 如何利用OpenVINO加速LangChain中LLM任務
如何利用OpenVINO加速LangChain中LLM任務
LangChain簡介
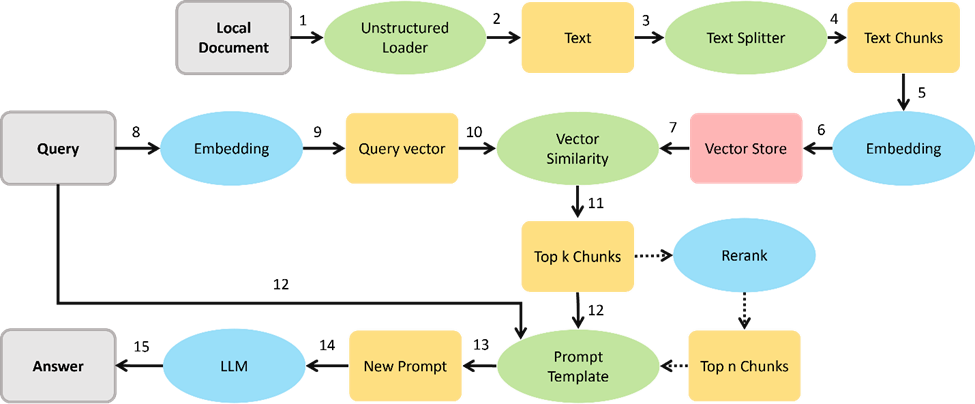
LangChain 是一個高層級的開源的框架,從字面意義理解,LangChain 可以被用來構建 “語言處理任務的鏈條”,它可以讓AI開發人員把大型語言模型(LLM)的能力和外部數據結合起來,從而去完成一些更復雜的任務。簡單來說,LangChain 可以讓你的 LLM 在回答問題時參考自定義的知識庫,實現更精確的答案輸出。例如在以下這個Retrieval Augmented Generation (RAG)任務,LangChain 可以根據問題從已有的知識庫中進行檢索,并將原始的檢索結果和問題一并包裝為Prompt提示送入 LLM 中,以此獲得更加貼近問題需求的答案。
LangChain 的核心能力主要由以下幾個模型所構成。
提示(prompts): 包括提示管理、提示優化和提示序列化。
大語言模型(LLM): 提供調用大預言模型生成文本的接口。
檢索(Retrieval): 該模塊用于構建自定義的知識倉庫,從而基于LLM實現基于文檔數據檢測的文本生成任務(RAG),這也是LangChain最核心的能力之一。
代理(agents): LLM作為代理其他工具的代理,通過LLM來判斷可以調用什么工具(tool)來解決用戶提出的特殊需求。此處的工具需要被封裝成API接口,供LangChain調用,比如一個返回文本長度的函數,就可以是一個工具。
記憶(memory): 記憶主要用來存儲多輪對話中的歷史數據,以便在后續的回答任務中可以對之前的交流記錄進行參考。
基于以上這些模塊,LangChain可以被應用于一些更復雜的任務中,例如:個人AI郵件助手,AI學習伙伴,AI數據分析,定制公司客服聊天機器人,社交媒體內容創作助手等,做為LangChain任務部署過程中的底座,LLM的推理任務勢必是重點可以被優化的方向,那如何利用OpenVINO來加速LangChain的中LLM任務呢,這里為大家整理了以下兩個方法:
方法一:利用 Huggingface pipeline
調用 Optimum 后端
鑒于langchain.llm對象已經支持了huggingface_pipeline來直接調用huggingface上的LLM
同時Huggingface的Optimum-intel組件可以將huggingface pipeline中的LLM推理任務通過OpenVINO進行加速。因此我們的第一種方案就是利用Optimum-intel的pipeline來替換原本的Transformers pipeline,如下代碼所示:
from langchain.llms import HuggingFacePipeline from transformers import pipeline - from transformers import AutoModelForCausalLM + from optimum.intel.openvino import OVModelForCausalLM - model = AutoModelForCausalLM.from_pretrained(model_id) + ov_model = OVModelForCausalLM.from_pretrained(model_id) pipe = pipeline("text-generation", model=ov_model, tokenizer=tokenizer, max_new_tokens=128, pad_token_id=tokenizer.eos_token_id) hf = HuggingFacePipeline(pipeline=pipe) llm_chain = LLMChain(prompt=prompt, llm= hf) output=llm_chain.run(question)
紅色部分是標準Transformers (第3、5行)庫在 huggingface_pipeline 中的調用方式,綠色部分為Optimum-intel(第4、6行)的調用方式,可以看到我們僅僅只需修改兩行代碼就可以把 LangChain 原生的 LLM 任務,通過 OpenVIN 進行加速,并且 Optimum-intel 提供的 API 也支持將 LLM 部署到不同的硬件平臺,例如 Intel 的 CPU 及 GPU 系列產品。
