 ChatGLM3-6B在CPU上的INT4量化和部署
ChatGLM3-6B在CPU上的INT4量化和部署
作者:劉力 英特爾邊緣計算創新大使
ChatGLM3-6B 簡介
ChatGLM3 是智譜 AI 和清華大學 KEG 實驗室聯合發布的新一代對話預訓練模型。ChatGLM3-6B 是 ChatGLM3 系列中的開源模型,在填寫問卷進行登記后亦允許免費商業使用。
請使用命令,將 ChatGLM3-6B 模型下載到本地:
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
左滑查看更多
BigDL-LLM 簡介
BigDL-LLM 是開源,遵循 Apache 2.0 許可證,專門用于在英特爾的硬件平臺上加速大語言模型(Large Language Model, LLM)推理計算的軟件工具包。它是在原有的 BigDL 框架基礎上,為了應對大語言模型在推理過程中對性能和資源的高要求而設計的。BigDL-LLM 旨在通過優化和硬件加速技術來提高大語言模型的運行效率,減少推理延遲,并降低資源消耗。
BigDL-LLM 的主要特點包括:
1低精度優化:通過支持 INT4/INT5/INT8 等低精度格式,減少模型的大小和推理時的計算量,同時保持較高的推理精度。
2硬件加速:利用英特爾 CPU 集成的硬件加速技術,如 AVX(Advanced Vector Extensions)、VNNI(Vector Neural Network Instructions)和 AMX(Advanced Matrix Extensions)等,來加速模型的推理計算。
3使用方便:對于基于 Hugging Face Transformers API 的模型,只需修改少量代碼即可實現加速,使得開發者可以輕松地在其現有模型上應用 BigDL-LLM。
4性能提升:BigDL-LLM 可以顯著提高大語言模型在英特爾平臺上的運行速度,減少推理時間,特別是在處理大規模模型和復雜任務時。
5資源友好:通過優化模型運行時的資源使用,BigDL-LLM 使得大語言模型可以在資源受限的環境中也能高效運行,如普通的筆記本電腦或服務器。
使用 BigDL-LLM
量化并部署 ChatGLM3-6B
第一步,創建虛擬環境
請安裝 Anaconda,然后用下面的命令創建名為 llm 的虛擬環境:
conda create -n llm python=3.9 conda activate llm
左滑查看更多
第二步,安裝 BigDL-LLM
執行命令:
pip install --pre --upgrade bigdl-llm[all] -i https://mirrors.aliyun.com/pypi/simple/
左滑查看更多
第三步:運行范例程序
范例程序下載地址:
https://gitee.com/Pauntech/chat-glm3/blob/master/chatglm3_infer.py
import time
from bigdl.llm.transformers import AutoModel
from transformers import AutoTokenizer
CHATGLM_V3_PROMPT_FORMAT = "<|user|>
{prompt}
<|assistant|>"
# 請指定chatglm3-6b的本地路徑
model_path = "d:/chatglm3-6b"
# 載入ChatGLM3-6B模型并實現INT4量化
model = AutoModel.from_pretrained(model_path,
load_in_4bit=True,
trust_remote_code=True)
# 載入tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path,
trust_remote_code=True)
# 制作ChatGLM3格式提示詞
prompt = CHATGLM_V3_PROMPT_FORMAT.format(prompt="What is Intel?")
# 對提示詞編碼
input_ids = tokenizer.encode(prompt, return_tensors="pt")
st = time.time()
# 執行推理計算,生成Tokens
output = model.generate(input_ids,max_new_tokens=32)
end = time.time()
# 對生成Tokens解碼并顯示
output_str = tokenizer.decode(output[0], skip_special_tokens=True)
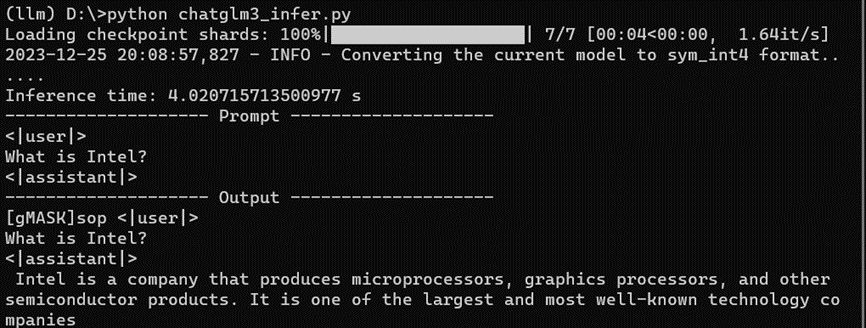
print(f'Inference time: {end-st} s')
print('-'*20, 'Prompt', '-'*20)
print(prompt)
print('-'*20, 'Output', '-'*20)
print(output_str)
左滑查看更多
運行結果,如下所示:
ChatGLM3-6B WebUI demo
請先安裝依賴軟件包:
pip install gradio mdtex2html streamlit -i https://mirrors.aliyun.com/pypi/simple/
左滑查看更多
下載范例程序:
https://gitee.com/Pauntech/chat-glm3/blob/master/chatglm3_web_demo.py
然后運行:
streamlit run chatglm3_web_demo.py
左滑查看更多
運行結果如下:
總結
BigDL-LLM 工具包簡單易用,僅需三步即可完成虛擬環境創建、BigDLL-LLM 安裝以及 ChatGLM3-6B 模型的 INT4 量化以及在英特爾 CPU 上的部署。
作者簡介
劉力,深圳市鉑盛科技有限公司的創始人。帶領團隊成功設計了多種計算機系統,并申請了多項專利和軟件著作,鉑盛科技為國家高新技術企業,深圳市專精特新企業。鉑盛通過整合算力和算法,打造軟硬件一體化的AIPC解決方案,目前產品已在工業控制、智能機器人、教育、醫療、金融等多個邊緣計算領域得到廣泛應用。
審核編輯:湯梓紅
-
英特爾
+關注
關注
61文章
10183瀏覽量
174167 -
cpu
+關注
關注
68文章
11054瀏覽量
216292 -
AI
+關注
關注
88文章
34589瀏覽量
276236 -
開源
+關注
關注
3文章
3634瀏覽量
43585
原文標題:三步完成 ChatGLM3-6B 在 CPU 上的 INT4 量化和部署 | 開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
CoolPi CM5運行ChatGLM-MNN大語言模型
NCNN+Int8+yolov5部署和量化

