 探討DeepSeek-R1滿血版的推理部署與優化策略
探討DeepSeek-R1滿血版的推理部署與優化策略

TL;DR
春節假期開始, 好像很多人都在開始卷DeepSeek-R1的推理了. 渣B也被兄弟團隊帶著一起卷了一陣, 其實推理中還有很多約束, 比較認同的是章老師的一個觀點: “推理框架很有可能就此走向兩種極致分化的方向.“ 本文來做一個詳細的闡述, 從一些亂七八糟的benchmark開始, 然后談談測試方法, 推理系統的各種約束, 推理框架的區別, 并行策略的區別,然后再解構一下DeepSeek的原廠方案.
1. 前情回顧 2. 推理性能指標概述 3. 推理系統性能約束 3.1 用戶SLA的約束 3.2 內存的約束 4.約束帶來的分叉 5. 私有化部署 5.1 基于SGLang 5.2 基于vLLM 5.3 并行策略選擇 6. 平臺部署 6.1 PD分離技術 6.2 Prefill階段 6.3 Decode階段 7. 未來優化的方向和對開源生態的建議
1. 前情回顧
比較現實的是兩個極端, 一方面是各種平臺的測評, 例如公眾號“CLUE中文語言理解測評基準”的
《DeepSeek-R1 網頁端穩定性首測:12家第三方平臺真實測評》
另一方面是尤洋老師在微博的一個評論MaaS的商業模式和平臺推理虧損, 這里提到了4臺H800的總吞吐量
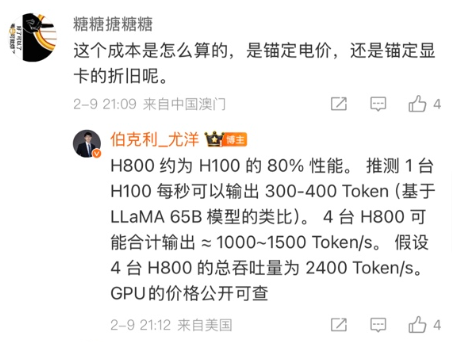
另一方面是各種私有化部署的需求, 例如小紅書上最近經常刷到還有章明星老師的KTransformer可以在單卡的4090 24GB上配合Intel CPU的AMX部署Q4的量化版本. 通過將Routed Expert放置在CPU上運行來降低內存的使用量.
還有直接ollama找一個1TB內存的CPU實例就開跑的方案.
然后Benchmark的定義上,一會兒20 Tokens/s, 一會兒又是幾千Tokens/s的benchmark滿天飛, 到底是怎么回事? 其實有很多認知的問題, 讓渣B回憶起剛畢業入職工作的時候做運營商級的電話信令網關時, 天天測性能算Erlang模型的日子...
2. 推理性能指標概述
推理是一個在線業務, 因此對第一個Token出來的延遲(Time To First Token,TTFT)和后續token產生的延遲(Time Per output Token,TPOT)都會對用戶體感產生影響.
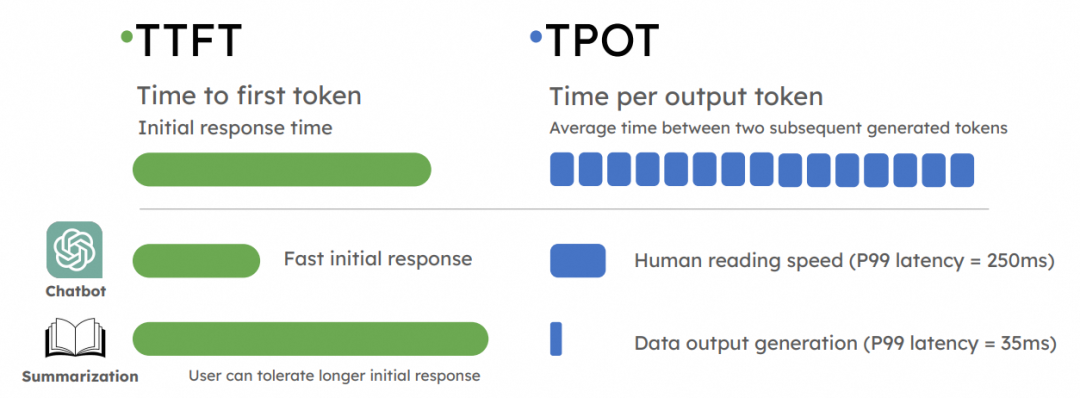
通常會使用測試工具生成如下一個報告, 具體數據就不多說了.
