 AI智能化問答:自然語言處理技術的重要應用
AI智能化問答:自然語言處理技術的重要應用
自然語言處理(NLP)是人工智能領域的一個重要分支,它致力于使計算機能夠理解、解釋和生成人類語言。
問答系統作為NLP的一個重要應用,能夠精確地解析用戶以自然語言提出的問題,并從包含豐富信息的異構語料庫或專門構建的問答知識庫中檢索出最匹配的答案。與通用搜索引擎相比,問答系統的優勢在于其深層的語義理解能力,這使得它不僅能夠識別用戶提問的字面意思,還能洞察其背后的真實意圖。這種深層次的理解能力,使得問答系統在提供信息時更加精準和高效,更好地滿足用戶的信息需求。
本文將從技術原理、實現方法和技術應用三個方面,詳細解析自然語言處理問答系統。
01 技術原理
- 語言模型
問答系統的核心是語言模型,它能夠預測文本序列的概率分布。常見的模型包括n-gram模型、循環神經網絡(RNN)、長短時記憶網絡(LSTM)和Transformer等。
- 意圖識別
系統需要識別用戶的查詢意圖,這通常通過模式匹配或機器學習分類器實現。
- 實體識別
從用戶查詢中提取關鍵信息,如人名、地點、時間等,這通常通過命名實體識別(NER)技術實現。
- 語義理解
理解用戶查詢的真正含義,可能涉及到句子的依存關系分析和語義角色標注。
- 答案生成
根據理解的意圖和實體,從知識庫中檢索或生成答案。
02 實現方法
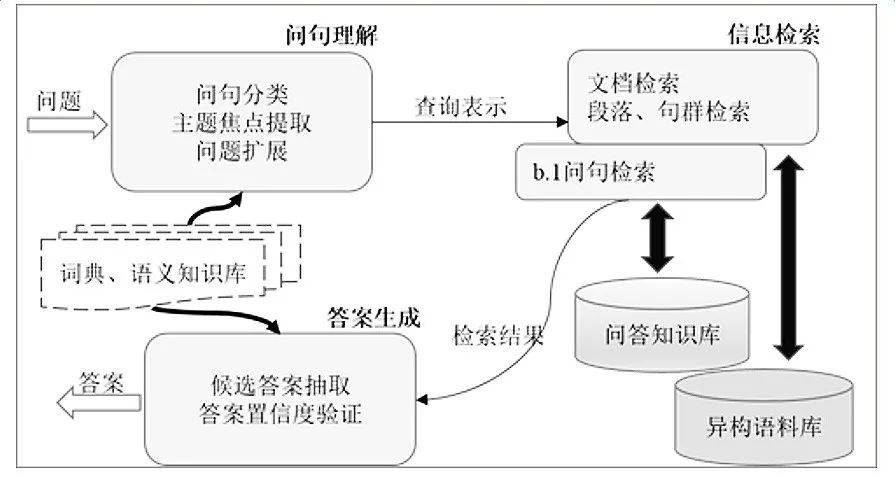
問答系統在處理用戶問題時采用的方法因其應用領域而異。例如:
專門針對常見問題解答(FAQ)的系統通常通過直接匹配問句來快速檢索出答案。
開放領域的問答系統則需要更復雜的處理流程:首先需要分析問題,然后從大量文檔中檢索相關信息,最后從這些信息中抽取出最合適的答案。
盡管不同問答系統在模塊劃分和實現細節上有所區別,但大多數問答系統的核心處理流程都遵循一個相似的框架,包括理解用戶的問句、檢索相關信息和生成答案這三個關鍵步驟。這個框架確保了系統能夠從用戶的問題中提取出意圖,并據此從可用數據源中找到并生成準確的答案。
(資料來源:CSDN LegenDavid基于深度學習的智能問答)
No.1 問句理解
問句理解是問答系統的第一步,目的是準確解析用戶的自然語言輸入,以理解其語義內容和查詢意圖。
