") 龍鷹一號(hào)siengine SE1000開發(fā)板測(cè)評(píng)
龍鷹一號(hào)siengine SE1000開發(fā)板測(cè)評(píng)
大家好,這期測(cè)評(píng)一款國(guó)產(chǎn)芯片(龍鷹一號(hào)siengine SE1000)。 主要側(cè)重其中的AI能力部分,圍繞著“如何在開發(fā)板上跑一個(gè)完整AI應(yīng)用”這一主題來寫,前期根據(jù)官方提供的信息編譯簡(jiǎn)單app,跟大家一起熟悉流程,知道如何配置開發(fā)環(huán)境、要用到哪些工具、操作流程是啥。后面接著就跑復(fù)雜一點(diǎn)的AI模型,講解軟件SDK中每個(gè)模塊(parser,quant,Gbuilder,simulator,profiler)的作用,逐代碼進(jìn)行講解,以及如何DIY適配自己的需求等,so, let’s go!
1.硬件信息
龍鷹一號(hào)是一顆國(guó)產(chǎn) 7nm 智能座艙芯片,擁有 8 核 CPU 和 14 核 GPU,CPU算力能夠達(dá)到90~100K DMIPS,GPU算力900+GFLOPS,NPU算力達(dá)到8TOPS,對(duì)標(biāo)的是高通的8155,從安兔兔跑分來看確實(shí)數(shù)據(jù)差不多,目前已知是搭載在吉利汽車旗下領(lǐng)克08(23年9月發(fā)布)車型上
定位是座艙芯片的“龍鷹一號(hào)”不僅會(huì)負(fù)責(zé)中控屏幕的計(jì)算與顯示,還會(huì)負(fù)責(zé)汽車儀表、功能屏幕甚至HUD的顯示。“龍鷹一號(hào)”支持輸入11路相機(jī)數(shù)據(jù)(遺憾的是截至目前,我仍然無法購(gòu)買適配好的攝像頭進(jìn)行應(yīng)用開發(fā)),最高可支持7塊高清顯示屏顯示。 “龍鷹一號(hào)”會(huì)同時(shí)運(yùn)行三個(gè)操作系統(tǒng),分別是儀表的RTOS操作系統(tǒng)、HUD的Linux系統(tǒng)以及中控屏幕的安卓系統(tǒng)(目前提供的SDK默認(rèn)是使用linux系統(tǒng)的);開發(fā)板是交給第三方的RADXA設(shè)計(jì)的,型號(hào)為SiRider S1,具體鏈接在這:https://docs.radxa.com/sirider/s1

