") λ-IO:存儲(chǔ)計(jì)算下的IO棧設(shè)計(jì)
λ-IO:存儲(chǔ)計(jì)算下的IO棧設(shè)計(jì)
動(dòng)機(jī)和背景
存儲(chǔ)計(jì)算&IO棧
存儲(chǔ)計(jì)算可以降低數(shù)據(jù)移動(dòng)開銷并充分利用設(shè)備內(nèi)帶寬,相比于特定計(jì)算加速,通用存儲(chǔ)計(jì)算框架可以允許用戶自定義卸載到存儲(chǔ)設(shè)備的計(jì)算邏輯。然而大部分工作都關(guān)注于控制存儲(chǔ)設(shè)備的接口和用戶空間,但是缺乏對(duì)主機(jī)側(cè)計(jì)算&存儲(chǔ)資源的充分利用。IO棧是管理存儲(chǔ)器的的基本組件,包括設(shè)備驅(qū)動(dòng)、塊接口層、文件系統(tǒng),目前一些用戶空間IO庫(kù)(如SPDK)有效降低了延遲,但是io棧仍然不可或缺。這是因?yàn)?)大部分引用采用POSIX接口需要IO棧的兼容性;2)IO棧提供了包括page cache、文件系統(tǒng)等多種功能模塊。而用戶空間IO庫(kù)只提供原始數(shù)據(jù)傳輸功能;3)IO棧可以使得不同用戶、應(yīng)用充分共享存儲(chǔ)設(shè)備。
主機(jī)-設(shè)備協(xié)作
作者通過測(cè)試,發(fā)現(xiàn)不同特征的應(yīng)用,對(duì)主機(jī)/設(shè)備具有不同的適應(yīng)性。例如,在主機(jī)/設(shè)備側(cè)分別運(yùn)行Stat64和stat32。stat64在主機(jī)側(cè)運(yùn)行更快,stat32在設(shè)備側(cè)運(yùn)行更快。另外,一個(gè)應(yīng)用的不同運(yùn)行階段,也具有不同的特征。例如使用warm page-cache策略運(yùn)行stat64,發(fā)現(xiàn)無緩存時(shí)在設(shè)備上更快,緩存越多主機(jī)端越快。
eBPF
eBPF是一種內(nèi)核中的虛擬機(jī),允許用戶在不修改內(nèi)核源碼的情況下運(yùn)行一段代碼,其運(yùn)行過程如下圖所示。因?yàn)閑BPF可以提供硬件無關(guān)的字節(jié)碼格式,其可用于構(gòu)建ISC運(yùn)行時(shí)。然而,eBPF也存在一些問題:1)eBPF的靜態(tài)校驗(yàn)器過于嚴(yán)格;2)缺乏指針訪問和動(dòng)態(tài)長(zhǎng)度循環(huán)機(jī)制。因此,需要對(duì)eBPF進(jìn)行擴(kuò)展以更好的支持存儲(chǔ)計(jì)算。

設(shè)計(jì)方案
λ-IO通過擴(kuò)展vanilla-IO框架,支持將計(jì)算動(dòng)態(tài)卸載到內(nèi)核/設(shè)備中進(jìn)行計(jì)算。
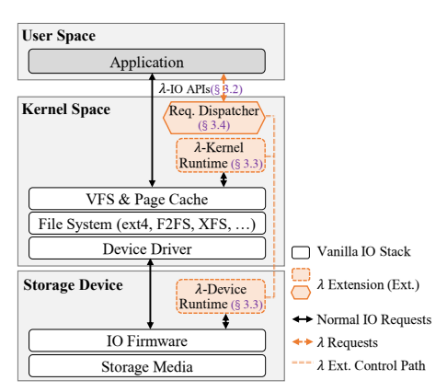
它由三部分組成,如下圖所示:
λ-IO API:用于提供擴(kuò)展的應(yīng)用編程接口
λ運(yùn)行時(shí):包括λ內(nèi)核運(yùn)行時(shí)和λ設(shè)備運(yùn)行時(shí),用于提供λ請(qǐng)求的計(jì)算接口
請(qǐng)求分發(fā)器:用于評(píng)估效率,將任務(wù)自動(dòng)分發(fā)給設(shè)備/內(nèi)核執(zhí)行。
λ-API
