 上線一周就2.1k star!單張圖像直接轉為3D模型!
上線一周就2.1k star!單張圖像直接轉為3D模型!

0. 筆者個人體會
提問:給你一張2D圖像,要求獲得完整的三維模型,你會怎么做?
我第一反應是拿SolidWorks自己畫一個~
最近就看到了這樣的一項開源工作Wonder3D,可以直接從2D圖像生成3D模型,感覺很神奇。讀了讀文章,發現這項工作是基于擴散模型實現的,這里也不得不感嘆擴散模型確實在AI繪畫和圖像生成領域有無限前景。今天筆者也將帶領讀者閱讀一下這項工作,當然筆者水平有限,如果有理解不當的地方歡迎大家一起探討,共同學習。
1. 效果展示
Wonder3D僅需2~3分鐘即可從單視圖圖像重建高細節紋理網格。Wonder3D首先通過跨域擴散模型生成一致的多視法線圖與相應的彩色圖像,然后利用一種法線融合方法來實現快速和高質量的重建。這里也推薦「3D視覺工坊」新課程《徹底搞透視覺三維重建:原理剖析、代碼講解、及優化改進》。

對不同風格的圖像也都適用。

甚至對各種小動物也適用:
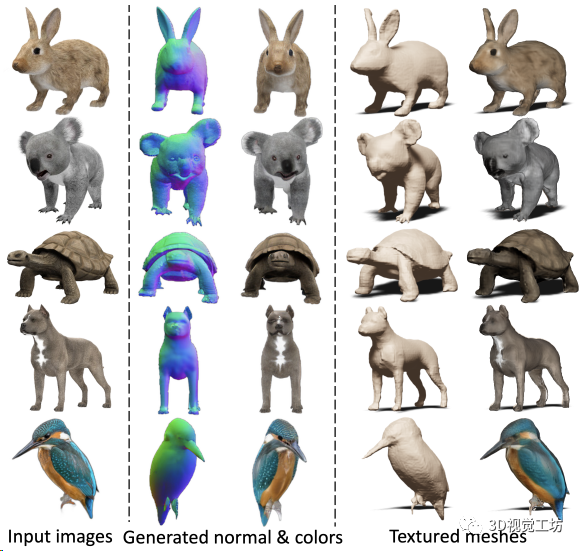
代碼已經開源了,而且他們的官方主頁還放上了Live Demo的鏈接,感興趣的讀者可以上傳自己的圖像來嘗試,下面展示一下筆者自己的測試結果。
原始圖像:

生成的多視角圖像:

2. 摘要
在這篇文章中,我們介紹了Wonder3D,一種從單視圖圖像中高效生成高保真紋理網格的新方法。基于分數蒸餾采樣(SDS)的最近方法已經顯示出從2D擴散先驗恢復3D幾何形狀的潛力,但是它們通常遭受每個形狀優化的耗時和不一致的幾何形狀。相比之下,某些作品通過快速網絡推理直接產生3D信息,但其結果通常質量較低且缺乏幾何細節。為了從整體上提高圖像到3D任務的質量、一致性和效率,我們提出了一種跨域擴散模型來生成多視圖法線貼圖和相應的彩色圖像。為了確保一致性,我們采用了一種多視圖跨域關注機制,該機制有助于跨視圖和模態的信息交換。最后,我們介紹了一種幾何感知法向融合算法,從多視圖2D表示中提取高質量的表面。我們的大量評估表明,與先前的工作相比,我們的方法實現了高質量的重建結果、魯棒的泛化以及相當好的效率。
3. 算法解析
先讓我們重新審視一下這個問題:
給定單張圖像,繪制其三維模型。
傳統方法會怎么做呢?
使用SLAM或SfM?單張圖像做初始化都不夠。
使用MVS方法?沒有多視角圖像就沒有視差圖。
用NeRF?最吃數據了,視角大一點都不行。
直接訓模型學習?思路上可以,實操起來效果非常差。
這個任務本身就非常反人類,因為只有一個視角,沒有先驗信息誰也不知道完整的三維模型長什么樣。
那怎么做呢?
這篇文章的思路很巧妙,沒有像NeRF那樣直接從2D圖像生成3D模型,而是先用擴散模型生成多個視角的2D圖像和法線圖,再融合生成3D模型。
這么做有啥好處呢?
最大的好處就是可以直接利用Stable Diffusion這種經過數十億張圖像訓練過的2D擴散模型,實際上相當于引入了非常強的先驗信息。而且法線圖可以表征物體的起伏和表面幾何信息,進而計算3D模型的高保真幾何元素。
這樣,整個任務就變為了建立一個馬爾科夫鏈,然后從中采樣顏色和法線信息的過程。
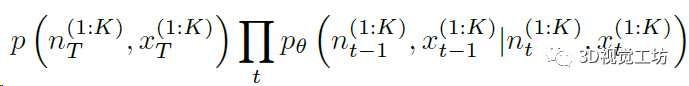
其中p代表高斯噪聲,n代表法線圖,x代表RGB圖,K代表圖像數量。
不太對,擴散模型只能處理一個域,怎么出來RGB和法線兩個域了?
的確是這樣,最直觀的改動思路就是給擴散模型添加一個頭,重新訓練模型,直接輸出RGB和法線信息,這也是前兩年多任務網絡的常用做法。但是實際操作過程中會發現收斂很慢,而且泛化性差。
另一個思路是直接訓練兩個擴散模型,但這樣不光增加了計算量,還會導致性能下降。
Wonder3D的做法是設計了一個域轉換器(Domain Switcher),實際上是一個標注域信息的一維向量。域轉換器先做位置編碼,聚合時間embedding信息,再把它也輸送給擴散模型,就可以讓擴散模型同時處理兩個域的信息。
這一點可以先放一個定性對比圖來觀察:
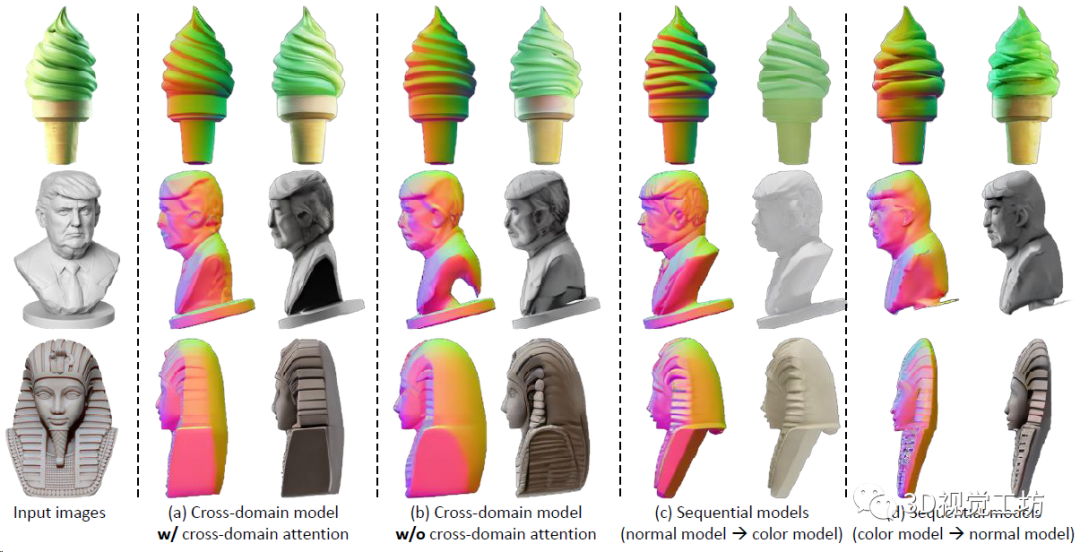
還有問題,RGB和法線是獨立生成的,多視角的RGB圖也未必就幾何一致。
在這里,Wonder3D引入了一個注意力機制,分別處理多個時間RGB幾何不一致的問題,以及RGB和法線圖的關聯問題。
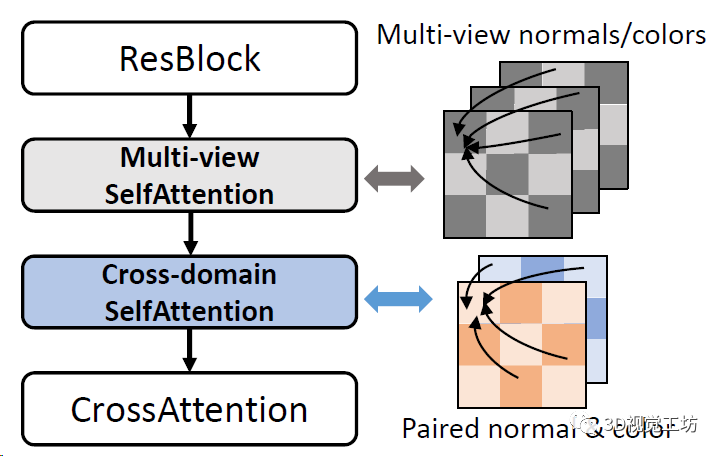
到這里,Wonder3D具體的Pipeline就出來了:
輸入一幅圖像,Wonder3D取原始圖像、CLIP產生的文本embedding、多視角相機參數,以及一個域轉換器作為條件,生成一致的多視點法線圖和彩色圖。隨后,Wonder3D借助法線融合算法,將2D表征重建為高質量的3D幾何圖形,產生高保真的紋理網格。
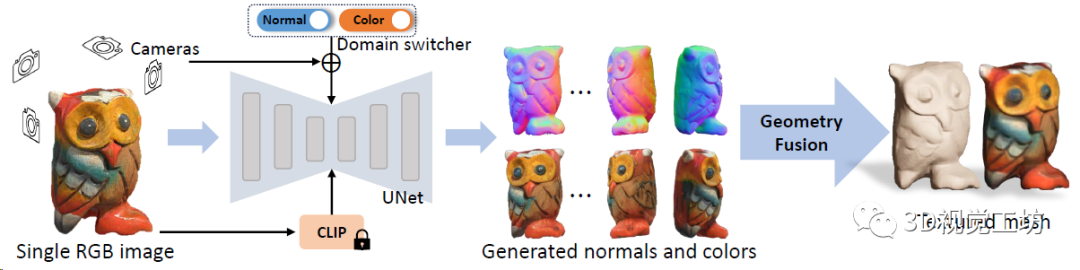
最后再看看這個幾何融合是怎么做的:
Wonder3D是優化神經隱式SDF場,來從匹配的RGB和法線圖中提取完整的三維信息。
剛才不是說NeRF需要稠密的圖像序列嗎?
如果直接做NeRF-SDF重建的話,誤差非常大,并且會一直累計下去。Wonder3D的做法是引入了一系列損失函數來約束優化:
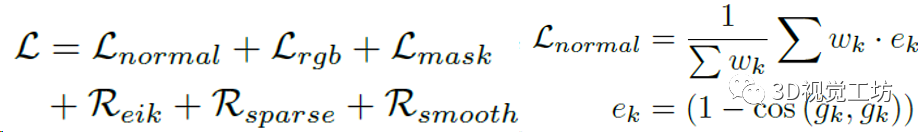
4. 實驗
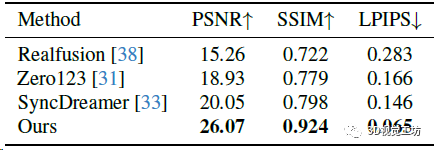
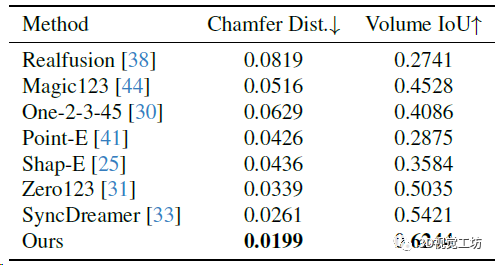
訓練數據集是LVIS子集,batch size是512,在8塊A800上訓練了3天(果然普通人還是玩不起)。從2D圖像生成3D模型的方法還是用的Instant NGP(論NeRF在各個領域的入侵haaaaa)。評估使用Google Scanned Object數據集。評估指標方面,3D重建用Chamfer Distances (CD)和Volume IoU,生成圖像質量用PSNR、SSIM、LPIPS這幾個常見指標。對比的方案也都是目前的SOTA,包括Zero123、RealFusion、Magic123、One-2-3-45、Point-E、Shap-E、SyncDreamer這些。
新視點合成對比,Zero 123缺乏多視圖一致性,SyncDreamer對輸入圖像的仰角比較敏感,但是Wonder3D生成具有語義一致性和幾何一致性的圖像。這里也推薦「3D視覺工坊」新課程《徹底搞透視覺三維重建:原理剖析、代碼講解、及優化改進》。

