") 語(yǔ)言模型的弱監(jiān)督視頻異常檢測(cè)方法
語(yǔ)言模型的弱監(jiān)督視頻異常檢測(cè)方法
引言
近年來(lái),弱監(jiān)督視頻異常檢測(cè)(WSVAD,VAD)因其廣闊的應(yīng)用前景而受到越來(lái)越多的關(guān)注,在WSVAD任務(wù)中,期望異常檢測(cè)器在僅提供視頻級(jí)注釋的情況下生成的精細(xì)化幀級(jí)異常置信度。然而當(dāng)前該領(lǐng)域的大多數(shù)研究遵循一個(gè)系統(tǒng)性的框架,即,首先是使用預(yù)先訓(xùn)練的視覺模型來(lái)提取幀級(jí)特征,例如C3D、I3D和ViT等,然后將這些特征輸入到基于多實(shí)例學(xué)習(xí)(MIL)的二分類器中進(jìn)行訓(xùn)練,最后一步是用預(yù)測(cè)的異常置信度檢測(cè)異常事件。盡管這類方案很簡(jiǎn)單,分類效果也很有效,但這種基于分類的范式未能充分利用跨模態(tài)關(guān)系,例如視覺語(yǔ)言關(guān)聯(lián)。
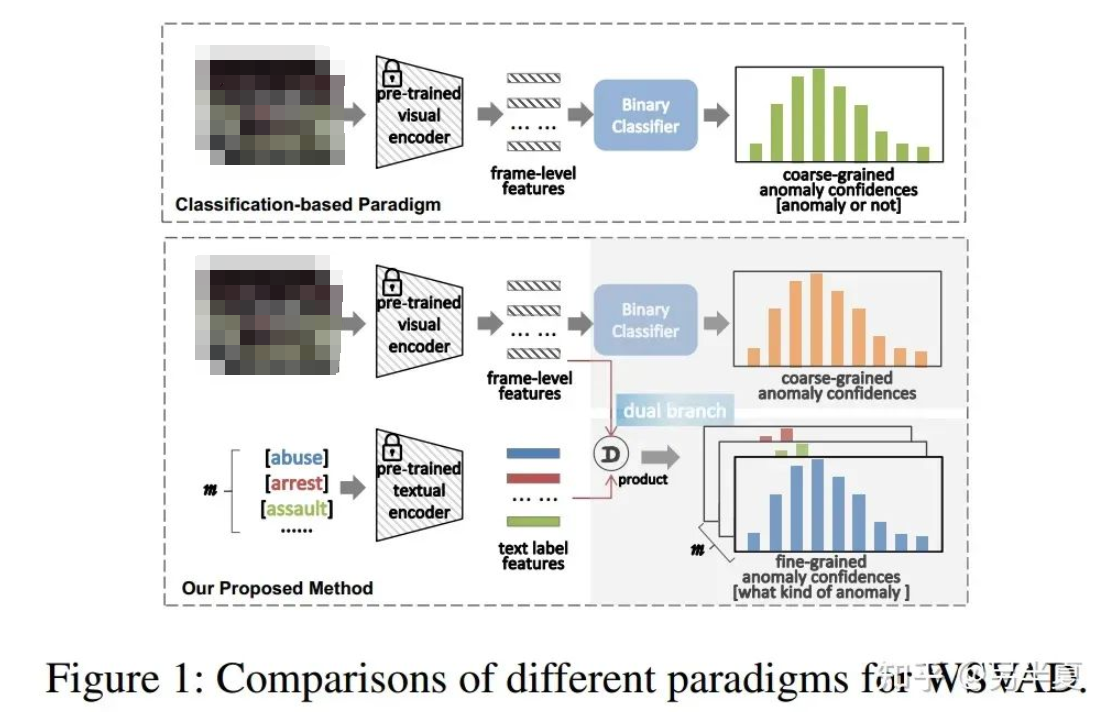
在過(guò)去的兩年里,我們見證了視覺語(yǔ)言預(yù)訓(xùn)練(VLP)模型取得了巨大進(jìn)展,例如CLIP,用于學(xué)習(xí)具有語(yǔ)義概念的廣義視覺表示。CLIP的主要思想是通過(guò)對(duì)比學(xué)習(xí)來(lái)對(duì)齊圖像和文本,即將圖像和匹配的文本描述在聯(lián)合特征空間拉近,同時(shí)分離不匹配的圖文對(duì)。鑒于CLIP的突破性的潛力,在CLIP之上構(gòu)建任務(wù)專用模型正成為新興的研究課題,并應(yīng)用于廣泛的視覺任務(wù),這些模型取得了前所未有的性能。最近,越來(lái)越多的視頻理解領(lǐng)域的工作利用CLIP構(gòu)建專用模型并解決各種視頻理解任務(wù)。基于此,我們認(rèn)為CLIP對(duì)于WSVAD任務(wù)同樣有巨大的潛力。
為了有效利用廣義知識(shí),使CLIP在WSVAD任務(wù)中充分發(fā)揮其潛力,基于WSVAD的特點(diǎn),有幾個(gè)關(guān)鍵的挑戰(zhàn)需要解決。(1)首先,如何進(jìn)行時(shí)序關(guān)系建模,捕獲上下文的依賴關(guān)系;(2)其次,如何利用視覺信息和文本信息聯(lián)系;(3)第三,如何在弱監(jiān)督下優(yōu)化基于CLIP的模型。
