") 盤點一下史上最全大語言模型訓練中的網絡技術
盤點一下史上最全大語言模型訓練中的網絡技術

1.引言
人工智能的基礎設施在大語言模型訓練和推理過程中發(fā)揮了關鍵的作用。隨著大語言模型規(guī)模不斷增大,其對計算和通信的需求也在不斷增加。高性能網絡是人工智能基礎設施的重要組成部分,引起了業(yè)界的廣泛關注。
大語言模型(Large Language Model)的擴展定律[40]和涌現能力[9]驅動大語言模型參數數量的持續(xù)增大,目前大語言模型的參數規(guī)模已經擴展到萬億級別,如此巨大的訓練任務遠超單個服務器的計算和存儲能力,需要通過構建包含大量服務器的高性能計算集群來共同完成這些任務。這些服務器節(jié)點之間通過高性能網絡互聯(lián),將工作負載分布在多個節(jié)點上加速訓練過程。因此,網絡性能直接決定了這些服務器節(jié)點間的通信效率[31,32],進而影響整個計算集群的吞吐量和性能。并且隨著模型規(guī)模持續(xù)擴大,其帶來的分布式訓練規(guī)模和通信量將會井噴式增長。
綜合目前業(yè)界的應用以及當前的技術現狀,大語言模型的訓練網絡主要面臨著以下重大挑戰(zhàn):
大規(guī)模并行擴展
大語言模型的訓練需要在數千甚至數萬個GPU上進行并行訓練,這給網絡組網帶來了巨大的挑戰(zhàn),需要設計高效的網絡拓撲結構和路由算法。
高通量和低延遲
大語言模型訓練過程中,不同的GPU之間需要交換大量的數據[23,24]。這可能會導致通信瓶頸[31,32],進而影響訓練的效率。尤其是對于大語言模型訓練任務而言,整體訓練進度的完成往往取決于最后一條消息的到達時間,這使得網絡尾延遲指標的重要性大大提高。
高昂的網絡成本
大語言模型訓練網絡的建設和維護成本非常高昂,需要探索新的方法來降低成本,使LLM訓練網絡更加經濟。傳統(tǒng)上分布式訓練系統(tǒng)網絡相關的成本[25]只占到整個基礎設施成本的10%左右,而大語言模型的網絡成本占比已經提高到總成本的20%。
高可靠和高可用
大語言模型的訓練周期比較長,計算節(jié)點和網絡故障都會導致整個訓練過程的重啟,進而導致整個訓練周期的延長,因此大語言模型的訓練對網絡的可靠性和可用性有著更高的要求。據統(tǒng)計,在某個千億大模型的訓練總時長中[11],真正用于模型訓練的時間只有50%,其他時間都用于處理故障以及進行斷點恢復。
本文進一步研究和探討網絡技術在大語言模型訓練中的應用。首先闡述了同構和異構網絡的特點與優(yōu)勢,然后針對網絡的關鍵技術點,綜述互聯(lián)協(xié)議、網絡拓撲、擁塞控制等技術在大語言模型訓練中的研究進展和成果。隨之介紹了業(yè)界知名的大語言模型訓練網絡,并討論了大語言模型訓練網絡的未來發(fā)展趨勢。
2.訓練網絡分類
大語言模型訓練網絡有很多種分類方法,比如英偉達根據訓練網絡的規(guī)模、支持的業(yè)務類型和用戶數量等維度,將網絡分為AI factory和AI cloud兩種類型。
本文從網絡技術類型角度將訓練網絡分為同構網絡和異構網絡兩種:
一、同構網絡以Google TPU為代表,通過使用ICI互聯(lián)協(xié)議,采用3D的環(huán)形網格網絡構建TPU集群;
