 數字化時代的數據管理:多樣化數據庫選型指南
數字化時代的數據管理:多樣化數據庫選型指南
非常感謝Kevin和張健對本文提供的建議和指導。
1. 概述
在數字化時代,數據是企業最寶貴的資產之一。隨著技術的進步和數據量的爆炸性增長,如何有效地存儲、管理和分析這些數據成為每個企業面臨的重大挑戰。數據庫作為數據管理的核心技術,其選型對于系統至關重要。傳統的關系型數據庫(RDBMS)以其嚴格的ACID事務、優秀的一致性和安全性在企業應用中占據了長久的統治地位。然而,隨著互聯網、大數據和云計算的興起,非關系型數據庫(NoSQL)因其靈活的數據模型、易于水平擴展的特性和優異的處理高并發請求的能力,在特定場景下得到廣泛應用。此外,時間序列數據庫(TSDB)、圖數據庫等針對特定類型的數據和查詢提供了更加專業的解決方案。除此之外,新型數據庫如向量數據庫則為機器學習、人工智能和相似性搜索提供了更高效的整體解決方案。
本文將探討9種數據庫,涉及各種數據庫風格。本文并非旨在將某種數據庫新手培養成專家,因為那樣的話,任何一種數據庫都會需要大量的篇幅來詳細描述。然而,通過閱讀本文,你應該能夠理解并掌握每種數據庫的獨特優勢,并在面對不同的使用場景時做出最佳決策。
1.1 數據存儲風格
數據庫分為各種類型,例如,關系型、鍵-值型、多列型、面向文檔型、圖型、時序型和向量型,各種數據庫有著其本身獨特的風格。流行的數據庫一般可以劃分為這幾大類型。本次對涉及的數據庫精心挑選,以覆蓋這些類型,包括一個關系數據庫(MySQL),一個鍵-值存儲的數據庫(Redis),兩個面向列的數據庫(HBase和ClickHouse),兩個面向文檔的數據庫(MongoDB和ElasticSearch),一個圖數據庫(Neo4j),一個時序數據庫(Prometheus)以及一個向量數據庫(Milvus)。
1.1.1 關系數據庫
關系型數據庫(RDBMS)仍然是目前應用最廣泛的數據庫類型之一。關系型數據庫(RDBMS)以其強大的結構化查詢語言(SQL)、事務性(支持ACID屬性:原子性、一致性、隔離性、持久性)、以及嚴格的數據完整性約束而聞名。它們以行和列的形式組織數據,并存儲在一系列互相關聯的表中,這些表通過外鍵等機制實現數據之間的關系。這種模式非常適合于需要執行復雜查詢和報告的場景,如財務系統、人力資源管理系統和庫存系統。關系型數據庫的模式(schema)在創建時需要定義,這意味著數據的結構在數據庫中是預先確定的,這為數據的一致性和規范化提供了保障。
流行的關系型數據庫系統包括Oracle、MySQL、PostgreSQL和Microsoft SQL Server,它們在不同的應用環境中被廣泛部署,從小型企業到大型企業級應用。第二章將介紹MySQL。雖然關系型數據庫在處理大規模分布式數據方面面臨挑戰,但它們的強類型和結構化特性使其在數據準確性和完整性至關重要的應用中繼續保持其價值和重要性。隨著技術的發展,現代關系型數據庫也在不斷地演化,以滿足云計算、高可用性和自動化運維等新興需求。
1.1.2 鍵-值數據庫
鍵值型數據庫,作為非關系型數據庫(NoSQL)的一個重要類別,以其簡潔高效的數據存儲模式在現代應用開發中占有一席之地。這類數據庫基于鍵值對的結構來存儲數據,其中“鍵”是唯一的標識符,而“值”可以是簡單的數據項或更復雜的數據結構。鍵值數據庫的主要優勢在于其高速讀寫性能和出色的可擴展性,這使得它們非常適合處理大量的并發請求,如在線購物平臺的購物車、社交網絡中的用戶會話和高速緩存系統等場景。
鍵值數據庫的操作簡單直觀,主要包括鍵的添加、查詢、修改和刪除,因此開發者可以快速實現數據的存取,無需復雜的查詢語言。此外,由于數據是以鍵值對的形式直接存儲,這種結構的靈活性允許應用在不需要預定義模式的情況下動態添加數據,極大地提高了開發效率和系統的靈活性。
流行的鍵值數據庫包括Redis、Amazon DynamoDB和Memcached等,它們各自有著不同的性能特點和優化場景。第三章將介紹Redis,Redis以其極高的性能和支持多種數據結構而廣泛應用于需要高速緩存的場景。盡管鍵值數據庫在處理高并發、大規模數據分布式應用方面表現出色,但它們通常不適用于需要復雜查詢和數據關聯分析的應用場景。選擇鍵值數據庫作為解決方案時,需要綜合考慮應用的具體需求和數據處理特性。
1.1.3 列式數據庫
列式數據庫,又稱為列存儲數據庫,是一種為了高效讀寫大量數據而設計的數據庫系統,它與傳統的行式數據庫相對,將數據按列而不是按行存儲。這種存儲方式特別適合于分析大規模數據集,因為它可以快速聚合同一列的數據,優化了磁盤I/O性能并減少了數據讀取量。在列式數據庫中,每一列的數據緊密排列存儲,且通常會對這些數據進行壓縮,這樣既節省了存儲空間,又加快了查詢速度。
列式數據庫的主要優勢在于其對數據倉庫和在線分析處理(OLAP)查詢的支持。它們能夠高效地執行復雜的查詢,如計數、求和、平均值等聚合操作,這些操作通常只需要訪問表中的少數幾列。因此,列式數據庫非常適合用于商業智能、大數據分析、科學計算等領域,這些領域通常涉及到對大量數據進行快速讀取和分析。
流行的列式數據庫包括Apache Cassandra、Apache HBase和ClickHouse等,它們在處理大數據和實時分析方面展現出巨大的潛力。在本文中將介紹HBase(第四章)和ClickHouse(第五章)兩個當下比較流行的產品。雖然列式數據庫在數據寫入方面可能不如行式數據庫高效,但通過批量操作、延遲寫入和其他優化技術,它們能夠實現對寫入性能的改進。總的來說,列式數據庫是那些需要高效進行數據分析和報告的應用的理想選擇,尤其是當工作負載涉及到大量數據且主要是讀取操作時。
1.1.4 文檔數據庫
文檔數據庫,是一種以文檔為中心的非關系型數據庫(NoSQL),它允許存儲、查詢和管理基于文檔格式的數據。文檔在這里指的是類似于JSON、XML或BSON這樣的數據結構,這些結構能夠嵌套、具有層次性,并且可以存儲多種數據類型。這種靈活性使得文檔數據庫特別適合于處理多變的數據模式和非結構化或半結構化數據。
