 基于深度學習的三維點云分類方法
基于深度學習的三維點云分類方法
來源:3D視覺工坊
2. 摘要
近年來,點云表示已成為計算機視覺領域的研究熱點之一,并廣泛應用于自動駕駛、虛擬現實、機器人等許多領域。雖然深度學習技術在處理常規結構化的二維網格圖像數據方面取得了巨大成功,但在處理不規則、非結構化的點云數據方面仍面臨著巨大挑戰。點云分類是點云分析的基礎,許多基于深度學習的方法已被廣泛應用于此任務。因此,本文旨在為該領域的研究人員提供最新的研究進展和未來趨勢。首先,我們介紹點云獲取、特征和挑戰。其次,我們回顧了用于點云分類的3D數據表示、存儲格式和常用數據集。然后,我們總結了基于深度學習的點云分類方法,并補充了最近的研究工作。接下來,我們比較和分析了主要方法的性能。最后,我們討論了點云分類的一些挑戰和未來方向。
3.引言
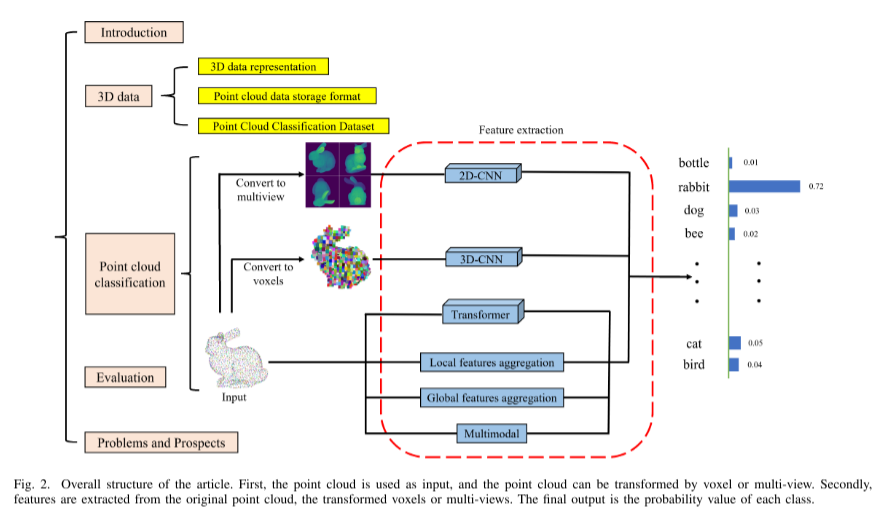
近年來,計算機視覺領域的二維圖像處理技術已接近成熟,許多研究人員已將研究重點轉向更符合現實世界的三維場景。在三維場景中,點云因其豐富的表達信息而在表示三維場景中發揮著重要作用。因此,點云已成為三維視覺研究中常見的數據表達形式。隨著技術的進步,點云數據的獲取變得越來越智能和便捷,有許多獲取方法,例如:激光雷達檢測、通過3D模型計算獲取點云、通過2D圖像進行3D重建獲取點云等。作為最基本的點云分析任務,點云分類已廣泛應用于安全檢測、目標物體檢測、醫學和三維重建等許多領域。點云分類的目的是為點云中的每個點配備一個標記,以識別點云的整體或部分屬性。由于點云的組成屬性屬于點云分割的范疇,在本文中,我們主要關注點云的整體屬性,即點云分類。如圖1所示,3D數據有各種表示形式。目前,可以將點云轉換為網格、體素或多視圖數據,通過間接方法學習3D對象表示,但這些方法容易出現問題,如丟失對象的3D幾何信息或內存消耗過多。在PointNet之前,由于點云的無序性和不規則性,深度學習技術無法直接處理點云。早期的點云處理使用手工設計的規則進行特征提取,然后使用基于機器學習的分類器(如支持向量機(SVM)、AdaBoost、隨機森林(RF)等)來預測點云的類別標簽,但這些分類方法具有較差的適應能力,并且容易受到噪聲的影響。一些研究通過合成上下文信息來解決噪聲問題,例如條件隨機場(CRF)、馬爾可夫隨機場(MRF)等,這在一定程度上提高了分類性能。然而,手工設計規則提取的特征表達能力有限,特別是在復雜場景下,模型的準確性和泛化能力無法滿足人類的需求,而且這種方法嚴重依賴于具有專業知識和經驗的研究人員。隨著計算機計算和數據處理能力的迅速發展,深度學習技術在點云分析中的應用也得到了推廣。斯坦福大學的Charles等人于2017年發表的一篇論文提出了一個直接處理點云的深度學習網絡,PointNet。這篇論文是一個里程碑,直接處理點云的方法逐漸占據主導地位。面對3D點云的無序性、無規律性和稀疏性,點云分類仍然是一個具有挑戰性的問題。目前有一些綜述分析和總結基于深度學習的3D點云分類方法。本文在以往工作的基礎上進行了改進,并增加了新的基于深度學習的3D點云分類方法,如最近流行的基于Transformer的方法。最后,展望了3D點云分類技術的未來研究方向。文章的整體結構如圖2所示。具體來說,我們工作的主要貢獻如下:
我們首先對3D數據進行了詳細介紹,深入解釋了點云,以便讀者理解,并提供了用于點云分類的數據集及其獲取方法。
我們總結了最近發表的關于點云分類的研究綜述,基于此補充了最新研究方法。這些方法根據其特點分為四類,包括基于多視圖的、基于體素的、基于點云的方法和基于多形態融合的方法。然后將點云方法細分。
我們根據它們的分類特點,討論了各類方法的優勢和局限性。這種分類更適合研究人員根據實際需求探索這些方法。
我們提供了方法的評估指標和性能比較,以更好地展示各種方法在數據集上的性能,然后分析了該領域的一些當前挑戰和未來趨勢。
4. 3D數據
A. 3D數據表示
3D數據有各種表示形式,例如點云、網格和體素。
點云:點云本質上是在3D空間中繪制的大量微小點的集合,如圖1(a)所示,它由使用3D激光掃描儀捕獲的大量點組成。這些點可以表達目標的空間分布和表面特征。點云中的每個點包含豐富的信息,例如:三維坐標(x、y、z)、顏色信息(r、g、b)和表面法向量等。
網格:3D數據也可以用網格網格表示,可以視為建立點之間局部關系的點集。三角網格,也稱為三角面片(如圖1(b)所示),是描述3D對象的常用網格之一。一個切片的點和邊的集合稱為網格。
體素:在3D對象表示中,體素也是一種重要的3D數據表示形式,如圖1(c)所示,體素擅長表示非均勻填充的規則采樣空間,因此,體素可以有效地表示具有大量空白或均勻填充空間的點云數據。通過將點云數據進行體素化,有利于提高數據計算效率并減少對隨機存儲器的訪問,但是點云數據的體素化不可避免地會帶來一定程度的信息丟失。
多視圖:多視圖圖像(如圖1(d)所示)也是點云數據的表示形式,它源自單視圖圖像,是將3D對象渲染為在特定角度下的多個視點的圖像。挑戰主要在于透視和透視融合的選擇。
B. 點云數據存儲格式
點云有數百種文件格式可用,不同的掃描儀會以許多格式生成原始數據。點云數據文件之間的最大區別在于使用ASCII和二進制。二進制系統直接將數據存儲在二進制代碼中。常見的點云二進制格式包括FLS、PCD、LAS等。其他幾種常見文件類型可以同時支持ASCII和二進制格式。其中包括PLY、FBX。E57以ASCII和二進制代碼存儲數據,并將許多ASCII和二進制的優點結合在一個文件類型中。以下是一些常用的點云數據存儲格式:
Obj:obj格式的點云文件由Wavefront Technologies開發。它是一個文本文件。它是一種簡單的數據格式,僅表示3D數據的幾何、法線、顏色和紋理信息。這種格式通常以ASCII形式表示,但也有專有的obj二進制版本。
Las:las格式主要用于存儲LIDAR點云數據,本質上是一個二進制格式文件。LAS文件由三部分組成:頭文件區(包括點總數、數據范圍、每個點的維度信息)、可變長度記錄區(包括坐標系、額外維度等)、點集記錄區(包括點坐標信息、R、G、B信息、分類信息、強度信息等)。las格式考慮到LIDAR數據的特點,結構合理,易于擴展。
