") 如何在基于Arm Neoverse平臺的Google Axion處理器上構(gòu)建RAG應(yīng)用
如何在基于Arm Neoverse平臺的Google Axion處理器上構(gòu)建RAG應(yīng)用
作者:Arm 基礎(chǔ)設(shè)施事業(yè)部 AI 解決方案架構(gòu)師 Na Li 等
你是否好奇如何防止人工智能 (AI) 聊天機器人給出過時或不準確的答案?檢索增強生成 (Retrieval-Augmented Generation, RAG) 技術(shù)提供了一種強大的解決方案,能夠顯著提升答案的準確性和相關(guān)性。
本文將探討 RAG 的性能優(yōu)勢,并分享如何在基于 Arm Neoverse 平臺的 Google Axion 處理器上構(gòu)建 RAG 應(yīng)用,以優(yōu)化 AI 工作負載。在本文的測試中,Google Axion 處理器相較于 x86 架構(gòu)處理器,性能提升了 2.5 倍,并節(jié)省了 64% 的成本。Google Axion 處理器通過更好的 RAG 性能加速推理過程,從而實現(xiàn)更快的知識檢索、更低的響應(yīng)延遲和更高效的 AI 推理,這對于實時、動態(tài) AI 應(yīng)用至關(guān)重要。
了解 RAG:高效的 AI 文本生成方法
RAG 是一款主流 AI 框架,能夠?qū)崟r檢索相關(guān)外部知識,從而提升大語言模型 (LLM) 生成文本的質(zhì)量和相關(guān)性。與僅依賴靜態(tài)預(yù)訓(xùn)練數(shù)據(jù)集的方法不同,RAG 動態(tài)集成了最新外部資源信息,能夠生成更精確且貼近上下文的輸出結(jié)果。這使得 RAG 在實際應(yīng)用場景中表現(xiàn)出色,例如客服聊天機器人、智能體工具和動態(tài)內(nèi)容生成等場景。
何時選擇 RAG 而非微調(diào)或重新訓(xùn)練?
基礎(chǔ) LLM 通過類似人類的文本生成功能徹底改變了 AI 領(lǐng)域,但其有效性取決于模型是否擁有企業(yè)所需的最新信息。對經(jīng)過預(yù)訓(xùn)練的 LLM 模型進行重新訓(xùn)練和微調(diào)是集成額外知識的兩種常用方法。重新訓(xùn)練 LLM 是一個資源密集型的復(fù)雜過程;而微調(diào)則能夠使用特定數(shù)據(jù)集對 LLM 進行訓(xùn)練,調(diào)整模型的權(quán)重,以更好地完成目標任務(wù)。不過,模型仍然需要定期重新部署,以保持與時俱進。
通常,在將 LLM 納入 AI 戰(zhàn)略時,必須評估 LLM 的能力和局限性。主要考慮因素包括:
訓(xùn)練數(shù)據(jù)集的局限性:對于訓(xùn)練數(shù)據(jù)集未包含的主題,LLM 可能難以提供準確或最新的信息。
資源需求高:重新訓(xùn)練這些大模型需要大量的算力和工程資源,使得頻繁更新難以實施。
對內(nèi)部知識的訪問受到限制:由于企業(yè)的主要業(yè)務(wù)數(shù)據(jù)受到防火墻的保護,因此 LLM 無法通過定期重新訓(xùn)練納入專有信息,這可能會限制 LLM 在企業(yè)內(nèi)部使用時的相關(guān)性。
RAG 的優(yōu)勢