文檔數據庫的主要優勢在于其靈活性和直觀性。它們不需要預定義的數據模式,因此開發者可以輕松地添加或刪除字段,而不影響現有的數據。此外,由于數據模型的直接性和自描述性,開發者可以更快速地理解和操作數據,從而加快開發速度。文檔數據庫通常還提供強大的查詢語言和索引功能,使得對文檔內的數據進行查詢和分析變得高效且靈活。
流行的文檔數據庫如MongoDB、Couchbase和Amazon DynamoDB等,非常適合內容管理系統、電子商務應用和移動應用,這些應用中的數據經常發生變化且結構多樣。在第六章將介紹MongoDB。在第七章介紹了當下流行的搜索引擎ElasticSearch,但ElasticSearch也傾向于被歸類為文檔數據庫或NoSQL數據庫。盡管文檔數據庫提供了高度的靈活性和擴展性,但在需要復雜事務處理和關系型數據強一致性的場合,它們可能不如傳統的關系型數據庫。在選擇文檔數據庫時,開發者和架構師需要仔細考慮應用的具體需求,包括數據模式的穩定性、查詢的復雜度以及系統的擴展需求。
1.1.5 圖數據庫
這是一種不太常用的數據庫類型,圖數據庫善于處理高度互聯的數據。圖數據庫是專門設計來處理圖形結構數據的數據庫,它們優化了節點、邊以及節點之間關系的存儲和查詢。在圖數據庫中,數據模型本質上是一個圖,即由點(節點)和線(邊)組成的集合,能夠直觀地表示和存儲數據項之間的多對多關系。這種結構特別適合社交網絡、推薦系統、知識圖譜、網絡分析等場景,這些場景中的數據關系復雜且密集。
圖數據庫的一個關鍵優勢是它們能夠高效地執行深度連接查詢和圖遍歷,這在關系型數據庫中可能非常耗時和復雜。它們通過優化鄰接數據的存取速度來實現這一點,使得即便是在大規模網絡中也能快速發現復雜的模式和關系。此外,圖數據庫通常具有靈活的模式,可適應不斷變化的數據模式,而不需要進行昂貴的模式遷移。
流行的圖數據庫實現包括Neo4j、OrientDB和Amazon Neptune等。在第八章討論了流行的圖數據庫Neo4j。它們提供了豐富的API和查詢語言,如Cypher和Gremlin,使得開發者能夠輕松構建復雜的圖查詢和算法。雖然圖數據庫在處理高度關聯的數據方面表現出色,但它們在大規模的數據分布式處理和存儲方面可能不如某些專為此目的設計的數據庫系統。在選擇圖數據庫時,應仔細考慮實際的業務需求,特別是數據的關聯性和查詢的復雜性。
1.1.6 時序數據庫
時序數據庫是專門為處理時間相關數據而設計的數據庫系統,它優化了時序數據的存儲、查詢和分析。時序數據是隨時間連續記錄或采樣的數據點集合,典型的例子包括股票市場數據、物聯網傳感器數據、應用性能指標等。這類數據庫通過對時間標簽的優化索引,提供了對時間序列數據高效寫入、查詢和壓縮存儲的能力。
時序數據庫的核心優勢在于它們對數據的時間屬性有著原生支持,可以快速處理大量按時間順序排列的數據點。它們通常提供時間窗口查詢、時間聚合以及時間序列的快速降采樣和升采樣功能,這些特性對于時間依賴性分析至關重要。此外,時序數據庫能夠高效地處理高吞吐量和大數據量的寫入操作,這對于實時監控和事件驅動的應用尤為重要。
流行的時序數據庫包括InfluxDB、Prometheus和TimescaleDB等,它們被廣泛應用在金融分析、工業監控、資源監測和運維監控等多種場景。在第九章介紹了用于運維監控的時序數據庫Prometheus。由于時序數據庫的設計專注于時間維度,它們可能不如通用數據庫在處理多維復雜查詢方面靈活。因此,在選擇時序數據庫時應考慮應用是否對時間數據的處理有高效率的需求。總之,時序數據庫是處理時間敏感數據的理想解決方案,能夠為業務分析和決策提供強有力的時間維度支持。
1.1.7 向量數據庫
向量數據庫,作為一種專注于處理高維度數值向量的非關系型數據庫(NoSQL),在近年來隨著人工智能和機器學習的飛速發展而獲得廣泛關注,是推動AI應用發展的關鍵技術之一。這類數據庫的核心在于它們能夠存儲和管理由多維度特征構成的數據點,即向量,這些向量通常代表圖像、文本、聲音或用戶行為等非結構化數據的深度特征。向量數據庫最大的優點在于其能夠通過先進的索引技術和相似性搜索算法,高效地執行基于內容的檢索和匹配操作,如快速找到與給定圖像特征相似的圖像或尋找語義內容相近的文本。
此類數據庫設計用于優化大規模向量數據的存儲和查詢性能,支持各種距離和相似性度量標準,如歐氏距離、余弦相似度等,以滿足不同應用場景的需求。向量數據庫的應用領域廣泛,包括但不限于推薦系統、圖像和視頻分析、自然語言處理和生物信息學等,它們在這些領域中為實現復雜的相似性搜索和數據分析提供了強大的支持。
流行的向量數據庫包括Milvus、Faiss、Pinecone和Chroma等,它們在不同的場景下提供了豐富的功能和優化,滿足了從基礎研究到商業應用的廣泛需求。最后介紹一下當下流行的用于大模型的向量數據庫Milvus。盡管向量數據庫面臨著數據規模和查詢效率的挑戰,但隨著技術的進步和優化,向量數據庫正逐漸克服這些挑戰,為各種先進的AI應用提供強大的數據支持,展現出廣闊的發展前景。
1.2 DB-Engines數據庫排行榜
以下是2024年6月份的DB-Engines數據庫排名列表,這是一個專門收集和呈現數據庫管理系統信息的數據庫引擎排名,里面列舉了超過 300 多種數據庫產品,大部分的開源和商業數據庫都在列,排名中的位置通常能反映出它的使用情況。
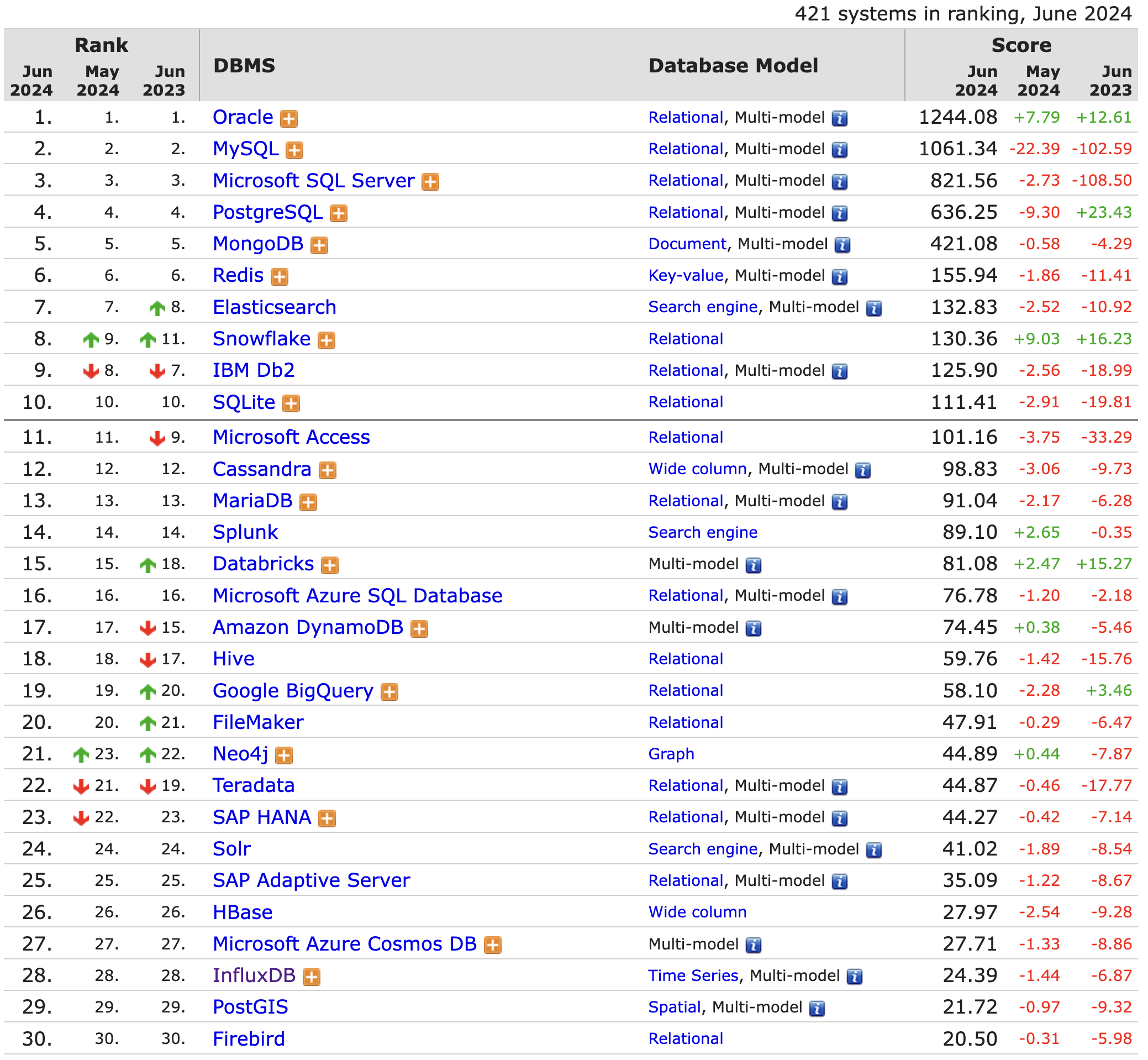
DB-Engines排名的數據依據 5 個不同的因素:
?Google及Bing搜索引擎的關鍵字搜索數量;
?Google Trends的搜索數量;
?Indeed網站中的職位搜索量;
?LinkedIn中提到關鍵字的個人資料數;
?Stackoverflow上相關的問題和關注者數。
2. MySQL
MySQL是一種廣泛使用的開源關系型數據庫管理系統(RDBMS),它基于SQL(結構化查詢語言)進行操作,允許用戶創建、維護和查詢數據庫。作為Web應用的后端數據庫,MySQL因其穩定性、可靠性和簡易性而受到開發者的青睞。

2.1 優點
