") “輕松上手!5分鐘學(xué)會用京東云打造你自己的專屬DeepSeek”
“輕松上手!5分鐘學(xué)會用京東云打造你自己的專屬DeepSeek”

#從第?步驟到第四步驟是完成DeepSeek本地部署和使?,可以滿?中?企業(yè)環(huán)境的穩(wěn)定 使?,第五步驟為基于AnythingLLM和本地數(shù)據(jù)進(jìn)?訓(xùn)練(基于本地數(shù)據(jù)搭建本地知識 庫): ?:京東云GPU云主機(jī)環(huán)境準(zhǔn)備 ?:部署Ollama 三:運(yùn)?DeepSeek模型 四:圖形客戶端使? #第五步驟可以不執(zhí)? 五:本地數(shù)據(jù)投喂
?:京東云GPU云主機(jī)環(huán)境準(zhǔn)備:
DeepSeek的不同版本模型對主機(jī)硬件(主要是CPU、內(nèi)存和GPU)的要求不?樣,推薦使?擁有單獨GPU的主機(jī)進(jìn)?部署以獲得更好的使?體驗,顯卡推薦使?如NVIDIA RTX 3090或同等以上規(guī)格的顯卡,CPU需要?持AVX2、AVX-512等指令集可以進(jìn)?步提?響應(yīng)性能, 如已有符合業(yè)務(wù)需求的主機(jī)環(huán)境可以跳過當(dāng)前的主機(jī)環(huán)境準(zhǔn)備步驟。
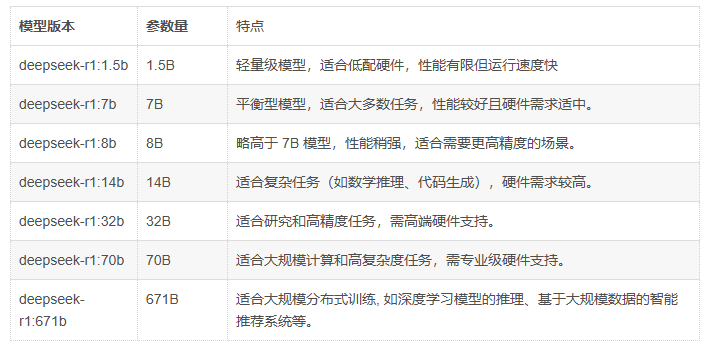
1.1: 京東云創(chuàng)建GPU云主機(jī):
基于實際業(yè)務(wù)需求選擇云主機(jī)計費模式、地域、可?區(qū)、CPU架構(gòu)、系統(tǒng)鏡像及系統(tǒng)版本, 企業(yè)環(huán)境對于穩(wěn)定性要求?較?通常使?Linux系統(tǒng)運(yùn)?業(yè)務(wù)系統(tǒng), 本步驟以Ubuntu 22.04 LTS系統(tǒng)版本為例(Rocky Linux及RHEL的操作步驟?致)、GPU為vidia Tesla P40, 演示基于Ollama部署DeepSeek-R1 :
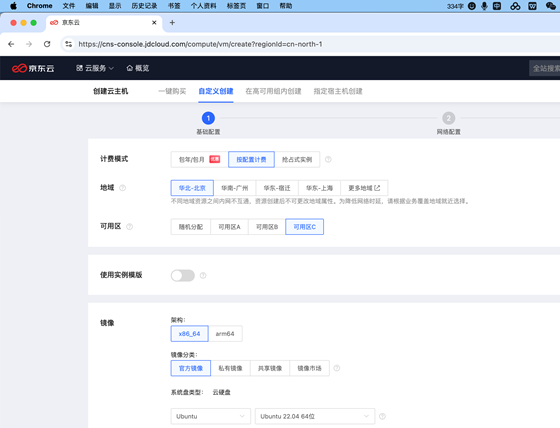
選擇GPU實例規(guī)格類型,可選自動安裝GPU驅(qū)動、或云主機(jī)運(yùn)行成功后單獨安裝GPU驅(qū)動(本文檔為單獨安裝GPU驅(qū)動)
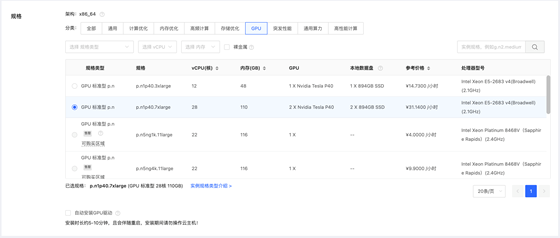
自定義云盤類型及大小、然后下一步
自定義云主機(jī)網(wǎng)絡(luò)、安全組、彈性公網(wǎng)IP, 安全組需要允許客戶端訪問11434端口, 然后下一步
?
