") AI圈巨震!微軟論文聲稱ChatGPT是20B(200億)參數(shù)量的模型?
AI圈巨震!微軟論文聲稱ChatGPT是20B(200億)參數(shù)量的模型?
【導讀】微軟最近一篇論文爆料,GPT-3.5的參數(shù)量只有20B,遠遠小于之前GPT-3公布175B。網(wǎng)友表示,ChatGPT能力似乎「配得上」這個體量?
GPT-3.5只有200億參數(shù)?
今天,大模型圈都被微軟論文中的一紙截圖刷爆了,究竟是怎么回事?
就在前幾天,微軟發(fā)表了篇論文并掛在了arXiv上,該論文提出了一個參數(shù)量只有75M的小規(guī)模擴散模型——CodeFusion。
性能方面,7500萬參數(shù)的CodeFusion在top-1準確率指標上,可以與最先進的350M-175B模型相媲美。

論文地址:https://arxiv.org/abs/2310.17680
這篇論文的工作很有意義,但引起大家格外注意的卻是——
作者在對比ChatGPT(gpt-3.5-turbo)時,標稱的參數(shù)量竟然只有20B!
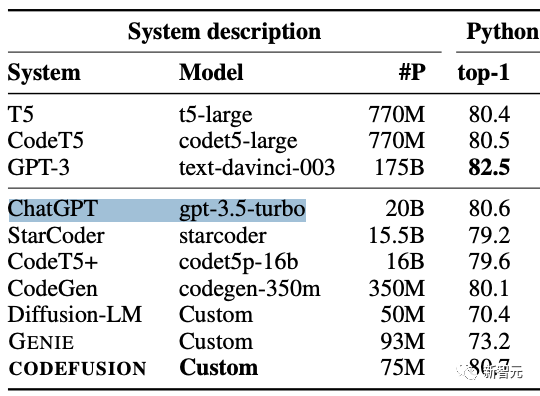
在此之前,大家針對GPT-3.5參數(shù)量的猜測都是1750億,這相當于是縮減了差不多十倍!
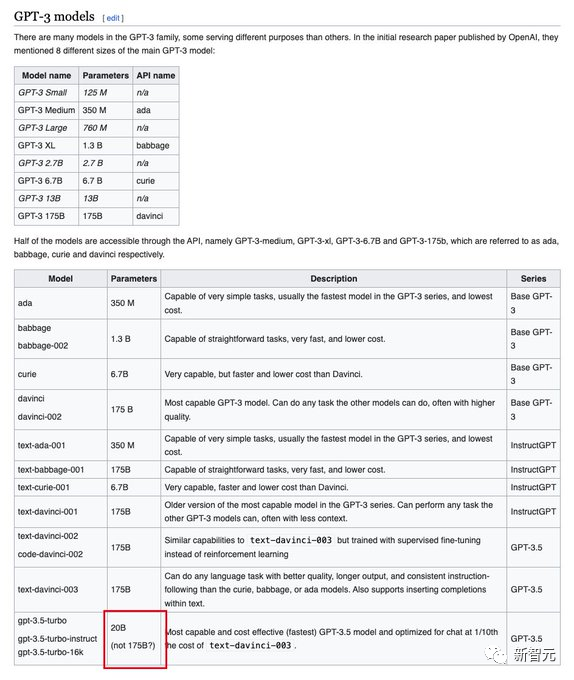
根據(jù)這篇論文的爆料,網(wǎng)友還去維基百科上更新了GPT-3.5的介紹,直接把參數(shù)大小改成了20B。
消息一出,直接登上知乎熱搜,網(wǎng)友們都炸了。