?成本效益:作為一個開源系統,MySQL減少了數據庫解決方案的成本。
?易于使用:具有直觀的界面設計和易于理解的SQL語法,大家基本上都用得比較熟。
?強大的社區支持:龐大的開發者社區,豐富的在線資源和文檔,以及廣泛的第三方工具。
?配套成熟:具有備份恢復、數據訂閱、數據同步等配套功能。
2.2 缺點
?復雜性:隨著數據量和復雜度的增加,MySQL 的管理和維護可能會變得復雜。
?可擴展性:雖然MySQL適用于許多應用,但在處理極大規模數據或極高并發的情況下,性能可能會受到影響。
2.3 最佳實踐
?優化數據模型:合理設計數據庫和表結構,確保數據的規范化。
?定期清理無用數據:及時刪除不再需要的數據可以減少磁盤空間占用,提高查詢效率。
?適當的索引策略:合理創建和維護索引以優化查詢速度和性能。
?性能監控和優化:定期監控數據庫性能,分析慢查詢日志,并根據需要進行優化。
2.4 應用場景
?Web應用:MySQL是LAMP(Linux, Apache, MySQL, PHP/Python/Perl)堆棧的一部分,適合動態網站和Web應用。
?小到中型企業解決方案:對于需要可靠數據庫支持但預算有限的企業,MySQL提供了一個強大而經濟的選項。
3. Redis
Redis(Remote Dictionary Server)是一個開源的高性能鍵值存儲系統,通常被用作緩存。它支持多種類型的數據結構,如字符串(strings)、列表(lists)、集合(sets)、有序集合(sorted sets)、哈希表(hashes)、位圖(bitmaps)、超日志(hyperloglogs)以及地理空間(geospatial)索引半徑查詢。Redis主要用于需要高速讀寫操作的場景,數據存儲在內存中,但也可以持久化到磁盤,以保證數據安全。

3.1 優點
?高性能:由于所有數據都存儲在內存中,Redis能夠提供極快的讀寫速度。
?數據結構豐富:支持多種數據結構,滿足不同場景的需求。
?持久化:支持RDB和AOF兩種持久化機制,可以根據需求進行配置。
?功能豐富:包括發布/訂閱、事務、Lua腳本編程等功能。
?高可用與分布式:通過哨兵和集群模式支持高可用性和水平擴展。
3.2 缺點
?內存成本:數據存儲在內存中,對于大規模數據集,成本較高。
?數據集大小受內存限制:由于數據存儲在內存中,因此數據集的大小受到物理內存的限制。
?持久化有瓶頸:雖然Redis提供了持久化功能,但是在高負載情況下,持久化可能會成為性能瓶頸。
?單線程模型:雖然單線程模型簡化了設計,提高了性能,但也限制了CPU利用率。
3.3 最佳實踐
?內存管理:定期審查和優化內存使用,設置合理的TTL,使用適當的數據淘汰策略管理內存。
?適當選擇持久化策略:根據業務需求選擇RDB、AOF或兩者結合的持久化方式。
?避免長時間運行的命令:長時間運行的命令可能會阻塞Redis,影響性能,如keys *操作。
?合理設計KEY:避免大KEY、熱點KEY。
3.4 應用場景
?緩存:由于其高性能,Redis是構建高速緩存系統的絕佳選擇。
?會話存儲:快速地讀寫操作使得Redis非常適合存儲用戶會話。
?排行榜/計數器:Redis的數據結構非常適合實現排行榜和計數器。
?實時分析:適用于需要快速響應的數據分析和監控系統。
4. HBase
HBase是一個開源的、非關系型的、分布式的列存儲數據庫,設計用于利用廉價的硬件提供高吞吐量的隨機讀寫訪問。它是Google的Bigtable論文的開源實現,能夠在大規模分布式環境中高效存儲和管理海量數據。

4.1 優點
?水平擴展性:HBase非常適合處理大量數據,可以水平擴展到成千上萬的節點來處理PB級別的數據。
?快速隨機訪問:優秀的隨機讀寫能力,適合對大數據集進行實時查詢。
?自動故障轉移:依托于Hadoop生態系統,能夠處理節點故障,自動進行數據復制和故障轉移。
?列存儲:列式存儲模型適合存儲結構化數據,便于進行大規模的數據分析和處理。
4.2 缺點
?復雜性:部署和管理HBase系統相對復雜,需要較深的知識儲備。
?內存和IO敏感:高性能依賴于足夠的內存和IO資源。
?缺少事務支持:不支持傳統意義上的多行事務。
?學習曲線:對于熟悉關系型數據庫的開發者來說,學習HBase的API和數據模型需要一定的時間。
4.3 最佳實踐
?合理設計Row Key:避免熱點問題,確保數據均勻分布。
?數據模型優化:利用HBase的列族特性,將頻繁訪問的數據放在同一個列族中,減少I/O操作。
?監控和調優:定期監控HBase集群的性能,根據需要調整配置參數。
?使用合適的壓縮算法:選擇合適的數據壓縮算法(如Snappy或LZ4),以減少存儲空間和提高I/O性能。
4.4 應用場景
?大規模數據處理:適用于需要存儲和處理TB到PB級別數據的應用。
?實時查詢:適合需要快速讀取大量數據的應用,如實時分析和監控系統。
?寫重型應用:適用于寫操作遠多于讀操作的場景。
5. ClickHouse
ClickHouse是一個用于聯機分析處理(OLAP)的開源列式數據庫管理系統(DBMS)。它是為實時生成的數據分析而設計的,能夠以極高的速度執行實時查詢和報告任務。由于其列式存儲架構,ClickHouse特別適合處理大規模數據集,能夠高效地執行數據壓縮和快速的數據檢索操作。

5.1 優點
?高性能查詢:基于列式存儲,優化了大量數據的讀取速度,特別適合分析和聚合大數據集。
?高度優化的數據壓縮:列式存儲允許高效的數據壓縮,減少存儲成本。
?近實時分析:支持近乎實時的數據插入和查詢,使得最新數據可以迅速被分析。
?水平擴展性:通過添加更多節點來輕松擴展系統,適合處理PB級別的大數據量。
?多核和向量化查詢執行:充分利用現代CPU的多核架構和向量指令,提升查詢效率。
?強大的SQL支持:支持SQL查詢,使得從其他數據庫系統遷移過來的用戶可以很容易上手。
5.2 缺點
?寫入負載:雖然優化了讀取性能,但在高并發寫入場景下,性能可能受限。
?管理復雜性:對于大型部署,集群管理可能比較復雜,需要專業知識。
?限制的事務支持:主要面向分析負載,對于需要復雜事務處理的應用場景,支持有限。