新視點合成的定量對比。
3D重建質量的對比,Shape-E的重建結果不完整且扭曲。SyncDreamer的重建結生成圖像大致對齊,但紋理質量不好。相比之下Wonder3D實現幾何和紋理上最高的重建質量。

3D重建的定量對比。
最后3D生成模型中各項損失函數的消融實驗,驗證損失函數的必要性:

還是一個消融實驗,驗證多視圖幾何一致性和RGB-法線對其的注意力機制的作用:

5. 總結
本文為各位讀者介紹了Wonder3D,可以從單張圖像直接生成完整的三維模型,整個模型的設計思路很巧妙,而且也開源。渲染速度也達到了2~3分鐘,這項工作的應用也很廣泛,建圖、VR、AR、動畫、影視等等都可以用。感覺Wonder3D還是很神奇的,有點長見識了。
-
3D
+關注
關注
9文章
2957瀏覽量
110563 -
圖像
+關注
關注
2文章
1094瀏覽量
41166 -
模型
+關注
關注
1文章
3511瀏覽量
50271
原文標題:上線一周就2.1k star!單張圖像直接轉為3D模型!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一種以圖像為中心的3D感知模型BIP3D
使用海爾曼太通/HellermannTyton 3D CAD 模型進行快速高效的設計
3D打印可以打印那種柔韌性好,能隨意變形的模型嗎?
騰訊混元3D AI創作引擎正式發布
騰訊混元3D AI創作引擎正式上線
Techwiz LCD 3D案例:LCOS模擬
AN-1249:使用ADV8003評估板將3D圖像轉換成2D圖像

uvled光固化3d打印技術

淘寶攜手Rokid上線3D購物新體驗

安寶特產品 安寶特3D Analyzer:智能的3D CAD高級分析工具
安寶特產品 3D Evolution : 基于特征實現無損CAD格式轉換
歡創播報 騰訊元寶首發3D生成應用






 工商網監
工商網監
評論