù)據(jù)模式顯著偏離的數(shù)據(jù)點(diǎn)的技術(shù)方法。這些異常點(diǎn),也稱為離群值,通常表示系統(tǒng)中的異常狀態(tài)、潛在威脅或需要特別關(guān)注的事件。
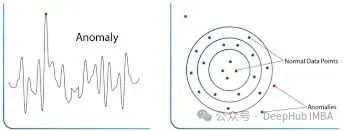
異常檢測技術(shù)在多個(gè)關(guān)鍵領(lǐng)域發(fā)揮著重要作用。在金融領(lǐng)域,通過識(shí)別異常交易模式和支出行為來實(shí)現(xiàn)欺詐檢測;在制造業(yè)中,通過監(jiān)控質(zhì)量指標(biāo)的異常波動(dòng)來保障產(chǎn)品質(zhì)量;在醫(yī)療健康領(lǐng)域,通過檢測生理指標(biāo)的異常變化來進(jìn)行健康監(jiān)測。這些應(yīng)用的核心目標(biāo)是將異常事件標(biāo)記出來,供相關(guān)專業(yè)人員進(jìn)行進(jìn)一步審查和處理,從而有效降低潛在風(fēng)險(xiǎn)。
根據(jù)數(shù)據(jù)標(biāo)記情況和應(yīng)用場景的不同,異常檢測方法可以分為監(jiān)督學(xué)習(xí)、半監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)三大類別。
監(jiān)督異常檢測方法基于已標(biāo)記的正常和異常樣本進(jìn)行模型訓(xùn)練。這種方法在擁有可靠標(biāo)記數(shù)據(jù)且異常模式相對(duì)明確的場景中表現(xiàn)優(yōu)異。常用的算法包括貝葉斯網(wǎng)絡(luò)、k近鄰算法和決策樹等傳統(tǒng)機(jī)器學(xué)習(xí)方法。
半監(jiān)督異常檢測,也稱為潔凈異常檢測,主要用于識(shí)別高質(zhì)量數(shù)據(jù)中正常模式的顯著偏差。這種方法適用于數(shù)據(jù)結(jié)構(gòu)良好且模式相對(duì)可預(yù)測的應(yīng)用場景,如欺詐檢測和制造質(zhì)量控制等領(lǐng)域。
無監(jiān)督異常檢測方法通過尋找顯著偏離大部分?jǐn)?shù)據(jù)分布的數(shù)據(jù)點(diǎn)來識(shí)別異常。當(dāng)異常事件相對(duì)罕見或缺乏充分了解,且訓(xùn)練數(shù)據(jù)中不包含標(biāo)記異常樣本時(shí),這種方法特別有效。典型算法包括K-means聚類和一類支持向量機(jī)等。
無監(jiān)督異常檢測的主要技術(shù)方法
無監(jiān)督異常檢測方法根據(jù)其技術(shù)原理可以分為統(tǒng)計(jì)方法、聚類方法、基于鄰近度的方法、時(shí)間序列分析方法和機(jī)器學(xué)習(xí)算法等幾個(gè)主要類別。
統(tǒng)計(jì)方法
統(tǒng)計(jì)方法通過分析數(shù)據(jù)的統(tǒng)計(jì)特性來識(shí)別異常觀測值。Z分?jǐn)?shù)方法通過計(jì)算數(shù)據(jù)點(diǎn)距離均值的標(biāo)準(zhǔn)差倍數(shù)來量化異常程度,將遠(yuǎn)離均值的數(shù)據(jù)點(diǎn)標(biāo)記為異常。百分位數(shù)方法則通過設(shè)置基于分位數(shù)的閾值來識(shí)別落在正常范圍之外的數(shù)據(jù)點(diǎn)。這類方法最適用于具有明確統(tǒng)計(jì)分布特征的數(shù)據(jù),其中異常表現(xiàn)為對(duì)統(tǒng)計(jì)正態(tài)性的明顯偏離。
聚類方法
聚類方法通過將相似數(shù)據(jù)點(diǎn)分組來識(shí)別異常,其中異常通常表現(xiàn)為不屬于任何明確定義簇的孤立點(diǎn)。DBSCAN算法基于密度進(jìn)行聚類,將位于低密度區(qū)域且不屬于任何簇的點(diǎn)視為異常。K-Means聚類則通過計(jì)算數(shù)據(jù)點(diǎn)到簇中心的距離來識(shí)別遠(yuǎn)離所有簇中心的異常點(diǎn)。這類方法在正常數(shù)據(jù)形成明顯聚類結(jié)構(gòu)的場景中效果最佳。
