") 揭秘JDQ限流架構(gòu):實(shí)時(shí)數(shù)據(jù)鏈路的多維動(dòng)態(tài)帶寬管控
揭秘JDQ限流架構(gòu):實(shí)時(shí)數(shù)據(jù)鏈路的多維動(dòng)態(tài)帶寬管控
作者:京東零售 饒璐
1、背景
在數(shù)字化轉(zhuǎn)型的浪潮席卷之下,大數(shù)據(jù)和云計(jì)算技術(shù)已成為企業(yè)創(chuàng)新和發(fā)展的關(guān)鍵驅(qū)動(dòng)力。尤其是以京東為代表的電商平臺(tái)為例,其日常運(yùn)營中持續(xù)生成海量數(shù)據(jù),涵蓋實(shí)時(shí)交易記錄、點(diǎn)擊曝光統(tǒng)計(jì)及用戶行為軌跡等,這些數(shù)據(jù)對精準(zhǔn)業(yè)務(wù)決策、深化用戶體驗(yàn)優(yōu)化等方面具有重要意義。然而,隨著業(yè)務(wù)版圖的快速擴(kuò)張,特別是在618、雙11等年度大促盛宴中,數(shù)據(jù)流量呈現(xiàn)井噴式增長,給數(shù)據(jù)系統(tǒng)帶來前所未有的壓力。
在此情境下,盡管Apache Kafka憑借其卓越的高吞吐能力與低延遲特性,成為了企業(yè)處理實(shí)時(shí)數(shù)據(jù)流的首選,但面對當(dāng)今降本增效的宏觀趨勢,企業(yè)急需在不增加過多資源負(fù)擔(dān)的前提下,實(shí)現(xiàn)效能的最大化。特別是針對網(wǎng)絡(luò)帶寬這一寶貴資源,如何在海量數(shù)據(jù)與復(fù)雜業(yè)務(wù)場景交織的挑戰(zhàn)中,實(shí)施更加精細(xì)、高效且智能的流量限速控制策略,以確保消息中間件服務(wù)能夠持續(xù)提供高可用性與高穩(wěn)定性,成為了企業(yè)技術(shù)團(tuán)隊(duì)亟需攻克的難關(guān)。
JDQ 是基于 Apache 基金會(huì)開源的 Kafka 消息隊(duì)列,深入打造的具備高吞吐、低延遲、高可靠性的實(shí)時(shí)流式消息中間件框架,可應(yīng)用于數(shù)據(jù)管道、實(shí)時(shí)數(shù)倉、數(shù)據(jù)分析、等多種場景,是京東統(tǒng)一的實(shí)時(shí)數(shù)據(jù)總線。京東JDQ團(tuán)隊(duì)結(jié)合降本增效的行業(yè)趨勢,針對開源Kafka在限流技術(shù)方面的不足和局限性進(jìn)行了深入研究,并在此基礎(chǔ)上進(jìn)行了創(chuàng)新性優(yōu)化,開發(fā)出支持多維度、動(dòng)態(tài)以及優(yōu)先級等限流功能的JDQ帶寬管控限流架構(gòu)。本文將針對Kafka限流存在的問題,以及JDQ限流架構(gòu)進(jìn)行深入介紹。
2、Kafka 限流
2.1 限流概述
在服務(wù)器日常運(yùn)營中,限流是一種自我保護(hù)機(jī)制,用于避免突發(fā)和異常的數(shù)據(jù)流入流出量徒增對系統(tǒng)造成的沖擊。這種情況尤其常見于電商促銷高峰期,此時(shí)某些特定的主題(topics)可能會(huì)經(jīng)歷流量激增,導(dǎo)致過多的占用Broker帶寬資源和磁盤I/O資源。如果不加以控制,這不僅會(huì)影響其他客戶端的正常讀寫操作,還會(huì)干擾集群內(nèi)部的主從同步過程,給整個(gè)集群帶來巨大的壓力。當(dāng)集群承受過大的壓力,不僅可能導(dǎo)致服務(wù)過載,甚至可能引發(fā)系統(tǒng)崩潰。部分節(jié)點(diǎn)的故障雪崩,最終會(huì)波及到集群內(nèi)所有業(yè)務(wù)的正常運(yùn)行。因此,通過精細(xì)化的限流策略,我們能夠有效維護(hù)集群的穩(wěn)定運(yùn)作,保障業(yè)務(wù)的連續(xù)性和服務(wù)質(zhì)量。
