") 【飛騰派4G版免費(fèi)試用】 第三章:抓取圖像,手動(dòng)標(biāo)注并完成自定義目標(biāo)檢測(cè)模型訓(xùn)練和測(cè)試
【飛騰派4G版免費(fèi)試用】 第三章:抓取圖像,手動(dòng)標(biāo)注并完成自定義目標(biāo)檢測(cè)模型訓(xùn)練和測(cè)試
抓取圖像,手動(dòng)標(biāo)注并完成自定義目標(biāo)檢測(cè)模型訓(xùn)練和測(cè)試
在第二章中,我介紹了模型訓(xùn)練的一般過程,其中關(guān)鍵的過程是帶有標(biāo)注信息的數(shù)據(jù)集獲取。訓(xùn)練過程中可以已有的數(shù)據(jù)集合不能滿足自己的要求,這時(shí)候就需要自己獲取素材并進(jìn)行標(biāo)注然后完成模型的訓(xùn)練,本章就介紹下,如何從網(wǎng)絡(luò)抓取素材并完成佩奇的目標(biāo)檢測(cè)。整個(gè)過程由如下幾個(gè)部分:
- 抓取素材,這里我使用下面的python腳本完成
#!/bin/python3
# 支持根據(jù)關(guān)鍵詞抓取百度圖片搜索的圖片
import requests
import os
import re
def get_images_from_baidu(keyword, page_num, save_dir):
# UA 偽裝:當(dāng)前爬取信息偽裝成瀏覽器
# 將 User-Agent 封裝到一個(gè)字典中
# 【(網(wǎng)頁右鍵 → 審查元素)或者 F12】 → 【Network】 → 【Ctrl+R】 → 左邊選一項(xiàng),右邊在 【Response Hearders】 里查找
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
# 請(qǐng)求的 url
url = 'https://image.baidu.com/search/acjson?'
n = 0
for pn in range(0, 30 * page_num, 30):
# 請(qǐng)求參數(shù)
param = {'tn': 'resultjson_com',
# 'logid': '7603311155072595725',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': '', # 這個(gè)參數(shù)沒公開,但是不可少
'pn': pn, # 顯示:30-60-90
'rn': '30', # 每頁顯示 30 條
'gsm': '1e',
'1618827096642': ''
}
request = requests.get(url=url, headers=header, params=param)
if request.status_code == 200:
print('Request success.')
request.encoding = 'utf-8'
# 正則方式提取圖片鏈接
html = request.text
image_url_list = re.findall('"thumbURL":"(.*?)",', html, re.S)
print(image_url_list)
# # 換一種方式
# request_dict = request.json()
# info_list = request_dict['data']
# # 看它的值最后多了一個(gè),刪除掉
# info_list.pop()
# image_url_list = []
# for info in info_list:
# image_url_list.append(info['thumbURL'])
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for image_url in image_url_list:
image_data = requests.get(url=image_url, headers=header).content