5.3 最佳實踐
?數據模型優化:根據查詢需求合理設計表結構,利用列式存儲和數據壓縮的優勢。
?合理使用索引:創建合適的索引來加速查詢,但避免過度索引以減少資源消耗。
?批量插入數據:利用批量插入提高數據寫入效率,減少系統開銷。
?監控系統性能:使用ClickHouse自帶的監控工具或第三方工具定期檢查系統狀態,優化配置。
?數據分片和復制:利用ClickHouse的分片和復制機制提高查詢性能和數據可靠性。
5.4 應用場景
?大規模日志分析:適合處理和分析Web服務器、應用程序、安全系統等產生的大量日志數據。
?實時數據分析:支持對金融市場數據、電商平臺用戶行為等實時數據進行分析。
?商業智能(BI):支持復雜的BI查詢,為企業提供即時的業務洞察和數據驅動的決策支持。
6. MongoDB
MongoDB是一種流行的開源NoSQL數據庫,專為簡化開發和擴展而設計。作為一個面向文檔的數據庫,MongoDB允許開發者以動態的模式(稱為BSON)存儲數據,這意味著與傳統的關系型數據庫相比,你可以存儲更復雜的數據類型更為靈活。MongoDB設計用于處理大量的數據和高并發的讀寫操作,適用于各種規模的企業和多種應用場景。

6.1 優點
?靈活的文檔模型:不需要預定義模式,可以輕松地存儲和組合多種數據格式。
?可擴展性:支持水平擴展,可以通過增加更多服務器來提升處理能力和存儲容量。
?高性能:針對讀寫操作進行了優化,尤其是在處理大規模數據時表現突出。
?高可用性:內置復制和故障轉移功能,保證數據的持續可用性。
6.2 缺點
?事務支持: 在處理跨文檔(跨集合)的事務時,MongoDB的支持不如傳統的關系型數據庫。雖然最新版本的MongoDB增加了對多文檔事務的支持,但在分布式事務處理方面,它的復雜性和性能損耗仍然是一個挑戰。
?存儲空間:由于其靈活的文檔模型,可能會消耗更多的存儲空間。
?內存占用:為了提高性能,MongoDB會使用較多的內存來存儲熱數據和索引。
?運維考量:MongoDB的集群管理和運維比較復雜,尤其是在處理分片和副本集時,需要較高的專業知識。
?索引限制: 雖然索引可以幫助提升查詢性能,但是不當的索引策略(如過多的索引、不合適的索引類型)可能會導致性能問題。MongoDB對索引大小和數量有限制,不恰當的索引使用會增加存儲和維護成本。
6.3 最佳實踐
?合理設計文檔結構:避免過度嵌套,使文檔結構盡量扁平化,以提高查詢效率。
?使用索引優化查詢:合理創建索引來優化查詢性能,但要避免過度索引以減少維護成本和空間占用。
?分片策略:對于大數據量的應用,合理規劃分片(Sharding)策略,以實現數據的水平擴展。
?監控與維護:利用MongoDB Atlas或其他工具監控數據庫性能,及時調整配置。
6.4 應用場景
?內容管理系統(CMS):靈活的文檔模型適合管理各種格式和類型的內容。
?移動應用:快速開發周期和數據模型的變化頻繁,MongoDB提供了足夠的靈活性和性能。
?物聯網(IoT):能夠處理和分析來自成千上萬傳感器和設備的數據。
?大數據應用:MongoDB的高性能和擴展性使其非常適合大數據存儲和實時分析應用。
7. ElasticSearch
ElasticSearch(ES)是一個基于Apache Lucene的強大開源搜索和分析引擎。雖然它提供了類似于關系型數據庫的一些功能,比如數據存儲、索引、查詢等,但它并不是傳統意義上的關系型數據庫管理系統(RDBMS)。ES更傾向于被歸類為一個NoSQL數據庫或文檔數據庫,因為它支持非結構化數據的存儲和查詢,并且具有高度可擴展性和靈活性。它能夠快速地、在近乎實時的情況下存儲、搜索和分析大量數據。ElasticSearch是高度可擴展的,支持分布式架構,可以輕松處理PB級別的數據。通過其RESTful API,用戶可以輕松地執行和組合多種類型的搜索 —— 全文搜索、結構化搜索 —— 以及進行復雜的分析。

7.1 優點
?快速且可擴展:ElasticSearch能夠在幾毫秒內返回查詢結果,并且可以水平擴展到數百(甚至更多)節點。
?強大的搜索功能:支持全文搜索、模糊搜索、自動完成、地理位置搜索等。
?近實時分析:提供近乎實時的搜索和分析能力。
?成熟的生態系統:Elastic Stack提供日志收集、數據可視化等解決方案,生態系統成熟。
7.2 缺點
?資源密集型:為了保證性能,ElasticSearch可能會消耗大量的系統資源。
?學習曲線:雖然基本使用簡單,但深度利用其功能(如數據建模、集群管理)需要較深的學習。
?管理復雜性:在大規模部署和高負載下,集群管理和維護可能變得復雜。
7.3 最佳實踐
?合理規劃集群和索引:根據數據量和查詢需求合理規劃集群大小和索引結構。
?合理使用分片和副本:根據數據量和可用性需求合理設置分片和副本數量。
?性能提升:ES中僅存儲索引字段,通過id回查數據庫,不要全量數據存儲ES。ES的JVM垃圾收集器一般適合G1。
?數據建模:根據查詢需求合理設計文檔結構和索引策略,避免過度使用嵌套字段。
?安全措施:使用X-Pack或其他安全插件保護數據和訪問。
?監控和調優:使用Elastic Stack的監控工具,定期檢查和調優集群性能。
7.4 應用場景
?全文搜索:如電商網站、文檔庫等需要快速、靈活搜索能力的應用。
?復雜查詢:可以快速響應大規模數據的復雜搜索請求。
?日志分析和監控:用于收集、聚合、分析大量日志數據,如ELK(Elasticsearch, Logstash, Kibana)日志分析解決方案。
?地理信息系統(GIS):支持地理位置數據的索引和查詢,適用于地圖服務、位置搜索等應用。
?個性化推薦系統:通過用戶行為和偏好分析,提供個性化的搜索和推薦。
8. Neo4j
Neo4j是當前最流行的圖數據庫之一,它用圖形結構存儲數據,這種結構包含節點(Node)、關系(Relationship)、屬性(Property)。Neo4j特別適合處理復雜的關系和深度連接查詢,提供了強大的圖形查詢語言Cypher,使得查詢和處理圖數據變得非常直觀和高效。
?