2.2 原生 Kafka 限流機(jī)制
Kafka 原生的限流機(jī)制是配額優(yōu)先級限流機(jī)制,kafka提供兩個(gè)配額配置參數(shù),三種粒度來進(jìn)行限流管理:
兩個(gè)配置參數(shù):(可以動(dòng)態(tài)調(diào)整)
(1)producer_byte_rate:生產(chǎn)者單位時(shí)間(每秒)內(nèi)最高允許發(fā)送到單臺(tái)broker的字節(jié)數(shù)。
(2)consumer_byte_rate:消費(fèi)者單位時(shí)間(每秒)內(nèi)最高允許從單臺(tái)broker拉取的字節(jié)數(shù)。
三種粒度:
(1)user(認(rèn)證方式)
(2)client.id(客戶端標(biāo)識(shí))
(3)user + client.id
user只能在集群中開啟身份認(rèn)證鑒權(quán)的情況下使用,在每個(gè)broker的ProduceRequest和FetchRequest中攜帶的client/user客戶端身份標(biāo)識(shí),進(jìn)行對應(yīng)的限流。
Kafka 為user、client-id以及 (user+client-id)這三種粒度定義配額配置,同時(shí)支持設(shè)定默認(rèn)值,具體的配額可以覆蓋默認(rèn)配額,配額配置參數(shù)都是寫入zookeeper的 /config 路徑下,其中user 以及 (user+client-id)的配置是寫入 /config/users 下,而client-id是直接寫入 /config/clients 下,可以設(shè)置所有的user或者所有的clients默認(rèn)配額,如果有指定user或者指定clients則會(huì)覆蓋默認(rèn)值。這些覆蓋可以及時(shí)被服務(wù)監(jiān)聽,無需滾動(dòng)重啟整個(gè)集群也能夠動(dòng)態(tài)更新這些參數(shù)配置。
如果同時(shí)配置了多粒度的參數(shù),限流優(yōu)先級從高到低如下:
/config/users//clients/ 指定的 user+client-id的配置值 那么優(yōu)先級最高; /config/users//clients/ 指定user配置+clients的默認(rèn)值 /config/users/ 單獨(dú)的user粒度,指定user /config/users//clients/ user的默認(rèn)值+指定client-id /config/users//clients/ user的默認(rèn)值+默認(rèn)的client-id /config/users/ 單獨(dú)的user的粒度,所有user的默認(rèn)值 /config/clients/ 單獨(dú)的client-id粒度,指定client-id /config/clients/ 單獨(dú)的client-id粒度,所有client的默認(rèn)值,優(yōu)先級最低