針對(duì)上述的問(wèn)題,我們提出了一種基于CLIP的WSVAD新范式,稱為VadCLIP。VadCLIP由幾個(gè)組件組成,包括一個(gè)局部-全局時(shí)序關(guān)系適配器(LGT Adapter),一個(gè)由視覺分類器和視覺語(yǔ)言對(duì)齊模塊組成的雙分支異常檢測(cè)器(Dual Branch)。我們的方法既可以利用傳統(tǒng)WSVAD的分類范式,又可以利用CLIP提供的視覺語(yǔ)言對(duì)齊功能,從而基于CLIP語(yǔ)義信息和兩個(gè)分支共同優(yōu)化以獲得更高的異常檢測(cè)性能。
總的來(lái)說(shuō),我們工作的主要貢獻(xiàn)是:
(1)我們提出了一個(gè)新的WSVAD檢測(cè)方法,即VadCLIP,它涉及雙分支網(wǎng)絡(luò),分別以視覺分類和語(yǔ)言-視覺對(duì)齊的方式檢測(cè)視頻異常。借助雙分支的優(yōu)勢(shì),VadCLIP實(shí)現(xiàn)了粗粒度(二分類)和細(xì)粒度(異常類別多分類)的WSVAD。據(jù)我們所知,VadCLIP是第一個(gè)將預(yù)先訓(xùn)練的語(yǔ)言視覺知識(shí)有效地轉(zhuǎn)移到WSVAD的工作。
(2) 我們提出的方法包括三個(gè)重要的組成部分,以應(yīng)對(duì)新范式帶來(lái)的新挑戰(zhàn)。LGT適配器用于從不同的角度捕獲時(shí)間依賴關(guān)系;設(shè)計(jì)了兩種提示機(jī)制來(lái)有效地使凍結(jié)的預(yù)訓(xùn)練模型適應(yīng)WSVAD任務(wù);MIL對(duì)齊實(shí)現(xiàn)了在弱監(jiān)督下對(duì)視覺文本對(duì)齊范式的優(yōu)化,從而盡可能地保留預(yù)先訓(xùn)練好的知識(shí)。
(3) 我們?cè)趦蓚€(gè)大規(guī)模公共基準(zhǔn)上展示了VadCLIP的性能和有效性,VadCLIP均實(shí)現(xiàn)了最先進(jìn)的性能。例如,它在XD Violence和UCFCrime上分別獲得了84.51%的AP和88.02%的AUC分?jǐn)?shù),大大超過(guò)了當(dāng)前基于分類的方法。