二、異構網絡以英偉達 GPU訓練服務器為代表,網絡整體是由兩個子網絡組成,第一個子網絡(使用NVLINK或者其他自研的高速總線)用于服務器內部的加速器之間的互聯(lián),另一個子網絡(使用以太網、RoCE或者IB)用于服務器之間的高速互聯(lián)。
2.1.同構網絡
業(yè)界知名的同構網絡類型,其中之一就是Google TPU使用的自定義網絡,另外一個就是Intel的Gaudi2 全RoCE互聯(lián)方案。
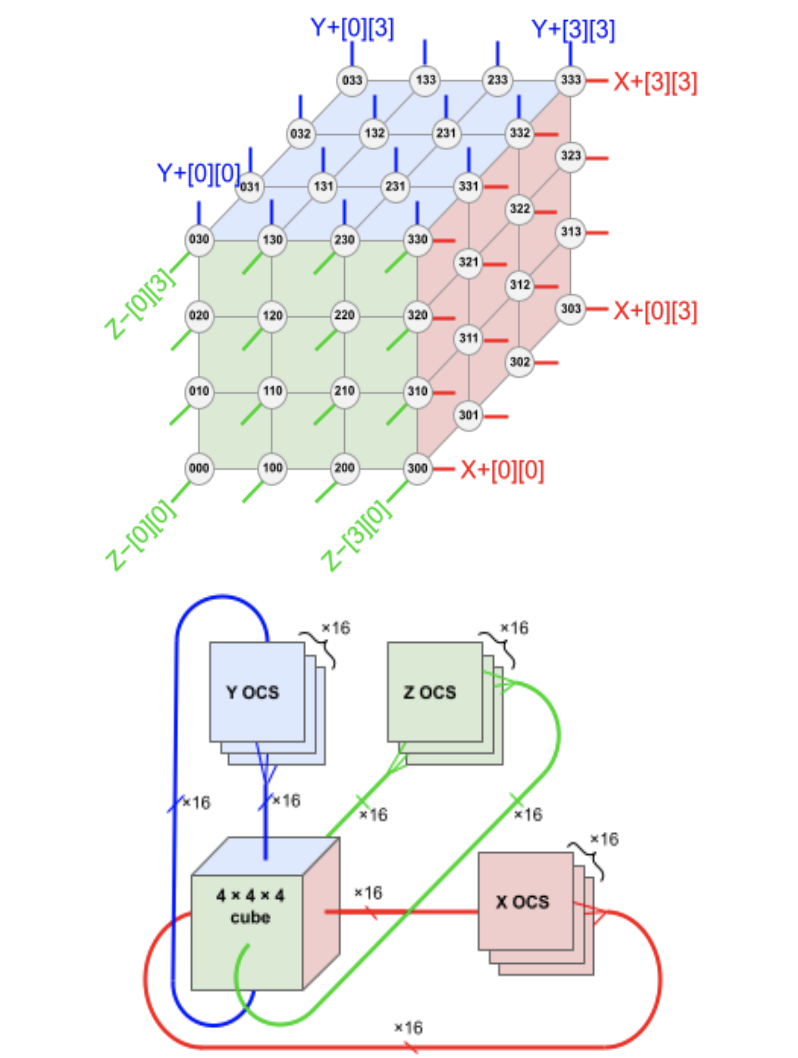
圖1 Google TPUV4 組網拓撲
Google TPUV4[3]使用自定義網絡協(xié)議ICI進行高速互聯(lián),ICI網絡是TPU集群專用網絡,在ICI網絡內部由64顆TPU和16顆CPU組成一組(即稱為一個TPU Slice),通過直連的銅質電纜連接在4*4*4的三維 Cube里面,而在這個ICI網絡之外就是OCS光學背板互連。Google SuperPod在AI工作負載方面具有性能和總擁有成本的優(yōu)勢,這得益于TPU從微架構到系統(tǒng)架構的整體設計,旨在協(xié)同特定模型和算法,以充分發(fā)揮出極致的并行性能和擴縮效益。
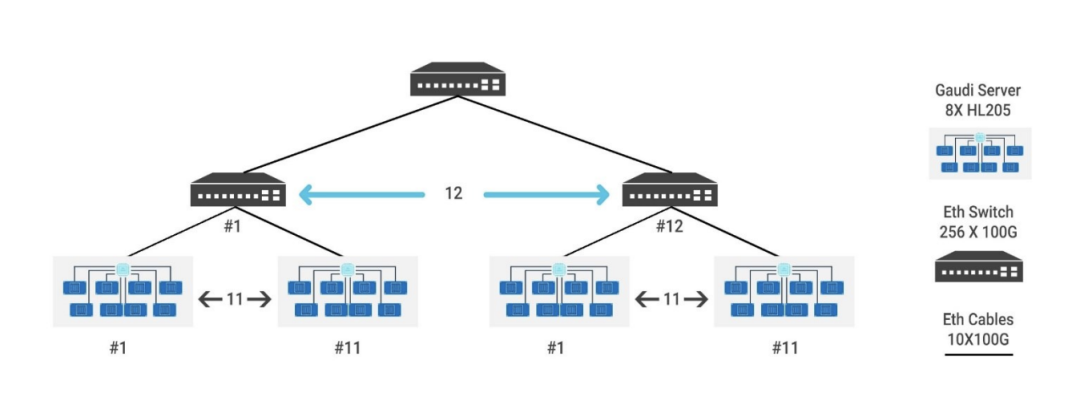
圖2 Intel Gaudi組網示意圖
Intel的Gaudi處理器[12,15]突破傳統(tǒng),采用了獨特的設計策略。不同于使用高性能總線進行節(jié)點內部互聯(lián),Gaudi直接在處理器內部集成了RoCE接口。例如,Gaudi2內部整合了21個100G RoCE接口。在HLS-1(類似于英偉達的DGX服務器)中,支持8塊Gaudi加速卡,每塊卡利用7個100G RoCE接口實現了八塊卡之間的全連接(all to all)互聯(lián)。此外,另外的14個100G RoCE接口用于實現HLS-1服務器之間的互聯(lián)。
2.2.異構網絡
以NVIDIA為代表的異構網絡組網模式,保證了系統(tǒng)的整體性能并降低系統(tǒng)組網成本。H100的GPU服務器[30]由8個搭載ConnectX-7 NIC的GPU組成,這些GPU可以通過連接到NVSwitch的高速NVLink互相通信,各個GPU通過每個方向上3600Gbps的NVLink連接到一組NVSwitch。服務器內的8個GPU可以通過其 400Gbps的ConnectX-7 NIC連接到外部交換機。
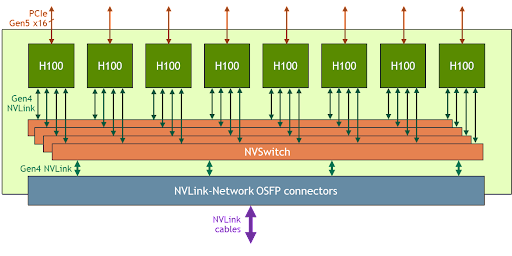
圖3 Nvidia DGX H100服務器
3.關鍵技術點
3.1.互聯(lián)協(xié)議
大語言模型網絡的互聯(lián)技術通常分為兩類,一類稱為總線互聯(lián)協(xié)議(典型總線包括NVLink、PCIE、CCIX、CXL等),用于加速芯片之間短距離、小規(guī)模和高通量互聯(lián);另一類稱為網絡互聯(lián)協(xié)議(典型網絡互聯(lián)技術包括RoCE、iWARP、infiniband等),用于服務器集群之間進行長距離、大規(guī)模的數據通信。
隨著總線和網絡技術的發(fā)展,這兩類技術已經出現了逐漸融合的趨勢,比如英偉達NVLink4.0已經可以支持256個GPU的互聯(lián),CXL在其規(guī)范中也提到將來支持機架間的互聯(lián)。
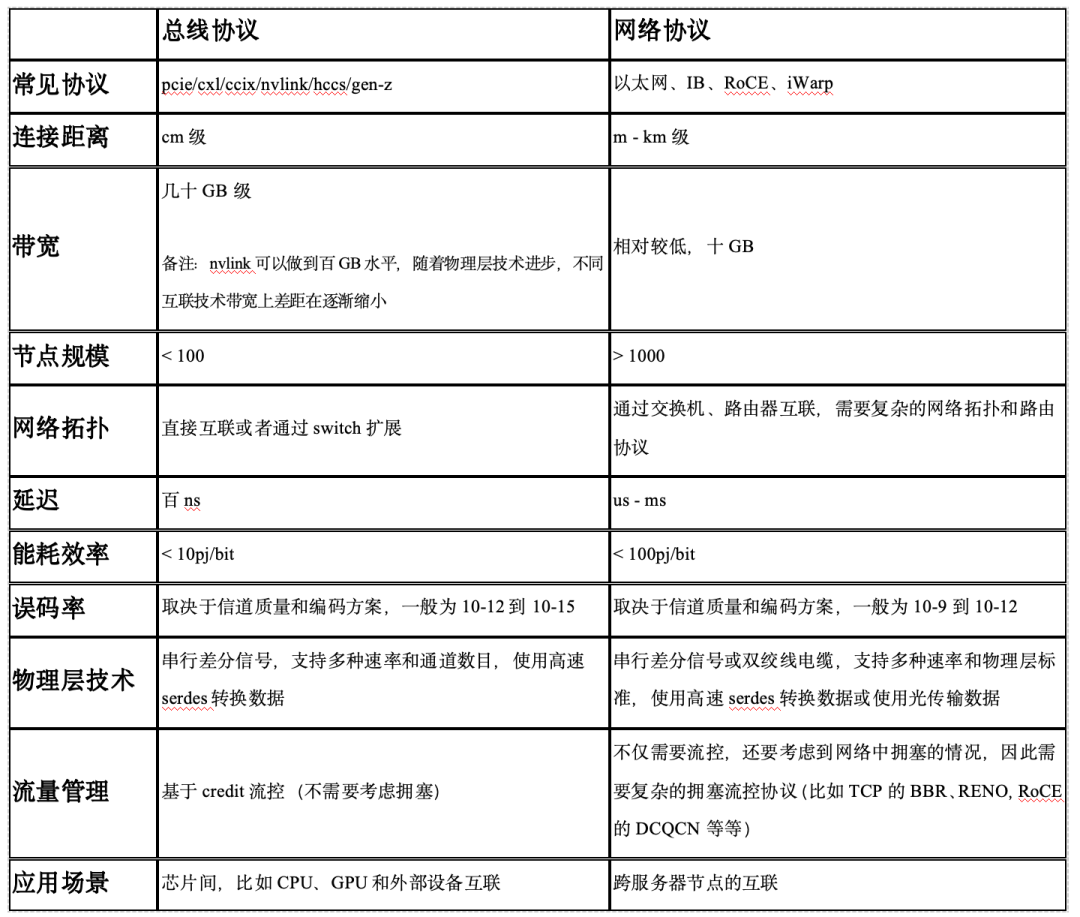
