") 浪潮信息發(fā)布“源”Yuan-EB助力RAG檢索精度新高
浪潮信息發(fā)布“源”Yuan-EB助力RAG檢索精度新高
近日,浪潮信息發(fā)布 “源”Yuan-EB(Yuan-embedding-1.0,嵌入模型),在C-MTEB榜單中斬獲檢索任務(wù)第一名,以78.41的平均精度刷新大模型RAG檢索最高成績,將基于元腦企智EPAI為構(gòu)建企業(yè)知識(shí)庫提供更高效、精準(zhǔn)的知識(shí)向量化能力支撐,助力用戶使用領(lǐng)先的RAG技術(shù)加速企業(yè)知識(shí)資產(chǎn)的價(jià)值釋放。
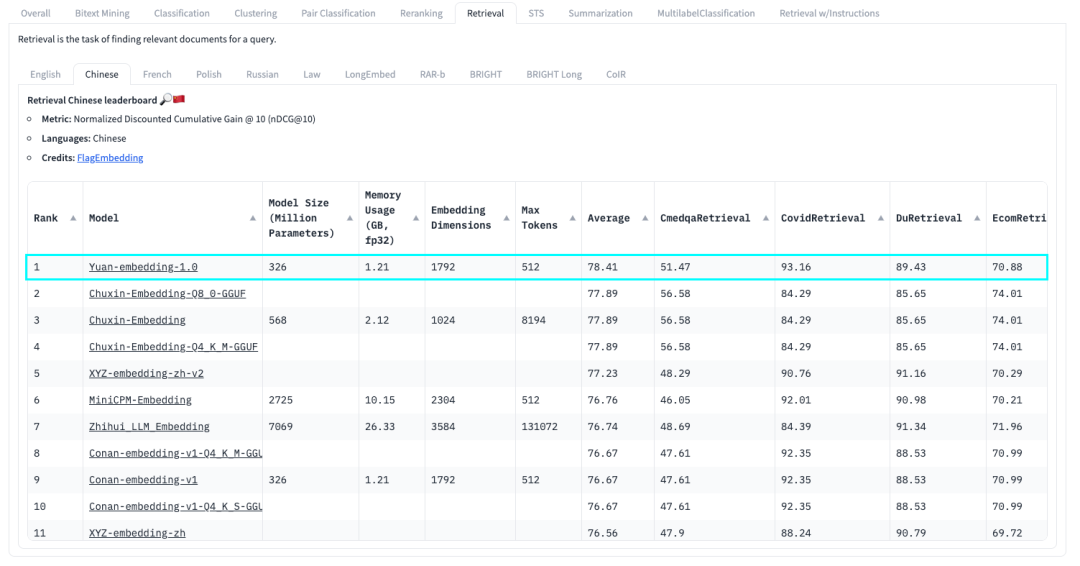
“源”Yuan-EB 在HuggingFace的C-MTEB榜單中排名第一
Yuan-EB(版本號(hào)Yuan-embedding-1.0) 是專為增強(qiáng)中文文本檢索能力而設(shè)計(jì)的嵌入模型(也稱Embedding模型),在 “源2.0” 大模型的工作基礎(chǔ)上,創(chuàng)新性地采用了“源2.0-M32”大模型進(jìn)行數(shù)據(jù)重寫與合成,并通過索引技術(shù)、樣本排序等系列方法完成高質(zhì)量微調(diào)數(shù)據(jù)集構(gòu)建,能夠有效提升RAG系統(tǒng)的檢索精度。
C-MTEB是目前業(yè)內(nèi)最權(quán)威的嵌入模型測試榜單。其中,檢索任務(wù)(Retrieval)是檢索增強(qiáng)生成(RAG)場景下最為重要、應(yīng)用最廣泛的任務(wù)能力,考察的是Embedding模型從大量的數(shù)據(jù)集中找到并返回與給定查詢最相關(guān)或最匹配的信息的過程。“源”Yuan-EB基于該任務(wù)提供的醫(yī)療、新聞、電商、娛樂等8個(gè)中文文本數(shù)據(jù)集,實(shí)現(xiàn)了業(yè)界領(lǐng)先的海量文本檢索精度。
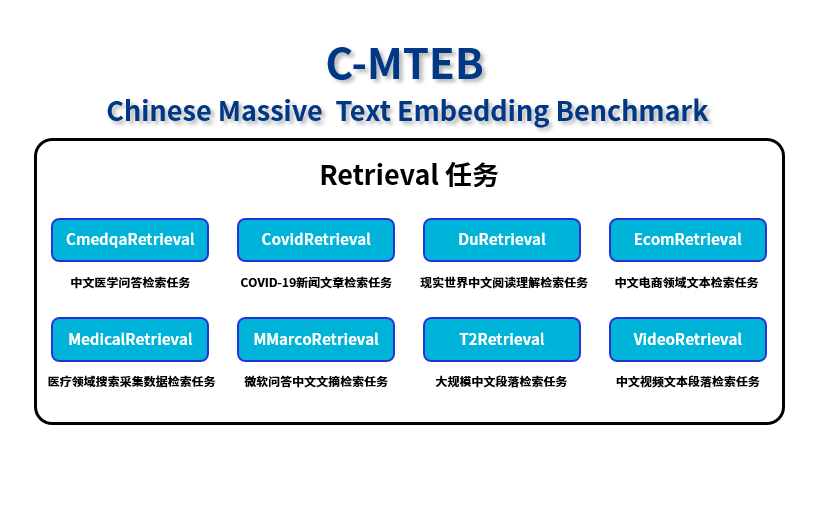
C-MTEB榜單Retrieval任務(wù)提供8個(gè)測試數(shù)據(jù)集
“源” Yuan-EB 助力RAG檢索精度新高
嵌入模型在RAG流程中扮演著關(guān)鍵角色,它能夠?qū)?fù)雜的高維數(shù)據(jù)(例如文本、圖像或音頻)轉(zhuǎn)換為機(jī)器可理解的向量形式,直接決定了RAG檢索的精準(zhǔn)性和效率。
“源”Yuan-EB通過數(shù)據(jù)準(zhǔn)備與模型微調(diào)兩個(gè)方面的技術(shù)創(chuàng)新,實(shí)現(xiàn)了模型精度的大幅提升:
■ 在數(shù)據(jù)方面,基于“源2.0”微調(diào)階段的問答數(shù)據(jù)進(jìn)行清洗與篩選,構(gòu)建問題(query)與文本(corpus)數(shù)據(jù)集;使用“源2.0-M32”對C-MTEB 訓(xùn)練數(shù)據(jù)進(jìn)行重寫與合成,通過索引技術(shù)與排序模型進(jìn)行高效的難負(fù)樣本提取,完成大規(guī)模難負(fù)例樣本挖掘,形成高質(zhì)量微調(diào)數(shù)據(jù)集;
■ 在微調(diào)方面,通過兩個(gè)階段的領(lǐng)先微調(diào)方法實(shí)現(xiàn)模型能力提升。第一階段,使用各個(gè)領(lǐng)域(醫(yī)療、新聞、長文本、娛樂等方向)的大規(guī)模數(shù)據(jù)進(jìn)行對比學(xué)習(xí)訓(xùn)練;第二階段,采用“源2.0-M32”生成的合成數(shù)據(jù)進(jìn)一步微調(diào),并使用MRL方法完成“源”Yuan-EB訓(xùn)練;
