") c++線程中鎖的基本類(lèi)型和用法
c++線程中鎖的基本類(lèi)型和用法
線程之間的鎖有:互斥鎖、條件鎖、自旋鎖、讀寫(xiě)鎖、遞歸鎖。一般而言,鎖的功能與性能成反比。不過(guò)我們一般不使用遞歸鎖(C++標(biāo)準(zhǔn)庫(kù)提供了std::recursive_mutex),所以這里就不推薦了。
互斥鎖(Mutex)
互斥鎖用于控制多個(gè)線程對(duì)他們之間共享資源互斥訪問(wèn)的一個(gè)信號(hào)量。也就是說(shuō)是為了避免多個(gè)線程在某一時(shí)刻同時(shí)操作一個(gè)共享資源。例如線程池中的有多個(gè)空閑線程和一個(gè)任務(wù)隊(duì)列。任何是一個(gè)線程都要使用互斥鎖互斥訪問(wèn)任務(wù)隊(duì)列,以避免多個(gè)線程同時(shí)訪問(wèn)任務(wù)隊(duì)列以發(fā)生錯(cuò)亂。
在某一時(shí)刻,只有一個(gè)線程可以獲取互斥鎖,在釋放互斥鎖之前其他線程都不能獲取該互斥鎖。如果其他線程想要獲取這個(gè)互斥鎖,那么這個(gè)線程只能以阻塞方式進(jìn)行等待。
頭文件:< mutex >
類(lèi)型:std::mutex
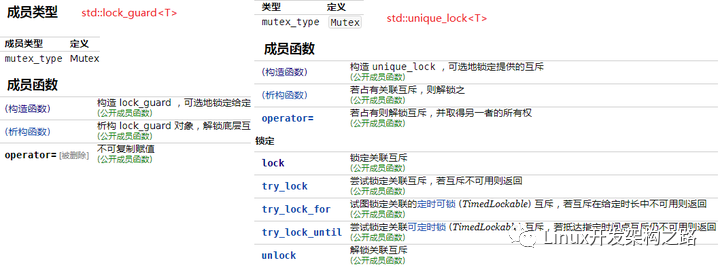
用法:在C++中,通過(guò)構(gòu)造std::mutex的實(shí)例創(chuàng)建互斥元,調(diào)用成員函數(shù)lock()來(lái)鎖定它,調(diào)用unlock()來(lái)解鎖,不過(guò)一般不推薦這種做法,標(biāo)準(zhǔn)C++庫(kù)提供了std::lock_guard和unique_lock類(lèi)模板,都是RAII風(fēng)格,它們是在定義時(shí)獲得鎖,在析構(gòu)時(shí)釋放鎖。它們的主要區(qū)別在于unique_lock鎖機(jī)制更加靈活,可以再需要的時(shí)候進(jìn)行l(wèi)ock或者unlock調(diào)用,不非得是析構(gòu)或者構(gòu)造時(shí)。std::mutex和std::lock _ guard。都聲明在< mutex >頭文件中。
#include
#include
std::list some_list;
std::mutex some_mutex;
void add_to_list(int new_value)
{
std::lock_guard guard(some_mutex);
some_list.push_back(new_value);
}
以下情況會(huì)出現(xiàn)死鎖:
int i = 0;
void fun0()
{
while (i < 100)
{
lock_guard g0(m0); //線程0加鎖0
lock_guard g1(m1); //線程0加鎖1
cout << "thread 0 running..." << endl;
}
return;
}
void fun1()
{
while (i < 100)
{
lock_guard g1(m1); //線程1加鎖1
lock_guard g0(m0); //線程1加鎖0
cout << "thread 1 running... "<< i << endl;
}
return;
}
int main()
{
thread p0(fun0);
thread p1(fun1);
p0.join();
p1.join();
return 0;
}
死鎖:死鎖是指兩個(gè)或兩個(gè)以上的進(jìn)程(線程)在運(yùn)行過(guò)程中因爭(zhēng)奪資源而造成的一種僵局,若無(wú)外力作用,這些進(jìn)程(線程)都將無(wú)法向前推進(jìn)。
解決死鎖的方法:
1、順序加鎖
int i = 0;
void fun0()
{
while (i < 100)
{
lock_guard g0(m0); //線程0加鎖0
lock_guard g1(m1); //線程0加鎖1
cout << "thread 0 running..." << endl;
}
return;
}
void fun1()
{
while (i < 100)
{
lock_guard g0(m0); //線程1加鎖0
lock_guard g1(m1); //線程1加鎖1
cout << "thread 1 running... "<< i << endl;
}
return;
}
int main()
{
thread p0(fun0);
thread p1(fun1);
p0.join();
p1.join();
return 0;
}
2、同時(shí)上鎖(需要用到lock函數(shù))++
int i = 0;
void fun0()
{
while (i < 100)
{
lock(m0,m1);