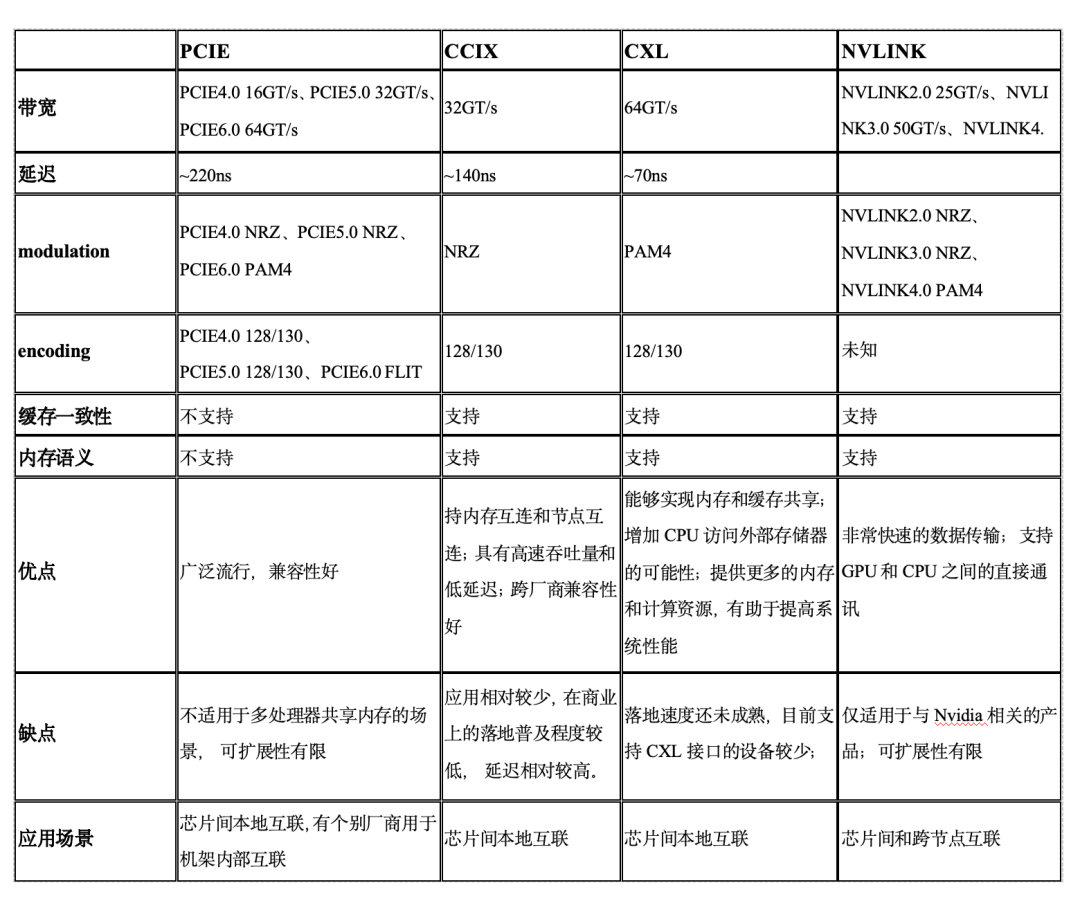
表1:互聯(lián)協(xié)議對比
3.1.1.總線互聯(lián)協(xié)議
常見的總線互聯(lián)協(xié)議包括英偉達的NVLink[14]、AMD的infinity fabric[63]、PCI-SIG組織發(fā)布的PCIE[64]和CXL聯(lián)盟推出的開放式互聯(lián)新標準CXL[62]。英偉達的NVLink是目前大模型訓練網絡中最具代表性的總線互聯(lián)協(xié)議,本章將以其為主線進行介紹。
NVLink于2014年3月的NVIDIA GTC 2014上發(fā)布,2016發(fā)布的P100是搭載NVLink的第一款產品,單個GPU具有160GB/s的帶寬,相當于PCIe Gen3 * 16帶寬的5倍。GTC 2017上發(fā)布的V100搭載的NVLink 2.0將GPU帶寬提升到了300GB/s,大約是PCIe的10倍,到了最新一代H100支持NVLink4.0,雙向帶寬更是提升到了900GB/s。

圖4 Nvidia NVLink路標
通過分析現有與NVLink協(xié)議相關的技術論文[6],可以得到以下結論:
1、在底層鏈路延遲方面(NVLink2.0 VS PCIE 3.0),NVLink只有PCIE延遲的55%;
2 、系統(tǒng)的延遲不僅取決于底層鏈路延遲,還與軟硬件的整體配合關系巨大。在reduce場景下,NVLink延遲意外高于PCIE協(xié)議(18us VS 14us),但是在Broadcast、reduce_scatter、all_gather場景下延遲更低,且不同通訊模式下NVLink延遲表現非常穩(wěn)定。
用于連接 GPU 服務器中的 8 個 GPU 的 NVLink 交換機也可以用于構建連接 GPU 服務器之間的交換網絡。Nvidia 在 2022 年的 Hot Chips 大會上展示了使用 NVswitch 架構連接 32 個節(jié)點(或 256 個 GPU)的拓撲結構。由于 NVLink 是專門設計為連接 GPU 的高速點對點鏈路,所以它具有比傳統(tǒng)網絡更高的性能和更低的開銷。
表2:總線協(xié)議對比
3.1.2.網絡互聯(lián)協(xié)議
表3:InfiniBand與RoCEv2技術特性對比
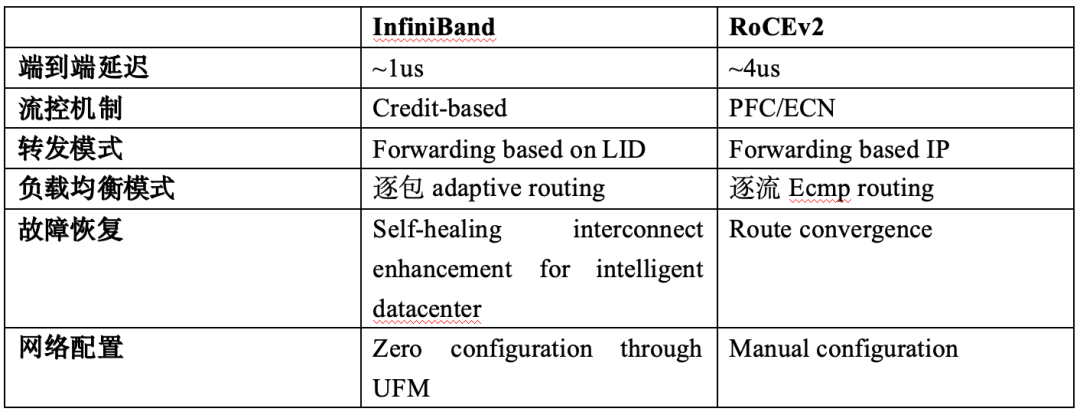
自1999年問世以來,InfiniBand(簡稱IB)[29,34,35]一直被視為高性能互聯(lián)的替代技術,在服務器、存儲和網絡基礎設施中得到廣泛應用。由于其高速率、低延遲和零包丟失的特點,IB長期在高性能計算、AI集群和數據中心領域處于應用的前沿地位。
IB協(xié)議秉持簡單高效設計理念,同時支持多種通信模式,通過基于信用的流量控制實現設備間的零丟包傳輸目標。IB交換機全面支持遠程直接內存訪問(RDMA),從而實現GPU間的直接內存互聯(lián)。然而,在架構和擴展能力方面,IB存在一定局限性。
相比之下,以太網應用范圍更廣,通過優(yōu)先級流量控制(PFC)等機制實現零丟包傳輸,并通過RoCEv2[26,27,28,33]實現了RDMA封裝傳輸。隨著技術的進步,以太網在大規(guī)模AI集群中替代IB的程度不斷增加。代表性的擁塞控制方案如DCQCN、HPCC等已得到廣泛應用,部分云服務商已經使用了規(guī)模超過32KGPU的以太網架構。