如果同時(shí)集群下存在多種配額配置參數(shù),以優(yōu)先級高的配額配置為準(zhǔn)。
舉一個(gè)例子解釋限流優(yōu)先級:如果指定一個(gè)user,userA設(shè)定他的producer_byte_rate為10M/s,同時(shí)該集群上還為所有user的都配置了默認(rèn)producer_byte_rate為50M/s,以及為默認(rèn)值下還設(shè)置了client-id粒度的配額;此時(shí)如果那user認(rèn)證的生成程序向集群生產(chǎn),生產(chǎn)速率的配額,應(yīng)該以user指定為準(zhǔn),即為10M/s。(第3級優(yōu)先于第5級)
限流算法:
我們假設(shè)當(dāng)前實(shí)際速率是O,T是預(yù)設(shè)的user限流速率值(可以根據(jù)實(shí)際情況配置),而W表示某一段時(shí)間范圍,我們希望在W時(shí)間內(nèi)O能夠下降到T以下(如果O本來就比T小,則什么都不用做),那么broker端就需要延緩等待一段時(shí)間后再響應(yīng)請求。如果假設(shè)這段時(shí)間是X,那么以下等式成立:
O * W = (W + X) * T
由此得出X = (O - T) / T * W。這就是Kafka用于計(jì)算限流等待時(shí)間的公式。當(dāng)然在具體實(shí)現(xiàn)時(shí),Kafka提供了兩個(gè)參數(shù)來共同計(jì)算W:W = quota.window.num * quota.window.size.seconds。前者表示取樣的時(shí)間窗口個(gè)數(shù),后者表示時(shí)間窗口大小。
超額處理:
消息隊(duì)列本身的功能是削峰填谷,在有突發(fā)流量的時(shí)候,流量很容易超過配額。此時(shí),機(jī)器層面一般是有能力處理流量的,如果直接拒絕流量,就會(huì)導(dǎo)致消息投遞失敗,客戶端請求異常。所以,在限流后,Kafka的處理方式是延時(shí)回包,通過加大單次請求的耗時(shí),整體上降低集群的吞吐。因?yàn)檎顟B(tài)下,客戶端和服務(wù)端的連接數(shù)是穩(wěn)定的,如果提升單次處理請求的耗時(shí),集群整體流量就會(huì)相應(yīng)下降。增加的耗時(shí)時(shí)長就是使用上述的限流算法計(jì)算的。
2.3 Kafka限流舉例
Kafka限流是各個(gè)粒度對于broker-topic請求下的限流,依賴于這個(gè)broker上承擔(dān)了多少個(gè)分區(qū)的 leader 分布,下述兩個(gè)例子具體說明:(以生產(chǎn)請求為例,特定user只設(shè)置了user的生產(chǎn)配額)
eg1:假設(shè)存在topic1,有3個(gè)分區(qū),每個(gè)分區(qū)有2個(gè)副本,具體的副本分區(qū)如下圖,其中分區(qū)色塊為粉紅色的是leader節(jié)點(diǎn)
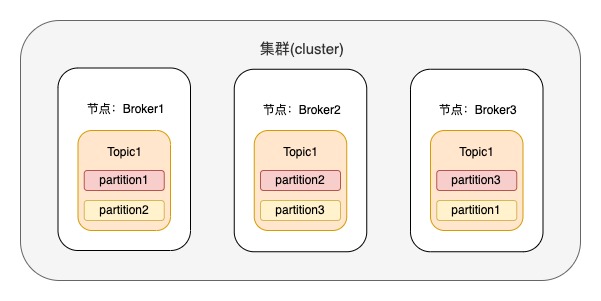
當(dāng)user1 對 topic1 授予了producer的權(quán)限,user1的單機(jī)生產(chǎn)限流配額 producer_byte_rate 為10M/s,那使用user通過認(rèn)證的生產(chǎn)客戶端可以往topic1里的每個(gè)分區(qū)生產(chǎn)數(shù)據(jù),那么每個(gè)分區(qū)的峰值流量都為10M/s;超過10M/s將會(huì)用觸發(fā)限流機(jī)制,根據(jù)限流算法計(jì)算出一個(gè)等待時(shí)長,來延緩下一個(gè)生產(chǎn)請求的發(fā)出。