自定義主機(jī)密碼、主機(jī)名稱等信息, 然后點擊立即購買
勾選已閱讀并同意并確認(rèn)開通
創(chuàng)建完成:
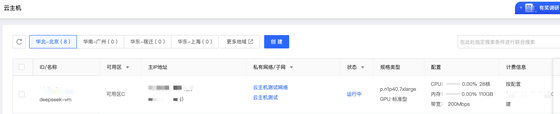
然后在云主機(jī)控制臺驗證主機(jī)運(yùn)行成功
1.2:安裝GPU顯卡驅(qū)動:
使?SSH?具遠(yuǎn)程連接到實例, 安裝顯卡驅(qū)動(以下為在Ubuntu 2204的顯卡驅(qū)動安裝過程)
root@deepseek-vm:~# apt update root@deepseek-vm:~# ubuntu-drivers devices == /sys/devices/pci0000:00/0000:00:0a.0 == modalias : pci:v000010DEd00001B38sv000010DEsd000011D9bc03sc02i00 vendor : NVIDIA Corporation model : GP102GL [Tesla P40] driver : nvidia-driver-470-server - distro non-free driver : nvidia-driver-450-server - distro non-free driver : nvidia-driver-550 - distro non-free recommended driver : nvidia-driver-535-server - distro non-free driver : nvidia-driver-418-server - distro non-free driver : nvidia-driver-545 - distro non-free driver : nvidia-driver-470 - distro non-free driver : nvidia-driver-535 - distro non-free driver : nvidia-driver-390 - distro non-free driver : xserver-xorg-video-nouveau - distro free builtin root@deepseek-vm:~# apt install nvidia-driver-550 -y #通過ubuntu倉庫安裝推薦的驅(qū)動版本或使用其它方式安裝顯卡驅(qū)動 root@deepseek-vm:~# reboot #重啟服務(wù)器以使顯卡驅(qū)動生效 root@deepseek-vm:~# nvidia-smi #重啟后驗證驅(qū)動及顯卡狀態(tài)(當(dāng)前演示主機(jī)為兩塊NVIDIA Tesla P40顯卡) Thu Feb 6 16:45:28 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.120 Driver Version: 550.120 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 Tesla P40 Off | 00000000:00:09.0 Off | 0 | | N/A 24C P8 9W / 250W | 0MiB / 23040MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 1 Tesla P40 Off | 00000000:00:0A.0 Off | 0 | | N/A 23C P8 9W / 250W | 0MiB / 23040MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
二:部署Ollama:
Ollama是一個開源的 LLM(large language model、大型語言模型)服務(wù)工具, 用于簡化和降低在本地的部署和使用門檻, 可以快速在本地環(huán)境部署和管理LLM運(yùn)行環(huán)境,。
官方地址:Ollama
下載地址:Download Ollama on macOS
ollama官方在linux 系統(tǒng)的安裝是基于腳本從github下載安裝包進(jìn)行安裝(https://ollama.com/install.sh、受網(wǎng)絡(luò)環(huán)境因素安裝過程不穩(wěn)定),可以使用二進(jìn)制安裝包直接安裝跳過在線下載過程。
2.1:下載?進(jìn)制安裝包:
Ollama可以運(yùn)?在Windows、Linux以及MacOS, 官?均提供對應(yīng)的安裝?件, ?產(chǎn) 環(huán)境對穩(wěn)定性要求?較?因此會通常使?Linux系統(tǒng), 本?的以Ubuntu 2204作為演 示環(huán)境:
https://myserver.s3.cn-north-1.jdcloud-oss.com/ollama-linuxamd64. tgz #ollama v0.5.7版本、已經(jīng)上傳到京東云OSS作為臨時下載地址 https://github.com/ollama/ollama/releases #github下載地址
?編輯
root@deepseek-vm:~# cd /usr/local/src/ root@deepseek-vm:/usr/local/src# wget https://myserver.s3.cnnorth- 1.jdcloud-oss.com/ollama-linux-amd64.tgz
2.2: 部署ollama:
ollama/docs/linux.md at main · ollama/ollama · GitHub
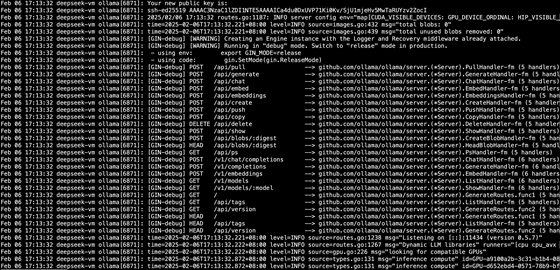
root@deepseek-vm:/usr/local/src# tar -C /usr -xzf ollama-linux-amd64.tgz #解壓安裝文件 root@deepseek-vm:/usr/local/src# ollama serve 測試啟動 Ollama Couldn't find '/root/.ollama/id_ed25519'. Generating new private key. Your new public key is: ssh-ed25519 AAAA..... 2025/02/06 17:08:47 routes.go:1187: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]" time=2025-02-06T17:08:47.465+08:00 level=INFO source=images.go:432 msg="total blobs: 0" time=2025-02-06T17:08:47.465+08:00 level=INFO source=images.go:439 msg="total unused blobs removed: 0" [GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached. [GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production. - using env: export GIN_MODE=release - using code: gin.SetMode(gin.ReleaseMode) [GIN-debug] POST /api/pull --> github.com/ollama/ollama/server.(*Server).PullHandler-fm (5 handlers) [GIN-debug] POST /api/generate --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (5 handlers) [GIN-debug] POST /api/chat --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (5 handlers) [GIN-debug] POST /api/embed --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (5 handlers) [GIN-debug] POST /api/embeddings --> github.com/ollama/ollama/server.(*Server).EmbeddingsHandler-fm (5 handlers) [GIN-debug] POST /api/create --> github.com/ollama/ollama/server.(*Server).CreateHandler-fm (5 handlers) [GIN-debug] POST /api/push --> github.com/ollama/ollama/server.(*Server).PushHandler-fm (5 handlers) [GIN-debug] POST /api/copy --> github.com/ollama/ollama/server.