Ply:PLY的全稱是Polygon File Format,受obj啟發,專門用于存儲3D數據。PLY使用名義上的平面多邊形列表來表示對象。它可以存儲包括顏色、透明度、表面法向量、紋理坐標和數據置信度在內的信息,并且可以為多邊形的前后兩側設置不同的屬性。該文件有兩個版本,一個是ASCII版本,一個是二進制版本。
E57:E57是用于點云存儲的供應商中立文件格式。它還可以用于存儲激光掃描儀和其他3D成像系統生成的圖像和元數據信息,是一個使用固定大小字段和記錄的嚴格格式。它使用ASCII和二進制代碼保存數據,并提供了ASCII的大部分可訪問性和二進制的速度,可以存儲3D點云數據、屬性、圖像。
PCD:PCD是Point Cloud Library的官方指定格式。它由頭文件和點云數據兩部分組成。它用于描述點云的整體信息。它有兩種數據存儲類型,ASCII和二進制,但PCD文件的頭文件必須使用ASCII編碼。PCD的一個好處是它很好地適應了PCL,與PCL應用程序相比,性能最高。
C. 3D點云公共數據集
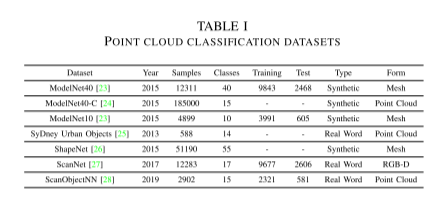
今天,許多工業和大學提供了許多點云數據集。不同方法在這些數據集上的表現反映了方法的可靠性和準確性。這些數據集包含虛擬或真實場景,可以為網絡訓練提供地面真實標簽。在本節中,我們將介紹一些常用的點云分類數據集,每個數據集的劃分如表I所示。
ModelNet40:該數據集由普林斯頓大學的視覺和機器人實驗室開發。ModelNet40數據集包含合成CAD對象。作為最廣泛使用的點云分析基準,ModelNet40因其多樣的類別、清晰的形狀和良好結構的數據集而受歡迎。該數據集包含40個類別的對象(例如飛機、汽車、植物、燈具),其中9843個用于訓練,2468個用于測試。相應的點是從網格表面均勻采樣的,然后通過移動到原點并縮放到單位球來進一步預處理。
ModelNet-C:ModelNet-C集合包含185,000個不同的點云,是基于ModelNet40驗證集創建的。這個數據集主要用于測試3D點云識別的損傷魯棒性,其中包括15種損傷類型和每種損傷類型的5種嚴重程度,例如噪聲、密度等。有助于了解模型的魯棒性。
ModelNet10:ModelNet10是ModelNet40的一個子集,該數據集僅包含10個類別,分為3991個訓練和908個測試形狀。
Sydney Urban Objects:該數據集收集于悉尼中央商務區,包含各種常見的城市道路物體,包括631個類別為車輛、行人、標志和樹木的掃描對象。
ShapeNet:ShapeNet是由斯坦福大學、普林斯頓大學和芝加哥豐田技術研究所的研究人員開發的大型3D CAD模型倉庫。該倉庫包含超過3億個模型,其中22萬個模型被分類為3135個類別,使用WordNet上下位關系排列。ShapeNetCore是ShapeNet的一個子集,包括近51,300個獨特的3D模型。它提供了55個常見物體類別和注釋。ShapeNetSem也是ShapeNet的一個子集,包含12,000個模型。規模較小,但覆蓋面更廣,包括270個類別。
