 蟻群算法在驗證用例自動化回歸中的應用有哪些?
蟻群算法在驗證用例自動化回歸中的應用有哪些?
背景:如今的芯片規模越來越大,功能也愈加復雜。相應的驗證用例也越來越復雜,用例動態仿真耗時也隨之增加,而且個數有時動輒上百個。
在驗證回歸過程中,如何提高效率成為廣大驗證工程師不得不考慮的問題。
本文嘗試在驗證工作中,通過蟻群算法優化用例回歸序列,盡量縮短回歸時間,同時提高用例回歸的自動化程度。
(一)問題描述
假設當前有108個用例需要回歸,并且我們有先前用例仿真的日志文件:日志文件中有該用例仿真的耗時信息。
按照傳統做法,我們可能首先打開十多個terminal(比如15個),平均每個terminal分配若干用例(比如7個),根據用例名的字典序回歸用例。
在大多數情況下,會有個別terminal中分配的用例很快或較快的回歸完,而其余幾個terminal時間卻又很長,遲遲不能完成,時間最長的那個terminal決定了一次回歸所用的總時間。
那么,是否可以找到更好的回歸隊列分配給各個terminal, ***使得回歸總時間最短*** ?
(二)問題轉化
現在,問題就可以轉化為:108個耗時不等的任務,分配給15個并行隊列,求15個隊列的任務序列組合,使得15個隊列的總耗時最小;這個任務分配問題可以進一步引申為**負載調度**問題,108個任務分配給15臺性能各異(或同等)的服務器。
上面是從時間角度進行的問題轉化,也可以從空間角度考慮,把用例耗時對應空間大小,把問題轉化為 **存儲問題** ,本文暫不研究。
(三)問題解決
我們參考作者的JavaScript代碼,考慮用perl實現算法的核心代碼。具體步驟如下:
1)提取時間信息:即從仿真日志里提取時間信息,分兩步①粗提取,這個使用shell命令即可,可以放到makefile中;②準確提取,在剛剛的makefile中調用perl腳本,在perl腳本中利用perl強大的文本處理能力提取準確的時間信息,存入一個哈希%Case_hash(鍵-用例名,值-用例對應的時間)中。
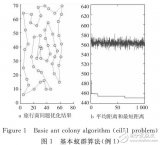
2)蟻群算法的perl實現:除了剛剛得到的哈希數組%Case_hash,我們還要給定隊列數目QueneNum,這是蟻群算法的輸入。同時,蟻群算法還涉及螞蟻數量AntNum,迭代次數ItNum,隨機因子等參數,參考文獻[1]中有詳細說明,這里不再贅述。 最終,蟻群算法會得到最優的任務分配矩陣,我們通過這個矩陣就可以知道每個隊列分配了那幾個用例。
3)回歸隊列生成:得到用例回歸隊列后,將這些隊列以target形式寫入新的makefile中(sub_makefile,在主makefile中include這個sub_makefile)。
4)自動回歸:剛剛生成了sub_makefile,我們再新建一個腳本,實現“自動打開指定個數terminal,在每個terminal自動輸入相應回歸命令(make)即可”。
(四)問題的問題
在perl實現蟻群算法時,矩陣的處理可能會稍微麻煩一些,這里使用了哈希嵌套的做法[2]。
另外,在實際應用中,蟻群算法有以下問題①在有限迭代次數內,算法不收斂;②算法收斂,但得到的最優解是**局部最優解**,非全局最優解。局部最優解是傳統蟻群算法的缺點之一。實際使用時可以折衷考慮,適當 *增大迭代次數* ,同時提高蟻群的 *隨機性* ,在有限的迭代次數內*持續搜尋最短時間的任務分配方案。*
審核編輯:劉清
-
仿真器
+關注
關注
14文章
1034瀏覽量
85082 -
JAVA
+關注
關注
20文章
2987瀏覽量
107219 -
蟻群算法
+關注
關注
3文章
55瀏覽量
13354
原文標題:蟻群算法在驗證用例自動化回歸中的應用
文章出處:【微信號:處芯積律,微信公眾號:處芯積律】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄








 工商網監
工商網監
評論