 Harvard FairSeg:第一個用于醫學分割的公平性數據集
Harvard FairSeg:第一個用于醫學分割的公平性數據集
近年來,人工智能模型的公平性問題受到了越來越多的關注,尤其是在醫學領域,因為醫學模型的公平性對人們的健康和生命至關重要。高質量的醫學公平性數據集對促進公平學習研究非常必要。現有的醫學公平性數據集都是針對分類任務的,而沒有可用于醫學分割的公平性數據集,但是醫學分割與分類一樣都是非常重要的醫學AI任務,在某些場景分割甚至優于分類, 因為它能夠提供待臨床醫生評估的器官異常的詳細空間信息。在本文中,我們提出了第一個用于醫學分割的公平性數據集,名為Harvard-FairSeg,包含10,000個患者樣本。此外,我們提出了一種公平的誤差界限縮放方法,通過使用最新的Segment Anything Model(SAM),以每個身份組的上界誤差為基礎重新加權損失函數。為了促進公平比較,我們利用了一種新穎的評估公平性在分割任務的標準,叫做equity-scaled segmentation performance。通過全面的實驗,我們證明了我們的方法要么具有優越性,要么與最先進的公平學習模型在公平性能上相當。
在這里和大家分享一波我們ICLR 2024中稿的工作 “Harvard FairSeg: A Large-Scale Medical Image Segmentation Dataset for Fairness Learning Using Segment Anything Model with Fair Error-Bound Scaling”
在本次工作中, 我們提出了第一個研究醫療分割算法的公平性的大型數據集 并且提出了方法嘗試提升不同組別的公平性 (讓不同組別的準確率接近)。

文章: https://arxiv.org/pdf/2311.02189 代碼地址: https://github.com/Harvard-Ophthalmology-AI-Lab/Harvard-FairSeg 數據集網站: https://ophai.hms.harvard.edu/datasets/harvard-fairseg10k/ 數據集下載鏈接: https://drive.google.com/drive/u/1/folders/1tyhEhYHR88gFkVzLkJI4gE1BoOHoHdWZ Harvard-Ophthalmology-AI-Lab 致力于提供高質量公平性數據集 更多公平性數據集 請點擊lab的數據集主頁:https://ophai.hms.harvard.edu/datasets/
背景:
隨著人工智能在醫學影像診斷中的應用日益增多,確保這些深度學習模型的公平性并深入探究在復雜的現實世界情境中可能出現的隱藏偏見變得至關重要。遺憾的是,機器學習模型可能無意中包含了與醫學圖像相關的敏感屬性(如種族和性別),這可能影響模型區分異常的能力。這一挑戰促使人們在機器學習和計算機視覺領域進行了大量的努力,以調查偏見、倡導公平性,并推出新的數據集。
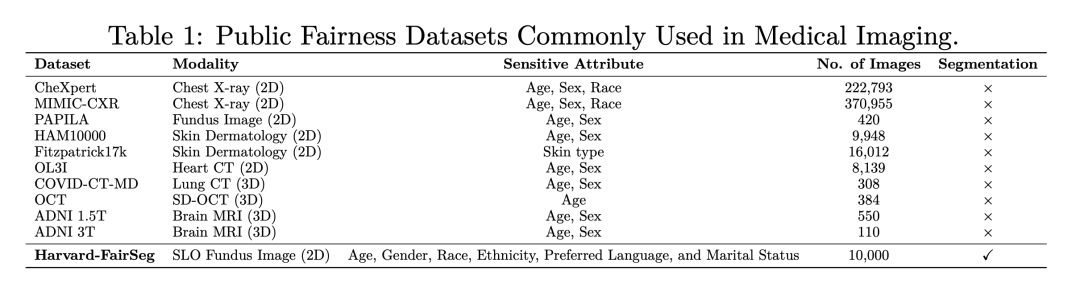
截至目前,只有少數公共公平性數據集被提出用于研究公平性分類,主要的是,這些數據集中的大多數都只是表格數據,因此不適合開發需要影像數據的公平計算機視覺模型。對計算機視覺公平性的缺失尤其令人關注,特別是考慮到依賴此類數據的深度學習模型的影響力日益增強。在醫學影像領域,只有少數數據集被用于公平學習。然而,這些數據集大多沒有專門為公平性建模而設計(目前僅有的醫療圖像數據集我們列在了table 1)。它們通常只包含有限范圍的敏感屬性,如年齡、性別和種族,因此限制了檢查不同人群公平性的范圍。此外,它們也缺乏全面的基準測試框架。更重要的是,盡管這些先前的數據集和方法為醫學分類提供了解決方案,但它們忽視了醫學分割這一更為關鍵的領域。
然而,為公平學習創建這樣一個新的大型數據集面臨著多重挑戰。首先,缺乏大規模、高質量的醫學數據以及手工像素級注釋,這些都需要大量勞動力和時間來收集和標注。其次,現有提升公平性的方法主要是為醫學分類設計的,當適應分割任務時,其性能仍然存疑。同樣不確定的是,分割任務中存在的不公平是否可以通過算法有效地緩解。最后,評估醫學分割模型公平性的評判標準 (evaluation metric)仍然難以捉摸。此外,將現有為分類設計的公平性指標適應到分割任務上也可能存在挑戰。
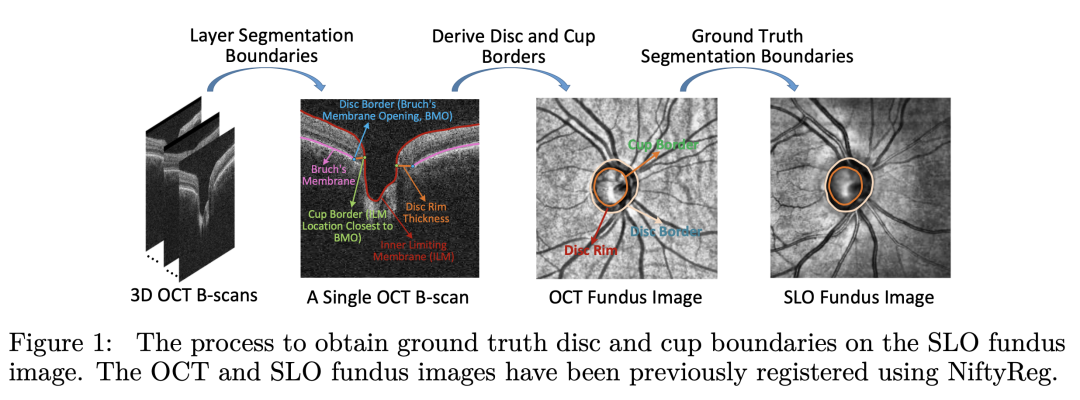
為了解決這些挑戰,我們提出了第一個大規模醫學分割領域的公平性數據集, Harvard-FairSeg。該數據集旨在用于研究公平性的cup-disc segmentation,從SLO眼底圖像中診斷青光眼,如圖1所示。青光眼是全球不可逆盲目的主要原因之一,在40-80歲年齡段的患病率為3.54%,大約影響了8000萬人。盡管其重要性,早期青光眼通常無癥狀,這強調了及時進行專業檢查的必要性。對cup-disc的準確分割對于醫療專業人員早期診斷青光眼至關重要。值得注意的是,與其他群體相比,黑人患青光眼的風險加倍,然而這一人群的分割準確率通常最低。這激勵我們整理一個數據集,以研究分割公平性問題我們提出的Harvard-FairSeg數據集的亮點如下:(1)醫學分割領域第一個公平性學習數據集。該數據集提供了SLO眼底成像數據的cup-disc分割;
(2)該數據集配備了從現實醫院臨床情景中收集的六種敏感屬性,用于研究公平性學習問題;
(3)我們在我們提出的新數據集上評估了多個SOTA公平性學習算法,并使用包括Dice和IoU在內的多種分割性能指標進行了評估。
如何獲得大量的高質量分割標注:
本研究中測試的對象來自于一家大型學術眼科醫院,時間跨度為2010年至2021年。本研究將發布三種類型的數據:(1)SLO眼底掃描圖像;(2)患者人口統計信息 包含了六種不同的屬性;(3)由OCT機器自動標注以及由專業醫療從業者手工評級的像素級標注如何獲得大量高質量分割標注一直是醫療分割的很重要分體。
我們新穎的通過把 cup 和disc區域的像素標注首先從OCT機器獲得,其中disc邊界在3D OCT中被分割為Bruch’s膜開口,由OCT制造商軟件實現,cup邊界被檢測為內限膜(ILM)與導致最小表面積的平面之間的交叉點和disc邊界在平面上的交叉點。大致上,cup邊界可以被認為是ILM上最靠近視盤邊界的位置,即被定義為Bruch’s膜開口。由于Bruch’s膜開口和內限膜與背景之間的高對比度,它們很容易被分割。因此因為OCT制造商軟件利用了3D信息,利用oct機器對cup和disc的分割通常是可靠的。相比之下,眼底照片上的2Dcup和disc分割可能因包括衰減的成像信號和血管阻塞等各種因素而具有挑戰性。然而,由于OCT機器相當昂貴且在初級保健中較少見,因此我們提議將這些注釋從3D OCT遷移到2D SLO眼底圖片,以在初級保健領域的早期青光眼篩查中產生更廣泛的影響。具體來說,我們首先使用NiftyReg工具將SLO眼底圖像與OCT衍生的眼底圖像(OCT眼底)對齊隨后,將NiftyReg的仿射度量應用于OCT眼底圖像的cup-disc掩碼,使其與SLO眼底圖像對齊。這一過程有效地產生了大量高質量的SLO眼底掩碼注釋,避免了勞動密集型的手工像素標注過程。值得注意的是,這種medical registration的操作在現實世界場景中展示了相當高的精確度,我們的經驗觀察表明,medical registration成功率大約為80%。在這一自動化過程之后,生成的掩碼經過嚴格審查,并由五名醫學專業人員小組手動評級,以確保cup-disc區域的精確標注,并排除位置錯誤的cup或disc掩碼和registration失敗的情況。
數據特征:我們的Harvard-FairSeg數據集包含來自10,000名受試者的10,000個樣本。我們將數據分為包含8,000個樣本的訓練集和包含2,000個樣本的測試集。數據集的平均年齡為60.3 ± 16.5歲。在該數據集中,包含了六個敏感屬性,用于深入的公平性學習研究,這些屬性包括年齡、性別、種族、民族、首選語言和婚姻狀況。在種族人口統計學上,數據集包括來自三個主要群體的樣本:亞洲人,有919個樣本;黑人,有1,473個樣本;白人,有7,608個樣本。在性別方面,女性占受試者的58.5%,其余為男性。民族分布以90.6%的非西班牙裔,3.7%的西班牙裔和5.7%的未說明。在首選語言方面,92.4%的受試者首選英語,1.5%首選西班牙語,1%首選其他語言,5.1%未確定。從婚姻狀況的角度來看,57.7%的人已婚或有伴侶,27.1%是單身,6.8%經歷過離婚,0.8%法律上分居,5.2%是喪偶,2.4%未說明。