eg2:假設(shè)存在topic2,有3個(gè)分區(qū),每個(gè)分區(qū)有2個(gè)副本,具體的副本分區(qū)如下圖,其中分區(qū)色塊為粉紅色的是leader節(jié)點(diǎn)
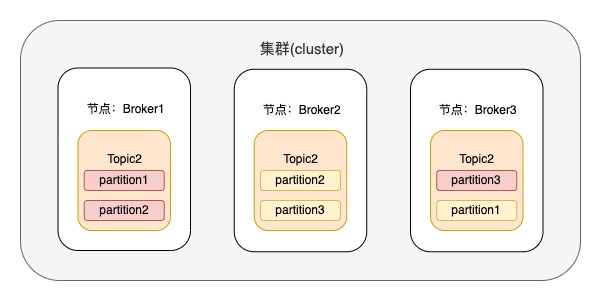
當(dāng)user1 對 topic2 授予了producer的權(quán)限,user2的單機(jī)生產(chǎn)限流配額 producer_byte_rate 為10M/s,那使用user通過認(rèn)證的生產(chǎn)客戶端可以往topic1里的每個(gè)分區(qū)生產(chǎn)數(shù)據(jù),那么分區(qū)1,2共享限流為10M/s;分區(qū)3的限流為10M/s;同樣;當(dāng)分區(qū)1和分區(qū)2累加的每秒生產(chǎn)的字節(jié)數(shù)超過了10M/s,或者分區(qū)3每秒生產(chǎn)的字節(jié)數(shù)超過了10M/s,觸發(fā)限流機(jī)制。
2.4 Kafka限流機(jī)制的局限性分析
2.4.1 Broker-Topic維度限流的固有缺陷:節(jié)點(diǎn)故障leader切換引發(fā)的速率波動(dòng)
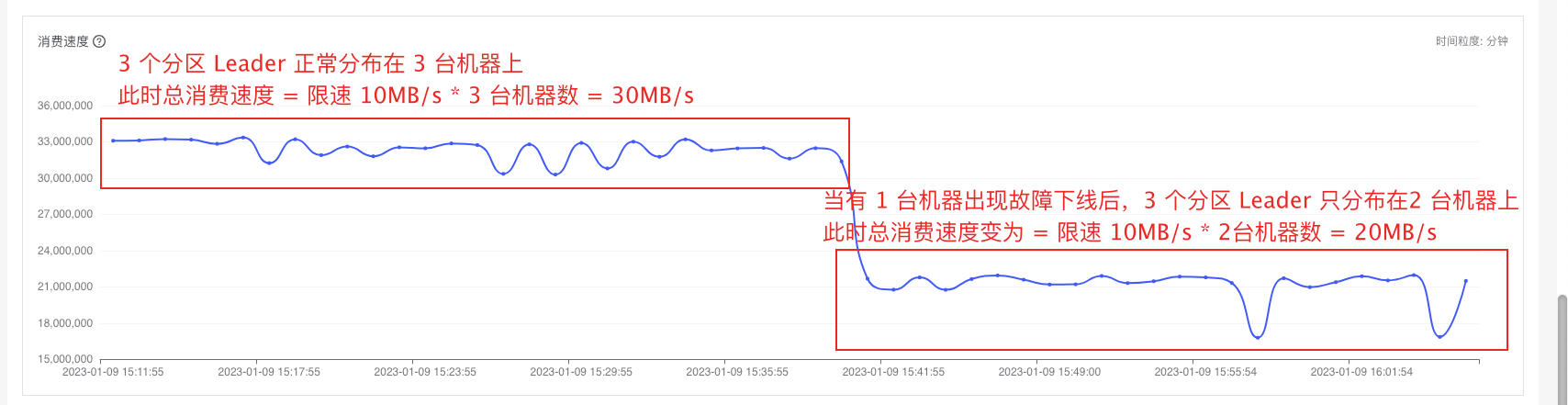
從2.3的兩個(gè)例子中,不難發(fā)現(xiàn),如果Kafka集群的某個(gè)Topic Leader在發(fā)生故障切換時(shí),會(huì)對生產(chǎn)與消費(fèi)速率產(chǎn)生的間接影響,暴露了現(xiàn)有限流機(jī)制的一個(gè)短板。在標(biāo)準(zhǔn)配置下,生產(chǎn)者消費(fèi)者的吞吐量分配與分區(qū)Leader的物理分布密切相關(guān)。
具體而言,假設(shè)一Topic擁有m個(gè)分區(qū),初始分布于n個(gè)活躍Broker之上,每個(gè)Broker承載m/n個(gè)分區(qū)的Leader。消費(fèi)者對于該Topic的限速配額設(shè)定為 s MB/s,理論上可實(shí)現(xiàn)總吞吐量 s*n MB/s。然而,一旦某Broker遭遇故障,Leader角色將重新分配至剩余 n-1 個(gè)Broker,盡管整體分區(qū)數(shù)保持不變,但限速原則卻按s*(n-1) MB/s重新計(jì)算,導(dǎo)致吞吐量驟減。這一現(xiàn)象表示Kafka限流算法在適應(yīng)動(dòng)態(tài)故障場景時(shí)的脆弱性,用戶需承受非預(yù)期的消費(fèi)速率下降及潛在的數(shù)據(jù)積壓風(fēng)險(xiǎn)。
2.4.2 缺乏單機(jī)限流機(jī)制與實(shí)時(shí)彈性調(diào)節(jié)能力