(*Server).CopyHandler-fm (5 handlers) [GIN-debug] DELETE /api/delete --> github.com/ollama/ollama/server.(*Server).DeleteHandler-fm (5 handlers) [GIN-debug] POST /api/show --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (5 handlers) [GIN-debug] POST /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).CreateBlobHandler-fm (5 handlers) [GIN-debug] HEAD /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).HeadBlobHandler-fm (5 handlers) [GIN-debug] GET /api/ps --> github.com/ollama/ollama/server.(*Server).PsHandler-fm (5 handlers) [GIN-debug] POST /v1/chat/completions --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (6 handlers) [GIN-debug] POST /v1/completions --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (6 handlers) [GIN-debug] POST /v1/embeddings --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (6 handlers) [GIN-debug] GET /v1/models --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (6 handlers) [GIN-debug] GET /v1/models/:model --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (6 handlers) [GIN-debug] GET / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers) [GIN-debug] GET /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers) [GIN-debug] GET /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers) [GIN-debug] HEAD / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers) [GIN-debug] HEAD /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers) [GIN-debug] HEAD /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers) time=2025-02-06T17:08:47.466+08:00 level=INFO source=routes.go:1238 msg="Listening on 127.0.0.1:11434 (version 0.5.7)" time=2025-02-06T17:08:47.466+08:00 level=INFO source=routes.go:1267 msg="Dynamic LLM libraries" runners="[cpu cpu_avx cpu_avx2 cuda_v11_avx cuda_v12_avx rocm_avx]" time=2025-02-06T17:08:47.466+08:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs" time=2025-02-06T17:08:48.193+08:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-a9100a2b-3c31-b1b4-0891-c11584b5a57f library=cuda variant=v12 compute=6.1 driver=12.4 name="Tesla P40" total="22.4 GiB" available="22.2 GiB" time=2025-02-06T17:08:48.193+08:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-d652ebd4-0571-78b9-bf01-9a8d1da592e5 library=cuda variant=v12 compute=6.1 driver=12.4 name="Tesla P40" total="22.4 GiB" available="22.2 GiB"
2.3:驗證Ollama是否正在運(yùn)行:
新建另外?個終端、驗證Ollama是否正在運(yùn)?: root@deepseek-vm:~# ollama -v ollama version is 0.5.7
2.4:添加 Ollama 作為啟動服務(wù):
新建賬戶和組、名稱都叫ollama, 以普通賬戶的身份運(yùn)?Ollama服務(wù)、并指定監(jiān)聽在 0.0.0.0:11434,以?便外部客戶端訪問。
root@deepseek-vm:~# useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
root@deepseek-vm:~# usermod -a -G ollama root
創(chuàng)建/etc/systemd/system/ollama.service 啟動文件:
root@deepseek-vm:~# vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
Environment="OLLAMA_HOST=0.0.0.0:11434"
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=default.target
#Ctrl+C退出2.3步驟運(yùn)行的ollama服務(wù)、并通過service文件啟動服務(wù):
root@deepseek-vm:~# systemctl daemon-reload
root@deepseek-vm:~# systemctl enable ollama
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
root@deepseek-vm:~# systemctl start ollama.service #啟動ollama服務(wù)
root@deepseek-vm:~# systemctl status ollama.service #確認(rèn)ollama服務(wù)處于運(yùn)行狀態(tài)
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2025-02-06 17:13:32 CST; 12min ago
Main PID: 6871 (ollama)
Tasks: 20 (limit: 132577)
Memory: 980.6M
CPU: 8.662s
CGroup: /system.slice/ollama.service
└─6871 /usr/bin/ollama serve
Feb 06 17:20:05 deepseek-vm ollama[6871]: time=2025-02-06T17:20:05.644+08:00 level=INFO sou>
Feb 06 17:23:01 deepseek-vm ollama[6871]: time=2025-02-06T17:23:01.005+08:00 level=INFO sou>
Feb 06 17:24:56 deepseek-vm ollama[6871]: time=2025-02-06T17:24:56.005+08:00 level=INFO sou>
Feb 06 17:25:16 deepseek-vm ollama[6871]: time=2025-02-06T17:25:16.005+08:00 level=INFO sou>
Feb 06 17:25:24 deepseek-vm ollama[6871]: time=2025-02-06T17:25:24.006+08:00 level=INFO sou
查看日志并確認(rèn)無報錯:
root@deepseek-vm:~# journalctl -e -u ollama
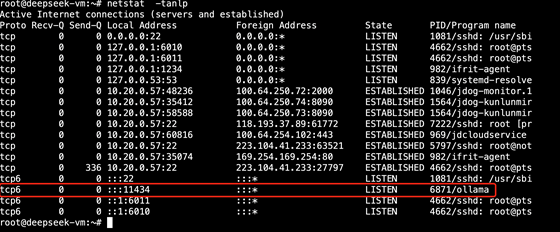
驗證ollama服務(wù)進(jìn)程和端?, 11434為ollama的默認(rèn)監(jiān)聽端?: root@deepseek-vm:~# netstat -tanlp
?
