") 算法與數(shù)據(jù)結(jié)構(gòu)——哈希表
算法與數(shù)據(jù)結(jié)構(gòu)——哈希表

周立功教授數(shù)年之心血之作《程序設(shè)計(jì)與數(shù)據(jù)結(jié)構(gòu)》以及《面向AMetal框架與接口的編程(上)》,書本內(nèi)容公開后,在電子行業(yè)掀起一片學(xué)習(xí)熱潮。經(jīng)周立功教授授權(quán),本公眾號(hào)特對(duì)《程序設(shè)計(jì)與數(shù)據(jù)結(jié)構(gòu)》一書內(nèi)容進(jìn)行連載,愿共勉之。
第三章為算法與數(shù)據(jù)結(jié)構(gòu),本文為3.5 哈希表。
>>>3.5.1 問題
假設(shè)需要設(shè)計(jì)一個(gè)信息管理系統(tǒng),用于管理大約一萬個(gè)學(xué)生的相關(guān)信息,可以通過學(xué)號(hào)查找到對(duì)應(yīng)學(xué)生的信息,每條學(xué)生記錄包含學(xué)號(hào)、姓名、性別、身高、體重等信息。即:

作為信息管理系統(tǒng),首先要能夠存儲(chǔ)學(xué)生記錄,這上萬條記錄如何存儲(chǔ)呢?簡單地,可以使用一段連續(xù)的內(nèi)存存儲(chǔ)學(xué)生記錄,比如,使用一個(gè)大數(shù)組存儲(chǔ),每個(gè)數(shù)組元素都可以存儲(chǔ)一條學(xué)生記錄:

當(dāng)使用數(shù)組存儲(chǔ)學(xué)生信息時(shí),如何通過學(xué)號(hào)查找相應(yīng)的信息呢?如果學(xué)號(hào)編排是一種非常理想的情況,10000個(gè)學(xué)生的學(xué)號(hào)按照 0 ~ 9999順序排列,則可以直接將學(xué)號(hào)作為數(shù)組的索引值查找相應(yīng)的數(shù)組元素,其存儲(chǔ)和查找的效率都非常高。但實(shí)際上學(xué)號(hào)往往不是如此簡單編排的,一種常見的編排方法是“年級(jí)+專業(yè)代碼+班級(jí)+班級(jí)內(nèi)序號(hào)”,比如,6字節(jié)學(xué)號(hào)為0x20, 0x16, 0x44, 0x70, 0x02, 0x39,即:201644700239,表示2016年入學(xué),專業(yè)代碼為4470(即計(jì)算機(jī)專業(yè)),2班的39號(hào)同學(xué)。
此時(shí),通過學(xué)號(hào)查找學(xué)生信息的方法也很簡單,直接從第一個(gè)學(xué)生記錄開始,順序遍歷各個(gè)學(xué)生記錄,將記錄中的學(xué)號(hào)與期望查找的學(xué)生學(xué)號(hào)相比較,學(xué)號(hào)相同即查找到了相應(yīng)學(xué)生的信息,詳見程序清單3.61。
程序清單3.61 順序查找范例程序