λ-API繼承了vanilla IO的open/close/read/write接口,并擴(kuò)展了λ_load/ λ _read/λ_write接口用于應(yīng)用提交計(jì)算卸載請(qǐng)求。其中,λ函數(shù)是計(jì)算方法的實(shí)體,load_ λ用于將λ函數(shù)編譯為eBPF代碼;而open_λ/close_ λ:與vanilla中的定義保持一致,可以使用vanilla/ λ擴(kuò)展函數(shù)。

pread_λ和pwrite_λ用于執(zhí)行計(jì)算卸載,其中pread_λ表示以fd,offset,length表示的文件內(nèi)容作為入?yún)?zhí)行λ_id表示的λ函數(shù),并將返回結(jié)果寫到buf中。其執(zhí)行步驟為:1)將文件數(shù)據(jù)作為輸入數(shù)據(jù)加載到內(nèi)存buffer中;2)為輸出數(shù)據(jù)分配buffer空間;3)執(zhí)行λ函數(shù);4)將輸出buffer的數(shù)據(jù)拷貝到用戶分配的buffer中。pwrite_λ與pread_λ類似,但是其輸入、輸出參數(shù)相反。
λ運(yùn)行時(shí)
λ運(yùn)行時(shí)是執(zhí)行l(wèi)oad_ λ, pread_ λ, pwrite _λ的核心,它的實(shí)現(xiàn)具有兩方面的關(guān)鍵挑戰(zhàn):1)計(jì)算:內(nèi)核/設(shè)備的λ運(yùn)行時(shí)都需要保存、執(zhí)行計(jì)算函數(shù);2)數(shù)據(jù):λ運(yùn)行時(shí)需要保存、訪問文件數(shù)據(jù)和用戶應(yīng)用信息。
作者通過允許sBPF對(duì)BPF代碼執(zhí)行動(dòng)態(tài)驗(yàn)證,使能指針、循環(huán)將eBPF擴(kuò)展為sBPF。其中,指針訪問的修改包括在JIT中增加指針地址檢測(cè)代碼,讓sBPF可以在運(yùn)行中檢查指針,若指針未落在輸入buffer中,則停止執(zhí)行并返回錯(cuò)誤碼。另外,作者表示,所有循環(huán)都包括一個(gè)offset為負(fù)的跳轉(zhuǎn)指令,因此sBPF使用了一個(gè)動(dòng)態(tài)的后跳計(jì)數(shù)器,并限制后跳的執(zhí)行次數(shù),以避免死循環(huán)的發(fā)生。作者之后對(duì)其安全性進(jìn)行了分析,并表示雖然增加了功能,但由于檢驗(yàn)嚴(yán)格,并不會(huì)增加eBPF的安全性風(fēng)險(xiǎn)。
關(guān)于數(shù)據(jù)問題,主要是設(shè)備/內(nèi)核的一致性訪問問題。對(duì)于λ內(nèi)核運(yùn)行時(shí),作者使用內(nèi)核中通用的kernel_write和kernel_read訪問文件,讓內(nèi)核管理頁(yè)緩存和文件一致性,另外為了減少讀寫文件引起的大規(guī)模內(nèi)存搬移,作者提出kernel_mmap進(jìn)行內(nèi)存映射解決這個(gè)問題。
對(duì)于設(shè)備運(yùn)行時(shí)的文件一致性訪問,作者提出,雖然由于設(shè)備對(duì)文件語義不可知,需要準(zhǔn)確的物理地址,但是文件的IOCTL中由FIEMAP和FIBMAP用于提取元數(shù)據(jù)中的物理地址,可以解決設(shè)備的文件訪問問題。而一致性問題包括內(nèi)核-用戶空間一致性和主機(jī)-設(shè)備一致性兩方面,對(duì)于內(nèi)核-用戶空間一致性問題,由于采用的是標(biāo)準(zhǔn)syscall接口,內(nèi)核可以管理一致性,而主機(jī)設(shè)備一致性問題則通過1)使用讀寫鎖避免同時(shí)訪問帶來的一致性風(fēng)險(xiǎn);2)在分發(fā)λ請(qǐng)求前,將請(qǐng)求數(shù)據(jù)文件相關(guān)的臟頁(yè)刷入設(shè)備并清空緩存,可以解決其一致性問題。