根據(jù)2.2所述,Kafka 現(xiàn)行限流機(jī)制聚焦于 User-Client 層面,忽視了單機(jī) Broker 的容量限制,從而在面對這個(gè) broker 下的user的生產(chǎn)/消費(fèi)的總速率超過單機(jī)硬件限制的理論帶寬上限的情況時(shí),只能手動(dòng)向下調(diào)整平臺(tái)上與 broker 有關(guān)的生產(chǎn)者,消費(fèi)者的配額參數(shù),而 Kafka 集群本身并不會(huì)做出什么相應(yīng)的限流舉動(dòng),任由過載狀態(tài)持續(xù)影響所有業(yè)務(wù),直至觸發(fā)網(wǎng)絡(luò)擁塞或數(shù)據(jù)丟失。同時(shí),Kafka 限流機(jī)制高度依賴于預(yù)先設(shè)定的業(yè)務(wù)系統(tǒng)限流配額,無法依據(jù)實(shí)時(shí)網(wǎng)絡(luò)狀況或 Broker 負(fù)載動(dòng)態(tài)調(diào)整對應(yīng)的生產(chǎn)消費(fèi)配額,削弱了系統(tǒng)的彈性和響應(yīng)性。
2.4.3 資源分配非最優(yōu)與業(yè)務(wù)優(yōu)先級處理缺失
當(dāng)前限流技術(shù)在自動(dòng)化處理業(yè)務(wù)重要性等級方面存在短板,未能充分考慮到不同業(yè)務(wù)場景的獨(dú)特性。特別是在資源競爭激烈的環(huán)境中,該技術(shù)未能針對不同業(yè)務(wù)的關(guān)鍵程度做出有效區(qū)分。當(dāng)達(dá)到限流閾值時(shí),所有業(yè)務(wù)均遭受無差別的限制,忽視了高優(yōu)先級服務(wù)的特殊需求。這種粗放式的處理方式,不僅無法滿足特定業(yè)務(wù)場景的個(gè)性化需求,還可能阻塞關(guān)鍵業(yè)務(wù)流程或降低用戶體驗(yàn),進(jìn)而引發(fā)用戶的不滿和投訴。在當(dāng)前強(qiáng)調(diào)成本控制和效率提升的大環(huán)境下,迫切需要一種解決方案,能夠在資源緊張時(shí)優(yōu)先保障高優(yōu)先級業(yè)務(wù),通過錯(cuò)峰生產(chǎn)/消費(fèi)模式,實(shí)現(xiàn)資源的合理配置和高效利用,以實(shí)現(xiàn)最大價(jià)值。
綜上所述,開源Kafka在限流技術(shù)方面存在一些不足之處,包括但不限于:
?維度單一:限流策略過于粗放,未能覆蓋分區(qū)級別或單Broker層級的精細(xì)化控制;
?缺乏實(shí)時(shí)彈性:依賴預(yù)設(shè)限流配額,無法根據(jù)實(shí)時(shí)業(yè)務(wù)情況進(jìn)行動(dòng)態(tài)自動(dòng)調(diào)整。
?未區(qū)分業(yè)務(wù)優(yōu)先級:未能根據(jù)業(yè)務(wù)的重要性和緊急性進(jìn)行差異化處理,影響了流量資源的最優(yōu)配置。
上述分析為Kafka限流機(jī)制的改進(jìn)指明了方向,促使我們探索更為先進(jìn)且靈活的限流策略,以應(yīng)對復(fù)雜多變的生產(chǎn)環(huán)境。
3、JDQ限流核心架構(gòu)
3.1 JDQ限流模型
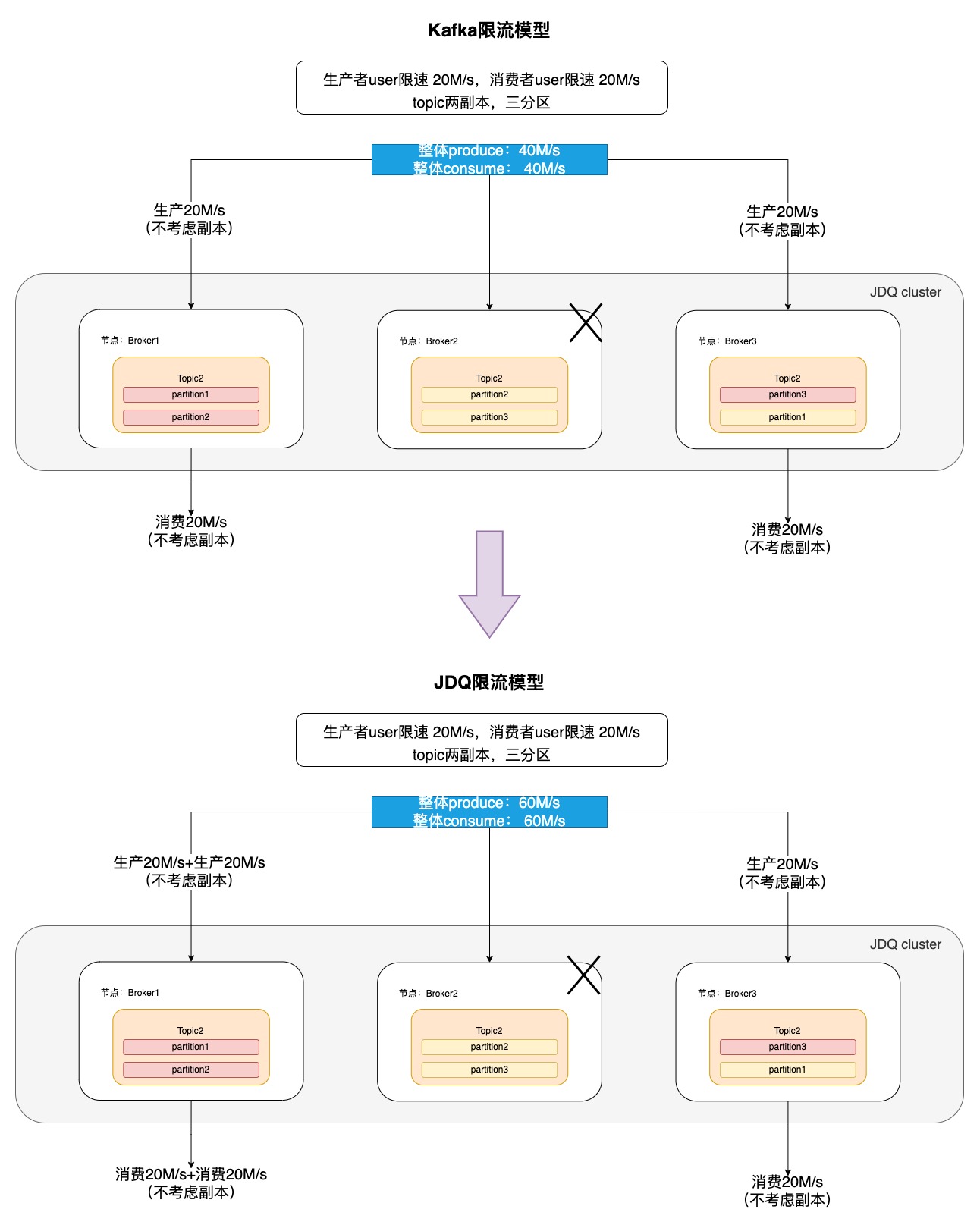
其中:分區(qū)色塊為粉紅色的是leader節(jié)點(diǎn),“X”為故障節(jié)點(diǎn)
3.2 多維度的精細(xì)化限流粒度
如上述限流模型所示,在Kafka的基礎(chǔ)上,JDQ平臺(tái)支持更精細(xì)化粒度限流,即分區(qū)級別限流,可以讓生產(chǎn)消費(fèi)的吞吐量都不受故障節(jié)點(diǎn)影響而降低。
