 LLM中的大規模激活
LLM中的大規模激活
Massive Activations in Large Language Models摘要:我們在大型語言模型(LLM)中觀察到一種經驗現象-很少有激活表現出比其他激活大得多的值(例如,100,000倍)。我們稱之為大規模激活。首先,我們證明了廣泛存在的大規模激活在各種LLM和表征他們的位置。其次,我們發現它們的值在很大程度上保持不變,無論輸入,它們作為不可或缺的偏置項在LLM中。第三,這些大規模的激活導致注意概率集中到它們相應的標記上,并進一步導致自我注意輸出中的隱式偏差項。最后,我們還研究了Vision Transformers中的大規模激活。
https://arxiv.org/abs/2402.17762
Q1: 這篇論文試圖解決什么問題?
A: 這篇論文主要研究了大型語言模型(LLMs)中的一個現象,即在模型的隱藏狀態中存在極少數激活值(activations)遠大于其他激活值的情況,這些被稱為“massive activations”。論文試圖解決的問題包括:
1.現象的普遍性:作者首先展示了這種massive activations在不同LLMs中的普遍存在,并對其進行了特征定位。
2.功能角色:研究這些massive activations在LLMs中的功能角色,即它們是否對模型性能有實質性影響,還是僅僅是無關緊要的異常值。
3.與自注意力機制的關聯:探討massive activations與自注意力機制之間的關系,以及它們如何影響模型的注意力分布。
4.作為固定偏差的作用:分析massive activations如何在LLMs中充當固定但重要的偏差項,并探究這種偏差對模型性能的影響。
5.在視覺變換器(Vision Transformers, ViTs)中的應用:將研究擴展到ViTs,觀察是否也存在類似的massive activations現象,并分析其在ViTs中的作用。
6.消除massive activations的可能性:通過實驗,作者探索了通過在自注意力中顯式引入偏差項來消除massive activations的可能性。
總的來說,這篇論文試圖深入理解LLMs內部表示中massive activations的本質、功能和影響,以及它們如何與模型的自注意力機制相互作用。這些發現有助于我們更好地理解大型模型的內部工作機制,可能對改進模型設計和訓練方法具有重要意義。
Q2: 有哪些相關研究?
A: 論文中提到了與massive activations現象相關的一些研究領域和具體工作,包括:
自回歸Transformers的有趣屬性:
Timkey和Schijndel (2021) 觀察到GPT-2的倒數第二層中存在特征維度,其激活值高達3000,這些維度在評估表示相似性的標準度量中占主導地位。
Heimersheim和Turner (2023) 發現GPT-2中初始token的特征范數比其他token增長得更快。
Kovaleva等人 (2021) 和 Zhao等人 (2023) 展示了GPT-2和LLaMA2-13B中LayerNorm的異常權重的存在,并表明將它們設置為零會導致模型性能的災難性下降。
異常特征(Outlier Features):
Dettmers等人 (2022) 展示了LLMs中異常特征的存在,這些特征在大多數序列維度中具有較大的激活值。盡管massive activations和異常特征在表面上看似相似,但論文中討論了它們的根本區別,并表明massive activations不能歸因于異常特征的存在。
注意力集中模式(Attention Concentration Patterns):
Clark等人 (2019b)、Kovaleva等人 (2019) 和 Bondarenko等人 (2021) 發現BERT中的注意力傾向于集中在“separate”token [SEP]上。
Xiao等人 (2023b) 展示了LLMs將大部分注意力分配給起始詞token。
Darcet等人 (2023) 揭示了ViTs中注意力的異常現象。
Robinson等人 (2023) 發現ViTs中的稀疏激活模式,這些模式將注意力吸引到特定token上。
自注意力中的偏差(Biases in Self-Attention):
Namazifar等人 (2023) 提出了在自注意力的線性層中使用簡單的加性偏差項。
Su等人 (2021) 和 Press等人 (2021) 引入了位置偏差來編碼每個token的位置信息。
Evan (2023) 和 Bondarenko等人 (2023) 提出了具有手動設計的softmax操作符的偏差變體。
Vision Transformers(ViTs)中的massive activations:
Darcet等人 (2023) 提出了在標準ViTs中引入額外的可學習token(稱為register tokens),并展示了訓練帶有register tokens的ViTs可以導致平滑的注意力圖,從而提高了下游任務的性能。
這些相關研究為理解LLMs和ViTs的內部機制提供了背景知識,并且與本文研究的massive activations現象有著直接或間接的聯系。
Q3: 論文如何解決這個問題?
