") OpenAI“政變”進(jìn)行時,“百模大戰(zhàn)”接下來該戰(zhàn)什么?
OpenAI“政變”進(jìn)行時,“百模大戰(zhàn)”接下來該戰(zhàn)什么?
這兩天AI圈最熱鬧的消息,應(yīng)該就OpenAI高層內(nèi)訌,標(biāo)志性人物、原CEO Sam Altman被董事會解雇,數(shù)位科學(xué)家和高層離職。
關(guān)于“政變”的原因,坊間有很多傳言,比如商業(yè)化和非營利原則的矛盾。總之,事件相關(guān)者在輿論場拉扯,吃瓜群眾則瞪大了眼睛看戲。這場風(fēng)波會給全球AI研發(fā),尤其是大模型帶來什么影響,還是未知數(shù)。
有人做了一個梗圖,大模型廠商亂成一鍋粥,只有賣卡的英偉達(dá)穩(wěn)坐釣魚臺。
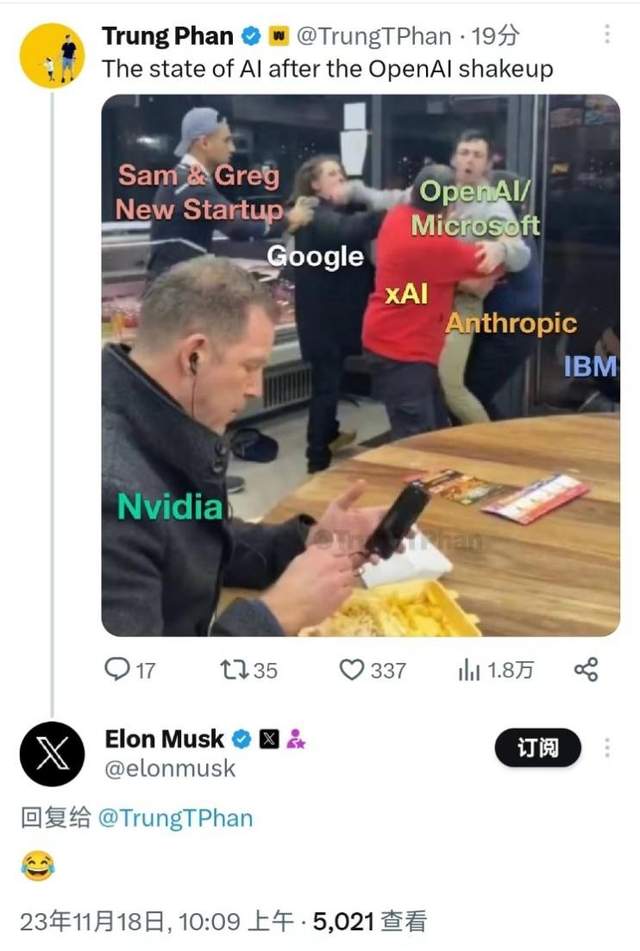
任它天邊云卷云舒,可以肯定的是,中國的AI大模型在取得廣泛成就的基礎(chǔ)上,會繼續(xù)向前發(fā)展,釋放產(chǎn)業(yè)價值,并且不會一味照搬海外,尤其是OpenAI的模式。
帶著這份淡定,我們將目光聚焦在國產(chǎn)大模型,會發(fā)現(xiàn)“百模大戰(zhàn)”熱潮中,還缺乏對各類大模型全面、分層、真實的能力評估。
通用大模型、行業(yè)大模型,都在比拼參數(shù)規(guī)模,但訓(xùn)練數(shù)據(jù)質(zhì)量不確定,僅憑參數(shù),行業(yè)客戶和用戶也難以選對適合的大模型。
那么看榜單呢?基準(zhǔn)測試benchmark和標(biāo)準(zhǔn)化數(shù)據(jù)集,可以針對性調(diào)優(yōu),榜單無法反映實際應(yīng)用效果差距。
而且大模型在不同任務(wù)場景下,表現(xiàn)的區(qū)分度很大。一位開發(fā)者說,“現(xiàn)在就是告訴你都有哪些大模型,實際效果還是得靠自己測測看”。
據(jù)中國信通院的數(shù)據(jù)顯示,目前的大模型測試方法和數(shù)據(jù)集已有200多個。想要一個個測過來,會給用戶帶來非常繁重的工作量。
“百模大戰(zhàn)”亂花漸欲迷人眼,那么,除了“跑分”打榜和參數(shù)“碾壓”,還有什么辦法來真實且有效地評判一個大模型的水平呢?