基于鄰近度的方法
基于鄰近度的方法通過測量數(shù)據(jù)點(diǎn)之間的距離或相似性來識(shí)別那些異常遠(yuǎn)離其鄰居或偏離數(shù)據(jù)中心趨勢(shì)的點(diǎn)。馬哈拉諾比斯距離考慮特征間的相關(guān)性來計(jì)算數(shù)據(jù)點(diǎn)到分布中心的距離。局部離群因子(LOF)通過計(jì)算數(shù)據(jù)點(diǎn)相對(duì)于其鄰居的局部密度偏差來識(shí)別在密度變化區(qū)域中的離群值。這類方法特別適用于異常由其孤立性或與其他數(shù)據(jù)點(diǎn)的距離來定義的場景,以及處理復(fù)雜多維數(shù)據(jù)集時(shí)密度變化具有重要意義的情況。
時(shí)間序列分析方法
時(shí)間序列分析方法專門針對(duì)序列數(shù)據(jù)設(shè)計(jì),基于時(shí)間模式來識(shí)別異常。移動(dòng)平均方法通過檢測數(shù)據(jù)點(diǎn)對(duì)特定時(shí)期內(nèi)計(jì)算的移動(dòng)平均的顯著偏離來識(shí)別異常。季節(jié)性分解方法將時(shí)間序列分解為趨勢(shì)、季節(jié)性和殘差成分,異常通常在無法通過趨勢(shì)或季節(jié)性解釋的殘差成分中被發(fā)現(xiàn)。這類方法最適用于觀察順序重要的序列數(shù)據(jù),以及異常表現(xiàn)為對(duì)預(yù)期趨勢(shì)、季節(jié)性或時(shí)間模式偏離的場景。
機(jī)器學(xué)習(xí)算法
機(jī)器學(xué)習(xí)算法通過從數(shù)據(jù)中學(xué)習(xí)復(fù)雜模式來進(jìn)行異常檢測。Isolation Forest作為一種集成方法,通過構(gòu)建樹狀結(jié)構(gòu)來有效隔離異常。一類支持向量機(jī)通過在正常數(shù)據(jù)周圍定義邊界來將數(shù)據(jù)點(diǎn)分類為正常或異常。K近鄰算法基于到K個(gè)最近鄰居的距離來分配異常分?jǐn)?shù)。自編碼器作為神經(jīng)網(wǎng)絡(luò)模型,通過學(xué)習(xí)數(shù)據(jù)的壓縮表示來檢測具有高重構(gòu)誤差的異常。這類方法在復(fù)雜非線性模式定義正常行為且異常相對(duì)微妙的場景中表現(xiàn)最佳。
異常檢測與無監(jiān)督聚類的區(qū)別
雖然異常檢測和無監(jiān)督聚類都用于分析未標(biāo)記數(shù)據(jù)中的模式,但兩者在目標(biāo)和應(yīng)用方式上存在根本差異。
以欺詐檢測為例,聚類方法有助于識(shí)別潛在欺詐交易的群組或不同的行為細(xì)分,其中某些群組可能比其他群組具有更高的風(fēng)險(xiǎn)水平。小規(guī)模的聚類簇并不一定表示欺詐行為,它們可能只是代表不同的用戶行為群組。
相比之下,異常檢測直接針對(duì)標(biāo)記異常到足以需要調(diào)查的單個(gè)交易作為潛在欺詐,無論這些交易是否形成群組。這兩種方法在基本目標(biāo)上存在差異,因此產(chǎn)生不同類型的輸出結(jié)果。
在目標(biāo)定位上,聚類旨在發(fā)現(xiàn)未標(biāo)記數(shù)據(jù)中的自然分組或細(xì)分,而異常檢測專注于識(shí)別顯著偏離正常模式的單個(gè)數(shù)據(jù)點(diǎn)。在輸出結(jié)果上,聚類為每個(gè)數(shù)據(jù)點(diǎn)分配聚類標(biāo)識(shí)符,而異常檢測提供異常分?jǐn)?shù)或二進(jìn)制標(biāo)志。
無監(jiān)督聚類的典型應(yīng)用場景包括:識(shí)別協(xié)同作案的欺詐團(tuán)伙,他們的個(gè)別交易可能不顯示強(qiáng)異常特征,但集體模式可疑;發(fā)現(xiàn)多個(gè)客戶共享同一聯(lián)系信息的貸款申請(qǐng)模式;幫助安全管理員識(shí)別本質(zhì)上風(fēng)險(xiǎn)較高的商戶類型。