A: 論文通過以下步驟來解決大型語言模型(LLMs)中massive activations的問題:
現象觀察:首先,作者在不同的LLMs中觀察并確認了massive activations的普遍存在。他們通過可視化技術展示了這些激活值在特定特征維度上的異常高值。
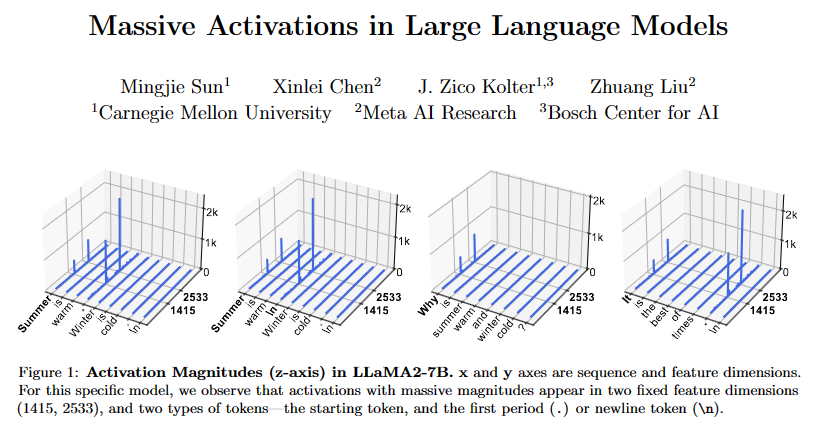
特征定位:作者確定了massive activations在模型的哪些層和特征維度上出現,以及它們與序列中的哪些token相關聯。他們發現這些激活通常出現在模型的起始token和分隔符token(如句點或換行符)。
功能分析:通過干預實驗(例如,將massive activations設置為零或其均值),作者分析了這些激活對模型性能的影響。他們發現,massive activations對模型性能至關重要,且其值在輸入變化時保持相對恒定,類似于固定偏差。
自注意力機制的深入研究:作者探討了massive activations如何影響自注意力機制,特別是它們如何導致注意力集中在與這些激活相關的token上。他們通過分解注意力輸出來展示這些token如何作為隱含的注意力偏差項。
顯式偏差的引入:為了消除massive activations,作者嘗試在自注意力中顯式引入偏差項。他們通過實驗發現,當在自注意力中添加額外的鍵(key)和值(value)嵌入作為顯式偏差時,模型不再需要學習massive activations。
視覺變換器(ViTs)的擴展研究:作者還將研究擴展到ViTs,觀察這些模型是否也存在類似的massive activations現象,并分析它們在ViTs中的作用。他們發現ViTs中的某些模型也表現出massive activations,并且這些激活在功能上類似于LLMs中的massive activations。
替代方法的探索:作者還探索了其他可能的方法來引入自注意力中的偏差,例如通過修改softmax操作符或添加額外的特征維度。
通過這些步驟,論文不僅揭示了massive activations在LLMs中的作用,還提出了可能的解決方案來調整或消除這些激活,從而可能改善模型的訓練和性能。
Q4: 論文做了哪些實驗?
A: 論文中進行了一系列實驗來研究大型語言模型(LLMs)中的massive activations現象,以及它們在模型中的作用和影響。以下是主要的實驗內容:
存在性驗證:作者在多個LLMs中觀察massive activations,包括LLaMA2-7B、LLaMA2-13B和Mixtral-8x7B等,通過可視化技術展示了這些激活在特定特征維度上的異常高值。
位置和特性分析:對于LLaMA2-7B模型,作者分析了massive activations在不同層和特征維度上的位置,以及它們與序列中特定token(如起始token和句點token)的關系。
干預實驗:作者通過將massive activations設置為零或其均值,來評估這些激活對模型性能的影響。實驗結果表明,massive activations對模型性能至關重要。
自注意力分析:作者研究了massive activations如何影響自注意力機制,特別是它們如何導致注意力集中在與這些激活相關的token上。他們通過分析注意力logits和注意力概率來展示這一點。
顯式偏差引入實驗:為了消除massive activations,作者嘗試在自注意力中引入顯式偏差項。他們訓練了GPT-2模型,并在自注意力中添加了額外的鍵(key)和值(value)嵌入作為顯式偏差。實驗結果顯示,這種方法可以消除massive activations。
Vision Transformers(ViTs)的實驗:作者在ViTs中也觀察到了massive activations現象,并分析了它們在ViTs中的作用。他們研究了CLIP、MAE和DINOv2等模型,并探討了register tokens在ViTs中的功能。
替代方法的探索:作者探索了其他可能的方法來引入自注意力中的偏差,例如通過修改softmax操作符或添加額外的特征維度,并評估了這些方法對massive activations的影響。
這些實驗不僅幫助作者深入理解了massive activations在LLMs中的作用,還為如何調整或消除這些激活提供了實驗依據。通過這些實驗,作者能夠提出新的見解和可能的改進方向。
Q5: 有什么可以進一步探索的點?