lock_guard g0(m0, adopt_lock);
lock_guard g1(m1, adopt_lock);
cout << "thread 0 running..." << endl;
}
return;
}
void fun1()
{
while (i < 100)
{
lock(m0,m1);
lock_guard g0(m0, adopt_lock);
lock_guard g1(m1, adopt_lock);
cout << "thread 1 running... "<< i << endl;
}
return;
}
int main()
{
thread p0(fun0);
thread p1(fun1);
p0.join();
p1.join();
return 0;
}
注意到這里的lock_guard中多了第二個(gè)參數(shù)adopt_lock,這個(gè)參數(shù)表示在調(diào)用lock_guard時(shí),已經(jīng)加鎖了,防止lock_guard在對(duì)象生成時(shí)構(gòu)造函數(shù)再次lock()。
條件鎖
當(dāng)需要死循環(huán)判斷某個(gè)條件成立與否時(shí)【true or false】,我們往往需要開(kāi)一個(gè)線程死循環(huán)來(lái)判斷,這樣非常消耗CPU。使用條件變量,可以讓當(dāng)前線程wait,釋放CPU,如果條件改變時(shí),我們?cè)賜otify退出線程,再次進(jìn)行判斷。
條件鎖就是所謂的條件變量,某一個(gè)線程因?yàn)槟硞€(gè)條件未滿足時(shí)可以使用條件變量使該程序處于阻塞狀態(tài)。一旦條件滿足以“信號(hào)量”的方式喚醒一個(gè)因?yàn)樵摋l件而被阻塞的線程(常和互斥鎖配合使用),喚醒后,需要檢查變量,避免虛假喚醒。最為常見(jiàn)就是在線程池中,起初沒(méi)有任務(wù)時(shí)任務(wù)隊(duì)列為空,此時(shí)線程池中的線程因?yàn)椤叭蝿?wù)隊(duì)列為空”這個(gè)條件處于阻塞狀態(tài)。一旦有任務(wù)進(jìn)來(lái),就會(huì)以信號(hào)量的方式喚醒一個(gè)線程來(lái)處理這個(gè)任務(wù)。
頭文件:< condition_variable >
類(lèi)型:std::condition_variable(只和std::mutex一起工作) 和 std::condition_variable_any(符合類(lèi)似互斥元的最低標(biāo)準(zhǔn)的任何東西一起工作)。

C++標(biāo)準(zhǔn)庫(kù)在< condition_variable >中提供了條件變量,借由它,一個(gè)線程可以喚醒一個(gè)或多個(gè)其他等待中的線程。
想要修改共享變量(即“條件”)的線程必須:
- 獲得一個(gè)std::mutex
- 當(dāng)持有鎖的時(shí)候,執(zhí)行修改動(dòng)作
- 對(duì)std::condition_variable執(zhí)行notify_one或notify_all(當(dāng)做notify動(dòng)作時(shí),不必持有鎖)
即使共享變量是原子性的,它也必須在mutex的保護(hù)下被修改,這是為了能夠?qū)⒏膭?dòng)正確發(fā)布到正在等待的線程。
任意要等待std::condition_variable的線程必須:
- 獲取std::unique_lockstd::mutex,這個(gè)mutex正是用來(lái)保護(hù)共享變量(即“條件”)的
- 執(zhí)行wait, wait_for或者wait_until. 這些等待動(dòng)作原子性地釋放mutex,并使得線程的執(zhí)行暫停
- 當(dāng)獲得條件變量的通知,或者超時(shí),或者一個(gè)虛假的喚醒,那么線程就會(huì)被喚醒,并且獲得mutex. 然后線程應(yīng)該檢查條件是否成立,如果是虛假喚醒,就繼續(xù)等待。
【注:所謂虛假喚醒,就是因?yàn)槟撤N未知的罕見(jiàn)的原因,線程被從等待狀態(tài)喚醒了,但其實(shí)共享變量(即條件)并未變?yōu)閠rue。因此此時(shí)應(yīng)繼續(xù)等待】
std::mutex mu;
std::condition_variable cond;
void function_1() //生產(chǎn)者
{
int count = 10;
while (count > 0)
{
std::unique_lock locker(mu);
q.push_front(count);
locker.unlock();
cond.notify_one(); // Notify one waiting thread, if there is one.