ScanNet:ScanNet是一個實例級室內RGB-D數據集,包含2D和3D數據。它是一個帶標記的體素集合,而不是點或對象。截至目前,最新版本的ScanNet,ScanNet v2,已經收集了1513個帶有大約90%表面覆蓋率的標記掃描。在語義分割任務中,該數據集用20個類別的注釋3D體素化對象進行標記。
ScanObjectNN:ScanObjectNN是一個由2902個3D對象組成的真實世界數據集,分為15個類別,由于數據集中的背景、缺失部分和變形等因素,這是一個具有挑戰性的點云分類數據集。
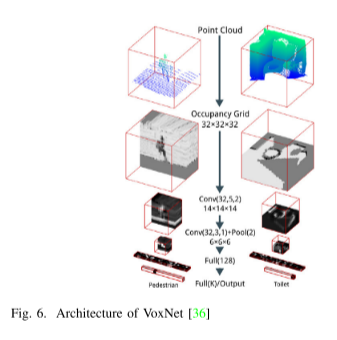
5. 基于深度學習的點云分類方法
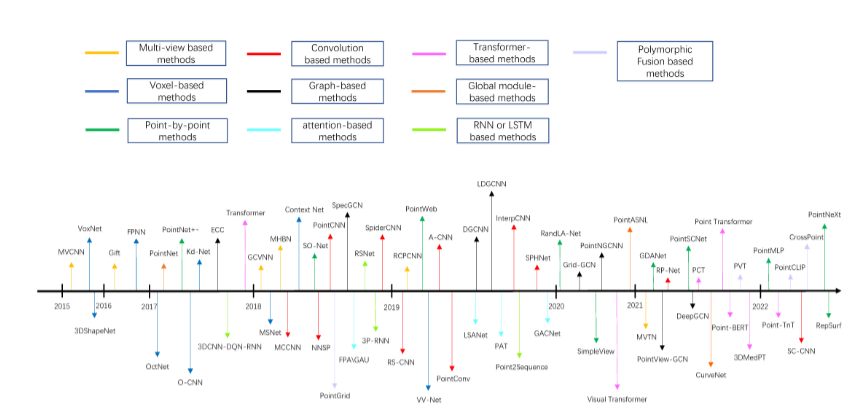
基于深度學習的點云分類模型由于其強大的泛化能力和高分類準確性等優勢,在點云分析中得到了廣泛應用。本節詳細介紹了基于深度學習的點云分類方法的劃分,并補充了一些最近的研究工作。圖3顯示了每種分類方法的發表時間表。
A. 基于多視圖的方法
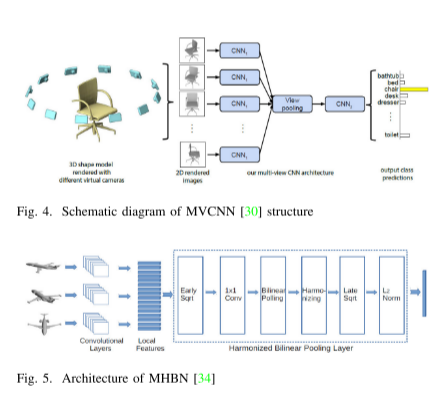
基于多視圖的方法利用多個視角的信息來描述和識別3D形狀。這種方法的優勢在于可以從不同的角度獲取豐富的特征信息,從而提高了形狀識別的準確性。然而,基于多視圖的方法在處理大規模場景和利用3D數據的固有幾何關系方面仍然存在挑戰。例如,在將多個視圖特征轉換為全局特征時,會忽略其他非最大元素的信息,導致信息丟失。因此,改進基于多視圖的方法以充分利用信息,并解決大規模場景和幾何關系的挑戰是未來研究的方向。
B. 基于體素的方法
基于體素的方法將3D點云模型轉換為體素形式,每個體素塊包含一組相關點,并使用3D卷積神經網絡對體素進行分類。這種方法可以有效地表示對象的形狀,并在3D對象識別中取得了良好的效果。然而,由于3D卷積計算復雜,對于體素進行卷積會增加模型的復雜性。為了降低內存消耗和提高計算效率,一些學者使用了八叉樹結構代替固定分辨率的體素結構。八叉樹結構使得網絡可以更深層次地表示數據,而不影響分辨率。然而,八叉樹結構也存在一些局限性,例如不能充分利用局部數據特征,因此未來研究可以致力于解決這些問題以提高基于體素的方法在點云分類中的效果。
C. 基于點云的方法
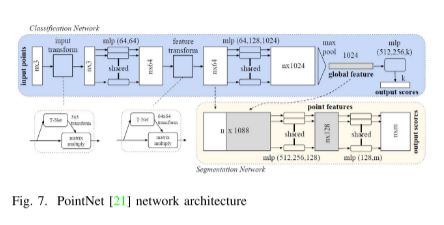
許多當前的研究方法更多地關注于使用深度學習技術直接處理點云。特征聚合運算符是處理點云的核心,它實現了離散點的信息傳遞。特征聚合運算符主要分為兩類:局部特征聚合和全局特征聚合。在本節中,從特征聚合的角度出發,將介紹這兩類方法。 2017年,齊等人提出的PointNet(如圖7所示)是基于點云的方法的開創性研究,這是一種全局特征聚合的方法。該方法直接將點云作為輸入,通過T-Net模塊對其進行變換,然后通過共享全連接學習每個點,最后通過最大池化函數將點的特征聚合成全局特征。盡管PointNet是基于深度學習的先驅,但仍然存在缺陷。例如,PointNet只捕捉了單個點和全局點的特征信息,但并未考慮相鄰點的關系表示,這使得PointNet無法有效地進行細粒度分類。