方法
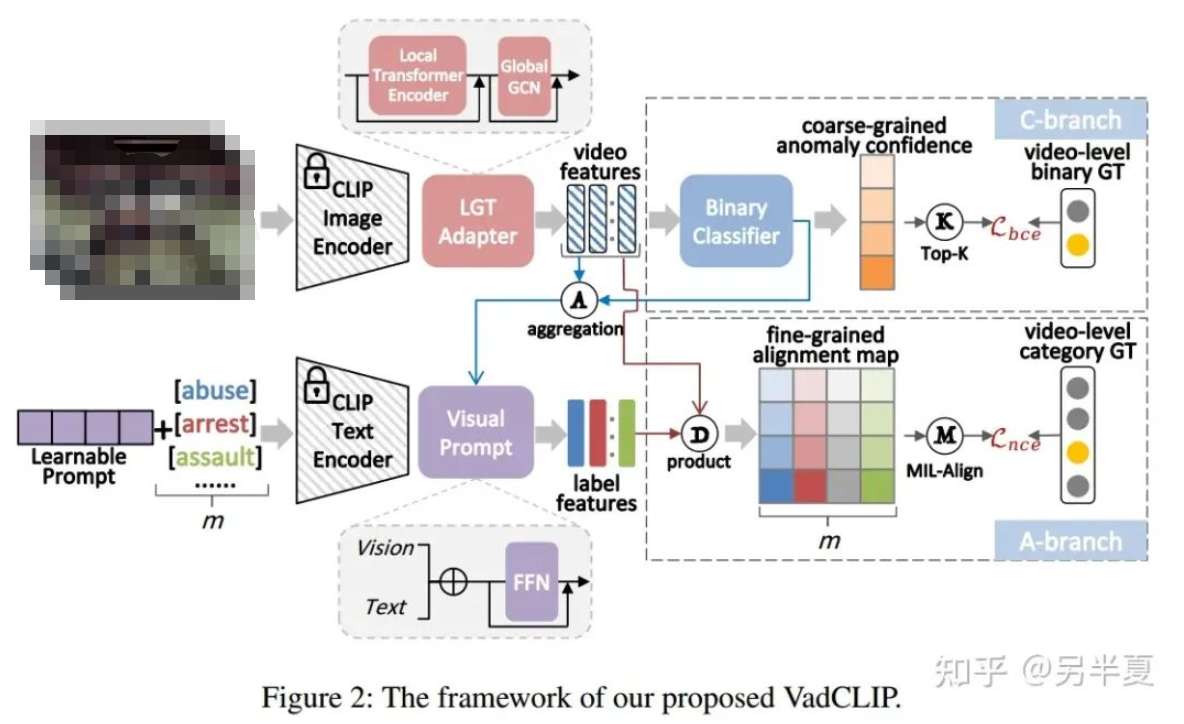
VadCLIP的模型結(jié)構(gòu)如圖所示,主要包括了三個(gè)部分,分別為局部全局時(shí)序關(guān)系適配器(LGT Adapter)、視覺二分類分支和視覺文本對(duì)齊細(xì)粒度分類分支。
LGT Adapter
LGT Adapter由局部關(guān)系Transformer和全局關(guān)系圖卷積串聯(lián)組成。考慮到常規(guī)的Transformer在長(zhǎng)時(shí)視頻時(shí)序關(guān)系建模時(shí)冗余信息較多、計(jì)算復(fù)雜度較高,我們改進(jìn)了局部Transformer的mask,從時(shí)序上將輸入視頻幀特征分割為多個(gè)等長(zhǎng)塊,令自注意力計(jì)算局限于塊內(nèi),減少了冗余信息建模,降低計(jì)算復(fù)雜度。
為了進(jìn)一步捕獲全局時(shí)間依賴性,我們?cè)诰植磕K之后引入了一個(gè)輕量級(jí)的圖卷積模塊,由于其在WSVAD任務(wù)中得到廣泛采用,性能已經(jīng)被證明,我們采用GCN來(lái)捕獲全局時(shí)間依賴關(guān)系。根據(jù)之前的工作,我們使用GCN從特征相似性和相對(duì)距離的角度對(duì)全局時(shí)間依賴性進(jìn)行建模,可以總結(jié)如下:
特征相似性分支通過(guò)計(jì)算兩幀之間的特征的余弦相似度生成GCN鄰接矩陣:

雙分支結(jié)構(gòu)
與之前的其他WSVAD工作不同,我們的VadCLIP包含雙分支,除了傳統(tǒng)的異常二分類分支之外,我們還引入了一種新穎的視覺-文本對(duì)齊分支。二分類分支和傳統(tǒng)的WSVAD工作類似,使用一個(gè)帶有殘差連接的FFN和二分類器,直接計(jì)算經(jīng)過(guò)時(shí)序關(guān)系建模的視覺特征的幀級(jí)別異常置信度。
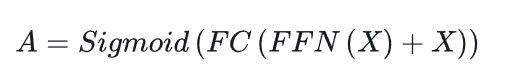