影響這個報告的因素很多, 例如測試工具是采用vllm的benchmark_serving還是采用sglang.bench_serving, 常用的參數是按照多少Request per seconds(RPS)測試或者按照多少并發量進行測試, 但是DeepSeek-R1的推理Reasoning時間很長, 通常都會選擇并發數進行約束.測試在一定的并發數量下的吞吐/延遲等指標. 測試命令如下所示:
###vLLM的bench測試 python3~/vllm/benchmarks/benchmark_serving.py--backendvllm --model~/deepseek-R1--port8000 --dataset-namerandom --random-input1234 --random-output2345 --random-range-ratio0.8 --dataset-path~/ShareGPT_V3_unfiltered_cleaned_split.json --max-concurrency16 --num-prompts64 ###sglangM的bench測試 python3-msglang.bench_serving--backendvllm --model~/deepseek-R1--port8000 --dataset-name=random--random-input=1234 --random-output=2345 --max-concurrency=64 --num-prompts=128 --random-range-ratio0.9 --dataset-path~/ShareGPT_V3_unfiltered_cleaned_split.json
除了并發數max-concurrency以外, 另兩個比較重要的參數是input多少token和output多少token, 這也是非常影響測試結果的. DeepSeek-R1作為一個Reasoning模型, 輸出Thinking階段的token也挺多的, 所以要根據實際的業務需要來進行分析.
因為以前長期做運營商級的呼叫信令網關, 對于請求到達是否按照Poisson過程, 對于結果的影響也很大, 這是一個非常重要的點, sglang的bench例如并發128時, 就是128個請求一起發出去了, 然后大家一起Prefill, 然后一起decode,這樣可能導致TTFT偏長. 而vllm的測試是如果設置并發時是按照Poisson過程請求的. 但是似乎做的也不太符合真實的情況.
3. 推理系統性能約束
主要的約束有幾個方面:
3.1 用戶SLA的約束
通常我們可以根據實際業務的需求獲得平均輸入Token數和輸出Token數以及方差, 然后根據企業員工的數量或者承載用戶的DAU計算出一個平均請求到達間隔, 然后根據一些SLA的約束, 例如TTFT首Token時間要小于4s, TPOT即用戶感知的每秒token輸出速度, 例如要大于20Token/S(TPS).然后再來估計用戶平均對一個請求的整體持續時間, 通過Erlang模型建模.
但是很多時候性能和成本之間會有一些取舍, 例如是否在一個低成本方案中,放寬對TTFT和TPOT的要求, 慢一點但是足夠便宜就好, 或者是另一方面例如袁老師的硅基流動, Pro版本就能夠嚴格保證用戶的SLA, 也就是夏Core講的, 穩定保持TPOT > 20TPS、
但是為了保證API平臺的SLA, 通常需要采用更復雜的并行策略, 降低延遲提高吞吐, 例如DeepSeek論文提到的EP320的 40臺機器的集群方案.
3.2 內存的約束
對于較長的Context,KVCache對顯存的占用也特別大, 雖然單機的H20顯存也能放得下滿血版的671B模型,但是剩余的顯存也會約束到模型的并發能力. 通常有些提供API的廠家會配置一個截斷, 例如最大長度就8192個Tokens. 通常在這種場景下為了提高并發, 最小配置都會用2臺以上的H20, 或者一些MI300的實例, 國外還有一些會采用H200的實例.
4.約束帶來的分叉
正如前一章節所屬, 兩個約束帶來了分叉. 一方面用戶希望低成本的私有化部署,帶來了一些小型化部署的機會, 例如小紅書上看到的, 200w如何私有化部署滿血版. 另一方面是大規模的云平臺提供服務的時候保障SLA.
這兩者直接決定了部署上的區別:
私有化部署: 2臺4臺并行小規模滿足成本的需求, 而不太在意TTFT和TPOT的需求, 能夠滿足企業內并發需求即可,甚至是季宇老師提到的一個極端的情況,就只做一個并發時, 如何用最低成本的硬件實現大概10~20TPS.