A: 論文中提出了一些可以進一步探索的點,包括但不限于:
massive activations的深入理解:
研究massive activations在不同類型和大小的LLMs中的普遍性和差異性。
探索massive activations在模型訓練過程中的動態變化,以及它們如何影響模型的學習過程。
massive activations與模型性能的關系:
分析massive activations對模型泛化能力、魯棒性和可解釋性的具體影響。
研究在不同的下游任務中,massive activations的作用和重要性。
自注意力機制的改進:
設計新的自注意力機制,以減少或消除對massive activations的依賴。
探索其他類型的顯式偏差項,以替代或增強massive activations的功能。
ViTs中的massive activations:
在更廣泛的ViTs模型和任務中研究massive activations現象。
分析register tokens在ViTs中的作用,以及它們與massive activations的關系。
模型壓縮和優化:
研究如何利用對massive activations的理解來優化模型的壓縮和加速。
探索在模型部署時,如何有效地處理massive activations以提高效率。
理論分析:
從理論角度分析massive activations的存在對模型表示能力的影響。
研究massive activations在模型的優化過程中所扮演的角色。
跨領域應用:
將對massive activations的研究擴展到其他類型的深度學習模型,如強化學習模型、序列生成模型等。
探索massive activations在多模態學習(如圖像和文本聯合處理)中的應用。
倫理和社會影響:
研究massive activations可能對模型的公平性、透明度和可解釋性帶來的影響。
探討如何在設計和部署LLMs時考慮到這些因素,以促進負責任的AI發展。
這些探索點不僅有助于提升我們對LLMs和ViTs內部機制的理解,還可能對模型設計、訓練策略和實際應用產生重要影響。
Q6: 總結一下論文的主要內容
A: 這篇論文主要研究了大型語言模型(LLMs)中的一個現象,即在模型的隱藏狀態中存在極少數激活值(activations)遠大于其他激活值的情況,這些被稱為“massive activations”。以下是論文的主要內容總結:
現象觀察:作者在多個LLMs中觀察到massive activations的存在,這些激活值在特定的特征維度上顯著高于其他激活值,且數量極少。
位置和特性分析:通過分析,作者發現massive activations通常出現在模型的起始token和分隔符token(如句點或換行符)上,且在模型的不同層中表現出不同的分布特征。
功能角色:實驗表明,massive activations在LLMs中扮演著類似固定偏差的角色,對模型性能至關重要。將它們設置為零會導致模型性能顯著下降,而將它們設置為均值則對性能影響不大。
與自注意力的關聯:作者發現massive activations與自注意力機制密切相關,它們導致注意力集中在相關token上,并在自注意力輸出中形成隱含的偏差項。
顯式偏差的引入:通過在自注意力中引入顯式偏差項,作者展示了可以消除massive activations的需要,這表明massive activations可能是在預訓練階段學習隱含偏差的一種方式。
Vision Transformers(ViTs)中的研究:作者還將研究擴展到ViTs,發現在ViTs中也存在類似的massive activations現象,這些激活在功能上類似于LLMs中的massive activations。
未來工作:論文提出了一些未來研究方向,包括更深入地理解massive activations在模型中的作用,探索如何在模型設計中利用或消除這些激活,以及它們在不同類型模型中的應用。
總的來說,這篇論文揭示了LLMs中massive activations的普遍性和重要性,以及它們如何影響模型的內部機制和性能。這些發現對于理解和改進大型模型的設計具有重要意義。
審核編輯:黃飛
-
大模型
+關注
關注
2文章
3046瀏覽量
3863
原文標題:每日論文速遞 | LLM中的大規模激活
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Veloce平臺在大規模SOC仿真驗證中的應用
大規模集成電路在信息系統中的廣泛應用
大規模特征構建實踐總結
大規模天線技術商用測試
大規模MIMO的利弊
大規模MIMO的性能
大規模FPGA設計中的多點綜合技術





 工商網監
工商網監
評論