核心邏輯為:在 Controller 發(fā)起的元數(shù)據(jù)更新請求中,記錄下來 Broker 上每個(gè) Topic 對應(yīng)的 leader 數(shù)量,在計(jì)算消費(fèi)等待時(shí)長時(shí),會(huì)讓消費(fèi)限速配額 consumer_byte_rate * 該 Topic 在分區(qū) Leader 數(shù)量,從而實(shí)現(xiàn)不論 Topic 的分區(qū) Leader 分布在幾臺(tái)機(jī)器上,消費(fèi)者或者生產(chǎn)者的總速率都能保持不變
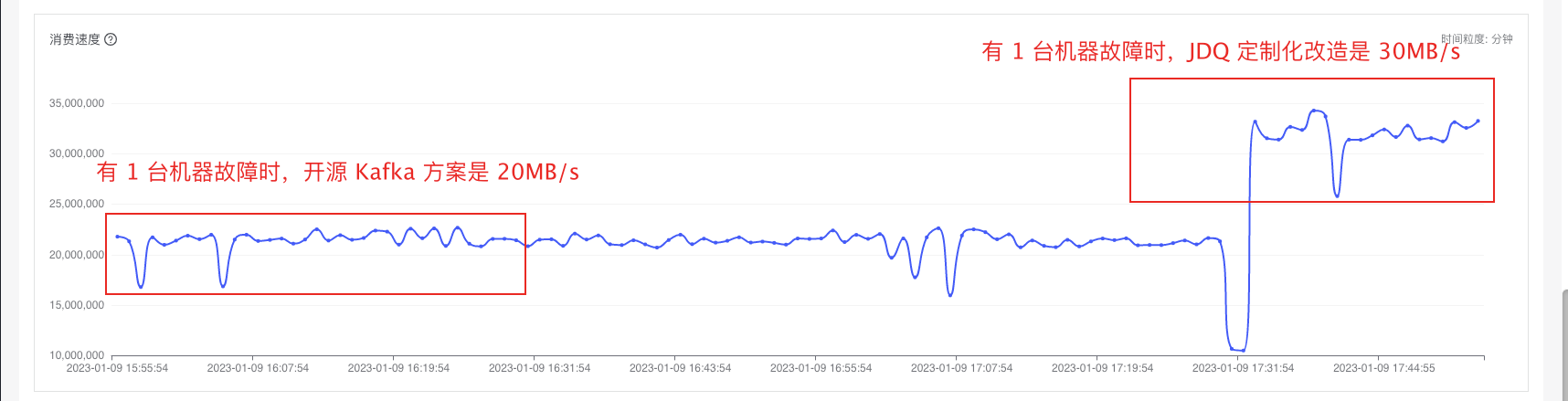
具體而言,假設(shè)一Topic擁有m個(gè)分區(qū),初始分布于n個(gè)活躍Broker之上,每個(gè)Broker承載m/n個(gè)分區(qū)的Leader。生產(chǎn)者/消費(fèi)者對于該Topic的限速配額設(shè)定為 s MB/s,理論上可實(shí)現(xiàn)總吞吐量 s*n MB/s。然而,一旦某Broker遭遇故障,Leader角色將重新分配至剩余 n-1 個(gè)Broker,但是整體分區(qū)數(shù)保持不變,原限流機(jī)制的理論總吞吐為 s*(n-1) MB/s, 但改造后的限流原則在節(jié)點(diǎn)故障前后均用 s*m MB/s計(jì)算,使得速率恒定為 配額*分區(qū)數(shù),進(jìn)而解決機(jī)器故障是對生產(chǎn)/消費(fèi)的吞吐量的影響。
3.3 單機(jī)限流和分級動(dòng)態(tài)彈性限流
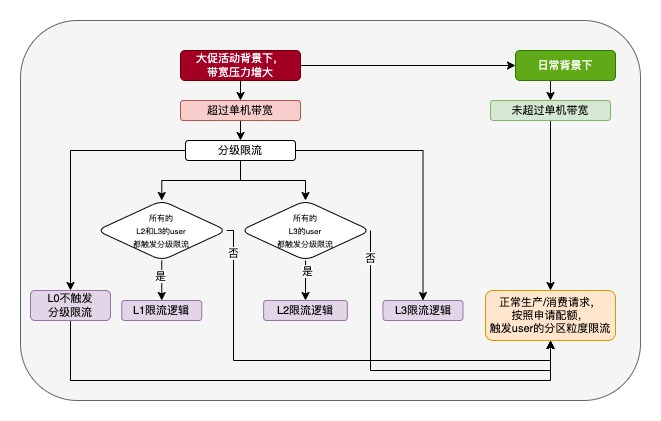
其圖中,L1、L2、L3的限流邏輯為,根據(jù)為每個(gè)等級下分配的被分級限流時(shí)不同的帶寬配額(可動(dòng)態(tài)改配),以及分區(qū)粒度的限流算法進(jìn)行計(jì)算等待時(shí)間,使對應(yīng)等級的業(yè)務(wù)進(jìn)行限流;
這一架構(gòu)的核心在于引入單機(jī)帶寬使用閾值,以及重要性等級機(jī)制(在分區(qū)限流的基礎(chǔ)上),為不同等級(L0,L1,L2,L3)的生產(chǎn)者/消費(fèi)者(即業(yè)務(wù)系統(tǒng))分配差異化的限流帶寬配額。這些參數(shù)可以支持動(dòng)態(tài)配置地傳入Kafka集群服務(wù)端,使得集群能夠?qū)崟r(shí)根據(jù)單機(jī)帶寬使用情況,自動(dòng)、彈性地調(diào)整對各個(gè)重要性等級業(yè)務(wù)系統(tǒng)的限流與恢復(fù)策略。具體來說,當(dāng)單機(jī)帶寬使用超過預(yù)設(shè)閾值時(shí),Kafka集群將依據(jù)重要性等級從低到高,分級實(shí)施限流措施,確保高重要性業(yè)務(wù)系統(tǒng)得到優(yōu)先保障。反之,當(dāng)帶寬使用回落到安全范圍內(nèi)時(shí),系統(tǒng)將自動(dòng)恢復(fù)限流,保障業(yè)務(wù)系統(tǒng)的順暢運(yùn)行。