英偉達:5nm實驗芯片用INT4達到INT8的精度
ChatGLM-6B的局限和不足
ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜單位列榜首
類GPT模型訓練提速26.5%,清華朱軍等人用INT4算法加速神經網絡訓練

探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商業落地

Yolo系列模型的部署、精度對齊與int8量化加速
OpenVINO? 2023.2 發布:讓生成式AI在實際場景中更易用
三步完成在英特爾獨立顯卡上量化和部署ChatGLM3-6B模型
【AIBOX】裝在小盒子的AI足夠強嗎?

chatglm2-6b在P40上做LORA微調
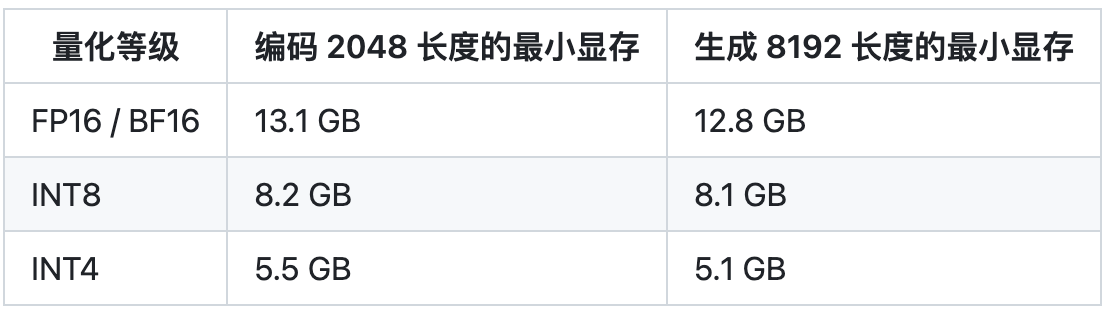
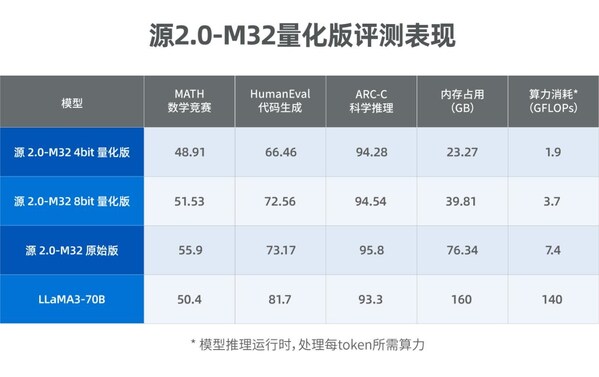
源2.0-M32大模型發布量化版 運行顯存僅需23GB 性能可媲美LLaMA3





 工商網監
工商網監
評論