有必要來聊聊,“百模大戰(zhàn)”,不同賽道都在戰(zhàn)什么?
大模型,不看高分看高能
所謂“百模大戰(zhàn)”,并不是每個大模型都在做著同樣的事。其中,既有想做基座模型basemodle的通用大模型,如百度的文心、阿里的通義、騰訊的混元、華為的盤古、訊飛的星火、智譜的ChatGLM等,也有面向行業(yè)、場景的垂直大模型,目前在金融、教育、工業(yè)、傳媒、政務(wù)等多個領(lǐng)域都大量涌現(xiàn)。
不同賽道的大模型,其核心競爭力也不一樣。比如一味拼算法的打榜,對于行業(yè)大模型來說,可以作為一種宣傳手段和“炫技”,但實際效果才是用戶最關(guān)注的。
目前不少開發(fā)者反映,各類大模型都存在各自的問題。
1.基座模型,本身能力有限制。
提到通用大模型,大家可能第一時間想到的就是推理能力,這也是大模型基準(zhǔn)測試的主要指標(biāo)。但在實際應(yīng)用中,尤其是文科類型任務(wù),大家不會沒事出“腦筋急轉(zhuǎn)彎”來測試通用大模型的邏輯推理能力,而是更希望大模型在復(fù)雜任務(wù)和上下文長度上,有更可靠的表現(xiàn)。
比如寫一篇演講文稿,篇幅一長就開始胡說八道或泛泛而談,文本的采用率下降;為AIGC配字幕,不能整篇生成,還需要人工將文案切割成片;編寫一個程序,半路開始network error……這些都是實際應(yīng)用中,大家比較關(guān)注的通用大模型的能力。
2.行業(yè)大模型,領(lǐng)域壁壘難翻越。
“百模大戰(zhàn)”進(jìn)行到當(dāng)下,很多行業(yè)開發(fā)者和企業(yè)都意識到,獨有的數(shù)據(jù)和場景,才是自己的護(hù)城河,開始打造定制化的大模型,而領(lǐng)域知識不夠,難以形成滿足某一領(lǐng)域需求的行業(yè)向產(chǎn)品。
比如大模型與行業(yè)知識不匹配、許多行業(yè)know-how還沒有知識化、傳統(tǒng)的知識圖譜與大模型的協(xié)同設(shè)計等,知識計算的能力不夠強(qiáng),就無法真正撼動領(lǐng)域壁壘,讓大模型解決實際的業(yè)務(wù)問題。
3.有用性,ROI是個謎。
大模型的實際應(yīng)用效果難以評估,其中一個主要原因,就是模型生成結(jié)果的有用性(采用率、可用率等指標(biāo)),涉及大量多模態(tài)數(shù)據(jù)。
金融、醫(yī)藥、交通、城市等產(chǎn)業(yè)中,存在著大量多模態(tài)信息,比如客服電話的語音、醫(yī)學(xué)影像圖片、傳感器數(shù)據(jù)等,大語言模型必須具備多模態(tài)理解能力,將多模態(tài)信息與語言進(jìn)行綜合分析處理,才能保證較高質(zhì)量的輸出。
在實際任務(wù)中,上述三種問題可能會同時存在,要同時解決。
一位醫(yī)藥專家告訴我,在研發(fā)醫(yī)學(xué)影像的算法時,就需要基座大模型在預(yù)訓(xùn)練階段就具備多模態(tài)理解能力、醫(yī)學(xué)影像知識,可以執(zhí)行通用任務(wù)。同時,行業(yè)側(cè)還需要根據(jù)知識設(shè)計目標(biāo)函數(shù),在特征抽取、相似性度量、迭代優(yōu)化算法等,都要貢獻(xiàn)好各自的知識,才可能訓(xùn)練出一個對醫(yī)務(wù)工作者友好的領(lǐng)域大模型,不需要專業(yè)知識,也不需要建模,就能上手使用。
就像工業(yè)革命的開始,是因為瓦特改良了蒸汽機(jī)。在此之前,蒸汽機(jī)早已被發(fā)明出來了,但一直沒有解決大規(guī)模高可用的問題,大模型也是如此。
大模型產(chǎn)業(yè)化,必須從基準(zhǔn)測試的“跑高分”,向可信賴的“高能力”進(jìn)化。
百模大戰(zhàn),究竟在戰(zhàn)哪些能力?
