") 英偉達(dá)AI服務(wù)器NVLink版與PCIe版有何區(qū)別?又如何選擇呢?
英偉達(dá)AI服務(wù)器NVLink版與PCIe版有何區(qū)別?又如何選擇呢?
在人工智能領(lǐng)域,英偉達(dá)作為行業(yè)領(lǐng)軍者,推出了兩種主要的GPU版本供AI服務(wù)器選擇——NVLink版(實(shí)為SXM版)與PCIe版。這兩者有何本質(zhì)區(qū)別?又該如何根據(jù)應(yīng)用場(chǎng)景做出最佳選擇呢?讓我們深入探討一下。
** NVLink版的服務(wù)器**
SXM架構(gòu),全稱Socketed Multi-Chip Module,是英偉達(dá)專(zhuān)為實(shí)現(xiàn)GPU間超高速互連而研發(fā)的一種高帶寬插座式解決方案。這一獨(dú)特的設(shè)計(jì)使得GPU能夠無(wú)縫對(duì)接于英偉達(dá)自家的DGX和HGX系統(tǒng)。這些系統(tǒng)針對(duì)每一代英偉達(dá)GPU(包括最新款的H800、H100、A800、A100以及之前的P100、V100等型號(hào))配備了特定的SXM插座,確保GPU與系統(tǒng)之間實(shí)現(xiàn)最高效率的連接。舉例來(lái)說(shuō),一張展示8塊A100 SXM卡在浪潮NF5488A5 HGX系統(tǒng)上并行工作的圖片,直觀展示了這種強(qiáng)大的整合能力。
在HGX系統(tǒng)主板上,8個(gè)GPU通過(guò)NVLink技術(shù)進(jìn)行了緊密耦合,構(gòu)建出前所未有的高帶寬互聯(lián)網(wǎng)絡(luò)。具體來(lái)說(shuō),每一個(gè)H100 GPU會(huì)連接至4個(gè)NVLink交換芯片,從而實(shí)現(xiàn)GPU之間的驚人傳輸速度——高達(dá)900 GB/s的NVLink帶寬。此外,每個(gè)H100 SXM GPU還通過(guò)PCIe接口與CPU相連,確保任意GPU產(chǎn)生的數(shù)據(jù)都能快速傳送到CPU進(jìn)行處理。
