") 基于單一LLM的情感分析方法的局限性
基于單一LLM的情感分析方法的局限性
作者:wkk
就像人類在做一件事情的時(shí)候,可能需要嘗試多次。LLM也是如此!這對(duì)于情感分析任務(wù)尤其如此,在情感分析任務(wù)中,LLM需要深入推理來處理輸入中的復(fù)雜語言現(xiàn)象(例如,從句組成、反諷等),單個(gè)LLM生成的單回合輸出可能無法提供完美的決策。
今天介紹的論文工作就上面提到的單一LLM框架在進(jìn)行情感分析時(shí)的缺陷展開。

在博士畢業(yè)就有10篇ACL一作的師兄指導(dǎo)下是種什么體驗(yàn)
簡(jiǎn)介
LLM的發(fā)展為情感分析任務(wù)帶來的新的解決方案。有研究人員使用LLM,在上下文學(xué)習(xí)(in-context learning, ICL)的范式下,僅使用少量的訓(xùn)練示例就能夠?qū)崿F(xiàn)與監(jiān)督學(xué)習(xí)策略旗鼓相當(dāng)?shù)男阅鼙憩F(xiàn)。
缺點(diǎn):但是單個(gè)LLM產(chǎn)生的單輪輸出可能無法提供完美的決策。針對(duì)情感分析任務(wù),LLM通常需要闡明推理過程,以解決輸入句子中的復(fù)雜語言現(xiàn)象。
創(chuàng)新:為了解決這個(gè)問題,本文提出了一種用于情感分析的多LLM協(xié)商策略。所提出的策略的核心是生成器-鑒別器框架,其中一個(gè)LLM充當(dāng)生成器做出情感決策,而另一個(gè)充當(dāng)鑒別器,任務(wù)是評(píng)估第一個(gè)LLM生成的輸出的可信度。如下圖所示。
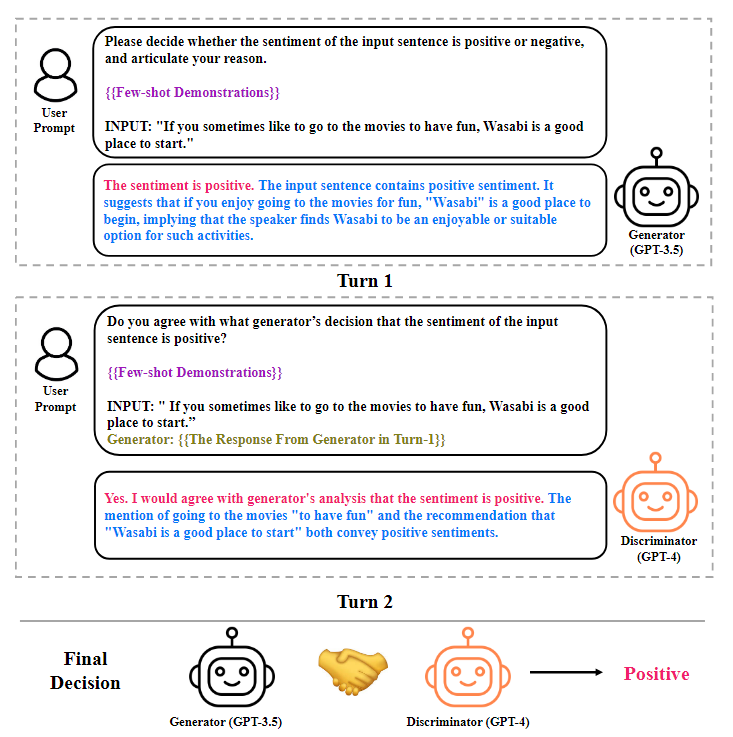
具體步驟:
推理生成器:一種LLM,它遵循結(jié)構(gòu)化的推理鏈,增強(qiáng)生成器的ICL,同時(shí)為鑒別器提供評(píng)估其有效性的證據(jù)和見解;
推導(dǎo)鑒別器的解釋;其他LLM,旨在為其判斷提供評(píng)估后的理由;
協(xié)商:兩個(gè)LLM充當(dāng)生成器和鑒別器的角色,執(zhí)行協(xié)商直到達(dá)成共識(shí)。
在情感分析基準(zhǔn)上的實(shí)驗(yàn)表明,在所有基準(zhǔn)中,所提出的算法始終比ICL基準(zhǔn)產(chǎn)生更好的性能,甚至比Twitter和電影評(píng)論數(shù)據(jù)集上的監(jiān)督基線更出色的性能。
相關(guān)工作
情感分析
情感分析是自然語言處理的熱門研究方向之一。其研究方法和思路由早期的“序列模型+分類器”演化到ICL,并逐漸成為一種新的NLP任務(wù)范式。研究人員發(fā)現(xiàn)在二分類的情感分析中,ICL取得了出色的性能。然而在一些更加復(fù)雜的任務(wù)(如方面級(jí)情感分析)中,ICL的表現(xiàn)不如監(jiān)督基線模型。
LLM and In-context Learning