2023年7月,由英特爾、AMD、惠普企業(yè)、Arista、Broadcom、思科、Meta和微軟等長期深度參與HPC和網絡領域的公司牽頭,共同宣布成立超以太網聯(lián)盟(Ultra Ethernet Consortium)。該聯(lián)盟的目標是創(chuàng)建一個“基于以太網的完整通信堆棧架構”,使其像以太網一樣具有普及性和成本效益,同時提供超級計算互連所需的性能。聯(lián)盟明確了以下理想特性:靈活的傳輸順序、現代的擁塞控制機制、多路徑和分組噴射,以及更大的可擴展性和端到端遙測。
中國移動聯(lián)合合作伙伴共同推出了全調度以太網(GSE)[42]。全調度以太網是具備無阻塞、高吞吐、低時延的新型以太網架構。全調度以太網架構自上而下分為三層,分別為控制層、網絡層和計算層,引入一種全新的動態(tài)全局隊列調度機制。動態(tài)全局調度隊列(DGSQ)按需、動態(tài)基于數據流目標設備端口創(chuàng)建,為了節(jié)省隊列資源數量,甚至可以基于目標或途經設備的擁塞反饋按需創(chuàng)建。基于 DGSQ 的調度可實現在整個網絡層面的高吞吐、低時延、均衡調度。
總體來看,隨著RoCEv2等技術的成熟[27]、全調度以太網[42]以及超以太網聯(lián)盟[36]的成立,以太網在AI集群互聯(lián)場景中的地位不斷提升,多種網絡互連技術在持續(xù)進化中共同推動著計算互聯(lián)的發(fā)展。
3.2.網絡拓撲
大語言模型訓練網絡對網絡拓撲的規(guī)模、擴展性、網絡直徑、可靠性、功耗和成本提出了更高的要求,比如訓練網絡的擴大需要設計更小的網絡直徑來降低網絡延遲,具體拓撲選擇上也需要考慮組網需要的路由器、線纜帶來的互聯(lián)成本,網絡拓撲需要具有足夠的擴展性以支持后續(xù)規(guī)模的動態(tài)擴容等等。
在高性能計算的發(fā)展中,Torus無疑占據了比較重要的位置,比如cray的T3D、T3E均采用了3D Torus的結構。隨著硬件條件的成熟,高維的Torus結構也已經被很多主流的高性能計算系統(tǒng)采用,最典型的就是fujisu公司推出的K computer采用的6D Torus結構。
胖樹結構[20]是目前在大語言模型訓練網絡中常見的拓撲結構,胖樹是一個靈活性和擴展性都比較好的拓撲結構,隨著網絡規(guī)模的擴大,其二分帶寬也會隨著等規(guī)模增加。

圖5 胖樹拓撲圖
相比于Torus結構,胖樹網絡路由算法更容易實現,有更低的網絡直徑,網絡性能相對出色。但是胖樹網絡在擴展至更大規(guī)模網絡時需要增加網絡層數,從而導致鏈路數隨之指數增長,會大大增加網絡成本。
Dragonfly是由John Kim等人在2008年的論文[5]中提出,它的特點是網絡直徑小、成本較低,對于高性能計算有著非常大的優(yōu)勢。現在已經被運用在使用Cray XC系列網絡的各種超算中。
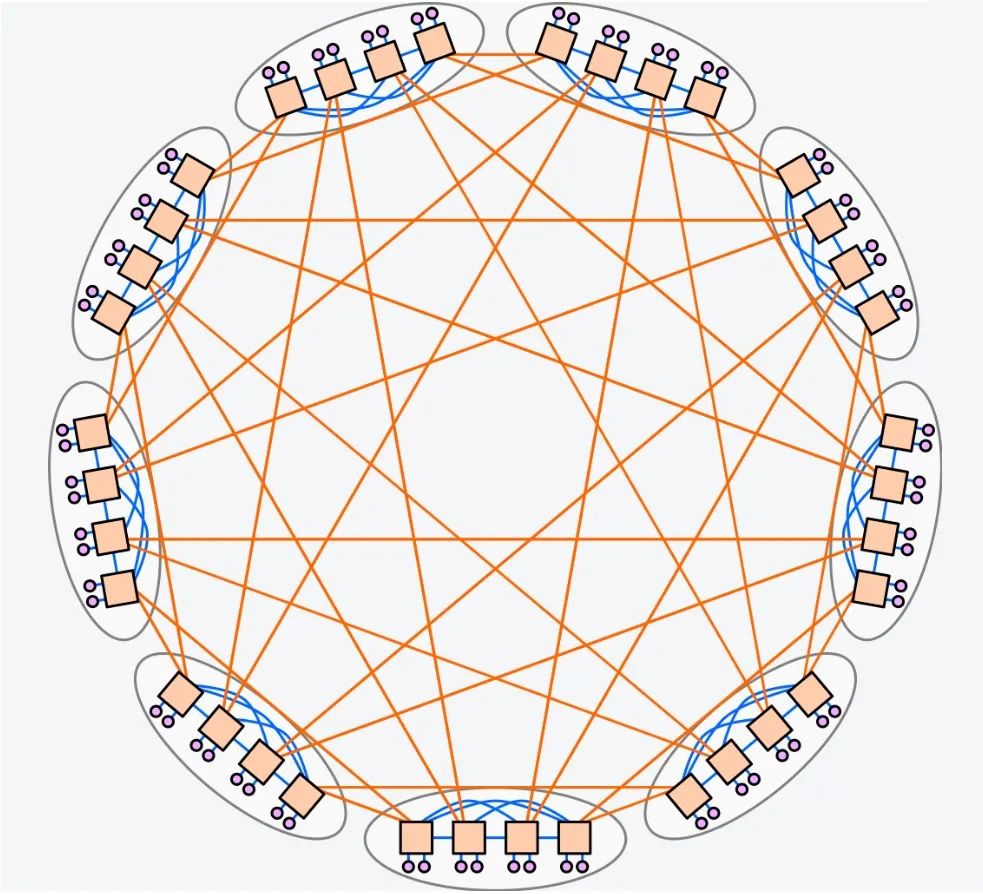
圖6 DragonFly拓撲圖
Dragonfly網絡雖然在成本、降低交換芯片連接端口數量等方面有一定優(yōu)勢,但是面對整體網絡計算節(jié)點的增多,Dragonfly、Dragonfly+等網絡結構依然要面臨網絡連線較為復雜,網絡總體設計成本仍然偏高以及整體網絡所需的全局光纖數偏高等挑戰(zhàn)。
