") AI繪圖實踐-用人工智能生圖助力618大促
AI繪圖實踐-用人工智能生圖助力618大促
現在各種AI大模型大行其道,前有GhatGPT顛覆了我們對對話型AI的原有印象,后有Sora文生視頻,讓我們看到了利用AI進行創(chuàng)意創(chuàng)作的無限可能性。如今各大公司和團隊都爭相提出自己的大模型,各種網頁端和軟件應用也極大地降低了我們使用AI作為生產力的門檻。
我這次就為大家?guī)硎褂肁I進行繪圖的入門實踐,為大促文章配圖,繪制大促廣告宣傳海報,提升促銷圖的畫質和精度,探索一下從這方面助力大促的新思路。
平臺
現在的AI繪圖主要用到的模型是SD(Stable Diffusion),它是一種穩(wěn)定擴散模型,用于生成高質量的圖像。這種模型是在傳統(tǒng)的擴散模型DDPMs(Denoising Diffusion Probabilistic models)的基礎上發(fā)展出來的。
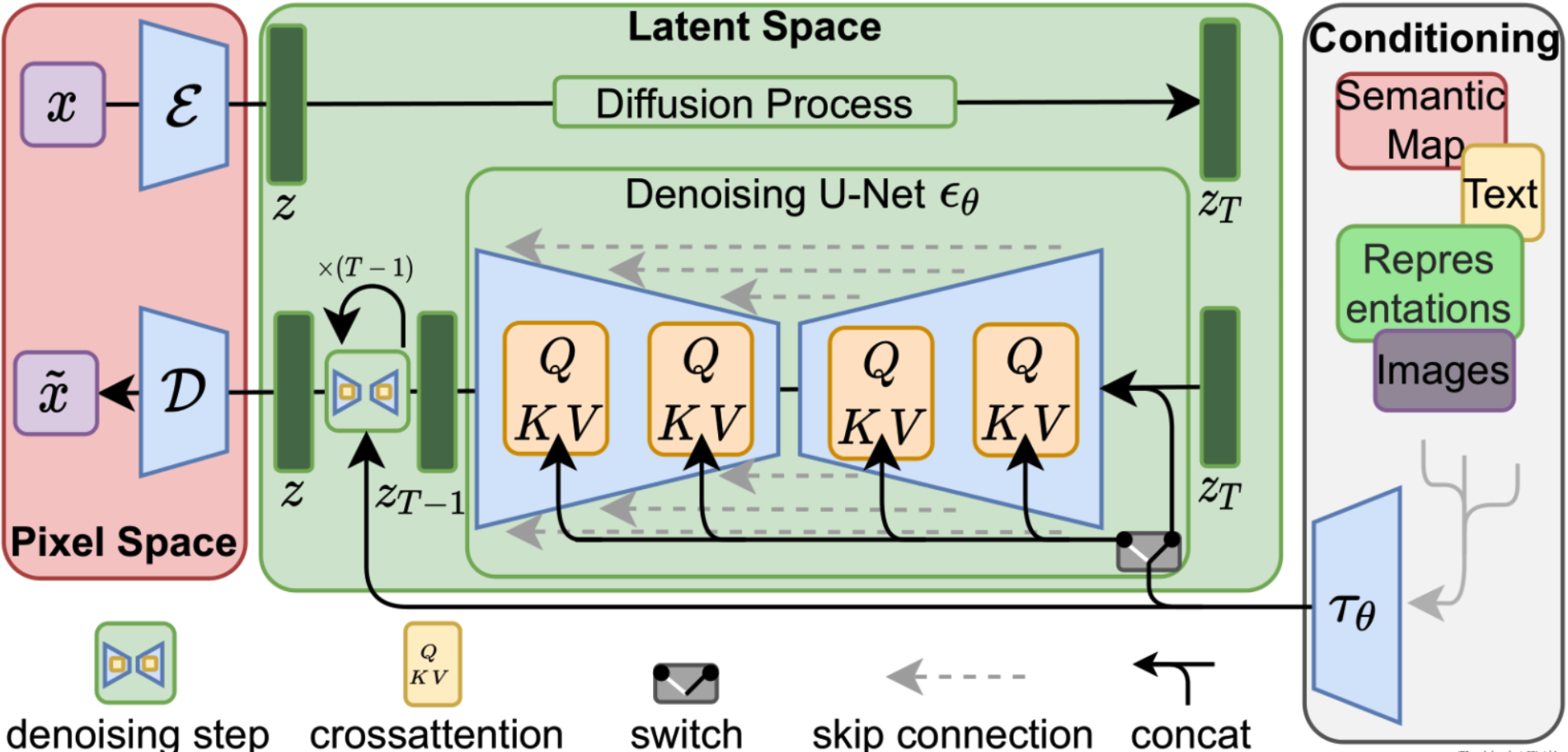
經過多個版本的迭代和改進,這類模型已經能很好的執(zhí)行“文生圖”、“圖生圖”、“后期處理”等AI功能,甚至可以在一定程度上代替PhotoShop等圖像處理軟件的工作。
現在許多開發(fā)者都發(fā)布了基于SD模型的改進型模型,基本上所有的網頁端和軟件也都是基于此模型搭建的,要使用它進行AI繪畫,主要有三種方法:
1.自己搭建基于SD的webui,在gitHub上有項目的源代碼: https://github.com/AUTOMATIC1111/stable-diffusion-webui 。這種方式的優(yōu)點是自由度高,可以根據自己的需求進行客制化改造,更新也最及時,但是要自己進行環(huán)境搭建,對于一般用戶來說學習門檻較高,國內使用的話需要魔法,同時經過我的體驗穩(wěn)定性不高,經常會失敗。