LLM訓(xùn)練來自大規(guī)模的未標(biāo)注語料庫。LLM可以劃分為三類:only Encoder,only Decoder and Encoder-Decoder模型。從GPT3.0開始,LLM通過ICL在許多自然語言處理任務(wù)中展現(xiàn)出了出色的性能。
LLM協(xié)作
LLM協(xié)作涉及多個(gè)LLM協(xié)同工作以解決給定任務(wù)。具體來說,任務(wù)被分解為幾個(gè)中間任務(wù),每個(gè)LLM被分配獨(dú)立完成一個(gè)中間任務(wù)。給定的任務(wù)是在對(duì)這些中間結(jié)果進(jìn)行集成或匯總后解決的。LLM協(xié)作方法可以利用LLM的能力,提高復(fù)雜任務(wù)的性能,并能夠構(gòu)建復(fù)雜的系統(tǒng)。
LLM情感分析協(xié)商
使用兩個(gè)LLM充當(dāng)答案生成器和鑒別器。將生成器和鑒別器之間的交互稱為協(xié)商。協(xié)商將重復(fù)進(jìn)行,直到達(dá)成共識(shí)或超過最大協(xié)商次數(shù)。圖示如下圖所示。

生成器
生成器由一個(gè)LLM扮演。通過提示詢問基于ICL范式的答案生成器,旨在生成一個(gè)循序漸進(jìn)的推理鏈,并對(duì)測(cè)試輸入的情緒極性做出決定。提示由三個(gè)元素組成:任務(wù)描述、演示和測(cè)試輸入。任務(wù)描述是用自然語言對(duì)任務(wù)的描述(如,“請(qǐng)確定測(cè)試輸入的整體情感傾向。”);測(cè)試輸入是測(cè)試集中的文本輸入(例如,“天空是藍(lán)色的”);演示是從訓(xùn)練中完成的任務(wù)。每一個(gè)都包含三個(gè)元素:輸入、推理鏈和情感決策。對(duì)于每個(gè)測(cè)試輸入,首先從訓(xùn)練集中檢索K nearest鄰居作為演示。然后,我們通過提示生成器生成推理鏈,將演示轉(zhuǎn)換為(輸入、推理過程、情緒決策)三元組。在連接任務(wù)描述、演示和測(cè)試輸入后,將提示轉(zhuǎn)發(fā)給生成器,生成器將以逐步推理鏈和情感決策作為響應(yīng)。
鑒別器
鑒別器則是由另一個(gè)LLM扮演。在完成答案生成過程后,使用答案鑒別器來判斷生成器所做的決定是否正確,并提供合理的解釋。為了實(shí)現(xiàn)這個(gè)目標(biāo),首先為答案鑒別器構(gòu)造提示。提示由四個(gè)元素組成:任務(wù)描述、演示、測(cè)試輸入和來自答案生成器的響應(yīng)。任務(wù)描述是一段用自然語言描述任務(wù)的文本(例如,“請(qǐng)確定決策是否正確。“)。每個(gè)演示由六個(gè)元素組成:(輸入文本、推理鏈、情感決策、鑒別者態(tài)度、鑒別器解釋、鑒別器決策)并且通過提示回答鑒別器提供為什么情緒決定對(duì)于輸入文本是正確的解釋來構(gòu)造。然后使用構(gòu)造提示詢問鑒別器。答案鑒別器將用文本字符串進(jìn)行響應(yīng),該文本字符串包含表示鑒別器是否同意生成器的態(tài)度(即,是,否)、解釋鑒別器為什么同意/不同意生成器的解釋,以及確定測(cè)試輸入情緒的鑒別器決定。
Why Two LLMs but Not One?