我們的提升公平性的方法Fair Error-Bound Scaling:
我們假設獲得較小整體Dice損失的樣本組意味著模型對該特定組的樣本學習得更好,因此,這些樣本組需要較小的權重。相反,整體Dice損失較大的樣本組(即難處理的案例)可能導致更差的泛化能力并引起更多的算法偏差,這需要為這些樣本組分配較大的學習權重。因此,我們提出了一種新的公平誤差界限縮放方法,用于在訓練過程中縮放不同人群組之間的Dice損失。我們首先定義預測像素得分和真實目標之間的標準Dice損失表示為:
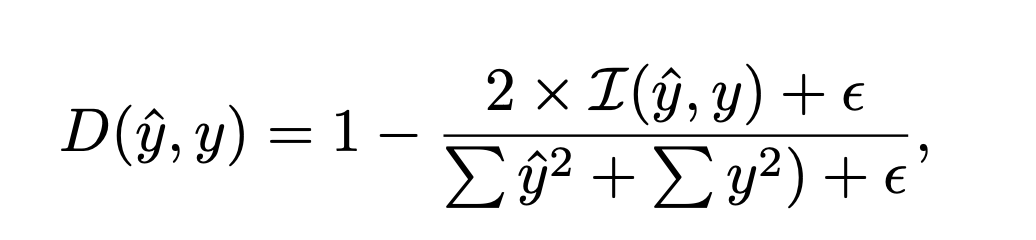
為了確保在不同屬性組之間的公平性,我們使用一種新穎的公平誤差界限縮放機制來增強上述Dice損失。損失函數:
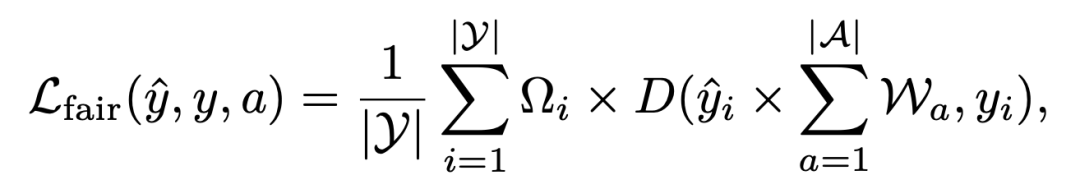
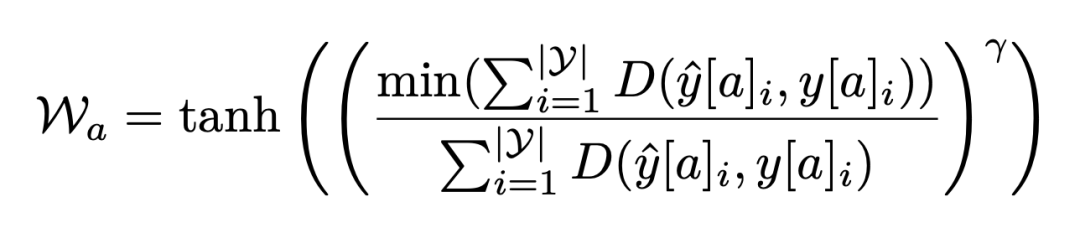
通過用這些屬性權重調節預測像素得分,這種損失確保不同屬性組在模型訓練過程中平衡地貢獻于損失函數,從而促進公平性。
用于評估公平分割準確性的metric:傳統的分割度量如Dice和IoU提供了對分割性能的洞察,但可能無法有效捕捉不同群體間的公平性。考慮到這一點,我們的目標是提出一種新的metric,既包括分割的準確性,也包括在不同群體間的公平性。這就產生了一個全面的視角,確保模型既準確又公平。
為了納入群體公平性,我們需要單獨評估群體的準確性。我們首先定義一個分割度量準確率差異?,如下所示:
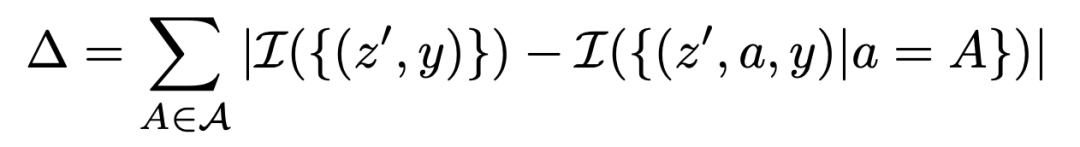
這里,?度量了每個群體的準確性與總體準確性的總體偏差。當所有群體達到類似的分割準確性時,它接近零。
當我們考慮不同群體間的公平性時,我們需要計算總體分割準確性與每個人口統計群體內的準確性之間的相對差異。基于這個,我們定義了Equity-Scaled Segmentation Performance(ESSP)度量,如下所定義:
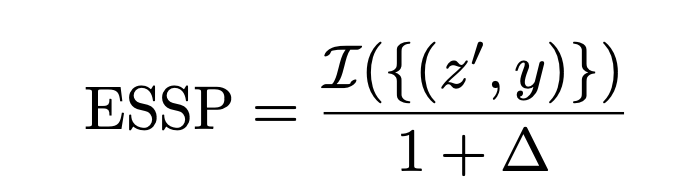
這種公式確保ESSP始終小于或等于I。隨著?減小(表示群體間的分割性能平等),ESSP趨于傳統分割metric。相反,較高的?表示群體間分割性能的更大差異,導致較低的ESSP得分。這種方法允許我們評估分割模型不僅在準確性(通過Dice、IoU等metric)上,而且在不同群體間的公平性上。這使得ESSP評分函數成為確保醫學成像任務中分割準確性和公平性的關鍵指標。這種metric可以和傳統的dice IoU拼到一起 成為ES-Dice和ES-IoU.