8.1 優點
?高效的關系處理能力:相比于關系數據庫,Neo4j在處理深度連接和復雜關系時更加高效。
?靈活的數據模型:圖形結構非常適合表示復雜的關系和動態變化的數據模型。
?強大的查詢語言:Cypher查詢語言直觀易學,能夠輕松處理復雜的圖形查詢。
?成熟的生態系統:提供了豐富的工具和庫,支持多種編程語言的接口,有大量的學習資源和社區支持。
?事務支持:支持ACID事務,確保數據的一致性和完整性。
8.2 缺點
?性能調優:對于大規模數據集和復雜查詢,性能調優可能會比較復雜。
?學習曲線:雖然Cypher查詢語言直觀,但對于習慣了SQL的用戶來說,仍然需要一定的學習和適應。
?資源消耗:為了保持高性能的關系處理能力,可能會消耗更多的內存和計算資源。
8.3 最佳實踐
?合理設計圖模型:根據應用場景合理設計節點、關系和屬性,避免過度設計。
?索引和約束:合理使用索引和約束來提高查詢效率和數據質量。
?批量導入數據:對于大量數據的導入,使用Neo4j提供的批量導入工具,而不是逐條插入。
?監控和調優:定期監控數據庫性能,根據監控結果適時進行調優。
8.4 應用場景
?社交網絡:管理用戶之間復雜的社交關系和互動。
?推薦系統:基于用戶和項目之間的關系進行個性化推薦。
?欺詐檢測:分析交易模式和用戶行為,識別潛在的欺詐活動。
?知識圖譜:構建領域知識的圖形表示,支持復雜的查詢和分析。
?網絡和IT運維:管理網絡設備、服務和應用之間的依賴關系,優化性能和故障排查。
9. Prometheus
Prometheus是一個開源的監控和警報工具,專為可靠性和快速診斷而設計。它通過定時抓取被監控服務的指標數據,存儲這些數據為時間序列,然后通過其查詢語言PromQL進行查詢、分析和警報。Prometheus廣泛應用于云原生環境,尤其是與Kubernetes的集成,使其成為監控容器和微服務架構的首選解決方案。

9.1 優點
?多維數據模型:支持通過標簽將任意維度的元數據附加到時間序列數據上,使數據查詢更為靈活。
?強大的查詢語言:PromQL允許進行復雜的數據查詢和計算,非常適合時間序列數據的分析。
?自帶時間序列數據庫:內置高效的時間序列數據庫,優化了數據的存儲和查詢。
?服務發現:支持多種服務發現機制,能自動監控新的服務實例,減少手工配置。
?靈活的警報規則:可以基于時間序列數據定義復雜的警報邏輯。
9.2 缺點
?長期數據存儲:對長期歷史數據的存儲和管理支持較弱,可能需要集成第三方解決方案。
?數據的刪除和修改:對于已存儲的數據,執行刪除或修改操作相對復雜。
?界面簡單:內置的Web界面功能較為基礎,對于復雜的數據可視化和分析需求,可能需要使用額外的工具如Grafana。
9.3 最佳實踐
?避免過度使用標簽:雖然標簽非常強大,但是每增加一個標簽都會增加數據庫的負擔。應當仔細考慮哪些標簽是必要的。
?精心設計警報規則:警報規則應當既不過于寬松也不過于嚴格,以避免錯過重要事件或產生過多噪音。
?利用服務發現:充分利用Prometheus的服務發現功能,自動監控動態變化的目標,減少手動配置工作。
?整合Grafana進行數據可視化:Prometheus本身的界面比較簡單,通過整合Grafana可以提供更豐富的數據可視化功能。
?規劃數據保留策略:根據監控數據的價值和存儲成本,合理規劃數據的保留周期。
?數據持久化策略:考慮集成長期存儲解決方案,如Thanos或Cortex,以處理長期數據存儲需求。
9.4 應用場景
?云原生應用監控:特別適合監控微服務、容器(如Docker),以及Kubernetes等云原生技術棧。
?基礎設施監控:適用于監控服務器的系統指標,如CPU、內存使用率,以及網絡流量等。
?應用性能監控(APM):可用于收集和分析應用程序的性能指標,如請求延遲、事務吞吐量等。
?業務指標監控:除了技術指標外,Prometheus也可以用來監控業務層面的關鍵指標,如訂單量、支付事務等。
?動態服務發現環境:在頻繁變化的服務部署環境中,Prometheus的自動服務發現功能可以大大簡化監控配置的復雜度。
10. Milvus
Milvus是一個開源的向量數據庫,旨在為機器學習、人工智能和相似性搜索提供高效、可擴展的解決方案。它支持多種索引算法,可以處理億級別的數據集和實時的數據插入,是企業和研究機構處理大規模向量數據的理想選擇。
?

10.1 優點
?高性能:Milvus專為向量檢索設計,通過索引加速查詢,支持毫秒級別的向量搜索響應。
?易于使用:提供了豐富的客戶端API(如Python、Java、Go等),簡化了與其他應用的集成。
?可擴展性:支持水平擴展和垂直擴展,可以根據需要增加節點以提高處理能力。
?容錯性和高可用性:通過數據復制和分片機制,確保數據的安全和服務的可用性。
?強大的社區支持:作為一個開源項目,Milvus 擁有活躍的社區和持續的開發支持。