std::this_thread::sleep_for(std::chrono::seconds(1));
count--;
}
}
void function_2() //消費(fèi)者
{
int data = 0;
while (data != 1)
{
std::unique_lock locker(mu);
while (q.empty())
cond.wait(locker); // Unlock mu and wait to be notified
data = q.back();
q.pop_back();
locker.unlock();
std::cout << "t2 got a value from t1: " << data << std::endl;
}
}
int main()
{
std::thread t1(function_1);
std::thread t2(function_2);
t1.join();
t2.join();
return 0;
}
上面的代碼有三個(gè)注意事項(xiàng):
1.在function_2中,在判斷隊(duì)列是否為空的時(shí)候,使用的是while(q.empty()),而不是if(q.empty()),這是因?yàn)閣ait()從阻塞到返回,不一定就是由于notify_one()函數(shù)造成的,還有可能由于系統(tǒng)的不確定原因喚醒(可能和條件變量的實(shí)現(xiàn)機(jī)制有關(guān)),這個(gè)的時(shí)機(jī)和頻率都是不確定的,被稱(chēng)作偽喚醒。如果在錯(cuò)誤的時(shí)候被喚醒了,執(zhí)行后面的語(yǔ)句就會(huì)錯(cuò)誤,所以需要再次判斷隊(duì)列是否為空,如果還是為空,就繼續(xù)wait()阻塞;
2.在管理互斥鎖的時(shí)候,使用的是std::unique_lock而不是std::lock_guard, 而且事實(shí)上也不能使用std::lock_guard。這需要先解釋下wait()函數(shù)所做的事情,可以看到,在wait()函數(shù)之前,使用互斥鎖保護(hù)了,如果wait的時(shí)候什么都沒(méi)做,豈不是一直持有互斥鎖?那生產(chǎn)者也會(huì)一直卡住,不能夠?qū)?shù)據(jù)放入隊(duì)列中了。所以,wait()函數(shù)會(huì)先調(diào)用互斥鎖的unlock()函數(shù),然后再將自己睡眠,在被喚醒后,又會(huì)繼續(xù)持有鎖,保護(hù)后面的隊(duì)列操作。lock_guard沒(méi)有l(wèi)ock和unlock接口,而unique_lock提供了,這就是必須使用unique_lock的原因;
3.使用細(xì)粒度鎖,盡量減小鎖的范圍,在notify_one()的時(shí)候,不需要處于互斥鎖的保護(hù)范圍內(nèi),所以在喚醒條件變量之前可以將鎖unlock()。

自旋鎖
假設(shè)我們有一個(gè)兩個(gè)處理器core1和core2計(jì)算機(jī),現(xiàn)在在這臺(tái)計(jì)算機(jī)上運(yùn)行的程序中有兩個(gè)線程:T1和T2分別在處理器core1和core2上運(yùn)行,兩個(gè)線程之間共享著一個(gè)資源。
首先我們說(shuō)明互斥鎖的工作原理,互斥鎖是是一種sleep-waiting的鎖。假設(shè)線程T1獲取互斥鎖并且正在core1上運(yùn)行時(shí),此時(shí)線程T2也想要獲取互斥鎖(pthread_mutex_lock),但是由于T1正在使用互斥鎖使得T2被阻塞。當(dāng)T2處于阻塞狀態(tài)時(shí),T2被放入到等待隊(duì)列中去,處理器core2會(huì)去處理其他任務(wù)而不必一直等待(忙等)。也就是說(shuō)處理器不會(huì)因?yàn)榫€程阻塞而空閑著,它去處理其他事務(wù)去了。
而自旋鎖就不同了,自旋鎖是一種busy-waiting的鎖。也就是說(shuō),如果T1正在使用自旋鎖,而T2也去申請(qǐng)這個(gè)自旋鎖,此時(shí)T2肯定得不到這個(gè)自旋鎖。與互斥鎖相反的是,此時(shí)運(yùn)行T2的處理器core2會(huì)一直不斷地循環(huán)檢查鎖是否可用(自旋鎖請(qǐng)求),直到獲取到這個(gè)自旋鎖為止。
從“自旋鎖”的名字也可以看出來(lái),如果一個(gè)線程想要獲取一個(gè)被使用的自旋鎖,那么它會(huì)一致占用CPU請(qǐng)求這個(gè)自旋鎖使得CPU不能去做其他的事情,直到獲取這個(gè)鎖為止,這就是“自旋”的含義。
當(dāng)發(fā)生阻塞時(shí),互斥鎖可以讓CPU去處理其他的任務(wù);而自旋鎖讓CPU一直不斷循環(huán)請(qǐng)求獲取這個(gè)鎖。通過(guò)兩個(gè)含義的對(duì)比可以我們知道“自旋鎖”是比較耗費(fèi)CPU的。
#include
#include
#include
#include