雖然BOM中的車規(guī)級(jí)物料改成了普通物料,但是憑借其扎實(shí)的配置(16GB LPDDR5, 128G UFS)還是使得成本達(dá)到了千元+級(jí)別,比同類的開發(fā)板(RK3588、樹莓派)是要貴上三五百塊的,其實(shí)也合理,畢竟RK3588 4核A76,6TopsNPU,450Gops都稍弱于SiRider S1; 由于我們關(guān)注的是AI這一部分,因此固件編譯部分我們就不細(xì)說了,因?yàn)榘遄幽J(rèn)就刷了ubuntu的固件,開箱后插上HDMI顯示器,插入鼠標(biāo)鍵盤就可直接開干了!
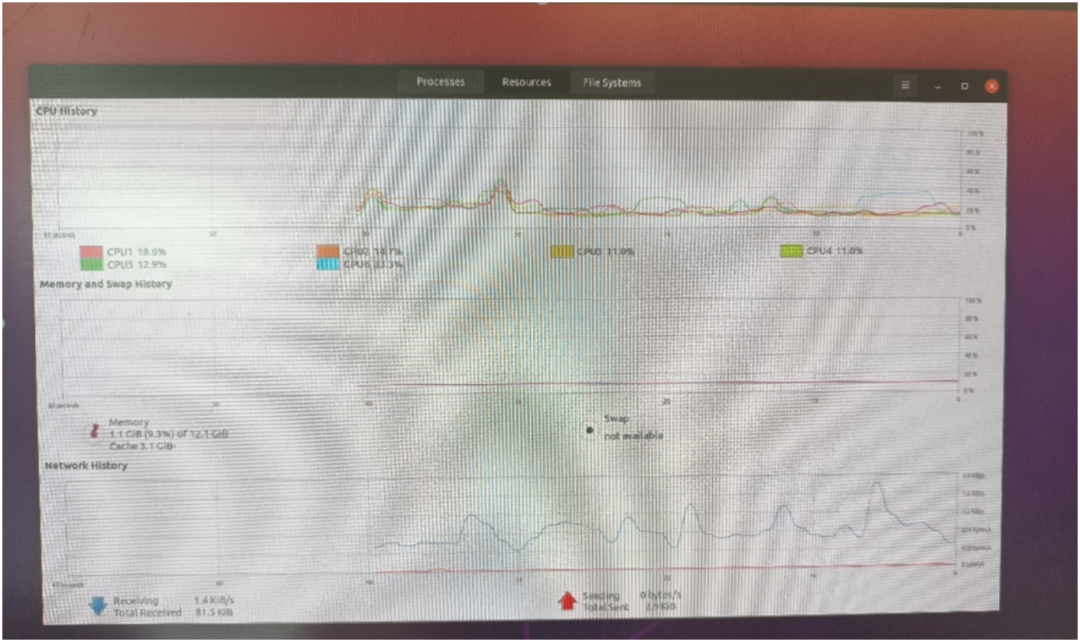
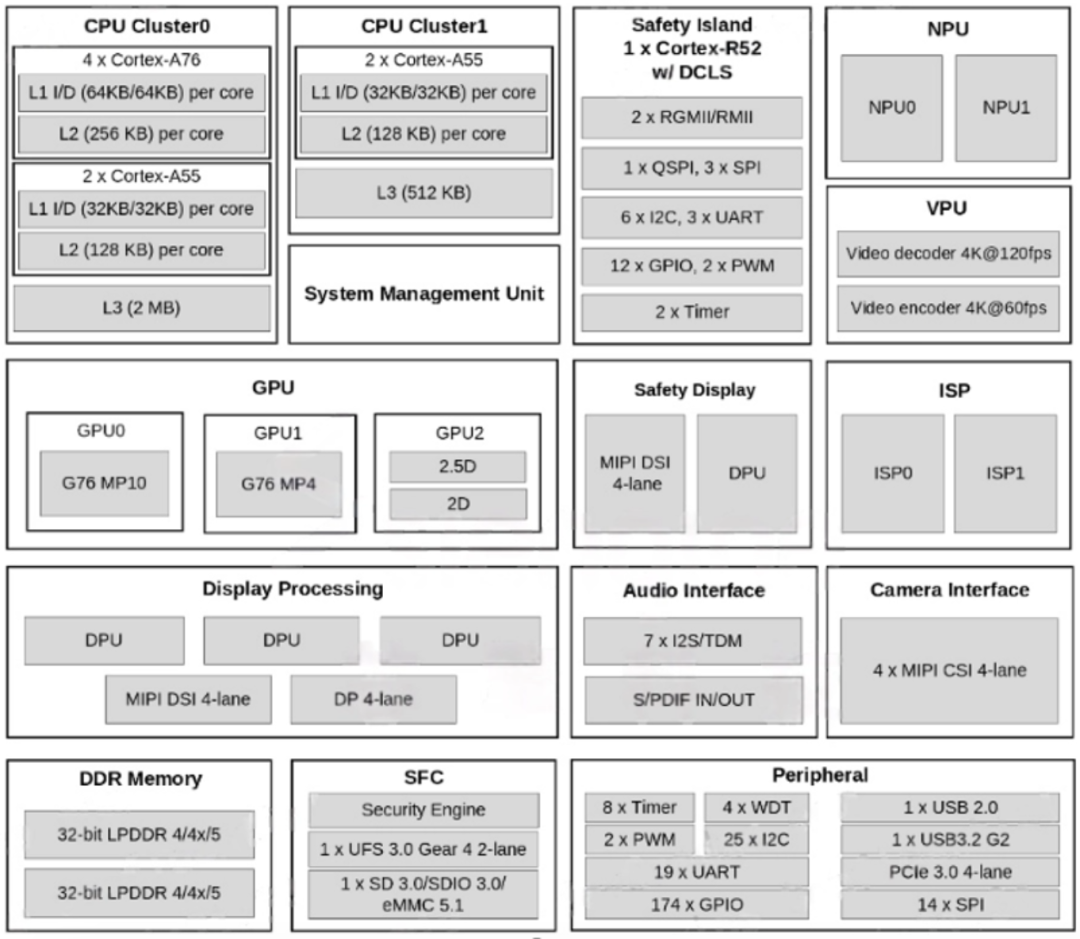
可以看到,ubuntu分配了4個(gè)大核A76+兩個(gè)小核A55;內(nèi)容用了12GB,剩下的都分配給FreeRTos了。 如下圖SOC框架圖所示,主要的算力擔(dān)當(dāng)以及視頻編解碼部分我認(rèn)為足夠驚艷了,用來做NAS,軟路由,平板,電視盒子等應(yīng)用都分分鐘ok的呀!外設(shè)部分同樣如此,接口最多的是UART,IIC跟SPI口,這些都是低速通用接口,因此想要做外設(shè)控制相關(guān)的應(yīng)用的話,指定不是直接去快速控制了(比如FOC無刷電機(jī),一般是需要3PWM接口/電機(jī)來進(jìn)行控制, 而外設(shè)這里只提供了2個(gè)),而是通過低速接口間接驅(qū)動(dòng)外設(shè)模塊了,比如開啟車門,開啟后備箱,開啟雨刮等非實(shí)時(shí)性要求高的應(yīng)用,嗯,定位非常準(zhǔn)確,所以我們做應(yīng)用的時(shí)候盡量去選這三種接口(uart/iic/spi)的封裝較好的獨(dú)立模塊就好了。
2. AI知識(shí)小科普
好的,背景介紹完畢,那我們現(xiàn)在開始進(jìn)入AI部分的內(nèi)容吧!在這個(gè)大模型百家爭(zhēng)鳴的時(shí)代,我相信大家對(duì)AI都有一定的了解吧!
“AI就是人工智能呀!” “AI就是像人一樣跟你對(duì)話!” “AI就能將你的口頭描述轉(zhuǎn)化成實(shí)際的圖片!”
其實(shí)除了這些高大上的AI之外,你每天使用的打卡器(打工人必備)、刷臉機(jī)、以及監(jiān)控?cái)z像頭、麥克風(fēng)等都含有AI技術(shù)在里面,你肯定好奇:
AI到底是怎么跑在具體的硬件設(shè)備上的呢?
假如我自己有個(gè)idea想要實(shí)現(xiàn)跑在具體硬件上,而不是通用PC上,我又該怎么做呢? 接下來我將為你一一解答。 類似于如何將大象塞入一個(gè)冰箱的問題,如何做一個(gè)AI應(yīng)用的頂層流程是這樣的,
第一步,你得有個(gè)天才般或者腦殘般的想法,針對(duì)這個(gè)想法提出需求;
第二步,基于需求訓(xùn)練一個(gè)模型出來;
