") GAN新手必讀:如何將將GAN應用于NLP(論文筆記)
GAN新手必讀:如何將將GAN應用于NLP(論文筆記)
作者:MirandaYang
GAN 自從被提出以來,就廣受大家的關注,尤其是在計算機視覺領域引起了很大的反響。“深度解讀:GAN模型及其在2016年度的進展”[1]一文對過去一年GAN的進展做了詳細介紹,十分推薦學習GAN的新手們讀讀。這篇文章主要介紹GAN在NLP里的應用(可以算是論文解讀或者論文筆記),并未涉及GAN的基本知識 (沒有GAN基礎知識的小伙伴推薦先看[1],由于本人比較懶,就不在這里贅述GAN的基本知識了J)。由于很長時間沒有寫中文文章了,請各位對文章中不準確的地方多多包涵、指教。
雖然GAN在圖像生成上取得了很好的成績,GAN并沒有在自然語言處理(NLP)任務中取得讓人驚喜的成果。 其原因大概可以總結為如下幾點:
-
原始GAN主要應用實數空間(連續(xù)型數據)上,在生成離散數據(texts)這個問題上并不work。GAN 理論的提出者Ian Goodfellow 博士這樣回答來這個問題問題:“GANs 目前并沒有應用到自然語言處理(NLP)中,最初的 GANs 僅僅定義在實數領域,GANs 通過訓練出的生成器來產生合成數據,然后在合成數據上運行判別器,判別器的輸出梯度將會告訴你,如何通過略微改變合成數據而使其更加現實。一般來說只有在數據連續(xù)的情況下,你才可以略微改變合成的數據,而如果數據是離散的,則不能簡單的通過改變合成數據。例如,如果你輸出了一張圖片,其像素值是1.0,那么接下來你可以將這個值改為1.0001。如果輸出了一個單詞“penguin”,那么接下來就不能將其改變?yōu)椤皃enguin + .001”,因為沒有“penguin +.001”這個單詞。 因為所有的自然語言處理(NLP)的基礎都是離散值,如“單詞”、“字母”或者“音節(jié)”, NLP 中應用 GANs是非常困難的。一般而言,采用增強學習算法。目前據我所知,還沒有人真正的開始研究利用增強算法解決 NLP 問題。”
-
在生成text時,GAN對整個文本序列進行建模打分。對于部分(partially)生成的序列,十分難判斷其在之后生成整個 (fully) 序列時的分數。
-
另一個潛在的挑戰(zhàn)涉及RNN的性質(生成文本大多采用RNN模型)。假設我們試圖從latent codes生成文本,error就會隨著句子的長度成指數級的累積。最開始的幾個詞可能是相對合理的,但是句子質量會隨著句子長度的增加而不斷變差。另外,句子的長度是從隨機的latent representation生成的,所以句子長度也是難以控制。
下面我將主要介紹和分析最近閱讀過的將GAN應用于NLP中的一些論文:
1. Generating Text via Adversarial Training
-
論文鏈接:
http://people.duke.edu/~yz196/pdf/textgan/paper.pdf
-
這是2016年的 NIPS GAN Workshop 上的一篇論文, 嘗試將 GAN 理論應用到了文本生成任務上。 文中的方法比較簡單,具體可以總結為:
-
以遞歸神經網絡(LSTM)作為GAN的生成器(generator)。其中,用光滑近似(smooth approximation)的思路來逼近 LSTM 的輸出。結構圖如下:

-
本文的目標函數和原始GAN有所不同,文中采用了feature matching的方法 。迭代優(yōu)化過程包含以下兩個步驟:
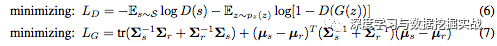
其中式 (6) 為標準GAN的優(yōu)化函數,式 (7) 為feature matching的優(yōu)化函數。
-
本文的初始化非常有意思,特別是在判別器的預訓練方面,利用原始的句子和該句子中交換兩個詞的位置后得到的新句子進行判別訓練。(在初始化的過程中,運用逐點分類損失函數對判別器進行優(yōu)化)。這非常有意思,因為將兩個單詞互換位置,輸入的數據信息實際上是基本相同的。比如,大多數卷積計算最終會得出完全相同的值。
-
本文生成器的更新頻率是判別器的更新頻率的5倍,這與原始GAN的設定恰好相反。這是因為LSTM比CNN的參數更多,更難訓練。
-
然而,本文生成模型 (LSTM) decode階段有exposure bias問題,即在訓練過程中逐漸用預測輸出替代實際輸出作為下一個詞的輸入。
2. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
-
論文鏈接:https://
https://arxiv.org/pdf/1609.05473.pdf
-
論文源碼:
https://github.com/LantaoYu/SeqGAN
-
文本將誤差作為一種增強學習的獎勵,以一種前饋的方式訓練,用增強的學習的探索模式去更新G網絡。
-
主要內容:這篇論文將序列生成過程當作一個sequential decision making過程。如下圖:
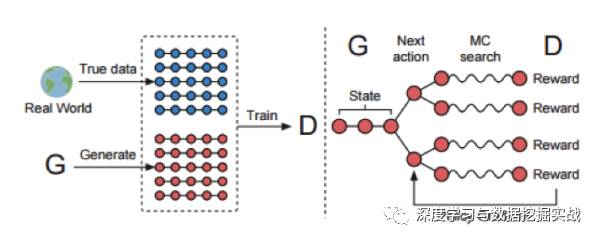
(a) 其中左圖為GAN網絡訓練的步驟1,判別器D主要用來區(qū)分真實樣本和偽造樣本,這里的判別器D是用CNN來實現的。
(b) 右圖為GAN網絡訓練的步驟2, 根據判別器D回傳的判別概率回傳給生成器G,通過增強學習的方法來更新生成器G,這里的的生成器G是用LSTM來實現的.