10.2 缺點
?資源消耗:為了實現高效的搜索,Milvus 可能需要較多的計算和內存資源。
?學習曲線:雖然易于使用,但要充分利用其功能,用戶可能需要對向量檢索的原理有一定了解。
?新產品挑戰:相對較新,社區雖然活躍但不如成熟數據庫廣泛,一些邊緣情況可能缺少現成的解決方案。
10.3 最佳實踐
?合理選擇索引:根據數據量和查詢需求選擇合適的索引類型,以平衡檢索速度和資源消耗。
?批量操作:盡可能使用批量插入和檢索,以提高效率。
?數據預處理:在數據插入前進行適當的預處理,如向量歸一化,可以提高檢索的準確性。
?監控和調優:監控系統性能,并根據實際情況調整配置,例如索引參數、緩存大小等。
10.4 應用場景
?圖像檢索:在海量圖像中快速找到與目標圖像相似的圖片。
?推薦系統:根據用戶的歷史行為和偏好,從大量商品或內容中檢索出相似的推薦項。
?自然語言處理:對文本內容進行向量化后,支持高效的語義搜索和文本相似度比較。
?生物信息學:在蛋白質序列、基因組數據等生物大數據中進行高效的相似性搜索。
11. Polyglot Persistence
在實際環境中,多種數據庫經常一起使用。使用單一的關系數據庫雖仍然很常見,但當前流行的做法是同時使用幾種數據庫,利用它們各自的長處,創建一個生態系統,比其各部分的功能總和更強大、更全面、更健壯,《七周七數據庫》的作者稱這種做法叫做多持久并存(Polyglot Persistence)。使用多持久并存,可以在同一系統中利用多種數據庫的優勢,以實現更高效的數據存儲和管理。
11.1 常見多持久并存場景
互聯網業務的主要場景是通過MySQL進行數據存儲,并且為了應對高并發場景,緩存也是必不可少的。因此,最常用的解決方案就是結合MySQL和Redis。
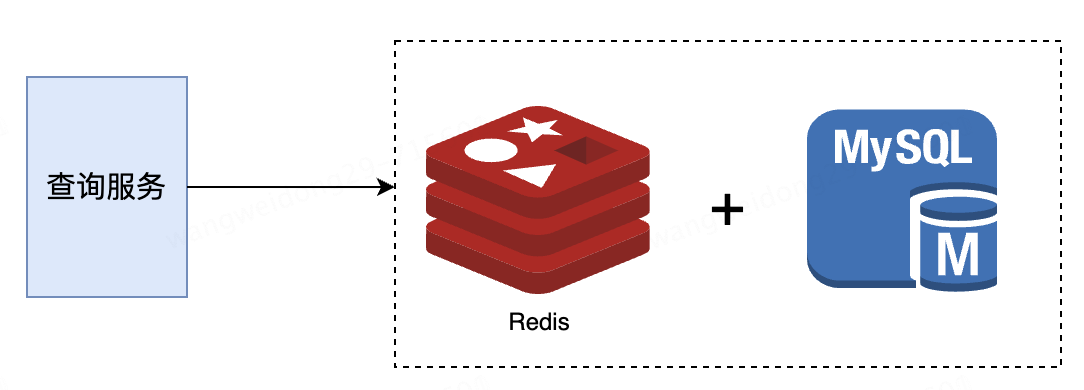
適用于日常主要場景:
?MySQL滿足事務性要求
?Redis抗熱點
11.2 海量數據多持久并存場景
數據量級在10億以上,并且每天新增的數據量仍在千萬級別以上持續增長。由于數據量非常大,需要考慮存儲成本和擴展性,并且在生產系統中,需要能夠支持海量數據的秒級查詢。
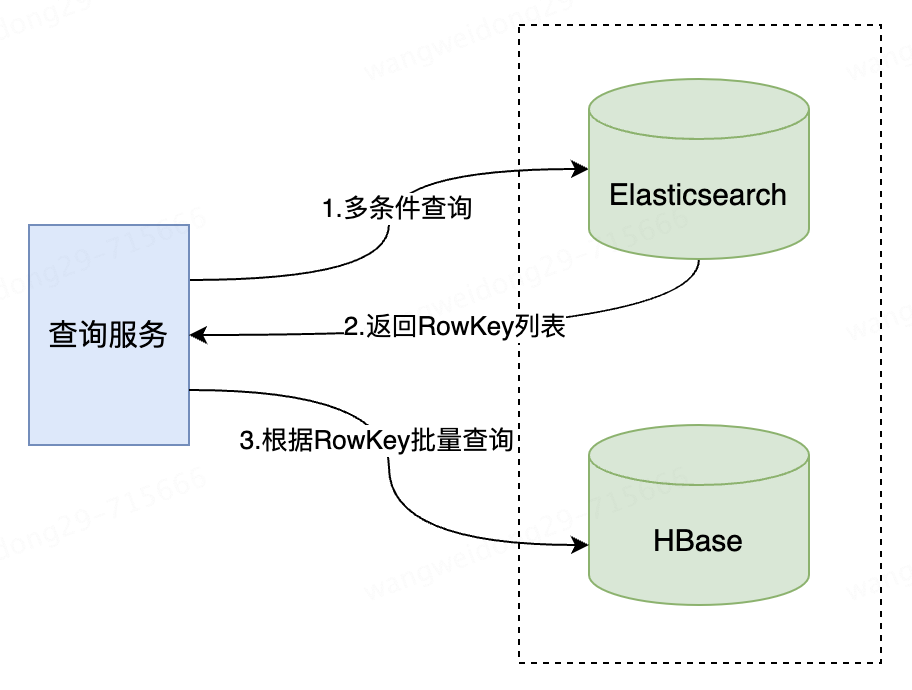
11.2.1 HBase + ElasticSearch
針對查詢場景簡單且查詢QPS不高,可考慮直接使用HBase。比如僅根據RowKey取Value場景直接讀取即可。對于列較少且有固定查詢模式的場景,若是直接引入ES/Solr,有”殺雞用牛刀”之感,其實可以維護二級索引或者采用phoenix(支持SQL)。
雖然HBase之上有很多開源組件,可以搞二級索引、phoenix可以支持SQL,但是當業務越來越復雜,數據量越來越大的時候,使用HBase構建復雜的查詢就很吃力了,甚至很多指標無法完成,畢竟HBase本身就不是為復雜查詢而生的,太折騰它也不好,所以這種情況下ES就起了關鍵性因素,使用HBase存儲海量數據,使用ES解決復雜查詢,發揮各自中間件的最大優勢。面對海量數據的低成本存儲+高效檢索的需求,業界通常使用HBase + ElasticSearch的組合方案。
此時可能有人會想,直接將所有字段都放入ES,豈不是都不用引入HBase了?所有字段都放入ES,在不考慮硬件成本,內存無限大的情況下,其實也可以,但是在現實場景下,必須考慮成本,就意味著內存是有限的。在內存資源有限的情況下,如何最大發揮ES的性能,其實算是使用ES的一種優化方案(ES很強大,需要深入掌握ES,可以根據不同場景進行優化設計),下面我們來看一下。
比如說現在有一行數據,orderNo、accountNo、receivedTime …等有400個字段,但是現在搜索,只需要根據accountNo、 receivedTime…等100個字段來搜索,如果往ES里寫入一行數據的所有字段,就會導致75%的數據是不用來搜索的,但結果是占據了ES機器上的 filesystem cache 的空間,單行數據的數據量越大,就會導致 filesystem cahce 能緩存的數據就越少,緩存的數據越少查詢性能就會越差,所以僅僅只是寫入ES中要用來檢索的字段就可以了。從ES中根據條件查詢獲取到每頁的docId,然后根據docId到HBase里去查詢每個docId對應的完整的數據(ES中的docId對應HBase里的RowKey),再返回給客戶端。從ES檢索可能花費50ms,然后再根據ES返回的docId去HBase里查詢,查10條數據,可能耗費30ms,每次查詢就是80ms,若是幾T的數據全都存ES,可能每次查詢都是1000~5000毫秒。總結一下就是“各司其職”,HBase就用來存儲,ES就用來做索引。
另外,在數據量小的情況下,單ES架構的性能是優于HBase + ES架構的,但是數據量小,建議直接用MySQL。