顯然,如果采用順序查找法,學(xué)生記錄越多,則查找時(shí)需要比較的次數(shù)越多,效率也就越低。當(dāng)學(xué)生記錄的條數(shù)上萬時(shí),則可能需要比較上萬次才能找到相應(yīng)的學(xué)生信息。
如何以更高的效率實(shí)現(xiàn)查找呢?在理想情況下,若將學(xué)號(hào)作為數(shù)組索引存儲(chǔ)數(shù)據(jù),則查找的效率非常高。既然如此,如果擴(kuò)大數(shù)組容量至學(xué)號(hào)的最大值加1(以包含學(xué)號(hào)0),則可以直接以學(xué)號(hào)作為數(shù)組的索引值。由于學(xué)號(hào)是由6字節(jié)組成的,因此數(shù)組必須能夠容納248條記錄,需要占用多少存儲(chǔ)空間呢?就算一條記錄只占用一個(gè)字節(jié),也需要262144 G存儲(chǔ)空間,何況電腦硬盤沒這么大!如果只使用其中的10000條記錄,則剩下的(248-10000)空間就會(huì)造成極大的浪費(fèi),顯然這種方式是不可取的。
在查找算法中,非常經(jīng)典高效的算法是“二分法查找”,按10000條記錄算,最多也只需要比較14次(log210000)。但使用“二分法查找”的前提是信息必須有序排列,即要求學(xué)生記錄必須按照學(xué)號(hào)的順序存儲(chǔ),這就導(dǎo)致在添加或刪除學(xué)生信息時(shí),數(shù)據(jù)庫存儲(chǔ)的信息需要進(jìn)行大量的移動(dòng)操作。比如,數(shù)組中已經(jīng)按照學(xué)號(hào)從小到大的順序存儲(chǔ)了9999條記錄,現(xiàn)在寫入第10000條記錄,若該記錄的學(xué)號(hào)最小,需要寫入到所有記錄的前面,這就需要將之前存儲(chǔ)的9999條記錄全部向后移動(dòng)一次,以預(yù)留出首元素的空間,然后將新的學(xué)生記錄寫入首元素對(duì)應(yīng)的空間中。由此可見,雖然使用這種方法可以提高查找效率,卻犧牲了添加信息時(shí)的效率。
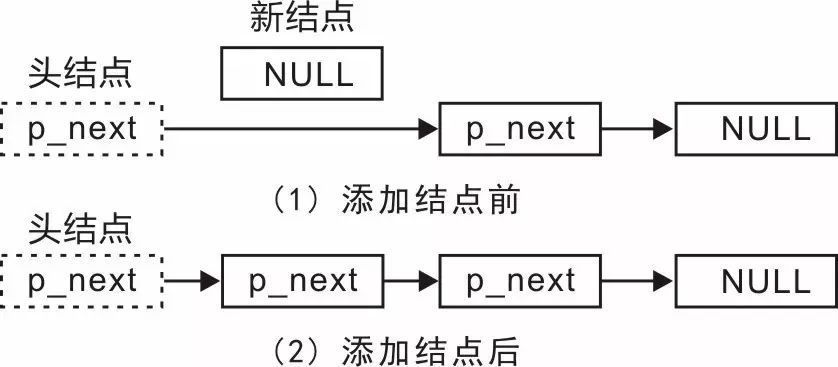
為了在添加信息時(shí)不進(jìn)行大量的數(shù)據(jù)移動(dòng),能否換一種存儲(chǔ)方式呢?比如,使用存儲(chǔ)空間不連續(xù)的“單向鏈表”結(jié)構(gòu),將各個(gè)學(xué)生記錄“鏈”起來,其示意圖詳見圖3.23。

圖3.23 使用單向鏈表管理學(xué)生記錄
當(dāng)使用鏈表管理學(xué)生記錄時(shí),實(shí)現(xiàn)有序排列只需每次插入新結(jié)點(diǎn)時(shí),找到正確的插入位置,無需進(jìn)行大量數(shù)據(jù)的移動(dòng)。由于存儲(chǔ)空間不連續(xù),因此無法使用“二分法”查找學(xué)生信息,則實(shí)現(xiàn)有序排列也沒有解決查找效率低下的問題,無論是否有序,查找時(shí)都需要從頭開始順序查找。
由此可見,使用“二分法查找”必須犧牲記錄寫入的效率以實(shí)現(xiàn)所有記錄有序排列,使得寫入記錄的效率非常低。雖然基礎(chǔ)的“順序查找”對(duì)寫入記錄的效率完全不影響,但查找效率極為低下。因此,這兩種情況都太極端了,要么選擇極低的寫入效率,要么選擇極低的查找效率。何不將二者結(jié)合一下,以折中寫入的效率和查找的效率呢?比如,將記錄“二分”為兩部分,使用兩個(gè)數(shù)組來存儲(chǔ):