有人表示,趕緊回頭再把我之前模型蒸餾的博文拿出來復習復習 。

是「烏龍」還是「事實」?
網(wǎng)友的爆料貼一出,瞬間就引發(fā)了激烈的討論。
目前,已經(jīng)有超過68萬人前來圍觀。
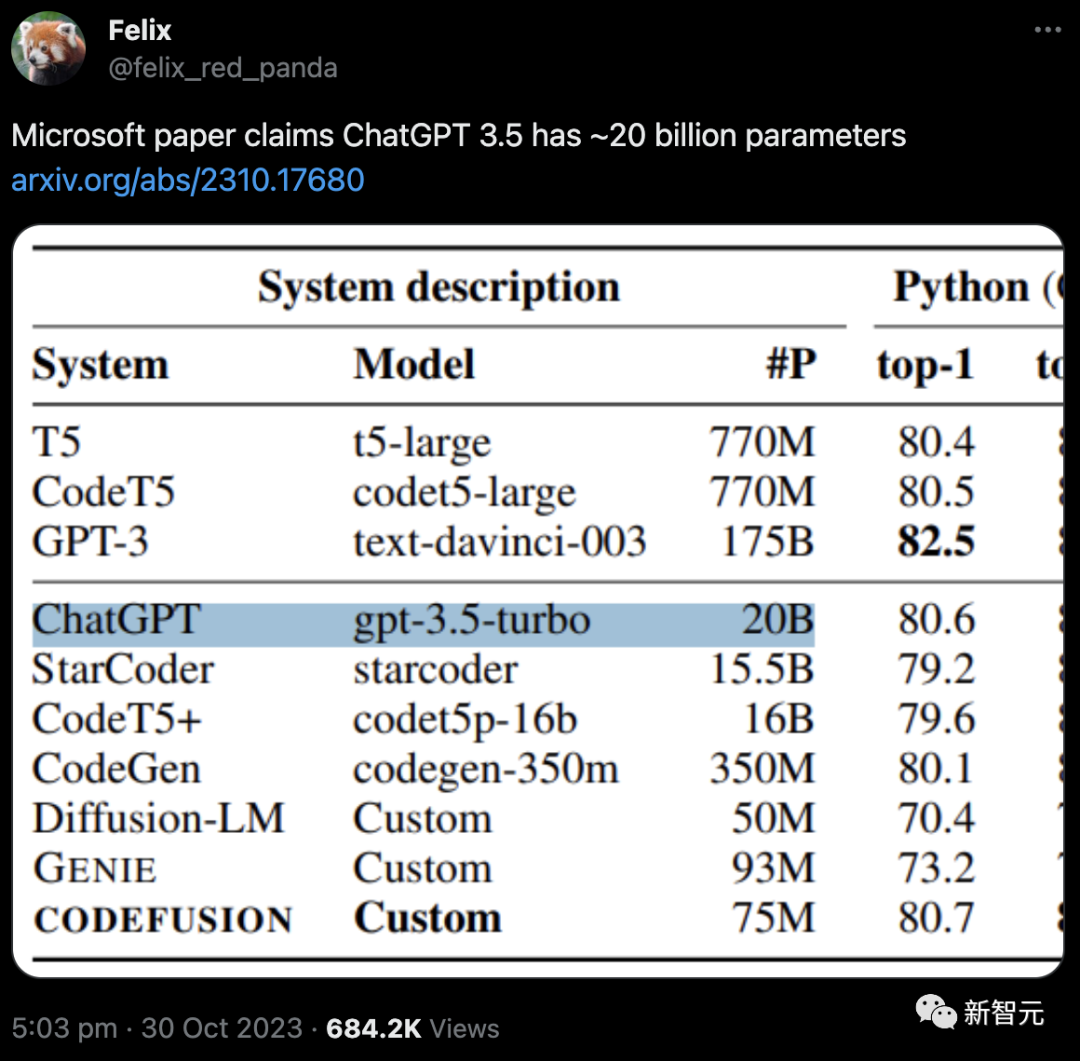
這位老哥表示,論文的幾位作者也都在用推特,估計過不了多久就會親自下場解釋。