std::atomic_flag lock = ATOMIC_FLAG_INIT;
void f(int n)
{
for (int cnt = 0; cnt < 100; ++cnt) {
while (lock.test_and_set(std::memory_order_acquire)) // 獲得鎖
; // 自旋
std::cout << "Output from thread " << n << 'n';
lock.clear(std::memory_order_release); // 釋放鎖
}
}
int main()
{
std::vector v;
for (int n = 0; n < 10; ++n) {
v.emplace_back(f, n);
}
for (auto& t : v) {
t.join();
}
}
說(shuō)明:atomic是C++標(biāo)準(zhǔn)程序庫(kù)中的一個(gè)頭文件,定義了C++11標(biāo)準(zhǔn)中的一些表示線程、并發(fā)控制時(shí)原子操作的類(lèi)與方法等。此頭文件主要聲明了兩大類(lèi)原子對(duì)象:std::atomic和std::atomic_flag。
1、atomic_flag類(lèi):是一種簡(jiǎn)單的原子布爾類(lèi)型,只支持兩種操作:test_and_set(flag=true)和clear(flag=false)。
2、std::atomic類(lèi)模板:std::atomic既不可復(fù)制亦不可移動(dòng)。atomic對(duì)int、char、bool等數(shù)據(jù)結(jié)構(gòu)進(jìn)行了原子性封裝,在多線程環(huán)境中,對(duì)std::atomic對(duì)象的訪問(wèn)不會(huì)造成競(jìng)爭(zhēng)-冒險(xiǎn)。利用std::atomic可實(shí)現(xiàn)數(shù)據(jù)結(jié)構(gòu)的無(wú)鎖設(shè)計(jì)。
所謂的原子操作,取的就是“原子是最小的、不可分割的最小個(gè)體”的意義,它表示在多個(gè)線程訪問(wèn)同一個(gè)全局資源的時(shí)候,能夠確保所有其他的線程都不在同一時(shí)間內(nèi)訪問(wèn)相同的資源。也就是他確保了在同一時(shí)刻只有唯一的線程對(duì)這個(gè)資源進(jìn)行訪問(wèn)。這有點(diǎn)類(lèi)似互斥對(duì)象對(duì)共享資源的訪問(wèn)的保護(hù),但是原子操作更加接近底層,因而效率更高。使用原子操作能大大的提高程序的運(yùn)行效率。
#include
#include
#include
#include
std::atomic count(0);
void threadFun()
{
for (int i = 0; i < 10000; i++)
count++;
}
int main(void)
{
clock_t start_time = clock();
// 啟動(dòng)多個(gè)線程
std::vector threads;
for (int i = 0; i < 10; i++)
threads.push_back(std::thread(threadFun));
for (auto&thad : threads)
thad.join();
// 檢測(cè)count是否正確 10000*10 = 100000
std::cout << "count number:" << count << std::endl;
clock_t end_time = clock();
std::cout << "耗時(shí):" << end_time - start_time << "ms" << std::endl;
return 0;
}
讀寫(xiě)鎖
先看看互斥鎖,它只有兩個(gè)狀態(tài),要么是加鎖狀態(tài),要么是不加鎖狀態(tài)。假如現(xiàn)在一個(gè)線程a只是想讀一個(gè)共享變量 i,因?yàn)椴淮_定是否會(huì)有線程去寫(xiě)它,所以我們還是要對(duì)它進(jìn)行加鎖。但是這時(shí)又有一個(gè)線程b試圖去讀共享變量 i,發(fā)現(xiàn)被鎖定了,那么b不得不等到a釋放了鎖后才能獲得鎖并讀取 i 的值,但是兩個(gè)讀取操作即使是同時(shí)發(fā)生的,也并不會(huì)像寫(xiě)操作那樣造成競(jìng)爭(zhēng),因?yàn)樗鼈儾恍薷淖兞康闹怠K晕覀兤谕诙鄠€(gè)線程試圖讀取共享變量的時(shí)候,它們可以立刻獲取因?yàn)樽x而加的鎖,而不是需要等待前一個(gè)線程釋放。
讀寫(xiě)鎖可以解決上面的問(wèn)題。它提供了比互斥鎖更好的并行性。因?yàn)橐宰x模式加鎖后,當(dāng)有多個(gè)線程試圖再以讀模式加鎖時(shí),并不會(huì)造成這些線程阻塞在等待鎖的釋放上。