with open(os.path.join(save_dir, f'{n:06d}.jpg'), 'wb') as fp:
fp.write(image_data)
n = n + 1
if __name__ == '__main__':
keyword = '佩奇'
save_dir = keyword
page_num = 3
get_images_from_baidu(keyword, page_num, save_dir)
print('Get images finished.')
將抓取的圖片,篩選以后(剔除沒有佩奇的圖片)分為兩組數(shù)據(jù),訓(xùn)練集和檢驗(yàn)集。結(jié)構(gòu)是類似這樣的:
? tree peppa_jpg/ | head -n 10
peppa_jpg/
├── 000000.jpg
├── 000001.jpg
├── 000002.jpg
├── 000003.jpg
├── 000004.jpg
├── 000005.jpg
├── 000006.jpg
├── 000007.jpg
├── 000008.jpg
┏─?[red]?─?[22:07:44]?─?[0]
┗─?[~/Projects/ai_track_feiteng/demo3]
? tree peppa_valid_jpg/ | head -n 10
peppa_valid_jpg/
├── 000067.jpg
├── 000072.jpg
├── 000077.jpg
├── 000078.jpg
├── 000079.jpg
├── 000083.jpg
├── 000088.jpg
├── 000089.jpg
├── 000090.jpg
- 手工標(biāo)注素材,這里我使用的是 labelImg ,標(biāo)注的過程類似這樣:
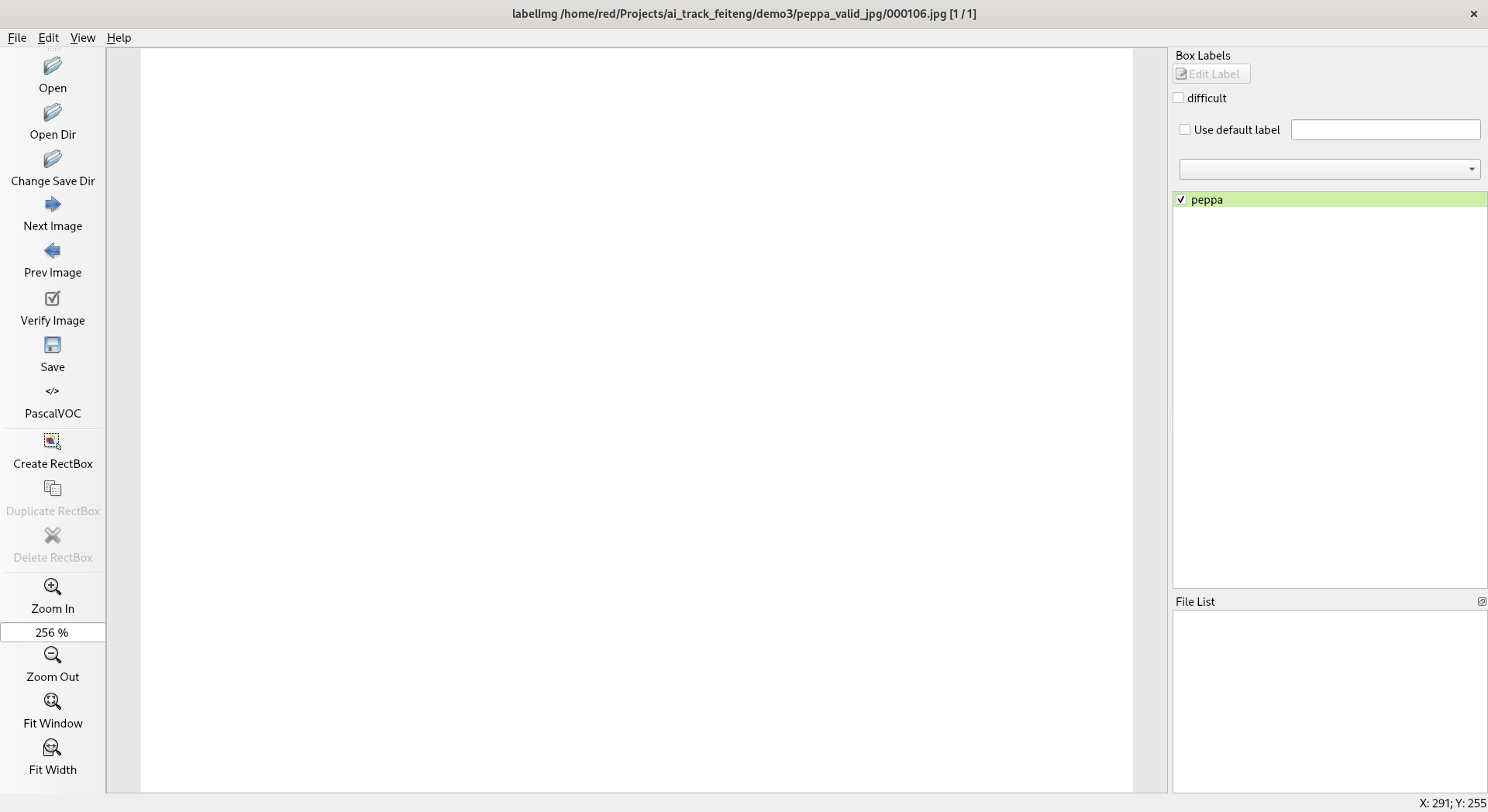
然后存儲(chǔ)為 PascalVOC 的 xml 文件。這里轉(zhuǎn)存之后是這樣的:
? tree peppa_xml/ | head -n 10
peppa_xml/
├── 000000.xml
├── 000001.xml
├── 000002.xml
├── 000004.xml
├── 000006.xml
├── 000007.xml
├── 000008.xml
├── 000010.xml
├── 000011.xml
┏─?[red]?─?[09:27:00]?─?[0]
┗─?[~/Projects/ai_track_feiteng/demo3]
? tree peppa_valid_xml/ | head -n 10
peppa_valid_xml/
├── 000067.xml
├── 000072.xml
├── 000077.xml
├── 000078.xml
├── 000079.xml
├── 000083.xml
├── 000088.xml
├── 000089.xml
├── 000090.xml
- 格式轉(zhuǎn)換為TFRecord 格式,這里我參考raccoon_dataset使用了兩個(gè)步驟,首先轉(zhuǎn)換為csv文件,然后再轉(zhuǎn)換為TFRecord 格式文件。這里我對(duì)其中涉及到的腳本進(jìn)行了微調(diào),其中 xml_to_csv.py 文件我改成下下面的內(nèi)容:
#!/bin/python3.8
import os
import sys
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main(xml_path, csv_file):
image_path = os.path.join(os.getcwd(), xml_path)
xml_df = xml_to_csv(image_path)
xml_df.to_csv(csv_file, index=None)
print('Successfully converted xml to csv.')