這部分負責將用戶的自然語言問題轉化為計算機能夠處理的形式,包括分詞、詞性標注、命名實體識別(NER)、問句分類、查詢表示、意圖識別和問題擴展。
分詞是將問題分解成單獨的詞匯或短語的過程;
詞性標注涉及識別每個詞的語法屬性;
NER用于識別問題中的實體如人名、地點等;
問句分類確定問題的類型;
查詢表示將問題轉換為適合檢索的格式;
意圖識別旨在理解用戶提問的目的或意圖;
問題擴展通過添加上下文或同義詞來豐富問題信息。
涉及到的技術點:
- 自然語言處理庫:如NLTK、spaCy等,用于分詞和詞性標注。
- 深度學習模型:如BERT、GPT,用于實體識別和意圖識別。
- 依存句法分析:分析詞之間的依存關系,幫助理解句子結構。
- 語義角色標注:識別句子中的謂詞及其對應的論元。
No.2 信息檢索
信息檢索是問答系統的第二步,其目的是從大量數據中找到與用戶問題最相關的信息。
這部分負責從大量數據中找到與用戶問題最相關的信息,包括文檔檢索、段落、句群檢索和主題焦點提取。
文檔檢索是從數據庫或文檔集中檢索相關文檔;
段落、句群檢索是在文檔中檢索包含答案的段落或句子;
主題焦點提取確定文檔中與問題最相關的部分。
涉及到的技術點:
- 倒排索引:用于快速檢索包含特定詞匯的文檔。
- 向量空間模型:將文本轉換為向量,用于計算文本間的相似度。
- TF-IDF:統計方法,用于評估一個詞對于一個文檔集或一個語料庫中的其中一份文檔的重要性。
- BM25:信息檢索算法,用于估計文檔與查詢的相關程度。
No.3 答案生成
答案生成是問答系統的第三步,其目的是從檢索到的信息中抽取或生成確切的答案。
這部分負責從檢索到的信息中抽取或生成確切的答案,包括候選答案抽取、答案置信度驗證和答案選擇。
候選答案抽取是從檢索結果中抽取可能的答案;
答案置信度驗證評估候選答案的準確性和可靠性;
答案選擇是從多個候選答案中選擇最佳答案。
涉及到的技術點:
- 模式匹配:使用正則表達式等方法從文本中抽取結構化信息。
- 深度學習模型:如Seq2Seq模型,用于生成答案。
- 排序算法:如學習排序(Learning to Rank),用于對候選答案進行排序。
- 答案驗證:使用邏輯規則或外部知識庫來驗證答案的正確性。