RAG 無需修改 LLM,只需利用外部數(shù)據(jù)源更新知識庫,將動態(tài)信息檢索與語言模型的生成能力相結(jié)合。如果你所在的領(lǐng)域知識經(jīng)常變化,那么 RAG 是保持準確性和相關(guān)性,并減少 LLM 幻覺的理想解決方案。
RAG 的實際應(yīng)用:對比分析
在以下所舉的例子中,比較了通用 LLM(左)和經(jīng)過 RAG(右)增強的聊天機器人。左圖中,由于信息過時或缺乏特定領(lǐng)域的知識,聊天機器人難以準確回答用戶的詢問;而 RAG 增強型聊天機器人能夠從上傳的文件中檢索最新信息,提供準確且相關(guān)的回復(fù)。
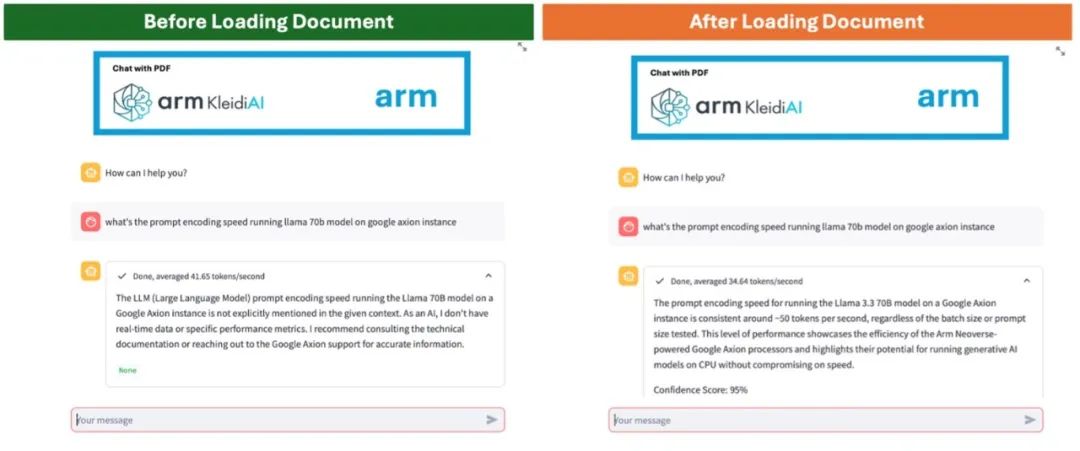
圖 1:通過 LLM 實現(xiàn)的聊天機器人(左)
和經(jīng)過 RAG 增強的聊天機器人(右)
為何選擇 Axion 來實現(xiàn) RAG 解決方案
基于 Arm Neoverse 平臺的 Google Axion 處理器為運行 LLM 的 AI 推理功能提供了理想平臺,該處理器能夠以高性能和高效率支持 RAG 應(yīng)用的運行。
優(yōu)化 AI 加速:基于 Neoverse 平臺的 CPU 具有高吞吐量向量處理和矩陣乘法功能,這對于高效處理 RAG 至關(guān)重要。
云計算的效率和可擴展性:基于 Neoverse 平臺的 CPU 可最大限度地提高每瓦性能,在高速處理和能效之間取得平衡。因此,特別適用于需要在云端快速推理并兼顧成本效益的 RAG 應(yīng)用。基于 Neoverse 的處理器還可用于擴展 AI 工作負載,確保無縫集成各種 RAG 用例。
面向 AI 開發(fā)者的軟件生態(tài)系統(tǒng):對于希望在基于 Arm 架構(gòu)的基礎(chǔ)設(shè)施上利用最新 AI 功能的開發(fā)者,Arm Kleidi 技術(shù)能夠顯著提升 RAG 應(yīng)用的性能和效率。Arm Kleidi 已經(jīng)集成到 PyTorch、TensorFlow 和 llama.cpp 等開源 AI 和機器學(xué)習(xí) (ML) 框架中,使開發(fā)者能夠?qū)崿F(xiàn)開箱即用的默認推理性能,而無需使用供應(yīng)商插件或進行復(fù)雜的優(yōu)化。
這些特性的結(jié)合帶來了顯著的性能提升,首個基于 Google Axion 的云虛擬機 C4A 與 x86 同類方案相比,大幅提升了基于 CPU 的 AI 推理和通用云工作負載的性能,使 C4A 虛擬機成為在 Google Cloud 上運行 RAG 應(yīng)用的理想選擇。
Google Axion 性能基準測試
使用 RAG 系統(tǒng)進行推理涉及兩個關(guān)鍵階段:信息檢索和生成響應(yīng)。
信息檢索:系統(tǒng)搜索向量數(shù)據(jù)庫,根據(jù)用戶的查詢找到相關(guān)內(nèi)容。
生成響應(yīng):檢索到的內(nèi)容與用戶查詢相結(jié)合,生成與上下文相關(guān)的準確回復(fù)。
