") Hadoop 生態(tài)系統(tǒng)在大數(shù)據(jù)處理中的應(yīng)用與實(shí)踐
Hadoop 生態(tài)系統(tǒng)在大數(shù)據(jù)處理中的應(yīng)用與實(shí)踐
Hadoop Distributed File System(HDFS)是其分布式文件存儲(chǔ)基礎(chǔ)。它將大文件分割成多個(gè)數(shù)據(jù)塊,存儲(chǔ)在不同節(jié)點(diǎn)上,實(shí)現(xiàn)高容錯(cuò)性和高擴(kuò)展性。NameNode 負(fù)責(zé)管理文件系統(tǒng)命名空間和元數(shù)據(jù),DataNode 負(fù)責(zé)實(shí)際數(shù)據(jù)存儲(chǔ)。上傳文件時(shí),HDFS 自動(dòng)將文件切塊并分配到不同 DataNode,確保數(shù)據(jù)可靠性。
MapReduce 是分布式計(jì)算模型,用于大規(guī)模數(shù)據(jù)集并行處理。以經(jīng)典的 WordCount 案例來(lái)說(shuō),Map 階段將輸入文本分割成單詞,并映射為鍵值對(duì),如(“apple”,1);Reduce 階段將相同單詞的鍵值對(duì)匯總,統(tǒng)計(jì)出每個(gè)單詞的出現(xiàn)次數(shù)。這種分而治之的思想,能高效處理海量數(shù)據(jù)。