2.使用網頁端應用,這類網站是基于stable-diffusion-webui 搭建的第三方平臺,由他們負責維護和更新,并提供穩(wěn)定的連接,用戶只需要選擇需要的模型和參數,輸入提示詞,就可以在線生成圖片。
國內有:
Liblib Ai: https://www.liblib.art/
MJ: https://mj.wxcbh.cn/home/?from=AI05&strategy=drawing5&bd_vid=17724435435623318479#/mj
都不需要魔法 。
國外的像:Playground AI: https://playground.com/ ,每天有免費的體驗次數,速度和質量也不錯。
這類網站一般都有自己的模型市場,以供創(chuàng)作者們上傳和下載自定義的模型,并且分享自己的繪圖作品以及相關生圖的參數,非常方便。但是一般都會收費,都會收費,都會收費,重要的事情說三遍。
3.PC端軟件,這類軟件一般也是基于SD模型進行封裝,可以下載模型,設置參數并在本地生成圖片,使用體驗類似于PS等圖片處理軟件,但是由于整個生成過程在本地執(zhí)行,比較依賴于本機算力,電腦性能不好的話生成會很慢,但是好處就是自定義程度相對較高,而且一般免費。
生圖軟件
我這次主要介紹軟件的途徑,使用的軟件就是這款Draw Things,Mac端App Store免費下載,不需要魔法
他的界面是這樣的:
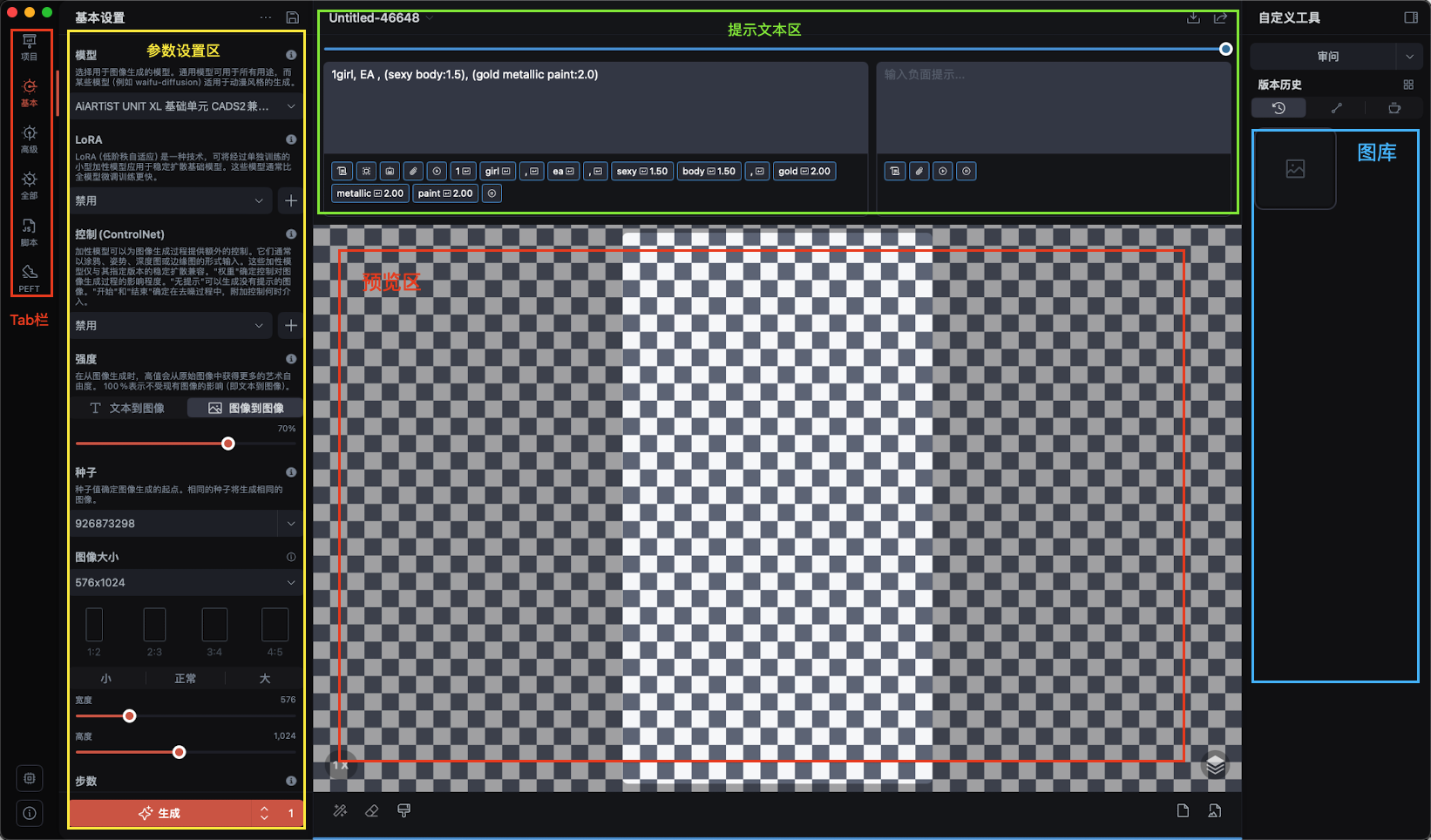
參數設置區(qū)用于選擇模型,采集器,步數和隨機種子等參數,首次生成圖片首先選擇“文本到圖像”模式。在這里我大致介紹一下涉及到的名詞:
模型
模型是AI繪畫的基礎,一般的模型都是基于SD改進的,SD模型也有V1.0、V1.5、V2.0、V2.1等不同的迭代版本,不同的模型可以生成不同風格的圖片,可以根據自己的需要進行選擇,模型可以在DrawThings里進行下載和選擇,當然也可以在Liblib Ai等網站上下載然后導入。