第三步,將模型部署到具體的硬件上面去。
第一步跟第二步不是我們這次的主要學(xué)習(xí)內(nèi)容,接下來簡(jiǎn)單帶過。 AI模型是由智力絕頂?shù)?a target="_blank">算法工程師們訓(xùn)練出來的,俗稱煉丹。煉丹的丹爐各式各樣,煉丹界主流的就是Tensorflow跟Pytorch;
這顆丹內(nèi)部由一堆的節(jié)點(diǎn)組成,節(jié)點(diǎn)本質(zhì)就是一堆數(shù)據(jù)加處理這堆數(shù)據(jù)的計(jì)算方法,如下圖所示:
在個(gè)人PC上或者服務(wù)器上,想要讓整個(gè)模型跑起來是非常簡(jiǎn)單的,因?yàn)椋麄€(gè)基建部分都被各大廠商(主要是英偉達(dá))給搭建好了,我們直接使用就好了,這就好比我們要找個(gè)地方住一晚,最方便且安全的選擇就是去找現(xiàn)成的五星級(jí)酒店(缺點(diǎn)顯然是*),而不是去自己建房子然后住進(jìn)去。而且,這些AI部署的相關(guān)服務(wù)是被全球開發(fā)者多年驗(yàn)證過的,好用、方便。但是,一旦你想部署到某個(gè)具體的、特定的、不通用的硬件上時(shí),之前那一套就完全沒用了,得“入鄉(xiāng)隨俗”,用與特定硬件相匹配的軟件棧。具體到我們這里,就是周易SDK這一套軟件棧,想把AI模型跑到板子上我們就得學(xué)習(xí)這一套SDK的使用、開發(fā)方法。
3. 周易SDK介紹
老規(guī)矩,還是先看下整體流程:首先,假設(shè)現(xiàn)在已經(jīng)拿到一個(gè)訓(xùn)練好的模型model了,比如model.onnx,
這個(gè)模型只能是tensoflow/pytorch/caffe/mxnet/onnx格式的
然后我們用SDK中的工具鏈對(duì)模型model.onnx進(jìn)行編譯得到aipu.bin,就像這樣aipubuild build.cfg 最后將這個(gè)aipu.bin封裝到應(yīng)用程序APP中, 放到到板子上運(yùn)行即可;
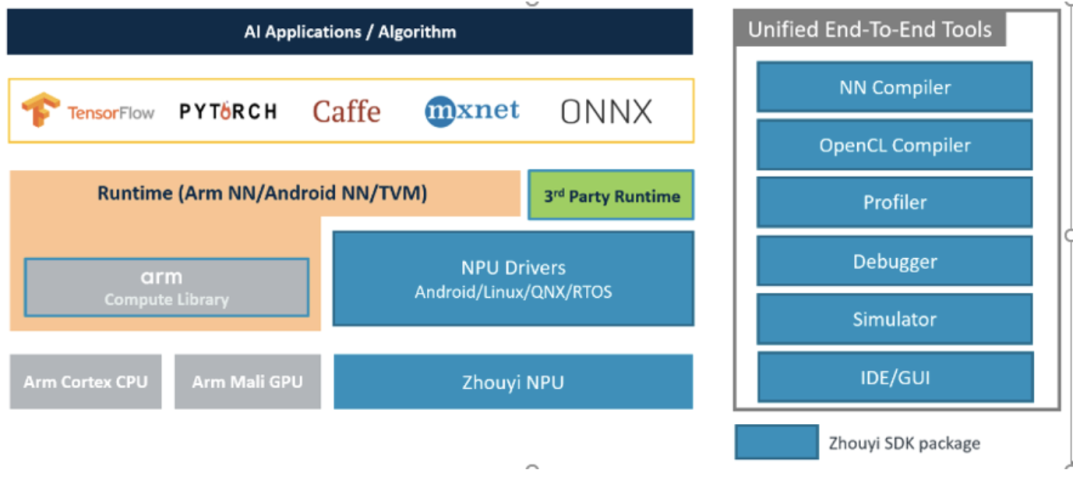
簡(jiǎn)單來說,流程跟你gcc編譯c代碼是一樣的,只是參數(shù)格式不一樣而已,這里的輸入是模型,輸出的是NPU支持的bin可執(zhí)行文件; 此外,調(diào)bug有debugger可用,性能問題可以用profiler,沒有具體硬件可以用simulator模擬硬件來跑,當(dāng)然了IDE圖形化操作界面也是有的。 后續(xù)的課程中我將就每一個(gè)模塊結(jié)合SDK文檔進(jìn)行詳細(xì)講解+逐代碼分析。這章回,我們先跟著教程走一遍流程,認(rèn)識(shí)認(rèn)識(shí)代碼框架。