if len(sys.argv) < 2:
print("please input xml_path and out csv file")
else:
main(sys.argv[1], sys.argv[2])
這里通過命令:
? ./red_xml2csv.py peppa_xml/ peppa_jpg/pegga_train_labels.csv
Successfully converted xml to csv.
? ./red_xml2csv.py peppa_valid_xml/ peppa_valid_jpg/peppa_valid_labels.csv
Successfully converted xml to csv.
就可以分別將訓(xùn)練集和校驗(yàn)集轉(zhuǎn)換為相應(yīng)的 csv 文件并存儲(chǔ)到圖像數(shù)據(jù)集的目錄中,因?yàn)楹罄m(xù)會(huì)分別在對(duì)應(yīng)的目錄中執(zhí)行轉(zhuǎn)換為TFRecord格式的操作進(jìn)行。
執(zhí)行的命令分別是:
?python3.8 ../generate_tfrecord.py --csv_input=pegga_train_labels.csv --output_path=pegga_train.record
?python3.8 ../generate_tfrecord.py --csv_input=pegga_valid_labels.csv --output_path=pegga_valid.record
至此,就完成了從原始的圖像數(shù)據(jù),到含有標(biāo)注信息的TFRecord格式數(shù)據(jù)集的轉(zhuǎn)換。接下來就是訓(xùn)練和校驗(yàn)了。
- 訓(xùn)練和校驗(yàn)的過程和第二章一樣,只是數(shù)據(jù)集變了,這里只是展示下訓(xùn)練過程和模型導(dǎo)出過程的截圖。
模型訓(xùn)練:
模型導(dǎo)出:
模型到處完成后,我們會(huì)看到模型在如下目錄,以及其中的文件和從網(wǎng)上下載的TensorFlow2的模型壓縮包里面的結(jié)構(gòu)一樣。
我們可以對(duì)比看看,我從網(wǎng)上下載的efficientdet_d0_coco17_tpu-32模型中的內(nèi)容結(jié)構(gòu):
- 模型導(dǎo)出之后就是測(cè)試過程了,測(cè)試方法和第二章的方法一樣,我就直接附上我從網(wǎng)上下載的測(cè)試圖片和標(biāo)注以后的圖片:
希望本章可以為想上手通過機(jī)器學(xué)習(xí)進(jìn)行目標(biāo)檢測(cè)的伙伴提供一點(diǎn)幫助,下一章,我就準(zhǔn)備將模型部署到飛騰派進(jìn)行測(cè)試了,敬請(qǐng)期待。
-
模型
+關(guān)注
關(guān)注
1文章
3501瀏覽量
50149 -
目標(biāo)檢測(cè)
+關(guān)注
關(guān)注
0文章
223瀏覽量
15949 -
飛騰派
+關(guān)注
關(guān)注
2文章
9瀏覽量
387
發(fā)布評(píng)論請(qǐng)先 登錄
【飛騰派4G版免費(fèi)試用】第四章:部署模型到飛騰派的嘗試
【飛騰派4G版免費(fèi)試用】初步認(rèn)識(shí)飛騰派4G版開發(fā)板
【飛騰派4G版免費(fèi)試用】大家來了解飛騰派4G版開發(fā)板
【飛騰派4G版免費(fèi)試用】飛騰派開發(fā)板運(yùn)行Ubuntu系統(tǒng)
【飛騰派4G版免費(fèi)試用】來更多的了解飛騰派4G版開發(fā)板!
【飛騰派4G版免費(fèi)試用】飛騰派4G版開發(fā)板套裝測(cè)試及環(huán)境搭建
【飛騰派4G版免費(fèi)試用】4.手把手玩轉(zhuǎn)QT界面設(shè)計(jì)
【新品體驗(yàn)】飛騰派4G版基礎(chǔ)套裝免費(fèi)試用
【飛騰派4G版免費(fèi)試用】第三章:抓取圖像,手動(dòng)標(biāo)注并完成自定義目標(biāo)檢測(cè)模型訓(xùn)練和測(cè)試

【飛騰派4G版免費(fèi)試用】第四章:部署模型到飛騰派的嘗試






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論