讀寫(xiě)鎖是多線程同步的另外一個(gè)機(jī)制。在一些程序中存在讀操作和寫(xiě)操作問(wèn)題,對(duì)某些資源的訪問(wèn)會(huì)存在兩種可能情況,一種情況是訪問(wèn)必須是排他的,就是獨(dú)占的意思,這種操作稱(chēng)作寫(xiě)操作,另外一種情況是訪問(wèn)方式是可以共享的,就是可以有多個(gè)線程同時(shí)去訪問(wèn)某個(gè)資源,這種操作稱(chēng)為讀操作。這個(gè)問(wèn)題模型是從對(duì)文件的讀寫(xiě)操作中引申出來(lái)的。把對(duì)資源的訪問(wèn)細(xì)分為讀和寫(xiě)兩種操作模式,這樣可以大大增加并發(fā)效率。讀寫(xiě)鎖比互斥鎖適用性更高,并行性也更高。
需要注意的是,這里只是說(shuō)并行效率比互斥高,并不是速度一定比互斥鎖快,讀寫(xiě)鎖更復(fù)雜,系統(tǒng)開(kāi)銷(xiāo)更大。并發(fā)性好對(duì)于用戶(hù)體驗(yàn)非常重要,假設(shè)互斥鎖需要0.5秒,使用讀寫(xiě)鎖需要0.8秒,在類(lèi)似學(xué)生管理系統(tǒng)的軟件中,可能90%的操作都是查詢(xún)操作。如果突然有20個(gè)查詢(xún)請(qǐng)求,使用的是互斥鎖,則最后的查詢(xún)請(qǐng)求被滿足需要10秒,估計(jì)沒(méi)人接收。使用讀寫(xiě)鎖時(shí),因?yàn)樽x鎖能多次獲得,所以20個(gè)請(qǐng)求中,每個(gè)請(qǐng)求都能在1秒左右被滿足,用戶(hù)體驗(yàn)好的多。
讀寫(xiě)鎖特點(diǎn)
1 如果一個(gè)線程用讀鎖鎖定了臨界區(qū),那么其他線程也可以用讀鎖來(lái)進(jìn)入臨界區(qū),這樣可以有多個(gè)線程并行操作。這個(gè)時(shí)候如果再用寫(xiě)鎖加鎖就會(huì)發(fā)生阻塞。寫(xiě)鎖請(qǐng)求阻塞后,后面繼續(xù)有讀鎖來(lái)請(qǐng)求時(shí),這些后來(lái)的讀鎖都將會(huì)被阻塞。這樣避免讀鎖長(zhǎng)期占有資源,防止寫(xiě)鎖饑餓。
2 如果一個(gè)線程用寫(xiě)鎖鎖住了臨界區(qū),那么其他線程無(wú)論是讀鎖還是寫(xiě)鎖都會(huì)發(fā)生阻塞。
頭文件:boost/thread/shared_mutex.cpp
類(lèi)型:boost::shared_lock
用法:你可以使用boost::shared_ mutex的實(shí)例來(lái)實(shí)現(xiàn)同步,而不是使用std::mutex的實(shí)例。對(duì)于更新操作,std::lock_guard< boost::shared _mutex>和 std::unique _lock< boost::shared _mutex>可用于鎖定,以取代相應(yīng)的std::mutex特化。這確保了獨(dú)占訪問(wèn),就像std::mutex那樣。那些不需要更新數(shù)據(jù)結(jié)構(gòu)的線程能夠轉(zhuǎn)而使用 boost::shared _lock< boost::shared _mutex>來(lái)獲得共享訪問(wèn)。這與std::unique _lock用起來(lái)正是相同的,除了多個(gè)線程在同一時(shí)間,同一boost::shared _mutex上可能會(huì)具有共享鎖。唯一的限制是,如果任意一個(gè)線程擁有一個(gè)共享鎖,試圖獲取獨(dú)占鎖的線程會(huì)被阻塞,知道其他線程全都撤回它們的鎖。同樣的,如果一個(gè)線程具有獨(dú)占鎖,其他線程都不能獲取共享鎖或獨(dú)占鎖,直到第一個(gè)線程撤回它的鎖。
簡(jiǎn)單的說(shuō):
shared_lock是read lock。被鎖后仍允許其他線程執(zhí)行同樣被shared_lock的代碼。這是一般做讀操作時(shí)的需要。
unique_lock是write lock。被鎖后不允許其他線程執(zhí)行被shared_lock或unique_lock的代碼。在寫(xiě)操作時(shí),一般用這個(gè),可以同時(shí)限制unique_lock的寫(xiě)和share_lock的讀。
遞歸鎖
std::recursive_mutex 與 std::mutex 一樣,也是一種可以被上鎖的對(duì)象,但是和 std::mutex 不同的是,std::recursive_mutex 允許同一個(gè)線程對(duì)互斥量多次上鎖(即遞歸上鎖),來(lái)獲得對(duì)互斥量對(duì)象的多層所有權(quán),std::recursive_mutex 釋放互斥量時(shí)需要調(diào)用與該鎖層次深度相同次數(shù)的 unlock(),可理解為 lock() 次數(shù)和 unlock() 次數(shù)相同,除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