而在視覺文本對(duì)齊分支中,文本標(biāo)簽,例如虐待、暴亂、打架等,不再被編碼為一個(gè)one-hot向量,相反,它們被凍結(jié)參數(shù)的CLIP文本編碼器編碼為一個(gè)類嵌入向量,因?yàn)槲谋揪幋a器可以為視頻異常檢測(cè)提供語(yǔ)言知識(shí)。然后,我們計(jì)算類嵌入和幀級(jí)視覺特征之間的匹配余弦相似度,這類似于CLIP。在視覺文本對(duì)齊分支中,每個(gè)輸入文本標(biāo)簽代表一類異常事件,從而自然地實(shí)現(xiàn)了細(xì)粒度的WSVAD。

損失函數(shù)

實(shí)驗(yàn)結(jié)果
對(duì)比結(jié)果
表1和表2展示了在兩個(gè)常用的WSVAD數(shù)據(jù)集UCF-Crime和XD-Violence中,我們的方法和之前的工作的對(duì)比結(jié)果,為了保證公平,上述列出結(jié)果的工作均使用CLIP特征進(jìn)行重新訓(xùn)練,可以看出我們的方法在兩個(gè)數(shù)據(jù)集中相較之前的工作有較大的提升。
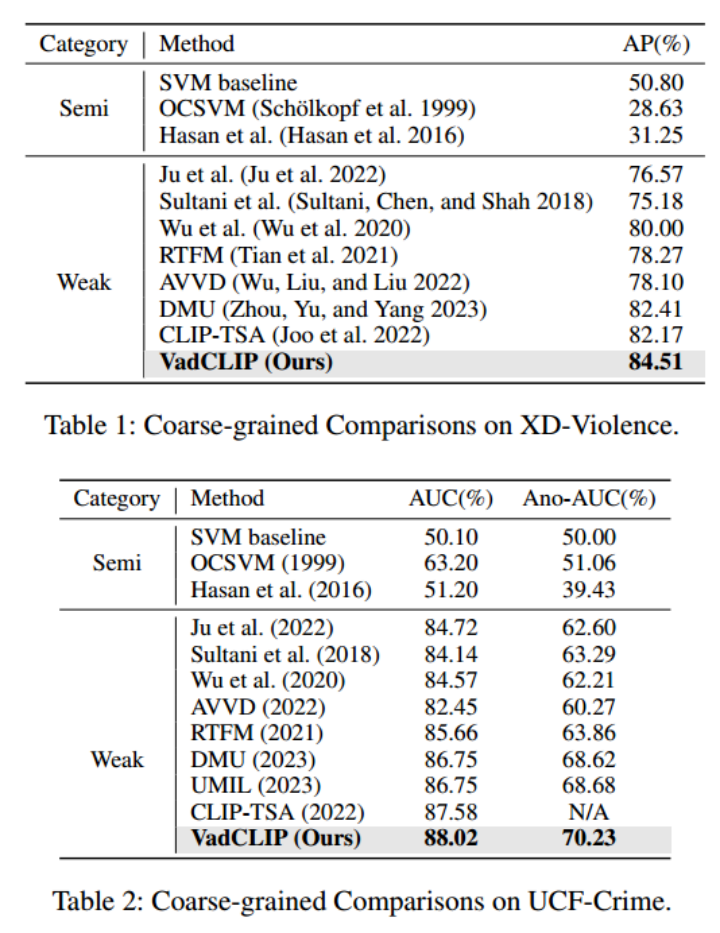
表3和表4展示了使用了細(xì)粒度多類別標(biāo)簽進(jìn)行異常檢測(cè),且計(jì)算幀mAP@IOU結(jié)果的情況,可以看出我們的方法在進(jìn)行細(xì)粒度多分類異常檢測(cè)時(shí)也有明顯的提升。
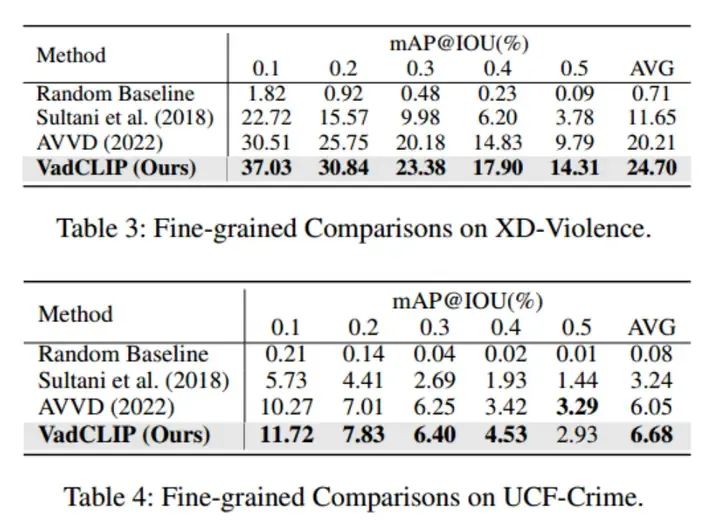
上圖分別展示了幀級(jí)別粗粒度異常檢測(cè)可視化結(jié)果和細(xì)粒度多分類異常檢測(cè)結(jié)果。
總結(jié)
在這項(xiàng)工作中,我們提出了一種新的范式VadCLIP,用于弱監(jiān)督視頻異常檢測(cè)。為了有效地將預(yù)訓(xùn)練的知識(shí)和視覺語(yǔ)言關(guān)聯(lián)從凍結(jié)的CLIP遷移到WSVAD任務(wù),我們首先設(shè)計(jì)了一個(gè)LGT適配器來(lái)增強(qiáng)時(shí)間建模的能力,然后設(shè)計(jì)了一系列提示機(jī)制來(lái)提高通用知識(shí)對(duì)特定任務(wù)的適應(yīng)能力。最后,我們?cè)O(shè)計(jì)了MIL對(duì)齊操作,以便于在弱監(jiān)督下優(yōu)化視覺語(yǔ)言對(duì)齊。我們通過(guò)和最先進(jìn)的工作對(duì)比和在兩個(gè)WSVAD基準(zhǔn)數(shù)據(jù)集上的充分消融,驗(yàn)證了VadCLIP的有效性。未來(lái),我們將繼續(xù)探索視覺語(yǔ)言預(yù)訓(xùn)練知識(shí),并進(jìn)一步致力于開放集VAD任務(wù)。