無監(jiān)督異常檢測的典型應(yīng)用場景包括:檢測新型信用卡詐騙模式;識(shí)別員工對(duì)內(nèi)部系統(tǒng)的未授權(quán)訪問;發(fā)現(xiàn)合法客戶賬戶被入侵后的異常交易;檢測用戶在短時(shí)間內(nèi)從不同地理位置的登錄行為;識(shí)別使用一次性郵箱從相同IP范圍創(chuàng)建多個(gè)新賬戶的行為。
這些應(yīng)用場景通常涉及尋找非常微妙的個(gè)別不規(guī)律性,在缺乏標(biāo)記數(shù)據(jù)或先前示例的情況下,主要模型可能忽略這些不規(guī)律模式。
Isolation Forest算法原理
Isolation Forest是一種基于二叉樹結(jié)構(gòu)的異常檢測算法,通過利用異常的固有特征來隔離異常點(diǎn),而不是對(duì)正常數(shù)據(jù)進(jìn)行建模。這種直觀且高效的方法使其成為異常檢測任務(wù)的熱門選擇。
算法的核心特征包括:采用集成方法構(gòu)建多個(gè)隔離樹;通過異常點(diǎn)被隔離的難易程度來識(shí)別異常(需要更少的分割步驟來被分離的點(diǎn)更可能是異常);對(duì)高維數(shù)據(jù)具有相對(duì)快速和可擴(kuò)展的處理能力;作為無監(jiān)督方法不需要標(biāo)記數(shù)據(jù)進(jìn)行訓(xùn)練;直接針對(duì)離群值檢測而不分析正常點(diǎn)的分布;在處理具有眾多特征的高維數(shù)據(jù)集時(shí)表現(xiàn)優(yōu)異。
算法工作機(jī)制
Isolation Forest的工作原理可以通過以下流程來理解:首先,數(shù)據(jù)點(diǎn)需要遍歷森林中的每棵樹(樹1、樹2、...、樹T)。
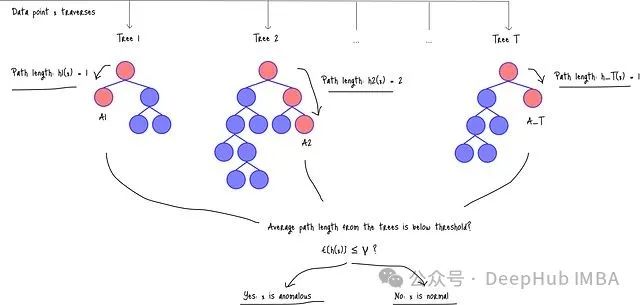 圖:Isolation Forest架構(gòu)以及數(shù)據(jù)點(diǎn)處理流程
圖:Isolation Forest架構(gòu)以及數(shù)據(jù)點(diǎn)處理流程
在算法執(zhí)行過程中,h_i(x)表示數(shù)據(jù)點(diǎn)在第i棵樹中的路徑長度,即數(shù)據(jù)點(diǎn)從根節(jié)點(diǎn)到葉節(jié)點(diǎn)所經(jīng)過的邊數(shù)。路徑長度越短,表明數(shù)據(jù)點(diǎn)越可能是異常。
接下來,算法計(jì)算數(shù)據(jù)點(diǎn)在所有T個(gè)隔離樹中的平均路徑長度E[h(x)]:
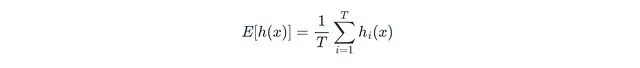
其中T表示森林中隔離樹的總數(shù),h_i(x)表示數(shù)據(jù)點(diǎn)x在第i棵隔離樹中的路徑長度。
異常分?jǐn)?shù)計(jì)算
Isolation Forest模型將平均路徑長度轉(zhuǎn)換為標(biāo)準(zhǔn)化的異常分?jǐn)?shù)s(x):
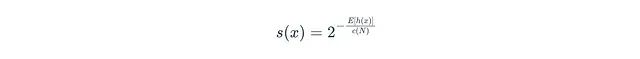
公式中各參數(shù)的含義為:E[h(x)]表示x的平均路徑長度;N表示用于構(gòu)建單棵樹的訓(xùn)練子集中的數(shù)據(jù)點(diǎn)數(shù)量(子采樣大小);c(N)表示標(biāo)準(zhǔn)化因子,代表在N個(gè)點(diǎn)的二叉搜索樹中不成功搜索的平均路徑長度:
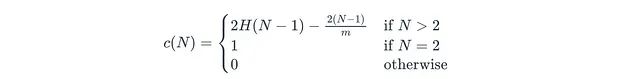
其中m表示樣本大小。
異常分?jǐn)?shù)的取值范圍為0到1,分?jǐn)?shù)越高表示成為異常的可能性越大。最終,模型將計(jì)算得到的分?jǐn)?shù)與預(yù)設(shè)閾值(γ)進(jìn)行比較,如果分?jǐn)?shù)低于閾值,則將該數(shù)據(jù)點(diǎn)標(biāo)記為異常。