例如函數(shù)a需要獲取鎖mutex,函數(shù)b也需要獲取鎖mutex,同時(shí)函數(shù)a中還會(huì)調(diào)用函數(shù)b。如果使用std::mutex必然會(huì)造成死鎖。但是使用std::recursive_mutex就可以解決這個(gè)問(wèn)題。
1. C++中使用的鎖:mutex
鎖,是生活中應(yīng)用十分廣泛的一種工具。鎖的本質(zhì)屬性是為事物提供“訪問(wèn)保護(hù)”,例如:大門(mén)上的鎖,是為了保護(hù)房子免于不速之客的到訪;自行車(chē)的鎖,是為了保護(hù)自行車(chē)只有owner才可以使用;保險(xiǎn)柜上的鎖,是為了保護(hù)里面的合同和金錢(qián)等重要東西……
在c++等高級(jí)編程語(yǔ)言中,鎖也是用來(lái)提供“訪問(wèn)保護(hù)”的,不過(guò)被保護(hù)的東西不再是房子、自行車(chē)、金錢(qián),而是內(nèi)存中的各種變量。此外,計(jì)算機(jī)領(lǐng)域?qū)τ凇版i”有個(gè)響亮的名字——mutex(互斥量),學(xué)過(guò)操作系統(tǒng)的同學(xué)對(duì)這個(gè)名字肯定很熟悉。
Mutex,互斥量,就是互斥訪問(wèn)的量。這種東東只在多線程編程中起作用,在單線程程序中是沒(méi)有什么用處的。從c++11開(kāi)始,c++提供了std::mutex類(lèi)型,對(duì)于多線程的加鎖操作提供了很好的支持。下面看一個(gè)簡(jiǎn)單的例子,對(duì)于mutex形成一個(gè)直觀的認(rèn)識(shí)。
Demo1——無(wú)鎖的情況
假定有一個(gè)全局變量counter,啟動(dòng)兩個(gè)線程,每個(gè)都對(duì)該變量自增10000次,最后輸出該變量的值。在第一個(gè)demo中,我們不加鎖,代碼文件保存為:mutex_demo1_no_mutex.cpp
#include
#include
#include
#include
#include
int counter = 0;
void increase(int time) {
for (int i = 0; i < time; i++) {
// 當(dāng)前線程休眠1毫秒
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
}
}
int main(int argc, char** argv) {
std::thread t1(increase, 10000);
std::thread t2(increase, 10000);
t1.join();
t2.join();
std::cout << "counter:" << counter << std::endl;
return 0;
}
為了顯示多線程競(jìng)爭(zhēng)導(dǎo)致結(jié)果不正確的現(xiàn)象,在每次自增操作的時(shí)候都讓當(dāng)前線程休眠1毫秒
對(duì)應(yīng) CMakeLists.txt
cmake_minimum_required(VERSION 3.0.0)
# 聲明一個(gè) cmake 工程
project(HelloMutex)
# 設(shè)置編譯模式
set(CMAKE_BUILD_TYPE "Debug")
# 語(yǔ)法:add_executable( 程序名 源代碼文件 )
add_executable(${PROJECT_NAME} mutex_demo1_no_mutex.cpp)
if(WIN32)
set(PLATFROM_LIBS Ws2_32 mswsock iphlpapi ntdll)
else(WIN32)
set(PLATFROM_LIBS pthread ${CAMKE_DL_LIBS})
endif(WIN32)
# 將庫(kù)文件鏈接到可執(zhí)行程序上
target_link_libraries(${PROJECT_NAME} ${PLATFROM_LIBS})
如果沒(méi)有多線程編程的相關(guān)經(jīng)驗(yàn),我們可能想當(dāng)然的認(rèn)為最后的counter為20000,如果這樣想的話,那就大錯(cuò)特錯(cuò)了。下面是兩次實(shí)際運(yùn)行的結(jié)果:
counter:19997
[root@2d129aac5cc5 demo]# ./mutex_demo1_no_mutex
counter:19996
出現(xiàn)上述情況的原因是:自增操作"counter++"不是原子操作,而是由多條匯編指令完成的。多個(gè)線程對(duì)同一個(gè)變量進(jìn)行讀寫(xiě)操作就會(huì)出現(xiàn)不可預(yù)期的操作。以上面的demo1作為例子:假定counter當(dāng)前值為10,線程1讀取到了10,線程2也讀取到了10,分別執(zhí)行自增操作,線程1和線程2分別將自增的結(jié)果寫(xiě)回counter,不管寫(xiě)入的順序如何,counter都會(huì)是11,但是線程1和線程2分別執(zhí)行了一次自增操作,我們期望的結(jié)果是12!!!!!
