 pandas中合并數據的5個函數
pandas中合并數據的5個函數
今天借著這個機會,就為大家盤點一下pandas中合并數據的5個函數。
join
join是基于索引的橫向拼接,如果索引一致,直接橫向拼接。如果索引不一致,則會用Nan值填充。
索引一致
x = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=[0, 1, 2])
y = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=[0, 1, 2])
x.join(y)
結果如下:

索引不一致
x = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=[0, 1, 2])
y = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=[1, 2, 3])
x.join(y)
結果如下:

merge
merge是基于指定列的橫向拼接,該函數類似于關系型數據庫的連接方式,可以根據一個或多個鍵將不同的DatFrame連接起來。該函數的典型應用場景是,針對同一個主鍵存在兩張不同字段的表,根據主鍵整合到一張表里面。
- 可以指定不同的how參數,表示連接方式,有inner內連、left左連、right右連、outer全連,默認為inner;
x = pd.DataFrame({'姓名': ['張三', '李四', '王五'],
'班級': ['一班', '二班', '三班']})
y = pd.DataFrame({'專業': ['統計學', '計算機', '繪畫'],
'班級': ['一班', '三班', '四班']})
pd.merge(x,y,how="left")
結果如下:

concat
concat函數既可以用于橫向拼接,也可以用于縱向拼接。
縱向拼接
x = pd.DataFrame([['Jack','M',40],['Tony','M',20]], columns=['name','gender','age'])
y = pd.DataFrame([['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
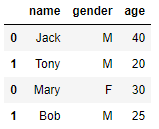
z = pd.concat([x,y],axis=0)
z
結果如下:
橫向拼接
x = pd.DataFrame({'姓名': ['張三', '李四', '王五'],
'班級': ['一班', '二班', '三班']})
y = pd.DataFrame({'專業': ['統計學', '計算機', '繪畫'],
'班級': ['一班', '三班', '四班']})
z = pd.concat([x,y],axis=1)
z
結果如下:

append
append主要用于縱向追加數據。
x = pd.DataFrame([['Jack','M',40],['Tony','M',20]], columns=['name','gender','age'])
y = pd.DataFrame([['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
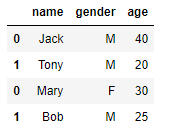
x.append(y)
結果如下:
combine
conbine可以通過使用函數,把兩個DataFrame按列進行組合。
x = pd.DataFrame({"A":[3,4],"B":[1,4]})
y = pd.DataFrame({"A":[1,2],"B":[5,6]})
x.combine(y,lambda a,b:np.where(a>b,a,b))
結果如下:

注:上述函數,用于返回對應位置上的最大值。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據
+關注
關注
8文章
7245瀏覽量
91055 -
函數
+關注
關注
3文章
4371瀏覽量
64241 -
索引
+關注
關注
0文章
59瀏覽量
10628
發布評論請先 登錄
相關推薦
熱點推薦
從Excel到Python-最常用的36個Pandas函數
本文涉及pandas最常用的36個函數,通過這些函數介紹如何完成數據生成和導入、數據清洗、預處理
Python工具pandas篩選數據的15個常用技巧
pandas是Python數據分析必備工具,它有強大的數據清洗能力,往往能用非常少的代碼實現較復雜的數據處理 今天,總結了pandas篩選

盤點Pandas的100個常用函數
分析過程中,必然要做一些數據的統計匯總工作,那么對于這一塊的數據運算有哪些可用的函數可以幫助到我們呢?具體看如下幾張表。 import pandas

數據處理中pandas的groupby小技巧
pandas的groupby是數據處理中一個非常強大的功能。雖然很多同學已已經非常熟悉了,但有些小技巧還是要和大家普及一下的。為了給大家演示,我們采用一個公開的
分享pandas中超級好用的str矢量化字符串函數
的數據清洗方法,會讓你的能力調高100倍。 本文基于此, 講述pandas中超級好用的str矢量化字符串函數 ,學了之后,瞬間感覺自己的數據

解讀12 種 Numpy 和 Pandas 高效函數技巧
本文分享給大家 12 種 Numpy 和 Pandas 函數,這些高效的函數會令數據分析更為容易、便捷。最后,讀者也可以在 GitHub 項目中找到本文所用代碼的 Jupyter No
超強圖解Pandas,建議收藏
Pandas是數據挖掘常見的工具,掌握使用過程中的函數是非常重要的。本文將借助可視化的過程,講解Pandas的各種操作。

如何使用Python和pandas庫讀取、寫入文件
= pd.read_excel(' data .xlsx') 此代碼中,我們首先導入 pandas 庫并將其重命名為 pd。使用 pd.read_excel() 函數讀取 'data.xlsx' 文件并將其存儲在
Pandas:Python中最好的數據分析工具
使用 Pandas 分析數據的能力。 常見的比如說: 在處理貨幣值時使用貨幣符號。例如,如果您的數據包含值 25.00,您不會立即知道該值是人民幣、美元、英鎊還是其他某種貨幣。 百分比是另一個
Pandas函數的三個接口介紹
本文主要介紹pandas.DataFrame的三個接口,即assign、eval、query,分別用于賦值、查詢和執行計算。 01 assign 在數據分析處理中,賦值產生新的列是非常






 工商網監
工商網監
評論