請(qǐng)求分發(fā)器
請(qǐng)求分發(fā)器的目的是通過預(yù)測(cè)主機(jī)、設(shè)備對(duì)某個(gè)任務(wù)的執(zhí)行時(shí)間,選擇其中更快的那個(gè)進(jìn)行分發(fā),以達(dá)到更快、更高效的目的。為了評(píng)估執(zhí)行時(shí)間,需要對(duì)執(zhí)行時(shí)間進(jìn)行建模。
為此,首先對(duì)相關(guān)變量進(jìn)行符號(hào)表示如下表。
| D | 存儲(chǔ)器中內(nèi)容大小 |
| Bs | 存儲(chǔ)介質(zhì)-控制器傳輸帶寬 |
| Bd | 主機(jī)-設(shè)備傳輸帶寬 |
| Bh | 主機(jī)計(jì)算的等效帶寬 |
| α | 輸入/輸出長(zhǎng)度比值 |
| β | 設(shè)備/主機(jī)計(jì)算吞吐量比值 |
之后,對(duì)主機(jī)、設(shè)備端分別建模其執(zhí)行時(shí)間,當(dāng)不考慮緩存時(shí),使用pread_λ在內(nèi)核、設(shè)備端的執(zhí)行時(shí)間如下公式所示
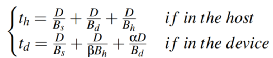
。當(dāng)考慮緩存時(shí),則其形式變?yōu)槿缦?/p>

。而pwrite_λ的執(zhí)行時(shí)間則為
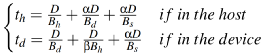
。
評(píng)估
評(píng)估環(huán)境
本文中在一個(gè)配備4核8線程的I7-7700@3.6GHz,16GB DDR4內(nèi)存的電腦上運(yùn)行內(nèi)核為linux 5.10.21的Ubuntu20.04LTS操作系統(tǒng)進(jìn)行測(cè)試。存儲(chǔ)計(jì)算設(shè)備則采用Xilinx Zynq Ultrascale+ ZU17EG搭配2GB內(nèi)存核64GBNand Flash。測(cè)試負(fù)載包括Stat64, Stat32, KNN, Grep, Bitmap。評(píng)估對(duì)比對(duì)象包括了1)Buffer IO(B):默認(rèn)的vanilla IO;2)DirectIO(I):類似Buffer IO,但開啟O_DIRECT;3)Mmap(M):將數(shù)據(jù)文件讀入用戶空間,避免內(nèi)核數(shù)據(jù)拷貝;4)λ-IO kernel(K):使用內(nèi)核計(jì)算的λ-IO;5)λ-IO device(D):使用設(shè)備計(jì)算的λ-IO;6)λ-IO(λ):啟用請(qǐng)求分發(fā)的λ-IO。
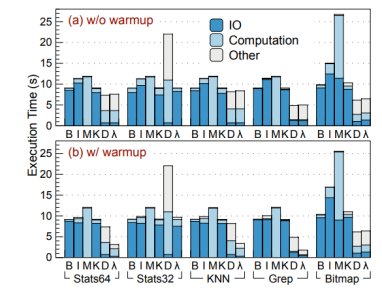
單應(yīng)用性能測(cè)試