假設(shè)規(guī)定,學(xué)號(hào)小于某值(即201044700239)時(shí),記錄存儲(chǔ)在student_db0中,反之,記錄存儲(chǔ)在student_db1中。如此一來,在寫入記錄時(shí),只需要多一條判斷語句,對(duì)性能并沒太大影響。而在查找時(shí),只要根據(jù)學(xué)號(hào)判斷記錄在哪一個(gè)數(shù)組中,即可按照順序查找的方式查找。此時(shí),查找需要比較的次數(shù)就從最大的10000次降低到了5000次。由此可見,通過一個(gè)簡單的方法,將信息分別存儲(chǔ)在兩個(gè)數(shù)組中,就可以明顯地提高查找效率。為了繼續(xù)提高查找的效率,還可以繼續(xù)分組,比如,分成250組,每組的大小為40:

顯然,采用這種定義方式太繁瑣了,由于每個(gè)數(shù)組的大小是相同的,因此可以直接將存儲(chǔ)40個(gè)學(xué)生記錄的數(shù)組定義為一個(gè)類型:

此時(shí),每個(gè)分組的大小為40,從而使得查找記錄時(shí),最多只需要比較40次。接下來,需要定義分組規(guī)則,以通過學(xué)號(hào)找到該記錄屬于哪個(gè)組。在定義規(guī)則時(shí),應(yīng)盡可能地使所有記錄平均地分布在各個(gè)組中,不應(yīng)該出現(xiàn)一些組存儲(chǔ)的記錄非常多,而一些組存儲(chǔ)的記錄非常少的情況。但這并不是一件容易的事情,需要對(duì)學(xué)號(hào)的數(shù)據(jù)分布進(jìn)行精確的分析。
如果分成250組,假定學(xué)號(hào)是均勻分布的,則可以將6字節(jié)學(xué)號(hào)數(shù)求和除以250(分組數(shù)目)所得的余數(shù)(取余法)作為分組的索引,由于寫入和查找時(shí),都需要通過學(xué)號(hào)找到該記錄應(yīng)該屬于哪個(gè)組,因此可以根據(jù)學(xué)號(hào)分組的依據(jù),編寫一個(gè)通過學(xué)號(hào)找到對(duì)應(yīng)分組索引的函數(shù),詳見程序清單3.62。
程序清單3.62 通過學(xué)號(hào)分組范例程序

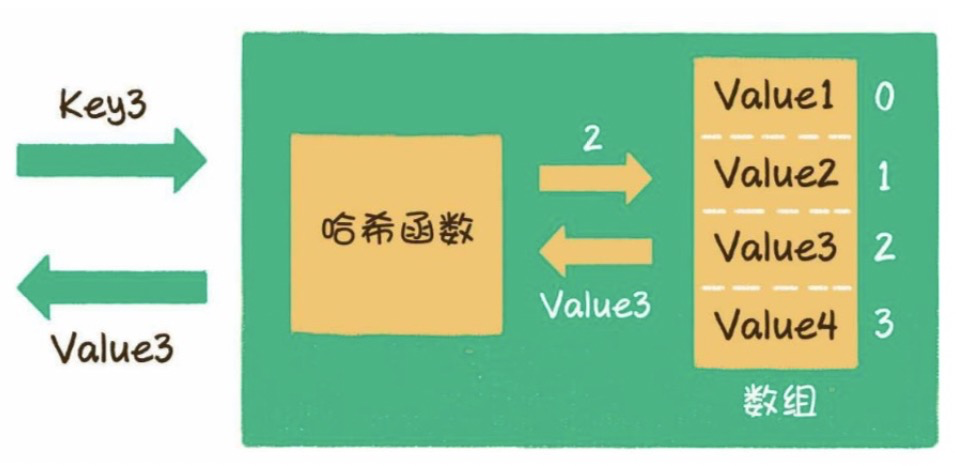
即將分組數(shù)為250看作一個(gè)大小為250的表格,每個(gè)表項(xiàng)可以存儲(chǔ)40個(gè)學(xué)生記錄的數(shù)組,通過db_id_to_idx()函數(shù)找到關(guān)鍵字學(xué)號(hào)ID對(duì)應(yīng)在該表中的位置。其中,大小為250的表格就是“哈希表”,詳見圖3.24。db_id_to_idx()函數(shù)就是“哈希函數(shù)”,哈希函數(shù)的結(jié)果(分組索引)稱之為“哈希值”。