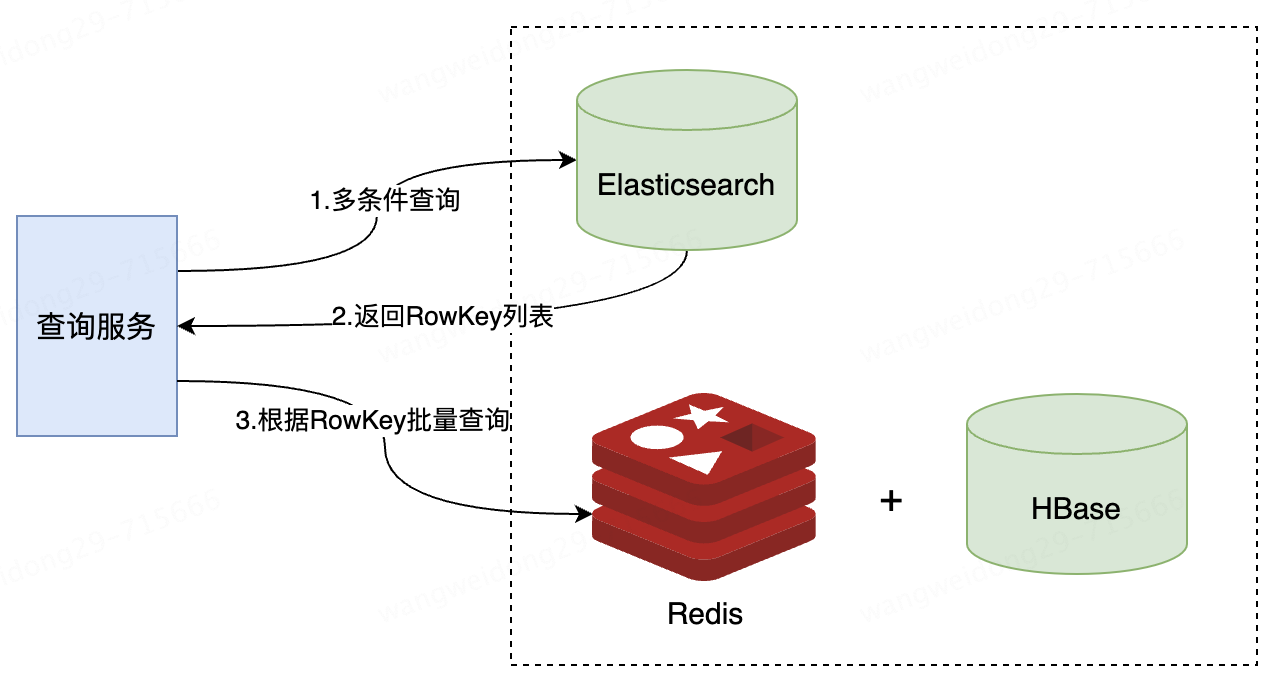
11.2.2 HBase + Redis + ElasticSearch
HBase底層架構的設計決定了HBase對高并發查詢場景支撐不足,為了扛住高并發場景,也需要引入緩存,解決方案就是HBase + Redis。若此時查詢復雜度也高,則再引入ES,解決方案就變成了HBase + Redis + ES。
11.3 物流交易訂單中心多持久并存實踐
在訂單中心的建設初期,系統的設計往往以簡單有效為原則。當日均單量不足10萬時,系統的處理需求相對較低,因此一個基于MySQL的關系數據庫配合Redis作為緩存的架構通常可以滿足需求。MySQL提供了可靠的事務支持和一致性保證,而Redis則可以提升讀取性能,緩解數據庫的壓力。
隨著業務的快速增長和日均單量的劇增至1000萬以上,原有架構開始面臨性能瓶頸和成本問題。此時,架構需要進行升級以應對以下挑戰:
海量數據存儲:原有的MySQL可能無法高效地處理海量數據。此時,引入HBase分布式數據庫,它擅長處理大規模數據集,提供了線性擴展的能力,并且HBase硬件成本相對MySQL極低。
復雜查詢優化:隨著查詢復雜度的提升,MySQL可能無法滿足快速響應的需求。ElasticSearch (ES) 作為一個搜索引擎,可以提供快速的全文搜索和復雜查詢功能。
成本控制:海量數據帶來硬件成本的突增,為了控制成本,高成本的MySQL從事務處理核心轉移到大數據抽數場景,降低MySQL配置和啟用MySQL壓縮存儲。待數據入湖后,銷毀MySQL,可節省70萬元/年。
削峰寫入:為了平滑高峰期的數據寫入壓力,繼續使用Redis作為緩存,并引入消息隊列以實現異步處理訂單提升系統吞吐量,同時流量削峰減輕直接請求ES、HBase、數據庫的壓力。
隨著業務的發展,訂單中心的架構從一個單一數據庫和緩存的簡單模型,逐步演變為一個包含專門搜索引擎、分布式存儲和緩存削峰的復雜系統。每一次架構的調整都是為了解決具體的痛點,提高系統的可擴展性、穩定性和成本效率。
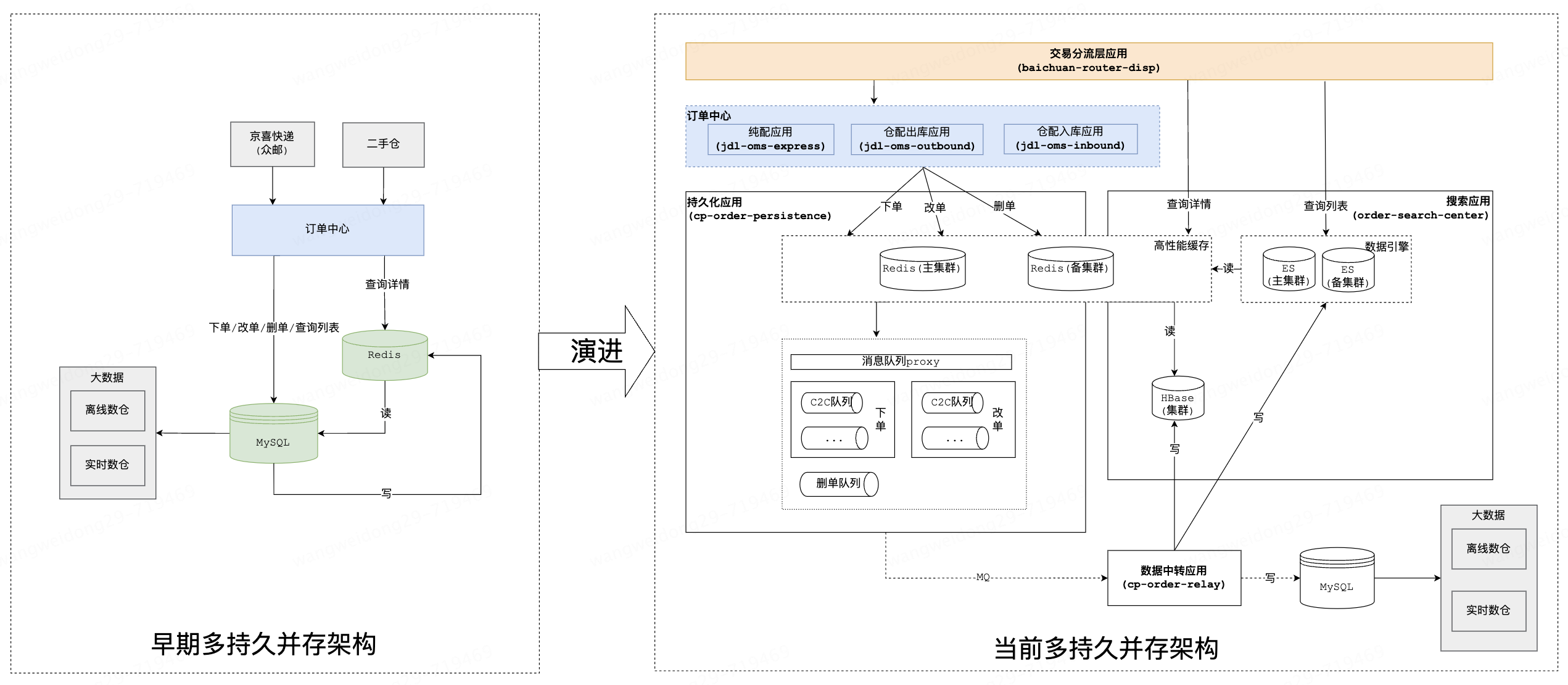
從上圖可以看出,訂單中心早期的架構對應是11.1章節的場景,經過演進,架構升級到11.2.2章節的場景,架構的演進是一個持續的過程,不是一蹴而就的。
關于當前訂單中心多持久并存架構的更多細節,建議查閱《交易日均千萬訂單的存儲架構設計與實踐》,該文章詳細介紹了相關的設計與實踐經驗。
12. 結束語
在數字化時代,數據已經成為企業的核心資產,如何有效地存儲、管理和分析這些數據是每個企業面臨的巨大挑戰。本文詳細探討了九種不同類型的數據庫,包括關系型數據庫(RDBMS)、鍵-值存儲數據庫、面向列的數據庫、面向文檔的數據庫、圖數據庫、時間序列數據庫(TSDB)和向量數據庫。通過對這些數據庫的特點和應用場景的深入分析,希望為大家在選擇數據庫時提供有價值的參考。
關系型數據庫(如MySQL)以其嚴格的事務性和一致性,長期以來在企業應用中占據主導地位。然而,隨著互聯網和大數據的興起,非關系型數據庫(NoSQL)因其靈活的數據模型和良好的擴展性,逐漸在特定場景下獲得了廣泛應用。鍵-值存儲數據庫(如Redis)以其高性能和簡單的數據模型,適用于緩存和會話管理等場景;面向列的數據庫(如HBase和ClickHouse)則在處理大規模數據分析和實時查詢方面表現出色;面向文檔的數據庫(如MongoDB和ElasticSearch)提供了靈活的數據存儲和查詢能力,適合處理半結構化數據;圖數據庫(如Neo4j)在處理復雜關系和圖形數據時具有獨特優勢;時間序列數據庫(如Prometheus)則專為處理時間序列數據設計,廣泛應用于監控和性能分析;而向量數據庫則為AI和機器學習應用提供了高效的數據索引和檢索能力。
數據庫選型不僅需要考慮技術需求,還需綜合考慮團隊的技能棧、成本預算、社區支持和生態系統。每種數據庫都有其獨特的優勢和適用場景,理解這些特點并根據具體業務需求做出明智的選擇,是每個數據庫專家和技術決策者的重要任務。
在本文的結尾,希望大家能夠通過對各種數據庫的了解,掌握它們的獨特優勢和適用場景,從而在面對不同的使用場景時做出最佳決策。無論是選擇傳統的關系型數據庫,還是探索新型的NoSQL數據庫和專用數據庫,都應基于具體的業務需求和技術環境,充分發揮每種數據庫的優勢,為企業的數據管理和分析提供強有力的支持。
未來,隨著技術的不斷進步和數據量的持續增長,數據庫技術也將不斷演進。鼓勵大家持續關注數據庫領域的新發展,不斷學習和實踐,以應對不斷變化的技術環境和業務需求。通過合理的數據庫選型和優化,企業可以更好地利用數據驅動業務創新和增長,迎接數字化時代的挑戰和機遇。
13. 相關文檔和推薦讀物