平臺部署: 最小320卡到最大數千數萬卡并行的需求, 這種需求下并發的請求數量, KVCache的用量和累計整個集群的TFTT和TPOT的約束都非常大, 因此需要在并行策略上進行更多的考慮, 例如EP并行還有PD分離等.
很多較小的提供商通常只有開源軟件sglang和vllm的部署能力, 然后并行策略上只有非常局限的TP/PP選擇, 因此只有2~4臺機器并行一組的方式提供服務, 自然就會遇到一些成本過高,吞吐過低無法通過token收費掙錢的情況. 這也就是所謂的夾在中間非常難受的一個例子.
因此章明星老師講的這兩種部署帶來的推理系統分叉將會成為一個必然趨勢.
5. 私有化部署
通常的做法是買兩臺H20或者在云上租用2臺H20構建一個最小部署集, 然后自建的方式來部署.
5.1 基于SGLang
基于Sglang的部署方式如下, 兩臺機器安裝sglang
pipinstallsgl-kernel--force-reinstall--no-deps pipinstall"sglang[all]>=0.4.2.post3"--find-linkshttps://flashinfer.ai/whl/cu124/torch2.5/flashinfer/
第一臺機器執行時, nnodes=2, node-rank=0, dist-init-addr都是第一臺機器的IP地址.
python3-msglang.launch_server --model-path~/deepseek-R1/ --tp16--dist-init-addr1.1.1.1:20000 --nnodes2--node-rank0 --trust-remote-code--host0.0.0.0--port8000
第二臺機器執行時,--nnodes 2 --node-rank 1
python3-msglang.launch_server --model-path~/deepseek-R1/ --tp16--dist-init-addr1.1.1.1:20000 --nnodes2--node-rank1 --trust-remote-code--host0.0.0.0--port8000
需要注意的是,現階段Sglang只支持TP并行, PP并行在未來幾周可能會支持.
5.2 基于vLLM
vLLM需要基于Ray部署, 如下圖所示:
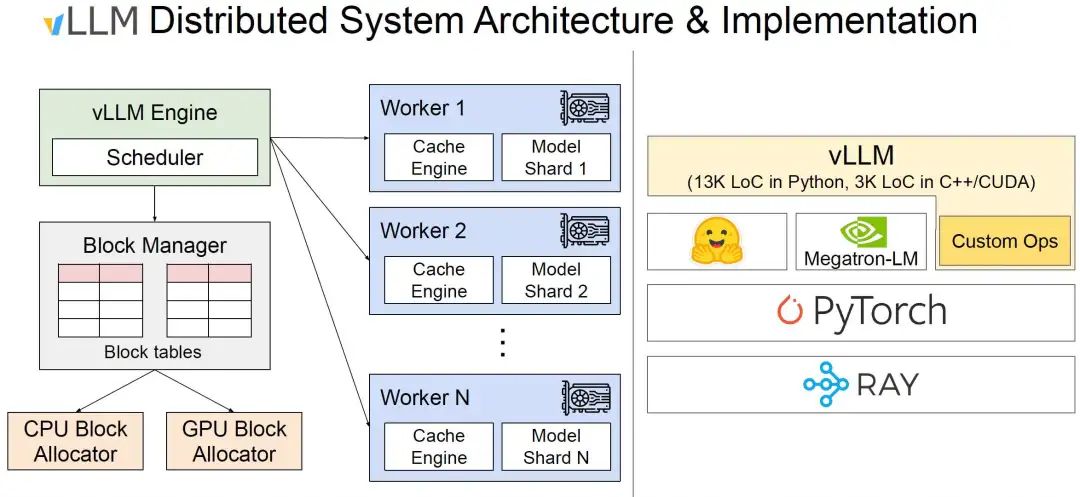
首先需要安裝Ray
pip3installray
然后第一臺機器配置
raystart--head--dashboard-host0.0.0.0
第二個機器根據第一個機器的提示輸入加入集群
raystart--address=':6379'
然后檢查集群狀態
raystatus ========Autoscalerstatus:2025-02-071906.335568======== Nodestatus --------------------------------------------------------------- Active: 1node_50018fxxxxx 1node_11cc6xxxxx Pending: (nopendingnodes) Recentfailures: (nofailures) Resources --------------------------------------------------------------- Usage: 0.0/256.0CPU 0.0/16.0GPU 0B/1.59TiBmemory 0B/372.53GiBobject_store_memory Demands: (noresourcedemands)
然后兩臺機器都安裝vllm, 注意需要安裝最新版的vllm 0.7.2性能有很大提升.