局部特征聚合
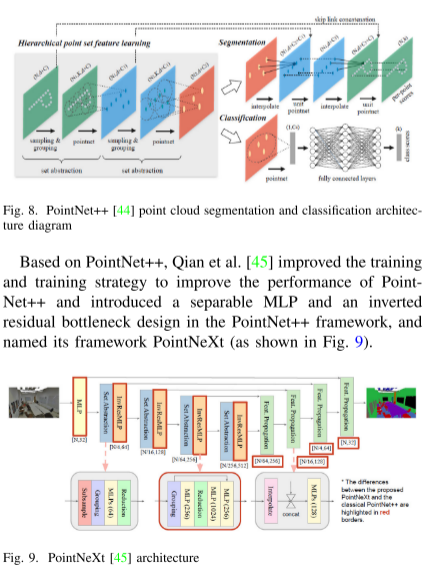
局部特征聚合是點云處理的核心,實現了離散點的信息傳遞。從特征聚合的角度來看,局部特征聚合分為兩類方法:點對點方法和基于采樣的方法。點對點方法如PointNet++通過分層處理點云,每一層包含采樣、分組和PointNet層,能夠處理局部鄰域的特征,并考慮點之間的關系。在此基礎上,一些方法如PointNeXt、PointWeb和RandLA-Net進一步改進了局部特征的提取和聚合方式,提高了性能和效率。基于采樣的方法通過空間填充曲線等方式對點云進行采樣,然后通過特征融合模塊學習結構和相關信息,如PointSCNet。另外,一些方法如GDANet引入了幾何解纏模塊來捕捉和細化幾何信息,取得了良好的效果。局部特征聚合方法的發展使得點云處理能夠更好地捕捉局部結構,提高了處理效率和性能。
基于卷積的方法
基于卷積的方法將傳統的卷積神經網絡(CNN)擴展到處理不規則的三維點云數據上,是處理點云分類的重要方法。這些方法主要包括以下方面的研究:
Point Convolution:將點云上的函數擴展為連續體函數,并在此基礎上進行卷積操作,例如PCNN(Point Convolutional Neural Network)。
Relation-based Convolution:通過建立點云中點與點之間的關系來進行卷積操作,如RS-CNN(Relational Shape Convolutional Networks)。
Dynamic Filter Convolution:應用動態濾波器來處理點云上的卷積操作,例如PointConv。
Monte Carlo Integration Convolution:將卷積看作蒙特卡洛積分來處理,如MCCNN。
Spatial Pooling Convolution:使用空間池化來對點云進行卷積,例如DNNSP。
Hierarchical Convolution:通過層級結構進行卷積操作,例如SpiderCNN。
Anisotropic Spatial Geometry Convolution:利用空間覆蓋卷積來處理點云,如SC-CNN(Spatial Coverage Convolutional Neural Network)。
這些方法的設計旨在有效地處理點云的不規則性、稀疏性和無序性,從而提高點云分類的準確性和效率。
基于圖的方法
基于圖的方法利用圖神經網絡(GNN)等技術處理點云數據。這些方法主要包括以下幾種類型:
圖卷積網絡(GCN)優化:GCN是對CNN的優化,能夠在半監督分類任務中表現良好。一些方法對GCN進行了改進,如使用覆蓋感知網絡查詢(CAGQ)提高空間覆蓋率,并簡化網絡模型以解決梯度消失問題。