輪到mutex上場(chǎng)。
Demo2——加鎖的情況
定義一個(gè)std::mutex對(duì)象用于保護(hù)counter變量。對(duì)于任意一個(gè)線程,如果想訪問(wèn)counter,首先要進(jìn)行"加鎖"操作,如果加鎖成功,則進(jìn)行counter的讀寫(xiě),讀寫(xiě)操作完成后釋放鎖(重要!!!);如果“加鎖”不成功,則線程阻塞,直到加鎖成功。
#include
#include
#include
#include
#include
int counter = 0;
std::mutex mtx; // 保護(hù)counter
void increase(int time) {
for (int i = 0; i < time; i++) {
mtx.lock();
// 當(dāng)前線程休眠1毫秒
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
mtx.unlock();
}
}
int main(int argc, char** argv) {
std::thread t1(increase, 10000);
std::thread t2(increase, 10000);
t1.join();
t2.join();
std::cout << "counter:" << counter << std::endl;
return 0;
}
上述代碼保存文件為:mutex_demo2_with_mutex.cpp。先來(lái)看幾次運(yùn)行結(jié)果:
counter:20000
[root@2d129aac5cc5 demo]# ./mutex_demo2_with_mutex
counter:20000
[root@2d129aac5cc5 demo]# ./mutex_demo2_with_mutex
counter:20000
這次運(yùn)行結(jié)果和我們預(yù)想的一致,原因就是“利用鎖來(lái)保護(hù)共享變量”,在這里共享變量就是counter(多個(gè)線程都能對(duì)其進(jìn)行訪問(wèn),所以就是共享變量啦)。
簡(jiǎn)單總結(jié)一些std::mutex:
- 對(duì)于std::mutex對(duì)象,任意時(shí)刻最多允許一個(gè)線程對(duì)其進(jìn)行上鎖
- mtx.lock():調(diào)用該函數(shù)的線程嘗試加鎖。如果上鎖不成功,即:其它線程已經(jīng)上鎖且未釋放,則當(dāng)前線程block。如果上鎖成功,則執(zhí)行后面的操作,操作完成后要調(diào)用mtx.unlock()釋放鎖,否則會(huì)導(dǎo)致死鎖的產(chǎn)生
- mtx.unlock():釋放鎖
- std::mutex還有一個(gè)操作:mtx.try_lock(),字面意思就是:“嘗試上鎖”,與mtx.lock()的不同點(diǎn)在于:如果上鎖不成功,當(dāng)前線程不阻塞。
2. lock_guard
雖然std::mutex可以對(duì)多線程編程中的共享變量提供保護(hù),但是直接使用std::mutex的情況并不多。因?yàn)閮H使用std::mutex有時(shí)候會(huì)發(fā)生死鎖。回到上邊的例子,考慮這樣一個(gè)情況:假設(shè)線程1上鎖成功,線程2上鎖等待。但是線程1上鎖成功后,拋出異常并退出,沒(méi)有來(lái)得及釋放鎖,導(dǎo)致線程2“永久的等待下去”(線程2:我的心在等待永遠(yuǎn)在等待……),此時(shí)就發(fā)生了死鎖。給一個(gè)發(fā)生死鎖的 :
Demo3——死鎖的情況(僅僅為了演示,不要這么寫(xiě)代碼哦)
為了捕捉拋出的異常,我們重新組織一下代碼,代碼保存為:mutex_demo3_dead_lock.cpp。
#include
#include
#include
#include
#include
int counter = 0;
std::mutex mtx; // 保護(hù)counter
void increase_proxy(int time, int id) {
for (int i = 0; i < time; i++) {
mtx.lock();
// 線程1上鎖成功后,拋出異常:未釋放鎖
if (id == 1) {
throw std::runtime_error("throw excption....");
}
// 當(dāng)前線程休眠1毫秒
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
mtx.unlock();
}
}
void increase(int time, int id) {
try {
increase_proxy(time, id);
}
catch (const std::exception& e){
std::cout << "id:" << id << ", " << e.what() << std::endl;
}
}
int main(int argc, char** argv) {
std::thread t1(increase, 10000, 1);
std::thread t2(increase, 10000, 2);
t1.join();
t2.join();
std::cout << "counter:" << counter << std::endl;
return 0;
}
執(zhí)行后,結(jié)果如下圖所示:
id:1, throw excption....
