 pycharm如何訓練機器學習模型
pycharm如何訓練機器學習模型
PyCharm是一個流行的Python集成開發環境(IDE),它提供了豐富的功能,包括代碼編輯、調試、測試等。在本文中,我們將介紹如何在PyCharm中訓練機器學習模型。
一、安裝PyCharm
- 下載PyCharm :訪問JetBrains官網(https://www.jetbrains.com/pycharm/download/),選擇適合您操作系統的版本進行下載。
- 安裝PyCharm :運行下載的安裝程序,按照提示完成安裝。
- 啟動PyCharm :安裝完成后,啟動PyCharm。
二、配置Python環境
- 創建項目 :在PyCharm中,點擊“Create New Project”,選擇項目類型(例如Python),設置項目路徑,然后點擊“Create”。
- 配置解釋器 :在項目創建完成后,需要配置Python解釋器。點擊右上角的“Settings”(或“Preferences”在Mac上),然后選擇“Project: YourProjectName” > “Python Interpreter”。
- 添加庫 :在Python Interpreter頁面,點擊“+”號添加所需的庫,例如NumPy、Pandas、Scikit-learn等。
- 安裝庫 :在庫列表中,選中需要安裝的庫,然后點擊右側的“Install Package”按鈕進行安裝。
三、數據預處理
- 導入數據 :使用Pandas庫導入數據集。例如,從CSV文件導入數據:
import pandas as pd
data = pd.read_csv('data.csv')
- 數據清洗 :處理缺失值、異常值等。
data = data.dropna() # 刪除缺失值
data = data[data['column'] != '異常值'] # 刪除異常值
- 特征工程 :創建新特征或轉換現有特征。
data['new_feature'] = data['existing_feature'] ** 2
- 數據劃分 :將數據劃分為訓練集和測試集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data.drop('target', axis=1), data['target'], test_size=0.2, random_state=42)
四、模型訓練
- 選擇模型 :選擇一個適合問題的機器學習模型。例如,使用邏輯回歸:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
- 訓練模型 :使用訓練集數據訓練模型。
model.fit(X_train, y_train)
- 特征重要性 :查看模型的特征重要性。
importances = model.coef_[0]
feature_names = X_train.columns
importance_dict = dict(zip(feature_names, importances))
五、模型評估
- 預測 :使用測試集數據進行預測。
y_pred = model.predict(X_test)
- 評估指標 :計算評估指標,如準確率、召回率、F1分數等。
from sklearn.metrics import accuracy_score, recall_score, f1_score
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
- 混淆矩陣 :生成混淆矩陣以可視化模型性能。
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
六、模型優化
- 超參數調優 :使用網格搜索(GridSearchCV)或隨機搜索(RandomizedSearchCV)等方法調整模型的超參數。
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.1, 1, 10], 'penalty': ['l1', 'l2']}
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
- 交叉驗證 :使用交叉驗證評估模型的穩定性。
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X_train, y_train, cv=5)
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
操作系統
+關注
關注
37文章
7113瀏覽量
125112 -
集成開發
+關注
關注
0文章
22瀏覽量
12181 -
機器學習模型
+關注
關注
0文章
9瀏覽量
2655
發布評論請先 登錄
相關推薦
熱點推薦
如何才能高效地進行深度學習模型訓練?
分布式深度學習框架中,包括數據/模型切分、本地單機優化算法訓練、通信機制、和數據/模型聚合等模塊。現有的算法一般采用隨機置亂切分的數據分配方式,隨機優化算法(例如隨機梯度法)的本地
機器學習訓練秘籍——吳恩達
``1 機器學習為什么需要策略?機器學習(machine learning)已然成為無數重要應用的基石——如今,在網絡搜索、垃圾郵件檢測、語音識別以及產品推薦等領域,你都能夠發現它的身
發表于 11-30 16:45
Pytorch模型訓練實用PDF教程【中文】
本教程以實際應用、工程開發為目的,著重介紹模型訓練過程中遇到的實際問題和方法。在機器學習模型開發中,主要涉及三大部分,分別是數據、
發表于 12-21 09:18
人工智能基本概念機器學習算法
目錄人工智能基本概念機器學習算法1. 決策樹2. KNN3. KMEANS4. SVM5. 線性回歸深度學習算法1. BP2. GANs3. CNN4. LSTM應用人工智能基本概念數據集:訓
發表于 09-06 08:21
什么是機器學習? 機器學習基礎入門
工程師在數據收集過程中使用標簽對數據集進行分類數據收集和標記是一個耗時的過程,但對于正確處理數據至關重要。雖然機器學習領域有一些創新,利用預先訓練的模型來抵消一些工作和新興的工具來簡
發表于 06-21 11:06
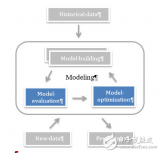
機器學習之模型評估和優化
監督學習的主要任務就是用模型實現精準的預測。我們希望自己的機器學習模型在新數據(未被標注過的)上取得盡可能高的準確率。換句話說,也就是我們希
發表于 10-12 15:33
?0次下載
超詳細配置教程:用Windows電腦訓練深度學習模型
雖然大多數深度學習模型都是在 Linux 系統上訓練的,但 Windows 也是一個非常重要的系統,也可能是很多機器學習初學者更為熟悉的系統
預訓練模型的基本原理和應用
預訓練模型(Pre-trained Model)是深度學習和機器學習領域中的一個重要概念,尤其是在自然語言處理(NLP)和計算機視覺(CV)
pycharm怎么訓練數據集
在本文中,我們將介紹如何在PyCharm中訓練數據集。PyCharm是一款流行的Python集成開發環境,提供了許多用于數據科學和機器學習的
AI大模型與傳統機器學習的區別
多個神經網絡層組成,每個層都包含大量的神經元和權重參數。 傳統機器學習 :模型規模相對較小,參數數量通常只有幾千到幾百萬個,模型結構相對簡單。 二、





 工商網監
工商網監
評論