而對于這個神秘的「20B」,網(wǎng)友們也是眾說紛紜。

有人猜測,這很可能是作者手誤打錯了。比如原本是120B,或者200B。

結合現(xiàn)實中的各項評測來看,確實有很多小模型能夠取得和ChatGPT差不多的成績,比如Mistral-7B。

也許,這也是側面證實了GPT-3.5體量真的不大。
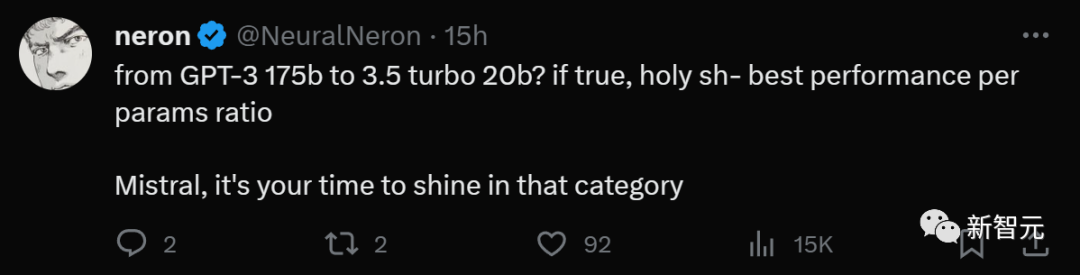
很多網(wǎng)友也認為20B的參數(shù)可能是準確的,紛紛發(fā)出感嘆:
「這也太難以想象了!Falcon-180B和Llama2-70B,竟然都無法擊敗這款20B的模型。」

也有網(wǎng)友認為,gpt-3.5-turbo是精煉版的gpt-3.5。
而這次參數(shù)的「泄露」,正好從側面印證了那些關于gpt-3.5-turbo表現(xiàn)不如舊版gpt-3.5的傳言。

不過,根據(jù)OpenAI的官方文檔,除了已經(jīng)不再使用的text-davinci和code-davinci,GPT-3.5家族全員都是基于gpt-3.5-turbo構成的。