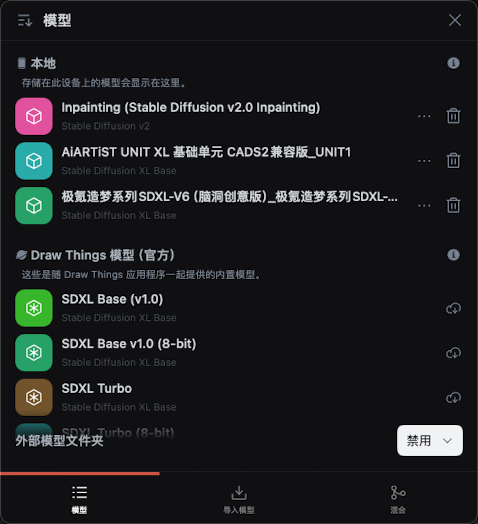
模型分為幾個主要的種類:
chekpoint(檢查點)
它是完整模型的常見格式,模型體積較大,一般真人版的單個模型的大小在7GB左右,動漫版的在2-5個G之間。決定了圖片的整體風格。chekpoint的后綴名是safetensors
有寫實,科幻,漫畫,廣告等等風格
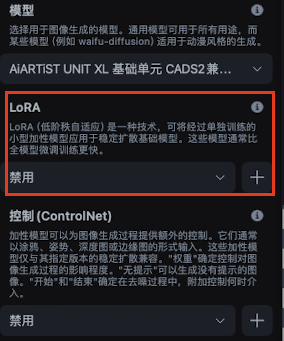
是一種體積較小的繪畫模型,是對大模型的微調。可以添加Lora為圖片創(chuàng)造更豐富的表現形式。與每次作畫只能選擇一個大模型不同,lora模型可以在已選擇大模型的基礎上添加一個甚至多個。一般體積在幾十到幾百兆左右。
Lora的后綴名也是safetensors,所以在安裝的時候要注意,Lora要在規(guī)定的地方導入:
Hypernetwork(超網絡)
類似 LoRA ,但模型效果不如 LoRA,不能單獨使用,需要搭配大模型使用
?
采樣器
采樣器也會在一定程度上影響圖畫風格,不同于模型,它一般是基于算法。選擇對的采樣器對于生成圖片的質量至關重要,下面介紹一些主流的采樣器類型:
DDIM和PLMS是早期SD專為擴散模型而設計的采樣器。DPM和DPM++系列是專為擴散模型而設計的新型采樣器。DPM++是DPM的改進版。
Euler a 比較適用于圖標設計、二次元圖像、小型場景等簡單的圖像數據生成場景。
DPM和DPM++系列非常適用于三維景象和復雜場景的描繪,例如寫實人像。
Karras系列是專為擴散模型而設計的改進版采樣器,有效提升了圖片質量。