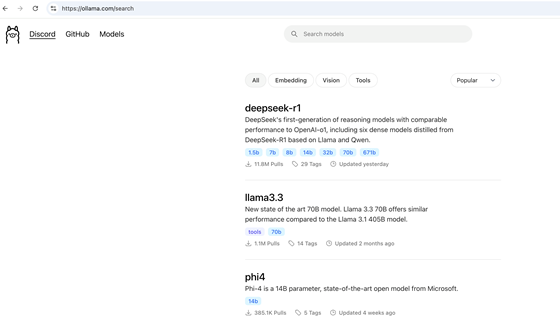
三:運(yùn)行DeepSeek模型:
https://ollama.com/search #ollama可以部署不同類型的模型和版本
DeepSeek-R1在很多方面都已經(jīng)達(dá)到或超越OpenAI-o1, 具體的模型版本可以根據(jù)實際業(yè)務(wù)需求進(jìn)行安裝, 本次為安裝deepseek-r1:8b進(jìn)行演示:
3.1:運(yùn)行deepseek-r1:8b:
https://ollama.com/library/deepseek-r1 #官??檔
deepseek-r1:1.5b #需要在線下載1.1GB的數(shù)據(jù),根據(jù)網(wǎng)絡(luò)環(huán)境和服務(wù)端負(fù)載、大約需要下載幾分鐘或更長時間 deepseek-r1:8b #需要在線下載4.9BG的數(shù)據(jù),根據(jù)網(wǎng)絡(luò)環(huán)境和服務(wù)端負(fù)載、大約需要下載幾十分鐘或更長時間 root@deepseek-vm:~# ollama run deepseek-r1:1.5b #運(yùn)行deepseek-r1:1.5b root@deepseek-vm:~# ollama run deepseek-r1:8b #運(yùn)行deepseek-r1:8b,本操作只用于說明不同版本的安裝方式、可以不執(zhí)行 根據(jù)模型的大小和網(wǎng)絡(luò)環(huán)境,需要一定的下載時間,下載過程中如果網(wǎng)絡(luò)中斷或取消, 再次執(zhí)行支持?jǐn)帱c續(xù)傳。
deepseek-r1:1.5b下載中:

deepseek-r1:8b下載中:

?下載完成后會直接進(jìn)入命令行交互式窗口,可以通過命令行窗口進(jìn)行會話
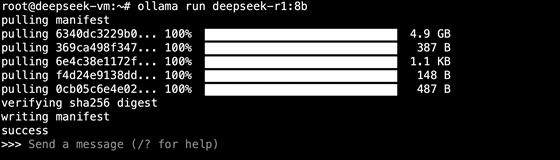
3.2:對話驗證:
3.2.1:提問一:
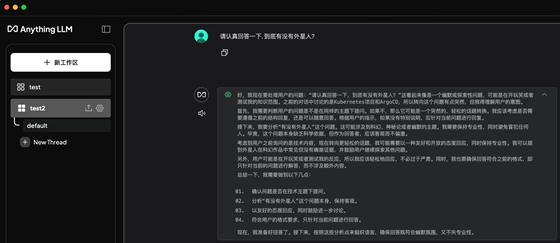
請認(rèn)真回答一下, 到底有沒有外星人?

3.2.2:提問二:
介紹一下kubernetes的優(yōu)缺點
四:圖形客戶端使用:
可以使用不同的圖形客戶端連接DeepSeek進(jìn)行交互式使用,如Chatbox、LobeChat等, 本步驟以Chatbox為例
4.1:Windows環(huán)境Chatbox圖形客戶端:
Chatbox是一個通用的圖形客戶端,支持在MacOS、Windows、Linux、安卓手機(jī)、蘋果手機(jī)等系統(tǒng)環(huán)境安裝和使用, 只需要安裝在需要訪問DeepSeek的主機(jī)、并配置連接DeepSeek連接地址及模型版本即可, 甚至還可以直接啟動網(wǎng)頁版, 本步驟演示如何在windows系統(tǒng)安裝和使用Chatbox, 本步驟介紹如果在Windows系統(tǒng)安裝Chatbox及配置和使用過程。
https://chatboxai.app/zh#download #官方下載URL https://chatboxai.app/zh/help-center/connect-chatbox-remote-ollama-service-guide #安裝文檔 https://github.com/Bin-Huang/chatbox/releases #安裝文件下載地址
4.1.1:下載安裝文件:
點擊免費下載:
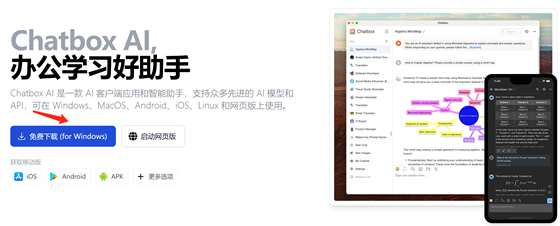
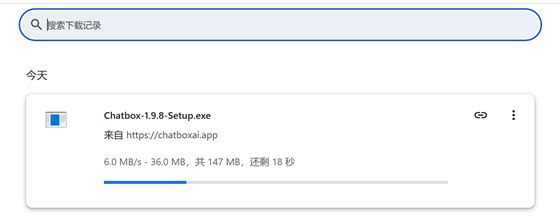
下載過程中:
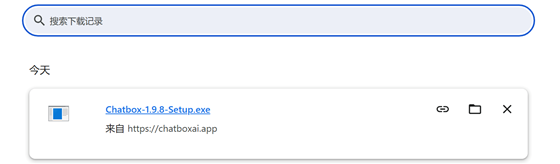
下載完成:
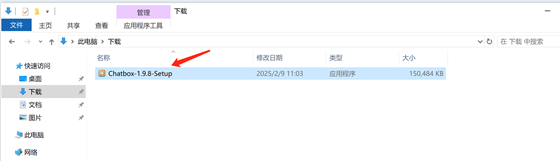
4.1.2:安裝Chatbox:
在下載目錄雙擊安裝文件執(zhí)行安裝:
可選擇為當(dāng)前用戶還是所有用戶安裝、然后點擊下一步:
?