邊緣條件卷積(ECC)網絡:ECC網絡可應用于任何圖結構,并能夠捕獲圖中點之間的關系,有助于圖像分割等任務。
動態圖CNN(DGCNN):DGCNN通過邊緣卷積(EdgeConv)網絡模塊提取點云的局部幾何特征,保持排列不變性,對于3D識別任務具有重要意義。
多級圖卷積網絡(GCN):這些網絡能夠分層聚合單視圖點云的形狀特征,有助于編碼對象的幾何線索和多視圖關系,生成更具體的全局特征。
鄰域圖濾波器:這種方法使用鄰域圖濾波器提取特征空間和笛卡爾空間中的鄰域特征信息和空間分布信息,有助于更好地理解點云數據。
基于圖的方法能夠有效地處理點云數據,提取特征并解決分類、分割等任務,為點云分析領域的研究提供了重要的技術支持。
基于注意力機制的方法
基于注意力機制的方法將人類感知的選擇性應用于機器學習,專注于處理數據的部分信息而非整體。在點云分類中,研究者們利用注意力機制來提高模型對關鍵信息的關注程度。這些方法包括以下幾個方面的工作:
點注意力變換器(PAT):使用高效的Group-Shuffle Attention(GSA)代替昂貴的Multi-Head Attention(MHA),從而減少計算成本。
特征金字塔注意力模塊(FPA)和全局注意力上采樣模塊(GAU):結合注意力機制和空間金字塔,提高模型對不同尺度特征的關注度。
局部空間感知(LSA)層:學習局部區域的空間關系,生成空間分布權重,執行空間獨立操作,從而提取局部信息。
圖注意力卷積(GAC):利用圖注意力卷積來提高模型對點云中局部信息的關注度。
GAPointNet:結合自注意力機制和圖卷積,學習局部信息表示,并使用并行機制來聚合不同層級的注意力特征,從而更好地提取局部上下文特征。
這些方法通過增強模型對點云中不同區域的關注度,提高了點云分類任務的性能和準確性。
全局特征聚合
基于Transformer的方法
基于Transformer的方法在點云處理領域取得了顯著的進展。這些方法通過將點云作為輸入,并利用Transformer結構中的自注意力機制,實現了對點云的全局特征建模和關聯學習。具體而言,這些方法包括以下關鍵點:
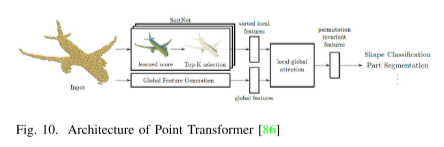
Point Transformer: Engel等人提出的Point Transformer直接操作無序和非結構化的點集。它使用學習分數的焦點模塊來提取局部和全局特征,并通過排序網絡對局部特征進行排序,最后通過局部全局注意力關聯局部和全局特征。
Point TnT: Berg等人提出的Point TnT方法通過兩階段機制有效地實現了單個點和點集之間的相互關注,解決了傳統自注意力機制在處理全局關系時效率低下的問題。
Visual Transformer (VT): Wu等人的VT將Transformer應用于基于特征圖的圖像標簽,更高效地學習和關聯稀疏分布的高級概念。