Hive 提供了類 SQL 的查詢語(yǔ)言 HiveQL,使數(shù)據(jù)分析人員能方便地對(duì)存儲(chǔ)在 HDFS 上的數(shù)據(jù)進(jìn)行查詢和分析。Hive 將 HiveQL 語(yǔ)句轉(zhuǎn)化為 MapReduce 任務(wù)執(zhí)行,降低了大數(shù)據(jù)處理的門檻。例如統(tǒng)計(jì)電商訂單數(shù)據(jù)中的總訂單數(shù)、各品類銷售數(shù)量等,使用 HiveQL 能快速完成。
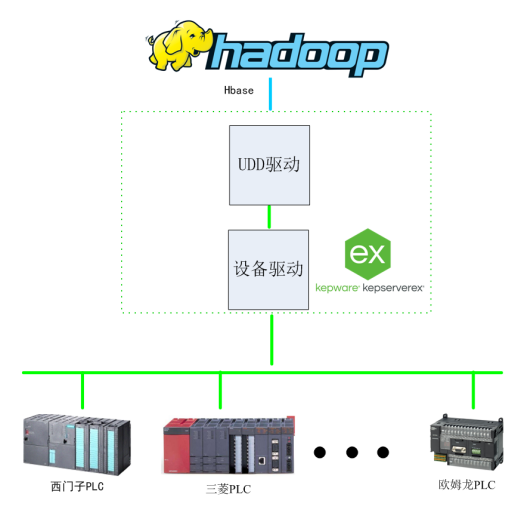
HBase 是基于 HDFS 的分布式 NoSQL 數(shù)據(jù)庫(kù),適用于海量結(jié)構(gòu)化數(shù)據(jù)的實(shí)時(shí)讀寫。比如在物聯(lián)網(wǎng)場(chǎng)景中,設(shè)備產(chǎn)生的海量實(shí)時(shí)數(shù)據(jù),可通過(guò) HBase 快速存儲(chǔ)和查詢。深入掌握 Hadoop 生態(tài)系統(tǒng),能有效應(yīng)對(duì)大數(shù)據(jù)處理挑戰(zhàn),挖掘數(shù)據(jù)價(jià)值。
審核編輯 黃宇
-
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8953瀏覽量
139704
發(fā)布評(píng)論請(qǐng)先 登錄
地物光譜儀在多維生態(tài)系統(tǒng)監(jiān)測(cè)中的應(yīng)用
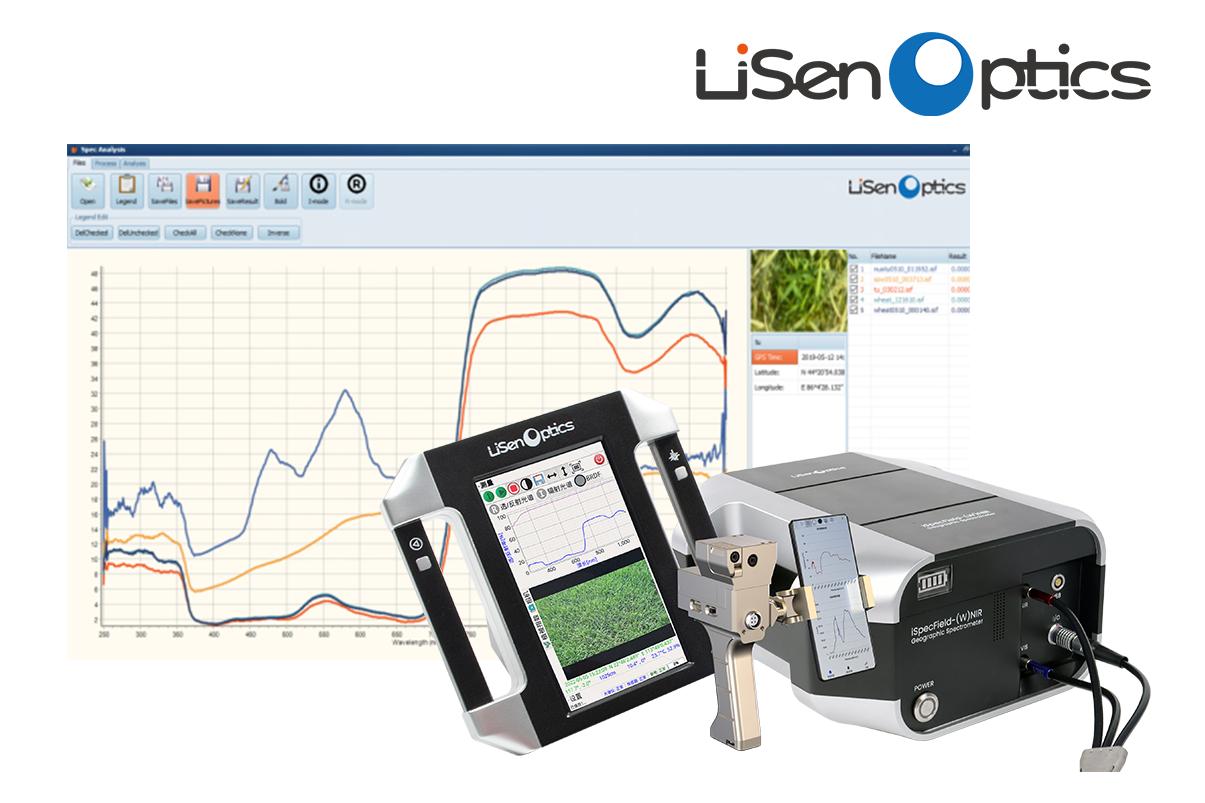
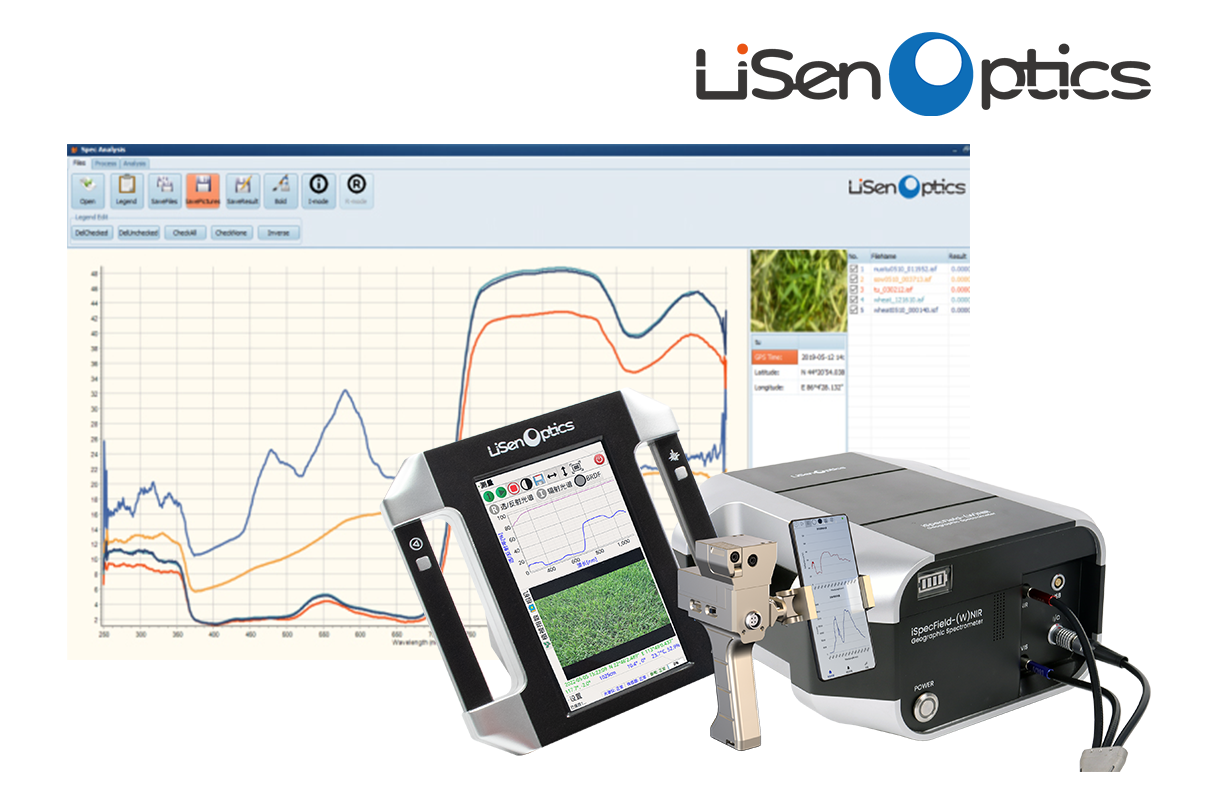