“源”Yuan-EB為用戶提供了大模型企業(yè)知識(shí)庫應(yīng)用開發(fā)的最優(yōu)模型選擇,能夠在 RAG流程的多個(gè)方面起到顯著的精度提升,包括信息檢索的準(zhǔn)確性、處理大規(guī)模數(shù)據(jù)的效率、消除語義歧義、降低計(jì)算成本、增強(qiáng)對長文檔的處理能力以及模型魯棒性等,最大化提升RAG流程的整體性能和應(yīng)用效果。
元腦企智EPAI集成“源”Yuan-EB,加速知識(shí)庫構(gòu)建與性能提升
目前,“源”Yuan-EB已經(jīng)在開源社區(qū)和企業(yè)大模型開發(fā)平臺(tái)元腦企智EPAI中全面開放下載。用戶可以在元腦企智EPAI平臺(tái)中快速使用“源”Yuan-EB,并結(jié)合EPAI自研的多階段RAG技術(shù),零代碼、低成本地基于企業(yè)數(shù)據(jù)構(gòu)建大模型知識(shí)庫應(yīng)用。
企業(yè)大模型開發(fā)平臺(tái)“元腦企智”EPAI(Enterprise Platform of AI),是浪潮信息為企業(yè)AI大模型落地應(yīng)用打造的高效、易用、安全的端到端開發(fā)平臺(tái),提供數(shù)據(jù)準(zhǔn)備、模型訓(xùn)練、知識(shí)檢索、應(yīng)用框架等系列工具,支持調(diào)度多元算力和多模算法,幫助企業(yè)高效開發(fā)部署生成式AI應(yīng)用、打造智能生產(chǎn)力。
元腦企智EPAI已經(jīng)支持超過13種類型文檔的信息識(shí)別與提取,結(jié)合創(chuàng)新的多級(jí)混合檢索策略,有效提升元腦企智EPAI在管理、解析、檢索知識(shí)庫與生成內(nèi)容方面的最終效果,幫助企業(yè)用戶實(shí)現(xiàn)基于私有數(shù)據(jù)、行業(yè)數(shù)據(jù)下的精準(zhǔn)檢索、精準(zhǔn)問答,確保專業(yè)場景下大模型生成內(nèi)容的準(zhǔn)確性和可靠性,加速大模型創(chuàng)新力釋放。
-
浪潮
+關(guān)注
關(guān)注
1文章
474瀏覽量
24512 -
開源
+關(guān)注
關(guān)注
3文章
3618瀏覽量
43504 -
大模型
+關(guān)注
關(guān)注
2文章
3035瀏覽量
3840
原文標(biāo)題:浪潮信息發(fā)布“源”Yuan-EB,刷新大模型RAG檢索精度紀(jì)錄!
文章出處:【微信號(hào):浪潮AIHPC,微信公眾號(hào):浪潮AIHPC】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】RAG基本概念
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+第一章初體驗(yàn)
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+Embedding技術(shù)解讀
浪潮信息與智源研究院攜手共建大模型多元算力生態(tài)
浪潮信息與智源研究院達(dá)成戰(zhàn)略合作協(xié)議
浪潮信息發(fā)布"源"Yuan-EB,刷新RAG檢索最高成績
浪潮信息與17家元腦伙伴共簽億級(jí)分銷協(xié)議
借助浪潮信息元腦企智EPAI高效創(chuàng)建大模型RAG

RAG的概念及工作原理
浪潮信息AI存儲(chǔ)性能測試的領(lǐng)先之道

浪潮信息源2.0大模型與百度PaddleNLP全面適配
浪潮信息:元腦企智EPAI助力金融大模型快速落地






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論