Detection Transformer (DETR): Carion等人的DETR將目標檢測視為直接集成預測問題,使用Transformer編碼器-解碼器生成邊界框,實現了端到端的檢測Transformer。
Point Cloud Transformer (PCT): Guo等人的PCT是一種基于Transformer的點云學習框架,通過偏移注意力和歸一化細化實現了對點云的全局特征建模,具有置換不變性。
Point-BERT: Yu等人的Point-BERT將BERT的概念推廣到點云,通過局部塊和點云標記器生成局部信息的離散點標簽,實現了對點云的建模和學習。
這些方法利用Transformer的優勢,在點云處理中取得了令人矚目的成果,為點云的全局特征建模和關聯學習提供了新的思路和方法。
基于全局模塊的方法
基于全局模塊的方法旨在處理點云中的全局特征聚合問題。這些方法通過設計特定的模塊或網絡結構,能夠有效地捕獲整個點云的全局信息,從而提高了點云處理任務的性能。一些方法包括:
全局模塊:該模塊計算某個位置的響應,作為所有位置特征的加權和,從而聚合全局特征。
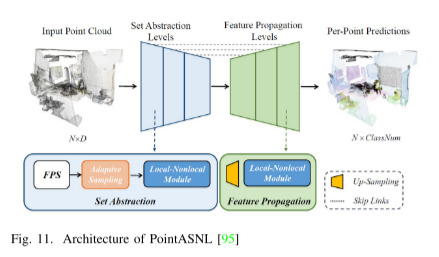
PointASNL:該端到端網絡結合了自適應采樣模塊(AS)和局部非局部模塊(L-NL),可以有效地處理嘈雜的點云。AS模塊通過推理更新點的特征,并通過重新加權初始采樣點來緩解偏置效應。L-NL模塊由點的局部和非局部單元組成,降低了學習過程對噪聲的敏感性。
DeepGCN:這是一種深度GCN架構,采用了一些CNN方法來支持。它包括GCN骨干模塊用于輸入點云特征轉換,融合模塊用于生成和融合全局特征,以及MLP模塊預測模塊用于預測標簽。DeepGCN的設計旨在解決GCN訓練中梯度消失的問題,使得可以訓練更深層的GCN網絡。
CurveNet:這是一種基于聚合假設曲線的方法,有效地實現了曲線的聚合策略。CurveNet的網絡結構由一系列構建塊組成,其中包括曲線分組運算符和曲線聚合運算符。
基于RNN或LSTM的方法 RNN(循環神經網絡)
基于RNN或LSTM的方法通常利用這些循環結構處理序列信息或全局上下文信息,以提高點云處理任務的性能和準確性。Engelmann等人提出了擴展了PointNet的PointNet++,以處理大規模場景,并通過引入額外的上下文信息提高了性能。Liu等人提出的3DCNN-DQN-RNN方法融合了多種網絡結構,通過這種融合提高了處理大規模點云的準確性。其他方法如RSNet、3P-RNN和Point2Sequence等也通過結合RNN或LSTM等循環結構,有效地利用了上下文信息,提高了點云處理的性能。
D. 多態融合方法
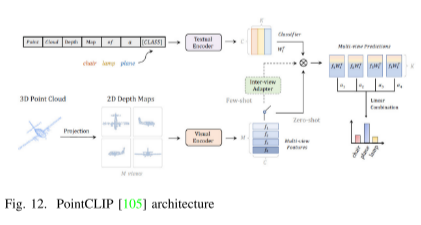