此架構(gòu)能夠有效地應(yīng)對帶寬使用的潮汐變化,實(shí)現(xiàn)對不同重要性等級業(yè)務(wù)系統(tǒng)的精準(zhǔn)限流與恢復(fù),實(shí)現(xiàn)帶寬資源錯(cuò)峰使用的智能化管理,確保重要性較高的業(yè)務(wù)系統(tǒng)能夠得到優(yōu)先保障,最大程度的減少資源有限的情況下,因帶寬過載而可能造成的損失。此外,還顯著降低現(xiàn)有技術(shù)中人為參與調(diào)整業(yè)務(wù)系統(tǒng)流量配額所耗費(fèi)的人力成本,避免了人為誤操作的風(fēng)險(xiǎn)。同時(shí),其可配置參數(shù)的高度可擴(kuò)展性和靈活性使得用戶可以根據(jù)實(shí)際業(yè)務(wù)需求和網(wǎng)絡(luò)狀況,動(dòng)態(tài)調(diào)整重要性等級、單機(jī)帶寬過載閾值以及限流配額等參數(shù),確保該限流機(jī)制在不同環(huán)境和場景下都能表現(xiàn)出卓越的性能和適應(yīng)性。這一限流架構(gòu)不僅提升了Kafka集群的帶寬管理效率,發(fā)揮有限資源的最大價(jià)值,也增強(qiáng)了業(yè)務(wù)系統(tǒng)的穩(wěn)定性和可靠性。
4、實(shí)際應(yīng)用效果
具體實(shí)例1:(驗(yàn)證分區(qū)限流)三臺(tái)機(jī)器分別為同一個(gè)topic的三個(gè)分區(qū)的leader,經(jīng)過我們分區(qū)粒度的限流后,就算存在有一臺(tái)機(jī)器故障時(shí)(停掉服務(wù)模擬故障),切換leader之后,消費(fèi)者的總速率應(yīng)該為30M/s
原限流邏輯:
改造分區(qū)限流邏輯:
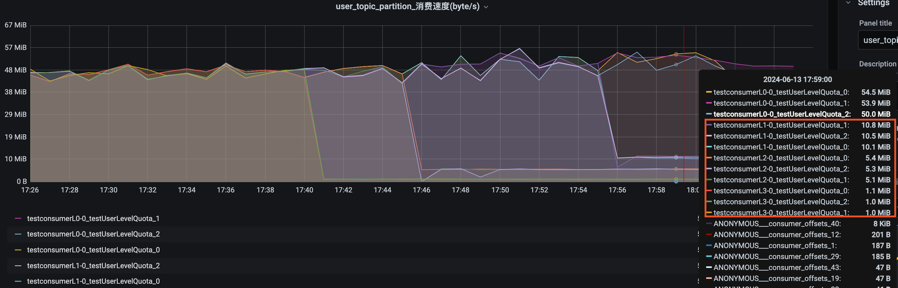
具體實(shí)例2:(驗(yàn)證單機(jī)和分級限流)以消費(fèi)請求為例,JDQ的限流策略是如何在大促洪峰流量出現(xiàn)時(shí),保證資源優(yōu)先分配給高等級的任務(wù)呢?以消費(fèi)為例,當(dāng)機(jī)器單機(jī)流出配額帶寬為50M/s時(shí) (單機(jī)配額較低,模擬數(shù)據(jù)洪峰達(dá)到機(jī)器帶寬上限),對應(yīng)的分級限流的差異化流出帶寬配額為L1-10M/s、L2-5M/s、L3-1M/s。啟動(dòng)L0、 L1、 L2、 L3四個(gè)不同的等級業(yè)務(wù)系統(tǒng)的消費(fèi)程序,正常的消費(fèi)時(shí)分區(qū)速率在50M/s 以上,觸發(fā)逐級限流時(shí)的測試結(jié)果如下圖,L3立即限流至1M/s,L2隔段時(shí)間限流至5M/s,L1再隔段限流至10M/s,L0不限流,按照等級由低到高逐級進(jìn)行限流,對重要性等級高的系統(tǒng)優(yōu)先分配帶寬,優(yōu)化了帶寬資源分配,錯(cuò)峰消費(fèi)。
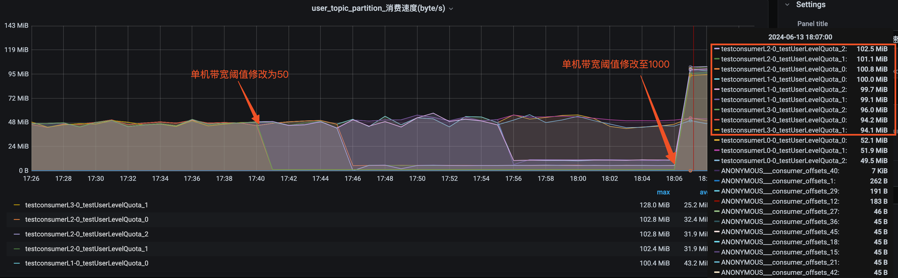
具體實(shí)例3:(驗(yàn)證彈性限流)在實(shí)例2的基礎(chǔ)上,將機(jī)器單機(jī)流出配額帶寬動(dòng)態(tài)修改至1000(模擬數(shù)據(jù)洪峰已過),可以看到所有的就正常全力消費(fèi),不被限制,符合彈性根據(jù)潮汐值進(jìn)行限流
5、未來限流優(yōu)化方向
在未來的Kafka限流技術(shù)研發(fā)方向上,我們將計(jì)劃針對以下幾個(gè)方面進(jìn)行優(yōu)化和創(chuàng)新:
?多形式多粒度的限流粒度:未來優(yōu)化將著眼于更多形式的限流,比如根據(jù)QPS限流,更細(xì)粒度的限流,如消息類型的限流,從而更好地滿足多樣化的業(yè)務(wù)需求和資源分配策略。