無標(biāo)記數(shù)據(jù)環(huán)境下的評(píng)估方法
在實(shí)際應(yīng)用中,由于缺乏標(biāo)記數(shù)據(jù)或歷史記錄,無法直接確認(rèn)檢測到的異常是否確實(shí)需要被標(biāo)記。因此需要通過多種方式來評(píng)估來自Isolation Forest的異常標(biāo)記結(jié)果。
人工參與循環(huán)評(píng)估
人工審查是評(píng)估異常標(biāo)記的關(guān)鍵步驟,包括向欺詐調(diào)查專家展示標(biāo)記的異常事件。調(diào)查專家對(duì)真實(shí)欺詐和誤報(bào)數(shù)量的反饋為異常檢測系統(tǒng)提供了寶貴的改進(jìn)信息。關(guān)鍵評(píng)估問題包括:模型輸出是否導(dǎo)致實(shí)際調(diào)查發(fā)現(xiàn)真實(shí)欺詐,還是主要產(chǎn)生噪音;模型是否能夠持續(xù)一致地將相似類型的事件標(biāo)記為異常。
半監(jiān)督評(píng)估方法
當(dāng)擁有少量保留的標(biāo)記數(shù)據(jù)集時(shí)(即使由于數(shù)量太少而不用于訓(xùn)練),可以使用這些數(shù)據(jù)計(jì)算相關(guān)指標(biāo)。Precision@k指標(biāo)評(píng)估模型標(biāo)記的前k個(gè)異常中真正欺詐的百分比。Recall@k指標(biāo)類似于Precision@k,但專注于前k個(gè)標(biāo)記中包含的實(shí)際欺詐案例數(shù)量。ROC AUC和PR AUC指標(biāo)將異常分?jǐn)?shù)視為連續(xù)變量并繪制相應(yīng)的性能曲線。
合成異常注入測試
通過向干凈數(shù)據(jù)集中注入已知數(shù)量的合成異常,觀察模型成功識(shí)別的比例。這種方法有助于對(duì)不同無監(jiān)督算法進(jìn)行基準(zhǔn)測試比較。
這些評(píng)估方法的價(jià)值在于:生成新的標(biāo)記數(shù)據(jù)用于重新訓(xùn)練主要模型;創(chuàng)建新特征或規(guī)則來應(yīng)對(duì)新興威脅;調(diào)整Isolation Forest超參數(shù)(如contamination參數(shù))以優(yōu)化檢測準(zhǔn)確性。
實(shí)驗(yàn)設(shè)計(jì)與實(shí)現(xiàn)
本節(jié)通過信用卡交易數(shù)據(jù)集演示異常檢測的完整周期,包括Isolation Forest調(diào)優(yōu)、人工反饋循環(huán)評(píng)估,以及使用新標(biāo)記數(shù)據(jù)訓(xùn)練LightGBM模型。
數(shù)據(jù)預(yù)處理
Isolation Forest與其他基于決策樹的模型類似,需要進(jìn)行適當(dāng)?shù)臄?shù)據(jù)預(yù)處理。從Financial Transactions Dataset: Analytics數(shù)據(jù)集加載數(shù)據(jù)后,對(duì)數(shù)值特征執(zhí)行列轉(zhuǎn)換以進(jìn)行標(biāo)準(zhǔn)化和歸一化處理。
原始數(shù)據(jù)集結(jié)構(gòu):

經(jīng)過列轉(zhuǎn)換后的數(shù)據(jù):
[[-1.39080197 -0.03606896 0.04983562 -1.30648276 0.37940361 -1.67063883]
[-0.192827 -0.52484299 -0.42640285 -0.52439344 1.85293745 -0.46941254]
[ 0.66316843 -0.62795398 -0.5266197 -0.03136157 -0.46709455 -0.40267775]
...