pip3installvllm
最后在第一臺機器上開啟服務即可, 然后需要根據容忍的最大輸入和模型輸出調整max-num-batched-tokens和max-model-len
vllmserve~/deepseek-R1 --tensor-parallel-size16 --enable-reasoning --reasoning-parserdeepseek_r1 --max-num-batched-tokens8192 --max-model-len16384 --enable-prefix-caching --trust-remote-code --enable-chunked-prefill --host0.0.0.0
單個輸入的測試腳本如下
#test.py
fromopenaiimportOpenAI
#ModifyOpenAI'sAPIkeyandAPIbasetousevLLM'sAPIserver.
openai_api_key="EMPTY"
openai_api_base="http://localhost:8000/v1"
client=OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models=client.models.list()
model=models.data[0].id
#Round1
messages=[{"role":"user","content":"whatisthepresheaf?andhowtoproveyonedalemma?"}]
response=client.chat.completions.create(model=model,messages=messages)
reasoning_content=response.choices[0].message.reasoning_content
content=response.choices[0].message.content
print("reasoning_content:",reasoning_content)
print("content:",content)
5.3 并行策略選擇
如果選擇sglang,當前只有TP并行策略, 因此需要為每個GPU配置400Gbps網卡構成雙機3.2Tbps互聯, 這是一筆不小的開銷. 當然TP并行理論上說在Token generate的速度上會有優勢, 但事實上和vLLM新版本的PP并行差距并不大. 相反TP并行的SGlang在Prefill階段的性能還是有很大問題的, TTFT比起PP并行的vLLM很多場景下慢了一倍.
而vLLM更推薦PP并行, 主要是壓根就不需要RDMA網絡, 就CPU上插一張網卡即可, 同時KV Cache的容量和吞吐都有提升. 特別是KVCache, 比起TP并行省了很多, 對于私有化部署提高并發很有好處.
有一篇關于vLLM 0.7.2優化的分析文章[1]其中提到

具體分析一下兩種并行方式, PP并行也就是在模型的中間按層分開, 按照一個Token hidden-dim 7168和FP8計算, 如果每秒吞吐為1000個token, 則累積的帶寬需求為7MB/s 即便是Prefill階段需要5000tokens/s的能力,也就35MB/s, 一般一張100Gbps的網卡就夠了.
而TP并行在Sglang中的實現是采用了對MLA進行DP并行, 每張卡維護不同Seq的KVCache, 并分別通過DP worker完成prefill/decode一類的任務, 從而相對于TP并行節省KVCache開銷, 然后再進行一次allgather 讓不同的卡都拿到hidden-state進行MoE的計算.
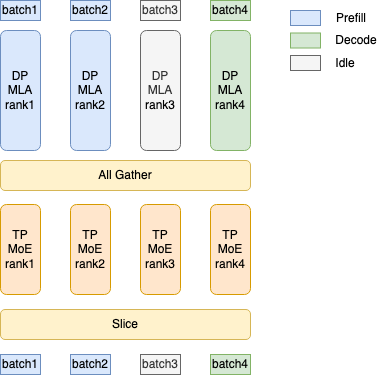
但是官方的文檔[2]似乎并沒有開啟這種模式, 而是采用標準的TP并行, 這樣每個卡都要有全量的kvcache.
綜合來看, 從私有化部署的成本來考慮, 選擇vLLM或者未來支持pp并行的Sglang是一個更好的選擇. 性能差距很小的情況下,省掉了一個專用的GPU RDMA網絡的成本還是非常好的, 而且也適合企業部署, 隨便找個機柜放兩臺, CPU的網卡接交換機上即可,無需特別的維護. 另一方面伴隨著兩三個星期以后兩個框架都支持了MTP, 應該整體性能還有進一步的提升.
