") 什么是自然語言處理 (NLP)
什么是自然語言處理 (NLP)
一、什么是自然語言處理 (NLP)
自然語言處理(Natural Language Processing, NLP)是人工智能領(lǐng)域中的一個重要分支,它專注于構(gòu)建能夠理解和生成人類語言的計算機系統(tǒng)。NLP的目標是使計算機能夠像人類一樣理解和處理自然語言文本,從而實現(xiàn)人機交互的流暢和自然。NLP不僅關(guān)注理論框架的建立,還側(cè)重于實際技術(shù)的開發(fā)和應(yīng)用,廣泛應(yīng)用于法律、醫(yī)療、教育、安全、工業(yè)、金融等多個領(lǐng)域。
二、NLP的重要性
NLP的重要性體現(xiàn)在多個方面:
- 提升工作效率 :通過自動化處理大量文本數(shù)據(jù),NLP技術(shù)可以顯著提高工作效率,減少人工干預(yù)和錯誤。
- 改善用戶體驗 :在客戶服務(wù)、智能助手等領(lǐng)域,NLP技術(shù)能夠提供更加智能、個性化的交互體驗。
- 推動技術(shù)創(chuàng)新 :NLP作為人工智能的重要組成部分,其發(fā)展不斷推動人工智能技術(shù)的整體進步。
三、NLP的應(yīng)用場景
NLP技術(shù)在多個領(lǐng)域具有廣泛應(yīng)用,包括但不限于:
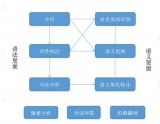
- 機器翻譯 :實現(xiàn)不同語言之間的自動翻譯,打破語言障礙。
- 情感分析 :判斷文本的情感傾向,如積極、消極或中立,用于輿情監(jiān)測、產(chǎn)品評價等。
- 命名實體識別 :從文本中提取特定類型的實體信息,如人名、地名、組織名等,用于信息抽取、知識圖譜構(gòu)建等。
- 垃圾郵件檢測 :識別并過濾掉不受歡迎的電子郵件,保護用戶隱私和安全。
- 智能客服 :通過聊天機器人提供自動化的客戶服務(wù),解決用戶問題,提高客戶滿意度。
- 自動完成和預(yù)測輸入 :在文本編輯、搜索等場景中,預(yù)測用戶輸入的下一個詞或短語,提高輸入效率。
- 文本生成 :生成類似人類寫作的文本,如新聞報道、小說、詩歌等,用于內(nèi)容創(chuàng)作、廣告營銷等。
四、NLP的工作原理
NLP技術(shù)通過一系列復(fù)雜的算法和模型來實現(xiàn)對自然語言文本的處理和理解,主要包括以下幾個步驟:
- 數(shù)據(jù)預(yù)處理 :包括文本清洗、分詞、去停用詞、標準化和特征提取等步驟,為后續(xù)的文本處理提供高質(zhì)量的輸入數(shù)據(jù)。
- 文本表示 :將文本轉(zhuǎn)換為計算機可理解的數(shù)值形式,常用的文本表示方法包括詞袋模型、詞嵌入等。
- 模型構(gòu)建 :選擇合適的NLP模型,如傳統(tǒng)機器學(xué)習(xí)模型(邏輯回歸、樸素貝葉斯等)或深度學(xué)習(xí)模型(RNN、LSTM、Transformer等),對文本數(shù)據(jù)進行訓(xùn)練和學(xué)習(xí)。
- 結(jié)果輸出 :根據(jù)訓(xùn)練好的模型對新的文本數(shù)據(jù)進行處理,輸出相應(yīng)的結(jié)果,如分類標簽、翻譯文本、摘要等。
五、NLP的主要技術(shù)
NLP涵蓋了多種技術(shù)和算法,以下是一些關(guān)鍵技術(shù):
- 詞嵌入(Word Embedding) :將詞語映射到低維向量空間,使得語義相近的詞語在向量空間中距離較近。常見的詞嵌入算法包括Word2Vec、GloVe和FastText等。
- 序列模型(Sequence Models) :處理序列數(shù)據(jù)的算法,對于NLP特別重要。RNN和LSTM是常用的序列模型,能夠捕捉自然語言的上下文和語義依賴關(guān)系。
- 注意力機制(Attention Mechanism) :用于提取和聚焦于輸入序列中相關(guān)部分的技術(shù),廣泛應(yīng)用于機器翻譯、文本摘要和問答系統(tǒng)等任務(wù)。
- Transformer模型 :一種基于自注意力機制的模型架構(gòu),能夠同時處理序列中的所有元素,克服了RNN的局限性,在多個NLP任務(wù)上取得了優(yōu)異性能。
- 預(yù)訓(xùn)練語言模型(Pre-trained Language Models) :如BERT、GPT等,通過在大規(guī)模文本數(shù)據(jù)上進行預(yù)訓(xùn)練,學(xué)習(xí)語言的通用表示,然后應(yīng)用于各種下游NLP任務(wù)。
六、NLP面臨的挑戰(zhàn)
盡管NLP技術(shù)取得了顯著進展,但仍面臨諸多挑戰(zhàn):