[ 0.66316843 -0.96249769 -0.85253289 -1.06913227 1.39833658 -1.53716925]
[-1.56087595 -0.67663075 -0.57406012 0.17866552 -1.97198017 0.26467019]
[-0.3129254 -0.53653239 -0.43765848 -0.20775319 -1.59575877 0.06446581]]
數(shù)據(jù)形狀:(1000, 6)
Isolation Forest參數(shù)調(diào)優(yōu)
在沒有任何欺詐線索的初始階段,采用相對(duì)寬松的超參數(shù)設(shè)置,使模型具有較高的靈活性:
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
isolation_forest = IsolationForest(
n_estimators=500, # 森林中樹的最大數(shù)量
contamination="auto", # 初始設(shè)置為auto(后續(xù)調(diào)整)
max_samples='auto',
max_features=1, # 每次分割僅考慮一個(gè)特征
bootstrap=True, # 使用bootstrap樣本確保魯棒性
random_state=42,
n_jobs=-1
)
y_pred_iso = isolation_forest.fit_predict(X_processed)
inliers_iso = X[y_pred_iso == 1]
outliers_iso = X[y_pred_iso == -1]
print(f"Isolation Forest detected {len(outliers_iso)} outliers.")
One-Class SVM對(duì)比實(shí)驗(yàn)
為了進(jìn)行性能比較,同時(shí)調(diào)優(yōu)一類支持向量機(jī),設(shè)置相對(duì)寬松的nu值:
one_class_svm = OneClassSVM(
kernel='rbf',
gamma='scale',
tol=1e-7,
nu=0.1, # 寬松的nu值設(shè)置
shrinking=True,
max_iter=5000,
)
y_pred_ocsvm = one_class_svm.fit_predict(X_processed)
inliers_ocsvm = X[y_pred_ocsvm == 1]
outliers_ocsvm = X[y_pred_ocsvm == -1]
print(f"One-Class SVM detected {len(outliers_ocsvm)} outliers.")
實(shí)驗(yàn)結(jié)果分析
實(shí)驗(yàn)結(jié)果顯示:
Isolation Forest檢測到166個(gè)異常點(diǎn)
One-Class SVM檢測到101個(gè)異常點(diǎn)
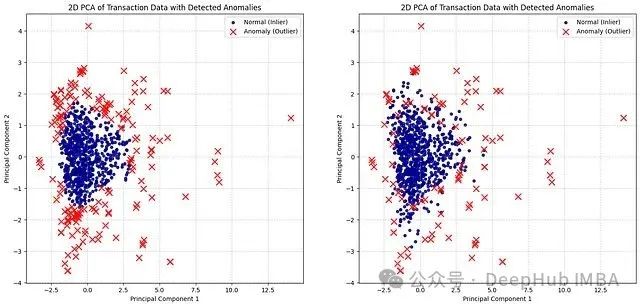
圖:Isolation Forest(左)和One-Class SVM(右)的無監(jiān)督異常檢測結(jié)果對(duì)比
Isolation Forest在尋找容易被"隔離"的點(diǎn)方面表現(xiàn)更為積極,擅長發(fā)現(xiàn)新穎的、真正異常的點(diǎn),即使這些點(diǎn)與主要數(shù)據(jù)簇的距離并不是非常遠(yuǎn)。如果對(duì)"異常"的定義相對(duì)寬泛,這種特性可能導(dǎo)致檢測到更多的異常點(diǎn)。
One-Class SVM在正常數(shù)據(jù)周圍定義了更加結(jié)構(gòu)化的邊界,將邊界之外的點(diǎn)標(biāo)記為異常。這種方法相對(duì)保守,需要從"正常"流形更顯著的偏差才會(huì)被標(biāo)記為異常。
人工反饋循環(huán)評(píng)估
為了實(shí)際演示評(píng)估過程,將標(biāo)記的記錄按照以下四個(gè)類別進(jìn)行逐一審查:
類別1(真正例,TP):模型標(biāo)記的交易確實(shí)是欺詐性的。類別2(假正例,F(xiàn)P):模型標(biāo)記的交易實(shí)際上是合法的,表示"虛假警報(bào)"。過多的假正例可能使分析師工作負(fù)擔(dān)過重并導(dǎo)致效率低下。類別3(新欺詐模式):識(shí)別出被捕獲的新類型欺詐,或以前錯(cuò)過的欺詐類型,為不斷演變的威脅態(tài)勢(shì)提供新的洞察。類別4(合法但異常行為):交易看似合法但對(duì)該客戶或客戶群體確實(shí)異常,了解模型標(biāo)記原因具有重要價(jià)值。
需要注意的是,假陰性(FN)記錄通常來自其他來源,如客戶投訴或退單,因?yàn)檫@些交易未被模型標(biāo)記但后來發(fā)現(xiàn)是欺詐性的。在這個(gè)實(shí)驗(yàn)中,由于重點(diǎn)關(guān)注模型標(biāo)記的準(zhǔn)確性,暫時(shí)排除了假陰性分析。在實(shí)際應(yīng)用中,欺詐專家對(duì)記錄進(jìn)行準(zhǔn)確分類至關(guān)重要。
以下是一些標(biāo)記記錄的示例和相應(yīng)的人工審查結(jié)果:
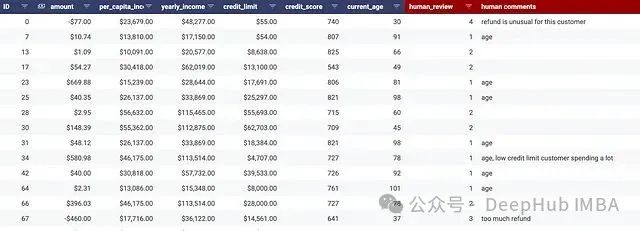
圖:標(biāo)記的交易記錄列表(合成數(shù)據(jù))和人工審查示例
以記錄#0為例,77美元的退款雖然不一定可疑或欺詐,但確實(shí)代表了該特定客戶的異常行為模式。記錄#67(底部)同樣顯示了大量退款行為。如果將此識(shí)別為新的欺詐方案,可以將其標(biāo)記為類別3。
對(duì)于記錄#23、#25等,客戶年齡超過90歲。來自該年齡群體個(gè)人的如此高交易量通常是異常的,需要特別關(guān)注。
在166個(gè)潛在異常中,按類別分布情況為:類別1占94個(gè),類別2占30個(gè),類別3占10個(gè),類別4占23個(gè)。
污染度參數(shù)調(diào)整
基于審查結(jié)果的分析顯示:總標(biāo)記數(shù)為166個(gè);真正例(TP)為94個(gè);假正例(FP)為72個(gè)(166-94);標(biāo)記集的精確度為TP/(TP+FP) = 94/166 ≈ 56.63%。
這表明雖然模型預(yù)測了16.6%的污染率,但該數(shù)據(jù)集的實(shí)際可觀察污染率為9.4%(1000個(gè)總樣本中的94個(gè)異常)。同時(shí)必須考慮模型在此實(shí)驗(yàn)中未標(biāo)記的假陰性(遺漏的異常),因此真實(shí)污染率可能大于等于9.4%。
基于這一發(fā)現(xiàn),在下一次迭代中將contamination參數(shù)設(shè)置為0.1(10%):
refined_isolation_forest = IsolationForest(
n_estimators=500,
contamination=0.1, # 更新為0.1
max_samples='auto',
max_features=1,
bootstrap=True,
random_state=42,
n_jobs=-1
)
訓(xùn)練樣本標(biāo)簽更新
另一個(gè)重要步驟是基于更新的數(shù)據(jù)集重新訓(xùn)練主要模型。向原始DataFrame添加三個(gè)新列,將human_review類別1標(biāo)記為is_fraud = true(1):
human_review:存儲(chǔ)審查類別(0,1,2,3,4),非異常情況為零
is_fraud_iforest:存儲(chǔ)來自Isolation Forest的初始異常檢測結(jié)果(二進(jìn)制:1,-1)
is_fraud:存儲(chǔ)最終欺詐判定結(jié)果(二進(jìn)制:0,1),其中1表示欺詐
is_fraud列作為目標(biāo)變量用于訓(xùn)練主要模型:
import pandas as pd
df_human_review = pd.read_csv(csv_file_path, index_col=1)
df_merged = df_new.merge(
df_human_review[['human_review']],
left_index=True,

right_index=True,
how='left'
)
df_merged['human_review'] = df_merged['human_review'].fillna(0).astype(int)