程序并沒(méi)有退出,而是永遠(yuǎn)的“卡”在那里了,也就是發(fā)生了死鎖。
那么這種情況該怎么避免呢?這個(gè)時(shí)候就需要std::lock_guard登場(chǎng)了。std::lock_guard只有構(gòu)造函數(shù)和析構(gòu)函數(shù)。簡(jiǎn)單的來(lái)說(shuō):當(dāng)調(diào)用構(gòu)造函數(shù)時(shí),會(huì)自動(dòng)調(diào)用傳入的對(duì)象的lock()函數(shù),而當(dāng)調(diào)用析構(gòu)函數(shù)時(shí),自動(dòng)調(diào)用unlock()函數(shù)(這就是所謂的RAII,讀者可自行搜索)。我們修改一下demo3。
Demo4——避免死鎖,lock_guard
demo4保存為:mutex_demo4_lock_guard.cpp
#include
#include
#include
#include
#include
int counter = 0;
std::mutex mtx; // 保護(hù)counter
void increase_proxy(int time, int id) {
for (int i = 0; i < time; i++) {
// std::lock_guard對(duì)象構(gòu)造時(shí),自動(dòng)調(diào)用mtx.lock()進(jìn)行上鎖
// std::lock_guard對(duì)象析構(gòu)時(shí),自動(dòng)調(diào)用mtx.unlock()釋放鎖
std::lock_guard lk(mtx);
// 線程1上鎖成功后,拋出異常:未釋放鎖
if (id == 1) {
throw std::runtime_error("throw excption....");
}
// 當(dāng)前線程休眠1毫秒
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
}
}
void increase(int time, int id) {
try {
increase_proxy(time, id);
}
catch (const std::exception& e){
std::cout << "id:" << id << ", " << e.what() << std::endl;
}
}
int main(int argc, char** argv) {
std::thread t1(increase, 10000, 1);
std::thread t2(increase, 10000, 2);
t1.join();
t2.join();
std::cout << "counter:" << counter << std::endl;
return 0;
}
執(zhí)行上述代碼,結(jié)果為:
id:1, throw excption....
counter:10000
結(jié)果符合預(yù)期。所以,推薦使用std::mutex和std::lock_guard搭配使用,避免死鎖的發(fā)生。
3. std::lock_guard的第二個(gè)構(gòu)造函數(shù)
實(shí)際上,std::lock_guard有兩個(gè)構(gòu)造函數(shù),具體的(參考:cppreference):
lock_guard( mutex_type& m, std::adopt_lock_t t ); (2) (since C++11)
lock_guard( const lock_guard& ) = delete; (3) (since C++11)
在demo4中我們使用了第1個(gè)構(gòu)造函數(shù),第3個(gè)為拷貝構(gòu)造函數(shù),定義為刪除函數(shù)。這里我們來(lái)重點(diǎn)說(shuō)一下第2個(gè)構(gòu)造函數(shù)。
第2個(gè)構(gòu)造函數(shù)有兩個(gè)參數(shù),其中第二個(gè)參數(shù)類(lèi)型為:std::adopt_lock_t。這個(gè)構(gòu)造函數(shù)假定:當(dāng)前線程已經(jīng)上鎖成功,所以不再調(diào)用lock()函數(shù),這里不再給出具體的例子。
-
參數(shù)
+關(guān)注
關(guān)注
11文章
1860瀏覽量
32428 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4346瀏覽量
62977 -
C++
+關(guān)注
關(guān)注
22文章
2114瀏覽量
73859 -
線程
+關(guān)注
關(guān)注
0文章
505瀏覽量
19758
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
C和C++中const的用法比較
C語(yǔ)言的數(shù)據(jù)基本類(lèi)型分為哪幾種
C++ 面向?qū)ο蠖?b class='flag-5'>線程編程下載
C++面向?qū)ο蠖?b class='flag-5'>線程編程 (pdf電子版)
C語(yǔ)言數(shù)據(jù)的基本類(lèi)型
C語(yǔ)言和C++的特點(diǎn)與用法詳細(xì)說(shuō)明
Vulkan API 基本類(lèi)型介紹
Vulkan API 基本類(lèi)型 小結(jié)

C++可移植性及多線程
C++入門(mén)之表達(dá)式
C++入門(mén)之string
C++的引用和指針
如何用C++實(shí)現(xiàn)一個(gè)線程池呢?
javascript基本類(lèi)型有哪些
C++中實(shí)現(xiàn)類(lèi)似instanceof的方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論