圖3.24 哈希表
哈希表的核心工作在于哈希函數(shù)的選擇,將查找的關(guān)鍵字送給哈希函數(shù)產(chǎn)生一個(gè)哈希值,哈希函數(shù)的選擇直接決定了記錄的分布,必須盡可能地確保所有記錄均勻地分布在各個(gè)組中。在上面的示例中,每個(gè)分組中都定義了大小相同的數(shù)組作為記錄存儲(chǔ)的空間。如果按照分組規(guī)則,能夠確保恰好均勻地分布在各個(gè)分組中,這是最佳的。
而實(shí)際上學(xué)生記錄是會(huì)變動(dòng)的,可能增加或刪除,則很難保證按照現(xiàn)在定義的分組規(guī)則,保證100%的完全平均。如果每個(gè)分組都使用大小相同的數(shù)組作為記錄存儲(chǔ)的空間,則可能會(huì)導(dǎo)致部分?jǐn)?shù)組未存滿,部分?jǐn)?shù)組卻存不下的情況,就會(huì)導(dǎo)致部分學(xué)生記錄無處可存,造成嚴(yán)重的數(shù)據(jù)管理問題。
由于數(shù)組都是提前定義好大小的,動(dòng)態(tài)性能差,而鏈表的動(dòng)態(tài)性能更好,可以根據(jù)需要增加、刪除結(jié)點(diǎn),改變鏈表長度,因此可以使用鏈表管理學(xué)生記錄,就算分布不均勻,也只存在鏈表長度的差異,不會(huì)出現(xiàn)數(shù)據(jù)存儲(chǔ)不了的問題,其示意圖詳見圖3.25。

圖3.25 鏈?zhǔn)焦1?/span>
當(dāng)使用鏈表管理學(xué)生記錄時(shí),哈希表每個(gè)表項(xiàng)的實(shí)際內(nèi)容就是該組鏈表的表頭。鏈表頭結(jié)點(diǎn)的類型slist_head_t(slist.h)的定義如下:

基于此,在哈希表的每個(gè)表項(xiàng)中存儲(chǔ)一個(gè)slist_head_t類型的鏈表頭結(jié)點(diǎn)即可,哈希表的定義如下:

根據(jù)對(duì)鏈?zhǔn)焦1斫Y(jié)構(gòu)的分析,編寫一個(gè)基于鏈?zhǔn)焦1淼男畔⒐芾硐到y(tǒng),作為示例僅提供增加、刪除、查找三種功能。當(dāng)然,在使用這些功能前,還必須定義一個(gè)哈希表對(duì)象的類型,以便使用該類型定義具體的哈希表實(shí)例,進(jìn)而使用各個(gè)功能接口對(duì)該實(shí)例進(jìn)行操作。
>>> 3.5.2 哈希表的類型
哈希表類型struct _hash_db定義如下:

在結(jié)構(gòu)體中,需要包含哪些哈希表的相關(guān)信息呢?鏈?zhǔn)焦1淼暮诵氖且粋€(gè)slist_head_t類型的數(shù)組,其大小與分組數(shù)目相關(guān)。為了通用,分組數(shù)目應(yīng)由用戶根據(jù)實(shí)際情況確定。slist_head_t類型的數(shù)組信息由一個(gè)指向數(shù)組首地址的slist_head_t*類型的指針和一個(gè)指定數(shù)組大小的size構(gòu)成,哈希表結(jié)構(gòu)體類型的定義如下:

在實(shí)際的應(yīng)用中,信息可以是任意數(shù)據(jù)類型(void *),其次還需要知道該void *指針指向的記錄的長度,比如,學(xué)生記錄的長度是sizeof(student_t),因此更新哈希表結(jié)構(gòu)體類型的定義如下:

在存儲(chǔ)或查找記錄時(shí),可以通過與關(guān)鍵字(比如,學(xué)號(hào)ID)比較找到哈希表中的索引值,然后在對(duì)應(yīng)的表項(xiàng)中添加或查找記錄。在存儲(chǔ)記錄時(shí),需要提供關(guān)鍵字和記錄;而在查找記錄時(shí),僅需提供關(guān)鍵字。由此可見,關(guān)鍵字和記錄是兩個(gè)不同的概念,關(guān)鍵字具有特殊的作用,因此關(guān)鍵字和記錄應(yīng)該分別對(duì)待。對(duì)于學(xué)生信息管理系統(tǒng)來說,其關(guān)鍵字為學(xué)號(hào),長度是6字節(jié),記錄包含姓名、性別、身高、體重等信息。因此,在學(xué)生記錄結(jié)構(gòu)體的定義中,將關(guān)鍵字ID分離出來。學(xué)生記錄的定義如下:

同理,關(guān)鍵字的長度也是由用戶決定的,在存儲(chǔ)一條記錄時(shí),需要分配內(nèi)存存儲(chǔ)關(guān)鍵字,以便查詢時(shí)讀取該關(guān)鍵字與查詢使用的關(guān)鍵字進(jìn)行比較。因此在哈希表的結(jié)構(gòu)體類型中,需要包含關(guān)鍵字長度信息,更新哈希表結(jié)構(gòu)體類型的定義如下:

特別地,在前面的分析中,哈希表最重要的一個(gè)概念就是“哈希函數(shù)”,哈希函數(shù)的作用是通過關(guān)鍵字(如學(xué)號(hào)ID)得到其對(duì)應(yīng)記錄在哈希表中的索引值,哈希函數(shù)要盡可能確保記錄均分地分布在哈希表的各個(gè)表項(xiàng)中。對(duì)于不同的數(shù)據(jù),用戶可能選擇不同的哈希函數(shù),因此哈希函數(shù)應(yīng)該由用戶指定。基于此,在哈希表結(jié)構(gòu)體中新增一個(gè)函數(shù)指針,用于指向用戶自定義的哈希函數(shù)。完整的哈希表結(jié)構(gòu)體類型定義如下(hash_db.h):

在使用哈希表的各個(gè)接口函數(shù)前,首先需要使用該類型定義一個(gè)哈希表實(shí)例:

如果系統(tǒng)中需要使用多張哈希表,則只需要使用該類型定義多個(gè)哈希表實(shí)例即可:

>>> 3.5.3 哈希表的實(shí)現(xiàn)
1、初始化
hash_db_init()接口用于哈希表實(shí)例的初始化,在定義哈希表結(jié)構(gòu)體類型時(shí),哈希表數(shù)組大小、記錄長度、關(guān)鍵字長度和哈希函數(shù)都需要由用戶根據(jù)實(shí)際情況確定,其函數(shù)原型定義如下(hash_db.h):

在這里,以學(xué)生記錄為例,創(chuàng)建一個(gè)大小為250組的哈希表:

在初始化函數(shù)的實(shí)現(xiàn)中,需要按照size指定的大小分配內(nèi)存,用于存儲(chǔ)哈希表的各個(gè)表項(xiàng)(鏈表頭),接著需要完成各個(gè)鏈表頭和結(jié)構(gòu)體成員的初始化,初始化函數(shù)的實(shí)現(xiàn)范例詳見程序清單3.63。
程序清單3.63 初始化函數(shù)范例程序

2、添加記錄
hash_db_add()接口用于向已經(jīng)初始化的哈希表中添加一條記錄,添加一條記錄時(shí),需要指定關(guān)鍵字信息和記錄值信息,其函數(shù)原型定義(hash_db.h):

其中,p_hash為指向哈希表實(shí)例的指針,key為指向關(guān)鍵字的指針,value為指向記錄值的指針。特別地,由于在添加記錄時(shí),程序不會(huì)修改key和value指針?biāo)赶虻闹担虼耍羔樁技恿薱onst修飾符。以添加一條學(xué)生記錄為例,使用范例如下:

在添加記錄函數(shù)的實(shí)現(xiàn)中,首先需要使用哈希函數(shù)找到關(guān)鍵字對(duì)應(yīng)的記錄在哈希表中的索引,以確定該條記錄所在鏈表的表頭,然后分配一個(gè)存儲(chǔ)記錄的結(jié)點(diǎn)空間,將關(guān)鍵字、記錄等信息存儲(chǔ)在該空間中,然后將結(jié)點(diǎn)添加到對(duì)應(yīng)鏈表的頭部(由于記錄在鏈表中的具體位置不重要,因此直接添加在鏈表頭部,效率更高)。函數(shù)實(shí)現(xiàn)的范例詳見程序清單3.64。
程序清單3.64 添加記錄函數(shù)范例程序