除了上述拓撲結構,騰訊的星脈網絡[58]、MIT和META的rail-only[8]等還提出了定制化拓撲結構,這些拓撲結構專門針對大語言模型的通信需求進行設計,旨在提升性能的同時顯著降低成本。
3.3.擁塞控制
大語言模型訓練作為典型的大規(guī)模數據密集型應用場景,為了應對不斷增長的高吞吐量和超低延遲需求,優(yōu)秀的擁塞控制算法成為必要的配置。
現有的擁塞控制算法可以根據擁塞控制驅動點的位置,即發(fā)送端、交換機或接收端進行分類。發(fā)送端驅動的方法中發(fā)送端利用在ACK數據包中攜帶的信息判定擁塞并觸發(fā)控制動作,如DCTCP[47]、DCQCN[49]、TIMELY[48]和HPCC[50]。DCTCP[47]是數據中心網絡的第一個擁塞控制算法,它利用ECN標記在往返時間內調整速率。DCQCN[49]與DCTCP類似,但更準確地結合了ECN信息。TIMELY[48]則基于RTT進行控制。HPCC[50]利用每一跳帶內網絡遙測(INT)來調整速率和發(fā)送窗口。此類方法較為成熟部署也最為廣泛,但它們往往受到長反饋延時的影響,難以有效應對瞬時突發(fā)流量。此外,在這方向上近些年一些基于強化學習的擁塞控制算法也不斷出現,如RL-CC[51]、DeepCC[52]和Pareto[53]等。
交換機側控制的方法是在交換機上監(jiān)控流量生成顯式反饋控制報文來減少控制環(huán)路的延遲。RoCC[56]基于交換機上的隊列長度,通過PI(Proportional Integral)算法實現控制。PACC[54]則以動態(tài)間隔監(jiān)測隊列長度,區(qū)分突發(fā)流量和擁塞,并直接從交換機生成通知。此類方法較為精確但是又往往依賴于特殊的交換機,限制了部署的范圍。
接收端驅動的方法在接收端檢測擁塞狀況并產生驅動報文以調節(jié)流量。例如RCC [55]結合了顯式窗口分配和迭代窗口調整并在接收端實現控制。
3.4.運維技術
大語言模型訓練網絡不同于傳統(tǒng)的數據中心網絡,具有訓練周期長,中斷次數多特點,其特殊的流量特點要求網絡運維有更高精度的流量采集能力、更精細化的流量統(tǒng)計能力以及更全面的對流控相關指標的采集和統(tǒng)計能力。只有具備上述能力才能更好使用整個訓練網絡,快速的發(fā)現和定位問題。
《智算中心網絡架構白皮書》[10]中認為運維技術的關鍵技術包括:1)可視化網管系統(tǒng),實現對整個集群網絡和節(jié)點內部網絡的可視化;2)高精度流量采集,利用交換設備上telemetry功能,具備秒級流量統(tǒng)計、按需訂閱和高性能的特點;3)數據可視化展示,通過telemetry采集各項指標,用戶選擇性的進行前端展示;4)智能化運維,實現自動故障分析、定位和修復。
《星河AI網絡白皮書》[11]中首次提出了三層兩維可視化運維方案,三層主要是指覆蓋基礎網絡運維、RoCE無損網絡通用場景運維和AI網絡特有場景運維。兩維主要指從監(jiān)控和排障兩個維度,針對三層場景,提供運維和能力手段。
3.5.在網計算