從高分到高能,讓大模型具有與行業(yè)結(jié)合的可行性,也讓“百模大戰(zhàn)”正在進(jìn)入新的階段。
從產(chǎn)業(yè)實際需求來看,可用且有效的大模型,至少應(yīng)該具備幾個核心能力:
1.長文能力。
大語言模型的技術(shù)特點,被認(rèn)為是“鸚鵡學(xué)舌”,將輸入信號拼湊成有一定語法結(jié)構(gòu)的句子,也就是文本補(bǔ)全能力。而大模型都有“幻覺”,上下文窗口的長度增加,邏輯幻覺就可能越嚴(yán)重,“鸚鵡學(xué)舌”開始變得吃力。
在很多垂直行業(yè)應(yīng)用中,如金融、法律、財務(wù)、營銷等,長文檔的分析處理和生成能力是剛需。
在長文中保持邏輯的連貫性、合理性,考驗著大模型的綜合能力,比如對復(fù)雜語句的理解及記憶能力,生成的可靠性,這也是大模型走向產(chǎn)業(yè)化的核心。
目前,無論開源、閉源大模型,都將長文能力作為一個核心競爭力。比如流行的開源大模型Llama 2,就將上下文長度擴(kuò)展至 128k,而基于LLaMA架構(gòu)的零一萬物的Yi系列大模型,此前曾宣稱拿下了全球最長上下文窗口寶座,達(dá)到200K,可直接處理40萬漢字超長文本輸入。閉源大模型中,GPT-4 Turbo支持了比ChatGPT更長的上下文(128k tokens),百度的文心大模型通過對話增強(qiáng),提升上下文理解能力。
2.知識能力。
大模型“大力出奇跡”的模式,忽略了模型準(zhǔn)確感知和理解注入知識的能力,目前已經(jīng)凸顯了很多問題。比如不理解領(lǐng)域知識,在實際業(yè)務(wù)中表現(xiàn)不佳,無法滿足ToB用戶的需求。因此,當(dāng)歐美科技公司依然在執(zhí)著追求更大參數(shù)時,百度、華為等國內(nèi)大模型廠商,開始轉(zhuǎn)向了行業(yè)場景,將強(qiáng)業(yè)務(wù)知識引入文心、盤古的行業(yè)大模型之中,來提升大模型在行業(yè)任務(wù)中的應(yīng)用效果。
具體是怎么做的呢?以“行業(yè)知識增強(qiáng)”為核心特色的文心,是在預(yù)訓(xùn)練大模型的基礎(chǔ)上,進(jìn)一步融合大規(guī)模知識圖譜,挖掘行業(yè)應(yīng)用場景中大量存在的行業(yè)特色數(shù)據(jù)與知識,再結(jié)合行業(yè)專家的知識,從大規(guī)模知識和海量數(shù)據(jù)中融合學(xué)習(xí),把知識內(nèi)化至模型參數(shù)中。
當(dāng)用戶輸入問題時,文心4.0會拆解回答問題所需的知識點,進(jìn)而在搜索引擎、知識圖譜、數(shù)據(jù)庫中查找準(zhǔn)確知識,再將知識組裝進(jìn)Prompt送入大模型。另一方面,大模型還將對輸出結(jié)果進(jìn)行反思,從生成結(jié)果總結(jié)知識點,進(jìn)而通過以上方式進(jìn)行確認(rèn)驗證,對結(jié)果差錯進(jìn)行修正。
目前來看,在同等參數(shù)規(guī)模下,知識增強(qiáng)的深度語意理解,效果大幅超越了純粹用深度學(xué)習(xí)的方法,推理效率更高,并且可解釋性更強(qiáng),更符合產(chǎn)業(yè)對可信AI的需求。
目前,知識+大模型還有許多細(xì)節(jié)有待解決,比如知識體系的構(gòu)建,知識的持續(xù)獲取,知識應(yīng)用和推理等,這些問題的攻克都會給行業(yè)認(rèn)知智能帶來重大機(jī)會。
3.多模態(tài)能力。
2022年我參加華為云AI院長峰會,一位科學(xué)家提到,大模型有一個問題,就是有很多符號領(lǐng)域,大模型根本就不理解。他認(rèn)為,大模型是數(shù)據(jù)與知識雙輪驅(qū)動的,雙輪驅(qū)動是未來人工智能發(fā)展的重要模式。