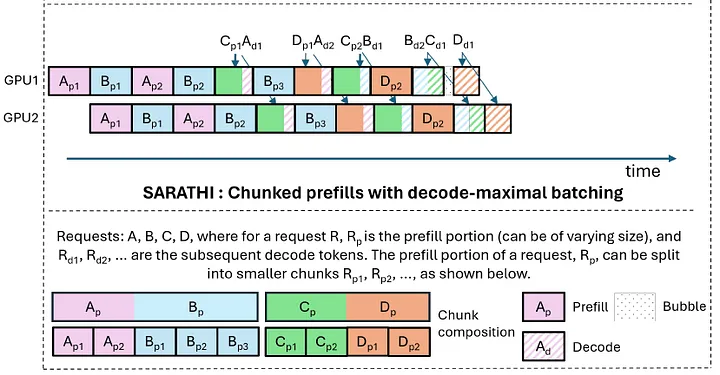
另外針對這樣的小規模兩機部署,通常會采用Chunk-Prefill的技術, 將Prefill的計算拆分成chunk穿插在Decode任務中, 來避免同一個卡運行Prefill和Decode時, 兩階段的資源爭搶干擾會導致TTFT和TPOT都很難達到SLA的標準.
6. 平臺部署
平臺部署,更多的就要參考Deepseek-V3的論文了. DeepSeek首先采用了PD分離的技術.
6.1 PD分離技術
當Prefill和Decode兩個階段在同一個卡上運行時, 兩階段的資源爭搶干擾會導致TTFT和TPOT都很難達到SLA的標準. 例如突然來一個很長的prompt的請求需要大量的計算資源來進行prefill運算, 同時也需要大量的顯存來存儲這個請求的KV Cache.針對Prefill Compute-Bound計算和Decode Memory-bound計算的特點, 以及不同卡的算力差異, 出現了Prefill-Decode分離的架構, 即用高算力的卡做Prefill, 低算力的卡做Decode, 并且Prefill節點在完成計算傳輸KV Cache給Decode節點后就可以free掉本地顯存.
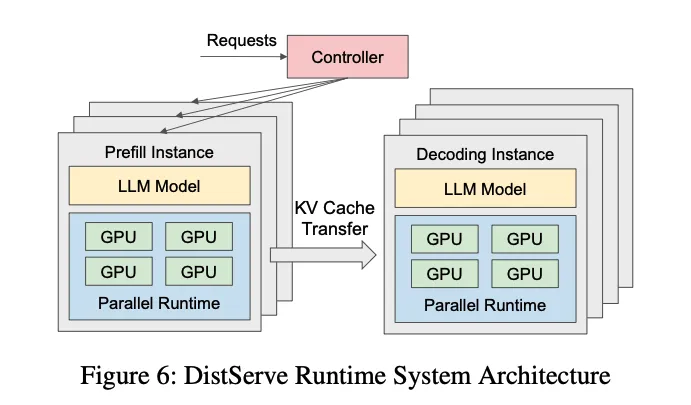
分離后的延遲和性能(來自論文DistServe), 可以看到在滿足SLA的條件下, 分離后的性能會更好.
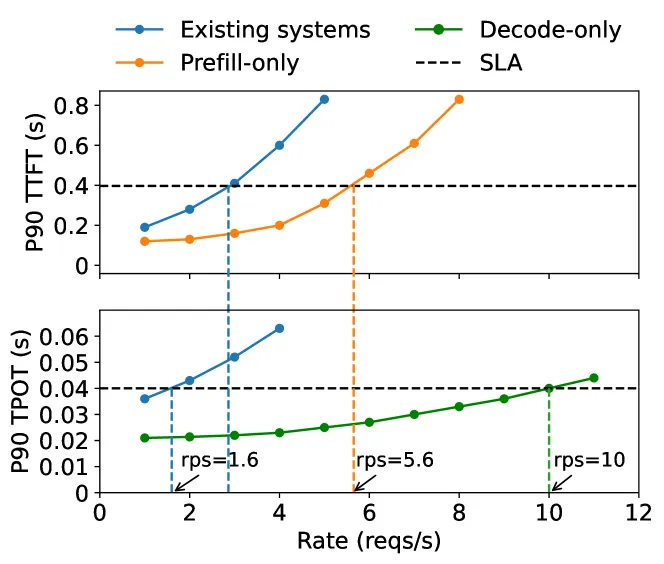
在PD分離架構下, 可以分別針對Compute-bound和Memory-bound進行有針對性的優化. 例如對請求的batch處理, Prefill階段由于每個token都要計算,當batch中的總token數達到計算瓶頸門限后, 吞吐率就趨于平緩了. 而在Decode階段隨著batchsize增大可以顯著的增加吞吐率
6.2 Prefill階段
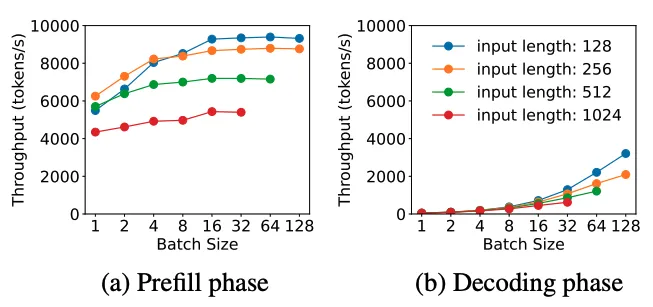
預填充階段的最小部署單元由4個節點和32個GPU組成。
Attention block 采用4路張量并行(TP4)與序列并行(SP)結合,并輔以8路數據并行(DP8)。其較小的TP尺寸為4,限制了TP通信的開銷。
對于MoE部分,使用32路專家并行(EP32),確保每個專家處理足夠大的批量大小,從而提升計算效率。對于MoE的all-to-all通信,采用與訓練時相同的方法:首先通過InfiniBand(IB)在節點間傳輸token,然后通過NVLink在節點內的GPU之間轉發。