在網計算功能使得網絡內部的硬件計算引擎能夠在網絡通信的過程中卸載復雜操作。在網計算通過網絡的交換和端側設備共同配合的形式得以實現。作為一種內部網絡基于樹狀聚合的機制,在網計算可以支持多個同時的集合操作。交換機被標識為聚合節(jié)點,將執(zhí)行這樣的數據reduce操作。以典型allreduce算子為例,傳統(tǒng)的通信交互復雜度為O(logN)(N代表網絡節(jié)點規(guī)模),啟動在網計算功能后其交互復雜度變?yōu)镺(C)(C代表網絡層級),與網絡節(jié)點規(guī)模無關,極大減少了計算節(jié)點之間的通信交互過程,降低了網絡時延,提升了計算效率。
在AI訓練網絡中最知名的在網計算技術就是英偉達的SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)[17, 18],目前在其infiniband交換機和nvswitch都已經支持。Intel在2018年提出了switchML[19],該系統(tǒng)在其Tofino專用芯片(ASIC)的可編程交換機上實現了AllReduce操作,充分利用了交換機的編程能力。
華為公司NetReduce[22]基于RoCEV2,使用 FPGA 來實現了交換機,實現了數據中心中各粒度的 AllReduce 聚合。此外,論文Flare[21]實現了更靈活的架構,基于開源指令集處理器 RISC-V,使用 sPIN 編程模型設計了一個交換機支持allreduce計算。
3.6.鏈路負載均衡
在大語言模型的推理和訓練應用中,GPU 或其他類型的計算單元的通訊模式通常包括較少的數據流和巨大的每數據流吞吐量,這就極易導致負載不均衡情況的出現。這種不均衡極可能惡化網絡通訊狀況同時帶來帶寬資源的浪費。為了解決這個問題,不同的負載均衡(Load balance)方法被提出,在ECMP[37]中數據包使用靜態(tài)哈希分布到等效的多路徑上,該方法以流為傳輸單元。對于CONGA[38] 和LetFlow [41] , 流片(flowlet)作為傳輸單元,CONGA根據端到端路徑條件的全局信息的實時狀態(tài)選擇流量最佳的下一跳。Letflow根據預定時間間隔對數據包集群進行分類,并隨機選擇每個集群的轉發(fā)端口。DRILL [39] 通過采用隨機策略與工作負載結合的機制選擇轉發(fā)端口,Hermes[40] 將流量傳輸劃分,根據路徑和流的狀態(tài)決定是在流水平重新路由短流還是在數據包水平重新路由長流。
3.7.高性能通信庫
在大語言模型訓練和推理網絡中,高性能通信庫扮演著關鍵的角色,它們負責優(yōu)化數據傳輸和通信,加速AI工作負載,提高整體性能。常見的高性能通信庫包括:
NCCL(NVIDIA Collective Communications Library)[43],它由NVIDIA開發(fā),專為GPU集群通信而設計。針對NVIDIA GPU進行了優(yōu)化,支持高效的點對點和集體通信操作,適用于深度學習框架如TensorFlow和PyTorch。
OpenMPI[44]:一個開源的消息傳遞接口(MPI)實現,用于并行計算。適用于多種硬件和網絡拓撲,支持各種通信模式,廣泛應用于科學計算和大規(guī)模數據分析。
Horovod[45]:Uber工程團隊開發(fā)的集合通信庫支持多種深度學習框架,如TensorFlow、PyTorch和MXNet。同時支持通信優(yōu)化,以加速分布式訓練。
Gloo[46]:Facebook開源的通信庫為分布式深度學習和模型并行計算而設計, 具有高性能的點對點和集體通信實現,適用于各種硬件和網絡環(huán)境。