這三個部分共同構成了一個完整的問答系統,每個部分都包含了一系列復雜的處理步驟和技術點,以確保系統能夠有效地理解和回答用戶的問題。
03 技術應用
隨著人工智能技術的飛速發展,問答系統已經成為各行各業提升服務效率、優化用戶體驗的關鍵工具。
在金融領域,問答系統能夠快速響應客戶的查詢,提供個性化的投資建議;在醫療行業,它能幫助患者獲取健康信息,甚至輔助醫生進行初步診斷;而在零售業,問答系統則通過聊天機器人的形式,提供產品推薦和購物咨詢,增強了顧客的購物體驗。
對于求職者而言,掌握問答系統的開發和應用能力,無疑會大大拓寬就業面積,提升就業競爭力。在當前的就業市場中,具備NLP技能的專業人才備受青睞,無論是大型科技公司還是初創企業,都在積極尋找能夠構建和優化問答系統的人才。

所以有這方面就業需求的或對這部分技術感興趣的同學,可以提前通過系統地學習掌握這一應用,按照由淺入深的順序,逐步掌握:
- Python基礎:學習Python語言,為后續的編程實踐打下基礎。
- 機器學習與深度學習:深入學習機器學習算法和深度學習模型,為構建問答系統提供理論支持。
- NLP:會詳細講解NLP-循環神經網絡關鍵技術棧與深層次的原理,并結合Word-Embedding理解語言對于模型的概念
- 大模型(AIGC):探討Transformer、注意力機制、位置編碼、生成式人工智能的原理,從而知道如何更好的使用大模型。
- 問答系統開發:通過項目實踐,學習如何構建一個簡單的問答系統。
- 模型優化與部署:學習如何優化模型性能,并將其部署為一個可訪問的服務。
問答系統是自然語言處理領域的一個重要應用,不僅能夠提高信息檢索的效率,還能夠提升用戶體驗。通過系統性的課程,掌握構建問答系統所需的關鍵技術和工具,提升自己的就業競爭力。
AI體系化學習路線
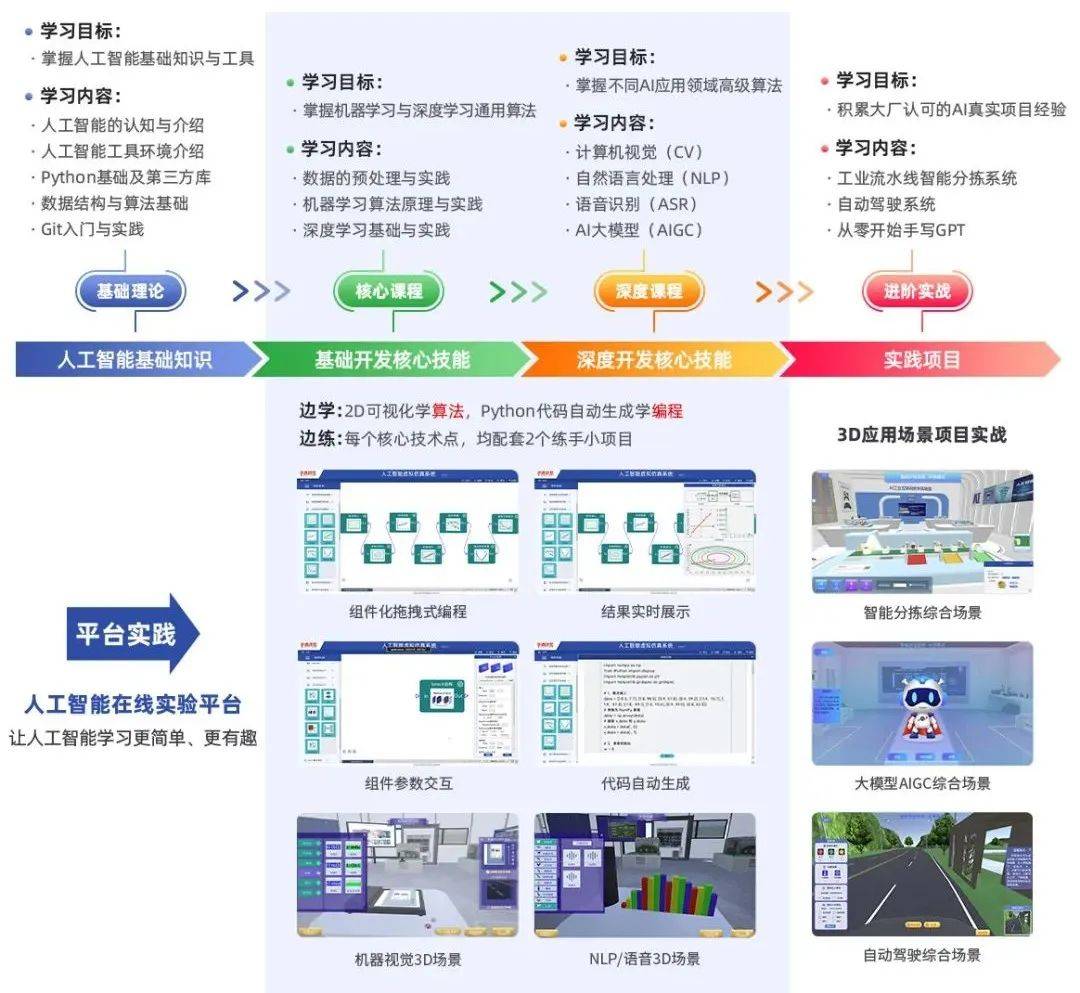
全體系課程詳情

-
AI
+關注
關注
88文章
34589瀏覽量
276236 -
人工智能
+關注
關注
1805文章
48843瀏覽量
247449 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14059
發布評論請先 登錄





 工商網監
工商網監
評論