對(duì)單個(gè)應(yīng)用的性能分析,作者將執(zhí)行時(shí)間細(xì)分為三部分:IO/計(jì)算/其他。首先對(duì)比λ-IO Device(d)和Buffer IO(B)。可以發(fā)現(xiàn),d相比B,Stats64, KNN, Grep, Bitmap分別提升23.24%, 10.82%, 87.13%, 60.15%。這是由于主機(jī)端IO時(shí)間占比超過92.04%。另外,由于設(shè)備僅有4核4線程,而主機(jī)發(fā)送請(qǐng)求為8線程,因此出現(xiàn)了請(qǐng)求排隊(duì)現(xiàn)象。在stat32中d執(zhí)行時(shí)間超過B 6.65倍 ,是由于64位eBPF對(duì)32位程序執(zhí)行效率不高導(dǎo)致的。
之后作者對(duì)比了λ-Io Kernel(k)核vanilla-IO(B)之間的性能差異,并發(fā)現(xiàn)二者性能基本相同。λ-IO由于sBPF增加了運(yùn)行時(shí)動(dòng)態(tài)檢驗(yàn),帶來了部分額外開銷,但是又因?yàn)閗ernel_mmap避免了內(nèi)存復(fù)制的開銷,二者基本相互抵消。
最后作者對(duì)比了λ-IO不同模式之間的性能差異,并發(fā)現(xiàn),引入請(qǐng)求分配器的λ-IO在每項(xiàng)測(cè)試中的性能都基本相當(dāng)于k、d模式下更快的那一個(gè),并且通過對(duì)比,可以發(fā)現(xiàn)請(qǐng)求分配器帶來的額外開銷約為4.98%。
多應(yīng)用評(píng)估
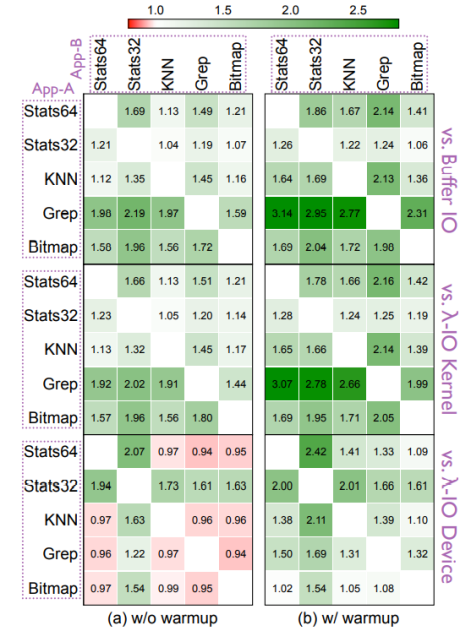
作者通過同時(shí)運(yùn)行5種負(fù)載之二評(píng)估同時(shí)運(yùn)行不同負(fù)載的性能差別。發(fā)現(xiàn),當(dāng)運(yùn)行項(xiàng)包括stat32時(shí),Stat32被分發(fā)到主機(jī),另一個(gè)分發(fā)到設(shè)備運(yùn)行,因此λ-IO性能提升2.19倍,其他情況下λ-IO也有1.98倍的整體性能提升。
敏感性分析
作者接著進(jìn)行了敏感性分析。首先是數(shù)據(jù)集大小敏感性,作者使用stat64測(cè)試為例,發(fā)現(xiàn)在緩存>數(shù)據(jù)集大小時(shí),由于避免了IO瓶頸,內(nèi)核性能最佳,當(dāng)緩存≈?jǐn)?shù)據(jù)大小時(shí),頁(yè)緩存的影響變小,λ-IO性能更好,當(dāng)數(shù)據(jù)>緩存大小時(shí),λ-IO由于高效分發(fā)請(qǐng)求,比其他對(duì)照組快1.28-1.60倍不等。
接著是熱啟動(dòng)敏感性,作者發(fā)現(xiàn)Buffer-IO在熱啟動(dòng)下性能比冷啟動(dòng)更好一些,但是λ-IO性能仍是Buffer-IO的4.05倍。
之后作者分析了請(qǐng)求分發(fā)器的預(yù)測(cè)周期和預(yù)測(cè)長(zhǎng)度的敏感性,發(fā)現(xiàn),當(dāng)預(yù)測(cè)周期超過200后,性能基本不發(fā)生改變,因此將默認(rèn)預(yù)測(cè)周期設(shè)為200,而對(duì)于預(yù)測(cè)長(zhǎng)度,可以看到隨著預(yù)測(cè)長(zhǎng)度增加,執(zhí)行時(shí)間迅速增長(zhǎng),因此默認(rèn)預(yù)測(cè)長(zhǎng)度被設(shè)為5。
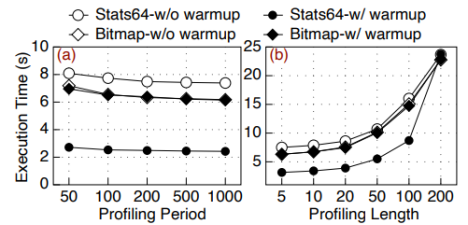

對(duì)于緩存大小和線程數(shù)量,可以看到大部分應(yīng)用對(duì)緩存大小不敏感,且大部分應(yīng)用隨著線程數(shù)增長(zhǎng)而增長(zhǎng),并在4線程時(shí)基本觸頂。