4. 操作流程+代碼框架初識(shí)
第一步是搭建開發(fā)環(huán)境,跟著這個(gè)教程:https://docs.radxa.com/sirider/s1/app-development/zhouyi\\\_npu一步一步來,就能把整個(gè)環(huán)境搭建流程跑通(windows直接用WSL2即可)。 第二步是編譯模型,在x86 PC段進(jìn)行模型編譯,還是上面鏈接(看編譯部分)
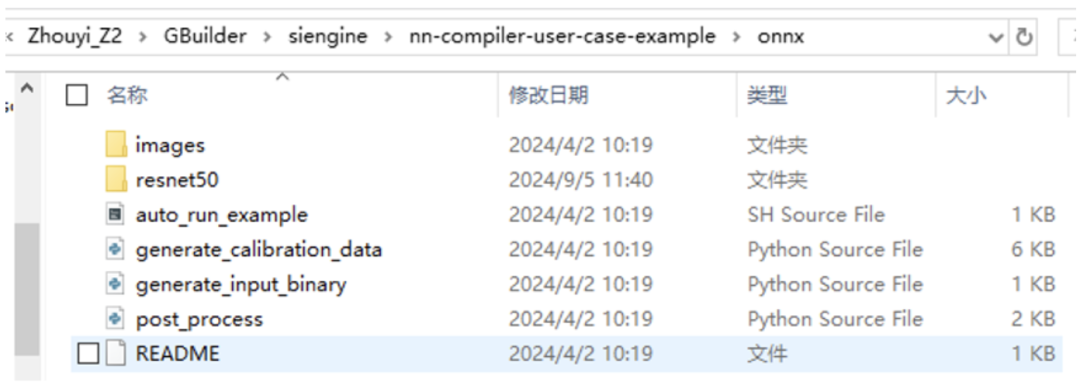
看到有如上文件,第一步是生成量化校準(zhǔn)集,因?yàn)槲覀兊脑寄P褪莊p32的,但NPU是不支持fp32的,因此我們需要將其量化到int8/int16。 一個(gè)fp32的值量化到int8,在量化領(lǐng)域有非常多的算法來實(shí)現(xiàn),我們這里使用的是PTQ(假設(shè)不理解也不要緊,后面我會(huì)專門講解一下量化相關(guān)的內(nèi)容,因?yàn)檫@部分代碼開源了,因此甚至對(duì)著開源的代碼進(jìn)行code級(jí)講解的)進(jìn)行量化。 量化需要準(zhǔn)備一個(gè)數(shù)據(jù)集進(jìn)行數(shù)據(jù)范圍分布的采集過程,假如不理解為什么要這一步也不要緊,知道有這個(gè)流程就行了,后面講量化算法的時(shí)候就明白了。
python3generate_calibration_data.py

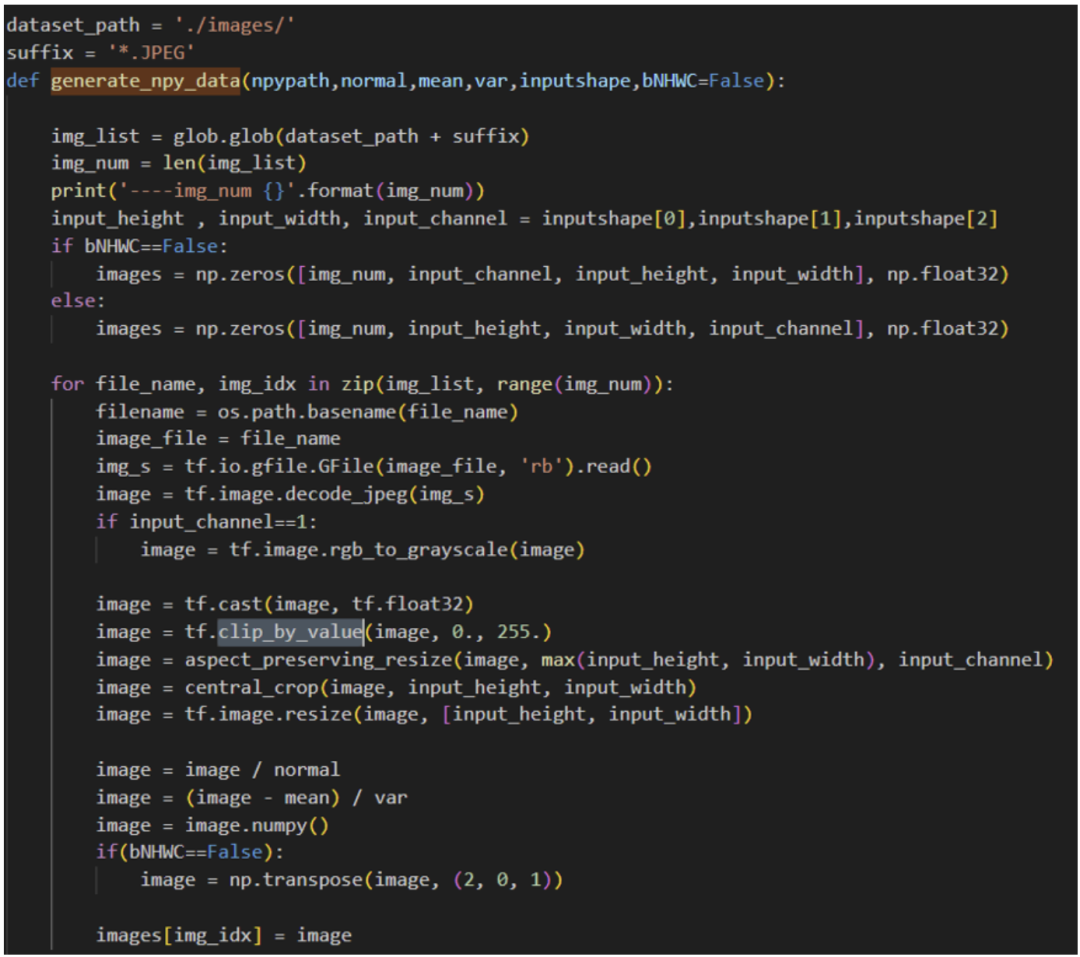
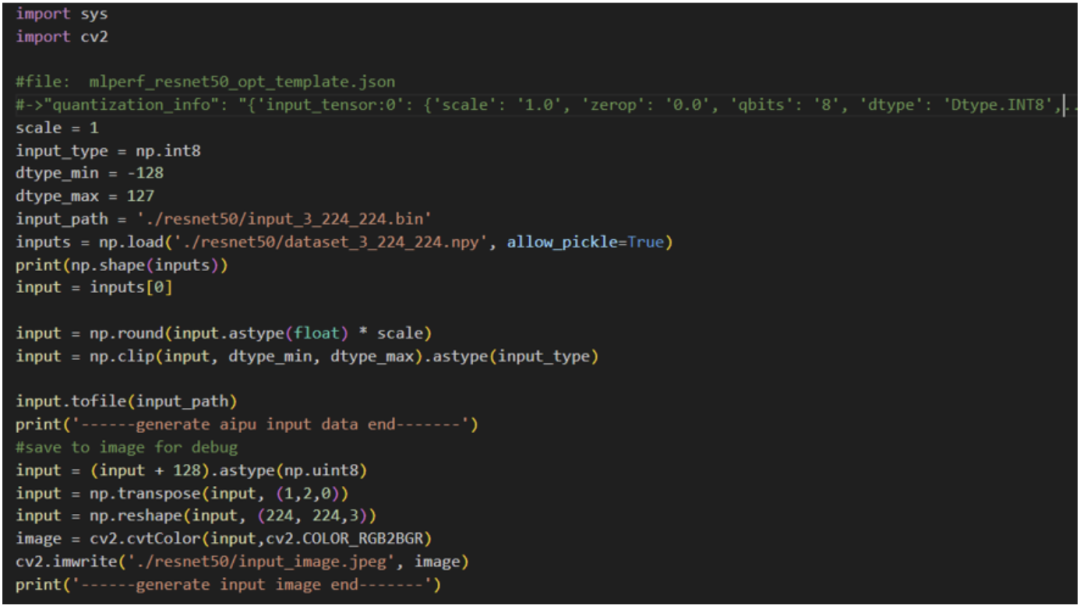
python3 generate\_input\_binary.py
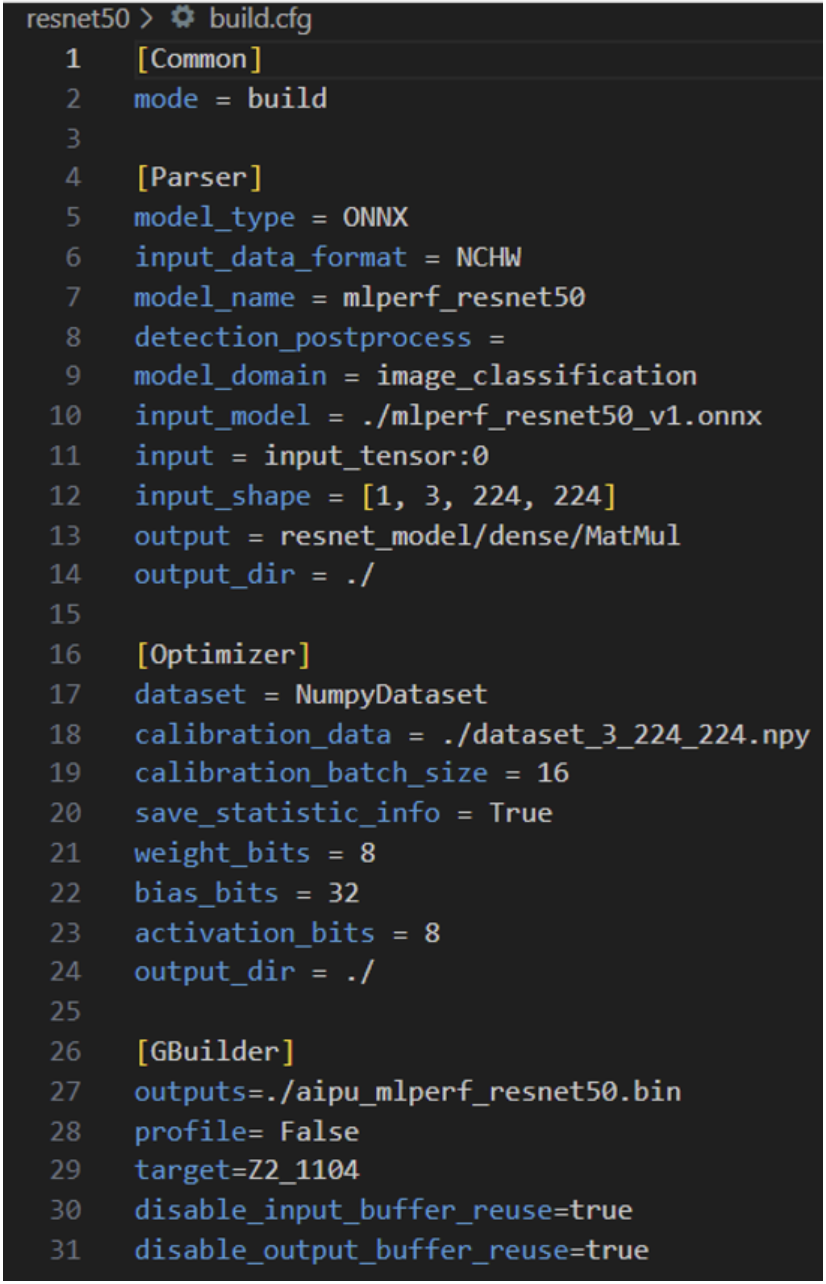
vim ./resnet50/build.cfg
解析模型;
量化
編譯執(zhí)行
Parser的作用是將標(biāo)準(zhǔn)的通用模型(ONNX、TF、pytorch等)轉(zhuǎn)換為內(nèi)部專用的IR;Input\_data\_format 指的是輸入的data\_layout,我們?cè)谇懊娴臉?gòu)造輸入數(shù)據(jù)時(shí)選的就是NHWC,所以這里填NHWC;模型名字model\_name,標(biāo)準(zhǔn)填就好了;Detection\_postprocess填后處理的算子名,像檢測(cè)模型都是有后處理部分的,我們對(duì)應(yīng)填,當(dāng)然也可以選擇不填,直接在CPU端做后處理;其他都是所見即所得,除了注意input的配置即可,這是輸入tensor的名字,用netron打開onnx