實驗:
我們選擇了兩個分割網絡作為backbone 。其中,我們選擇了最近推出的分割大模型 Segment Anything Model (SAM) 來實驗SOTA的分割準確性,另一個backbone我們選擇了TransUNet。
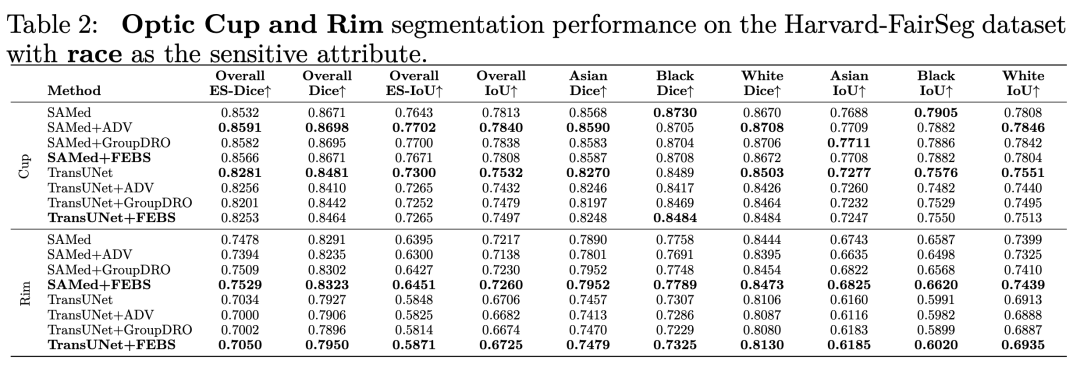
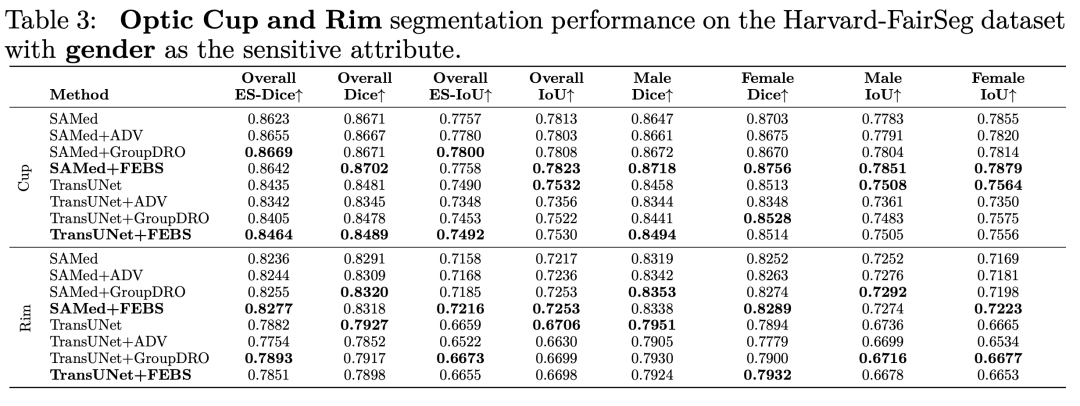
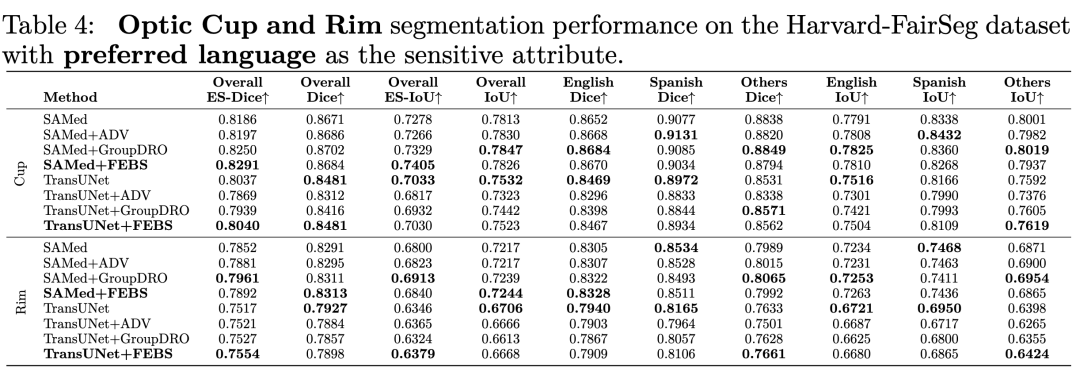
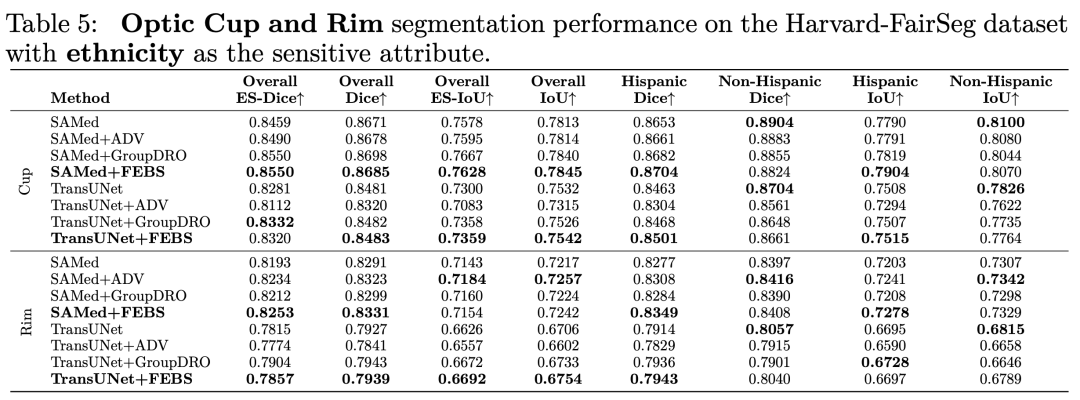
我們也利用了其他分割的metric例如 HD95 ASD 和NSD進行測試,下面是在種族上的結果:
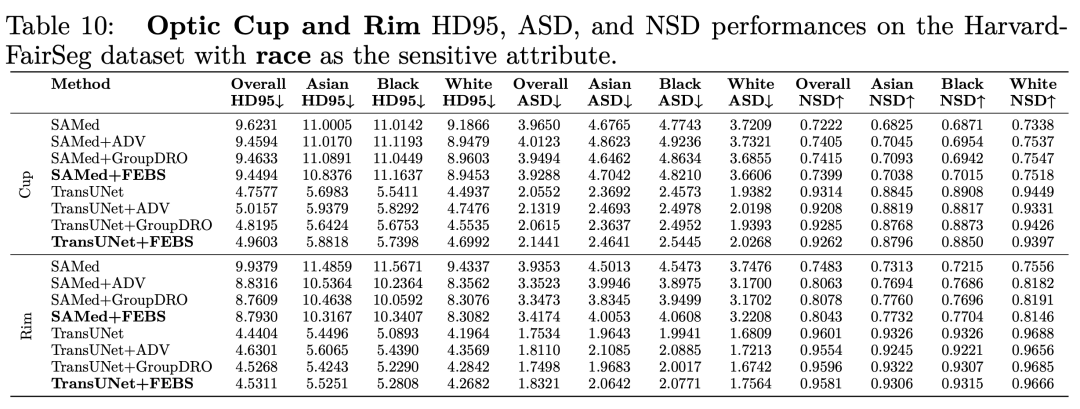
-
人工智能
+關注
關注
1804文章
48785瀏覽量
246893 -
模型
+關注
關注
1文章
3499瀏覽量
50066 -
數據集
+關注
關注
4文章
1223瀏覽量
25295
原文標題:ICLR 2024 首個!Harvard FairSeg:第一個用于醫學分割的公平性數據集
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何去獲取Arm Spinlock的公平性呢
深度學習在醫學圖像分割與病變識別中的應用實戰
高速TCP變種協議與DCCP協議的公平性研究
一種基于RTT公平性的TCP慢啟動算法
基于分層時間有色Petri網的支付協議公平性分析
一種提高IEEE 802.11吞吐量和公平性的自適應優化算法
改進DBTMA協議公平性方案
基于最大最小公平性的功率分配算法
云環境下能耗感知的公平性提升資源調度策略

云環境下公平性優化的資源分配方法
亞馬遜專注于AI的公平性研究
人工智能的算法公平性實現
基于X光圖片的實例分割垃圾數據集WIXRay (Waste Item X- Ray)
語義分割數據集:從理論到實踐
通用AI大模型Segment Anything在醫學影像分割的性能究竟如何?





 工商網監
工商網監
評論