ACCL[57]:ACCL(Alibaba Collective Communication Library)是一款高性能通信庫,提供了AllReduce、AllToAllV、Broadcast等常用集合操作接口以及點到點Send/Recv接口,為多機多卡訓練提供高效的通信支持。
此外還有其他廠家根據自己的硬件平臺定制的集合通信庫,比如TCCL(Tencent Collective Communication Library)、HCCL(Huawei Collective Communication Library)等等,這些高性能通信庫有助于克服在大規(guī)模AI工作負載中可能遇到的通信瓶頸,提高模型訓練和推理的效率。選擇適當的通信庫通常取決于硬件架構、網絡拓撲和具體的應用場景。
4.業(yè)界知名的大模型訓練網絡
很多的云廠商、互聯(lián)網公司紛紛結合自己的技術優(yōu)勢,通過自研和外部合作的方式搭建起自己的大語言模型訓練網絡的基礎設施。
騰訊采用高性能RDMA網絡[58],采用自研網絡協(xié)議TiTa、定制化集合通信庫TCCL、多軌道網絡拓撲再加上自研全棧網絡運營系統(tǒng)搭建星脈網絡集群,支持10萬卡的超大規(guī)模,具備3.2T通信帶寬,提升40%的GPU利用率,節(jié)省30-60%的模型訓練成本,為AI及大語言模型訓練帶來10倍的通信性能提升。
阿里推出高性能AI訓練計算平臺-靈駿[59],使用基于內存語義的低延遲、高帶寬可線性擴展的磐久高性能網絡predFabric,采用自研Solar-RDMA高速網絡協(xié)議,并結合網絡協(xié)議硬件化,芯片化延時降低至2微秒,實現了5倍的通信性能提升,千卡并行計算效率高達90%。
百度聯(lián)合英偉達共同完成容納萬卡規(guī)模以上的IB網絡[10],提供單集群EFLOPS級別的算力。整個網絡采用8通道架構,通道內spine和leaf交換機做fullmesh全互聯(lián)。為了減少跨交換機通信,采用網絡架構感知方法,訓練任務調度時將同一個任務調度到同一個匯聚組內。對于跨匯聚組的通信,通過匯聚組信息對全局GPU做有序化處理,減少跨交換機流量。
英偉達推出了面向超大規(guī)模生成式 AI 的加速以太網平臺——Spectrum-X[60],其擁有無損網絡、動態(tài)路由、流量擁塞控制、多業(yè)務性能隔離等主要特性,能夠滿足云上部署AI或生成式AI工作負載對網絡性能的要求,有助于節(jié)約訓練成本、縮短訓練時間,加速大模型走向面市。
MIT和Meta團隊發(fā)布了名為“Rail-Only”的全新大語言模型架構設計[8],對專門用于訓練大型語言模型的 GPU 集群的傳統(tǒng)any-to-any網絡架構提出了挑戰(zhàn)。Rail-Only架構通過將GPU分組,組成一個高帶寬互聯(lián)域(HB域),然后再將這些HB域內的特定的GPU跨接到特定的Rail交換機,雖然增加了跨域通信的路由調度復雜度,但是通過合理的HB域和Rail交換機設計,整體架構可以大量減少交換機的使用,最多可以降低75%的網絡通信。
微軟與OpenAI獨家合作打造了一臺性能位居全球前五,擁有超過28.5萬個CPU核心、1萬個GPU,每GPU擁有400Gbps網絡帶寬的超級計算機——Azure AI超算平臺[61],主要用于大規(guī)模分布式AI模型訓練。