特別地,在最開始三層的 Dense MLP中使用1路張量并行,以節省TP通信開銷。
為了實現MoE部分中不同專家之間的負載均衡,需要確保每個GPU處理大致相同數量的token。為此,引入了冗余專家的部署策略,通過復制高負載專家并冗余部署它們來達到這一目的。高負載專家是基于在線部署期間收集的統計數據檢測出來的,并會定期調整(例如每10分鐘一次)。在確定冗余專家集合后,會根據觀察到的負載,在節點內的GPU之間精心重新安排專家,盡可能在不增加跨節點alltoall通信開銷的情況下,實現GPU之間的負載均衡。在DeepSeek-V3的部署中,為預填充階段設置了32個冗余專家。對于每個GPU,除了其原本負責的8個專家外,還會額外負責一個冗余專家。
此外,在預填充階段,為了提高吞吐量并隱藏alltoall和TP通信的開銷,采用了兩個計算量相當的micro-batches,將一個micro ba t ch的Attention和MoE計算與另一個microbatch的Disptach和Combine操作overlap。
另外,論文還提到了他們正在探索動態的專家冗余策略, 即每個GPU負責更多的專家(例如16個專家),但在每個推理步驟中只激活其中的9個。在每一層的AlltoAll操作開始之前,動態計算全局最優的路由方案.
6.3 Decode階段
在Decode階段, 將Shared Expert和其它Routed Expert一視同仁. 從這個角度來看,每個token在路由時會選擇9個專家,其中共享專家被視為一個高負載專家,始終會被選中。解碼階段的最小部署單元由40個節點和320個GPU組成。注意力部分采用TP4與SP結合,并輔以DP80,而MoE部分則使用EP320。在MoE部分,每個GPU僅負責一個專家,其中64個GPU專門用于托管冗余專家和共享專家。
需要注意的是, dispatch和combine部分的AlltoAll通信通過IB的直接點對點傳輸實現,以降低延遲。此外,還利用IBGDA技術進一步最小化延遲并提升通信效率,即直接利用GPU構建RDMA隊列和控制網卡doorbell
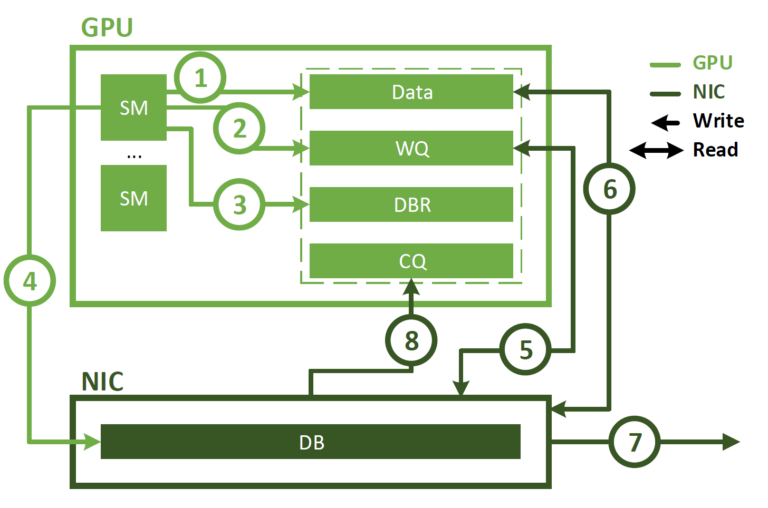
與Prefill階段類似, 基于在線服務的統計專家負載,定期確定冗余專家的集合。然而,由于每個GPU僅負責一個專家,因此不需要重新安排專家的位置。同時也在探索解碼階段的動態冗余策略。不過,這需要對計算全局最優路由方案的算法以及與Dispatch Kernel的融合進行更細致的優化,以減少開銷。