(c) 因為G網絡的更新策略是增強學習,增強學習的四個要素state, action, policy, reward分別為:state 為現在已經生成的tokens (當前timestep之前LSTM decoder的結果), action是下一個即將生成的token (當前解碼詞), policy為GAN的生成器G網絡,reward為GAN的判別器D網絡所生成的判別概率。其中,reward采用以下方法來近似: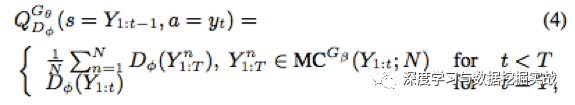
本過程特點:即當解碼到t時,即對后面T-t個timestep采用蒙特卡洛搜索搜索出N條路徑,將這N條路徑分別和已經decode的結果組成N條完整輸出,然后將D網絡對應獎勵的平均值作為reward. 因為當t=T時無法再向后探索路徑,所以直接以完整decode結果的獎勵作為reward。
(d) 對于RL部分,本文采用了policy gradient方法。 根據policy gradient理論,生成器G的目標函數可以表示如下:
求導結果為: (詳細推導過程請看原論文附頁)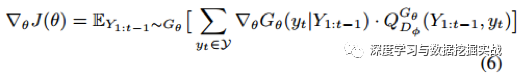
(e) 每隔一段時間,當生成更多的更逼真的句子后,重新訓判別器D,其中判別器的目標函數表示如下:
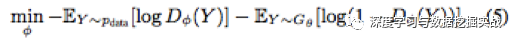
算法結構圖可以表示為如下:
-
實驗
實驗部分主要分為合成數據實驗和現實數據實驗。
(a) 合成數據實驗: 隨機初始一個LSTM生成器A,隨機生成一部分訓練數據,來訓練各種生成模型.
評判標準為:負對數似然(交叉熵) NLL. 詳細實驗設置可以參看原論文。
(b) 現實數據實驗:主要展示中文詩句生成,奧巴馬演講生成,音樂生成的結果。實驗數據分別為中文詩歌數據集 (16,394首絕句),奧巴馬演講數據集 (11,092 段落), Nottingham音樂數據集 (695首歌)。評測方法為BLEU score, 實驗結果如下: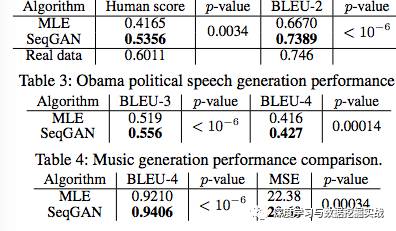
文中并未展示模型生成的詩歌等, 具體效果如何?
3. Adversarial Learning for Neural Dialogue Generation
-
論文鏈接:https://
https://arxiv.org/pdf/1701.06547.pdf
-
論文源碼:
https://github.com/jiweil/Neural-Dialogue-Generation
-
這篇論文是2017年1月26號上傳到arxiv上的,屬于最新的GAN用于NLP的論文。文中主要用對抗性訓練 (adversarial training) 方法來進行開放式對話生成 (open-domain dialogue generation)。文中把這項任務作為強化學習(RL)問題,聯(lián)合訓練生成器和判別器。和SeqGAN一樣,本文也是使用判別器D的結果作為RL的reward部分,這個reward用來獎勵生成器G,推動生成器G產生的對話類似人類對話。
-
總體來說,本文的思路和SeqGAN是大體一樣的,但是有幾處不同和改進的地方:
(a) 因為本文是用于開放式對話生成,所以文中的生成器采用seq2seq模型 (而非普通的LSTM模型)。 判別器則采用了hierarchical encoder (而非CNN)。
(b) 采取了兩種方法為完全生成或者部分生成的序列計算reward。除了 Monte Carlo search (與SeqGAN相似) 方法,本文新提出了一個能對部分生成的序列進行reward計算的方法。使用所有完全 (fully) 和部分 (partially) 解碼的序列來訓練判別器會造成overfitting。早期產生的部分(partially)序列會出現在許多的訓練數據中,比如生成的第一個token y_1將會出現在所有的部分生成 (partially generated) 的序列里。所以本文提出僅僅分別從正(positive)序列 y+ 和負(negative)序列y-的每個子序列中隨機地選取一個 sample來訓練判別器D。這個方法比Monte Carlo search更快速,但是也會使得判別器更弱,更不準確。
(c) 在SeqGAN中,生成器只能間接的通過判別器生成的reward來獎勵或者懲罰自己所產生的序列。而不能直接從 gold-standard序列中直接獲取信息。 這種訓練方式是脆弱的,一旦生成器在某個訓練batch中變壞,判別器將會很容易對生成的句子進行判斷 (比如reward為0 ),此時生成器就會迷失。生成器只知道現在生成的句子是壞的,但是并不知道如何調整才能使得生成的句子變好。為了解決這個問題,在生成器的更新過程中,本文輸入了human-generated responses。對于這些human-generated responses, 判別器可以將其reward設置為1。這樣生成器可以在上述情況下仍能生成好的responses。
(d) 訓練過程中,有些針對dialogue system的設置(trick)。這部分內容,讀者可以參考Jiwei Li之前的關于dialogue system的論文。
-
部分實驗結果:

-
值得思考的地方:文中只嘗試用判別器的結果作為reward, 結合 原文作者之前在dialogue system文中提出的其他reward機制(e.g., mutual information)會不會提高效果?
