") B200一經(jīng)面市,就只能做弟弟?Cerebras '巨無霸'能否逆襲成功?
B200一經(jīng)面市,就只能做弟弟?Cerebras '巨無霸'能否逆襲成功?
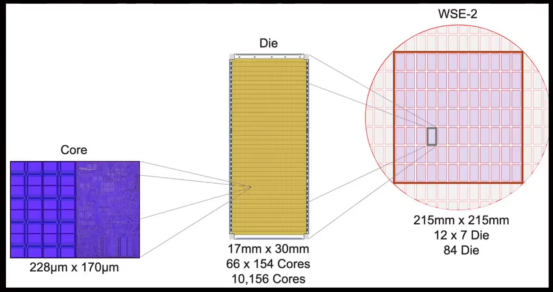
Cerebras Systems 發(fā)布全球最大芯片 WSE3 搭載4萬億個晶體管。與英偉達 B200 GPU 的2080億晶體管相比較,WSE3 的規(guī)模宛如巨人面對侏儒。其打破常規(guī),不再將一個晶圓切割為多個單獨芯片,而是巧妙地將一整個12英寸的晶圓轉(zhuǎn)化為一塊龐大芯片,總面積達到 46225 平方毫米,相當(dāng)于84個常規(guī)芯片組合在一起。