可選安裝路徑、然后單機(jī)安裝:
安裝過程中:
安裝完成, 點擊完成并運(yùn)行Chatbox:
4.1.3:配置Chatbox:
首次打開要配置一下使用的模型, 選擇使用自己的API Key或模型:
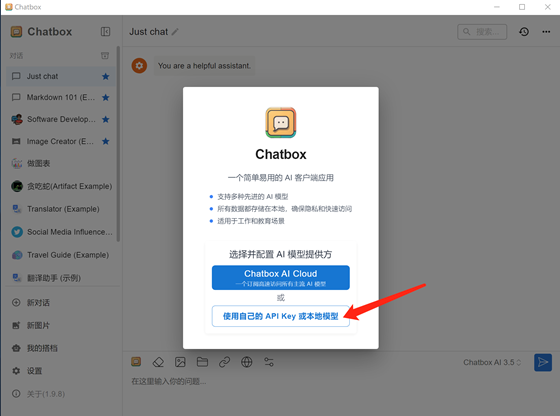
選擇使用Ollama API:
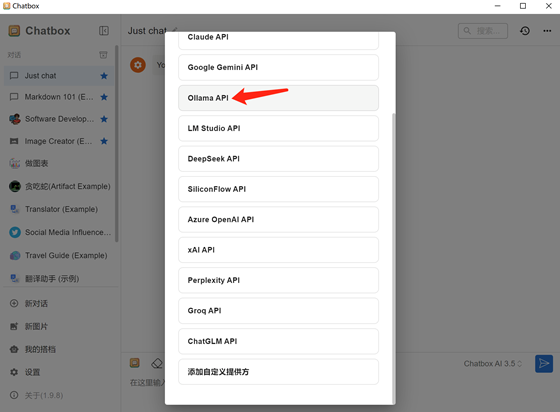
具體配置:
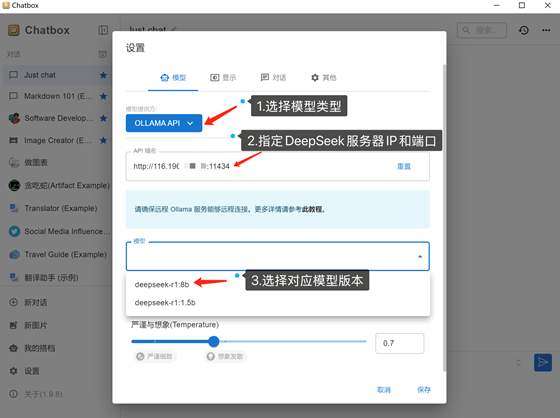
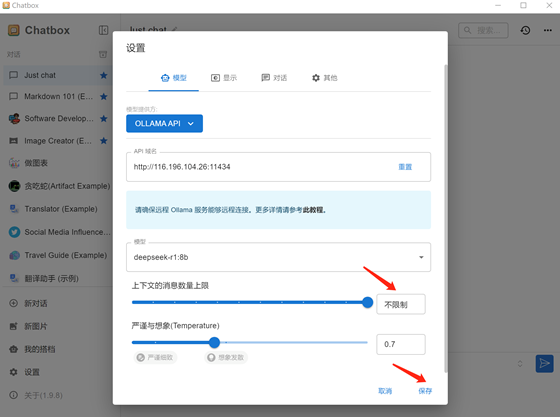
上下文消息數(shù)(保存的歷史會話數(shù)量)可以不限制、然后點擊保存:
4.1.4:對話測試:
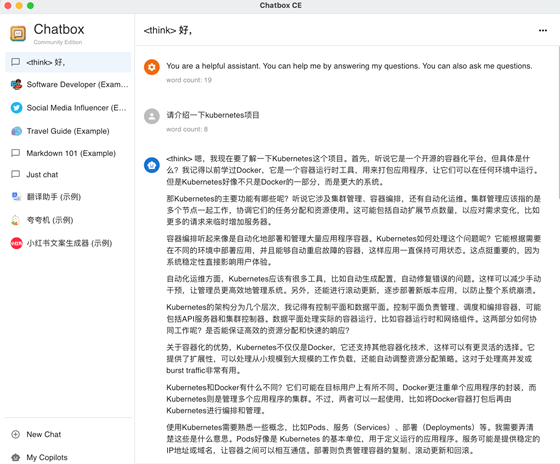
Chatbox可以通過DeepSeek進(jìn)行成功對話
4.1.4.1:提問一:
請認(rèn)真回答一下, 到底有沒有外星人?
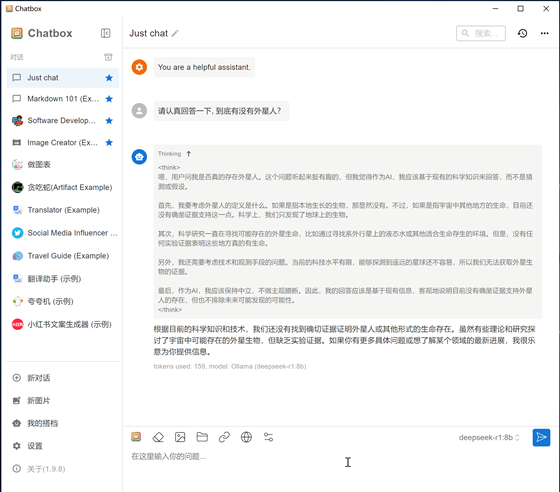
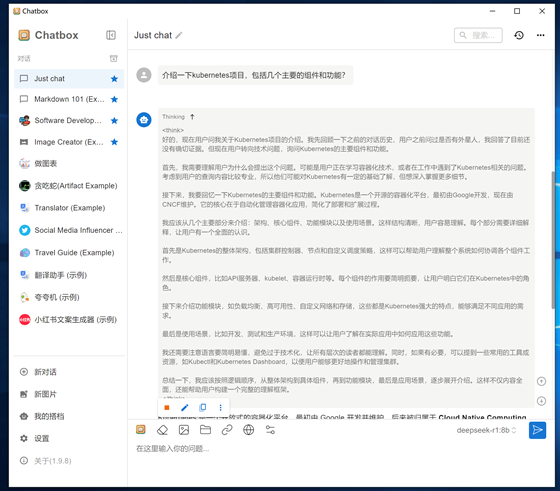
4.1.4.2:提問二:
介紹一下kubernetes項目,包括幾個主要的組件和功能?
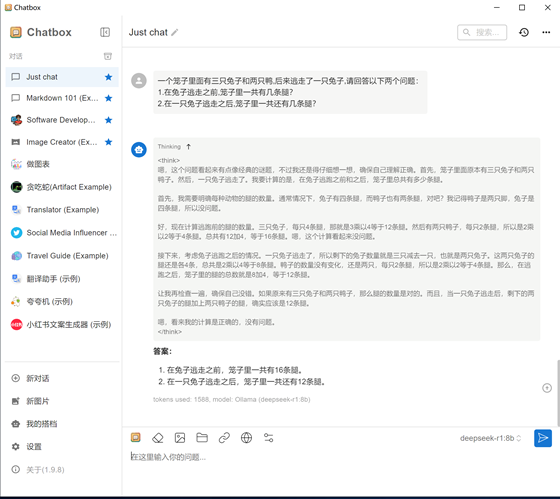
4.1.4.3:提問三:
一個籠子里面有三只兔子和兩只鴨,后來逃走了一只兔子,請回答以下兩個問題:
1.在兔子逃走之前,籠子里一共有幾條腿?