此外,為了提高吞吐量并隱藏AlltoAll通信的開銷,還在探索在解碼階段同時處理兩個計算工作量相似的microbatch。與預填充階段不同,解碼階段中Attention計算占據了更大的時間比例。因此,需要將一個Microbatch的注意力計算與另一個microbatch的Dispatch+MoE+Combine操作Overlap。
在Decode階段,每個專家的批量大小相對較小(通常在256個token以內),瓶頸在于內存訪問而非計算。由于MoE部分只需加載一個專家的參數,內存訪問開銷極小,因此使用較少的SM不會顯著影響整體性能。因此,為了避免影響Attention block的計算速度,可以僅為Dispatch+MoE+Combine分配一小部分SMs。
其實DeepSeek的工作已經做的非常細致了, 例如Prefill階段通過兩個microbatch來隱藏attention和MoE的A2A和TP通信開銷. 并且通過冗余專家來降低Alltoall開銷, 而在Decode階段并沒采用原來的訓練中那樣的PXN方式, 而是采用了直接p2p IB通信的方式, 并啟用了IBGDA降低延遲. 對于一個大集群來看, 使用這些優化比起尤洋老師估計的每臺機器400tokens/s的量, 應該起碼高出20~50倍.
7. 未來優化的方向和對開源生態的建議
私有化部署和平臺部署將會帶來推理生態的分叉, 在雙機部署或者未來大內存的單機部署下, 可能更多的是考慮片上網絡如何高效的互聯, 例如帶AMX的CPU來做MoE而輔助一些TensorCore做Attention Block, 例如GB200 NVL4這樣的單機推理平臺
或者就是極致的,像Apple M4那樣的Unified Memory, 帶一些NPU, 或者例如Project Digits那樣的GB10的chip, 然后做到大概10萬人民幣能夠完成滿血版671B的部署, 這些單U的服務器或許也逐漸會成為云服務提供商的主力機型. 另一方面最近在做一些R1-Zero的復現和算法分析相關的事情, 覺得似乎這樣的一些小規模集群對于強化學習RLFT也可能成為一個很好融合的機會. 例如4臺~8臺的小規模集群做一些垂域的模型蒸餾等, 這個市場會逐漸打開.
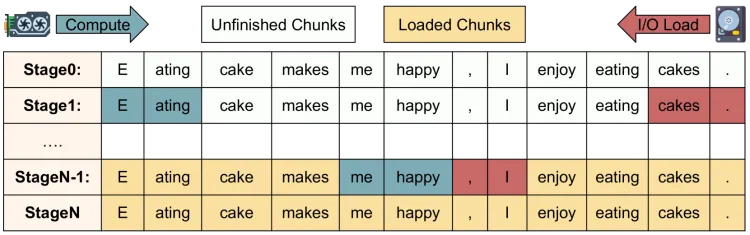
對于這些小機器, 內存通常受限的, 是否可以做一個雙向加載?例如論文《Compute or Load KV Cache? Why not both?》采用了雙向fill的機制, 從最后一個token開始倒著向前讀取KV-Cache, 然后前向從第一個Token開始進行KVCache計算, 直到兩個過程交匯.