前面我們說了知識能力的重要性,那么“數(shù)據(jù)”究竟拼的是什么呢?就是多模態(tài)能力。
把大模型應(yīng)用到領(lǐng)域的時候,會發(fā)現(xiàn)問題非常多,根本達(dá)不到預(yù)期的效果。一個主要原因,大語言模型完全是基于語言的,而真實世界的復(fù)雜任務(wù),有大量的數(shù)值、圖表、語音、視頻等多模態(tài)數(shù)據(jù),數(shù)據(jù)的多模態(tài)特性增加了模型處理、建模和推理的復(fù)雜性。
一位醫(yī)療模型的開發(fā)者告訴我,醫(yī)療任務(wù)分析非常繁雜,數(shù)量級很多,有不同模態(tài)、病種,每一種模態(tài)有不同的診療任務(wù),要把文本、圖像等多模態(tài)包容過來,而醫(yī)療領(lǐng)域非常缺少多模態(tài)的預(yù)訓(xùn)練模型。
大模型要在實際業(yè)務(wù)中達(dá)到與人更接近的能力,也需要跨模態(tài)建立統(tǒng)一認(rèn)知。
舉個例子,AIGC生成營銷活動物料,根據(jù)文字描述生成圖像、視頻,既要精確理解提示詞的語義,還要符合領(lǐng)域規(guī)范,不能出現(xiàn)不合規(guī)的素材,同時要控制生成內(nèi)容的質(zhì)量,保持跨模態(tài)的語義一致性。
國產(chǎn)大模型在多模態(tài)領(lǐng)域也做了很多差異化探索,除了大家熟悉的以文生圖,在醫(yī)療影像、遙感、抗體藥物、交通等領(lǐng)域,跨模態(tài)技術(shù)融合也在快速開展,未來會是基座大模型和行業(yè)大模型的亮點。
從這些產(chǎn)業(yè)需要的能力來看,大模型的產(chǎn)業(yè)屬性和價值已經(jīng)清晰展露了出來。
大模型,絕不是聊聊天、搞怪圖片那么膚淺,技術(shù)覆蓋區(qū)域是很廣闊的,技術(shù)應(yīng)用價值已經(jīng)足夠具有說服力。
但也必須承認(rèn),目前,絕大多數(shù)產(chǎn)業(yè)所獲取的技術(shù)能力和技術(shù)深度,都還遠(yuǎn)遠(yuǎn)不夠。一方面受限于上游的基座大模型能力,同時也缺乏深度定制化的中游服務(wù)商,導(dǎo)致用戶大多只能調(diào)用簡單化、標(biāo)準(zhǔn)化的API,而難以將領(lǐng)域知識、多模態(tài)數(shù)據(jù)與大模型深度結(jié)合。
未來,從高分到高能,國產(chǎn)大模型一定會依靠自身的差異化技術(shù)路線,以及中國豐富多樣的產(chǎn)業(yè)需求,從懵懂走向成熟,甚至先于歐美,走向千行百業(yè)
審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
88文章
34421瀏覽量
275793 -
OpenAI
+關(guān)注
關(guān)注
9文章
1204瀏覽量
8666
發(fā)布評論請先 登錄
Omdia 林麟:2025 年 AI 眼鏡市場將呈現(xiàn)百鏡大戰(zhàn)
AI眼鏡大模型激戰(zhàn):多大模型協(xié)同、交互時延低至1.3S
OpenAI與百度開啟大模型5.0競賽,并宣布全面免費
OpenAI CEO預(yù)告GPT-4.5及GPT-5未來規(guī)劃
使用BP神經(jīng)網(wǎng)絡(luò)進(jìn)行時間序列預(yù)測
OpenAI即將推出o3 mini推理AI模型
【飛凌嵌入式OK3588J-C開發(fā)板體驗】OK3588J-C開發(fā)板的支持RKMPP的FFmpeg移植
OpenAI考慮取消AGI條款








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論