BPF開銷
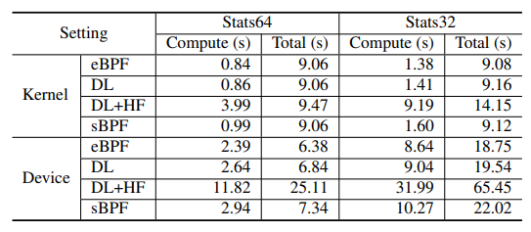
通過對(duì)比運(yùn)行時(shí)間,作者表示sBPF相比eBPF,循環(huán)檢查對(duì)內(nèi)核/設(shè)備增加不超過2.44%和10.09%的開銷,加上指針檢查,sBPF對(duì)內(nèi)核/設(shè)備引入不超過16.96%和22.68%的額外開銷。
Spark SQL
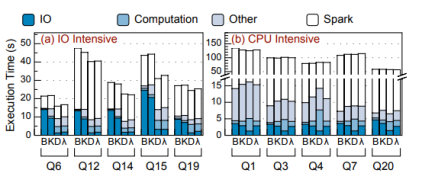
作者最后將spark SQL移植適配λ-IO,并測(cè)試了其在TPC-H負(fù)載下的真實(shí)性能表現(xiàn)。對(duì)比發(fā)現(xiàn)在buffer-IO模式下,IO占用了27.02%-60.41%的總時(shí)間,λ-IO Kernel與buffer-IO類似,λ-IO將任務(wù)分發(fā)至設(shè)備,提升最高81.55%的性能,暖啟動(dòng)后λ-IO比B/K/D分別提升2.15、2.16、1.51倍,在CPU密集型任務(wù)中Q20任務(wù)在D中執(zhí)行時(shí)間比K少18.45%。

總結(jié)
在本文中提出了λ-IO,其擴(kuò)展了Linux IO,使計(jì)算能夠卸載到主機(jī)內(nèi)核和設(shè)備。作者在真實(shí)的軟硬件環(huán)境中實(shí)現(xiàn)并評(píng)估了λ-IO,其顯示出顯著的性能提升。
-
Linux
+關(guān)注
關(guān)注
87文章
11345瀏覽量
210401 -
BPF
+關(guān)注
關(guān)注
0文章
25瀏覽量
4055 -
IO棧
+關(guān)注
關(guān)注
0文章
2瀏覽量
559
原文標(biāo)題:λ-IO:存儲(chǔ)計(jì)算下的IO棧設(shè)計(jì)
文章出處:【微信號(hào):SSDFans,微信公眾號(hào):SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
IO如何實(shí)現(xiàn)
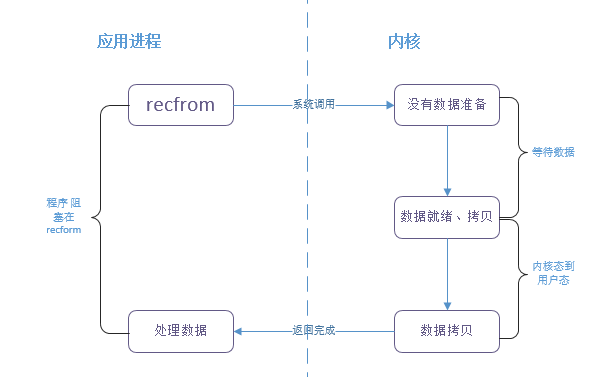
簡(jiǎn)單說一下阻塞IO、非阻塞IO、IO復(fù)用的區(qū)別?
緩存和RAID如何提高IO
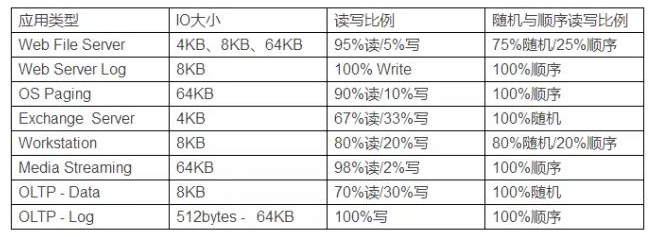
不同應(yīng)用程序的存儲(chǔ)IO類型解析
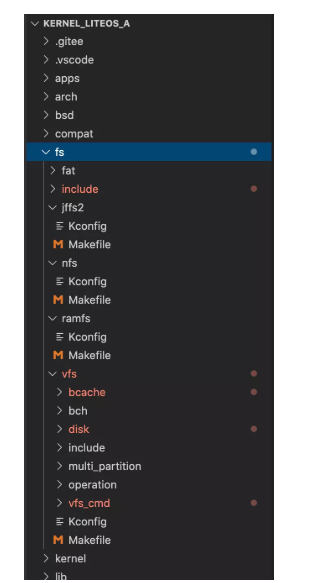
鴻蒙系統(tǒng) IO棧和Linux IO棧對(duì)比分析
如何使用io.Reader和io.Writer接口在程序中實(shí)現(xiàn)流式IO
簡(jiǎn)要敘述分布式IO和遠(yuǎn)程IO的區(qū)別
現(xiàn)代異步存儲(chǔ)訪問API探索:libaio、io_uring和SPDK

信號(hào)驅(qū)動(dòng)IO與異步IO的區(qū)別
亞信電子推出全新IO-Link設(shè)備軟件協(xié)議棧解決方案
亞信電子推出全新IO-Link設(shè)備軟件協(xié)議棧解決方案

遠(yuǎn)程IO與分布式IO的區(qū)別
初識(shí)IO-Link及IO-Link設(shè)備軟件協(xié)議棧
亞信電子于IAS 2024展出最新IO-Link主站&設(shè)備軟件協(xié)議棧解決方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論