model即可得到; Optimizer中dataset字段就是指定數(shù)據(jù)集的格式,前面我們構(gòu)造的是numpy格式的,所以這里填NumpyDataset;主要注意下bits部分的設(shè)置,因?yàn)橐话愕耐娣ㄖ挥羞@里有可調(diào),來粗粒度的調(diào)整精度/性能的權(quán)衡,當(dāng)然了,后期大家想玩的話我就帶大家進(jìn)行代碼級(jí)的玩法。 Gbuilder部分就是直接編譯的,profile就是輸出perf性能數(shù)據(jù)的,會(huì)一定程度上影響性能,因此在debug階段使用即可;target指的是硬件的版本號(hào),這里是固定的填Z2\_1104即可,這一塊沒有什么需要額外配置的,當(dāng)然具體的每一個(gè)參數(shù)我們可以到后面的Gbuilder章節(jié)進(jìn)行詳細(xì)解說,這里堪堪帶過。 按照官方教程直接編譯:

可以看到Gbuilder的版本是5.3.2194,開始進(jìn)行解析模型了,這里由于我使用的是WSL2沒有cuda,所以會(huì)比較慢

解析完后輸出如上,此時(shí)就得到了我們NPU所需的中間表達(dá)格式(IR)了

得到IR后,我們會(huì)先做一個(gè)檢查,看解析出來的IR格式以及graph的連接關(guān)系是否合理,再初步做一個(gè)float graph級(jí)的圖優(yōu)化,可以看到這里優(yōu)化掉了一個(gè)Transpose層;
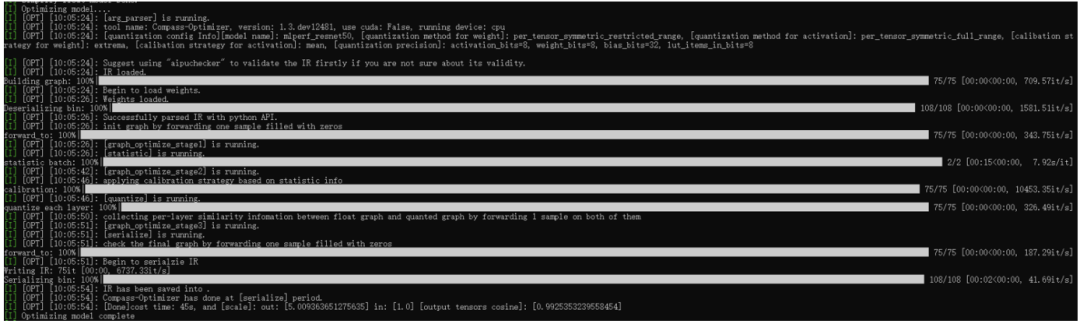
緊接著就進(jìn)入量化階段了,可以看到整個(gè)流程里面有非常多的階段,每個(gè)階段都有在做特定的事,這里涉及的內(nèi)容比較多,我們暫且按下不表,后面我們將會(huì)對(duì)照源碼進(jìn)行一一解說(有機(jī)會(huì)的話,還會(huì)跟業(yè)界做的比較好的ppq框架進(jìn)行相關(guān)的對(duì)比)。 這里主要關(guān)注下最后的輸出scale,用來在后處理階段使用的;以及輸出tensor的cosine值,這個(gè)值是反應(yīng)模型精度的。 總之,經(jīng)過量化后,我們就得到了定點(diǎn)格式的IR,此IR經(jīng)過編譯后,可以直接在NPU硬件上跑起來的。

由于量化過程中也會(huì)有圖結(jié)構(gòu)的改變,因此這里做完量化后也需要執(zhí)行圖檢查以及圖優(yōu)化步驟的。
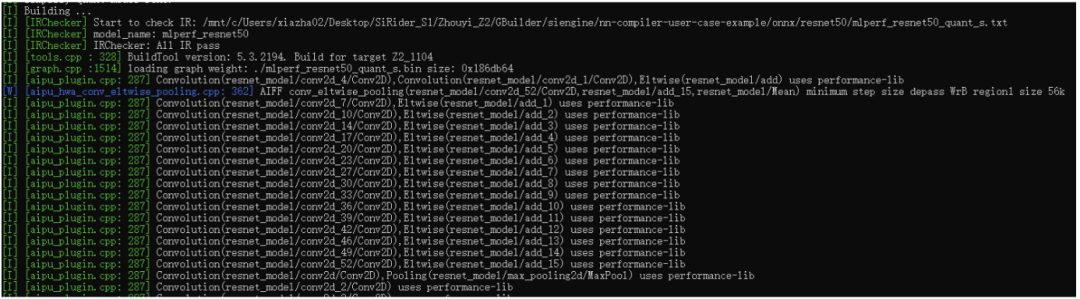