2.在一只兔子逃走之后,籠子里一共還有幾條腿?
?
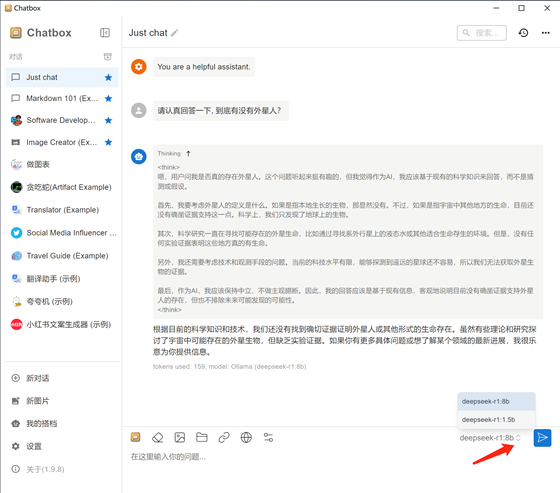
4.1.5:如果要切換模型版本:
如果在同一個DeepSeek服務(wù)器部署了不同版本的模型,可以在Chatbox右下角進(jìn)行不同版本的切換
4.2:MacOS環(huán)境Chatbox圖形客戶端:
本步驟介紹如果在MacOS系統(tǒng)安裝Chatbox及配置和使用過程
4.2.1:下載安裝文件:
蘋果系統(tǒng)(Intel CPU)下載的Chatbox.CE-0.10.4-mac.zip,如果是windows系統(tǒng)則是下載Chatbox.CE-0.10.4-Setup.exe
4.2.2:安裝Chatbox:
蘋果系統(tǒng)下載后解壓, 會有個Chatbox CE程序:
?

可以拷貝到應(yīng)用程序里面方便后期使用:

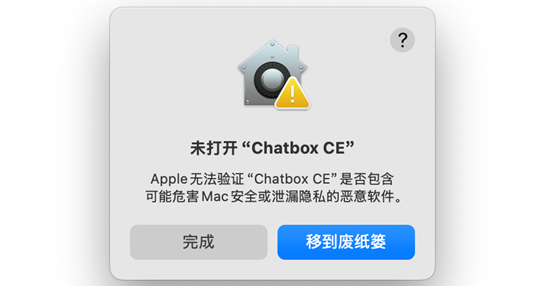
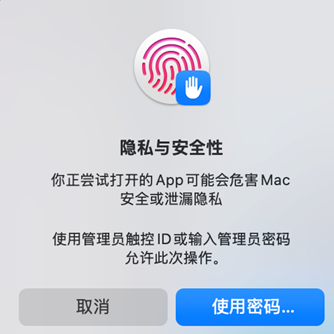
然后雙擊打開,首次打開需要信任:
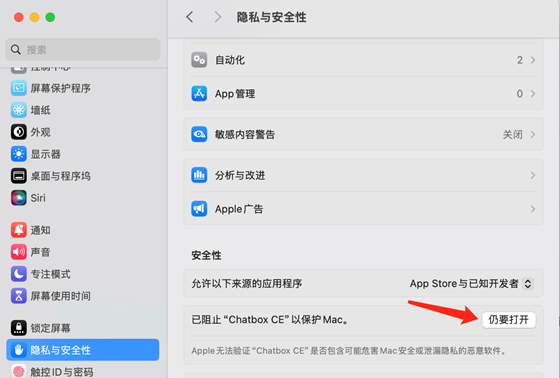
進(jìn)入系統(tǒng)菜單,設(shè)置-->隱私與安全性-->仍要打開:
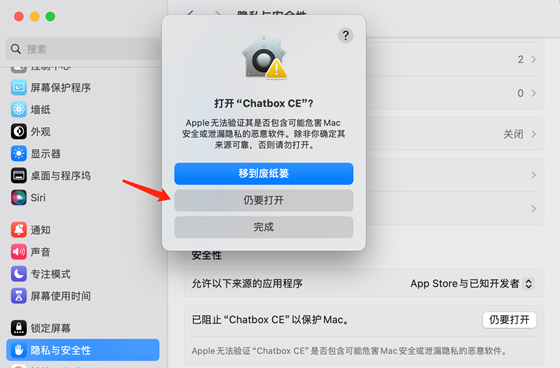
確認(rèn)仍要打開:
輸入認(rèn)證(密碼或指紋認(rèn)證)信息確認(rèn):
4.2.3:配置Chatbox:
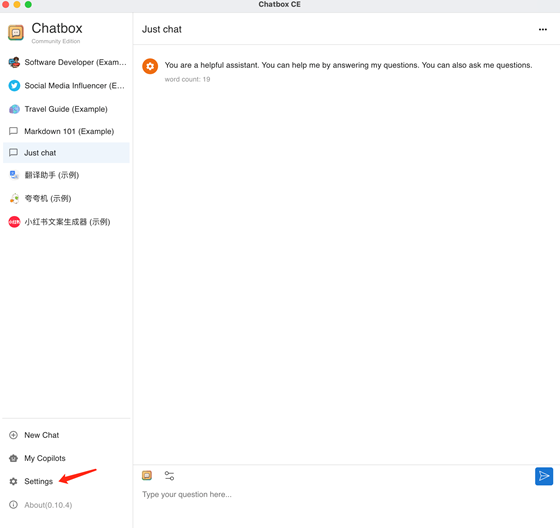
首次使用需要配置Chatbox連接deepseek模型, 點擊左側(cè)菜單Settings:
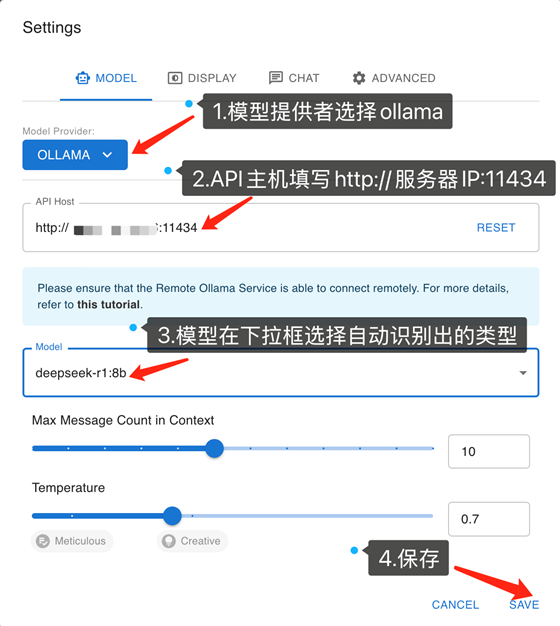
Chatbox配置信息如下:
4.2.4:對話測試:
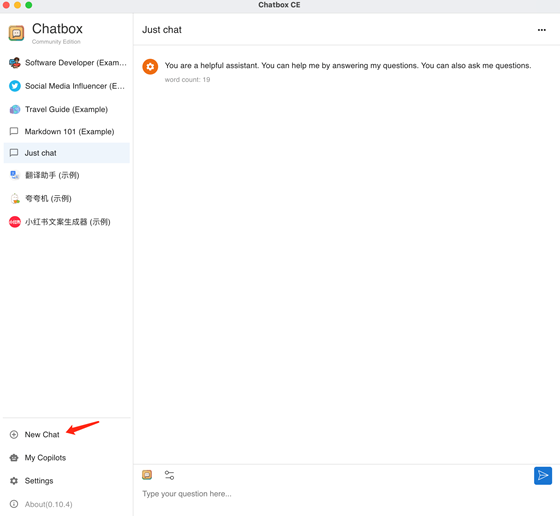
可選新建一個對話:
對話驗證:
五:本地數(shù)據(jù)投喂:
基于AnythingLLM+DeepSeek進(jìn)行數(shù)據(jù)投喂訓(xùn)練, 用于搭建本地離線知識庫等場景, 本步驟是測試搭建本地知識庫,非必須不需要執(zhí)行。
https://anythingllm.com/
https://github.com/Mintplex-Labs/anything-llm
5.1:下載并安裝AnythingLLM:

5.2:AnythingLLM基礎(chǔ)配置:
初始化AnythingLLM對接DeepSeek的配置
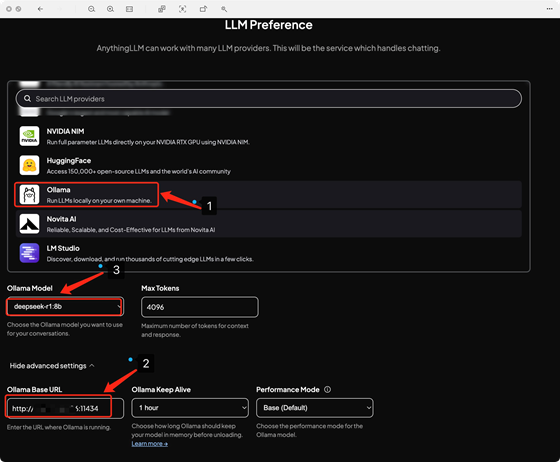
5.2.1:LLMPreference:
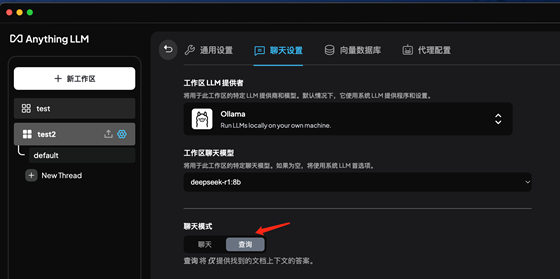
5.2.2:工作區(qū)對話設(shè)置:
將聊天模式從聊天改為查詢, 將會根據(jù)本地上傳和識別后的數(shù)據(jù)進(jìn)行響應(yīng)
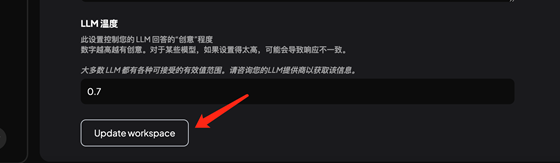
更新保存配置:
5.2.3:配置embedder首選項為ollama:
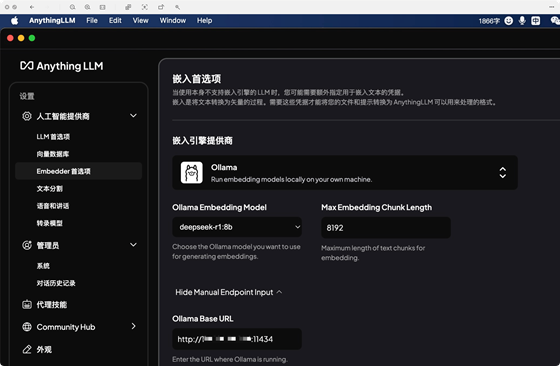
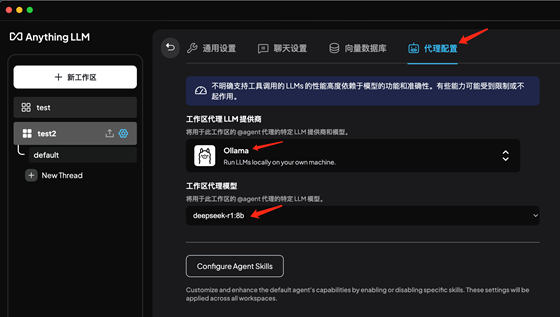
5.2.4:代理配置:
5.2.5:工作區(qū)上傳測試訓(xùn)練文檔:
上傳本地文檔之前無法回答問題,因此要上傳本地文檔進(jìn)行訓(xùn)練(支持PDF、Txt、Word、Excel、PPT等常見文檔格式):
本地文檔上傳中:
本地文檔上傳完成:
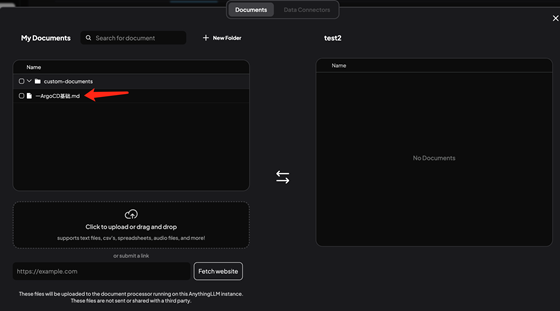