本文工作為何使用兩個(gè)不同的LLM分別扮演生成器和鑒別器的原因:
如果LLM由于錯(cuò)誤的推理而作為生成器出錯(cuò),它更有可能也會(huì)犯與鑒別器相同的錯(cuò)誤,因?yàn)閬碜酝荒P偷纳善骱丸b別器很可能會(huì)犯類似的理由;
通過使用兩個(gè)獨(dú)立的模型,能夠利用這兩個(gè)模型的互補(bǔ)能力。
角色轉(zhuǎn)換
在兩個(gè)LLM以協(xié)商結(jié)束后,要求它們轉(zhuǎn)換角色并啟動(dòng)新的協(xié)商,其中第二個(gè)LLM充當(dāng)生成器,第一個(gè)LLM用作鑒別器。同樣,角色轉(zhuǎn)換協(xié)商也會(huì)結(jié)束,直到達(dá)成共識(shí)或超過最大協(xié)商次數(shù)。當(dāng)兩次協(xié)商達(dá)成協(xié)議,并且他們的決定相同時(shí),選擇其中一個(gè)決定作為最終決定,因?yàn)樗鼈兪窍嗤摹H绻粋€(gè)協(xié)商未能達(dá)成共識(shí),而另一個(gè)協(xié)商達(dá)成決定,將從達(dá)成共識(shí)的協(xié)商中選擇一個(gè)決定作為最終決定。然而,如果雙方協(xié)商達(dá)成共識(shí),但雙方的決定不一致,將需要額外的LLM幫助。
引入第三個(gè)LLM
如果兩次協(xié)商的決定不一致,將引入第三個(gè)LLM,并與上述兩個(gè)LLM中的每一個(gè)進(jìn)行協(xié)商和角色轉(zhuǎn)換協(xié)商。隨后,將得到6個(gè)協(xié)商結(jié)果,并對(duì)這些結(jié)果進(jìn)行投票:將最頻繁出現(xiàn)的決策作為輸入測(cè)試的情感極性。
實(shí)驗(yàn)
實(shí)驗(yàn)選擇GPT3.5和GPT4.0作為骨干,并且使用以下三種不同的ICL方法。
Vanilla ICL
Self-Negotiation
Negotiation with two LLMs
Dataset and methods
本文在六個(gè)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),分別為:SST-2,Movie Review,Twitter,Yelp-Binary,Amazon-Binary和IMDB數(shù)據(jù)集。并選擇了以下Baselines。
supervised methods:DRNN, RoBERTa, XLNet, UDA, BERTweet和EFL。
ICL methods:FLan-UL2, T5, ChatGPT, InstructGPT-3.5, IDS, GPT-4和Self-negotiation。
實(shí)驗(yàn)結(jié)果與分析
本文實(shí)驗(yàn)結(jié)果如下表所示:
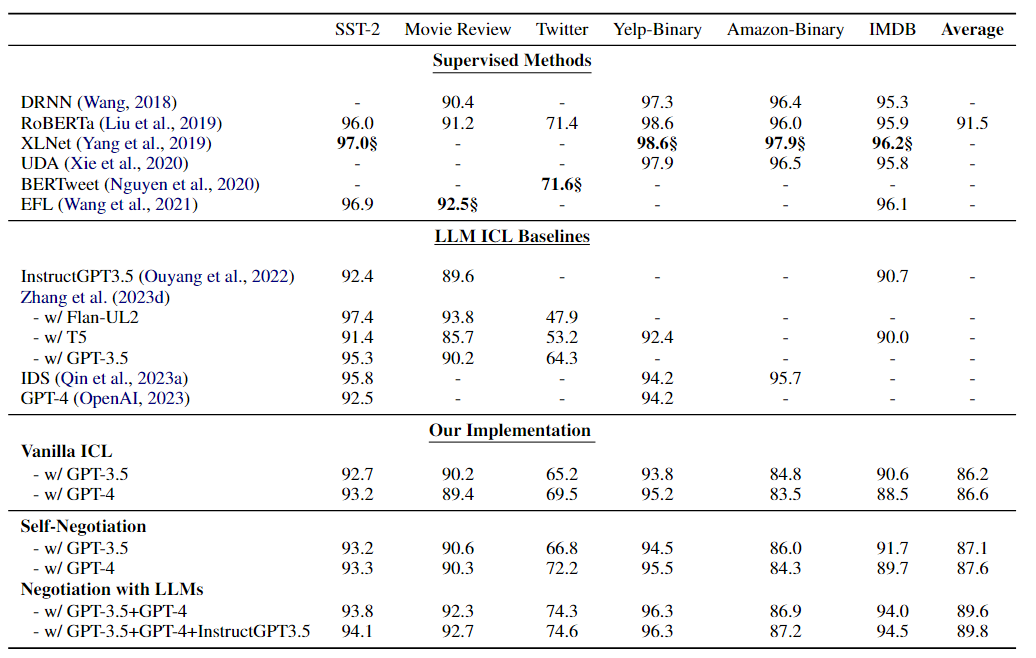
從表中可以看出,與普通ICL相比,使用一個(gè)LLM(Self-negotiation)遵循generate-discriminate范式在六個(gè)情緒分析數(shù)據(jù)集上獲得了性能增益:GPT-3.5增益平均+0.9;GPT-4增益平均+1.0 acc。這種現(xiàn)象表明,LLM作為答案鑒別器,可以校正由任務(wù)生成器引起的一部分錯(cuò)誤。
此外,與僅使用一個(gè)模型相比,使用兩個(gè)不同的LLM作為任務(wù)生成器和鑒別器反過來又帶來了顯著的性能改進(jìn)。在MR、Twitter和IMDB數(shù)據(jù)集上,使用兩個(gè)LLM的協(xié)商在準(zhǔn)確性方面分別優(yōu)于Self-negotiation方法+1.7、+2.1和+2.3。出現(xiàn)這種現(xiàn)象的原因是,使用兩個(gè)不同的LLM通過協(xié)商完成情感分析任務(wù),可以利用對(duì)給定輸入的不同理解,釋放兩個(gè)LLM的力量,從而做出更準(zhǔn)確的決策。