?基于容器化的帶寬彈性伸縮:進(jìn)一步探索JDQ與容器技術(shù)的深度融合,實(shí)現(xiàn)集群的按需彈性伸縮。用戶限速帶寬可以根據(jù)平時(shí)的實(shí)際使用率自動(dòng)調(diào)整,確保資源的高效利用與成本控制,同時(shí)提升系統(tǒng)的整體響應(yīng)能力和彈性。
?智能化限流規(guī)劃與研發(fā):為了進(jìn)一步降低運(yùn)維復(fù)雜度,提升系統(tǒng)可靠性,未來將加大投入于智能化限流方案的研發(fā),實(shí)現(xiàn)限流策略的自動(dòng)優(yōu)化,減少人為干預(yù),提升運(yùn)維效率。
綜上所述,JDQ的未來限流優(yōu)化將緊密圍繞用戶需求與技術(shù)前沿,致力于打造一個(gè)既能應(yīng)對高并發(fā)挑戰(zhàn),又能在成本控制,資源管理以及運(yùn)維層面實(shí)現(xiàn)智能化、自動(dòng)化的實(shí)時(shí)數(shù)據(jù)處理平臺(tái)。
6、結(jié)語
我們來自實(shí)時(shí)平臺(tái)研發(fā)部JDQ團(tuán)隊(duì),我們將繼續(xù)致力于 Kafka 限流技術(shù)的優(yōu)化與創(chuàng)新,探索更多前沿技術(shù),以進(jìn)一步提升 Kafka 的穩(wěn)定性和效率。
同時(shí),我們也將加強(qiáng)與業(yè)界的交流與合作,共同推動(dòng) Kafka 技術(shù)的發(fā)展與應(yīng)用,為大數(shù)據(jù)時(shí)代的數(shù)字化轉(zhuǎn)型貢獻(xiàn)更多力量。
審核編輯 黃宇
-
數(shù)字化
+關(guān)注
關(guān)注
8文章
9373瀏覽量
63185 -
數(shù)據(jù)鏈
+關(guān)注
關(guān)注
2文章
39瀏覽量
15947 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8953瀏覽量
139696
發(fā)布評論請先 登錄
Analog Devices Inc. MAX22516 IO-Link數(shù)據(jù)鏈路控制器數(shù)據(jù)手冊
盟通方案|CANopen數(shù)據(jù)鏈路配置工具

自媒體推廣實(shí)時(shí)監(jiān)控從服務(wù)器帶寬到用戶行為解決方法
河道水位監(jiān)測系統(tǒng):全天候、高精度的實(shí)時(shí)數(shù)據(jù)監(jiān)控

ptp對實(shí)時(shí)數(shù)據(jù)傳輸?shù)挠绊?/a>
固定帶寬與動(dòng)態(tài)帶寬的區(qū)別
調(diào)試PCIE鏈路動(dòng)態(tài)均衡介紹
上位機(jī)實(shí)時(shí)數(shù)據(jù)處理技術(shù) 上位機(jī)在智能制造中的應(yīng)用
RNN在實(shí)時(shí)數(shù)據(jù)分析中的應(yīng)用
PCIE數(shù)據(jù)鏈路層架構(gòu)解析
實(shí)時(shí)數(shù)據(jù)與數(shù)字孿生的關(guān)系
實(shí)時(shí)數(shù)據(jù)處理的邊緣計(jì)算應(yīng)用
大數(shù)據(jù)實(shí)時(shí)鏈路備戰(zhàn)——數(shù)據(jù)雙流高保真壓測






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論