而另一個方向, 是大集群的MaaS/SaaS服務提供, 通信和計算的Overlap,計算集群的負載均衡等, 當然首先還是要一些開源生態先去把一些EP并行框架的問題解決了才有后續, 當然我個人是一直比較看好vLLM+Ray的部署的, Ray本身和計算節點的負載以及內存的ojbect抽象其實蠻好的, 其實在看《Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache》的工作, 在多個實例間共享內存實現分布式的KV-Cache存儲.
還有一些很細致的內存管理的工作, 例如GMLake/vTensor等...進一步解決它的一些通信延遲后, 可能和其它在線業務融合是一個蠻大的優勢.而另一方面Sglang也非常厲害, 前期性能超過vLLM很多.
更進一步,作為PaaS的基于SLA的調度還有很多工作和機會可以去做. 例如KVCache的存儲和優化. 其實每個做推理的PaaS或許都應該下場參與到開源生態中, 例如當年的Spark.
當然還有一些更細節的內容涉密就不多說了, 宏觀說幾點吧....從算子層來看, Group GEMM的細粒度打滿TensorCore, Warp specialization的處理, 如何統一ScaleUP和ScaleOut network, 如何更加容易的融入到現在的在線鏈路上? 然后這些RL模型是否可以逐漸做到按天的夜間FineTune白天上線快速迭代等?
最最后一條, 當前MoE性能的優化主要還是在AlltoAll, 優化的方式并不是說, ok, 因為延遲敏感需要一個更低延遲的網絡通信, 而是如何通過一些microbatch等調度策略, 保證在一定通信延遲門限下能夠足夠的隱藏延遲.
舉個例子吧, DeepSeek為什么Decode階段要采用P2P直接RDMA通信,而不是像訓練那樣采用PXN呢? 其實在一定的SLA約束下, ScaleUP的帶寬和延遲并不是那么極致的需求, 相反如何scaleOut, 才是關鍵. 這樣就會導致一個潛在的問題, 例如采用Multi-Rail或者Rail-Only的組網,可能由于Expert的放置和過載, 需要跨越不同機器的不同Rank通信. IBGDA可能只是一個暫時的方案, 是否會因為這些新的需求, 又回到傳統的CLOS架構, 放棄Rail-based部署呢? 特別是Decode階段的延遲問題處理上, 假設未來部署的集群專家并行規模大幅度提升呢? 這就成為一個軟硬件協同的很有趣的問題了, 建議算法團隊和一些有硬件能力的團隊更加緊密的合作, 算法對硬件妥協, 硬件進一步解鎖...
再進一步, 正如DeepSeek論文所示, Dynamic Routing, Experts placement也是一個很有趣的話題. 而DeepSeek對于未來硬件的建議也非常清楚的擺在那里了, 后面隨著推理的規模上量, 各個云之間卷推理成本而提高性能的事情
結論: 加大一些開源生態的投入吧:) 自己卷, 卷不過生態的.
參考資料 [1]
Enhancing DeepSeek Models with MLA and FP8 Optimizations in VLLM: https://neuralmagic.com/blog/enhancing-deepseek-models-with-mla-and-fp8-optimizations-in-vllm/
[2]
deepseek-v3-sglang: https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3#example-serving-with-2-h208
-
DeepSeek
+關注
關注
1文章
798瀏覽量
1746
原文標題:談談DeepSeek-R1滿血版推理部署和優化
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「DeepSeek 核心技術揭秘」閱讀體驗】書籍介紹+第一章讀后心得
Arm Neoverse N2平臺實現DeepSeek-R1滿血版部署

如何使用OpenVINO運行DeepSeek-R1蒸餾模型

RK3588開發板上部署DeepSeek-R1大模型的完整指南
行芯完成DeepSeek-R1大模型本地化部署
思必馳接入DeepSeek-R1滿血版大模型
Infinix AI接入DeepSeek-R1滿血版

了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
超星未來驚蟄R1芯片適配DeepSeek-R1模型
Deepseek R1大模型離線部署教程

DeepSeek-R1本地部署指南,開啟你的AI探索之旅

芯動力神速適配DeepSeek-R1大模型,AI芯片設計邁入“快車道”!

原生鴻蒙版小藝App上架DeepSeek-R1, AI智慧體驗更豐富
對標OpenAI o1,DeepSeek-R1發布





 工商網監
工商網監
評論