- 模型的偏見問題 :由于訓(xùn)練數(shù)據(jù)的不平衡或偏見,NLP模型可能會產(chǎn)生不公平的預(yù)測結(jié)果。
- 環(huán)境影響 :NLP模型的訓(xùn)練需要大量的計算資源和時間,對環(huán)境造成一定影響。
- 高昂的成本 :構(gòu)建和維護高性能的NLP系統(tǒng)需要投入大量的人力和物力資源。
- 模型的不可解釋性 :深度學(xué)習(xí)模型雖然性能優(yōu)異,但其決策過程往往難以解釋,不利于信任度的提升。
七、NLP的未來展望
隨著技術(shù)的不斷進步和應(yīng)用的深入,NLP的未來展望充滿希望:
- 多模態(tài)融合 :將NLP與計算機視覺、語音識別等技術(shù)相結(jié)合,實現(xiàn)更加全面的人機交互。
- 低資源語言處理 :針對低資源語言(如少數(shù)民族語言)開發(fā)更加有效的NLP技術(shù),促進語言多樣性。
- 可解釋性增強 :通過引入可解釋性算法和技術(shù),提高NLP模型的透明度和可信度。### NLP的未來展望(續(xù))
- 個性化與自然化 :隨著技術(shù)的進步,NLP系統(tǒng)將更加個性化,能夠根據(jù)用戶的習(xí)慣、偏好和上下文提供更加自然、貼合需求的交互體驗。這要求NLP系統(tǒng)具備更強的理解和推理能力,以及更靈活的適應(yīng)性。
- 自動化與智能化 :未來的NLP系統(tǒng)將更加自動化和智能化,能夠自主完成復(fù)雜的文本處理任務(wù),減少人工干預(yù)。例如,自動化的文檔分類、信息抽取、摘要生成等,將極大地提高工作效率和準確性。
- 跨語言處理 :隨著全球化的深入發(fā)展,跨語言處理成為NLP領(lǐng)域的一個重要研究方向。未來的NLP系統(tǒng)將能夠處理多種語言,實現(xiàn)跨語言的文本理解、翻譯和生成,打破語言障礙,促進全球信息的交流和共享。
- 實時性與高效性 :在實時應(yīng)用場景中,如在線聊天、語音助手等,NLP系統(tǒng)需要具備高效的處理能力和快速的響應(yīng)速度。未來的NLP技術(shù)將不斷優(yōu)化算法和模型,提高處理速度和效率,以滿足實時交互的需求。
- 隱私與安全 :隨著NLP技術(shù)的廣泛應(yīng)用,隱私和安全問題日益凸顯。未來的NLP系統(tǒng)將更加注重用戶數(shù)據(jù)的保護,采用加密、匿名化等技術(shù)手段,確保用戶隱私的安全。同時,也需要加強對NLP系統(tǒng)的監(jiān)管和審計,防止濫用和誤用。
- 終身學(xué)習(xí) :借鑒人類的學(xué)習(xí)機制,未來的NLP系統(tǒng)將具備終身學(xué)習(xí)的能力。它們能夠不斷從新的數(shù)據(jù)中學(xué)習(xí)新知識,優(yōu)化自身性能,適應(yīng)不斷變化的環(huán)境和需求。這種能力將使NLP系統(tǒng)更加靈活和強大,能夠在更廣泛的領(lǐng)域發(fā)揮作用。
- 倫理與道德 :隨著NLP技術(shù)的深入應(yīng)用,倫理和道德問題也日益受到關(guān)注。未來的NLP系統(tǒng)需要遵循一定的倫理規(guī)范和道德準則,確保技術(shù)的合理、合法和負責(zé)任地使用。這要求開發(fā)者、研究者和使用者共同努力,建立健全的倫理框架和監(jiān)管機制,促進NLP技術(shù)的健康發(fā)展。
結(jié)語
自然語言處理(NLP)作為人工智能領(lǐng)域的一個重要分支,具有廣泛的應(yīng)用前景和巨大的發(fā)展?jié)摿ΑMㄟ^不斷的技術(shù)創(chuàng)新和應(yīng)用實踐,NLP技術(shù)將不斷突破現(xiàn)有的局限和挑戰(zhàn),為人類社會的發(fā)展和進步貢獻更多的智慧和力量。然而,我們也應(yīng)該清醒地認識到NLP技術(shù)所面臨的挑戰(zhàn)和問題,并積極尋求解決方案和途徑,以確保技術(shù)的健康、可持續(xù)和負責(zé)任地發(fā)展。
-
計算機
+關(guān)注
關(guān)注
19文章
7632瀏覽量
90227 -
人工智能
+關(guān)注
關(guān)注
1804文章
48745瀏覽量
246683 -
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14028
發(fā)布評論請先 登錄
自然語言處理(NLP)領(lǐng)域的高效方法
命名實體識別(NER)是自然語言處理(NLP)中的基本任務(wù)之一
OpenAI介紹可擴展的,與任務(wù)無關(guān)的的自然語言處理(NLP)系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論