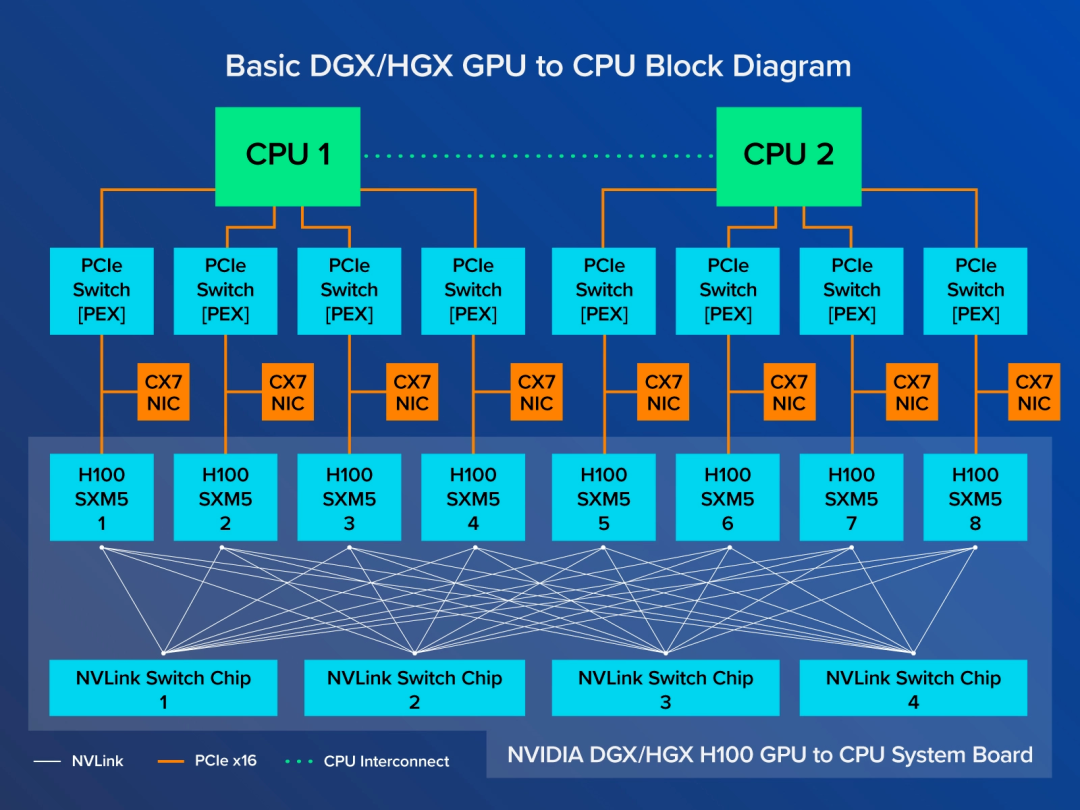
進(jìn)一步強(qiáng)化這種高性能互聯(lián)的是NVSwitch芯片,它把DGX和HGX系統(tǒng)板上的所有SXM版GPU串聯(lián)在一起,形成了一個(gè)高效的GPU數(shù)據(jù)交換網(wǎng)絡(luò)。未削減功能的A100 GPU可達(dá)到600GB/s的NVLink帶寬,而H100更是提升至900GB/s,即便是針對(duì)特定市場(chǎng)優(yōu)化過(guò)的A800、H800也能保持400GB/s的高速互連性能。

談及DGX和HGX的不同之處,NVIDIA DGX可視為出廠預(yù)裝且高度可擴(kuò)展的完整服務(wù)器解決方案,其在同等體積內(nèi)的性能表現(xiàn)堪稱業(yè)界翹楚。多臺(tái)NVIDIA DGX H800可通過(guò)NVSwitch系統(tǒng)輕松組合,形成包含32個(gè)乃至64個(gè)節(jié)點(diǎn)的超級(jí)集群SuperPod,足以應(yīng)對(duì)超大規(guī)模模型訓(xùn)練的嚴(yán)苛需求。而HGX則屬于原始設(shè)備制造商(OEM)定制整機(jī)方案。
** PCIe版的服務(wù)器**
相比于SXM版GPU的全域互聯(lián),PCIe版GPU的互聯(lián)方式更為傳統(tǒng)和受限。在這種架構(gòu)下,GPU僅僅通過(guò)NVLink Bridge與相鄰的GPU實(shí)現(xiàn)直接連接,如圖所示,GPU 1僅能直接連接至GPU 2,而非直接相連的GPU(如GPU 1與GPU 8)間的通信則必須通過(guò)較慢的PCIe通道來(lái)實(shí)現(xiàn),這過(guò)程中還需要借助CPU的協(xié)助。目前最先進(jìn)的PCIe標(biāo)準(zhǔn)提供的最大帶寬僅為128GB/s,遠(yuǎn)不及NVLink的超高帶寬。