4. GANs for sequence of discrete elements with the Gumbel-softmax distribution
-
論文鏈接:https://
https://arxiv.org/pdf/1611.04051.pdf
-
相比前面兩篇論文,本文在處理離散數據這個問題上則比較簡單暴力。離散數據 (用one-hot方法表示)一般可以從多項式采樣取得,例如由softmax函數的輸出p = softmax(h)。 根據之前的概率分布,以p的概率進行采樣y的過程等價于:y=one_hot(argmax_i(h_i+g_i)) , 其中g_i是服從Gumbel distribution (with zero location and unit scale)。然而one_hot(argmax(.)) 是不可微分的。與原始GAN不同,作者提出了一種方法來近似上面的式子: y = softmax(1/ r (h + g))。這個公式是可以微分的。算法結構如下:

-
本文的實驗部分做得比較粗糙,只展示了生成得context-free grammar, 并未在生成其他文本數據上做實驗。
-
總的來說,這篇論文本身方法還值得改進,也可以值得借鑒下。
5. Connecting generative adversarial network and actor-critic methods
-
論文鏈接:https://https://arxiv.org/pdf/1610.01945.pdfhttps://arxiv.org/pdf/1610.01945.pdf啊發(fā)afaffa
https://arxiv.org/pdf/1610.01945.pdf
-
Actor-critic methods [2]: 許多RL方法 (e.g., policy gradient) 只作用于policy 或者 value function。Actor-critic方法則結合了policy-only和value function-only 的方法。 其中critic用來近似或者估計value function,actor 被稱為policy structure, 主要用來選擇action。Actor-critic是一個on-policy的學習過程。Critic模型的結果用來幫助提高actor policy的性能。
-
GAN和actor-critic具有許多相似之處。Actor-critic模型中的actor功能類似于GAN中的generator, 他們都是用來take an action or generate a sample。Actor-critic模型中的critic則類似于GAN中的discriminator, 主要用來評估 actor or generator 的輸出。具體的相同和不同點,感興趣的朋友可以仔細閱讀原文。
-
這篇論文主要貢獻在于從不同的角度來說明了GAN和actor-critic模型的相同與不同點,從而鼓勵研究GAN的學者和研究actor-critic模型的學者合作研發(fā)出通用、穩(wěn)定、可擴展的算法,或者從各自的研究中獲取靈感。
-
最近Bahdanau等大神提出了用actor-critic模型來進行sequence prediction [3]。雖然[3]中并沒有用到GAN,或許對各位能有啟發(fā)。 用類似的思想,GAN在sequence prediction上也許也能取得的比較好的效果?
[1] 深度解讀:GAN模型及其在2016年度的進展
[2] Actor-Critic Algorithms
[3] An actor-critic algorithm for sequence prediction
-
GaN
+關注
關注
19文章
2183瀏覽量
76236 -
nlp
+關注
關注
1文章
490瀏覽量
22504
原文標題:干貨|GAN for NLP (論文筆記及解讀)
文章出處:【微信號:DatamingHacker,微信公眾號:深度學習與數據挖掘實戰(zhàn)】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
GaN已為數字電源控制做好準備
GaN可靠性的測試
基于GaN的開關器件
不同襯底風格的GaN之間有什么區(qū)別?
GaN和SiC區(qū)別
GaN在開關速度方面的優(yōu)勢
必讀!生成對抗網絡GAN論文TOP 10
生成對抗網絡GAN論文TOP 10,幫助你理解最先進技術的基礎





 工商網監(jiān)
工商網監(jiān)
評論