到這里后,終于開始編譯模型了,這個(gè)部分主要內(nèi)容包括給graph中的node進(jìn)行算子匹配,整網(wǎng)內(nèi)存分配及優(yōu)化,多核調(diào)度,硬件底層圖優(yōu)化等。比如上圖中的aipu\_plugin就是算子,每個(gè)標(biāo)準(zhǔn)算子都有好幾種底層硬件實(shí)現(xiàn)(opencl、asm),根據(jù)特定機(jī)制進(jìn)行整網(wǎng)全局匹配。

這里是layout的調(diào)度部分,目標(biāo)就是盡可能減少途中l(wèi)ayoutconvert的個(gè)數(shù),這個(gè)部分也是個(gè)最優(yōu)化的問題,細(xì)講下去也就停不下來了,將來有機(jī)會(huì)我們?cè)敿?xì)說說。
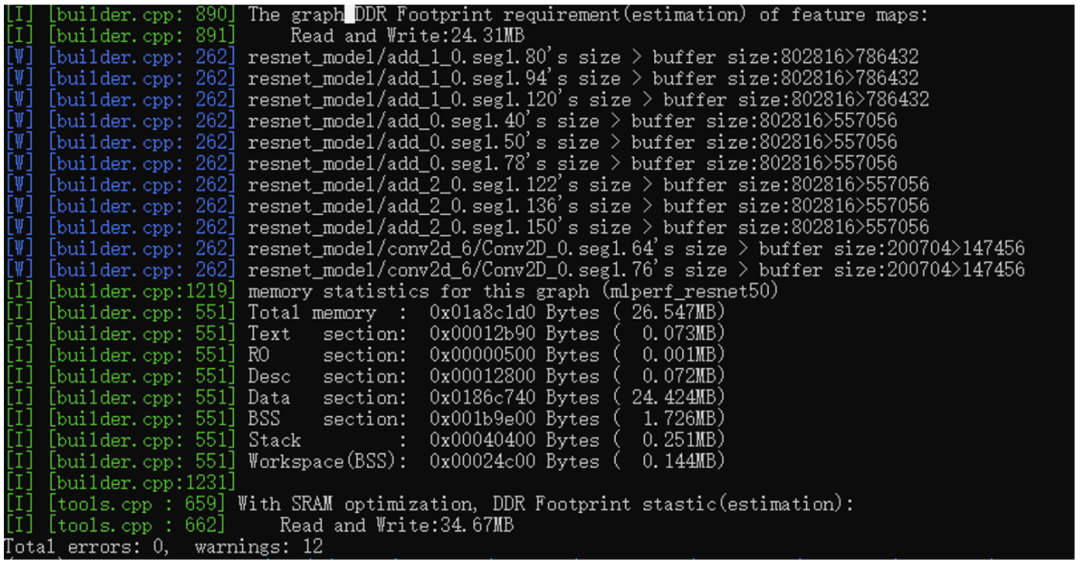
最后就是內(nèi)存部分的內(nèi)容了,整網(wǎng)所需的內(nèi)存是26.547MB,代碼段、RO段、desc段(這個(gè)不常見,這是底層算子的特定格式),DataBss都是標(biāo)準(zhǔn)格式。最后可以看到是有個(gè)SRAM的優(yōu)化的,這個(gè)是NPU內(nèi)部的一個(gè)快速靜態(tài)存儲(chǔ)區(qū)域,用來緩存node間的featuemap的,不僅能降低footprint還能提升性能。 好了,到這里,模型終于編好了,我們看下編出了些啥:
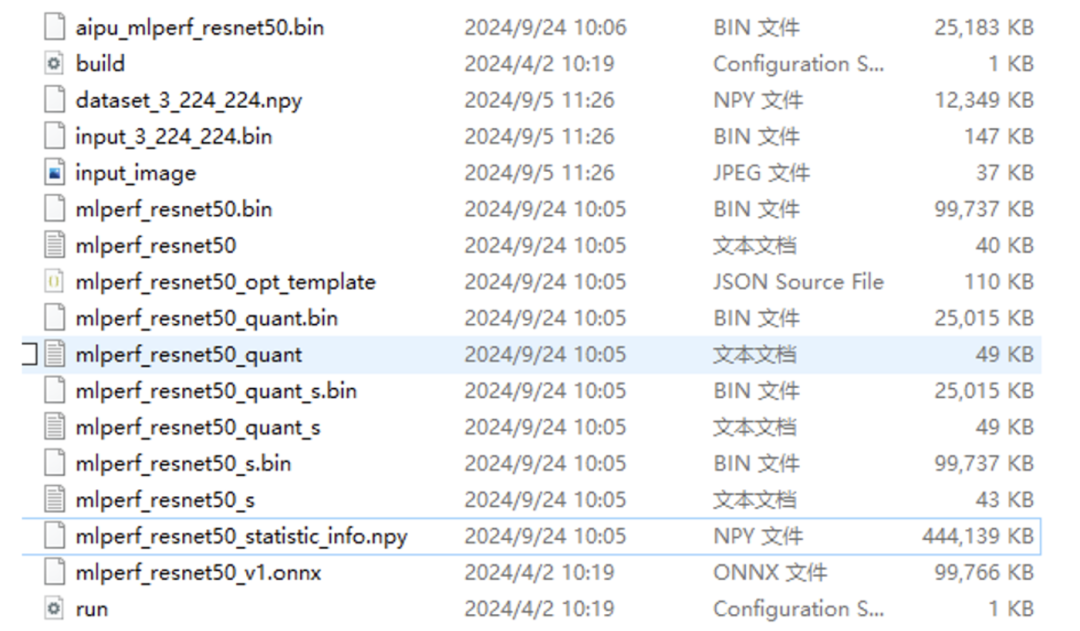
第一個(gè)文件就是我們NPU需要的可執(zhí)行文件,也就是在build.cfg指定的輸出文件;
第二個(gè)文件就是build配置腳本;
第三個(gè)時(shí)量化校準(zhǔn)數(shù)據(jù)集;
第四個(gè)時(shí)輸入數(shù)據(jù),第五個(gè)是輸入數(shù)據(jù)對(duì)應(yīng)的圖片;
第六個(gè)、第七個(gè)就是parser后得到的浮點(diǎn)IR文件(圖結(jié)構(gòu)文件以及權(quán)重文件);
第八個(gè)是量化產(chǎn)生的文件,有啥量化的問題你去這個(gè)文件內(nèi)查查即可;
第九個(gè)、第十個(gè)是量化后產(chǎn)生的定點(diǎn)IR;
第十一個(gè)、第十二個(gè)文件是定點(diǎn)IR經(jīng)過圖優(yōu)化后的精簡(jiǎn)IR;
第十三個(gè)、第十四個(gè)是浮點(diǎn)IR經(jīng)過圖優(yōu)化后產(chǎn)生的IR;