方法二:構建新的 OpenVINO pipeline 類
第一種方法固然簡單,但如果遇到 Optimum-intel 中還未適配的 LLM,那依然無法奏效,因此這里的第二種辦法就是參考 HuggingFacePipeline 這個類對象,重新構建一個基于 OpenVINO 的類對象,以此來支持自定義的模型類別。
倉庫中的ov_pipeline.py就是用來構建 OpenVINO pipeline 的代碼,為了方便演示,示例中底層還是調取 Optimum-intel 進行推理,但不同與第一種方式,這里我們可以選擇脫離 Optimum-intel 的束縛,自行定義pipeline中的關鍵方法。這里有兩個關鍵方法:
1. from_model_id函數用于讀取本地或者遠端的LLM以及其對應的Tokenizer,并利用OpenVINO runtime 對其進行編譯以及初始化。這里的函數名僅供參考,大家可以根據自己的習慣自行修改,此外在這個函數中,我們還可以對模型的配置進行調整,比如指定不同的硬件平臺進行部署,修改硬件端性能配置,例如供推理任務線程數(tread),并行任務數(stream)等,該函數預期返回一個可以直接運行的模型對象。
from_model_id(
cls,
model_id: str,
model_kwargs: Optional[dict] = None,
**kwargs: Any,
)->LLM
2. _call函數繼承自父類 LLM,用于根據提升生成本文,根據父類中的定義,他的輸入為 prompt文本,輸出同樣也是一個文本,因此在這個函數中就要求我們實現三個功能,Tokenizer分詞編碼->LLM推理->tokenizer 解碼,其實這也是LLM 問答任務中必須經歷的三個步驟,所以這里的實現方式大家可以根據自己LLM模型對于輸入輸出的要求自行定義。
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
**kwargs: Any,
)->str:
3. 這個倉庫中提供了一個簡單的 LangChain 示例sample.py,用于展示自定義 OpenVINO pipeline 在 LangChain 中的調用方式,核心部分可以參考以下代碼片段。
llm = OpenVINO_Pipeline.from_model_id(
model_id=model_path,
model_kwargs={"device":device, "temperature": 0, "trust_remote_code": True},
max_new_tokens=64
)
llm_chain=LLMChain(prompt=prompt,llm=llm)
總結
LangChain 做為當前最受歡迎的自然語言系統框架之一,可以幫助開發者快速構建起基于LLM的上層應用方案。而 OpenVINO 2023.2 新版本的發布又進一步提升了LLM的性能表現,同時降低了部署門檻,兩者的結合可以幫助開發者更便捷地在英特爾平臺上部署基于大語言模型的服務系統,豐富本地化 AI PC 應用場景的落地。
審核編輯:湯梓紅
-
開源
+關注
關注
3文章
3514瀏覽量
43210 -
語言模型
+關注
關注
0文章
556瀏覽量
10556 -
OpenVINO
+關注
關注
0文章
111瀏覽量
371
原文標題:如何在 LangChain 中調用 OpenVINO? 加速大語言模型
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于OpenVINO和LangChain構建RAG問答系統

利用OpenVINO和LlamaIndex工具構建多模態RAG應用

如何利用LLM做多模態任務?
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型

LLM在各種情感分析任務中的表現如何

LangChain 0.1版本正式發布
探索LangChain:構建專屬LLM應用的基石
解鎖LLM新高度—OpenVINO? 2024.1賦能生成式AI高效運行
LLM大模型推理加速的關鍵技術
LangChain框架關鍵組件的使用方法
OpenVINO 2024.4持續提升GPU上LLM性能






 工商網監
工商網監
評論