還發(fā)現(xiàn),當(dāng)引入第三個(gè)LLM來解決轉(zhuǎn)換角色協(xié)商之間的分歧時(shí),可以獲得額外的性能提升。這表明第三個(gè)LLM可以通過多次協(xié)商解決兩個(gè)LLM之間的沖突,并提高情緒分析任務(wù)的性能。值得注意的是,多模型協(xié)商方法在MR數(shù)據(jù)集上比監(jiān)督方法RoBERTa Large高出+0.9,并彌合了普通ICL與監(jiān)督方法之間的差距:在SST-2上實(shí)現(xiàn)94.1(+1.4)的準(zhǔn)確度;Twitter上92.1(+2.7);對(duì)Yelp-Binary為96.3(+2.5);Amazon-Binary的87.2(+3.7);在IMDB數(shù)據(jù)集上為94.5(+6.0)。
本文在Twitter數(shù)據(jù)集上的消融實(shí)驗(yàn)結(jié)果如下表所示:
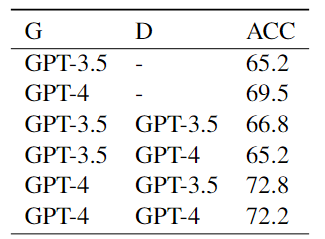
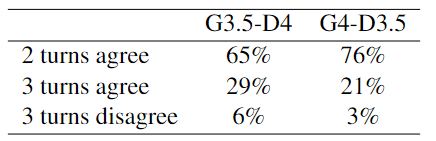
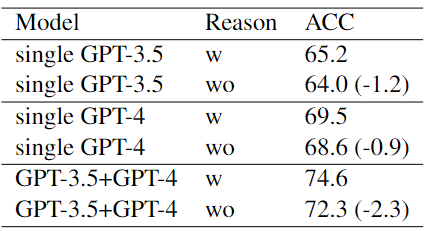
結(jié)果表明:
利用異構(gòu)LLM扮演不同的角色可以優(yōu)化協(xié)商的性能。
GPT-4的推理過程比3.5更明智,使前者的決策更有可能達(dá)成一致。
在協(xié)商過程中,LLM被要求闡明其推理原因過程具有重大的意義。
總結(jié)
在本文中,分析了基于單一LLM的情感分析方法的局限性,并引入了一種新的角色轉(zhuǎn)換的多LLM協(xié)商方法,以提高情感分類的準(zhǔn)確性和可解釋性。在多個(gè)基準(zhǔn)上的實(shí)驗(yàn)表明,與傳統(tǒng)的ICL和許多監(jiān)督方法相比,本文提出的方法具有優(yōu)勢(shì)。未來的工作可以探索優(yōu)化速度和資源消耗的框架,使基本原則適應(yīng)其他NLP任務(wù),并設(shè)計(jì)明確的協(xié)商模塊,以識(shí)別和減輕單個(gè)LLM中存在的偏見和解碼錯(cuò)誤的影響。
審核編輯:黃飛
-
生成器
+關(guān)注
關(guān)注
7文章
322瀏覽量
21542 -
自然語言處理
+關(guān)注
關(guān)注
1文章
625瀏覽量
13913 -
半監(jiān)督學(xué)習(xí)
+關(guān)注
關(guān)注
0文章
20瀏覽量
2598 -
LLM
+關(guān)注
關(guān)注
1文章
316瀏覽量
632
原文標(biāo)題:情感分析與LLMs角色扮演
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
34063的局限性
FPGA的優(yōu)勢(shì)與局限性
無線網(wǎng)絡(luò)有什么局限性?
MySQL優(yōu)化之查詢性能優(yōu)化之查詢優(yōu)化器的局限性與提示
超聲波液位計(jì)的局限性及安裝要求
運(yùn)算放大器的精度局限性是什么
貼片機(jī)轉(zhuǎn)塔式結(jié)構(gòu)的優(yōu)缺點(diǎn)是什么?有什么局限性?
基于FPGA的神經(jīng)網(wǎng)絡(luò)的性能評(píng)估及局限性
RS-485自動(dòng)換向電路設(shè)計(jì)的局限性
紅外顯微鏡用于測(cè)量高性能微波GaN HEMT器件和MMIC的有什么局限性?
WSN中LEACH協(xié)議局限性的分析與改進(jìn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論