df_merged['is_fraud'] = (df_merged['human_review'] == 1).astype(int)
圖:更新后的數(shù)據(jù)框,右側(cè)三列為新添加的列
主要模型重新訓(xùn)練
由于數(shù)據(jù)集存在類別不平衡問題,首先使用SMOTE技術(shù)對(duì)少數(shù)類進(jìn)行過采樣:
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
from collections import Counter
X = df_merged.copy().drop(columns='is_fraud', axis='columns')
y = df_merged.copy()['is_fraud']
X_tv, X_test, y_tv, y_test = train_test_split(X, y, test_size=300, shuffle=True, stratify=y, random_state=12)
X_train, X_val, y_train, y_val = train_test_split(X_tv, y_tv, test_size=300, shuffle=True, stratify=y_tv, random_state=12)
print(Counter(y_train))
smote = SMOTE(sampling_strategy={1: 75}, random_state=42)
X_train, y_train = smote.fit_resample(X_train, y_train)
print(Counter(y_train))
輸出結(jié)果:Counter({0: 370, 1: 30}) → Counter({0: 370, 1: 75})
然后使用更新的訓(xùn)練樣本重新訓(xùn)練主要模型(LightGBM)和基線模型:
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
# 主要模型
lgbm = HistGradientBoostingClassifier(
learning_rate=0.05,
max_iter=500,
max_leaf_nodes=20,
max_depth=5,
min_samples_leaf=32,
l2_regularization=1.0,
max_features=0.7,
max_bins=255,
early_stopping=True,
n_iter_no_change=5,
scoring="f1",
validation_fraction=0.2,
tol=1e-5,
random_state=42,
class_weight='balanced'
)
# 基線模型
lr = LogisticRegression(
penalty='l2',
dual=False,
tol=1e-5,
C=1.0,
class_weight='balanced',
random_state=42,
solver="lbfgs",
max_iter=500,
n_jobs=-1,
)
性能評(píng)估結(jié)果
使用訓(xùn)練集、驗(yàn)證集和測試集對(duì)主要模型與邏輯回歸基線進(jìn)行評(píng)估。為了減少假陰性,將F1分?jǐn)?shù)作為主要評(píng)估指標(biāo):
邏輯回歸(L2正則化):訓(xùn)練性能0.9886-0.9790 → 泛化性能0.9719
LightGBM:訓(xùn)練性能0.9133-0.8873 → 泛化性能0.9040
兩個(gè)模型都表現(xiàn)出良好的泛化能力,其泛化分?jǐn)?shù)接近訓(xùn)練分?jǐn)?shù)。在這個(gè)比較中,帶有L2正則化的邏輯回歸是性能更優(yōu)的模型,在訓(xùn)練數(shù)據(jù)和更重要的未見泛化數(shù)據(jù)上都達(dá)到了更高的準(zhǔn)確性。其泛化性能(0.9719)優(yōu)于LightGBM(0.9040)。
合成異常注入測試
最后,創(chuàng)建50個(gè)合成數(shù)據(jù)點(diǎn)來測試模型的適應(yīng)性:
from sklearn.metrics import f1_score
num_synthetic_fraud = 50
synthetic_fraud_X = generate_synthetic_fraud(num_synthetic_fraud, X_test, df_merged)
y_pred_test_with_synthetic = pipeline.predict(X_test_with_synthetic)
f1_test_with_synthetic = f1_score(y_test_with_synthetic, y_pred_test_with_synthetic, average='weighted')
測試結(jié)果表明,LightGBM在檢測合成欺詐方面達(dá)到了完美的F1分?jǐn)?shù)1.0000,顯著優(yōu)于邏輯回歸(F1分?jǐn)?shù):0.8764,精確度0.90,召回率0.84)。

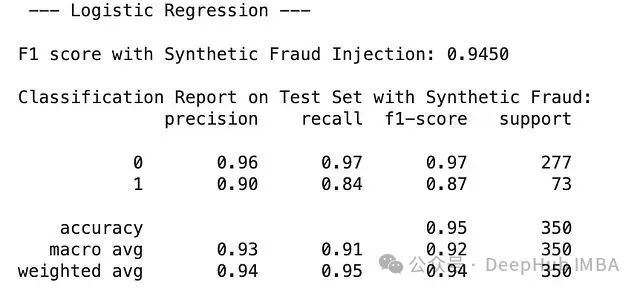
雖然LightGBM完美識(shí)別了注入的欺詐案例,但在當(dāng)前階段,帶有L2正則化的邏輯回歸可能為欺詐分類提供更好的整體平衡性能。
總結(jié)
本研究通過實(shí)驗(yàn)演示了異常標(biāo)記如何逐步完善異常檢測方案和主要分類模型在欺詐檢測中的應(yīng)用。實(shí)驗(yàn)結(jié)果表明,Isolation Forest作為一個(gè)強(qiáng)大的異常檢測模型,無需顯式建模正常模式即可有效工作,在處理未見風(fēng)險(xiǎn)事件方面具有顯著優(yōu)勢(shì)。
研究發(fā)現(xiàn),通過人工反饋循環(huán)可以有效提升模型性能,將無監(jiān)督異常檢測的結(jié)果轉(zhuǎn)化為有價(jià)值的訓(xùn)練數(shù)據(jù)。這種方法特別適用于缺乏歷史標(biāo)記數(shù)據(jù)但需要快速響應(yīng)新興威脅的場景。
對(duì)于實(shí)際應(yīng)用而言,自動(dòng)化人工審查系統(tǒng)和開發(fā)創(chuàng)建欺詐交易規(guī)則的結(jié)構(gòu)化方法將是對(duì)所提出方法的關(guān)鍵增強(qiáng)。未來的研究方向可以包括:建立更加智能化的人工反饋收集機(jī)制;開發(fā)自適應(yīng)的閾值調(diào)整算法;集成多種異常檢測算法以提高檢測精度;構(gòu)建實(shí)時(shí)異常檢測系統(tǒng)以應(yīng)對(duì)動(dòng)態(tài)變化的威脅環(huán)境。
作者:Kuriko IWAI
-
檢測系統(tǒng)
+關(guān)注
關(guān)注
3文章
974瀏覽量
43778 -
檢測
+關(guān)注
關(guān)注
5文章
4624瀏覽量
92622 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8499瀏覽量
134269
發(fā)布評(píng)論請(qǐng)先 登錄
全面剖析用于人工智能isolation_forest算法技術(shù)

提高IT運(yùn)維效率,深度解讀京東云AIOps落地實(shí)踐(異常檢測篇)
基于深度學(xué)習(xí)的異常檢測的研究方法
基于Q-學(xué)習(xí)算法的異常檢測模型
云計(jì)算平臺(tái)的異常探測
機(jī)器學(xué)習(xí)算法概覽:異常檢測算法/常見算法/深度學(xué)習(xí)
單分類支持向量機(jī)和主動(dòng)學(xué)習(xí)的網(wǎng)絡(luò)異常檢測
淺談機(jī)器學(xué)習(xí)中的異常檢測應(yīng)用

如何選擇異常檢測算法
機(jī)器學(xué)習(xí)中的異常檢測
FreeWheel基于機(jī)器學(xué)習(xí)的業(yè)務(wù)異常檢測實(shí)踐
使用MATLAB進(jìn)行異常檢測(上)
使用MATLAB進(jìn)行異常檢測(下)
基于機(jī)器學(xué)習(xí)的汽車CAN總線異常檢測方法
工業(yè)機(jī)械異常檢測






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論