微軟發(fā)布CodeFusion
而爆出GPT3.5只有20B參數(shù)的微軟論文,是想介紹一個用于代碼生成的擴散模型。
研究人員針對Bash、Python和Microsoft Excel條件格式(CF)規(guī)則的自然語言生成代碼的任務來評估這個模型——CodeFusion。
實驗表明,CodeFusion(只有75M參數(shù))在top-1精度方面與最先進的LLM(350M-175B參數(shù))相當,并且在top-3和top-5精度方面性能和參數(shù)比非常優(yōu)秀。
模型架構CODEFUSION用于代碼生成任務,它的訓練分為兩個階段,第一階段是無監(jiān)督預訓練,第二階段是有監(jiān)督微調。
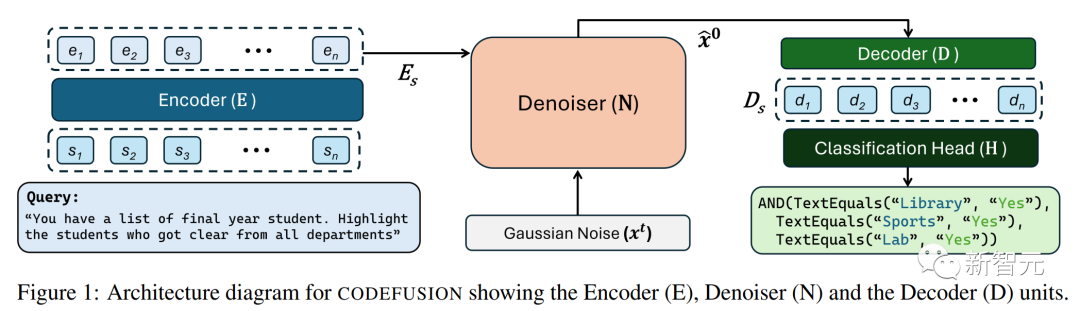
在第一階段,CODEFUSION使用未標記的代碼片段來訓練降噪器和解碼器。它還使用可訓練的嵌入層L,將代碼片段嵌入到連續(xù)空間中。
在第二階段,CODEFUSION進行有監(jiān)督的微調,使用來自文本-代碼對數(shù)據(jù)。在這個階段,編碼器、降噪器和解碼器都會得到調整,以更好地執(zhí)行任務。
此外,CODEFUSION還借鑒了之前有關文本擴散的研究成果,將來自解碼器的隱藏表示D融合到模型中。這是為了改進模型的性能。在訓練過程中,在不同step中,模型引入一些噪聲,然后計算損失函數(shù),以確保生成的代碼片段更符合預期的標準。
總之,CODEFUSION是一個執(zhí)行代碼生成工作的小模型,通過兩個階段的訓練和噪聲引入來不斷提升其性能。這個模型的靈感來自于文本擴散的研究,并通過融合解碼器的隱藏表示來改進損失函數(shù),以更好地生成高質量的代碼片段。
評估結果
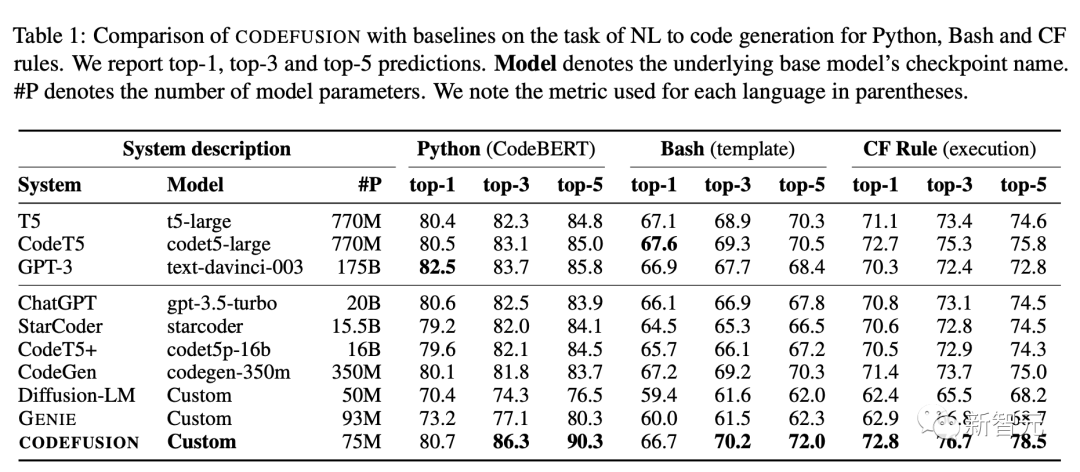
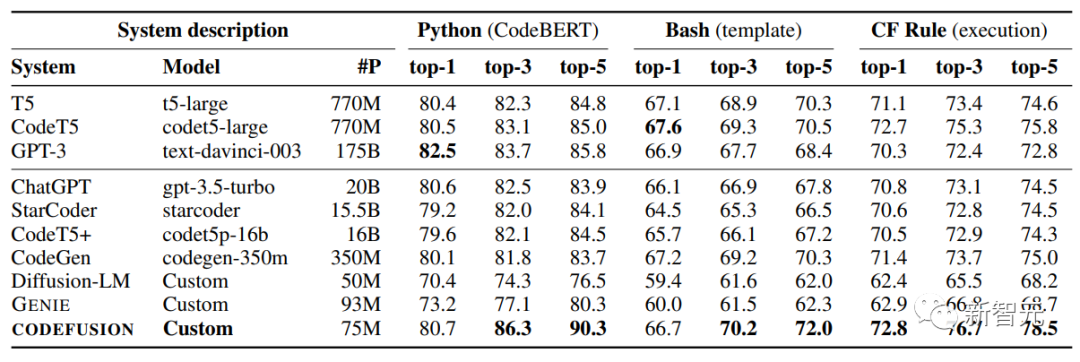
下表總結了CODEFUSION模型與各個基線模型在top-1、top-3和top-5設置下的性能表現(xiàn)。
在top-1中,CODEFUSION的性能與自回歸模型相媲美,甚至在某些情況下表現(xiàn)更出色,尤其是在Python任務中,只有GPT-3(175B)的性能稍微優(yōu)于CODEFUSION(75M)。然而,在top-3和top-5方面,CODEFUSION明顯優(yōu)于所有基線模型。