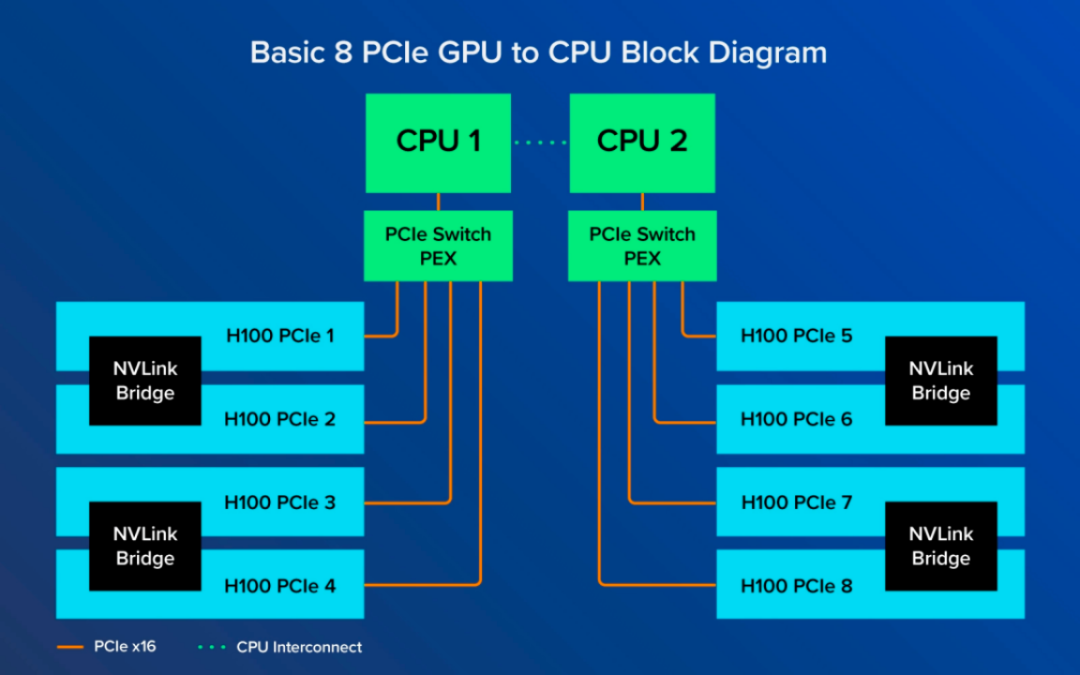
然而,盡管在GPU間互聯(lián)帶寬上PCIe版稍遜一籌,但單就GPU卡本身的計(jì)算性能而言,PCIe版與SXM版并無(wú)顯著差異。對(duì)于那些并不極端依賴于GPU間高速互連的應(yīng)用場(chǎng)景,如中小型模型訓(xùn)練、推理應(yīng)用部署等,GPU間互聯(lián)帶寬的高低并不會(huì)顯著影響整體性能。
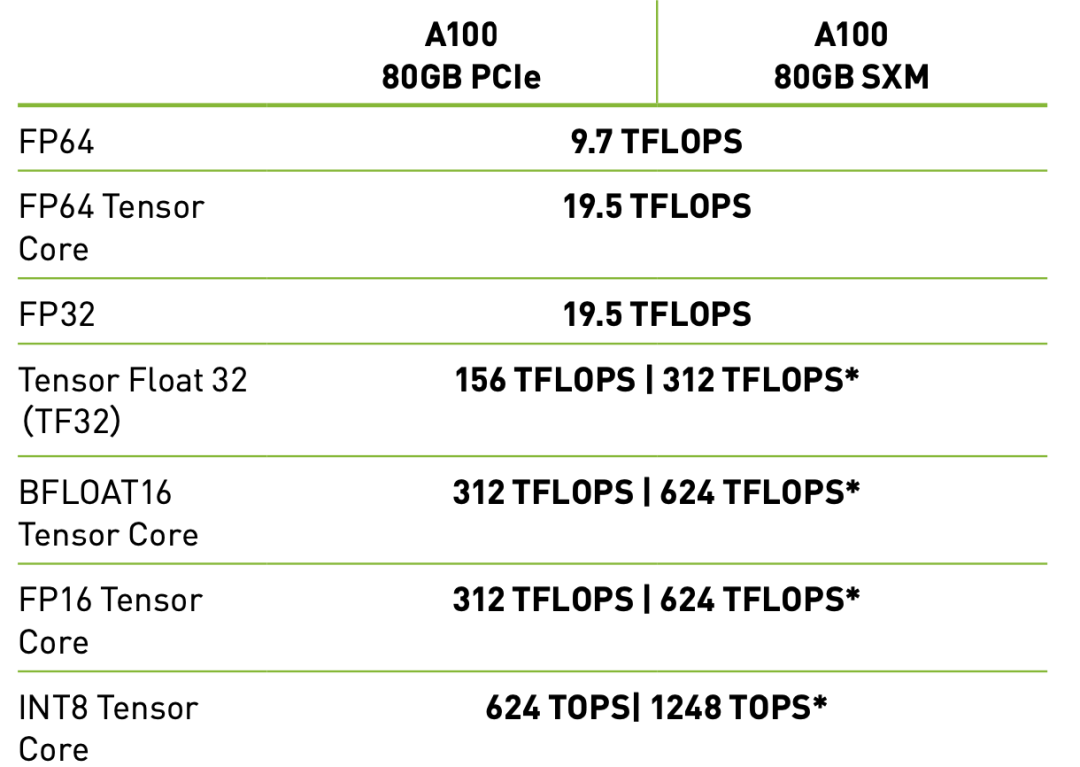
對(duì)比A100 PCIe與A100 SXM各項(xiàng)參數(shù)的圖表顯示兩者的計(jì)算核心性能并無(wú)太大差別。
** 該如何選擇?**
PCIe版GPU的優(yōu)勢(shì)主要體現(xiàn)在其出色的靈活性和適應(yīng)性。對(duì)于工作負(fù)載較小、追求GPU數(shù)量配置靈活性的用戶,PCIe版GPU無(wú)疑是個(gè)絕佳選擇。例如,某些GPU服務(wù)器僅需配備4張或者更少的GPU卡,此時(shí)采用PCIe版即可方便地實(shí)現(xiàn)服務(wù)器的小型化,可輕松嵌入1U或2U服務(wù)器機(jī)箱,同時(shí)降低了對(duì)數(shù)據(jù)中心機(jī)架空間的要求。
此外,在推理應(yīng)用部署環(huán)境中,我們經(jīng)常通過(guò)虛擬化技術(shù)將資源拆分和細(xì)粒度分配,實(shí)現(xiàn)CPU與GPU的一對(duì)一匹配。在這個(gè)場(chǎng)景下,PCIe版GPU因其較低的能耗(約300W/GPU)和普遍兼容性而受到青睞。而相比之下,SXM版GPU在HGX架構(gòu)中的功率消耗可能達(dá)到500W/GPU,雖然犧牲了一些能效比,卻換取了頂級(jí)的互聯(lián)性能優(yōu)勢(shì)。