Cerebras 自2015年成立以來,堅持不懈地推出一系列 WSE 芯片,到如今第三代 WSE3,每一步都標(biāo)志著其對制程工藝的深化掌握,這次更是采用了5納米工藝,承臺積電的技術(shù)優(yōu)勢。WSE系列以“世界最大芯片”而馳名,專注于滿足AI大模型訓(xùn)練的高性能需求,同時具備出色的推理能力。在這一領(lǐng)域,Cerebras 不僅自立門戶,更與高通展開合作,以其推理芯片進一步增強WSE3功能范疇。
WSE3發(fā)布還伴隨一系列承載其強勁計算力的服務(wù)器產(chǎn)品——CS1、CS2和CS3,這些服務(wù)器產(chǎn)品由AMDCPU賦能,共同構(gòu)成高效的計算生態(tài),旨在加速現(xiàn)代AI研究及實用性能向前邁進。
憑借其獨特的設(shè)計理念和規(guī)模優(yōu)勢,WSE3預(yù)示著 AI 硬件技術(shù)的一次飛躍。異常強大的算力背后,是Cerebras對芯片工藝的極致追求與不被常規(guī)限制的創(chuàng)新膽識,WSE3正將這份精神通過每一次AI模型的訓(xùn)練和推理,傳遞至整個科技行業(yè)。
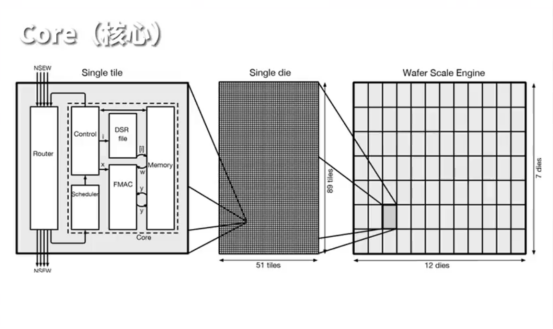
盡管有些人可能懷疑 WSE3 不過是一張巨型晶圓,但其真正的價值并不在于其體積,而在于其背后獨特的設(shè)計理念和架構(gòu)。WSE3 構(gòu)造包括84個區(qū)域,其中包含高達90萬個計算核心,每個區(qū)域內(nèi)含有超過1萬個核心。從架構(gòu)層面來看,由核心(Cores)、芯片單元(Die)以及晶圓(Wafer)共同構(gòu)成。
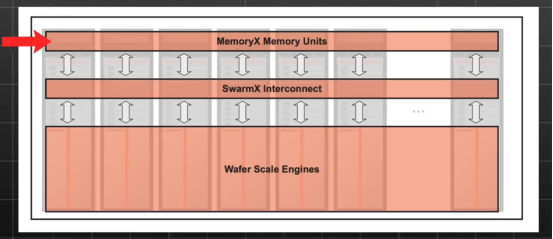
Cerebras的計算架構(gòu)大致可以劃分為WSE、SwarmX 和 MemoryX三個部分。在處理大模型訓(xùn)練時,MemoryX存儲設(shè)備儲存權(quán)重數(shù)據(jù),這些數(shù)據(jù)由DDR和Flash技術(shù)共同構(gòu)成,最大提供高達1200TB存儲空間。該設(shè)計意味著巨大數(shù)量級的模型參數(shù)可以一次性加載到設(shè)備中進行處理。在訓(xùn)練過程中,MemoryX上的權(quán)重數(shù)據(jù)將通過SwarmX傳輸至每個CS系統(tǒng)中的WSE,由WSE處理數(shù)據(jù)并完成向前傳播計算過程,生產(chǎn)出預(yù)測值。然后,通過損失函數(shù)計算出預(yù)測值與真實值間的梯度,用這些梯度進行反向傳播計算所有權(quán)重的梯度。計算得出的梯度數(shù)據(jù)隨后回到SwarmX,經(jīng)過匯總處理為全局梯度后送回MemoryX,MemoryX內(nèi)的計算單元會直接更新權(quán)重,為下一輪的訓(xùn)練做準(zhǔn)備。
Cerebras Systems把一個晶圓的全部晶體管都用上,并未按常規(guī)將其切割,而是構(gòu)建一個具有90萬個計算核心的密集網(wǎng)絡(luò)進行集中處理。松散耦合的計算和存儲設(shè)計讓 Cerebras 的 CS 系列服務(wù)器能夠輕松實現(xiàn)數(shù)據(jù)并行,不使用其他復(fù)雜的并行訓(xùn)練方法。Cerebras 這一獨特設(shè)計理念使其成為AI 訓(xùn)練領(lǐng)域的強勁競爭者。
深入探究Cerebras革命性 WSE 芯片會發(fā)現(xiàn),每一顆計算核心都擁有一塊48KB的SRAM存儲單元。令人驚訝的是48KB被巧妙劃分為八個6KB小區(qū)域,每個小區(qū)以32位寬數(shù)據(jù)通道進行操作,合起來就是一條256位寬數(shù)據(jù)高速公路。計算核心在每一個時鐘周期都能夠處理高達兩個64位的讀取通道以及一個64位的寫入通道,合計可達192位。
Cerebras的真正威力還在于它的分布式存儲與計算架構(gòu),使之擅長高效解決非結(jié)構(gòu)化的稀疏計算問題,尤其是那些需要處理海量零值或接近零值數(shù)據(jù)的場景。為此,WSE3 提供令人震撼的 21PB每秒的片上存儲帶寬,以及超乎想象的214PB每秒的網(wǎng)絡(luò)交互帶寬。
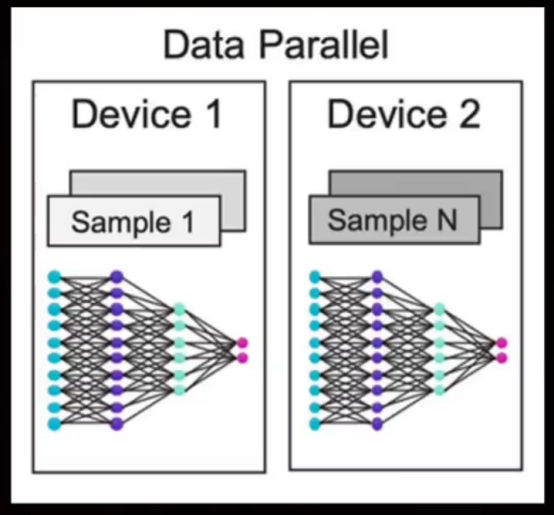
Cerebras的設(shè)計理念深入人心,無需切割晶圓,就將所有晶體管整合成一個緊密相連的網(wǎng)絡(luò),該網(wǎng)絡(luò)由高達90萬個計算核心組成,實現(xiàn)集中加工處理。與此同時,Cerebras系列的CS服務(wù)器得益于計算與存儲分離的創(chuàng)新設(shè)計,輕松實現(xiàn)數(shù)據(jù)并行處理,省去其他復(fù)雜并行訓(xùn)練方案的需要。這一設(shè)計不光為Cerebras贏得了與英偉達抗衡的實力,也為面對越來越龐大的模型規(guī)模——我們說的是達到萬億級參數(shù)——提供解決方案。在AI訓(xùn)練領(lǐng)域,Cerebras的 Wafer Scale Engine 設(shè)計無疑是它的巔峰時刻。
審核編輯 黃宇
-
芯片
+關(guān)注
關(guān)注
456文章
51283瀏覽量
427805 -
晶體管
+關(guān)注
關(guān)注
77文章
9782瀏覽量
138991 -
AI
+關(guān)注
關(guān)注
87文章
31711瀏覽量
270507
發(fā)布評論請先 登錄
相關(guān)推薦
北美運營商AT&T認證中的VoLTE測試項

NVIDIA DGX B200首次面向零售市場:配備8塊B200 GPU
onsemi LV/MV MOSFET 產(chǎn)品介紹 &amp;amp; 行業(yè)應(yīng)用

無人駕駛遇上&apos;超級WiFi&apos;,低速無人駕駛已成為了主要趨勢?

FS201資料(pcb &amp; DEMO &amp; 原理圖)
北美運營商AT&amp;amp;T認證入庫產(chǎn)品范圍名單相關(guān)
解讀北美運營商,AT&amp;amp;T的認證分類與認證內(nèi)容分享

特斯拉加碼AI布局:xAI將采購30萬塊英偉達B200芯片
英特爾任命Kevin O&apos;Buckley為代工部門負責(zé)人
智向未來,2024高通&amp;廣和通邊緣智能技術(shù)進化日成功舉辦

英偉達發(fā)布新一代AI芯片B200
英偉達發(fā)布性能大幅提升的新款B200 AI GPU
C程序中可用的存儲類有哪些?
深維科技-北京大學(xué)合作團隊在FPGA&apos;24布線加速競賽中奪得佳績!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論