第十五個(gè)文件是驗(yàn)證集的統(tǒng)計(jì)信息,有這個(gè)文件后,下次編譯就不用繼續(xù)跑耗時(shí)的校準(zhǔn)過程了;
第十六個(gè)文件是原始的resnet50.onnx模型;
第十七個(gè)文件是 run的時(shí)候(不是跑在NPU上而是在PC上跑simulator用的)用的cfg配置文件;
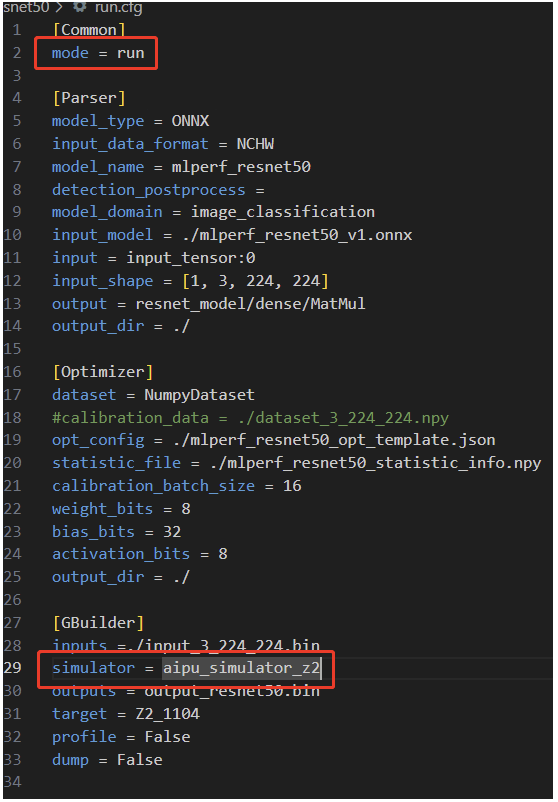
可以看到除了紅框內(nèi)的東西外,其余都是差不多的。 現(xiàn)在我們生成了模型的bin文件,但還不是最終應(yīng)用的可執(zhí)行文件,最終的應(yīng)用是調(diào)用我們剛剛生成的模型,這部分的代碼在這:
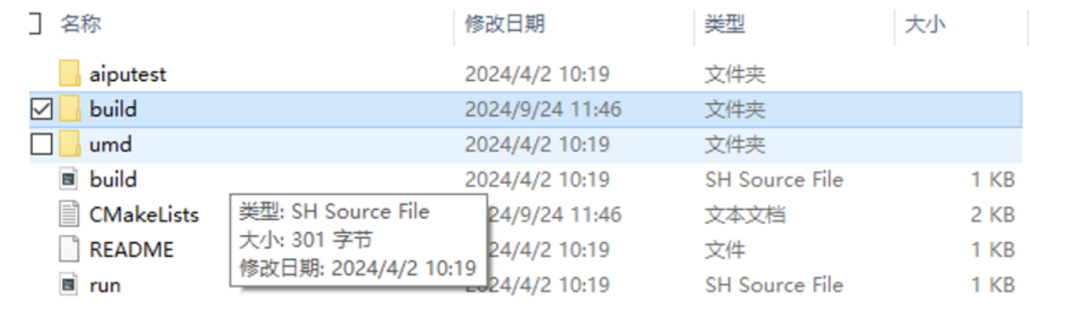
Aiputest就是應(yīng)用程序的邏輯部分,umd里面就是一堆面向用戶的庫(kù)函數(shù),庫(kù)函數(shù)里面是直接調(diào)用驅(qū)動(dòng),以及環(huán)境構(gòu)建的(待會(huì)我們直接進(jìn)去看下代碼結(jié)構(gòu))。 按照軟件工程的結(jié)構(gòu),我們先查看頂層的CMakeLists.txt文件,獲取到的信息如下:
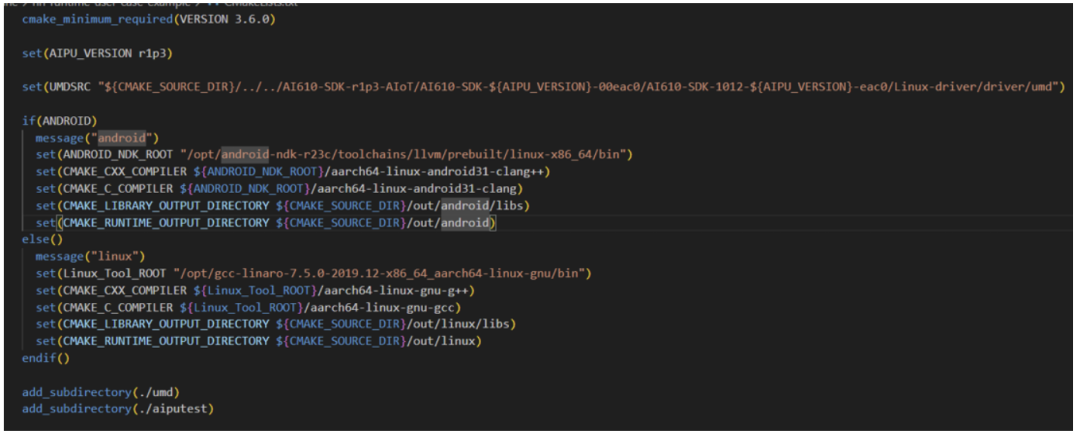
Cmake版本要搞對(duì)噢,UMDSRC變量要仔細(xì)檢查對(duì)路徑哈!設(shè)置好交叉編譯器的路徑,設(shè)置好最終的輸出路徑; 頂層配置好參數(shù),然后直接add\_subdirectory讓子目錄自己去根據(jù)參數(shù)執(zhí)行具體的編譯任務(wù)。 我們先看umd文件夾,里面直接Linux-driver/driver/umd的源碼拉進(jìn)來編成動(dòng)態(tài)庫(kù),給后面的應(yīng)用aiputest來動(dòng)態(tài)鏈接。
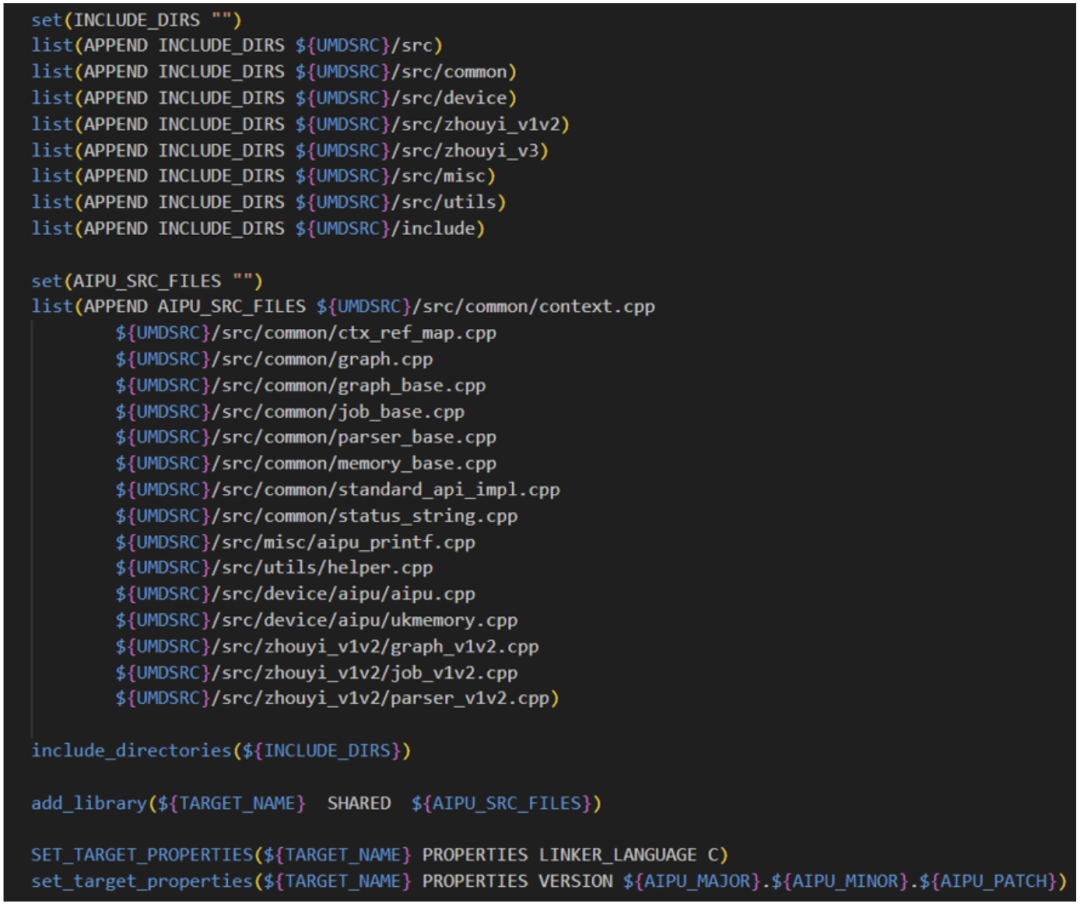
Aiputest是個(gè)非常簡(jiǎn)單的應(yīng)用,因此我們只需要將umd頭文件引進(jìn)來,umd動(dòng)態(tài)庫(kù)鏈接進(jìn)來,直接編譯即可。
我們看下main.cpp文件中的內(nèi)容結(jié)構(gòu):
其中UMD相關(guān)的功能全都封裝到standard\_api.h接口文件中了,接下來的代碼無非就是初始化環(huán)境,開啟NPU任務(wù),接受返回?cái)?shù)據(jù),清理“戰(zhàn)場(chǎng)”(環(huán)境)等標(biāo)準(zhǔn)步驟,沒啥特殊的,具體參數(shù)解析可以查文檔或者等我后續(xù)的文章逐代碼解析。 (ps. 其中可以看到雖然是c++環(huán)境,但是用的都是非常標(biāo)準(zhǔn)的c代碼風(fēng)格,挺好的,非常適合用來直觀理解執(zhí)行流程。)