審核編輯:黃飛
-
適配器
+關(guān)注
關(guān)注
9文章
2043瀏覽量
69424 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10709 -
Clip
+關(guān)注
關(guān)注
0文章
32瀏覽量
6997
原文標(biāo)題:AAAI 2024 | VadCLIP: 首個(gè)基于視覺-語(yǔ)言模型的弱監(jiān)督視頻異常檢測(cè)方法
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于transformer和自監(jiān)督學(xué)習(xí)的路面異常檢測(cè)方法分享

基于隱馬爾可夫模型的視頻異常檢測(cè)模型
基于稀疏隨機(jī)森林模型的用電側(cè)異常行為檢測(cè)
基于健壯多元概率校準(zhǔn)模型的全網(wǎng)絡(luò)異常檢測(cè)
云模型的網(wǎng)絡(luò)異常流量檢測(cè)
智能監(jiān)控視頻異常事件檢測(cè)
實(shí)現(xiàn)強(qiáng)監(jiān)督和弱監(jiān)督學(xué)習(xí)網(wǎng)絡(luò)的協(xié)同增強(qiáng)學(xué)習(xí)

如何使用獨(dú)立子空間分析實(shí)現(xiàn)不良視頻的檢測(cè)方法
集成流挖掘和圖挖掘的內(nèi)網(wǎng)異常檢測(cè)方法

融合零樣本學(xué)習(xí)和小樣本學(xué)習(xí)的弱監(jiān)督學(xué)習(xí)方法綜述

如何縮小弱監(jiān)督信號(hào)與密集預(yù)測(cè)之間的差距
基于視覺Transformer的監(jiān)督視頻異常檢測(cè)架構(gòu)進(jìn)行腸息肉檢測(cè)的研究
弱監(jiān)督學(xué)習(xí)解鎖醫(yī)學(xué)影像洞察力





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論