程序分配了一個(gè)結(jié)點(diǎn)的空間,該結(jié)點(diǎn)的空間需要存儲(chǔ)一個(gè)slist_node_t類型鏈表結(jié)點(diǎn),便于添加結(jié)點(diǎn)到鏈表中,存儲(chǔ)長度為p_hash->key_len的關(guān)鍵字,存儲(chǔ)長度為p_hash->value_len的記錄值,詳見圖3.26,其內(nèi)存的大小為:


圖3.26 結(jié)點(diǎn)存儲(chǔ)空間分布
由于結(jié)點(diǎn)空間的首部用于存儲(chǔ)結(jié)點(diǎn)slist_node_t的值以組織鏈表。因此需要將結(jié)點(diǎn)添加到鏈表中時(shí),直接將p_mem轉(zhuǎn)換為slist_node_t*類型使用即可,通用鏈?zhǔn)焦1淼慕Y(jié)構(gòu)示意圖詳見圖3.27。

圖3.27 通用的鏈?zhǔn)焦1斫Y(jié)構(gòu)示意圖
與圖3.25中管理學(xué)生記錄的鏈?zhǔn)焦1斫Y(jié)構(gòu)示意圖對(duì)比發(fā)現(xiàn),它們表達(dá)的含義是完全一致的,僅僅是具體類型變?yōu)榱烁油ㄓ玫膙oid *類型。
3、查找記錄
hash_db_search()接口通過關(guān)鍵字查找與之對(duì)應(yīng)的記錄,查找記錄時(shí),需要指定關(guān)鍵字信息,同時(shí)還需要使用一個(gè)指向記錄的指針獲取查找到的記錄值,其函數(shù)原型(hash_db.h)如下:

雖然參數(shù)與添加記錄是完全一樣的,但value表示的含義卻不一樣,此處的value是輸出參數(shù),用于得到查找到的記錄值。而添加記錄函數(shù)中的value是輸入?yún)?shù),提供需要存儲(chǔ)的記錄值。由于此處的value指向指向的值是需要被改變的(改變?yōu)椴檎业降挠涗浿担虼耍洳荒茉黾觕onst修飾符。以查找ID為201444700239的學(xué)生記錄為例,使用范例如下:

在該函數(shù)的實(shí)現(xiàn)中,首先需要使用哈希函數(shù)找到關(guān)鍵字對(duì)應(yīng)的記錄在哈希表中的索引,以確定該條記錄所在鏈表的表頭,然后遍歷鏈表的各個(gè)結(jié)點(diǎn),將提供的關(guān)鍵字與結(jié)點(diǎn)中存儲(chǔ)的關(guān)鍵字比對(duì),直到找到關(guān)鍵字完全一致的記錄(查找成功)或鏈表遍歷結(jié)束(查找失敗)。找到該記錄對(duì)應(yīng)的結(jié)點(diǎn)后,將結(jié)點(diǎn)中存儲(chǔ)的value值拷貝到參數(shù)value指針指向的空間中即可。函數(shù)實(shí)現(xiàn)的范例詳見程序清單3.65。
程序清單3.65 查找記錄函數(shù)范例程序

程序中,由于查找結(jié)點(diǎn)時(shí)需要遍歷鏈表,關(guān)鍵字比對(duì)的操作需要在遍歷函數(shù)的回調(diào)函數(shù)中完成,因此,需要將用戶查找記錄使用的關(guān)鍵字信息(關(guān)鍵字及其長度)提供給回調(diào)函數(shù),同時(shí),當(dāng)查找到記錄時(shí),需要將查找到的結(jié)點(diǎn)反饋給調(diào)用遍歷函數(shù)的主程序。為此,定義了一個(gè)內(nèi)部使用的用于尋找一個(gè)結(jié)點(diǎn)的上下文結(jié)構(gòu)體:

調(diào)用遍歷函數(shù)時(shí),需要提供一個(gè)設(shè)置好關(guān)鍵字信息的結(jié)構(gòu)體作為回調(diào)函數(shù)的用戶參數(shù)。遍歷函數(shù)結(jié)束時(shí),可以通過該結(jié)構(gòu)體中的p_result成員獲取遍歷結(jié)果。
4、刪除記錄
該接口用于刪除指定關(guān)鍵字對(duì)應(yīng)的記錄,可以定義其函數(shù)名為:hash_db_del()。刪除記錄時(shí),需要指定關(guān)鍵字信息。可以定義函數(shù)的原型為:

以刪除學(xué)號(hào)為201444700239的學(xué)生記錄為例,使用范例如下:

在該函數(shù)的實(shí)現(xiàn)中,絕大部分操作與查找記錄是相同的,唯一的不同是,當(dāng)找到關(guān)鍵字對(duì)應(yīng)的結(jié)點(diǎn)時(shí),不再需要將記錄值提取出來,直接將該結(jié)點(diǎn)刪除即可。函數(shù)實(shí)現(xiàn)的范例詳見程序清單3.66。
程序清單3.66 刪除記錄函數(shù)范例程序

5、解初始化
對(duì)應(yīng)于哈希表的初始化,用于當(dāng)不再使用哈希表時(shí),釋放相關(guān)的空間。可以定義其函數(shù)名為:hash_db_deinit()。需要通過參數(shù)指定需要解初始化的哈希表實(shí)例,可以定義函數(shù)的原型為(hash_db.h):
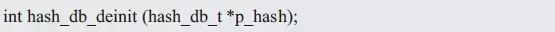
如不再使用學(xué)生信息管理系統(tǒng),則需使用解初始化函數(shù)釋放哈希表的相關(guān)資源,使用范例如下:

在該函數(shù)的實(shí)現(xiàn)中,需要釋放程序中分配的所有空間,主要包括添加記錄時(shí)分配的結(jié)點(diǎn)空間,鏈表頭結(jié)點(diǎn)數(shù)組空間。函數(shù)實(shí)現(xiàn)詳見程序清單3.67。
程序清單3.67 解初始化函數(shù)范例程序

為便于查閱,如程序清單3.29所示展示了hash_db.h文件的內(nèi)容。
程序清單3.68 hash_db.h文件內(nèi)容

以使用該鏈?zhǔn)焦1砉芾硐到y(tǒng)來管理學(xué)生記錄為例,綜合范例程序詳見程序清單3.30。
程序清單3.69 哈希表綜合范例程序

在這里,首先創(chuàng)建了一個(gè)哈希表,然后向其中添加了100個(gè)學(xué)生信息(以隨機(jī)數(shù)的方式產(chǎn)生的),接著查找了ID對(duì)應(yīng)的學(xué)生信息(這里的ID沒有特別設(shè)置,即查找最后添加的學(xué)生記錄),最后釋放哈希表。
-
哈希表
+關(guān)注
關(guān)注
0文章
9瀏覽量
4955
原文標(biāo)題:周立功:認(rèn)識(shí)并實(shí)現(xiàn)哈希表
文章出處:【微信號(hào):ZLG_zhiyuan,微信公眾號(hào):ZLG致遠(yuǎn)電子】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
數(shù)據(jù)結(jié)構(gòu)與算法分析(Java版)(pdf)
數(shù)據(jù)結(jié)構(gòu)概述及線性表
數(shù)據(jù)結(jié)構(gòu)教程,下載
C#數(shù)據(jù)結(jié)構(gòu)和算法分析_ 魏寶剛

數(shù)據(jù)結(jié)構(gòu)與算法習(xí)題
數(shù)據(jù)結(jié)構(gòu)與算法
算法與數(shù)據(jù)結(jié)構(gòu)——接口
java數(shù)據(jù)結(jié)構(gòu)學(xué)習(xí)
哈希表是什么?哈希表數(shù)據(jù)結(jié)構(gòu)詳細(xì)資料分析
大牛分享平時(shí)如何學(xué)習(xí)數(shù)據(jù)結(jié)構(gòu)與算法
哈希表是什么?為什么需要使用哈希表
JavaScrit數(shù)據(jù)結(jié)構(gòu)與算法(第2版)
算法和數(shù)據(jù)結(jié)構(gòu)基礎(chǔ)知識(shí)分享(中)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論