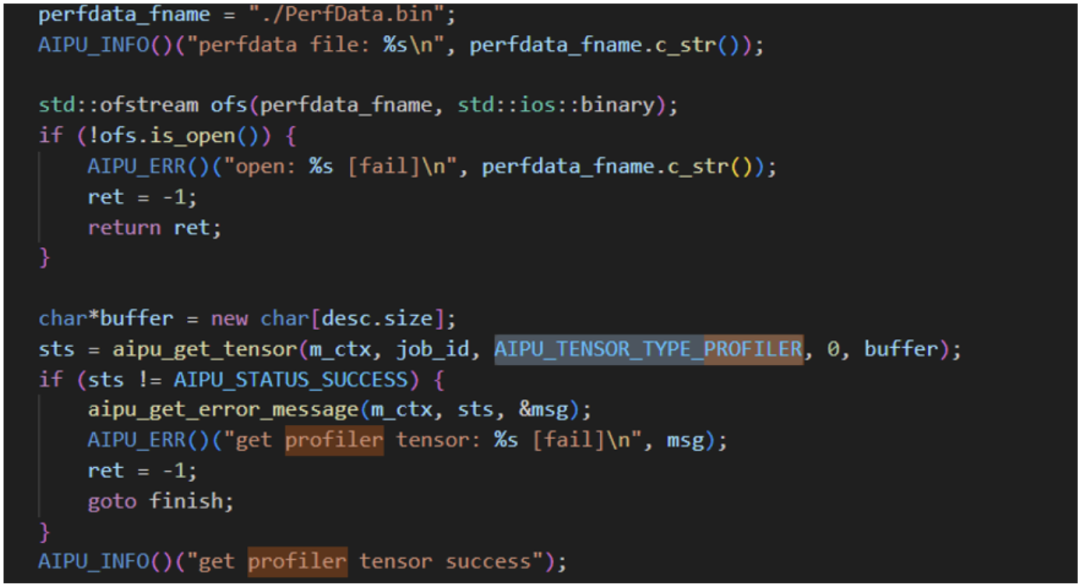
研究代碼發(fā)現(xiàn)這里有dump profiler的邏輯;
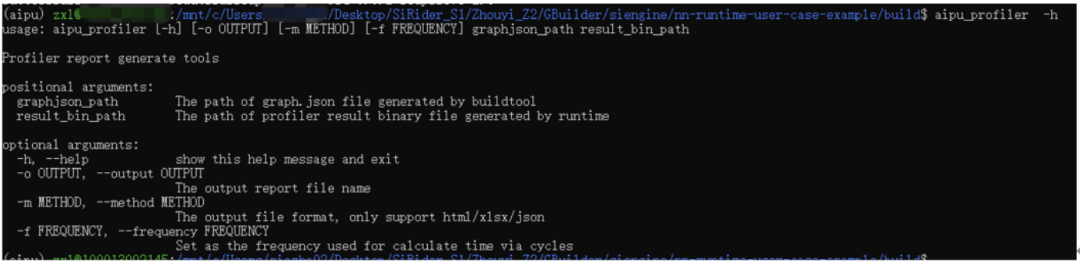
應(yīng)用中也是有profiler的程序的,其中result\_bin\_path就是上面代碼中輸出的PerfData.bin文件,因此我們可以留個(gè)坑,將來講講如何用這個(gè)來分析模型的性能優(yōu)化。 好了,視角拉回,我們直接編譯得到了對(duì)應(yīng)的文件,
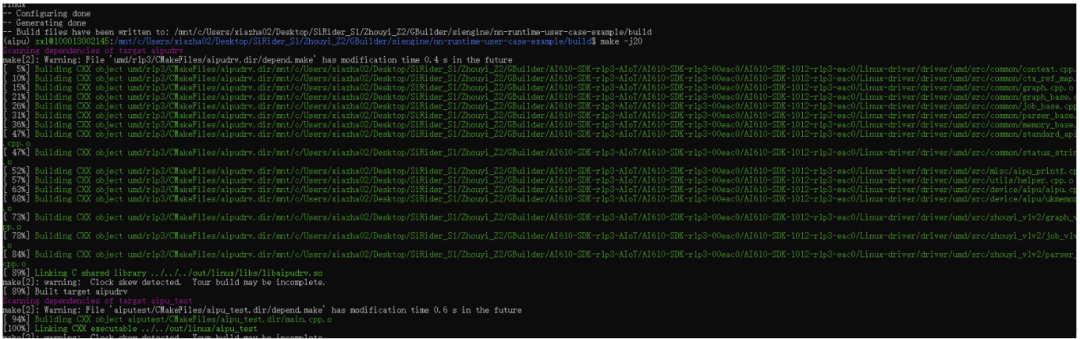
按照官方教程的步驟將文件scp到板子后,直接就可以跑啦~
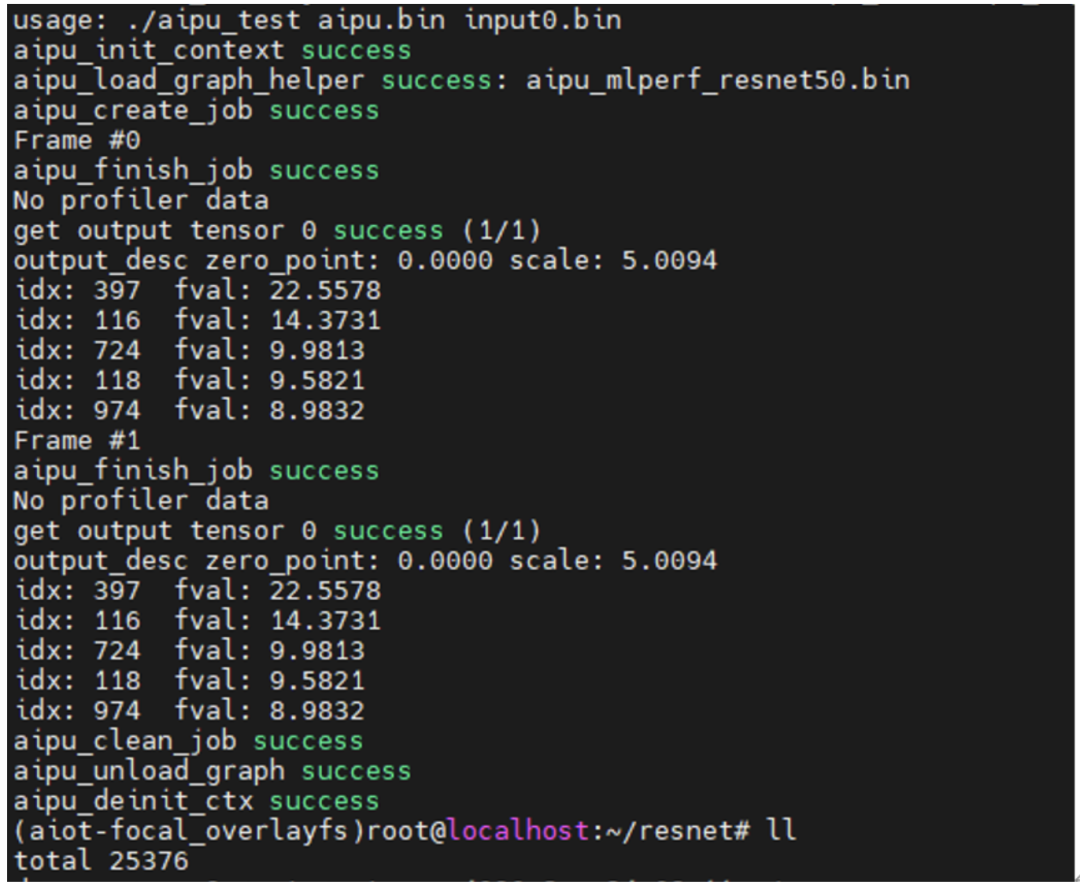
-
芯片
+關(guān)注
關(guān)注
459文章
52253瀏覽量
436979 -
開發(fā)板
+關(guān)注
關(guān)注
25文章
5565瀏覽量
102741 -
SDK
+關(guān)注
關(guān)注
3文章
1067瀏覽量
47792
原文標(biāo)題:開發(fā)板測(cè)評(píng)|芯擎SiRider S1初探流程·流暢
文章出處:【微信號(hào):Ithingedu,微信公眾號(hào):安芯教育科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
有ARM,NPU,F(xiàn)PGA三種核心的開發(fā)板 — 米爾安路飛龍派開發(fā)板

【新品】遠(yuǎn)距離圖傳數(shù)傳模塊開發(fā)板、藍(lán)牙模塊開發(fā)板、無線模塊開發(fā)板

【免費(fèi)試用】開發(fā)板評(píng)測(cè)大賽開啟!OH 、RISC-V、Rockchip頂級(jí)開發(fā)板等你試用~

貝啟BQ3568HM 開發(fā)板被選用為 OpenHarmony 明星開發(fā)板

來自資深工程師對(duì)ELF 2開發(fā)板的產(chǎn)品測(cè)評(píng)

視美泰EVS事件融合相機(jī)新品“靈光一號(hào)”正式發(fā)布,開啟視覺新紀(jì)元

FacenetPytorch人臉識(shí)別方案--基于米爾全志T527開發(fā)板








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論