水色遙感精細(xì)化:地物光譜儀在水生態(tài)系統(tǒng)監(jiān)測(cè)中的典型應(yīng)用
如何在光子學(xué)中利用電子生態(tài)系統(tǒng)
安森美PRISM生態(tài)系統(tǒng)助力相機(jī)開(kāi)發(fā)
英監(jiān)管機(jī)構(gòu)或優(yōu)先調(diào)查蘋果谷歌移動(dòng)生態(tài)系統(tǒng)
英國(guó)CMA將對(duì)蘋果谷歌移動(dòng)生態(tài)系統(tǒng)展開(kāi)調(diào)查
笙泉完善的MCU生態(tài)系統(tǒng)(ECO System),賦能高效開(kāi)發(fā)、提升競(jìng)爭(zhēng)優(yōu)勢(shì)
緩存對(duì)大數(shù)據(jù)處理的影響分析
cmp在數(shù)據(jù)處理中的應(yīng)用 如何優(yōu)化cmp性能
對(duì)三星而言開(kāi)放生態(tài)系統(tǒng)是什么
FPGA在數(shù)據(jù)處理中的應(yīng)用實(shí)例
英特爾和AMD組建x86生態(tài)系統(tǒng)咨詢小組
基于Kepware的Hadoop大數(shù)據(jù)應(yīng)用構(gòu)建-提升數(shù)據(jù)價(jià)值利用效能
邊緣計(jì)算物聯(lián)網(wǎng)關(guān)如何優(yōu)化數(shù)據(jù)處理流程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論