官方文檔是學習任何技術的最佳起點,建議閱讀官方文檔。
1.MySQL官方文檔:https://dev.mysql.com/doc/?
2.Redis官方文檔:https://redis.io/docs/latest/?
3.HBase官方文檔:https://hbase.apache.org/book.html?
4.ClickHouse官方文檔:https://clickhouse.com/docs/zh?
5.MongoDB官方文檔:https://www.mongodb.com/zh-cn/docs/?
6.Elasticsearch官方文檔:https://www.elastic.co/docs?
7.Neo4j官方文檔:https://neo4j.com/docs/?
8.Prometheus官方文檔:https://prometheus.io/docs/introduction/overview/?
9.Milvus官方文檔:https://milvus.io/docs?
?
以下是一些優秀書籍:
《高性能MySQL》- Baron Schwartz, Peter Zaitsev, Vadim Tkachenko
?深入探討了MySQL的性能優化、架構設計、復制和備份等高級主題,適合有經驗的數據庫管理員和開發者。
《Redis in Action》- Josiah L. Carlson
?是一本非常適合想要深入了解Redis并將其應用于實際項目的開發者閱讀的書籍。
《HBase in Action》- Nick Dimiduk, Amandeep Khurana
?通過實例講解了HBase的使用方法和最佳實踐,包括數據模型設計、應用開發、性能優化等。適合有一定基礎,希望通過實戰學習HBase的讀者。
《ClickHouse原理解析與應用實踐》- 朱凱
?從基礎到原理、從理念到實踐都有介紹,初中級讀者通過這一本書就能掌握ClickHouse。
《MongoDB權威指南》- Kristina Chodorow
?詳細介紹了MongoDB的使用和優化技巧,適合想要深入了解MongoDB的讀者。
《Elasticsearch權威指南》- Clinton Gormley, Zachary Tong
?這是一本非常全面的Elasticsearch學習資料,從基礎概念、數據管理到查詢和索引設計,都有詳細的介紹。雖然是基于較舊版本的Elasticsearch,但基本概念和使用方法仍然適用。最新版《Elasticsearch in Action》- Madhusudhan KondaMadhusudhan Konda
《Graph Databases》- Ian Robinson, Jim Webber, and Emil Eifrem
?這本書由Neo4j的創始人之一共同撰寫,全面介紹了圖數據庫的概念、原理和實踐應用,是理解圖數據庫的優秀入門書籍。
《Prometheus: Up & Running》- Brian Brazil
?由Prometheus的主要貢獻者之一編寫,這本書提供了關于如何在你的組織中部署和使用Prometheus的全面指南。它涵蓋了Prometheus的核心概念、配置、查詢語言PromQL以及如何構建和維護可靠的警報規則。
《Vector Databases Unleashed: Navigating the Future of Data Analytics》 - Raj C Vaidyamath
?該書深入探討了向量數據庫在現代數據分析中的重要性和潛力。作者通過介紹向量數據庫的基本原理、技術架構以及實際應用場景,幫助讀者理解如何利用向量數據庫來解決復雜的數據分析問題。
審核編輯 黃宇
-
數據庫
+關注
關注
7文章
3904瀏覽量
65818 -
數字化
+關注
關注
8文章
9328瀏覽量
63117 -
MySQL
+關注
關注
1文章
849瀏覽量
27607
發布評論請先 登錄
HarmonyOS5云服務技術分享--云數據庫使用指南
數據庫數據恢復——MongoDB數據庫文件拷貝后服務無法啟動的數據恢復
中興通訊GoldenDB數據庫助力首個住房公積金國產數據庫聯合實驗室落地揚州
SOLIDWORKS 2025教育版有效的數據管理與團隊協作
三品PDM產品數據管理系統:驅動企業高效協同與數字化轉型的核心引擎
云數據庫是哪種數據庫類型?
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

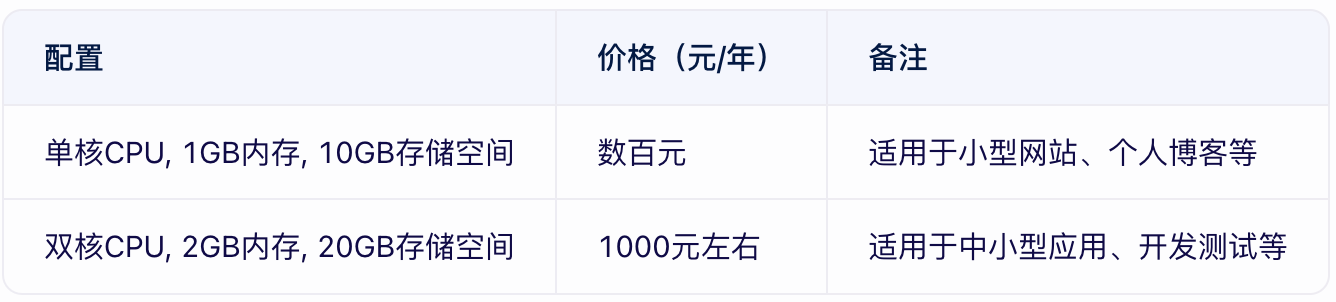
云數據庫價格貴嗎?云數據庫租用價格表
架構師日記-從數據庫發展歷程到數據結構設計探析

降本增效、極簡體驗!828 就選華為云 Flexus 云數據庫 RDS





 工商網監
工商網監
評論