多態融合方法將不同的數據表示方式融合在一起,以綜合利用它們的優勢。Le等人提出了一種將點云和網格結合的策略,通過卷積塊和最大池化來表示不同層次的特征,能夠更好地識別細粒度模型和表示局部形狀。Zhang等人的PVT方法結合了稀疏窗口注意模塊和相對注意模塊,將體素和點云的思想相結合,在點云分類的準確性方面表現出色。PointCLIP利用預訓練的CLIP學習點云,通過投影到多視圖深度圖中進行編碼,實現了從2D預訓練知識到3D域的零樣本識別。CrossPoint通過最大化點云和對應渲染的2D圖像在不變空間中的表現,實現了2D到3D的對應。與傳統方法相比,多態融合方法能夠更好地利用不同表示方式的信息,有望成為未來點云處理的重要方向。
6. 評估
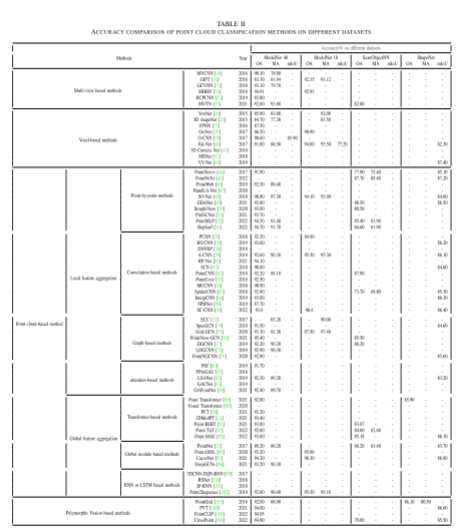
評估是用來衡量點云分類方法性能的重要過程。準確度、空間復雜度、執行時間等是評估方法的關鍵指標,其中準確度是最為關鍵的指標之一。通常使用準確度(Acc)、精度(Pre)、召回率(Rec)和交并比(IoU)等指標來評估方法的準確性。
準確度(Acc)表示正確預測的樣本數與總預測樣本數的比率,是衡量整體分類準確性的指標。
精度(Pre)表示被預測為正類的真實正類的比例,是衡量分類器預測正類的準確性的指標。
召回率(Rec)表示被預測為正類的樣本數與真實正類的總數的比率,是衡量分類器找出所有正類樣本的能力的指標。
交并比(IoU)表示預測值與真實值的交集與并集的比率,是衡量兩個集合重疊程度的指標。
除了上述指標外,還可以使用整體準確度(OA)、平均準確度(MA)和平均交并比(mIoU)等綜合指標來評估方法的性能。這些指標可以幫助研究人員全面了解方法在不同數據集上的表現,并為進一步改進提供參考。
7 總結與展望
在點云分類領域,深度學習方法不斷創新,為3D應用帶來新的可能性。本文綜述了近年來基于深度學習的點云分類方法,包括多視圖、體素、點云和多態融合等不同類型的方法。通過對比分析,可以看出各種方法在準確性、效率和適用場景等方面存在差異。
在評估方面,準確性是評價方法優劣的關鍵指標,同時還需要考慮空間復雜度和執行時間等。常用的評估指標包括準確率、精確度、召回率和交并比等,用于評估方法的性能。
未來的研究方向包括提高準確性和效率的平衡、針對室外場景進一步優化方法、簡化點云處理流程等。創新型方法的研究也是未來的重點,需要不斷探索新的思路和技術。
總的來說,基于深度學習的點云分類方法在不斷發展,未來有望取得更大的突破,為3D應用帶來更多可能性。
-
3D
+關注
關注
9文章
2955瀏覽量
110165 -
三維
+關注
關注
1文章
517瀏覽量
29388 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46618 -
深度學習
+關注
關注
73文章
5557瀏覽量
122580
原文標題:必看綜述!中科院帶你徹底了解基于深度學習的三維點云分類
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
港中文和商湯研究員提出高效的三維點云目標檢測?新框架
計算機視覺:三維點云數據處理學習內容總結


基于三維激光點云的目標識別與跟蹤研究







 工商網監
工商網監
評論