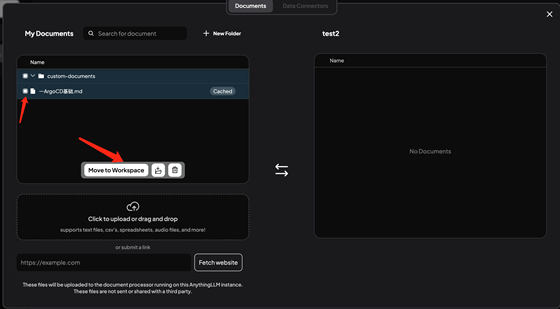
選擇指定的文檔并移動到工作區(qū):
?
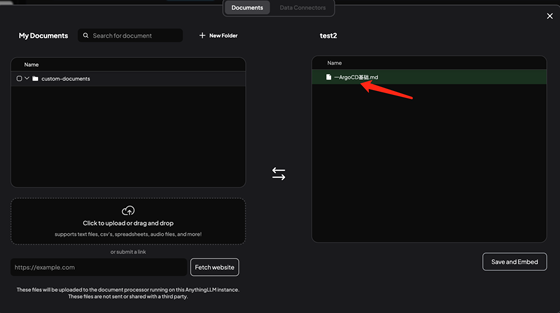
保存并導(dǎo)入:
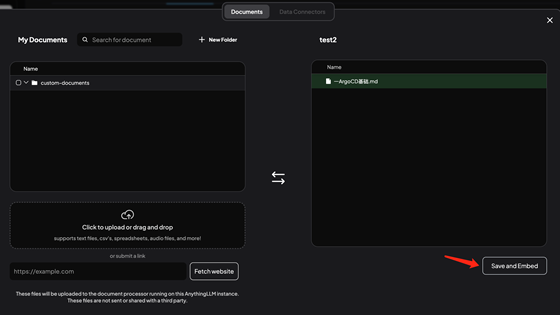
導(dǎo)入并識別中:
識別完成:
關(guān)閉窗口:
返回到對話窗口:
5.3:對話驗證:
DeepSeek可以根據(jù)本地的知識內(nèi)容進(jìn)行匹配和回答
5.3.1:基于本地文檔回答成功的:
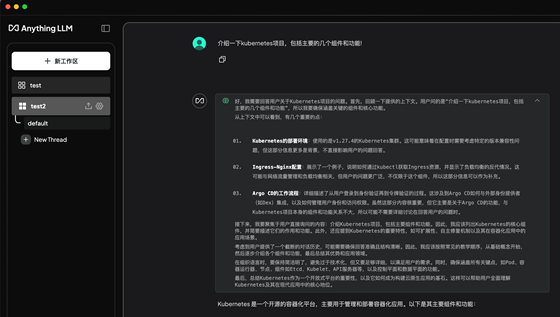
5.3.2:本地沒有的內(nèi)容提問及對話:
經(jīng)過多次提問、DeepSeek會盡可能使用本地文檔內(nèi)容進(jìn)行回復(fù)
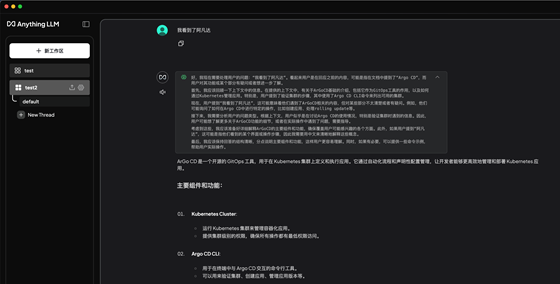
審核編輯 黃宇
-
gpu
+關(guān)注
關(guān)注
28文章
4949瀏覽量
131307 -
京東云
+關(guān)注
關(guān)注
0文章
178瀏覽量
139 -
DeepSeek
+關(guān)注
關(guān)注
1文章
798瀏覽量
1768
發(fā)布評論請先 登錄
京東回應(yīng)馬云“悲劇說”: 不必妄自多情
10分鐘學(xué)會FPGA設(shè)計
60分鐘學(xué)會OrCAD Capture CIS
如何利用SRC核心控制器來打造自己的專屬移動機(jī)器人
SRC核心控制器,輕松打造你的專屬移動機(jī)器人

京東云正式上線DeepSeek系列模型
10分鐘上手寫代碼,LuatOS協(xié)程輕松掌握!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論