一般來說,檢索速度取決于數(shù)據(jù)庫的大小和搜索算法的效率。在基于 Neoverse 平臺的 CPU 上運行時,經(jīng)優(yōu)化的算法可在幾毫秒內(nèi)返回結(jié)果。然后,將檢索到的信息與用戶的輸入相結(jié)合,構(gòu)建新的提示詞,并將其發(fā)送給 LLM 進行推理和生成響應(yīng)。相較于檢索階段,生成響應(yīng)階段耗時更長,RAG 系統(tǒng)的整體推理延遲在很大程度上受 LLM 推理速度的影響。
本次測試使用 llama.cpp 基準和 Llama 3.1 8B 模型(Q4_0 量化方案)評估了多個 Google Cloud 虛擬機的 RAG 推理性能。使用 48 個線程進行了所有測試,輸入詞元 (token) 大小為 2058,輸出詞元大小為 256。以下是測試配置:
Google Axion (C4A, Neoverse V2): 在 c4a-standard-48 實例上進行了評估。
Intel Xeon (C4, Emerald Rapids): 在 c4-standard-48 上進行了性能測試。
AMD EPYC (C3D, Genoa): 在啟用 48 個核心的 c3d-standard-60 上進行了測試。
Axion 處理器實現(xiàn)更快處理與更高效率
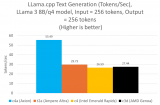
推理性能根據(jù)提示詞處理速度和詞元生成速度來測定。圖表 1 的基準測試結(jié)果表明,與當前一代 x86 實例相比,基于 Google Axion 的 C4A 虛擬機在提示詞處理和詞元生成方面實現(xiàn)了高達 2.5 倍的性能提升。
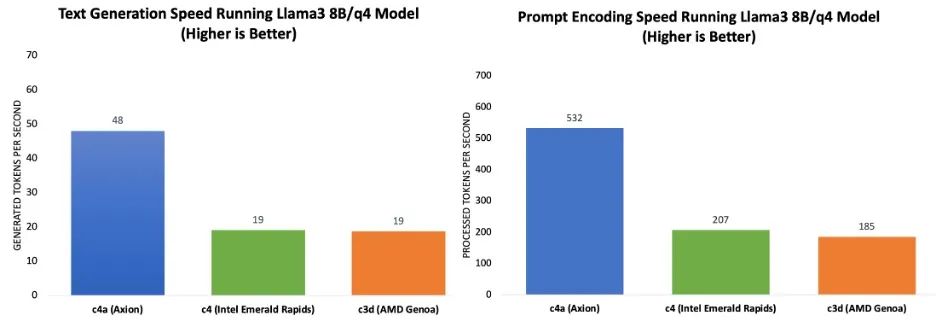
圖表 1:運行 Llama 3.1 8B/Q4 模型時,提示詞處理(左)
和詞元生成(右)與當前一代 x86 實例的性能比較
成本效益:降低 RAG 推理成本
為了評估推理任務(wù)的實例成本,還測量了從提交提示詞到生成響應(yīng)的延遲。有幾個因素會影響延遲,包括檢索速度、提示處理效率、詞元生成速率、輸入和輸出詞元大小以及用戶批處理規(guī)模。由于信息檢索延遲通常在毫秒級,與其他因素相比可以忽略不計,因此未納入計算。批次大小選擇為 1,以確保在單個用戶級別進行公平的比較。為了與基準測試保持一致,測試中將輸入和輸出詞元大小分別設(shè)置為 2048 和 256。首先通過提示詞編碼速度和詞元生成速度計算提示詞處理和詞元生成的延遲,然后根據(jù) Google Cloud 上的實例定價圖表[3]計算每次請求的成本,再將這些數(shù)字歸一化為所有三個實例的最大成本。
圖表 2 中的結(jié)果表明,基于 Axion 的虛擬機可節(jié)省高達 64% 的成本,處理每次請求所需的成本僅為當前一代 x86 實例的三分之一左右。
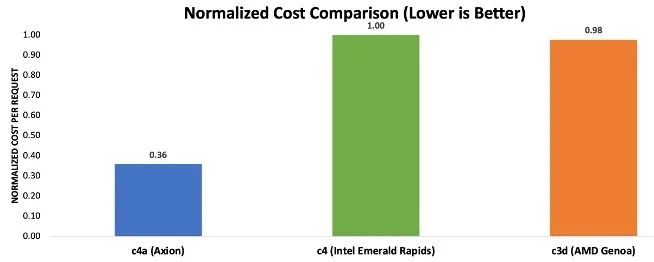
圖表 2:使用 RAG 處理推理請求的歸一化成本對比注
注:成本計算基于截至 2025 年 3 月 5 日公布的實例定價,可參見
https://cloud.google.com/compute/vm-instance-pricing
快速入門:基于 Arm 平臺構(gòu)建 RAG 應(yīng)用
以 Neoverse 平臺為核心,Google Axion 賦能的實例能以更低的成本提供高性能,助力企業(yè)構(gòu)建可擴展且高效的 RAG 應(yīng)用,同時與 x86 方案相比顯著降低了基礎(chǔ)設(shè)施開支。