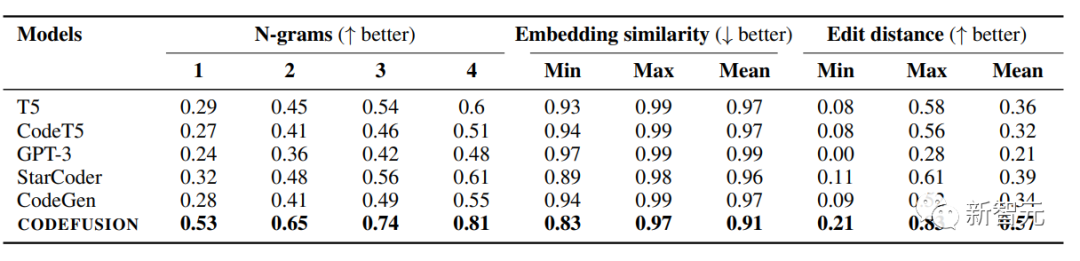
表下表展示了CODEFUSION和自回歸模型(包括T5、CodeT5、StarCoder、CodeGen、GPT-3)在各項基準任務上的平均多樣性結果,考察了每個模型的前5代生成結果。
相對于自回歸模型,CODEFUSION生成更加多樣化的結果,表現(xiàn)更出色。
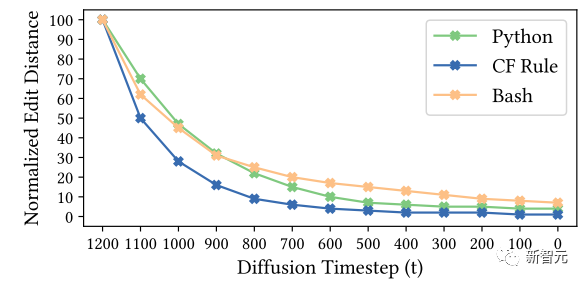
在消融實驗中,作者停止了去噪過程,并生成了在時間步t∈[0, T]范圍內的當前狀態(tài)的代碼片段。利用歸一化字符串編輯距離來衡量每個時間步長(每100步為一個增量)所獲得的結果。
這一方法有助于總結和展示CODEFUSION模型的逐步進展,如下圖所示。
說了這么多,GPT-3.5的參數(shù)量到底是多少?GPT-4與GPT-3.5在技術和其他方面有著什么樣的聯(lián)系?
GPT-3.5是一個個小專家模型的集成還是一個通才模型?是通過更大模型的蒸餾還是更大數(shù)據(jù)訓練?
這些問題的答案只能等到真正開源的時候才能揭曉了。
-
AI
+關注
關注
88文章
34597瀏覽量
276351 -
模型
+關注
關注
1文章
3501瀏覽量
50149 -
ChatGPT
+關注
關注
29文章
1589瀏覽量
8876
原文標題:AI圈巨震!微軟論文聲稱ChatGPT是20B(200億)參數(shù)量的模型?
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄

首創(chuàng)開源架構,天璣AI開發(fā)套件讓端側AI模型接入得心應手
DeepSeek發(fā)表重磅論文!推出NSA技術,讓AI模型降本增效

AMD發(fā)布10億參數(shù)開源AI模型OLMo

萬物皆AI 基于聯(lián)發(fā)科科技 MTK Genio 130 結合 ChatGPT 功能的解決方案
車載大模型分析揭示:存儲帶寬對性能影響遠超算力
ChatGPT背后的AI背景、技術門道和商業(yè)應用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論