Euler a,DPM2 a, DPM++2S a和DPM++2S a Karras適合給圖片增加創(chuàng)造性,隨著迭代步數的提升,圖片也會隨之變化。不同的采樣方法可能對不同的模型產生不同的影響,會影響生成圖片的藝術風格,建議結合模型和迭代步數多做嘗試。
步數
生圖時,去噪重復的步數被稱為采樣迭代步數。
測試新的模型或Prompts效果時,迭代步數推薦使用10~15,可以快速獲得結果,方便進行調整。當迭代步數太低時,生成的圖像幾乎無法呈現內容。20 ~ 30之間的迭代步數通常會有不錯的效果。40步以上的迭代步數會需要更長的生圖時間,但收益可能有限,除非在繪制動物毛發(fā)或皮膚紋理等。
過低或過高的初始分辨率都可能會讓SD生圖時無法正常發(fā)揮,建議參考基礎模型的分辨率,配置合適的初始寬高
隨機種子
隨機種子會影響生圖時的初始噪聲圖像。
當Seed=-1時,表示每次出圖都會隨機一個種子,使得每次生成的圖都會不同。其他創(chuàng)作者上傳圖片的時候,一般會附帶此圖片對應的隨機種子,可以參考它來生成類似的圖片。點擊可以生成一個隨機的種子,長按則可以輸入特定的隨機種子。
提示詞
提示詞是生成圖片時關鍵中的關鍵,它直接決定了圖片內容,畫面風格,場景,表情動作等一些列內容,在生成圖片時,選擇合適的提示詞至關重要。

提示詞分為“正向提示詞”和“反向提示詞”,“正向提示詞”代表你想要在圖片中呈現的內容,反之“反向提示詞”則是不想要在圖片里具備的要素。
比如,我想要畫一張“618西瓜大促”相關的宣傳圖,我就可以這樣描述:
“許多人在湖里流動的水邊吃西瓜,高質量的微型攝影”,翻譯成英文:“Many people eat watermelons by the flowing water in the lake, with high-quality miniature photography”
將這段文字輸入DrawThings的文本框,它會自動把整句話拆分成一個個提示詞。
當然,我們也可以直接填入想要繪制的提示詞:
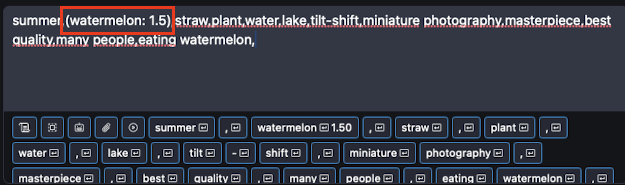
如上圖所示,如果我們想著重強調某一個提示詞,讓AI繪制的時候更偏重一這一特征,就可以用括號把它包起來,然后在后面注明權重,這里我就把西瓜(watermelon)加重到了1.5權重,以便更加突出這一點。
“反向提示詞”一般有:低質量,不適合上班時間瀏覽(NSFW),描繪人物的時候,糟糕的眼睛,多余的手指,扭曲,變形等等

其他
還有一些其他的參數,比如圖片分辨率和比例,文本指導強度(越高越忠實呈現文本內容),以及一次生成的圖片數量等等
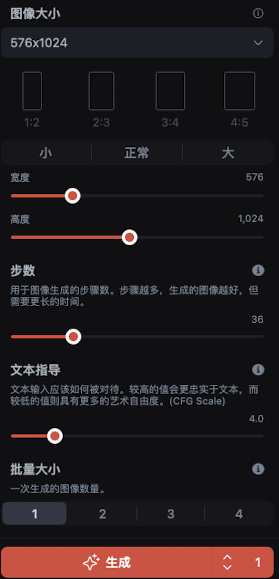
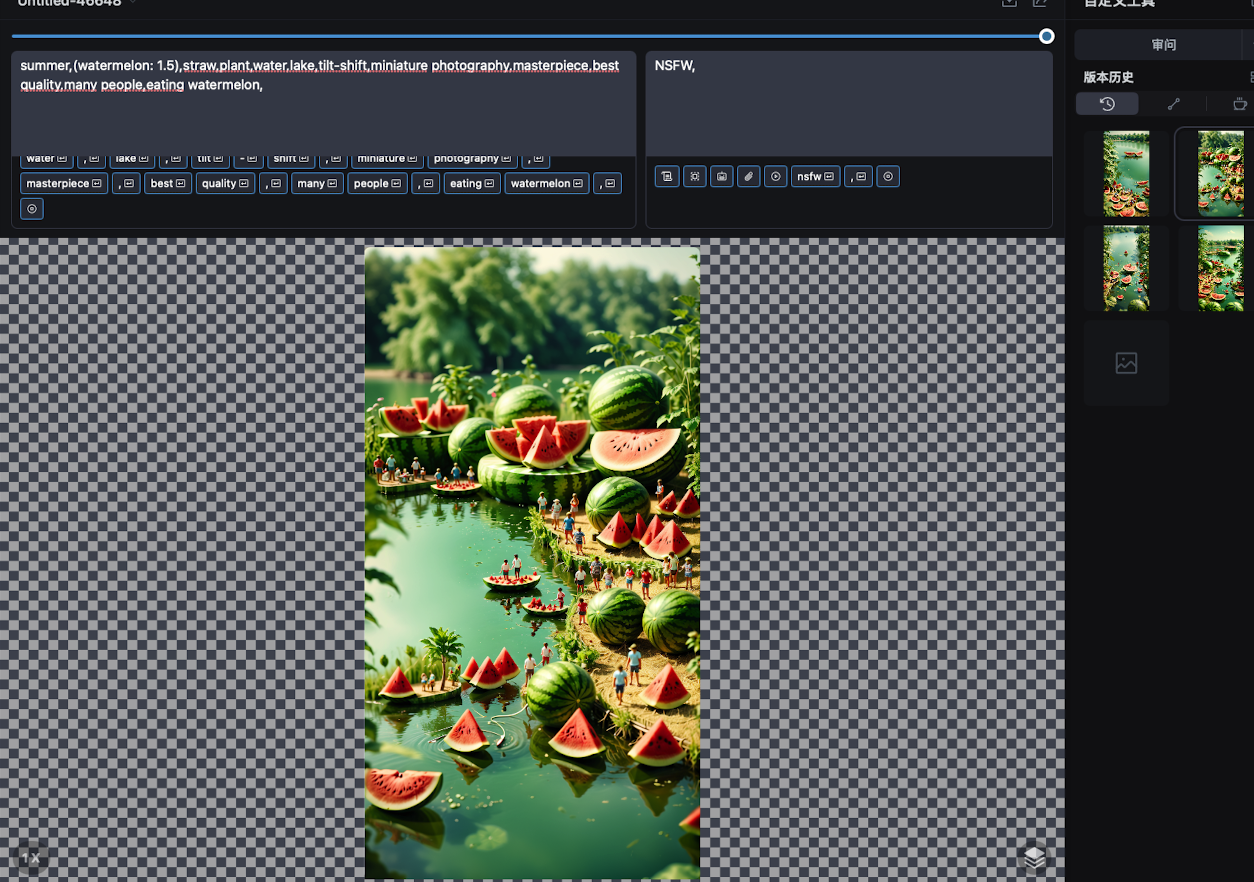
設置好一切,就可以開始生成圖片了,可以多嘗試幾張,從中挑選最合適的進行二次處理。
?
二次處理
如果對生成的圖片有些細節(jié)不滿意,可以利用“圖像到圖像”模式,然后選擇強度。高分辨率修復的重繪強度為0時不會改變原圖,30% 以下會基于原圖稍微修正,超過 70% 會對原圖做出較大改變,1 會得到一個完全不同的圖像。
二次處理主要包括以下幾個目的:
重繪圖像元素
如果對圖像中某部分的元素不滿意,可以用“橡皮擦”擦除該部分,然后重新生成,讓模型自動將擦數的部分重繪,甚至可以消除某部分圖像元素,實測效果甚至好于PS。
擴圖
對于一張圖片,如果想要擴展邊界部分,讓模型繪制出額外的內容,可以首先重新設置圖片的寬高。我這里原是圖片是1088*2048,想要擴展左側湖里的景象,就可以先將圖片寬度增加到1536,然后移動圖片到右側貼緊圖層邊緣。然后最關鍵的一步,用“橡皮擦”工具,沿著想要擴展的那一邊,細細的擦一道,這么做的目的是告訴模型,從這一部分開始重繪,風格要按照擦除的這部分來進行,然后重新生成?
提升畫質