2024年2月字節(jié)跳動聯(lián)合北京大學的研究團隊發(fā)表論文[65],介紹了他們用于訓練大語言模型的生產系統(tǒng)MegaScale。MegaScale搭建超過10000塊GPU的單一集群,在12288個GPU上訓練175B LLM模型時,實現了55.2%模型FLOP利用率。該系統(tǒng)還包含了一套診斷工具用于監(jiān)控系統(tǒng)組件和事件,找出根本原因,并實現容錯功能。
5.展望
隨著大語言模型規(guī)模的不斷增大,對網絡的帶寬、延遲、可靠性和健壯性的要求也越來越高。未來的大語言模型訓練網絡組網將向以下幾個方向發(fā)展:更高的帶寬、更低的延遲、更加可靠的組網以及自動化智能運維。結合上述發(fā)展方向,大語言模型訓練網絡組網存在以下幾個研究領域:
新型網絡拓撲
針對大語言模型訓練網絡研究新的拓撲結構,以提高網絡的帶寬和降低網絡的延遲。例如,可以研究基于Clos拓撲結構和Dragonfly拓撲結構的混合拓撲結構,以兼顧網絡的帶寬和延遲。
優(yōu)化流量工程算法
為優(yōu)化網絡中的數據流向,減少網絡擁塞,研究新的流量工程算法。例如,可以研究基于機器學習的流量工程算法,以動態(tài)調整網絡中的數據流向,避免網絡擁塞。
智能運維管理技術
在網絡管理技術上進一步深入研究,以盡可能簡化網絡的管理和維護。例如,可以研究基于人工智能的網絡管理技術,以自動發(fā)現和修復網絡故障,并根據網絡的實時狀態(tài)進行優(yōu)化。
領域定制高速互聯(lián)技術
觀察AI大模型網絡流量特點,針對關鍵技術如協(xié)議定義、擁塞和流量控制等進行針對性優(yōu)化,以期更好的適配大模型網絡的訓練特點。同時在架構設計上需要有足夠的靈活性允許引入新的功能,使其具備持續(xù)演進的能力。
這些研究領域對于大語言模型訓練網絡組網的未來發(fā)展至關重要。通過對這些領域的深入研究,我們可以研發(fā)出更高效、更可靠、更安全以及更智能的AI大模型訓練網絡,以滿足大語言模型訓練的需求。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19896瀏覽量
235371 -
人工智能
+關注
關注
1807文章
49029瀏覽量
249694 -
網絡拓撲
+關注
關注
0文章
105瀏覽量
11985 -
GPU芯片
+關注
關注
1文章
305瀏覽量
6207 -
大模型
+關注
關注
2文章
3147瀏覽量
4085
原文標題:史上最全大語言模型訓練中的網絡技術盤點
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
小白學大模型:訓練大語言模型的深度指南

如何訓練BP神經網絡模型
騰訊公布大語言模型訓練新專利
【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+大模型微調技術解讀
大語言模型開發(fā)框架是什么

mesh網絡技術的優(yōu)缺點

大語言模型如何開發(fā)
端到端InfiniBand網絡解決LLM訓練瓶頸

直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續(xù)學習






 工商網監(jiān)
工商網監(jiān)
評論