為了幫助開發(fā)者快速入門,Arm 開發(fā)了分步演示和 Learning Path 教程,以便開發(fā)者使用自己選擇的 LLM 和數(shù)據(jù)源構(gòu)建基本的 RAG 系統(tǒng)。
以下資源能夠幫助剛接觸 Arm 生態(tài)系統(tǒng)的開發(fā)者順利踏上開發(fā)旅程:
通過 Arm Learning Path 遷移到 Axion:依照詳細的指南和最佳實踐,簡化向 Axion 實例的遷移進程。
Arm Software Ecosystem Dashboard:及時了解 Arm 平臺上支持的最新軟件信息。
Arm 開發(fā)者中心:無論你是剛接觸 Arm 平臺,還是正在尋找資源來開發(fā)高性能軟件解決方案,Arm 開發(fā)者中心應(yīng)有盡有,可以幫助開發(fā)者構(gòu)建更好的軟件,為數(shù)十億設(shè)備提供豐富的體驗。在 Arm 不斷壯大的全球開發(fā)者社區(qū)中,開發(fā)者可以訪問資源、交流學(xué)習(xí)和提問探討。
還等什么?即刻開啟你的遷移之旅,利用 Arm Neoverse 平臺釋放云和 AI 工作負載的全部潛力!
-
處理器
+關(guān)注
關(guān)注
68文章
19825瀏覽量
233757 -
ARM
+關(guān)注
關(guān)注
134文章
9321瀏覽量
375445 -
Google
+關(guān)注
關(guān)注
5文章
1788瀏覽量
58716 -
人工智能
+關(guān)注
關(guān)注
1804文章
48788瀏覽量
246971
原文標題:利用基于 Arm 平臺的 Google Axion,解鎖 RAG 技術(shù)的強勁實力
文章出處:【微信號:Arm社區(qū),微信公眾號:Arm社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
向Intel發(fā)起重型計算挑戰(zhàn) ARM發(fā)布Neoverse 處理器
Arm Neoverse V1的AWS Graviton3在深度學(xué)習(xí)推理工作負載方面的作用
Arm Neoverse N1軟件優(yōu)化指南
ARM處理器Google系統(tǒng)讓華碩躊躇不已
如何在芯片的PL上構(gòu)建軟核處理器?

Arm推出Neoverse處理器家族 大有對標Intel之勢
ARM推出新一代Neoverse處理器平臺,面向5nm及3nm工藝性能提升30%以上
Arm推出新一代平臺 Neoverse V2 平臺
基于ARM的嵌入式電機控制處理器構(gòu)建的模型設(shè)計平臺

Arm發(fā)布新一代Neoverse數(shù)據(jù)中心計算平臺,AI負載性能顯著提升
Google Cloud推出基于Arm Neoverse V2定制Google Axion處理器
谷歌自主研發(fā):Google Axion處理器亮相
Arm技術(shù)助力Google Axion處理器加速AI工作負載推理
如何在基于Arm Neoverse平臺的CPU上構(gòu)建分布式Kubernetes集群





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論