最開始生成圖片時,為了提高速度和效率,可以適當降低分辨率,的到合適的圖片以后,可以重設分辨率和清晰度,重繪圖片,達到提升畫質的目的。當然,對于已經已經畫好的第三方圖片,也可以加載進來進行處理。
好了,本篇利用AI繪圖進行實踐的文章就介紹到這里,希望能夠幫助到大家。在以后大促文章配圖,和大促海報繪制方面為大家提供便利,助力618大促再創(chuàng)新高!
-
AI
+關注
關注
88文章
34421瀏覽量
275800 -
人工智能
+關注
關注
1804文章
48788瀏覽量
247008
發(fā)布評論請先 登錄
開售RK3576 高性能人工智能主板
AI人工智能隱私保護怎么樣

智慧路燈如何應用人工智能技術

嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創(chuàng)新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創(chuàng)新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創(chuàng)新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅動科學創(chuàng)新》第一章人工智能驅動的科學創(chuàng)新學習心得
risc-v在人工智能圖像處理應用前景分析
人工智能ai4s試讀申請
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創(chuàng)新
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
阿丘科技成功入選“北京市通用人工智能產業(yè)創(chuàng)新伙伴計劃”,AI+工業(yè)視覺實力再獲肯定






 工商網監(jiān)
工商網監(jiān)
評論