綜上所述,NVLink版(SXM版)GPU與PCIe版GPU各自服務(wù)于不同的市場(chǎng)需求。對(duì)于對(duì)GPU間互連帶寬有著極高需求的大規(guī)模AI模型訓(xùn)練任務(wù),SXM版GPU憑借其無(wú)可匹敵的NVLink帶寬和極致性能,成為了理想的計(jì)算平臺(tái)。而對(duì)于那些重視靈活性、節(jié)約成本、注重適度性能和廣泛兼容性的用戶,則可以選擇PCIe版GPU,它尤其適合輕量級(jí)工作負(fù)載、有限GPU資源分配以及各類(lèi)推理應(yīng)用部署場(chǎng)景。
企業(yè)在選購(gòu)英偉達(dá)AI服務(wù)器時(shí),務(wù)必充分考慮當(dāng)前業(yè)務(wù)需求、未來(lái)發(fā)展規(guī)劃以及成本效益,合理評(píng)估兩種GPU 服務(wù)器版本的優(yōu)劣,以便找到最適合自身需求的解決方案。最終的目標(biāo)是在保證計(jì)算效能的同時(shí),最大化投資回報(bào)率,并為未來(lái)的拓展留足空間。
審核編輯:劉清
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5196瀏覽量
105526 -
PCIe
+關(guān)注
關(guān)注
16文章
1305瀏覽量
84478 -
交換芯片
+關(guān)注
關(guān)注
0文章
88瀏覽量
11259 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3902瀏覽量
92950 -
GPU芯片
+關(guān)注
關(guān)注
1文章
304瀏覽量
6099
原文標(biāo)題:英偉達(dá)AI服務(wù)器NVLink版與PCIe版的差異與選擇
文章出處:【微信號(hào):AI_Architect,微信公眾號(hào):智能計(jì)算芯世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論